
Закон Мура против нанометров
Всё, что вы хотели знать о микроэлектронике, но почему-то не узнали…
Оглавление
Часть 1-я: Как всё начиналось — 1940–1989, а также о первых 1-кристальных процессорах.
Часть 2-я: Наши дни — 1990–2010, а также пример современного техпроцесса.
Часть 3-я: Анализ и перспективы — 70 лет микроэлектроники в таблицах и графиках, новый шаг Intel, макрохитрости микроэлектроники, и о будущем.
Как всё начиналось
1940-50-е
Давным-давно, в 1945 г. — когда вычислительная техника уже была электронной, но ещё релейно-ламповой (хотя британцы уже во Второй Мировой Войне использовали германиевые диоды) — руководство американской компании Bell Labs основало группу под руководством Уильяма Шокли по исследованию полупроводниковой замены вакуумным лампам, что и произошло через 2 года с изобретением транзистора. А в 1948 г. «transistron» был независимо изобретён работающими во Франции двумя немецкими физиками — Хэрбертом Матаре и Хайнрихом Велкером.
| Точечный транзистор. |
| «Транзистрон» на просвет в рентгене. |
| Один из первых биполярных транзисторов. |
 Прототип транзисторного радио на выставке в Дюссельдорфе (1953 г.) — чем не Айпод? :) |
 Прототип транзисторного компьютера в университете Манчестера “Manchester TC” (1953 г.). |
 Первый вытравленный рисунок был вовсе не частью транзистора, а надписью «Конец». Но оказалось всё наоборот… |
 5-кристальный осциллятор Килби. |
| Патент Эрни на пригодный для массового производства планарный транзистор. |
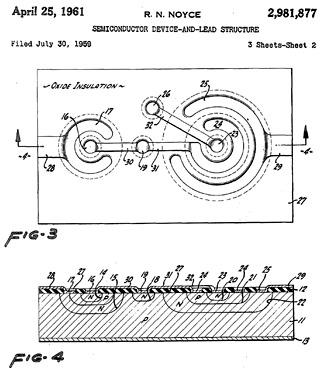 Патент Нойса на планарную ИС. Тут все контакты находятся уже по одну сторону от кремниевой пластины. |
 Кристалл первой «современной» микросхемы (1960 г.) — триггера с 4 транзисторами и 5 резисторами. |
 Ручная нарезка маски из рубилита применялась до 70-х гг. |
Правда, оба прибора были с неудобным в производстве точечным контактом к полупроводнику. В 1951 г. Шокли изобрёл биполярный транзистор с двумя p-n-переходами, полностью заменивший точечные уже к середине 50-х. К 1954 г. транзисторы уже стали обязательными компонентами в телефонных станциях и аппаратах фирмы Bell. Мудрейшим шагом компании было решение 1952 г. о продаже (за 25 000 долларов) лицензий на выпуск биполярных транзисторов 26 другим фирмам. Уже через 2 года появились транзисторные радиоприёмники, на время ставшие сутью самого слова «транзистор» в массовом сознании. В 1956 г. за открытие транзисторного эффекта Уильям Шокли и его помощники Джон Бэрдин и Уолтер Брэттэйн получили нобелевскую премию по физике.
После изобретения транзистора Шокли в 1956 г. основал компанию Shockley Semiconductor Laboratory, где изобрёл ещё один полупроводниковый прибор, названный им «диод Шокли». В отличие от транзистора, тут не 3, а 4 слоя полупроводника, что дало возможность блокировать прибор в открытом или закрытом состоянии без поддерживающего напряжения. Шокли был уверен, что это открытие не менее важно, чем транзистор, но на этот раз держал всё в секрете даже от своих сотрудников, что привело его к почти параноидальному поведению. В довесок, нерешительность Шокли при управлении проектами не давала возможность немедленно пустить идею в производство. Это так расстроило его коллег, что 8 наиболее молодых из них потребовали сменить главу компании. Когда стало ясно, что навстречу им не пойдут, «вероломная восьмёрка», как прозвала их жена Шокли, сама покинула компанию и в 1957 г. основала Fairchild Semiconductor для производства полупроводниковых транзисторов.
На тот момент под полупроводником электронщики понимали прежде всего германий. Транзисторы из него получались хорошие, но p-n-переходы были термически нестабильны (при том, что прибор заметно грелся), а дороговизна затрудняла распространение. Однако в 1952 г. впервые получен кристаллический кремний, а через 2 года Texas Instruments (TI) применила его в транзисторе. В 1955 г. всё в той же Bell Labs изобрели (точнее, впервые использовали для производственных целей) почти все основные технологические операции микроэлектроники: осаждение изолятора, фотолитографию с масками (для деталей аж в 200 микрон!), травление и диффузию. Тогда же сделали и первый полевой транзистор — именно такие (в миллиардных количествах) находятся в современных чипах. И ещё одно малоизвестное, но совершенно революционное открытие: в 1954 г. Чарлз Ли из Bell Labs изготовил транзистор с базой толщиной всего в 1 микрон и обнаружил, что он может работать на частоте до 170 МГц, что вдесятеро быстрее тогдашних аналогов…
В 1952 г. британский электронщик Джэффри Даммер опубликовал идею об интегральной схеме (ИС) как о «твёрдом бруске без соединяющих проводов». В 1956 г. Даммер попытался сделать первую микросхему, но неудачно. Через 2 года недавно принятый в TI молодой инженер Джэк Килби почти в одиночку сидел всё лето в лаборатории миниатюризации, т. к. компания не отпустила его в пока ещё не заработанный отпуск. 24 июля 1958 г. Килби написал в своей записной книжке, что если элементы электрической схемы (резисторы, конденсаторы и транзисторы) сделать из одного материала, то они могут быть помещены на общую пластинку (на сленге — «вафлю», причём в оригинале говорится только так: wafer). А 12 сентября Килби построил первую ИС из пяти элементов, выполняющую роль генератора — хотя она ещё не была однокристальной. Странно, что «нобелевки» за это достижение надо было ждать аж до 2000 г. …
Изобретение Килби имело большой недостаток — компоненты схемы соединялись золотыми проводками, что делало технологию малопригодной к дальнейшему уменьшению, усложнению и массовому производству. Однако к концу этого же 1958 г. Жан Эрни из Fairchild продемонстрировал размещение в кремнии областей с избытком электронов и дырок, вместе составляющих p-n-переход, над которым располагался изолятор из диоксида кремния. В изоляторе протравлено отверстие, которое заполняется алюминием, образующим контакт. А чешский физик Курт Леховец из калифорнийской компании Sprague Electric догадался использовать p-n-переход как изолятор. Наконец, в 1959 г. Роберт Нойс из Fairchild объединил обе идеи с возможностью напылять тонкий слой металла на схему. Этот слой потом выборочно вытравливался, получая одновременно все необходимые межсоединения, что сделало возможным изготовление более сложной схемы за несколько шагов. Так был изобретён планарный технологический процесс.
Правда, пока этот процесс подходил лишь для изготовления отдельных кристаллов. Но уже тогда стало ясно, что микросхем понадобится не меньше, чем дискретных элементов, а значит их производство должно быть более массовым. К счастью, в 1958 г. Джэй Лэст и Роберт Нойс построили один из первых фотоповторителей, позволявших на одну пластину проецировать множество копий маски. А в 1961 г. выпущены первые промышленные фотоповторители с уменьшением изображения — теперь маску можно сделать в 5–10 раз больше, что упрощало процесс её подготовки. Маски изготавливались переносом выполненных на прозрачной плёнке чертежей на лист рубилита, на котором координатограф полуручным способом гравировал оттиск. Сами чипы изготавливались из пластин диаметром всего 13⅓ мм, введённых в 1960 г. Право называться первой коммерческой оспаривают микросхемы Fairchild и Texas Instruments. Кстати, Уильям Шокли также достиг массового производства своего диода, но так и не добился успеха — потому что появились микросхемы, где 3–6 транзисторов могли заменить такой диод. (Вставить сюда фразу про злобного буратино — прим.авт.)
Впрочем, все микросхемы пока делались с биполярными транзисторами, и если бы так оставалось и впредь — не видать бы нам никаких персоналок и мобильников. Но в 1959 г. Джон Аталла и Дэвон Канг из Bell Labs изготовили полевой транзистор с изолированным затвором, чего не могли добиться с 1926 г., когда был открыт полевой эффект и указан его недостаток — поверхностные волны в металле не позволяли проникать полю затвора в канал. Получился всем сегодня известный «бутерброд»: металлический (Al) затвор, подзатворный оксид (SiO2) и канал-полупроводник (Si). И хотя первые два элемента уже давно делаются из других материалов, мы всё ещё называем это МОП-транзисторами. А в 1960 г. в Bell Labs изобрели ещё один нужный для массового производства процесс — эпитаксиальное осаждение тонкого слоя на кристаллической подложке, снова обнаружив, что малая толщина базы ускоряет биполярный транзистор.
В 1958 г. инженер Сеймур Крэй (уже тогда прослывший экспертом по компьютерам) устроился в компанию Control Data Corporation (CDC) на должность главного разработчика и сразу попросил фирму General Transistor изготовить быстрый германиевый транзистор для своей машины CDC 1604, ставшей в 1960 г. одним из первых коммерчески успешных диодно-транзисторных компьютеров (после IBM-овских моделей 1401 и 7090). Далее Крэй задался целью построить самый быстрый в мире компьютер (будущий CDC 6600), для чего ему нужен был транзистор со временем переключения менее 3 нс и способностью выдержать перегрев (ибо высокоплотный монтаж в электронике — тоже не сегодняшнее изобретение). P-канальные полевые транзисторы (в большинстве из них канал между истоком и стоком открыт при отрицательном напряжении на затворе относительно истока) в то время получались медленнее биполярных, а производили их просто потому, что они получались дешевле. Более быстрые n-канальные (канал открыт при положительном напряжении на затворе) появились только в 1964 г. Крэй заплатил фирме Fairchild аж 500 000 долларов, и в 1961 г. Жан Эрни, используя легирование золотом и эпитаксиальное осаждение, получил кремниевый биполярный транзистор, работающий быстрее германиевых.
1960-е
Товарищи из социалистического лагеря немедленно потребуют убрать тлетворное влияние частной собственности на средства производства и привести примеры ударных капиталистических строек, перевыполнения планов и прочие Закрома Родины — если таковое наблюдалось. Ну что ж… К 1961 г. авторитет США в мире был низок как никогда. 12 апреля стало ясно, что СССР постоянно выигрывает у США в космической гонке. 15 апреля США начали операцию “Pluto” (более известную как “Высадка в заливе Свиней”) по свержению Фиделя Кастро, ставшую одним из самых больших провалов ЦРУ. Ещё помнился перехват Гэри Пауэрса под Свердловском, когда президент Эйзенхауэр загнал себя и страну в ловушку, пытаясь скрыть разведывательный характер полёта “U-2”.
Нужна была некая национальная идея — знакомо?… 25 мая только что избранный Джон Кеннеди во 2-й раз обратился к нации (что само по себе необычно — обращения являются ежегодными) и заявил: «Я хочу верить, что мы сможем доставить человека на Луну и вернуть обратно до конца этого десятилетия». В отличие от “построения коммунизма к 1980 г.”, о чём в октябре того же 1961 г. заявил Никита Хрущёв, такая задача была не менее технической, чем идеологической. Помимо ракет и кораблей, надо было создать системы управления, которые сначала полетят на Луну в одиночку (в исследовательских миссиях), а затем будут отвечать за безопасность живых людей. А пока у США был лишь 15-минутный суборбитальный полёт и слабые ракеты. Поэтому программе выделили астрономические деньги (в сегодняшних ценах — 170 млрд. долларов) и присвоили высший приоритет.
 Логический вентиль производства Fairchild для AGC. |
 Модуль AGC производства Raytheon: корпус, плата и десятки ИС. |
По микроэлектронной части роль главного героя отводилась навигационному компьютеру для Аполлонов (Apollo Guidance Computer, AGC). До того момента первые чипы были относительно медленные и продавались по цене в несколько раз больше аналогичного набора дискретных элементов. И только в авиакосмических применениях миниатюрность и энергоэффективность оказались важнее недостатков, хотя ИС содержали лишь несколько компонентов. Уже в 1961 г. коллега Килби Харви Крэгон сделал демонстрационный “Молекулярный электронный компьютер” для ВВС США, в котором 587 ИС производства TI заменяли 8500 отдельных деталей. В этом же году чипы Fairchild уже применялись в простых компьютерах.
AGC оказался намного сложнее, требуя около 4000 логических вентилей по 20–30 долларов каждый. До 1965 г. AGC оставался самым большим потребителем чипов как по количеству (200 000), так и по общей цене. Боб Кук из TI изготовил первые экономные ИС для блока астронавигации. Одновременно (в 1962 г.) TI выиграла контракт на изготовление 22 видов заказных микросхем для системы наведения ракет Minuteman II. К этой же задаче присоединились и другие компании, так что в 1965 г. ракетчики стали главными заказчиками ИС в США. Кстати, ещё в 1961 г. британская Ferranti Semiconductor стала производить одно из первых в Европе семейств цифровой логики для миниатюризации бортовых систем в британских ВМС. В этом же году Стивен Хофстайн из RCA сделал самую сложную на тот момент 16-транзисторную ИС — но лишь для лабораторных исследований.
