Как компания Intel решила в очередной раз поменять правила игры и переизобрести компьютеры
Буквально несколько часов назад закончилась конференция Intel Architecture, на которой обновленная техническая команда корпорации рассказала нам о том, как в ближайшее время будет развиваться продукция гиганта, а с ней, понятно, и весь мир. Поделюсь с вами кратким пересказом самых интересных тезисов этого восьмичасового дня, насыщенного техническими и футурологическими подробностями.
Для начала как всегда о том самом законе. Да, вы знаете, о каком
С новыми интересными решениями в процессорном и графическом сегменте вот уже несколько лет было не то чтобы очень хорошо. Наращивалась мощность, уменьшался теплопакет, интегрированные графические ядра становились все более производительными, и, при этом с архитектурной точки зрения изменения были минимальны. И если в потребительском сегменте таким компаниям как Qualcomm или AMD удавалось навести шороху, в основном из-за эффективного решения определенных конкретных задач, то в архитектурном плане, увы и ах, наблюдался некоторый застой.
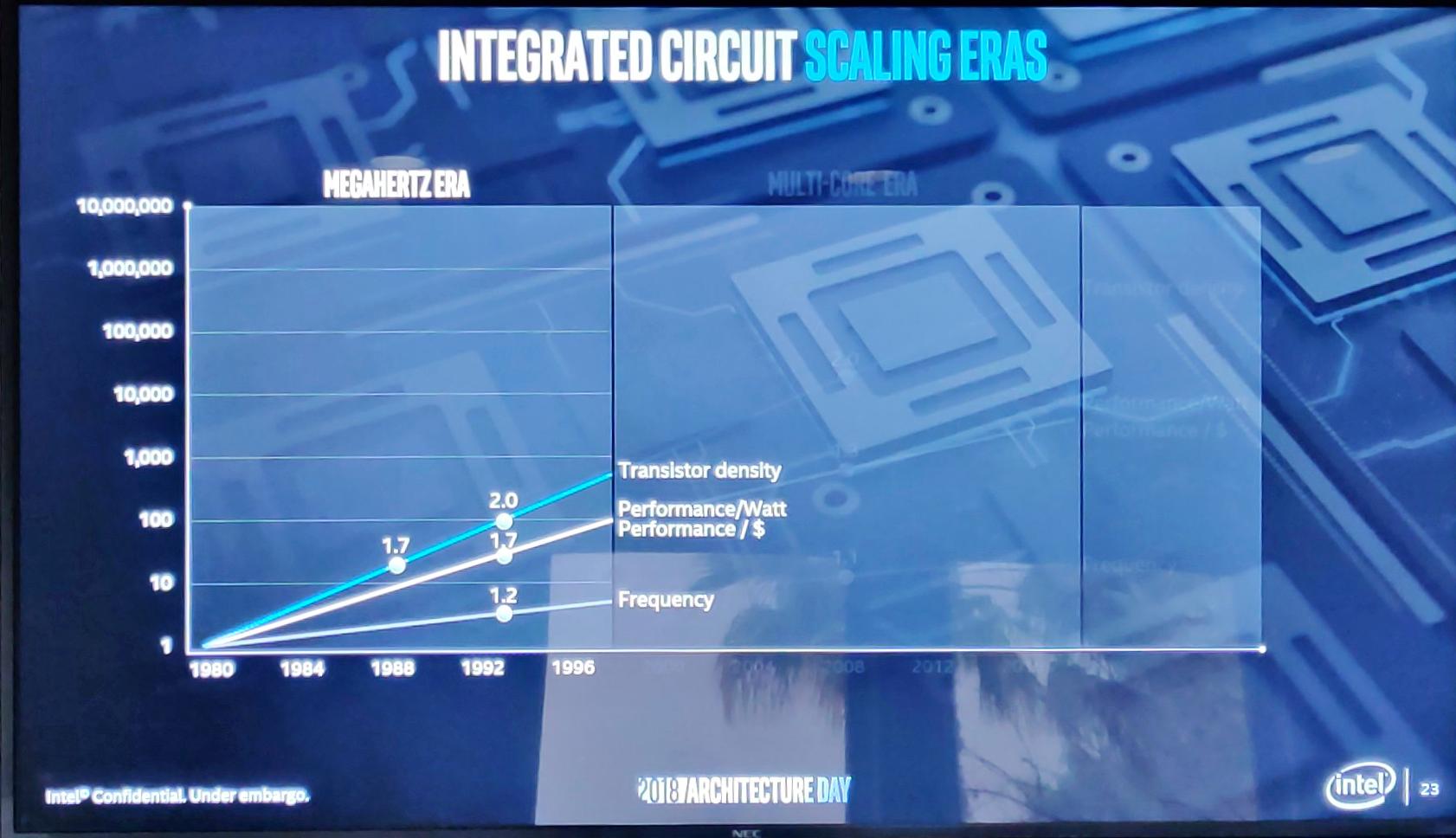

Оно и понятно — наращивать производительность по старой схеме "золотого времени мегагерц" было уже практически невозможно: техпроцесс становился все ближе к теоретическому пределу, а наращивание мускулов ядрами конечно давало свои плоды, но количество задач, которые не поддавались многопоточной оптимизации, оставалось слишком большим, чтобы не обращать на него внимание.
И более заметным замедление стало в последние пару лет, когда вроде уже должен был вступить в царствование обещанный к массовости 10нм техпроцесс.

Но он так и оставался слишком дорогим с точки зрения выхода годных кристаллов, чтобы переводить на него все подряд. Тогда-то и сломались доселе исправно поддерживавшие закон Мура часики Тик-Ток.

В общем, по словам Raja Koduri, бывшего главы Radeon Technologies Group, а ныне старшего вице-президента Intel Core and Visual Computing Group, настало время что-то сделать с архитектурой, чтобы увеличить «ценность для пользователя» каждого вложенного доллара и тем самым соблюсти модифицированный закон Мура.

