Nvidia Geforce GTX 690:
описание видеокарты и результаты синтетических тестов
Содержание
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Часть 3 — Результаты игровых тестов (производительность)
В этой части, как обычно, мы изучим саму видеокарту, а также познакомимся с результатами синтетических тестов.
Плата
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | |
|---|---|
|

|
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | |
|---|---|
|
Карта имеет 2x2048 МБ памяти GDDR5 SDRAM,
размещенной в 16 микросхемах на лицевой сторонe PCB.
Микросхемы памяти Hynix (GDDR5). Микросхемы рассчитаны на максимальную частоту работы в 1500 (6000) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | Reference card Nvidia Geforce GTX 590 |

|

|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | Reference card Nvidia Geforce GTX 590 |

|

|
Как мы видим, за концепцию создания карты был взят дизайн предшественника - GTX 590, система питания очень схожа (по пять фаз на каждую обвязку: GPU+память), тот же чип, отвечающий за мост SLI между GPU, разница лишь в том, что у GTX 590 разведены две шины по 384 бит, и потому микросхем памяти 12+12 (задействованы обе стороны PCB), а у GTX 690 - две шины по 256 бит, и потому микросхем памяти 8+8, все размещенные на лицевой стороне, поэтому оборотная сторона карты не требует охлаждения. PCB имеет 10 слоев.
Размеры карты также соблюдены такими же, как и у 590: лишь на 15 мм длиннее стандартных 270 мм для топового класса ускорителей.
Подключение к аналоговым мониторам с d-Sub (VGA) производится через специальные адаптеры-переходники DVI-to-d-Sub. Карта имеет 3 гнезда DVI (все Dual-Link), которые способны через адаптеры передавать сигнал на HDMI.
Отметим особо, что карта также имеет видеовыход DisplayPort версии 1.2 (формата мини), поэтому есть возможность с помощью специальных хабов выводить картинку с такого DP на три монитора.
Также немаловажно сказать, что GTX 690 способен выводить картинку одновременно на ЧЕТЫРЕ монитора! При этом возможна работа и в стерео-режиме. Это все уже играет большое значение для такого столь беспрецендентно мощного ускорителя, как GTX 690.
Максимальные разрешения и частоты:
- 240 Гц — максимальная частота обновления
- 2048×1536@85 Гц — по аналоговому интерфейсу
- 2560×1600@60 Гц — по цифровому интерфейсу (для DVI-гнезд с Dual-Link/HDMI)
Что касается возможностей по ускорению декодирования видео — в 2007 году мы проводили такое исследование, с ним можно ознакомиться здесь.
Карта требует дополнительного питания, причем двумя 8-контактными разъемами.
О системе охлаждения.
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | |
|---|---|
Про систему охлаждения особый разговор. В данном случае инженеры Nvidia постарались максимально возможно увеличить
эффективность кулера при минимальном уровне шума. Основой СО являются два радиатора, каждый из которых базируется
на испарительной камере из медного сплава (это как мини-водяная система охлаждения: жидкость нагревается от ядра,
испаряется и снова конденсируется на другой стороне испарительной камеры, которая более холодная). Каждая из
камер имеет припаянный к ней радиатор, покрытый никелевым сплавом.
В центре конструкции между радиаторами установлен большой вентилятор, также особо спроектированный, чтобы поток воздуха, прогоняемый через радиаторы, был максимально большим при соблюдении минимальной скорости вращения самого вентилятора. Для уменьшения шума и повышения обтекаемости гнездо, где сидит вентилятор, покрыто напыленным магниевым сплавом, который используется в двигателях F22 Raptor. Все устройство сидит на массивном плате, которая является также радиатором для микросхем памяти и силовых транзисторов, и на ней сделаны специальные направленные канавки для потоков воздуха. Кожух кулера покрыт напыленным алюминиевым сплавом и имеет пластиковые окна, через которые видны радиаторы (для контролирования их запыленности). В качестве дополнительного декоративного элемента кожух имеет подсвеченную надпись «Geforce GTX». Как результат, СО получилась крайне хорошо сбалансированной, малошумной (уровень шума примерно в 1.5 раза меньше, чем у двух GTX 680). |