В 1963 г. вышли первые ТТЛ-чипы (транзисторно-транзисторная логика, самая популярная до конца 70-х), но главное — Фрэнк Уанласс из Fairchild показал, что симметричное спаривание p- и n-канальных МОП-транзисторов уменьшает потребление энергии при простое (когда транзисторы не переключаются) в миллион раз, назвав этот вид логики «комплементарная (структура) МОП» (КМОП). Впервые изготовленная через 2 года, она сразу стала использоваться в авиации и космосе, но быстро добралась и до коммерческих устройств. Из-за использования медленных p-МОП-транзисторов на рекорды скорости поначалу такая логика не претендовала.
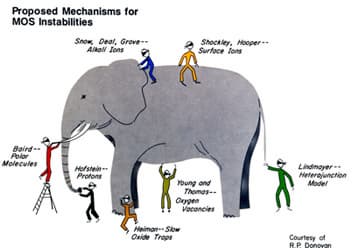 «Предполагаемые механизмы МОП-нестабильностей.» Вот ещё, оказывается, как делалась наука… |
 20-битный регистр сдвига производства General Microelectronics. |
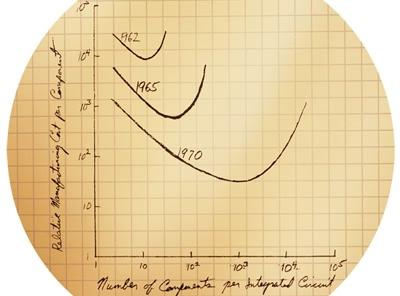 График из записной книжки Гордона Мура: зависимость относительной стоимости интегрального компонента от их числа на чипе в разные годы. |
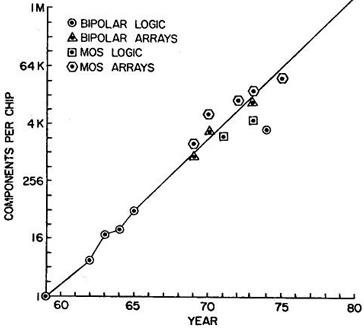 В 1975 г. Мур добавил к первоначальным отметкам новые (биполярные и полевые логика и память), убедившись, что рост числа компонентов сохраняется. |
 Эти чипы Мур использовал как доказательство геометрической прогрессии в микроэлектронике. |
 Кристалл 256-битной ТТЛ-памяти для процессора суперкомпьютера Illiac IV — двухмерная регулярность топологии очевидна. |
 Fairchild 3708 — первая коммерческая ИС с поликремниевыми затворами, 1968 г. |
Когда массовое производство ИС стало исчисляться уже миллионами, оказалось, что с применением пластин большего диаметра себестоимость чипов падает, а массовость растёт — и в 1964 г. введены 25 мм пластины, а через 2 года — на 38 мм. Однако уменьшать интегральные МОП-транзисторы оказалось труднее, чем биполярные, из-за производственных сложностей и падения надёжности. Причём эксперты чуть ли не соревновались по добавлению очередного аргумента в ряд «почему оно не будет работать» — так что это даже вылилось в пародию на известную индийскую притчу о слепцах, ощупывающих слона по частям, чтобы изучить его. В течение 1963–66 гг. специалисты из американских, европейских и японских компаний (в сотрудничестве и конкуренции) исследовали и решили бо́льшую часть вопросов надёжности МОП-схем.
В 1964 г. General Microelectronics выпустила первый коммерческий p-МОП-чип — 120-тразисторный 20-битный регистр сдвига. Через год сделаны ещё 23 заказных вида микросхем для первого настольного калькулятора на МОП-ИС (Victor Comptometer EC-3900), включая 600-тразисторный 100-битный регистр. К 1969 г. фирме Rockwell удалось сократить число калькуляторных чипов до 4, что позволило сделать портативные машины. В 1971 г. Mostek и TI представили однокристальные калькуляторные ИС (не считая внешнего контроллера экрана). До этого, в 1968 г. RCA показала чип статической памяти (СОЗУ) на 288 бит (почти 2000 транзисторов) и первое семейство простой КМОП-логики общего назначения. Таким образом, помимо военных заказов, во второй половине 60-х одним из локомотивов микроэлектроники стали простые настольные ЭВМ. Их было гораздо больше мэйнфреймов, хотя в последних ИС применялись тысячами.
Но главное — в течение 60-х гг. улучшения литографии позволяли увеличивать число транзисторов экспоненциальными темпами. Это заметил химик Гордон Мур, работавший тогда директором по НИОКР в Fairchild. В 1965 г. он написал внутренний доклад «Будущее интегральной электроники» с графиком, соединяющим 5 точек и связывающим число компонентов ИС и их минимальную цену для периода 1959–1964, и предсказанием развития на следующие 10 лет. Последнее основывалось на том, что число компонентов на чипе будет продолжать удваиваться каждый год. Чуть позже отредактированная версия появилась в виде статьи в журнале Electronics 19 апреля 1965 г.
Интересно, что в 1975 г. на ежегодной встрече Международной Организации Инженеров-Электронщиков (IEEE) Мур (уже как президент и исполнительный директор Intel) указал, что увеличение диаметра пластин, успехи в технологических процессах и “поумнение схем и устройств” позволило продолжиться прогнозу. Впрочем, Мур скорректировал свою закономерность до удвоения каждые 2 года, добавив в последние данные бо́льшую долю микропроцессоров как наиболее сложных логических (т. е. нерегулярных) схем. Предсказание оказалось самоподдерживающимся: теперь Гордон Мур уже не наносит на свой график очередные достижения, зато многочисленные фирмы (и, конечно, сама Intel) до сих пор стараются идти в ногу с прогрессией. Кстати, титул закона ей дал известный информатик Карвер Мид в 1980 г. Ещё раз публично проверяя своё предсказание в 1995 г., Мур сделал вывод, что оно “не скоро остановится”.
Поясним, почему делается разделение между регулярными и нерегулярными дизайнами (чаще всего под ними понимают память и процессоры, соответственно). Регулярный чип имеет в 5–10 раз бо́льшую плотность размещения транзисторов, чем в логических схемах, где относительно мало повторяющихся элементов. Однако прогресс последних более сложен и приносит больше пользы. Проще говоря, если вам мало памяти, то можно её набрать большим числом микросхем имеющегося объёма. А вот с недостатком производительности ЦП так просто не сделаешь.
В 1963 г. Роберт Нормэн из Fairchild запатентовал то, что позже получило название статического ОЗУ (СОЗУ). Через 2 года кооперация фирм Scientific Data Systems и Signetics изготовила первый 8-битный биполярный чип памяти. В 1966 г. команда Тома Лонго из Transitron сделала свою версию 16-битного ОЗУ для миниЭВМ Honeywell Model 4200, что стало первым применением интегральной полупроводниковой памяти в коммерческих компьютерах. 64-битные чипы появились в 1968 г. в IBM (для первого в мире кэша), Fairchild, Intel и TI. В 1969 г. IBM представила 128-битную схему уже для основного ОЗУ выпущенного через 2 года компьютера System/370 модели 145. В 1970 г. 256-битный чип Fairchild использован в машине Burroughs Illiac IV. Ну а суперкомпьютер Cray 1 в 1976 г. имел 65 536 килобитных ИС от Fairchild. Из этой прогрессии ясно, почему Муру поначалу казалось, что удвоение транзисторов будет ежегодным — для памяти это оказалось проще.
В 1968 г. сделан настолько важный прорыв, что за следующие 35 лет ничего подобного с транзистором не случалось: Роберт Кервин, Доналд Кляйн и Джон Сэрэс из Bell Labs сменили материал затвора с алюминия на поликремний (поликристаллическая форма кремния, сильно легированная проводящими примесями). Не смотря на то, что его сопротивление больше, чем у металла (и потому контакт к затвору по-прежнему металлический), осаждение и выборочное вытравливание кремния для затвора позволило использовать его в качестве маски для формирования истока и стока, идеально подогнанных к его краям, поэтому поликремневый затвор называется самосовмещённым (self-aligned). Это резко снижает разброс характеристик, вызванный неидеальным наложением масок при литографическом формировании истока и стока. Меньший разброс улучшает надёжность работы, а расположенные тесней части транзистора увеличивают скорость и плотность размещения самих транзисторов.
Некоторые микроэлектронные фабрики («фабы») до сих пор готовят чипы с почти тем же вариантом МОП-транзистора, что был изобретён в конце 60-х. В том же 1968 г. Федерико Фэггин и Том Кляйн из Fairchild переделали имеющуюся микросхему (8-канальный аналоговый мультиплексор) под новые транзисторы. Как часто бывает, не обошлось без обиженных: в 1965 г. Бойд Ваткинс представил почти такую же структуру на конференции General Microelectronics, но регистрация его патента почему-то задержалась до 1969 г.…
 «Вероломная восьмёрка», 1958 г. (через год после основания Fairchild). «Вероломная восьмёрка», 1958 г. (через год после основания Fairchild). |
Конец 60-х родил ещё две «революции», одна из которых вам наверняка нравится, а вторая — наверняка нет… :) Восьмёрка «молодых и дерзких» в 1968 г. ушла из Fairchild, и каждый основал свою компанию. В частности, Гордон Мур и Роберт Нойс основали Intel, а через год ещё 5 «fairchildren» («прекрасных детей», ещё одна кличка) основали AMD. Вообще, за 20 лет перебежчики из Fairchild зачали аж 65 разных компаний, но далеко не все оказались известными. После основания Intel сразу занялась производством — угадайте чего? Памяти — оказалось, что поликремниевый затвор ускоряет доступ в 3–5 раз и уполовинивает площадь по сравнению с обычным МОП-чипом той же ёмкости. Так что первой микросхемой Intel была i1101 — 256-битное ОЗУ (1969 г.).
1970-е
Это десятилетие ознаменовалось прежде всего взлётом микропроцессоров. Конечно, активно продвигалась и память — в частности, динамическое ОЗУ (ДОЗУ, DRAM) стало не только ёмче и надёжней, но и дешевле памяти на магнитных кольцах. Но именно в дизайне логических микросхем произошёл прорыв: за 10 лет процессоры из 4-битных стали 32-битными, и для многих применений этого хватает до сих пор. Рассматривать все «первые» мы не будем (уж больно тёмное дело), но о претендентах на самый-самый упомянем:
Кто первым начал?«Центральный обработчик (компьютер) аэроданных» (Central Air Data Computer, CADC) — интегрированная система управления полётом для первых версий истребителя F-14 Tomcat. Её МОП-ИС MP944 — первый в мире многокристальный процессор. Система конструировалась командой Стива Геллера и Рэя Холта из Garrett AiResearch с 1968 по 1970 гг. CADC состоит из 20-битного аналого-цифрового преобразователя, ЦП и ещё нескольких отдельных деталей. Процессор состоял из микросхем шести разных видов: параллельный умножитель, параллельный делитель, логика спецфункций, логика управления (до 3 штук), ОЗУ (до 3) и ПЗУ (до 19). Холт написал об этом ЦП в журнале Computer Design в 1971 г., но ВВС США засекретило статью аж до 1998 г. Фото чипов недоступны до сих пор…
В 1967 г. Ли Бойсел из Fairchild высказал идею, что весь компьютер может быть сделан на микросхемах. Компания наградила его должностью главы отдела разработки МОП-ИС, чтобы его идея стала явью. Но в 1968 г. Бойсел (с двумя коллегами) покинул Fairchild и основал фирму Four-Phase Systems. Их компьютер с первым в мире коммерческим однокристальным микропроцессором был показан в 1970 г. на конференции Fall Joint (сам ЦП был готов годом ранее). За год удалось продать 4 системы, ещё за два — 347. Постоянно наращивая продажи, компания в конце концов была куплена корпорацией Motorola за 253 млн. долларов в 1982 г. ЦП компьютера являлся 24-битным и состоял из трёх чипов AL1, обрабатывающих по 8 бит с учётом переноса, являясь таким образом ещё и первым наращиваемым или «бит-слайсовым» ЦП. Сам AL1 имел лишь АЛУ и 8 регистров, на что ушло, предположительно, более 4000 транзисторов. Впрочем, AL1 не называли микропроцессором и не продавали отдельно от «родного» компьютера. Однако когда в 1990 г. TI заявила, что именно она запатентовала 1-кристальный ЦП, Ли Бойсел собрал плату с одним AL1 (а не тремя) и принёс её прямо в зал суда для демонстрации работы.
Всемирно известный Intel i4004 являлся первым 1-кристальным коммерчески доступным ЦП, продававшимся в т. ч. отдельно (в отличие от AL1), хотя разработан был для конкретной модели калькулятора. Дизайнеры чипа — Федерико Фэггин и Тед Хофф из Intel и Масатоши Шима из Busicom. Этот 4-битный ЦП не умел наращивать разрядность, зато обошёлся всего в 2300 транзисторов. Тем не менее, Фэггину пришлось применить разнообразные ухищрения, чтобы уместить чип в размерах, приемлемых для рентабельного производства и узкого 16-выводного корпуса. |


Пока десяток фирм упражнялись в попытках уместить на микросхеме всё большее, IBM ещё с 1970 г. пыталась решить не менее важную проблему — уменьшение удельной цены чипов памяти (на каждый бит), чтобы они вытеснили магнитную память. Первая микросхема динамического ОЗУ Intel i1102 в 1970 г. стоила 21 доллар (позже подешевев вдвое), а ёмкость имела всего 1 килобит. Группа Дэйла Критчлоу в IBM пыталась достичь цены в 1 миллицент/бит. Для этого другой группе под руководством Боба Деннара (изобретателя самой компактной и до сих пор применяемой во всех чипах ДОЗУ 1-транзисторной ячейки) поручили сделать исследование, из которого оказалось, что самый верный способ — уменьшить площадь ячейки уменьшением не числа транзисторов, как было до сих пор (ДОЗУ начинались с 3 транзисторов/бит), а самих транзисторов. Ведь ещё в 1962 г. Томас Стэнли из RCA опубликовал аналитический доклад о том, что уменьшение особенно благотворно для МОП-структур, т. к. затвор, длина которого ограничивает скорость, лежит вдоль прибора, а не поперёк.