Я вижу, как многие напряглись — но поспешу успокоить (а кого-то и разочаровать) — конечно, речь не идет о том, чтобы вывести в свет все еще (и иногда хочется сказать «вечно») сырые идеи вроде наработок Бориса Арташесовича Бабаяна, о них будет написано еще много подобных оптимистичных статей. Основной вектор развития на грядущие несколько лет — изменение упаковки. Давайте объясню это на примере.
Смотрите — вот обычный компьютер. В нем есть гетерогенные части — отдельные дискретные платы, выполненные на самых различных техпроцессах.
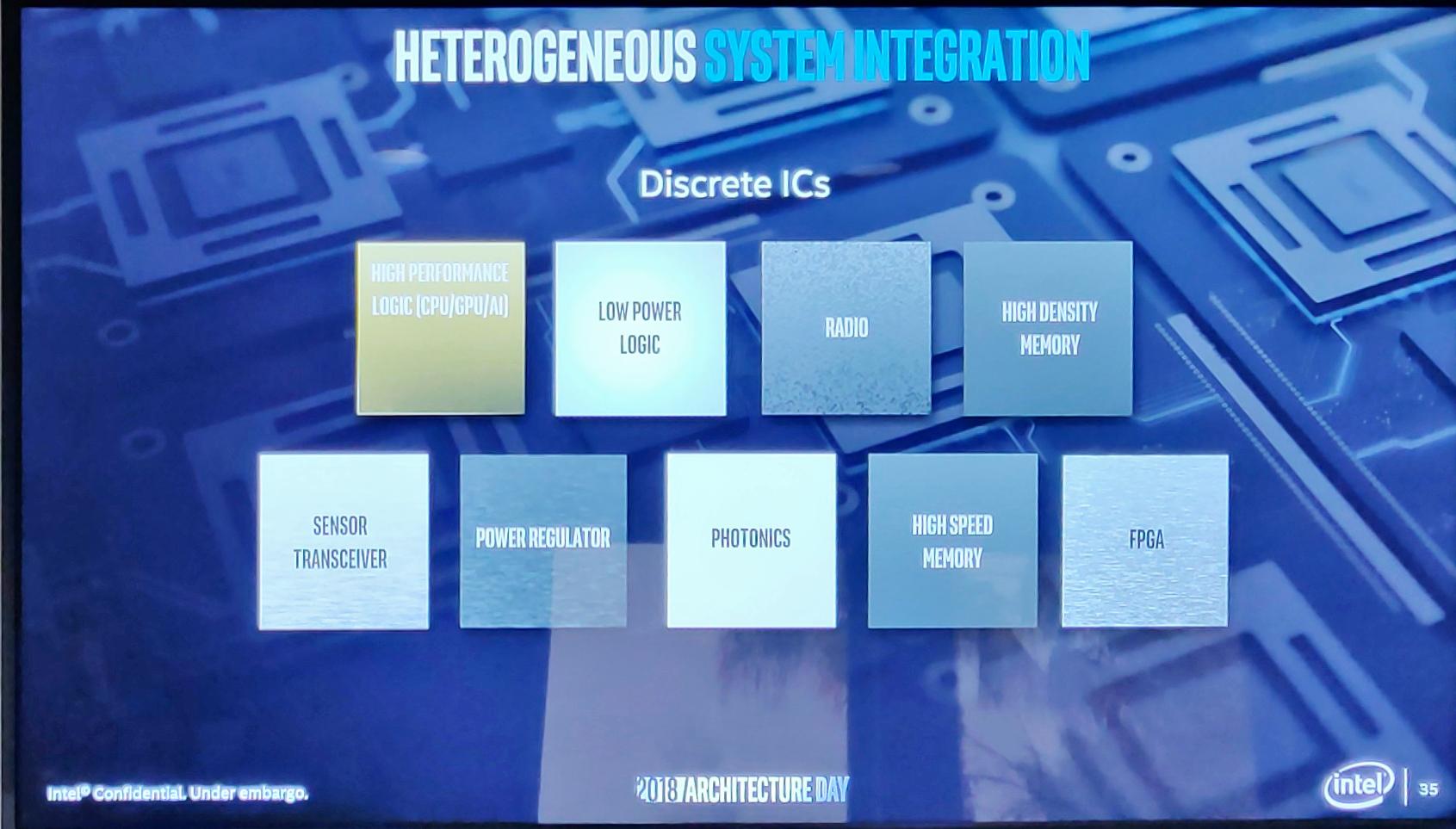
Современные же технологии упаковки процессоров выглядят примерно так — все их части гомогенны, выполнены по одному и тому же техпроцессу, притом, что зачастую это не так уж и нужно.

Вывод напрашивается сам собой, и идея вовсе не нова, просто на нее еще не делали такую мощную ставку. Давайте будем собирать монолитные системы на чипе на основе разного техпроцесса, главное — сделать быструю связь между такими разнородными частями (и кое-что еще, но об этом — позже).

Об этой технологии интерконнекта нам изначально рассказали еще в 2017 году, правда, тогда на нее не обратили особого внимания. Она получила название Foveros.

При этом, сама суть Foveros — в трехмерной упаковке (о чем тоже начали говорить, еще когда делали 22-нм техпроцесс). Это позволяет сделать передачу данных между частями сборки гораздо быстрее и отзывчивее, банально потому что физическое расстояние от компонента до компонента меньше, чем при двумерном расположении.

И, как уже упоминалось, одной из важных фишек стала также возможность упаковки частей, выполненных по разношерстному техпроцессу.

Вот такая схема, в частности, у первого продукта, сделанного по технологии Forevos, гибридного мобильного процессора. Как видите, у него всего 2mW потребление в режиме standby, и при этом наиболее критичная к техпроцессу часть, отвечающая за вычисления, выполнена по технологии 10нм. И все это упаковано в трехмере, что позволяет физически сократить длины связей.

