Как люди запоминают тысячи слов, не перегружая мозг: скрытый закон всех языков мира
Каждый день мы произносим тысячи слов, не задумываясь о том, как они устроены. Мы просто извлекаем их из памяти по мере необходимости. Однако если посмотреть на язык как на систему, мы обнаружим глубокий парадокс, связанный с возможностями нашего разума.
Человеческая память имеет физические ограничения. Мы не способны запомнить отдельное, полностью уникальное слово для каждого объекта, действия, свойства и состояния во Вселенной. Если бы мы попытались это сделать, наш словарь состоял бы из миллионов слов, а дети были бы вынуждены учиться говорить десятилетиями.

В то же время мы не можем использовать слишком мало слов. Если бы мы называли все окружающие нас предметы всего парой десятков терминов, мы бы постоянно путались. Общение потеряло бы всякий смысл, так как собеседник не мог бы понять, о чем именно идет речь.
Любой существующий язык — это результат непрерывного поиска компромисса. Он должен быть достаточно простым, чтобы его можно было легко выучить, и достаточно точным, чтобы люди понимали друг друга без ошибок. Недавнее исследование международной группы лингвистов доказывает, что этот баланс не случаен. Он подчиняется строгим законам человеческого мышления, которые работают абсолютно одинаково в русском, китайском, английском или в языках коренных народов Южной Америки.
Содержание
Колексализация, или как уместить несколько смыслов в одном слове
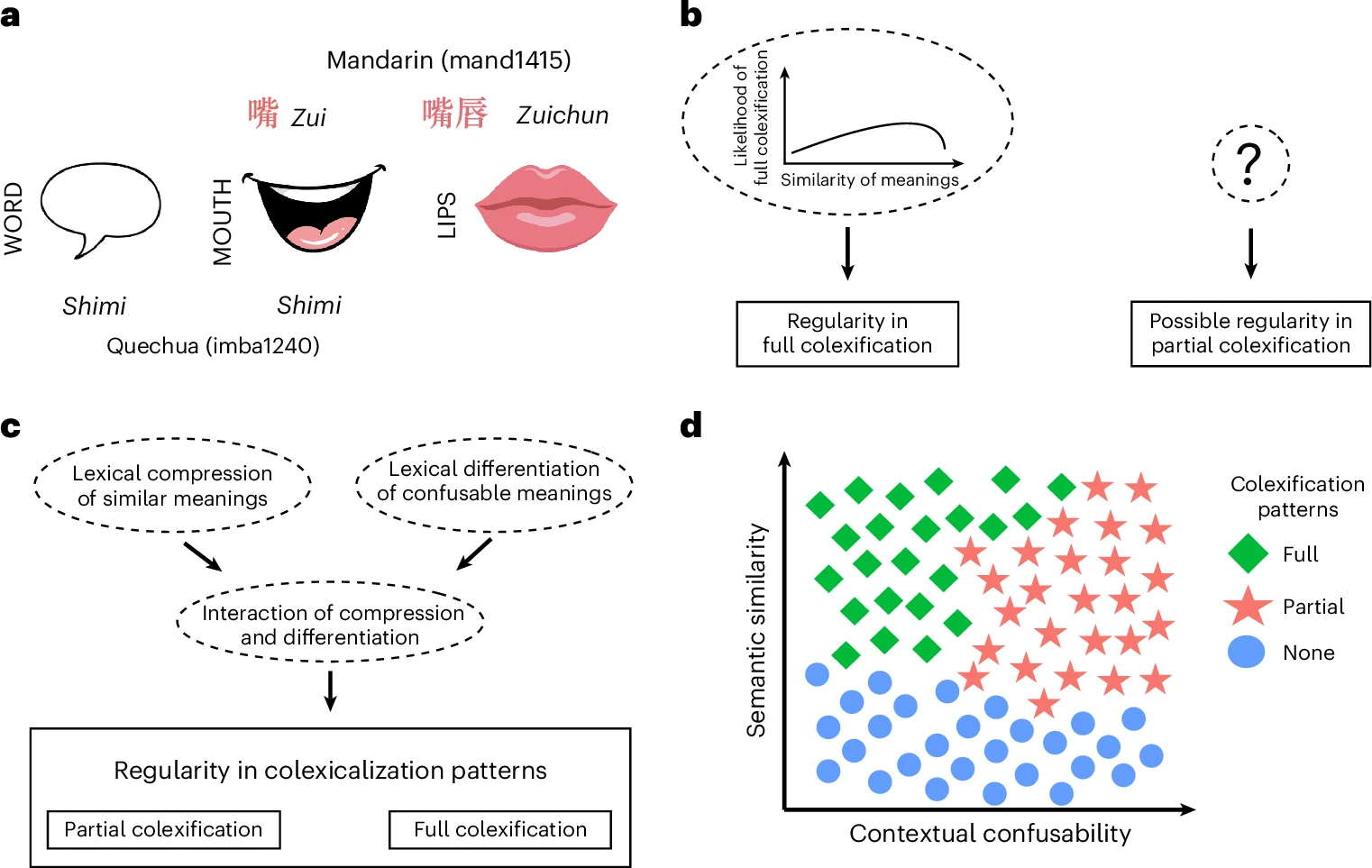
Для экономии усилий все языки мира используют один и тот же базовый прием. Лингвисты называют его колексализацией. Это явление, при котором одно и то же слово используется для обозначения разных, но близких по смыслу понятий.