|

|
|

|
|
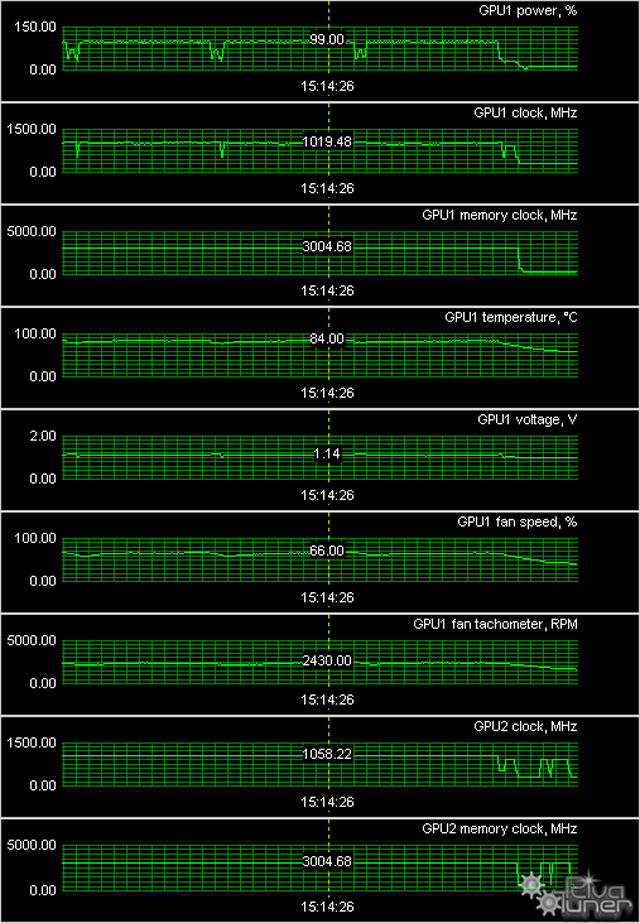
Мы провели исследование температурного режима с помощью новой версии утилиты EVGA PrecisionX (автор А. Николайчук AKA Unwinder) и получили следующие результаты.
| Nvidia Geforce GTX 690 2x2048 МБ 2x256-битной GDDR5 PCI-E | |
|---|---|
|
|
Как мы видим, после 6-ти часов прогона карты температура не превысила 84 градусов, что для супер-топового ускорителя просто прекрасный результат! Отметим, что вентилятор достигал 66% от максимальных оборотов, что составило почти 2500 оборотов в минуту, при этом шум был минимальным, хотя по идее должен быть более ощутим. Вышеотмеченные внедренные технологии работают на деле.
Видеокарта прибыла к нам без упаковки и комплекта (маркетинговый деревянный ящик мы не учитываем, потому как в нем серийные карты поставляться не будут), потому вопрос комплектации мы опускаем.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core i7-975 (Socket 1366)
- процессор Intel Core i7-975 (3340 МГц);
- системная плата Asus P6T Deluxe на чипсете Intel X58;
- оперативная память 6 ГБ DDR3 SDRAM Corsair 1600 МГц;
- жесткий диск WD Caviar SE WD1600JD 160 ГБ SATA;
- блок питания Enermax Platimax 1200 Вт.
- операционная система Windows 7 64-битная; DirectX 11;
- монитор Dell UltraSharp U3011 (30″);
- драйверы AMD версии Catalyst 12.4; Nvidia версии 301.33/301.24
VSync отключен.
Синтетические тесты
Используемые нами пакеты синтетических тестов можно скачать здесь:
- D3D RightMark Beta 4 (1050) с описанием на сайте 3d.rightmark.org.
- D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3 — тесты пиксельных шейдеров версий 2.0 и 3.0, ссылка.
- RightMark3D 2.0 с кратким описанием: под Vista без SP1, под Vista c SP1.
Для работы RightMark3D 2.0 требуется установленный пакет MS Visual Studio 2005 runtime, а также последнее обновление DirectX runtime.
В качестве синтетических тестов DirectX 11 мы использовали примеры из пакетов SDK компаний Microsoft и AMD, а также демонстрационной программой Nvidia. Во-первых, это HDRToneMappingCS11.exe и NBodyGravityCS11.exe из комплекта DirectX SDK (February 2010).
Мы взяли и приложения обоих производителей видеочипов: Nvidia и AMD. Из ATI Radeon SDK были взяты примеры DetailTessellation11 и PNTriangles11 (они также есть и в DirectX SDK). Дополнительно использовалась демонстрационная программа компании Nvidia — Realistic Water Terrain, также известная как Island11.
Синтетические тесты проводились на следующих видеокартах:
- Geforce GTX 690 со стандартными параметрами (далее GTX 690)
- Geforce GTX 680 SLI — две видеокарты Geforce GTX 680 в режиме SLI со стандартными параметрами (далее GTX 680 SLI)
- Geforce GTX 680 со стандартными параметрами (далее GTX 680)
- Radeon HD 7970 со стандартными параметрами (далее HD 7970)
- Radeon HD 6990 со стандартными параметрами (далее HD 6990)
Для сравнения результатов рассматриваемой сегодня двухчиповой видеокарты Nvidia Geforce GTX 690 эти модели были выбраны по следующим причинам. Geforce GTX 680 является старшей одночиповой моделью текущего поколения Kepler, а две такие видеокарты в конфигурации Nvidia SLI являются аналогичной новинке видеоподсистемой на базе двух чипов GK104.
Выбранная пара видеокарт от конкурирующей компании AMD была взята нами для синтетических тестов потому, что Radeon HD 7970 является наиболее производительным решением AMD, хотя эта видеокарта и основана на одном GPU. Так как эта компания пока что не анонсировала своё двухчиповое решение нового поколения, в тесты была взята и Radeon HD 6990 — как предыдущая топовая модель от AMD, имеющая два видеочипа. Понятно, что реальным конкурентом для Geforce GTX 690 будет двухчиповый аналог на двух графических процессорах Tahiti, но он ещё не анонсирован.