Вообще, подобная возможность «смешивать и взбалтывать» открывает очень широкие возможности — нам пообещали, что за 10 лет появится больше архитектурных инноваций, чем за прошлые 50. Изначально, услышав это, я подумал — ну вот и Intel уже стал лукавить в своих заявлениях, ведь фактически «дискретно» собрать разные процессоры из готовых компонентов — это не совсем то, что мы раньше подразумевали под «новой архитектурой», хотя формально и является правдой, ведь так?

Но по факту все оказалось куда интереснее. Вот смотрите. Компания Intel производит процессоры с разнообразной структурой — скалярной (это процессоры общего назначения), векторные (тут правильнее будет конечно сказать векторно-конвейерные), это графика, матричные для целей искусственного интеллекта (потребителей это не очень касается, но по факту сегмент растет с бешеной скоростью), ну и «пространственная» (хотя я не помню, чтобы этот термин так употребляли в русском языке) — для ПЛИС, которые применяются для специализированных задач.
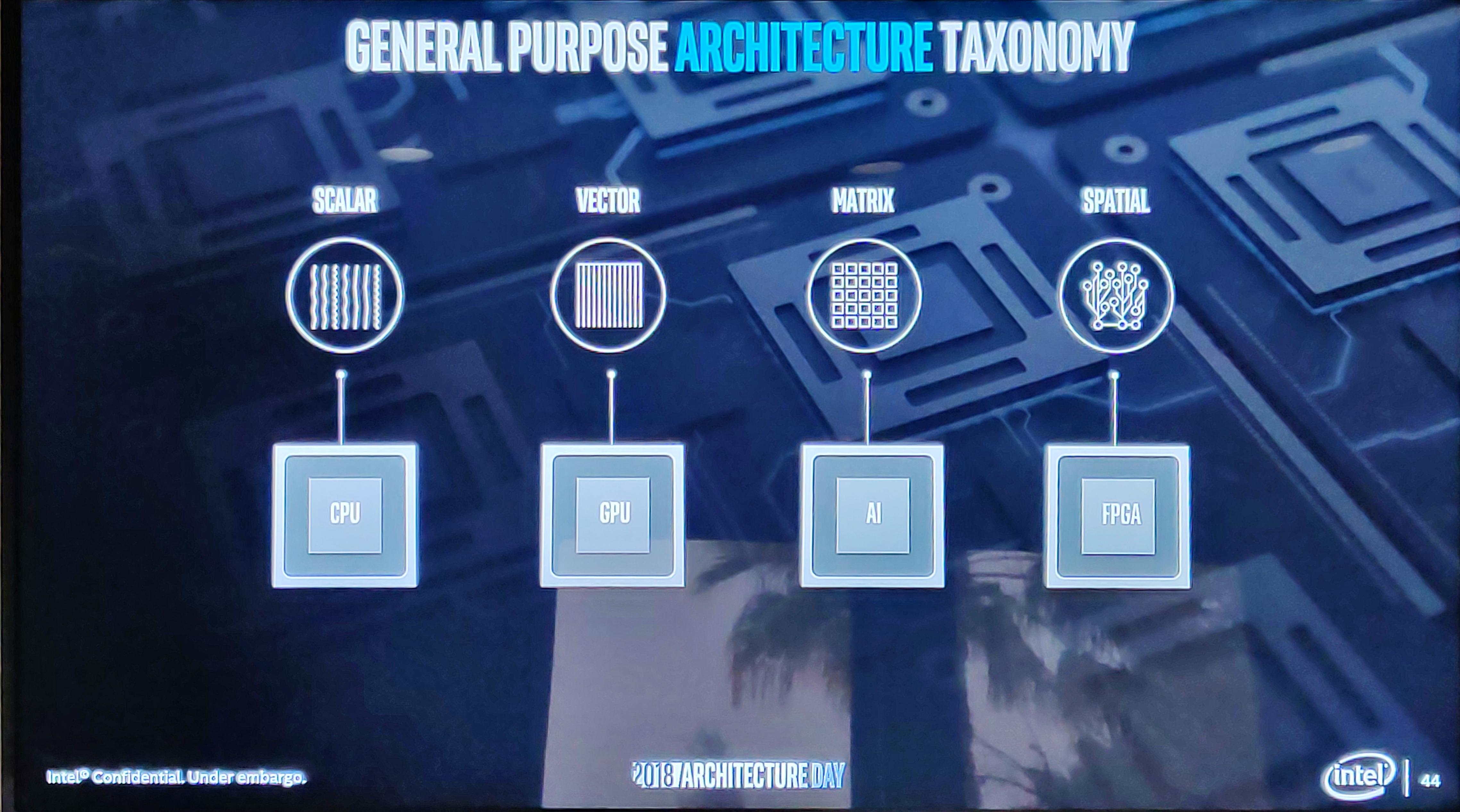
Каждые из этих вариантов процессоров находятся в разных местах по осям «универсальность — скорострельность». Обычные CPU — наиболее универсальны и наименее скорострельны, GPU лучше решают определенный тип задач (а за счет того, что такая архитектура хорошо масштабируется — скорострельность их наращивать не так уж и дорого).

Матричные блоки и вовсе «заточены» под решение определенных типов задач, специфичных, например, для распознавание образов и «впихнуть» в них что-то, требующее, например, большого количества монолитной адресуемой памяти — нереально.

Занятно, что на предыдущем слайде Раджа Кодури оперировал понятием «интеллигентности архитектуры», определяя ее как произведение производительности на универсальность. Понятно, что такой подход условен, но, тем не менее, позволяет неким более-менее понятным способом сравнивать разномастные процессоры.
Компоненты вычислительных систем будущего
Для того, чтобы было понятнее будущее, давайте посмотрим на «кирпичики», из которых Intel собирается городить вычислительную технику будущего, причем не только с помощью трехмерной упаковки.
Процессоры в самых разных вариантах
Начнем с центральных процессоров и небольшого повторения. Так, в 2001 году перестала бурно расти однозадачная производительность...