На тот момент самый передовой техпроцесс имел технорму 5 мк. Критчлоу и Деннар пропорционально уменьшили все части транзисторов в 5 раз, обнаружив почти линейную зависимость основных параметров — скорости и потребления (помимо очевидного уменьшения площади). Результаты этих опытов были представлены на IEDM (International Electron Devices Meeting — международная встреча [разработчиков] электронных устройств, крупнейшая ежегодная конференция электронщиков) в 1972 г.; в этом же году похожую работу опубликовали Карвэр Мид и Брюс Хёнейсен из Калифорнийского Института Технологий.
В течение ещё двух лет были проведены дополнительные исследования, и в 1974 г. родилась ставшая классикой работа “Устройство ионно-имплантированных МОП-транзисторов очень малых физических размеров”. Хотя тогда это ещё не все поняли, но предложенная теория масштабирования (по сути — научное подтверждение до тех пор эмпирической закономерности Мура) поставила окончательный крест на биполярных транзисторах, всё ещё применявшихся в самых быстрых логических чипах типа ЭСЛ (эмиттерно-связанная логика) — так что в 80-е уже и суперкомпьютеры перешли на МОП-ИС. А всё потому, что биполярные транзисторы не масштабируют свои параметры также хорошо как полевые с уменьшением своих размеров.
Но чтобы всемирная борьба за микроны (а позже — и нанометры) началась, не хватало ещё одного: надо соответственно улучшить и параметры производящего оборудования. Ведь до тех пор все микросхемы делались контактным способом, когда маска буквально впечатывались в пластину и только после этого облучалась. Это порождало большое число осколков и пыли, выбиваемых с поверхности и загрязнявших пластину. Но в 1973 г. фирма Perkin Elmer представила проекционный принтер — первый пример массовой фотолитографии. Применяя его с положительным фоторезистом (фоточувствительным материалом, растворимым после освещения), удалось добиться революционного прорыва в выходе годных (доля рабочих чипов среди изготовленных — важная характеристика реализации техпроцесса на конкретном фабе): плотность дефектов на единицу площади резко уменьшилась, т. к. физического контакта маски с пластиной больше нет. Сама маска теперь — кварцевая пластина с хромовым слоем, содержащим нужный рисунок.
Дополнительно к этому фабрики не забывали ещё одну гонку — по уменьшению себестоимости пластины, что достигалось увеличением их массовости и диаметра. Последний вторую половину 60-х был на уровне 38 мм, но в 1970 г. внедрены пластины на 57 мм, в 1973 — на 76, в 1975 — на 100, а в 1979 — на 125 мм. Т. е. за 10 лет площадь пластин увеличилась в 5–7 раз, что сказалось и на числе производимых микросхем (как всё это время росла средняя площадь самих чипов, покажем чуть позже). Таким образом, у мировой микроэлектронной промышленности появилась возможность следовать закону Мура не в ущерб себе, а как раз наоборот — с коммерческой выгодой.
Из других достижений 70-х:
- появление программируемых пользователем ПЗУ: сначала однократных (1970 г.), потом стираемых ультрафиолетом (1971, придумал Дов Фроман из Intel);
- первые цифровые сигнальные процессоры: сначала — как сопроцессоры для ЦП (1978, хотя идея предложена в 1972), а затем и самостоятельные, с собственным ПЗУ и ОЗУ (1979);
- первые микроконтроллеры (TI TMS1000 в 1974 г. и Intel i8048 в 1975 г.), т. е. 1-кристальные компьютеры, которые в ещё более интегрированной форме ныне зовутся системами-на-чипе (SoC);
- первый фотолитографический степпер (1978) — этот аппарат экспонирует пластину по частям, что позволило далее расти её диаметру и увеличивать детализацию масок без побочных краевых эффектов.
1980-е
Наверное, одно из самых больших событий в мировой микроэлектронике произошло в 1980 г., когда IBM, рассматривая ЦП Motorola и Intel, выбрала i8088 для выходящего через год IBM PC. Возможно, конкурент — 32-битный MC68000 — был слишком дорог (имея около 70 000 транзисторов против 29 300) или не был приспособлен для относительно дешёвых систем (имея 16-битную шину данных). Intel же к тому времени переделала 16-битный i8086 для 8-битных чипсетов в виде i8088. В 1982 г. Motorola также выпустила урезанную версию с 8-битной шиной (MC68008), но было уже поздно. Неясно, как бы развивалась микроэлекторника, если бы IBM не стала экономить и выбрала куда более прогрессивную архитектуру MC68000. Тем более, что Apple в 1984 г. выбрала её же для своих первых Макинтошей. Возможно, Intel по прежнему бы выпускала микросхемы памяти и простые 8-битные контроллеры. Особенно после провала своего первого (и заранее широко разрекламированного) 32-битного ЦП iAPX432, который должен был заменить архитектуру x86.
Однако ажиотажный успех первых PC (неожиданный даже для само́й IBM, где к проекту относились с сомнением и считали его экспериментальным) поставил всё на свои места: в Intel поняли, что миру будет нужно много «персональных процессоров», причём с регулярной сменой поколений. Непрофильные микросхемы постепенно отходили в сторону, уступая место процессорам x86. Интересно, что ещё до успеха PC Intel успела продать несколько лицензий на производство аналогов i8086 другим компаниям; AMD свою получила уже в 1982 г., по распространённому заблуждению — из-за политики IBM иметь нескольких поставщиков каждого важного компонента, чему Intel якобы вынужденно подчинилась. Так или иначе, потребовалось быстро обойти собственноручно созданных конкурентов, для чего выбрали улучшение не только микроархитектур ЦП, но и технологических процессов для их выпуска. Для Intel это не менее важно до сих пор, хотя большинство компаний (включая главного конкурента) давно перешли на модель «fabless + foundry», т. е. бесфабричного разработчика и контрактного завода-производителя.
Вроде бы, всё это должно было дать новый поток принципиальных достижений, продвигающих интегральную технику. Однако за следующие 10 лет таковых оказалось гораздо меньше, чем даже за 70-е, хотя количественный прогресс, диктуемый законом Мура, продолжался. Возможно, уже открытого хватало, чтобы двигаться вперёд с обновлениями, прежде всего, технормы и числа слоёв межсоединений. Помимо этого, промышленность не забывала наращивать и диаметр пластин: в 1981 г. — 150 мм, в 1985 — 200 (до сих пор используемые на не самых крутых фабах) и в 1996 — 300. Переход на пластины 450 мм сильно затянулся из-за чрезвычайной дороговизны оборудования, покупку которого до 2020 г. смогут потянуть лишь 5-6 компаний в мире.
Наши дни
1990-е
 Современный литографический сканер ASML TwinScan 1950i. Луч лазера, пройдя через многочисленные линзы и движущуюся взад-вперёд маску (её каретка видна справа от надписи TwinScan) попадает на каретку с экспонируемой пластиной, которая также движется, но уже в двух координатах, подставляя под луч новую порцию поверхности. Вторая каретка со следующей «вафлей» в этот момент проходит подготовительную стадию, в которой различные оптические датчики изучают малейшие неровности этой конкретной пластины, чтобы далее оптимизировать её экспонирование — двухстадийный конвейер. Слева от рабочей зоны видны входной и выходной порты для контейнеров с пластинами по 25 штук в каждом, а сверху (между надписью и кареткой маски) — банк масок, подставляющий нужную для данной экспозиции и имеющий собственный небольшой порт. «Светофор» — это индикатор состояния, встроенный почти в каждую установку в «чистой комнате» фаба. В движении всё это можно посмотреть тут. |
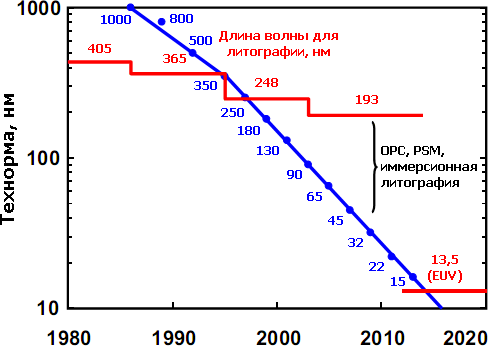
До 90-х гг. фотолитография использовала ртутные газоразрядные лампы, отсекая из их света всё, кроме нужной частоты, совпадающей с одним из пиков («линий») — G (436 нм), H (405) или I (365). После того, как мощности ламп стало не хватать для требуемой производительности, потребовалось внедрить эксимерный лазер, что сделали в 1982 г. в IBM (сам такой лазер изобретён в СССР в 1971 г.). В зависимости от газа он даёт длину волны 248 (KrF), 193 (ArF) и 157 нм (F2). От фторовых лазеров, правда, отказались из-за чрезвычайных технических проблем, решение которых не окупится преимуществами — дело в том, что сам воздух начинает поглощать излучение с длиной волны меньше 186 нм, так что весь литограф надо переделать под вакуум. Это его усложняет и удорожает с 40 до 50 млн. долларов, а сканеров фабу требуется несколько. Поэтому даже самые современные техпроцессы с технормами менее 30 нм всё ещё используют аргон-фторовый лазер. При этом переход на так называемый экстремальный ультрафиолет (ЭУФ, EUV) с длинами волн 13,5 нм и менее рано или поздно всё равно состоится — и без вакуума тут точно не обойтись.
Тут надо сказать, почему формирование рисунка на поверхности приобретает большие сложности, когда его размер оказывается меньше длины волны экспонирующего света. Строго говоря, законы волновой оптики не запрещают формирование деталей с таким разрешением. Но начиная с этих размеров линейная оптика заменяется на куда более сложную дифракционную, требующую большую точность при всех операциях — с соответствующим влиянием на цены установок. С точки зрения теории стоит познакомиться с эмпирическим критерием разрешения Рэлея (о минимальном угловом расстоянии между точками), числовой апертурой (NA) и технологическим параметром k1. Тут укажем лишь, что этот k1 в идеале может опускаться до 0,25, но насколько конкретная установка и техпроцесс приближены к идеалу — зависит от их продвинутости.
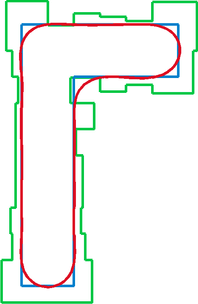 OPC: требуется вычислить такую маску (зелёный контур), чтобы получаемый ею символ (красный) оказался как можно ближе к требуемому (синий). Без коррекции толщина линий символа окажется больше или меньше в разных частях, в т. ч. за счёт влияния соседних линий. Это может привести как к разрыву дорожки, так и к замыканию пары дорожек. |
Одна из таких продвинутых методик — вычислительная литография: использование масок, рисунок которых вычислен с учётом волновых свойств света с целью добиться большего разрешения или меньших искажений при данной длине волны. Первые подобные программы были написаны в начале 80-х и использовались лишь для оптимизации рисунка маски, т. к. недостаток вычислительной мощности позволял моделировать площадь всего в несколько квадратных микрон. К 1998 г., когда замаячил переход на 180 нм (первый техпроцесс с технормой меньше длины волны), мощность компьютеров уже сильно возросла, что позволило использовать более точные алгоритмы и модели. Для современных технорм требуются уже тысячи процессоров и недели расчётов, чтобы вычислить рисунки для десятков масок, необходимых самых сложным ИС.
К основным методам вычислительной литографии относятся фазосдвигающие маски (PSM) и оптическая коррекция близости (OPC). Используемая с 90-нанометрового процесса (2006 г.) технология PSM — это коррекция толщины отдельных «пикселей» маски для изменения их прозрачности, что меняет фазу проходящего сквозь них света. Учитывая волновые свойства, это позволит (не считаясь с длиной волны) экспонировать на фоторезисте рисунок, отдельные элементы которого либо усилены синфазным наложением волновых пиков, либо удалены противофазным — это увеличивает разрешение, приближая тот самый параметр k1 к идеалу. Более современная OPC искажает рисунок маски для компенсации ошибок получаемого изображения из-за дифракции падающих волн. OPC нужна уже не для увеличения разрешения, а для исправления искажений одиночных структур, форма которых при таких размерах получается куда хуже, чем если бы элементы были регулярными.
Микроэлектронщики давно хотели использовать медные межсоединения вместо алюминиевых, т. к. удельное сопротивление меди меньше. Это значит, что «медные» чипы меньше выделяют тепла и быстрее работают, т. к. меньшая часть коммутируемого транзисторами тока уйдёт в нагрев, а не в переключение других транзисторов. Однако если в линиях электропередач и прочих проводах медь применяется давно, то микроэлектроника не могла внедрить столь полезный металл десятки лет. Причина в том, что после осаждения меди при дальнейших процессах нагрева она диффундирует (внедряется) в подлежащие элементы, особенно в кремний, что даже получило термин «медное отравление».
В 1997 г. IBM наконец-то решила задачу. Сначала медь надо осадить. Но из-за её химической стойкости её нельзя протравить плазмой сквозь окна в фоторезисте (не удалив при этом оставшуюся, т. е. маскирующую часть самого резиста), как это делается для алюминия. Вместо это применяется «дамасская работа» (damascene): процесс, похожий на изготовление булатной стали с мелким орнаментом. Сначала в изоляторе протравливаются канавки для дорожек. Далее вся поверхность выстилается барьерным металлом (который чаще всего оказывается нитридом титана или вольфрама, что, строго говоря, относится к керамике), не допускающим диффузии, но пропускающим ток. Его толщина должна быть небольшой, т. к. его сопротивление всё же больше, чем даже у алюминия.