Рассмотрим простые примеры. В русском языке слово «рука» обозначает и кисть, и всю конечность до плеча. Во многих европейских языках для этого существуют разные слова (например, hand и arm в английском). Почему русский язык объединил эти понятия? Потому что в повседневной жизни они тесно связаны, и нам редко требуется разделять их в обычной беседе.
Другой пример — слово «язык». Оно означает и орган чувств во рту, и систему общения между людьми. В испанском языке слово lengua выполняет точно такую же двойную работу. В языке кечуа, на котором говорят в Южной Америке, слово shimi означает одновременно «рот» и «слово». Еще один классический пример, встречающийся во многих языках мира — использование одного и того же слова для обозначения живого дерева и древесины как материала.
Это происходит потому, что нашему мозгу так удобнее. Вместо хранения в памяти двух разных слов мы храним только одно. Когда мы слышим его в предложении, наш разум мгновенно определяет истинное значение по контексту. Мы не путаем язык как орган и язык как предмет школьной программы, потому что они используются в совершенно разных ситуациях. Это позволяет экономить колоссальное количество ментальных усилий при обучении и повседневном общении.
Противоречие между экономией сил и точностью речи
Чтобы понять, как именно язык находит компромисс при создании слов, необходимо детально разобрать две основные потребности человека в процессе общения.
Первая потребность — это экономия усилий. Наше мышление устроено так, чтобы минимизировать траты энергии. Если мозг может не запоминать новое слово, он его не запомнит. С этой точки зрения идеальным решением было бы называть похожие вещи одним словом.
Вторая потребность — это точность. Если мы будем говорить слишком обобщенно, нас перестанут понимать. С этой точки зрения идеальным решением было бы иметь уникальное название для каждой мелочи.
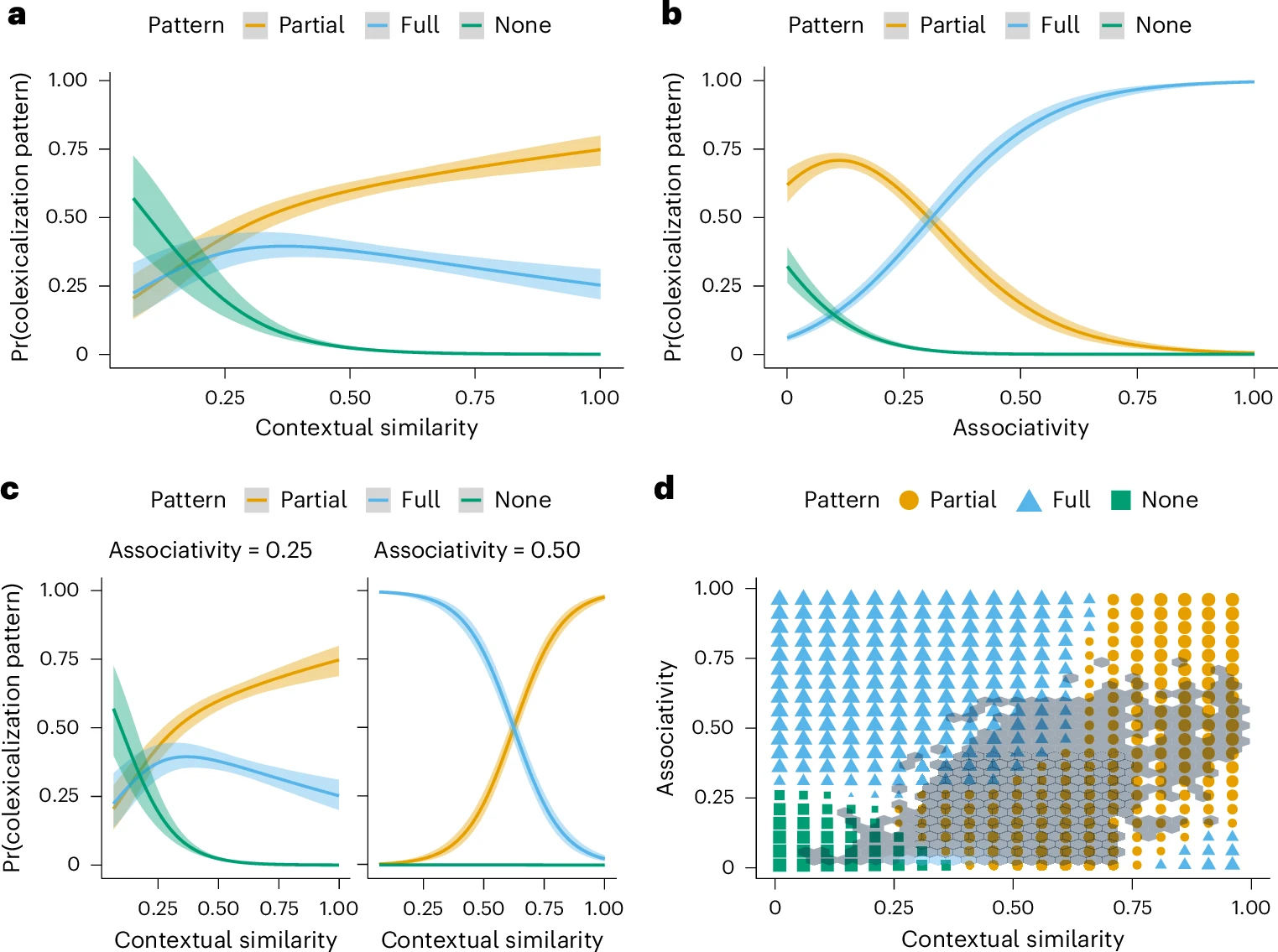
Как язык определяет, какие значения можно объединить в одном слове, а какие должны остаться разделенными? Ученые выяснили, что ключевую роль играют два фактора: семантическая ассоциативность (ментальная близость понятий) и контекстуальное сходство (вероятность встретить эти понятия в одинаковых предложениях).