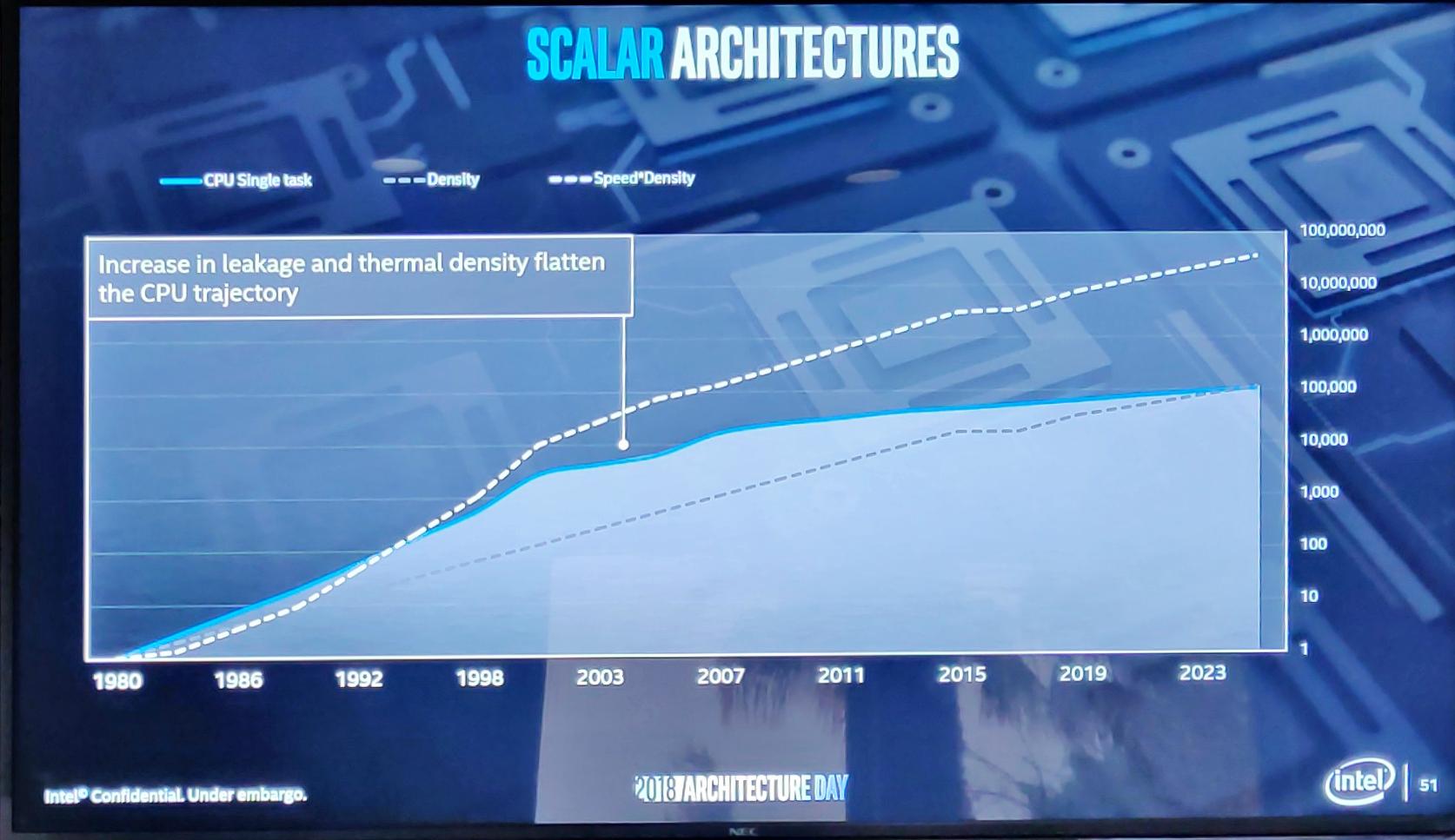
Ну и чем все закончилось — вы помните, в 2005 году с появлением многоядерных процессоров рост производительности восстановился.
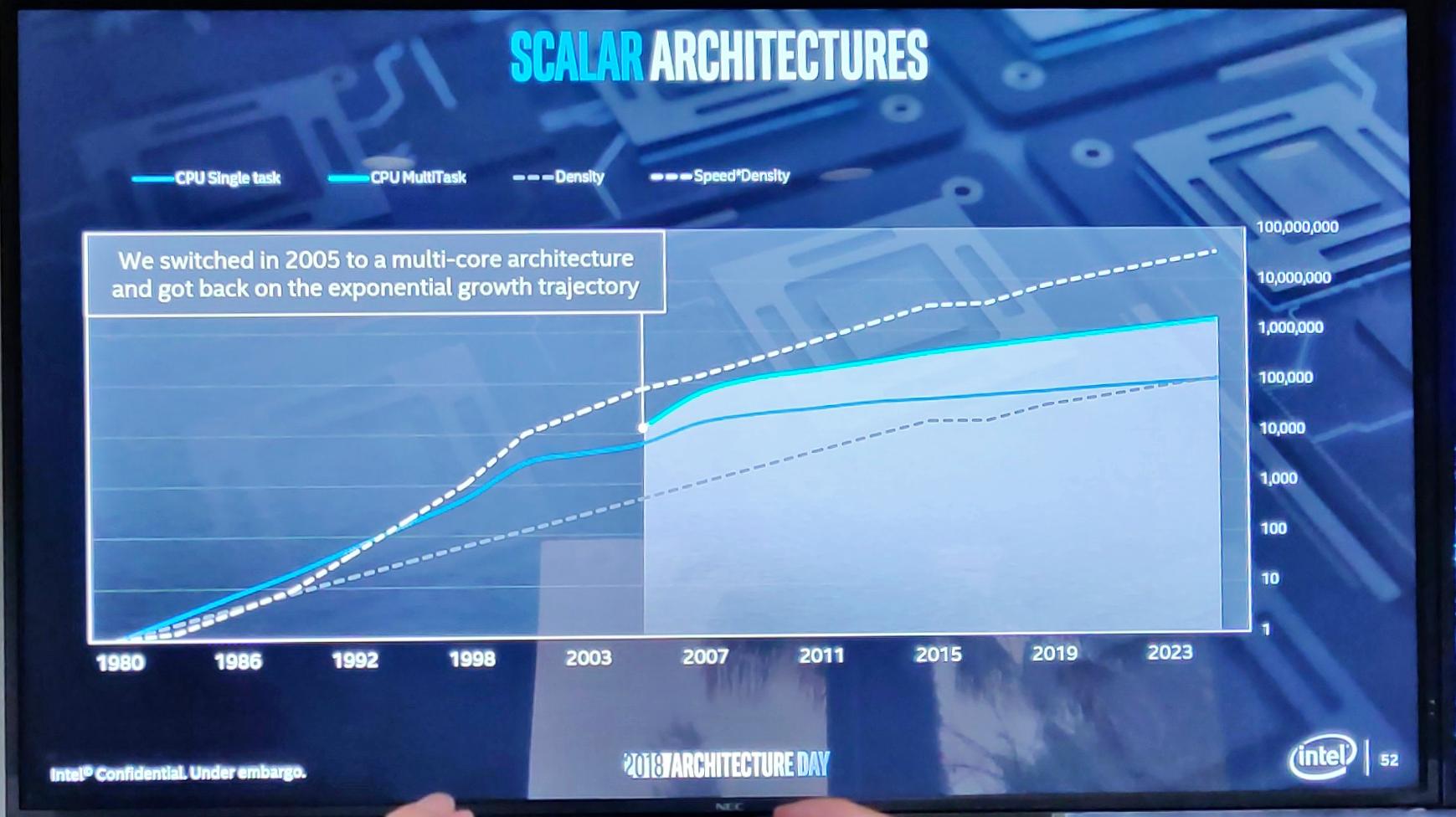
И сейчас у Intel есть две архитектуры, между которыми в последнее время уже не так уж и много общего — Core и Atom.