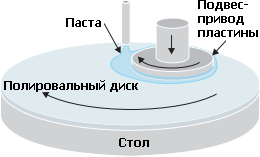 Химико-механическая планаризация: вращающийся подвес прижимает пластину лицевой стороной к вращающемуся диску с наносимой на него пастой. Специальный диск-восстановитель (не показан) выравнивает пасту. Восстановитель и подвес также могут двигаться вдоль радиуса. |
Далее на всю поверхность осаждают толстый слой меди, переполняющий канавки. Т. к. плазмохимическое травление (оно же — реактивное ионное травление, RIE) не подходит, используется химико-механическая планаризация (ХМП или CMP). До 90-х гг. она считалась слишком грязной и дефектной для тонкого производства, т. к. абразивные частицы полировальной пасты создавали острые осколки стираемого слоя, да и сама паста неидеально чистая. Но для медного слоя ХМП оказалась лучше имеющихся способов, т. к. процесс полировки металла останавливается на границе с изолятором (точнее, с его невытравленными частями, находящимися выше дна канавок). В результате на чипе остаётся очень плоский слой с внедрёнными медными дорожками, не выходящими по высоте из окружающего изолятора. Более того, так называемое двойное воронение позволяет одновременно получить ещё и вертикальные проводящие окна, соединяющие текущий слой с предыдущим. Сверху всё покрывается ещё одним барьерным слоем, излишки которого вытравливаются над внутрислойным изолятором, но не над дорожками. После этого можно осаждать уже межслойный изолятор для следующего проводящего слоя.
 КНИ в чипе IBM (для наглядности пространство между проводниками вытравлено). Снизу вверх: подложка, оксид-изолятор, тонкий слой кремния, транзисторы и один слой металлических межсоединений с опущенными до транзисторных выводов металлизированными окнами. |
Ещё одно достижение изначально было связано с радиационно-стойкой электроникой, необходимой в авиакосмических и атомных отраслях. При уменьшении размера транзистора он оказывается всё более чувствителен к высокоэнергетическим частицам, способным вызвать ошибку в схеме. Чтобы усилить защиту, в 1963 г. придумали применять не кремниевую, а сапфировую пластину, на которую осаждён тонкий слой кремния — КНС (кремний на сапфире) или SOS. Оказалось, то такая конструкция сильно уменьшает подзатворные утечки, а значит — и потребление энергии, а также снижает паразитную ёмкость, что повышает частоту. Однако выращивание сверхчистой сапфировой болванки оказывается куда дороже выращивания кремниевой, поэтому «в массах» такой вариант не прижился.
Но в 1998 г. IBM анонсировала технологию кремния на изоляторе (КНИ, silicon on insulator, SOI): на кремниевой пластине формируется слой оксида кремния (изолятора), а поверх него — тонкий рабочий слой кремния. Строго говоря, КНС тоже относится к КНИ, т. к. сапфир (оксид алюминия Al2O3) также является изолятором. Но кремниевый КНС дешевле и лучше приспособлен к имеющемуся оборудованию. Учитывая преимущества, можно предположить, что за 13 лет вся полупроводниковая промышленность давно перешла на КНИ-пластины. Однако мировой лидер этой самой промышленности, компания Intel, будто в упор их не замечает и продолжает использовать «bulk silicon», т. е. чистые кремниевые пластины, т. к. они ещё дешевле. К этому заявлению мы ещё вернёмся…
2000-е
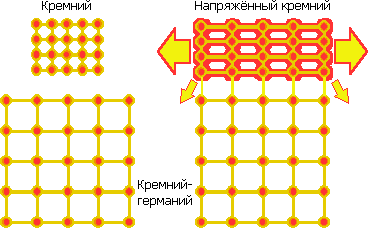 Кремний до и после осаждения на кремний-германиевый слой. |
В 2001 г. IBM изобретает напряжённый кремний (strained silicon) — формирование слоя кремния для канала, в котором расстояние между атомами (как минимум в направлении исток-сток) не равно естественному шагу кристаллической решётки (543 пм). Для большего шага сначала внедряется «посевной» слой кремния-германия. Кристалл германия имеет шаг атомов 566 пм. Смешанный полупроводник сохраняет это значение, даже если доля германия всего 17% (это для 90 нм; а для 32 нм — уже 40%). Осаждаемые поверх атомы кремния межатомными силами крепятся к атомам широкой решётки и остаются с её шагом, формируя канал. Разряжение атомов увеличивает подвижность электронов, что ускоряет n-канальный транзистор на 20–30%. Кстати, именно из-за большей подвижности электронов германий первым стали применять в электронике.
В 2004 г. эту технологию применили Intel и AMD для техпроцесса 90 нм. Для 65 нм внедрена ионная имплантация германия и углерода в исток и сток. Германий раздувает концы транзистора, сжимая его канал, что увеличивает скорость дырок (т. е. основных носителей заряда в p-канальных транзисторах). Углерод, наоборот, сжимает исток и сток, что растягивает n-канал, увеличивая подвижность электронов. Также весь p-канальный транзистор покрывается сжимающим слоем нитрида кремния. Применяются и растягивающие покрытия.
| Структурирование распорками (сверху вниз): формирование первичного шаблона фоторезистом (оранжевый), осаждение химической маски (зелёная), формирование распорок направленным (вертикальным) травлением, удаление резиста, травление рабочего слоя (синий), удаление распорок. |
В 2006 г. только что внедрённый техпроцесс 65 нм уже не мог основываться лишь на вычислительной литографии, т. к. с длиной волны 193 нм её уже не хватало. Решение, основательно обновившее мировое чипостроение — множественное структурирование, более известное по своей простейшей реализации — двойное структурирование (double patterning). Это семейство технологий снижает минимальный экспонируемый размер увеличением числа экспонирований. Как правило, в самых современных техпроцессах применяются несколько приёмов из этого арсенала.
Самосовмещёные распорки (self-aligned spacers) позволяют получить вдвое большее разрешение формируемого рисунка при той же технорме: вначале на боковые стенки фоторезиста налипает специальная химическая маска, используемая далее как финальный шаблон травления после удаления резиста. Разумеется, этот приём можно повторять и далее, используя вторичный шаблон для изготовления третичного с ещё вдвое большим разрешением — насколько это позволит химическая устойчивость материалов и повторяемость процессов.
Второй случай, требующий применения нового резиста, — двойное (кратное) экспонирование (double (multiple) exposure): вторая маска экспонируется на тот же резист со смещением относительно первой на величину технормы, причём пластина даже не покидает литограф. Чтобы второй рисунок добавился к первому (а не частично наложился на него), требуется, чтобы оба раза формировались детали шириной меньше технормы. Таким образом, например, формируются линии металла и поликремния — сначала все «вдоль», потом все «поперёк». Замена двухмерного рисунка двумя одномерными упрощает его нанесение.
Ещё один вариант двойного экспонирования (применяется начиная с 32 нм) использует два разных вида резиста. Второй наносится на рисунок, сформированный в первом, облучается через вторую маску, после чего удаляется незафиксированная часть второго резиста, но так, чтобы не повредить рисунок первого. И тут нужна продвинутая химия — новые резисты, боковое травление для уменьшения ширины и пр. Зато, теоретически, такая методика позволяют формировать сколь угодно мелкие детали. Например, 22-нанометровые элементы могут получаться перемежением двух масок на 45-нанометровом литографе, трёх масок на 65- или четырёх на 90-нанометровом. Т. е. текущий техпроцесс можно «разогнать» до следующего за счёт увеличения числа масок и производственных стадий — с очевидным удорожанием стоимости завода и внедрения производства новых микросхем. Но с недавних пор это всё равно оказывается дешевле «честного» уменьшения технормы через литографию.
Очевидными недостатками кратного экспонирования является кратное увеличение числа масок и технологических операций для формирования каждого критического слоя, а также очень высокие требования по точности совмещения масок. Небольшое смещение между двумя экспозициями слоя может привести, например, к асимметрии истока и стока (относительно затвора) у всех транзисторов пластины.
В 2006 г. появилось ещё одно улучшение — погружённая литография. Впрочем, в крайне неустойчивой и неполной русскоязычной терминологии по странной традиции прижилась транслитерированная форма оригинала — иммерсионная литография. Суть оной в том, что пространство между последней линзой и экспонируемой пластиной заполняется не воздухом, а жидкостью (на данный момент — водой). Это улучшает разрешение на 30–40% ввиду большего преломления жидкости, которое влияет на вышеуказанный параметр NA, равный 1 для воздуха и 1,33 для воды. Intel внедрила иммерсионную литографию вместо «сухой» с техпроцесса 32 нм, а AMD — ещё с 45 нм. Интересно, что первые «водные» сканеры появились ещё в 2005 г., но техпроцессы с ними пришлось дорабатывать около года после внедрения на фабах до применения в массовом производстве. И вот почему:
Мало того, что вода должна быть сверхчистая (она и так требуется почти в половине технических процессов производства ИС) — в ней не должно быть пузырьков, температура должна быть равномерной, она не должна сверх меры загрязняться и поглощаться фоторезистом или растворять его. Более того, 193-нанометровый ультрафиолет ионизирует воду — а выбитые электроны могут испортить фоторезист. Решить все эти вопросы удалось нанесением прозрачного гидрофобного защитного покрытия на фоторезист перед экспонированием. Таким образом плотность дефектов осталась примерно та же.
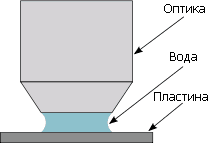 Иммерсионная литография. |
Не менее важная часть — производительность, ведь мало изготавливать чипы сложными и дешёвыми, их нужно много. Скорость пластины в литографическом сканере достигает 0,5 м/с, но держать её всю под слоем воды не выйдет — сверхточное позиционирование каретки с пластиной полагается на лазерные интерферометры, и малейшая рябь на поверхности воды всё испортит. Поэтому слой «привязали» к оптике. Чтобы пластина не уносила воду в сторону, вокруг оптики разместили водяные микросопла, половина из которых по ходу движения впрыскивают воду, а противоположные им — высасывают. Всё это происходит с очень точным контролем, чтобы не внести пузыри при впрыске и не оставить позади капли после отсоса, что особенно трудно с краю пластины. Теперь ясно, почему иммерсионный сканер гораздо дороже сухого.
В 2007 г. (для техпроцесса 45 нм) в микроэлектронике появилось сокращение HKMG — High-k [dielectric and] Metal Gate, т. е. изолятор с высокой диэлектрической проницаемостью и металлический затвор. Сначала о первой половине формулы. Параметр k означает относительную диэлектрическую проницаемость (безразмерную величину, разную для разных веществ), однако в английском языке (и, к сожалению, в большинстве русских переводов) её почему-то называют диэлектрической константой. (Не говоря уже о том, что вместо «k» должна быть греческая буква каппа — κ…) Настоящая же диэлектрическая константа (она же — электрическая постоянная, ε0), как и полагается, неизменна. В микроэлектронике «нормальным k» считается 3,9, что соответствует проницаемости диоксида кремния (SiO2), десятилетия использовавшегося в качестве боковых, межслойных и подзатворых изоляторов. Вещества с проницаемостью выше 3,9 относятся к классу high-k (высокопроницаемые), а ниже — к low-k (низкопроницаемые).
Последние нужны для межслойных и боковых диэлектриков, т. к. таким образом можно лучше изолировать металлические дорожки межсоединений, избегая диэлектрического пробоя из-за слишком тонкого слоя изоляции между ними. Сама же изоляция должна быть тонкой, т. к. иначе невозможно подвести дорожки к всё время уменьшающимся транзисторам, кроме как сделав такими же малыми и проводники, и разделяющие их изоляторы. К низкопроницаемым материалам относятся диоксид кремния-углерода (органосиликатное стекло с k=3 — самый популярный диэлектрик, используемый с 90 нм), он же, но пористый (k=2,7), нанокластерный кварц (2,25) и некоторые органические полимеры (k<2,2). По идее, изолятор, разделяющий затвор и канал транзистора, должен подчиняться этим же требованиям, но на деле оказывается всё наоборот — тут нужен как раз высокопроницаемый диэлектрик.
Всё дело в эффекте квантового туннелирования. К 90-нанометровому техпроцессу толщина затвора уменьшилась до величины от 1,2 (у Intel) до 1,9 нм (у Fujitsu; обе цифры — для n-каналов). А шаг кристаллической решётки кремния, напомним, равен 0,543 нм. При такой тонкости электроны начинают туннелировать сквозь изолятор, приводя к утечке тока. Дело обстояло настолько серьёзно, что для техпроцесса 65 нм уменьшились все параметры транзистора, кроме толщины затвора, т. к. если бы его сделали ещё тоньше, то ни о какой энергоэффективности не стоило бы и мечтать.