Рассмотрим это на конкретных примерах.
Возьмем слова «стол» и «стул». В нашем сознании эти понятия тесно связаны. Когда мы думаем о столе, мы часто представляем себе и стул рядом. Однако ни один язык мира не называет стол и стул одним и тем же словом. Причина кроется в их высоком контекстуальном сходстве. Мы употребляем эти слова в абсолютно одинаковых предложениях: «Я купил новый [стол / стул]» или «Поставь это на [стол / стул]». Если бы для них существовало только одно слово, собеседник никогда бы не понял, о каком именно предмете мебели идет речь. Риск совершить ошибку и запутать слушателя здесь слишком велик. Из-за этого контекстного сходства язык вынужден разделять эти понятия и давать им разные имена.
Теперь вернемся к примеру со словом «дерево» (как растение и как материал). Эти понятия тоже тесно связаны в нашей памяти. Но, в отличие от стола и стула, они используются в совершенно разных предложениях. Мы говорим: «На дерево села птица», но не можем сказать: «На материал села птица». Мы говорим: «Эта ложка сделана из дерева», но фраза «Эта ложка сделана из растения» в обычном разговоре прозвучит странно.
Поскольку эти два значения («растение» и «материал») практически никогда не конкурируют друг с другом в одинаковых фразах, риск запутаться минимален. В результате русский язык (как и многие другие языки мира) использует одно и то же слово для обоих понятий, экономя место в нашей памяти.
Как ученые проверили это правило на 1900 языках
Чтобы доказать, что этот принцип является универсальным законом человеческого мышления, а не просто особенностью нескольких крупных языков, международная группа исследователей провела масштабную работу. Они обратились к крупной лингвистической базе данных Lexibank.
В этой базе собраны сведения о структуре слов в 1982 языках, принадлежащих к 192 различным языковым семьям. В выборку вошли не только распространенные языки вроде английского, китайского или русского, но и редкие наречия малых народов Сибири, Африки, Австралии и Южной Америки.
Ученым нужно было математически точно измерить два параметра для тысяч понятий: ментальную близость в сознании людей и риск путаницы в предложениях.