При этом, работа в традиционных процессорных ипостасях продолжается, вот так выглядит дорожная карта Intel на ближайшие несколько лет (обратите внимание на то, что 'Next Month" это на самом деле 'Next Mont' :)

В случае с графикой все проще и банальнее, здесь у Intel был «низкий старт», и ежегодно встроенная графика показывает производительность на десятки процентов (а иногда и в разы) больше, чем прошлое поколение.
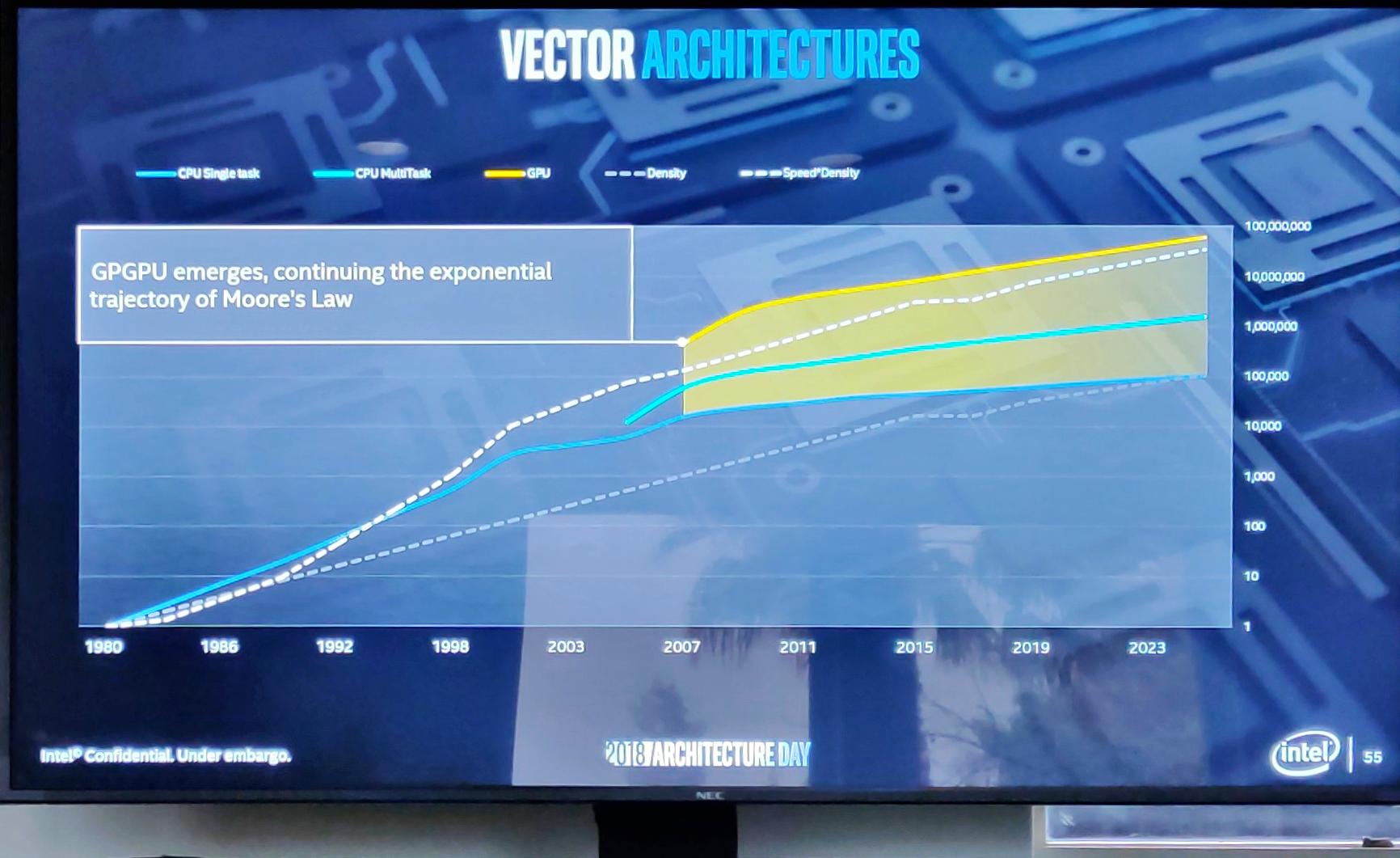
В ближайших планах Intel — появление встроенной графики 11 поколения (да, все правильно, 10 поколения не будет).