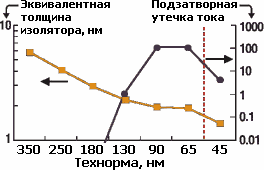 Графики толщины подзатворного изолятора в SiO2-эквиваленте и относительной утечки тока. Введение высокопроницаемых изоляторов для техпроцесса 45 нм позволило уменьшить эквивалентную толщину, увеличив физическую, чтобы уменьшить утечки для увеличения скорости. |
Высокопроницаемый диэлектрик позволяет электрическому полю затвора проникать на большую глубину или толщину, не снижая остальные электрические характеристики, влияющие на скорость переключения транзистора. Так что, заменив применявшийся с 90-х гг. оксинитрид кремния на новый оксинитрид кремния-гафния (HfSiON, k=20–40) толщиной в 3 нм, для процесса 45 нм удалось уменьшить утечки тока в 20–1000 раз. Для получения такой же скорости работы старый затвор пришлось бы делать толщиной в 1 нм, что было бы катастрофой. Встречающиеся сегодня цифры толщин подзатворных изоляторов менее чем в 1 нм являются как раз такими SiO2-эквивалентами и применяются только для вычисления частоты, но не утечки. Диоксид кремния, впрочем, до сих пор имеется в виде нижнего подзатворного слоя, но используется только как физический интерфейс для совместимости с текущими техпроцессами.
Любопытно, что при анонсе нового материала Intel поблагодарила старого микроэлектронного соперника — IBM. Но не потому, что инженеры «синего гиганта» разработали для коллег с не менее синим логотипом новый материал — а потому, что детальное математическое моделирование, доказавшее, что именно гафний является оптимальным материалом, провели на суперкомпьютере IBM. Учитывать пришлось не только проницаемость, но и ширину запрещённой зоны (она должна быть согласована с кремнием), морфологию слоя, термостабильность, ненарушение высокой подвижности носителей заряда в канале и минимальность краевых дефектов.
Впрочем, одного недостатка избежать не удалось: гафниевый изолятор не совместим с поликремниевым затвором, так что пришлось менять и его — на металлический. Теперь ясно, почему эти две технологии идут парой. Однако новый затвор не алюминиевый, как это было в 60-х, а в виде сплава двух металлов. Его сопротивление ниже, что ускоряет переключение транзистора. Изначально было известно лишь то, что сплав отличается для p- и n-канальных транзисторов, причём Intel (которая первой всё это применила) держит оба состава в строгом секрете. Однако через год (в 2008-м) инженеры IBM (работа которых с тех пор используется в т. ч. на заводах GlobalFoundries, ранее принадлежавших AMD) сделали свою версию этой технологии, так что деталями пришлось делиться и Intel.
До сих пор использованию металлов мешал тот факт, что после имплантации примесей пластина проходит отжиг при температуре 900–1000 °C, что выше температуры плавления многих металлов (включая алюминий) и сплавов, но не поликремния. Хотя даже и без плавления при повышении температуры металл может диффундировать в подлежащие слои. Теперь ясно, почему точная формула сплавов держится в секрете — их действительно трудно подобрать. Не зря лично Гордон Мур назвал HKMG наибольшим достижением с момента изобретения поликремниевого затвора в 1969 г. До этого момента алюминиевые затворы никому не мешали, т. к. не было ни высокотемпературного отжига, ни формирования истоков и стоков впритык к затворам. Сегодня же приходится применять всё более экзотические материалы — например, Panasonic легирует сплав для n-каналов своих HKMG-транзисторов редкоземельным элементом лантаном.
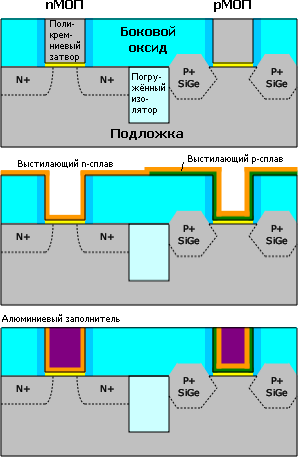 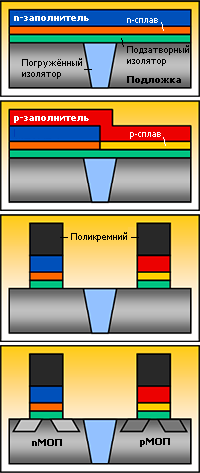 Варианты реализации металлического затвора — последним (слева, Intel) или первым (справа, общий случай). Стадии травления и полировки не показаны; также не указан барьерный слой между подзатворным изолятором и самим затвором (у Intel — TiN и TiAlN для p- и n-каналов, у GF — AlO). Версия IBM и GF для всех транзисторов использует одинаковые заполнитель (NiPtSi) и даже рабочий «металл» (TiN) — но для n-каналов они легируется мышьяком. |
Не меньше вопросов возникает при обсуждении двух версий технологии. Intel сначала формирует обычный поликремниевый затвор, работающий лишь как маска для создания истока и стока, затем вытравливает его, осаждает сплав для p-каналов, удаляет его из n-транзисторов, осаждает сплав для n-каналов и добавляет ко всем затворам алюминиевый заполнитель — этот вариант называется Gate last, «затвор последним». IBM и GF используют Gate first, «затвор первым»: на подзатворный изолятор осаждается p-сплав, удаляется над n-каналами, осаждается n-сплав, удаляется над p-каналами, осаждается поликремний в качестве заполнителя и маски — а далее как обычно.
Intel утверждает, что её версия лучше совместима с напряжённым кремнием (потому что ему не мешает металл затвора) и позволяет использовать большее разнообразие металлов (потому что они осаждаются после высокотемпературных обработок), тогда как у конкурентов сложнее получить разные виды транзисторов (по нагрузке, скорости, напряжению и пр.), и они всё равно окажутся чуть медленнее и с меньшим выходом годных. IBM и GF отвечают, что их способ дешевле и требует меньших ограничений на расположение транзисторов, что позволяет разместить их на 10–20% плотней, а в Intel приходится мириться с жёсткими ограничениями на размеры и расположение. Причём Intel тут в меньшинстве, потому что «затвор первым» формируют и в Chartered, Freescale, Infineon и Samsung. Последняя, правда, недавно заявила, что для её 20-нанометрового процесса затвор всё же будет «последним».
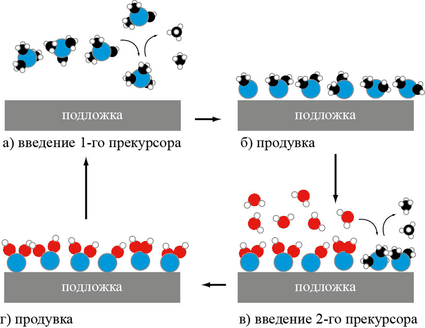 4 стадии цикла молекулярного наслаивания AlO2. Алюминий (синие атомы) поставляет 1-й прекурсор, валентные связи которого заняты лигандами (временными радикалами, в данном случае метильными группами —CH3). 1-я продувка удаляет метан (CH4) и избыток прекурсора. Вторым прекурсором является вода, замещающая остальные два лиганда у каждого атома Al. 2-я продувка удаляет лишнюю воду и метан. В следующем цикле атомы водорода 1-го слоя будут замещены связью с Al 2-го слоя, восстановив свободные метильные группы до метана. |
Формирование широко применяемых в современных чипах тонких плёнок было бы невозможно без технологии молекулярного наслаивания, она же — послойное атомное осаждение (Atomic Layer Deposition, ALD). Её суть заключается в том, что за один цикл обработки, длящийся всего несколько секунд, образуется ровно один слой молекул, так что толщину откладываемой плёнки можно регулировать с максимальной возможной точностью (для самых простых веществ — ±10 пм) лишь числом циклов. Каждый цикл состоит из двух стадий осаждения из газовой фазы прекурсоров (химических предшественников осаждаемого вещества) и двух продувок для удаления излишков. Прекурсоры подбираются так, чтобы лишь один их слой мог прилипнуть к уже осаждённому материалу — к подложке для 1-го осаждения, к предыдущему слою для нечётных осаждений (после 1-го) или к первому прекурсору для чётных. Способ подходит не только для составных веществ, но и для некоторых чистых металлов.
Молекулярное наслаивание впервые опробовано в начале 60-х профессором Станиславом Кольцовым из Ленинградского Технологического Института имени Ленсовета (ныне — СПбГТИ), а сама идея предложена профессором Валентином Алесковским в 1952 г. в его докторской диссертации «Остовная гипотеза и опыт синтеза катализаторов». Во всём остальном мире наслаивание появилось лишь в 1977 г. под именем «Atomic Layer Epitaxy» (ALE). Однако до микроэлектронного применения дело дошло лишь в середине 90-х — до этого очень тонкие плёнки были не нужны. Сейчас же, когда отдельные части транзистора исчисляются единичными атомными слоями, без ALD не обойтись. Тем страннее то, что в русской части Википедии об этой технологии и её создателях не написано вообще ничего, да и в остальном рунете — с гулькин нос…
Расскажем и о двух любопытных техниках, применяемых лишь некоторыми компаниями. Впрочем, первая известна с начала 2000-х и в какой-либо форме применяется во всех современных сканерах — структурный свет (structured light), меняющий форму луча лазера. Его сечение при этом оказывается не круглым, а кольцевым, 4-полюсным или каким-то ещё. Однако в 2009 г. Toshiba и NEC использовали в своём 32-нанометровом процессе новый вид такого освещения (возможно, в комплексе с доводкой методов OPC под него), что позволило обойтись без дорогостоящего двойного структурирования (которое у этих фирм вызвало 25-процентное увеличение дефектности). Обычно на таких размерах одно экспонирование единственной маски на слой приводит к сильным искажениям прямых дорожек (не смотря на OPC). Но структурный свет решает эту проблему и даже позволяет уменьшить шаг между элементами. Поэтому у Toshiba и NEC получилась самая маленькая (среди 32-нанометровых процессов всех фирм) ячейка СОЗУ — на 0,124 мк² (позже мы сравним эти цифры детальней), а плотность транзисторов в логике — 3,65 млн. вентилей/мм². И всё это по вдвое меньшей удельной цене, чем для своих же 45 нм, и на 9% дешевле, чем с применением двойного структурирования. Учись, Intel :)
 «Воздушные» (т. е. вакуумные) зазоры между проводниками 5-го и 7-го металлических слоёв. |
В том же 2009 г. IBM реализовала в массовом производстве технологию воздушных зазоров (Airgap) в качестве внутрислойных изоляторов, разделяющих медные проводники одного слоя. Состоит такой диэлектрик из тонкостенных пузырей размером в 20 нм, стенки которых собираются из полимера методом самосборки. Пузыри содержат, вопреки названию, не воздух, а вакуум — идеальный изолятор с проницаемостью, равной 1 (впрочем, у воздуха почти столько же). По заявлению IBM, с уменьшением межпроводной ёмкости чип потребляет на 35% меньше энергии или работает на 15% быстрее. Впрочем, почувствовать это могли лишь покупатели серверов IBM с ЦП архитектуры POWER. «Могли», потому что в 32-нанометровом процессе IBM воздушные зазоры исчезли — видимо, механическая прочность «дырявого» слоя оказалась слишком малой для его достаточно низкодефектной планаризации.
Пример современного техпроцесса
| Устройство 45-нанометрового p-канального транзистора в микросхемах Intel. Тут не указано присутствие в затворе слоя металла для n-канального транзистора. |
Чтобы подытожить всё вышенаписанное, приведём описание «скоростного» 45-нанометрового техпроцесса Intel как одного из наиболее изученных:
- используется пластина из цельного кремния (не КНИ) и сухая литография на 193 нм с двойным структурированием;
- длина затвора — 35 нм (как и в 65-нанометровом процессе);
- шаг затвора — 160 нм без изоляторов (на 27% меньше, чем в 65-нанометровом) и 200 нм с ними (на 9% меньше);
- осаждение металлического «затвора последним»;
- спрямление углов затвора с помощью покрытия вторым видом фоторезиста;
- эквивалентная толщина высокопроницаемого подзатворного изолятора — 1 нм;
- для улучшения подвижности дырок у p-канальных транзисторов легирование германием истока и стока увеличено с 23 до 30%, что в совокупности увеличило частоту на 51%;
- сонаправленные по всему чипу каналы;
- 10-слойные межсоединения (начиная со 2-го слоя — медные) с изолятором из легированного углеродом диоксида кремния, включая размещённый на истоках и стоках «нулевой» слой вольфрама, также служащий диффузионным барьером;
- почти везде чётные слои металла параллельны каналам, нечётные — перпендикулярны;
- последний, наиболее толстый слой металла работает как термо- и энергораспределитель для всего кристалла;
- обильное использование фиктивных структур (дорожек и затворов) для выравнивания локальной плотности и теплопроводности;
- бессвинцовая пайка кристалла в корпус.