Для измерения ментальной близости они использовали данные глобального проекта Small World of Words. В рамках этого проекта тысячи добровольцев, говорящих на разных языках, проходили тесты на свободные ассоциации. Им показывали слово и просили быстро написать первые три ассоциации, которые приходят в голову. Анализируя миллионы таких ответов, ученые смогли составить точную карту человеческой памяти. Она показывает, насколько близко друг к другу расположены те или иные понятия в сознании представителей разных культур.
Для измерения риска путаницы (контекстуального сходства) исследователи использовали компьютерные программы для анализа текстов. Эти программы изучили гигантские объемы литературы и зафиксировали, какие слова обычно окружают анализируемые понятия. Если два слова регулярно встречаются в окружении одних и тех же слов, компьютер делал вывод, что эти понятия легко спутать в живой речи.
Объединив все эти данные с помощью статистических моделей, исследователи обнаружили четкую закономерность. Во всех 1900 языках распределение слов подчинялось одному и тому же закону: чем выше ментальная связь между понятиями и чем ниже риск перепутать их в предложении, тем выше вероятность, что они будут называться одним словом.
Более того, ученые обнаружили, что эта закономерность сохраняет силу даже при использовании данных ассоциаций на английском языке для анализа языков других семей. Это подтверждает, что базовая структура ассоциативного мышления у всех людей на планете устроена примерно одинаково, независимо от того, на каком языке они разговаривают.
Частичное совпадение как компромиссное решение
Но что происходит в тех случаях, когда понятия очень близки в нашем сознании, но мы не можем назвать их одним словом из-за слишком высокого риска запутаться?
Типичный пример — понятия «рот» и «губы». Они находятся в одном месте, участвуют в одних и тех же процессах и постоянно упоминаются в близких ситуациях. Однако полностью объединить их в одно слово нельзя из-за разницы в физическом смысле: мы кладем пищу или лекарство в рот, но наносим защитный крем или помаду на губы. Если бы для этих понятий использовалось одно и то же слово, фраза «нанести мазь на рот» создавала бы опасную двусмысленность.
В таких ситуациях языки используют третий путь — частичную колексализацию. Вместо того чтобы придумывать полностью новое слово, никак не связанное с предыдущим, или использовать абсолютно то же самое слово, языки создают слова, которые частично перекрывают друг друга по форме.
Для этого используется морфология — приставки, суффиксы и сложение нескольких корней в одно слово.
В китайском языке слово «рот» звучит как zui. А слово «губы» — как zuichún. Мы видим, что слово «губы» буквально включает в себя слово «рот», но имеет дополнительную часть, которая указывает на конкретную деталь.
В русском языке мы видим схожие примеры: «бабушка» и «прабабушка». Эти понятия тесно связаны, но относятся к разным поколениям, поэтому называть их одинаково нельзя. Мы берем уже известное нам слово и добавляем к нему приставку «пра-«.
Это решение позволяет нашему мозгу экономить ресурсы. Нам не нужно учить с нуля совершенно новое, уникальное слово. Мы берем за основу уже знакомый корень («рот» или «бабушка») и добавляем к нему небольшое изменение. При этом слушатель мгновенно улавливает разницу и понимает, о ком или о чем идет речь.
Исследование показало, что этот метод работает систематически во всех языковых семьях. Как только риск путаницы между близкими понятиями становится слишком высоким для использования одного слова, языки во всем мире начинают использовать частичное совпадение форм. Это позволяет сохранять баланс между легкостью запоминания и точностью понимания.
Единый разум под разными масками
Долгое время в лингвистике велись споры о том, как развиваются языки. Часть ученых полагала, что языки формируются хаотично, под влиянием случайных исторических событий и культурных особенностей каждого народа. Казалось, что правила построения слов в каждом языке уникальны и не зависят от общих законов.
Данное исследование доказывает обратное. Несмотря на внешнее разнообразие звуков, алфавитов, грамматических правил и культурных контекстов, все языки мира строятся на одном фундаменте. Этот фундамент — устройство человеческого мышления и физиологические ограничения нашей памяти.
Наш мозг, независимо от расы, национальности и места проживания, решает одну и ту же задачу оптимизации. Он пытается тратить как можно меньше энергии на запоминание слов, сохраняя при этом возможность точно передавать информацию другим людям.
Поэтому язык — это прямое отражение нашей когнитивной системы. И когда мы изучаем, как строятся слова в русском языке, китайском или в языках коренных народов Южной Америки, мы видим работу одних и тех же универсальных механизмов человеческой логики и памяти.
Источник: Nature Human Behaviour











1 комментарий
Добавить комментарий