Фишек в нем будет не так уж и много, в основном это первый терафлоп на встроенном GPU (раньше все не достигало), удвоение обработки за такт, а также появившаяся возможность очень легко сделать «загрубление» пиксельных шейдеров в тех местах, где это не важно игроку (например, на периферии зрения в играх с видом от первого лица).

Технически это опять позволило поиграть в очередную игру, в которую нельзя было поиграть на предыдущем поколении (конечно, разработчики игр при этом продолжили все так же планомерно увеличивать количество игр, в которые на текущем поколении играть некомфортно).
Гораздо интереснее то, что в будущем (а точнее, уже к обозримому 2020 году) благодаря трехмерной упаковке графические ядра можно будет собирать в разных вариантах, создавая тем самым графику с разной требуемой производительностью (от терафлопс до петафлопс). Сборки будут отличаться по производительности, в более бюджетном сегменте будут X-Client Optimized, а в дорогом X-DC, то есть, оптимизированные для датацентров.

Для матричных процессоров планируется усложнение каждой вычислительной единицы.
Понятно, что часть задач матричных процессоров все еще можно будет выполнять на графических ускорителях общего назначения, и тут наибольшую роль будет играть улучшение ПО. По сравнению с неоптимизированным ПО, распознавание образов на этапе запуска Skylake было уже в 50 раз быстрее.
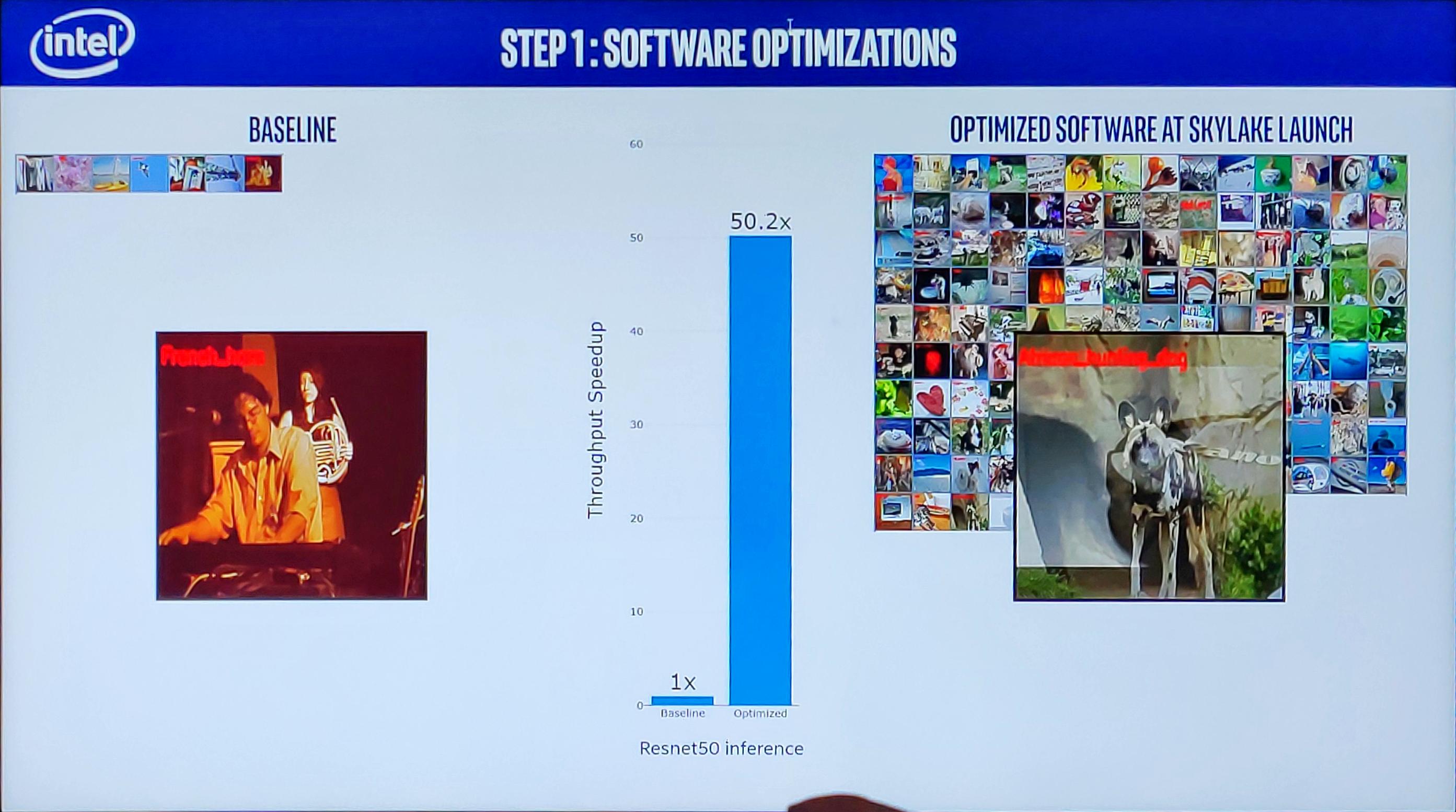
Дополнительные оптимизации уже после запуска позволили добиться улучшения производительности еще в 5.5 раз на Skylake, и с незначительными оптимизациями железа — еще в 2 раза на Cascade Lake.