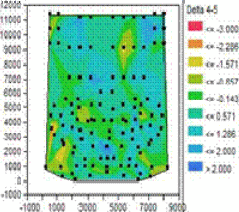
На одной 300-миллиметровой пластине умещается 568 процессоров Core 2 Duo с 6 МБ кэша L2, изготовленных по технорме 45 нм. Средний темп выхода пластин при производстве на фабах Intel — ≈20 мин. на лот (25 пластин). Проверить пластину на сбойность менее чем за 50 секунд полностью не получится, поэтому применяется быстрая оценка состояния транзисторов. Для этого в свободных местах каждого будущего кристалла расположены десятки простейших осцилляторов (чёрные точки), транзисторы которых имеют те же параметры, что и для окружающей логики или кэшей. Замерив частоты каждого осциллятора и зная их расположение, для каждого процессора строится карта отклонений параметров транзисторов. Тут на ней зелёным обозначены средние параметры, жёлтым и красным — замедленные, а голубым и синим — ускоренные. После разрезания пластины на отдельные кристаллы те, которые после оценочных тестов признаны хоть на что-то годными, отправляются на сборочный завод. Там они корпусируются, проходят программирование прошивки, детальное тестирование, отключение неработающих, медленных или слишком прожорливых частей (если требуется) и присваивание множителей и напряжений. | |
 4 последних поколения транзисторов Intel (слева направо, сверху вниз) — 90 (2003 г., первое применение напряжённого кремния), 65 (2005), 45 (2007, первое применение комбинации HKMG) и 32 (2009) нм. | |
 65-нанометровые транзисторы (слева) могли себе позволить такие роскошества как двунаправленные дорожки (вертикали и горизонтали) и переменные размеры затворов и их шагов. Для 32-нанометрового техпроцесса (справа) всё это запрещено. | |
Видео о внутреннем устройстве фабрики фирмы Infineon. А вот полурекламный ролик про интеловский Фаб-32: |
Общим взглядом…
Данные с IC Knowledge, если не указано иное. 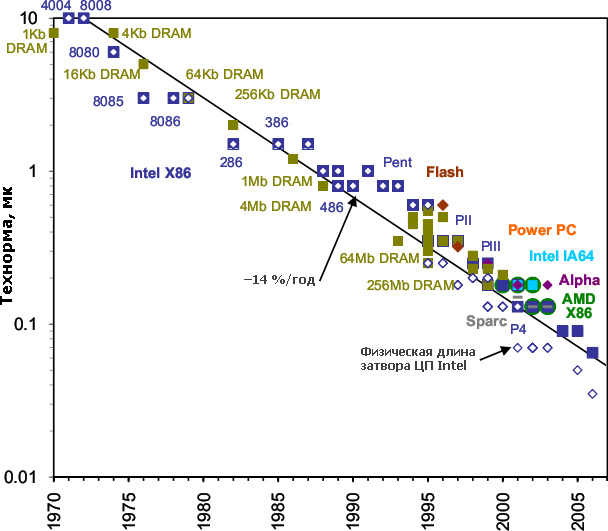 Технорма наиболее сложных микросхем. Падает также их цена — правда, не вдвое (исходя из примерно половинной площади чипа для данного числа транзисторов — за исключением последних техпроцессов…), а примерно в 1,5 раза при каждом переходе на очередной техпроцесс (т. к. он сложнее и дороже на каждую единицу площади). По какой причине физическая длина затвора (не только для ЦП Intel) оказывается меньше технормы — читайте ниже. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Технорма для ЦП Intel. По мнению компании, 15-нанометровый техпроцесс, возможно, станет первым, где будет применяться «экстремальный» ультрафиолет (EUV), если он окажется экономически оправданным. До сих пор чрезвычайная дороговизна (даже по меркам фотолитографов) сдерживала его внедрение, которое 10 лет назад пророчили уже для 45-нанометрового процесса. Основные причины — необходимость в совершенно новом источнике излучения, новой зеркальной (а не линзовой) оптике и полном вакууме в рабочей зоне. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
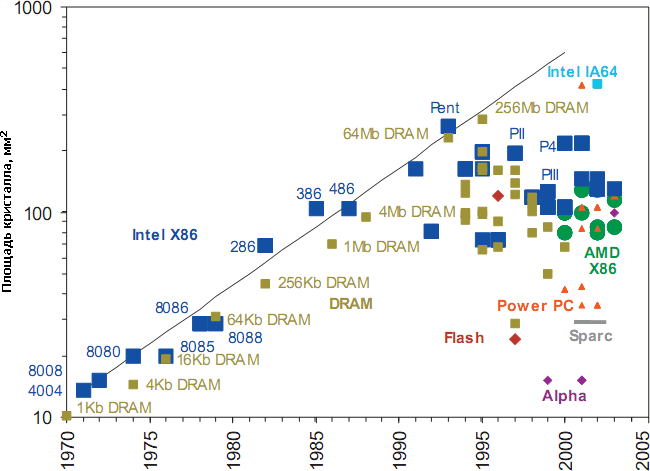 Площади кристаллов наиболее сложных микросхем процессоров и памяти на указанный год. В 1990-е годы тенденция увеличения площади на 14% в год (чёрная линия) остановлена. Впрочем, самые сложные кристаллы ГП и серверных ЦП достигают 400–500 мм², но и эта цифра не растёт уже лет пять, хотя почти все производители уже успели с 90-х перейти на 300-миллиметровые пластины, позволяющие производить с той же массовостью и ценой даже такие большие кристаллы. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
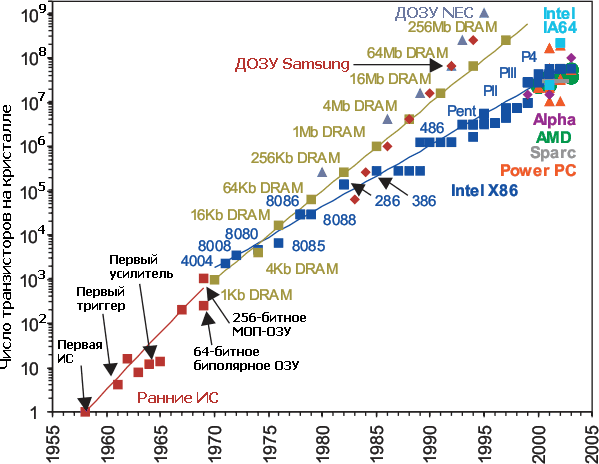 Число транзисторов на кристалле ИС как следствие уменьшения технормы и увеличения площади кристалла. Видно, что первоначальная тенденция 2-кратного роста в год, по которой строил свои рассуждения Гордон Мур, была в прямом смысле весьма крутой. Но с 70-х и микросхемы ДОЗУ (теперь — и флэша), и процессоры продолжили её с меньшими темпами — 58% и 38% в год. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
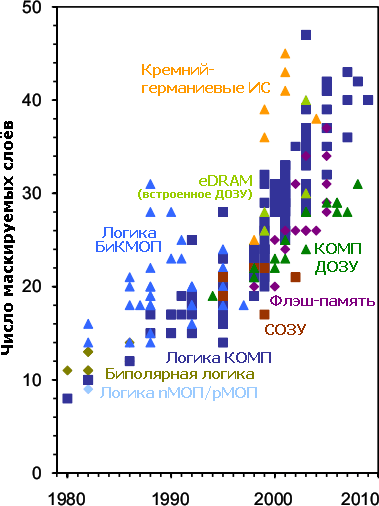
Число слоёв, требующих маски. До введения двойного шаблонирования равно числу самих масок. Каждая маска требует 7–8 производственных операций, а также контрольно-измерительные и транспортные. Примерно 20% слоёв в каждом кристалле (элементы транзисторов и первые слои дорожек и изоляторов) являются «критическими» — т. е. выполнены с номинальной технормой для данного техпроцесса. Остальным достаточно быть всё более грубыми по мере удаления вверх от транзисторов (см. иллюстрацию воздушных зазоров), т. к. верхние уровни металла, как правило, поставляют питание и синхронизацию, так что особой плотности проводников им не требуется. Таким образом наиболее дорогие технологии изготовления применяются только для части слоёв, но даже это не спасает от растущей сложности техпроцессов, особенно с 2000-х годов. 20 лет назад такое уже было с технологией БиКМОП (гибрид биполярной и КМОП), из-за чего от неё отказались (правда, Intel успела выпустить на ней 486DX4, Pentium и P.Pro, а Sun Microsystems — SuperSPARC). Сегодня от взрывного роста сложности не страдают пока только динамическая и (в меньшей степени) флеш-память. Сверхбыстрым SiGe-чипам высокая стоимость не сильно мешает, т. к. их изготавливают малыми партиями для военных и авиакосмических применений. В среднем число масок увеличивается на 2 с каждым техпроцессом, т. е. примерно за 2 года. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
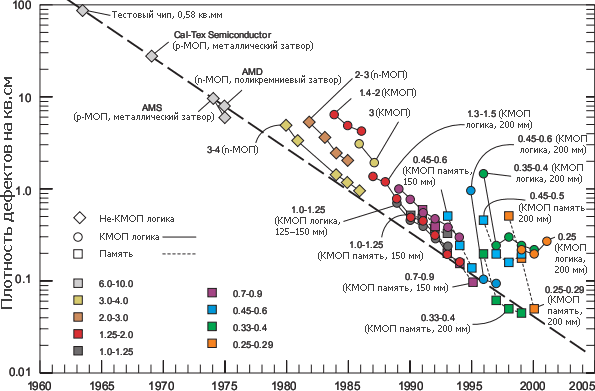 Плотность дефектов на 1 см² площади кристалла от наиболее продвинутых фабов при финальном тестировании. Жирными цифрами указана технорма в микронах, в скобках — диаметр пластин. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
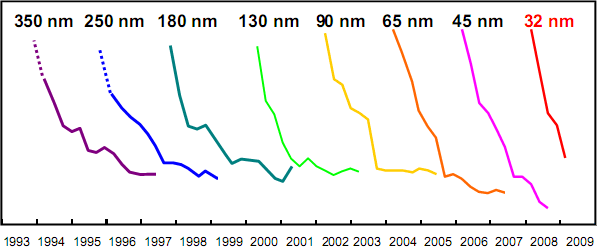 Снова плотность дефектов, но конкретно для чипов Intel. По её утверждению — также отложенная по логарифмической шкале (как и на графике выше), только без шкалы. ;) Данные для 45- и 32-нанометрового техпроцессов показаны не до конца — видимо, коммерческая тайна. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
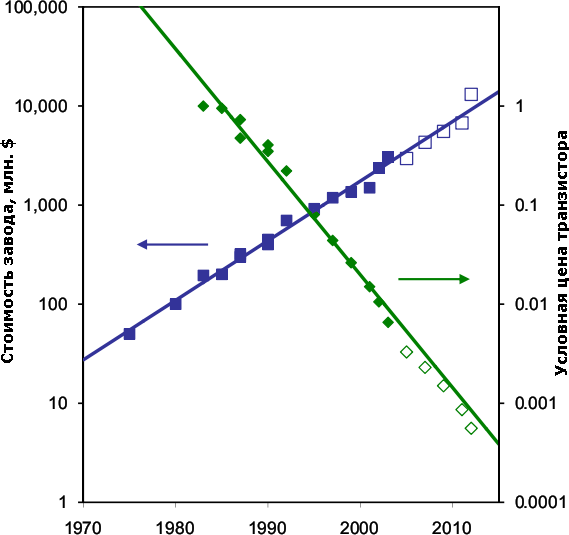 Стоимость постройки наиболее современного на указанный год завода (или его стоимость после обновления) возросла в 70 раз за 30 лет, а цена каждого выпускаемого ими транзистора упала в 2000 раз. Пустые квадраты означают примерные цифры. Тут не хватает графика производственной мощности, но надёжных данных по ней на весь период нет. Впрочем, известно, что современные фабы выпускают от 10 до 60 тыс. пластин в месяц в случае логики и ещё в 2–3 раза больше для памяти. Выпуск пластин удваивается примерно каждые 5 лет, помимо увеличения их диаметра. А «удвоение стоимости фаба каждые 4 года» даже было названо «вторым законом Мура» (иначе — законом Рока, Rock’s law), который в конце 90-х также пришлось поправить — каждые 5 лет. Наиболее дорогой станок — фотолитограф — дорожает с такой же скоростью: первый коммерческий проекционный степпер (1973 г.) стоил 210 тыс. долларов, а современный сканер — 40–50 млн.. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
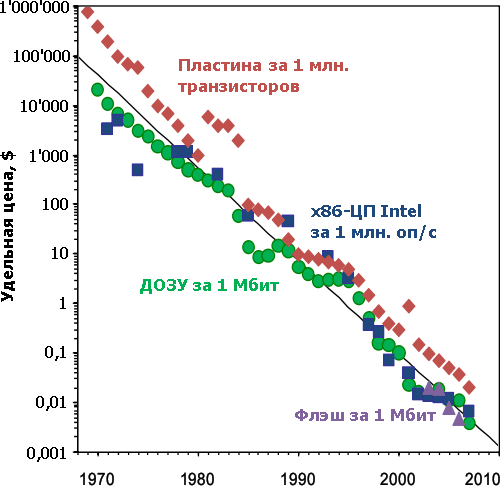 Удельные цены пластины и разных видов микросхем за единицу их наиболее ценных количественных характеристик. Чёрная линия указывает ежегодное падение средней цены на 35% или в 1,54 раза. Больше возможностей за ту же цену чипов позволяли расти продажам микросхем на 15% в год с 1960 по 2000 гг.. Однако лопнул пузырь доткомов, а через 8 лет грянул мировой кризис, что прекратило рост продаж (но не параметров). В 2010-х за счёт популярности смартфонов и планшетников возможен рост примерно на 5% в год, если, конечно, опять что-то не стрясётся… | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
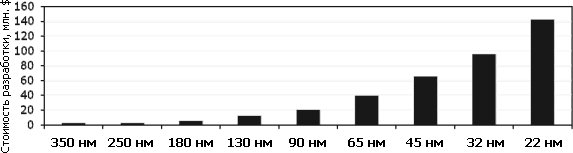 Стоимость разработки сложной микросхемы в зависимости от технормы (данные IBS, GlobalFoundries). Видно, что до 45 нм она каждый раз удваивалась, а начиная с 45 нм — увеличивается примерно в 1,5 раза. Абсолютные цифры уже выросли настолько, что и среди бесфабричных компаний мелким игрокам на рынке ЦП делать нечего. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Средняя стоимость производства пластины для КМОП-логики в 2003 г. на фабах Сев. Америки (в долларах):
Цены округлены и не учитывают финишных операций (тестирования, резки и корпусировки). По цифрам видно, почему производителям выгодно переходить на новые техпроцессы и бо́льшие диаметры пластин — дорожание производства каждой новой пластины окупается бо́льшим числом получаемых с неё чипов. Впрочем, переход на больший диаметр означает замену почти всего оборудования в чистой комнате и усиление потока сверхчистых рабочих материалов (особенно воды), поставляемых с сервисного этажа. А переход на новый техпроцесс, даже «несвежий», поначалу (пока его не отладят) даст меньший выход годных. Впрочем, Intel и тут отличилась, применяя на своих фабах по всему миру методику точного копирования (Copy Exactly): как только техпроцесс доведён до массового производства на одном из экспериментальных фабов в Хиллсборо (штат Орегон, США), он переносится на производственные фабы, копируя абсолютно всё до мелочей — список и тип станков, их параметры («рецепты») и программы, действия персонала… Даже ручные инструменты для монтажных и пуско-наладочных работ используются тех же видов. Звучит несколько параноидально, но Intel может перенести техпроцесс с одной фабрики на другую без ожидаемого в таких случаях ущерба для себестоимости всего за несколько месяцев, и ещё быстрее — производство чипа при уже готовом техпроцессе. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Новый шаг
В начале лета 2011 г. Intel объявила, что менее чем через год будет готова массово выпускать процессоры с технормой 22 нм (сначала это будет архитектура Ivy Bridge, основанная на современной Sandy Bridge). Согласно принятому в компании 2-летнему циклу «тик-так» (попеременному ежегодному выпуску новой микроархитектуры и нового техпроцесса) изначально планировалось выпустить Ivy Bridge в конце 2011 г. (также как Sandy Bridge — в 2010-м). Однако Intel преследуют задержки: презентация Sandy Bridge состоялась только этим январём, а недавно компания решила задержать выход Ivy Bridge как минимум до весны 2012 г.. Являются ли тому причиной сложности с техпроцессом — неясно. Это при том, что первые микросхемы СОЗУ с новыми 22-нанометровыми транзисторами Intel представила ещё в сентябре 2009 г..
Никаких технологических революций по части литографических методов не предвидится — помимо того, что длина волны 193 нм требует иметь не только иммерсионные сканеры, но и как минимум двойное шаблонирование. Это само по себе является любопытным, ибо ещё 5 лет назад эксперты в один голос говорили, что для таких длин волн надо переходить на новые виды литографии, что скачкообразно увеличивает сложность и стоимость техпроцесса.
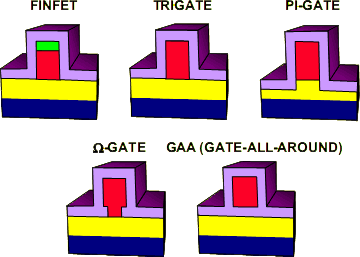 Помимо FinFET’ов, Intel рассматривала ещё 4 варианта новых видов транзисторов, но по разным причинам они были отклонены. Например, технически самый совершенный GAA-транзистор с затвором, полностью окружённым изолятором, видимо, показался слишком дорогим или ненадёжным. Кроме того, т. к. странная зелёная «шапка» ни на каких других иллюстрациях больше не встречается и не видна на микрофотографиях, можно сделать вывод, что реализован вариант с 3-сторонним затвором типа Trigate. |
Но самую большую сенсацию (разумеется, с подачи маркетологов компании) назначили на серьёзное изменение конструкции транзисторов, назвав их трёхмерными или трёхзатворными. Точнее, их надо называть FinFET — полевой транзистор с затвором-«плавником». Впрочем, за счёт утончения канала и размещения его вертикально их число может быть более одного для увеличения общей площади между затвором и каналами. Такой транзистор можно назвать многозатворным (multigate FET, MuGFET), хотя каждый его канал скорее будет управляться общим затвором. В результате к нему нужно будет приложить меньшее напряжение, чтобы переключить транзистор, скорость переключения будет больше, а утечка — меньше, т. к. теперь она возможна лишь через узкую нижнюю грань канала.
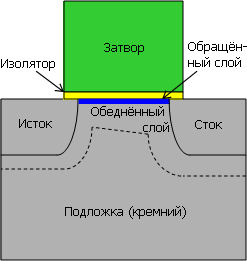 Транзистор на цельной подложке (какую до сих пор использует Intel) имеет утечку тока из канала, когда в нём полем затвора формируется обращённый слой. Подложка (даже если она заземлена) вытягивает часть носителей заряда в обеднённый слой. ▼ |
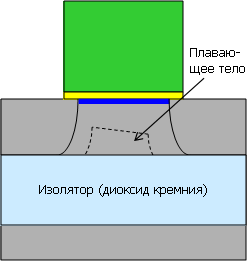 Уменьшить утечки можно технологией КНИ, в данном случае — частично обеднённой (Partially Depleted, PD SOI). Тут изолятор отсекает подложку, но остаточный слой под каналом («плавающее тело») всё ещё приводит к утечкам, хоть и не таким большим. Эта технология широко используется прежде всего из-за относительной дешевизны. ▼ |
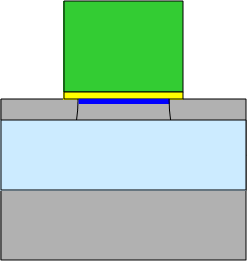 Более продвинутая версия — полностью обеднённый КНИ (Fully Depleted, FD SOI). Тут исток, сток и область канала истончаются так, что плавающему телу не остаётся места. Проблема утечки решается, но (по мнению Intel) с 10-процентным увеличением цены чипа, поэтому её не используют широко. ▼ |
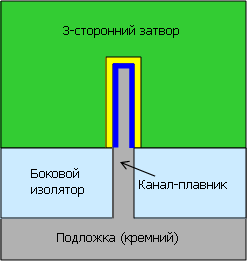 А вот и решение Intel (показанное сбоку, в отличие от предыдущих сечений вдоль канала) — поставить канал вертикально и окружить его затвором с трёх сторон из четырёх. Плавающего тела нет, утечек нет, площадь обращённого слоя больше, а т. к. дополнительные маски не требуются, цена — всего на 2–3% выше. Опять же, со слов Intel. |
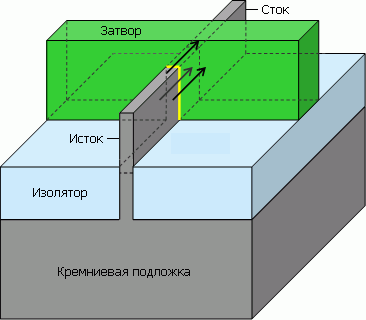 «Трёхзатворный» транзистор на деле означает транзистор с каналом, окружённым затвором (через прослойку в виде тонкого изолятора, обозначенного жёлтым) с трёх сторон — по сравнению с планарным, где поверхность сопряжения представляет собой одну плоскость. |
 Вверху показаны 32-нанометровые планарные транзисторы, внизу — 22-нанометровые 2- (в левом нижнем углу) и 6-затворные «трёхмерные». |
 4 поколения «плавниковых» транзисторов Intel — демонстрация конструкции (2002 г.), многозатворность (2003), ячейки СОЗУ (2006) и адаптация металлического «затвора последним» (2007). |
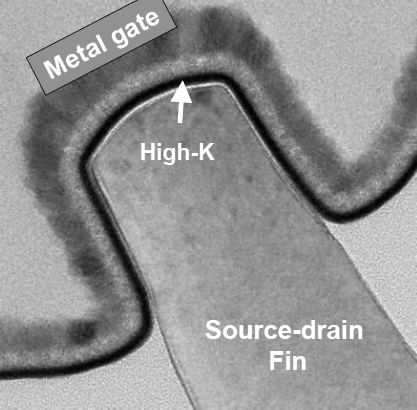 Сечение канала-плавника в образце 2006 г. с первой версией технологии HKMG. |
Конечно, Intel сразу похвасталась, что по сравнению с 10-микронным техпроцессом от i4004 22-нанометровый транзистор работает в 4000 раз быстрее, потребляя в 5000 меньше энергии и стоя в 50 000 меньше. Более важно, что потребовалось 5 лет для разработки и ещё 5 (как теперь выяснилось…) для адаптации к массовому производству. При этом Intel честно указывает на трудности реализации новой технологии: необходимость законцовок для затвора, проблемы с ёмкостью и изменчивостью параметров, трудности равномерной полировки и травления более толстых структур и передача каналом механического напряжения под затвор, и пр.. Надо полагать, все эти проблемы решены хотя бы удовлетворительно, иначе показанные чипы бы не работали. Вопросы о коэффициенте выхода годных и фактической себестоимости пока остаются открытыми. Конкуренты же (TSMC и Global Foundries) пока объявили лишь о начале разработки FinFET’ов для своих 14-нанометровых процессов, которые будут готовы где-то в 2014 г.…
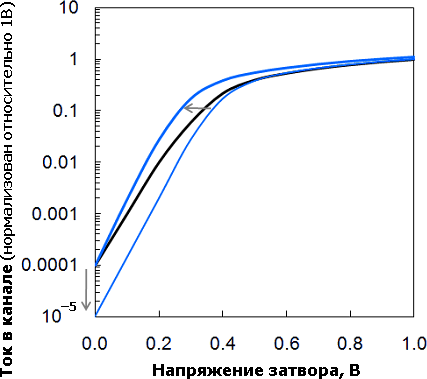
Вольтамперные характеристики (ВАХ) планарного (чёрная линия) и двух трёхмерных (синие) n-канальных транзисторов. Ток при нуле на затворе в идеале должен быть нулевым. Чем он меньше — тем меньше потребляет процессор, в т. ч. при простое. Пороговое напряжение — такое, при котором транзистор переключается (в данном случае — 0,33 В с током в 10% от номинала). Оно должно быть как можно меньше, чтобы транзистор срабатывал быстрее и при меньшем напряжении питания (тут — 1 В). Переход на трёхмерный затвор позволяет либо при том же напряжении уменьшить утечку при закрытом канале (нижняя линия), либо увеличить скорость его открытия (верхняя линия), заодно снизив напряжение. | |
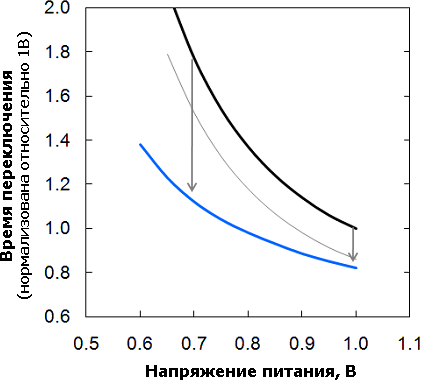
Зависимость времени переключения от напряжения питания (в идеале — гипербола) для 32-нанометровых (чёрная линия) и 22-нанометровых (серая) планарных, а также 22-нанометровых объёмного (синяя) транзисторов. Последний позволяет при той же скорости снизить напряжение питания на 0,2 В, что в теории уменьшит потребление в 1,56 раза, а по мнению Intel — более чем вдвое. Если же требуется повысить частоту, новые транзисторы принесут небольшую пользу при номинальном одном вольте (обещано ускорение на 18% относительно 32 нм), зато при 0,7 В (видимо, таково будет напряжение для мобильных чипов) дадут аж 37-процентное ускорение. Более того, если судить по этим графикам из презентации, то ускорения будут на 22% и 59% — т. е. 1/(1−0,18) и 1/(1−0,37), как и следует считать. Неужели мы застукали технарей Intel на элементарных ошибках при расчётах с процентами?.. |
Разбор нанометров
Самое время разобраться, что понимается под технормой. Попытка дать определение этому важнейшему термину не зря поставлена почти в конец статьи. Когда-то под технормой понимался самый малый по длине или ширине элемент, формируемый данным техпроцессом. Когда технорма стала меньше длины волны, появилось два отдельных определения — для регулярных чипов (память, программируемые матрицы, фотодатчики — в т. ч. со встроенными логическими блоками) и нерегулярных (сложная логика, в т. ч. содержащая кэши, буферы и т. п.). Для первых — минимальный полушаг линейно-регулярной структуры, для вторых — минимальная ширина дорожки нижнего уровня металла (что примерно вдвое длиннее затвора транзистора).
Однако с недавних пор и это перестало иметь значение. Дело в том, что число фабрик, производящих микросхемы по самым современным техпроцессам, неуклонно снижается. При этом ни одна фирма, производящая оборудование для производства полупроводников, их самих не делает — все производители микросхем покупают станки у примерно одних (тоже не очень многочисленных) фирм. Очевидно, собираемые из станков и настроек техпроцессы на фабах получились бы как две капли воды похожи, но это имеет смысл лишь для нескольких фабов одной компании, а таких компаний в мире — единицы. Так что каждая фирма пытается удовлетворить заказчиков чем-то особенным, выпускаемым на почти стандартном оборудовании. И вот тут под нож пошли те самые нанометры…
² — С иммерсионной литографией ³ — С иммерсионной литографией и низкопроницаемыми межслойными диэлектриками |
В этой таблице указана площадь (в кв. микронах) 6-транзисторной ячейки СОЗУ, которой обычно меряют плотность размещения транзисторов для логических микросхем. (Это само по себе любопытно, учитывая, что СОЗУ используются в разнообразных регистрах, буферах и кэшах — т. е. одно-, а чаще даже двухмерно регулярных схемах, а не в синтезированной логике, почти не имеющей повторений. И тем не менее…) А самое главное, что это всё — «45-нанометровые» (как утверждают эти компании) процессы!