На этом графике можно посмотреть на то, как три основных типа процессоров следуют закону Мура, и какие планы у компании Intel в этом отношении на ближайшие несколько лет.

Но, конечно, больше всего где развернуться с помощью новой технологии упаковки будет у FPGA процессоров.

Заточенные под определенную задачу процессоры с помощью трехмерной упаковки собираются как нельзя лучше благодаря своей структуре.

Ну и простор для оптимизации тут огромный — можно улучшать каждый логический блок, благо они простые, можно улучшать интерконнект, можно — ПО.

И как раз на FPGA процессорах уже и была опробована гетерогенная архитектура — имеются в виду продукты Arria 10 и Stratix 10.

Впрочем, после введения трехмерной упаковки, произошел количественный скачок, который фактически стал качественным. В новый Falcon Mesa (именно так называется грядущая серия FPGA процессоров) можно теперь добавить элементы, которых раньше для определенных задач не хватало (например, GPU и блок ASIC, или и вовсе универсальный процессор).

Остальные нововведения не так впечатляют, но тоже хороши. Если раньше максимальная скорость трансиверов на 14нм технологиях составляла 58G...
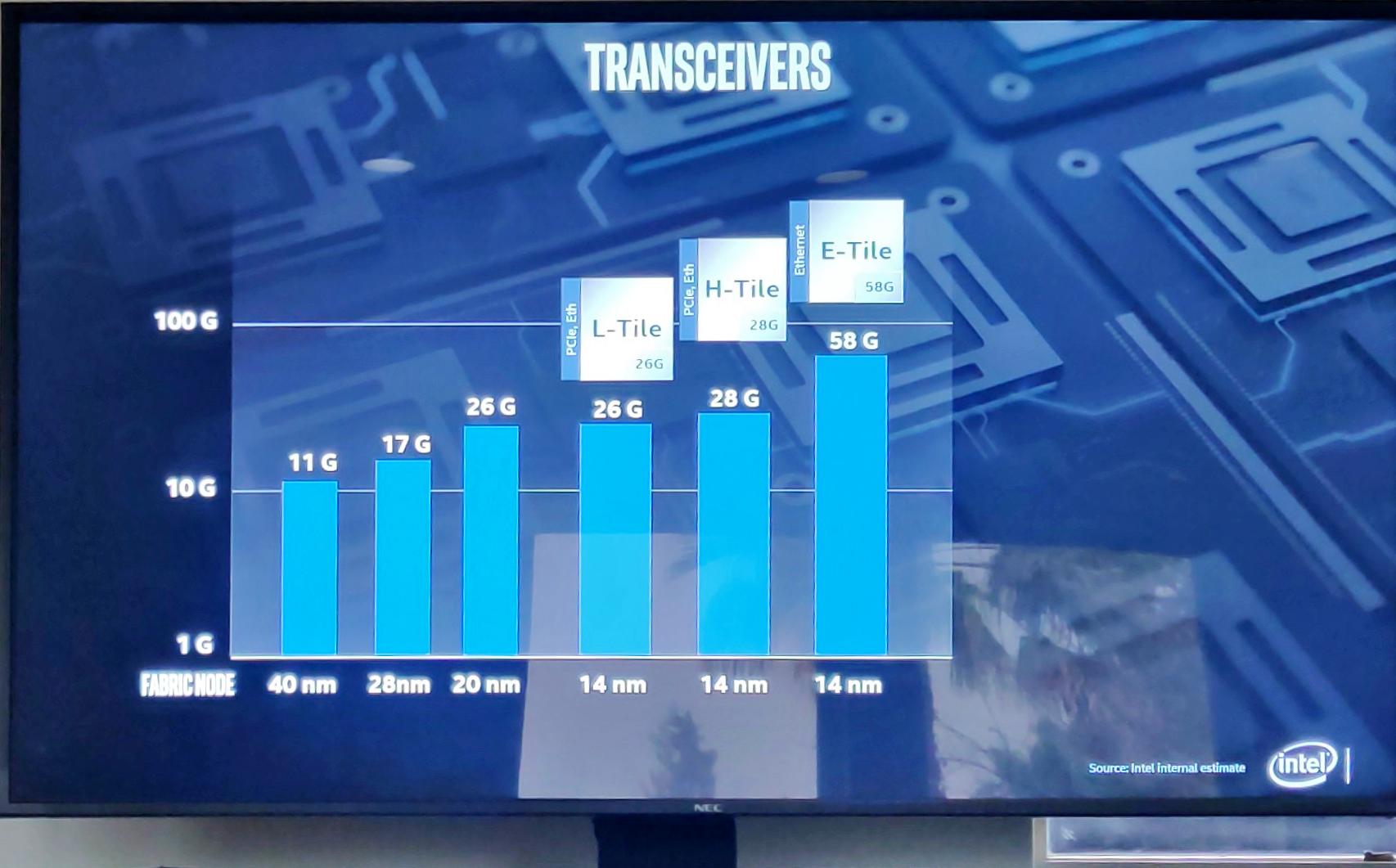
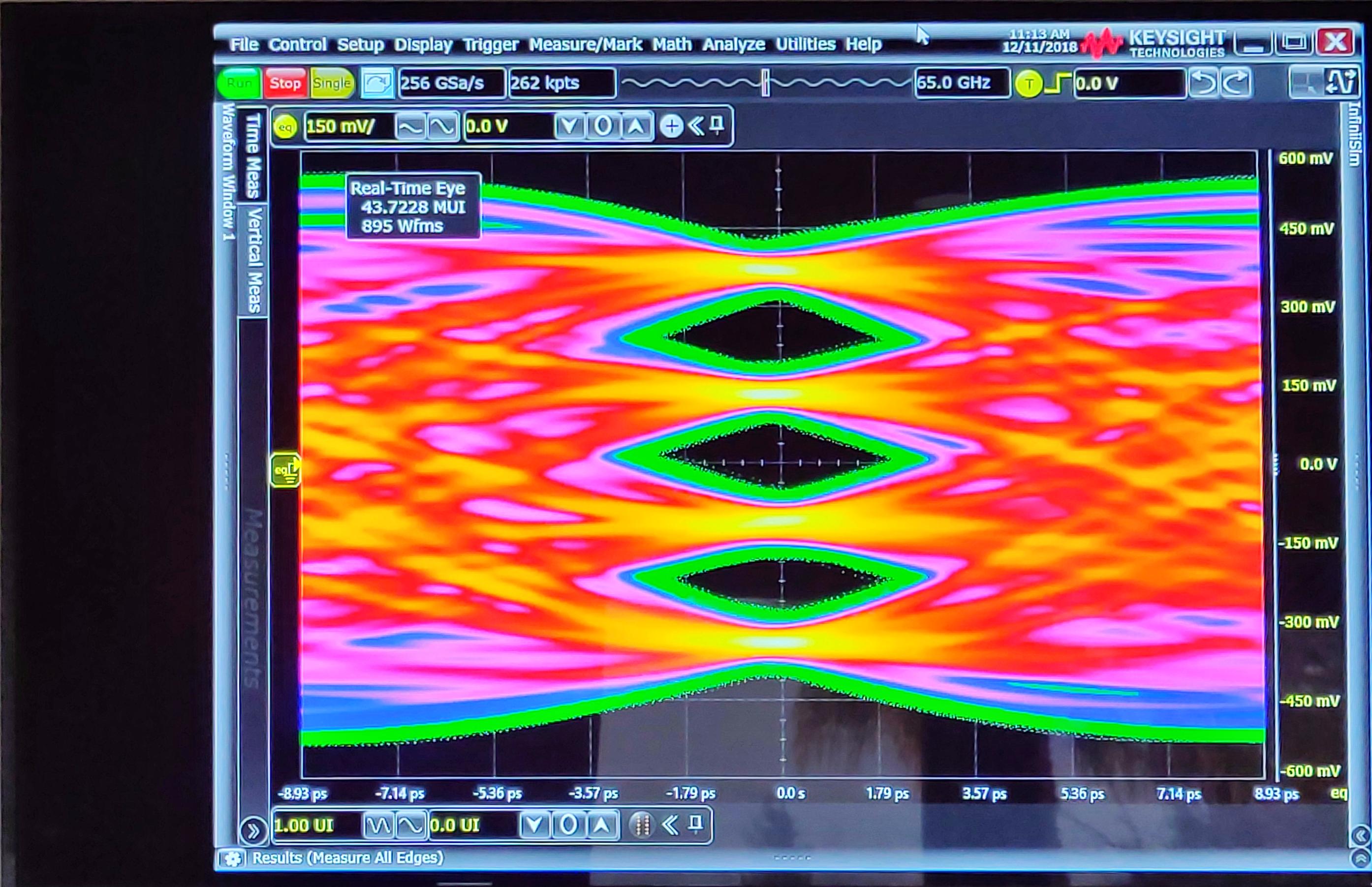
То на 10нм — уже 112G, при этом соединение было очень стабильным — динамическая диаграмма передачи выглядела как эта статическая картинка. Я не шучу.