Более того, ITRS (International Technology Roadmap for Semiconductors — международный технологический план для [производителей] полупроводников, составляемый экспертами из крупнейших фирм и их ассоциаций) регулярно выпускает рекомендации по основным параметрам техпроцессов для микроэлектронных компаний, т. е. для самих себя. А теперь посмотрим, как эти рекомендации соблюдаются:
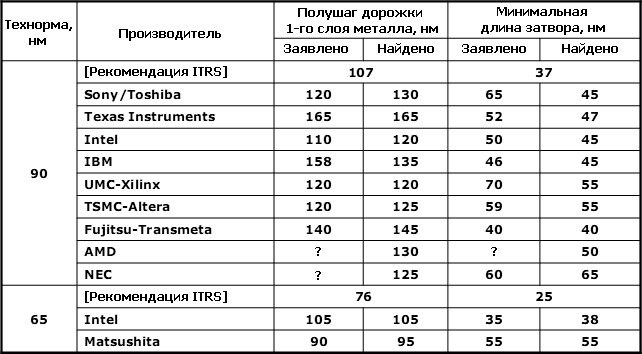 Рекомендации ITRS для логики в 2003 г. в сравнении с фактически найденными параметрами фирмой Chipworks, специализирующейся на «инженерной разборке» микросхем. |
Краткий ответ — никак. Дело дошло до того, что на недавнем форуме IEDM технорму признались считать маркетинговым понятием — т. е. не более чем цифрой для рекламы. Фактически, сегодня сравнивать техпроцессы по нанометрам стало не более разумно, чем 10 лет назад (после выхода Pentium 4) продолжать сравнивать производительность ЦП (пусть даже и одной программной архитектуры) по гигагерцам.
Разница в техпроцессах при одинаковых технормах активно влияет и на цену чипов. Например, AMD использовала разработанный совместно с IBM 65-нанометровый процесс с SOI-пластинами, двойными подзатворными оксидами, имплантированным в кремний германием, двумя видами напряжённых слоёв (сжимающим и растягивающим) и 10 слоями меди для межсоединений. 65-нанометровый техпроцесс у Intel включает относительно дешёвую пластину из цельного кремния, диэлектрик одинарной толщины, имплантированный в кремний германий, один растягивающий слой и 8 слоёв меди. По примерным подсчётам Intel потребует для своего процесса 31 маску, а AMD — 42.
В результате из-за значительной разницы в технологиях напряжённого кремния и типа подложки (SOI-пластины стоят примерно в 3,6 раз дороже простых) конечная цена 300-миллиметровой пластины для AMD будет ≈4300 долларов, что на 70% дороже цены для Intel — ≈2500 долларов. Кстати, ЦП Intel как правило оказываются ещё и с меньшими площадями кристаллов, чем аналогичные по числу ядер и размеру кэшей от AMD. Теперь ясно, почему Intel показывает завидную прибыль, а AMD недавно едва держалась на ногах.
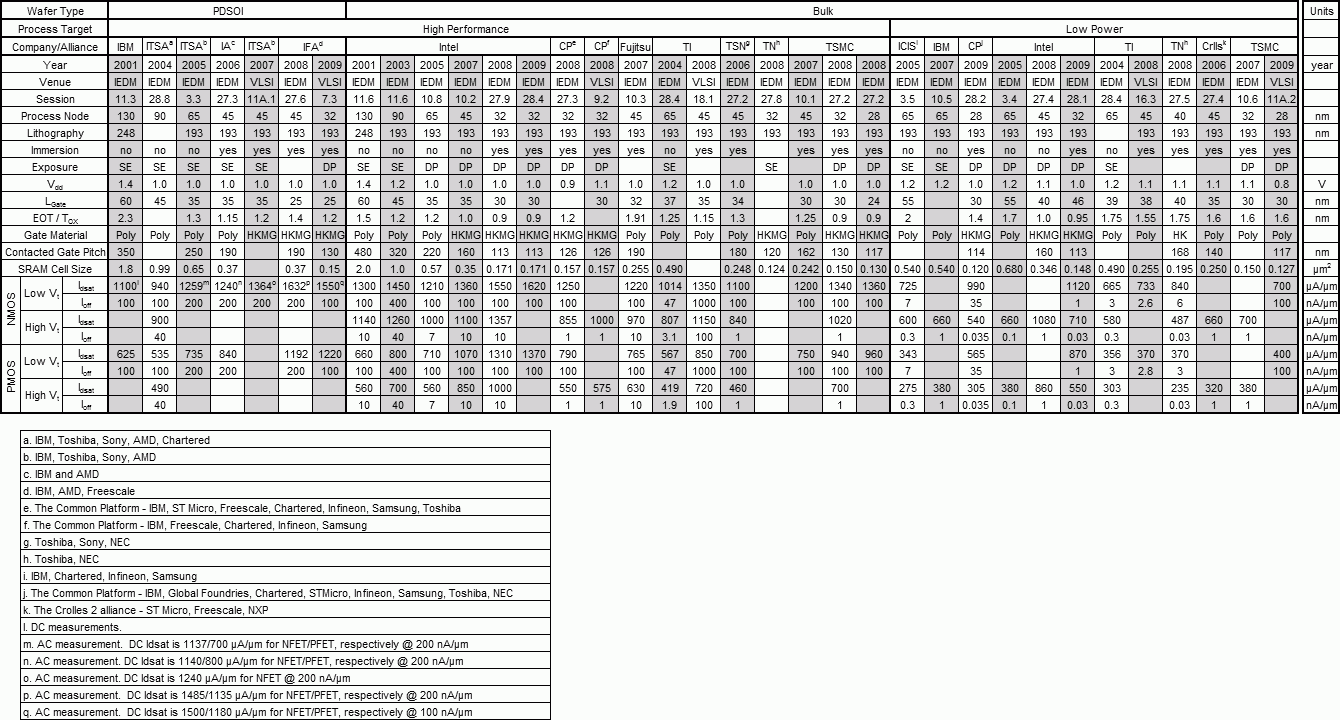 Данные с IEDM о техпроцессах к 2010 году. Источник — RealWorldTech. |
По докладам на IEDM можно составить сводную таблицу с параметрами последних техпроцессов ведущих компаний. Из неё видно, что все техпроцессы с «мелкой» технормой (process node) перешли на двойное шаблонирование (DP) и иммерсионную литографию, а напряжение питания (Vdd) давно остановилось на 1 вольте (потребление транзистором энергии и без этого продолжает падать, но не так быстро). Куда интересней сравнить длину затвора (LGate), шаг затвора с контактом (Contacted Gate Pitch) и площадь ячейки СОЗУ (SRAM Cell Size).
Тут надо указать, что кэши изготовленного с той же технормой ЦП той же фирмы имеют площадь ячейки на 5–15 % больше указанной в случае L2 и L3, и на 50–70 % больше для L1. Дело в том, что сообщаемые на IEDM цифры площади тоже являются несколько рекламными. Они верны лишь для одиночного массива ячеек и не учитывают усилители, буферы ввода-вывода, декодеры адреса, резервы размера для увеличения надёжности и размены плотности на скорость (для L1).
Для простоты возьмём только «скоростные» (High Performance) процессы Intel. Для 130 нм длина затвора составляла 46% технормы, а сегодня — 94%. Тем не менее, шаг затвора уменьшился в те же 4 раза, что и технорма. Однако если разделить площадь ячейки СОЗУ на квадрат технормы, то старым ячейкам нужно ≈120 таких квадратиков, а новым — уже ≈170. У AMD с её SOI-пластинами — примерно так же. На «65-нанометровом» техпроцессе фактический минимальный размер затвора может быть снижен до 25 нм, но шаг между затворами может превышать 130 нм, а минимальный шаг металлической дорожки — 180 нм. Начиная примерно с 2002 г. размеры транзисторов уменьшаются медленней технорм. Выражаясь языком современного рунета — нанометры уже не те…
А теперь, вооружившись цифрами об этом бардаке сложном микроэлектронном хозяйстве, вернёмся к обещанным Intel «22 нанометрам». По предварительным цифрам выглядит неплохо: площадь ячейки — 0,092 кв.мк. для «быстрой» и 0,108 для энергоэффективной версии процесса (данные 2009 г. для тестовой микросхемы СОЗУ на 22 нм). Для быстрой версии это эквивалентно 190 элементарным квадратам — чуть хуже, чем для прошлых технорм. Но Intel продолжит использовать 193-нанометровую иммерсионную литографию и для 14 нм, возможно — с тройным шаблонированием. А для 10 нм — с пятерным (5 экспозиций и одно скругление распорок). При этом для 10-нанометрового процесса стоимость стадий литографии на единицу площади будет примерно вшестеро больше, чем для 32-нанометрового, а вот окажется ли площадь меньше в 10 раз (как при линейном уменьшении) — сомнительно. Тут уже даже неважно, почему Intel решила, что следующие два её процесса будут иметь технормы 14 и 10 нм, а не 16 и 11, как можно ожидать (каждая следующая — в √2 раз меньше). Ведь нанометры теперь мало что значат…
Что дальше?
Если вернуться к обзорным графикам, последние несколько из них не зря касаются цены или себестоимости. Если по ним попытаться экстраполировать тенденции на будущее, то окажется, что через некоторое время в мире останется лишь 2–3 компании, способные разрабатывать и внедрять самые современные техпроцессы. Им это будет влетать в 11-значные суммы в долларах, окупить которые можно, лишь если продукция будет продаваться по всему миру, что возможно только при полной монополизации — одна платформа, одна архитектура, одна концепция… Для необходимой конкуренции избыточности места уже не останется — нас всего 7 миллиардов, и это число растёт совсем не так быстро, как цены на фабы и техпроцессы.
Более того, наверняка будет уменьшаться и число бесфабричных компаний. Дело даже не в том, что немногие крупные фирмы покроют своими чипами почти все потребности почти для всех. Даже если вы разработали что-то уникальное — стоимость внедрения может оказаться такой высокой, что вы не окупите её всеми своими продажами. И это тоже есть следствие массовых технологий:
Формируемое маской изображение перед попаданием на пластину оптически уменьшается в 4 раза до стандартной полосы засвета размером ≈24 мм (для современных литографов), а размер самой маски составляет около 18×12 см. Однако методы OPC и PSM требуют от неё иметь разрешение не хуже формируемого, что уже для 65 нм поднимает стоимость набора масок до сотен тысяч долларов, а для самых новых техпроцессов — до пары миллионов.
Теперь представим, что нам — маленькой, но гордой фирме — надо выпустить систему-на-кристалле, разработанную для новых планшетов и смартфонов. Маркетологи говорят, что из-за сильной конкуренции со стороны угадайте-какой компании устройства с нашим ЦП точно купят 100 000 человек. Процессор на 28-нанометровом техпроцессе (более старый проиграет гонку прожорливости) будет иметь себестоимость около 15 долларов, но если учесть цену масок (пусть и разделённую на 100 000), то будет уже 35 долларов. И это не учитывая выпуск нескольких ревизий для исправления ошибок и оптимизации параметров. Ревизий для нового сложного чипа нужно штук пять — и для каждой (после первой) надо обновлять значительную долю масок из всего набора.
В итоге окажется, что даже не допуская ни одной ошибки в рыночной стратегии, мы окупим нашу микросхему, лишь рассчитывая на производство и сбыт устройств с ней миллионами, иначе её никто не купит из-за цены. Недавно сотрудник компании Cadence (выпускающей специализированные САПРы для разработки микросхем) рассказал, что стоимость перехода с 32–28 на 22–20 нм сильно выросла по сравнению с предыдущими шагами. Микроэлектронные компании инвестировали в НИОКР по 32–28 нм 1,2 млрд. долларов и 2–3 млрд. для 22–20 нм. Проектирование чипа стоит 50–90 млн. долларов для 32 нм и 120–500 млн. долларов для 22 нм. Компенсация затрат на разработку и производство потребует продать 30–40 млн. 32-нанометровых кристаллов и 60–100 млн. на 20 нм.
Впрочем, и крупным компаниям, товары которых покупают как раз миллионами, тоже придётся с трудом объяснять, зачем покупать очередной процессор с терафлопсами и память на терабайты — учитывая, что и прошлые модели делают всё как надо. Возможно, с некоторого момента не поможет и принудительная плата за новинки — например, как следствие досрочно отменённой поддержки старых моделей или их запрограммированного износа и отключения…
Мировая микроэлектроника, следуя закону Мура, всегда опровергала регулярно выдвигаемые инженерами опасения, что мы вот-вот упрёмся в непреодолимые физические ограничения, после которых отрасль либо застрянет навсегда, либо будет вынуждена перейти на принципиально новые материалы и эффекты. Но как бы не оказалось так, что реальным тормозом будет эффект глобального насыщения: после бурного роста менять каждые год-два процессоры и память как обувь и одежду — на новые, подходящие размеры — уже не потребуется.
Другая проблема в том, что даже в тех применениях, где производительность и память никогда не будут лишними, качественный скачок (вместо очередного удвоения регистров, векторов, кэшей и ядер) может быть лишь при переходе на новый вид элементной базы — графеновой, фотонной, спинтронной, квантовой или прочей «волшебной». Но для её разработки, адаптации к массовому производству и (особенно!) построению самого производства потребуется огромное количество денег — куда большее цены современного фаба. Вполне возможно, лет через 10 (когда нынешнюю литографию растягивать далее уже не получится) никакие частные фирмы это не потянут. А какое из государств даже сегодня захочет профинансировать высокорисковые технологии микроэлектроники будущего?
Информация в третьей части, если не указано иное, взята с IC Knowledge.
Автор выражает благодарность экспертам с форума iXBT.com за поправки и замечания.
Комментарии