С процессорами вроде разобрались.
Память
С ней все просто и сложно одновременно. Просто — в том смысле, что с ней понятнее всего, что нужно делать. Вот такая вот у нас есть ее иерархия, где самый быстрый — процессорный кеш. Затем следует новоизобретенная Intel память «в упаковке» — фактически это очень большой кеш, но за счет возможности комбинировать гетерогенные компоненты на чипе, теперь его можно сделать дешево и эффективно.
Следующая — известная нам динамическая память, в которой уже оптимизировать вроде бы нечего. Дальше хранилище «очень горячих данных» в большом объеме или постоянная память. Раньше многие пытались уже что-то подобное сделать, городить всевозможные DRAM с батарейками, и все в них было хорошо, кроме батареек. Здесь же Intel обещает сделать энергонезависимую память. Основное отличие ее от быстрых SSD — в том, что постоянная память работает на уровне команд процессора, без вызова OS.
Ну и, напоследок, Intel хочет добавить дополнительную прослойку между холодными данными и теплыми — QLC 3D NAND SSD, то есть, дешевые и медленные SSD на четырехуровневых ячейках, трехмерно упакованных.

Занятно, что компания Intel распределяет уровни иерархии памяти по отзывчивости, и каждый уровень получается отзывчивее в 10 раз. Что же, логично.

С пропускной способностью все не так просто и красиво, но тоже логично.

Рассказ о памяти получился коротким, но я вернусь к ней в следующей статье.
К дальшейшим «частям» новой платформы компания Intel относит:
Безопасность
Здесь все более-менее понятно — у компании есть множество уровней, начиная от уровня SoC и заканчивая ПО.

Ну и, конечно же, важным компонентом обновленной технологической платформы станет
Программное обеспечение

На этом я завершу общий обзор компонентов грядущих «компьютеров будущего» компании Intel, хотя у меня и много что есть еще рассказать. Просто в Санта-Кларе уже 2 часа ночи, а через 5 часов мне вставать на самолет. Во время перелета я закончу еще одну часть рассказа, и, надеюсь, он будет немного менее сумбурным :) Поэтому, оставайтесь с нами, задавайте вопросы в комментариях и пишите свои соображения по поводу систем будущего. Ну и расскажите, с чего лучше начать рассказ — с CPU, GPU, или искусственного интеллекта?











37 комментариев
Добавить комментарий
Так что самое горячее повыше, самое холодное и мелкое — ниже
А тут ничего страшного, просто спекаем усё в 1 блин, ядро делаем по 10нм (больше ничего сделать не получается), память по 100нм. Расходимся, презентация ни о чём.
Добавить комментарий