Direct3D 9: тесты Pixel Shaders
Тесты текстурирования и заполнения (филлрейта) из пакета 3DMark Vantage мы рассмотрим ниже, а первая группа пиксельных шейдеров, которую мы используем, включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0, встречающихся в старых играх, и она очень проста для современных видеочипов.
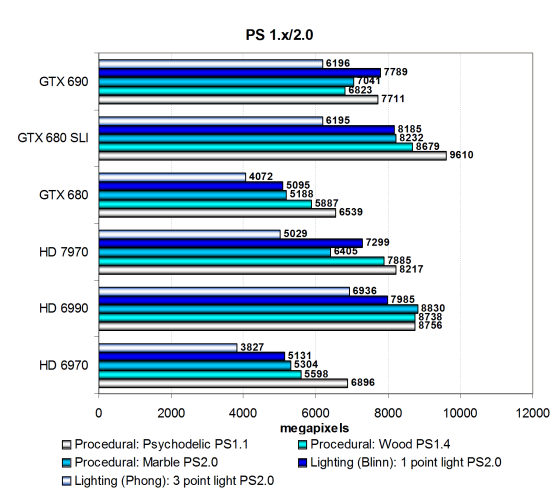
Производительность в этих тестах на современных GPU зачастую упирается в скорость текстурирования или филлрейт. Поэтому тесты показывают далеко не все возможности современных видеочипов, но интересны с точки зрения аналогов устаревших 3D приложений, которых до сих пор довольно много среди игр.
Судя по предыдущим нашим сравнениям, производительность новых видеокарт в этих тестах ограничена чаще всего филлрейтом, хотя и влияние скорости текстурных модулей тоже прослеживается. Но оно неявное, так как Geforce GTX 680 не стал победителем, уступив конкуренту от AMD и не так сильно обогнав предшествующую модель GTX 580.
В этих тестах сильнее всего или система на двух GTX 680 или топовая двухчиповая видеоплата компании AMD из предыдущего поколения. А вот небольшой прирост от двух GPU у двухчипового GTX 690 в простых тестах немного смущает, особенно на фоне результатов двух GTX 680 в SLI. Возможно, мы наблюдаем разницу в программных оптимизациях в драйвере или нехватку пропускной способности слота PCI-E для двух графических процессоров новинки.
Но в целом, здесь GTX 690 выступила неплохо, в половине тестов на уровне GTX 680 SLI и HD 6990. Хотя понятно, что по-хорошему сравнивать новинку нужно бы с реальным конкурентом в виде двухчиповой модели серии Radeon HD 7000, но его пока что не анонсировали. Посмотрим на результаты более сложных пиксельных программ промежуточных версий:
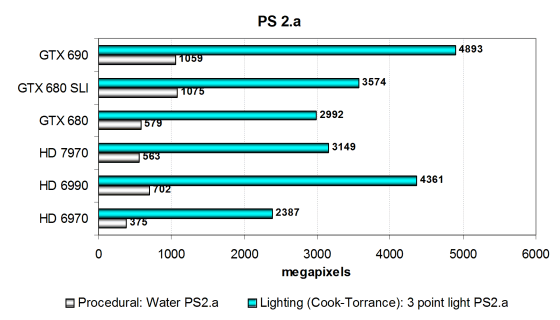
В этих тестах мы видим ещё более загадочную разницу между двумя двухчиповыми системами от Nvidia. Тест Cook-Torrance более интенсивен вычислительно, разница в нём примерно соответствует разнице в количестве ALU и их частоте, и от скорости TMU она также зависит. Но почему GTX 690 с большим преимуществом обогнала две GTX 680? Кроме программных оптимизаций под GTX 690, других мыслей в голову не приходит.
Вообще, этот тест лучше подходит графическим решениям компании AMD, и двухчиповый Radeon седьмой серии, скорее всего, станет лучшим. Но последние видеокарты Nvidia сильно подтянули производительность в этой части синтетики, и именно Geforce GTX 690 стала победителем.
Во втором, больше зависящем от скорости текстурирования, тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, и поэтому видеокарты в нём располагаются по скорости текстурирования. И в этом «текстурном» тесте новая модель GTX 690 показала результат почти на уровне двух GTX 680, уступив им только из-за немного сниженных частот. Зато видеокарты AMD остались позади и их двухчиповый вариант выше GTX 690 не прыгнет.
Direct3D 9: тесты пиксельных шейдеров Pixel Shaders 2.0
Эти тесты пиксельных шейдеров DirectX 9 сложнее предыдущих, они близки к тому, что мы сейчас видим в мультиплатформенных играх, и делятся на две категории. Начнем с более простых шейдеров версии 2.0:
- Parallax Mapping — знакомый по большинству современных игр метод наложения текстур, подробно описанный в статье Современная терминология 3D-графики.
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами.
Существует два варианта этих шейдеров: с ориентацией на математические вычисления и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:

Это — универсальные тесты, производительность в которых зависит и от скорости блоков ALU, и от скорости текстурирования, также в них важен общий баланс чипа и эффективность исполнения вычислительных программ. Результаты теста показывают, что в устаревших задачах архитектура AMD продолжает опережать GPU производства Nvidia.
Производительность лучшей из одночиповых видеокарт AMD в тесте «Frozen Glass» значительно выше, чем у новинки, и даже двух GTX 680 в SLI. Удивительно, но GTX 690 в этом тесте показала явно аномальный результат, говорящий о каких-то программных проблемах или нехватке пропускной способности PCI-E, что менее вероятно.
Во втором тесте «Parallax Mapping» новая видеокарта Nvidia показала более высокую производительность, по сравнению с двумя одночиповыми аналогами, что ещё раз убеждает нас в том, что разница между GTX 690 и GTX 680 SLI объясняется различными оптимизациями в видеодрайвере для SLI-конфигураций и конкретно модели Geforce GTX 690.
В любом случае, решения Nvidia в этом тесте не смогли догнать двухчиповую плату от AMD даже предыдущего поколения. Да и Radeon HD 7970 отстала совсем немного, так что двухчиповый вариант точно будет сильнее. Вероятно, новая архитектура Radeon просто эффективнее в подобных задачах. Рассмотрим эти же тесты в модификации с предпочтением выборок из текстур математическим вычислениям:
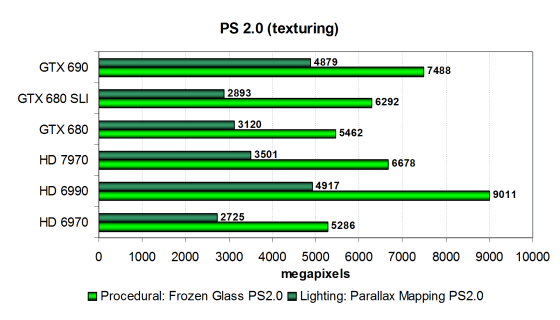
В целом положение плат с GPU производства Nvidia стало чуть лучше, и Geforce GTX 690 почти догнала старый двухчиповый Radeon HD 6990. Эффективность SLI в этих тестах очень низкая, и особенно это касается SLI-конфигурации на базе двух GTX 680. Новинка Nvidia чувствует себя лучше, и в этом явно виноваты программные оптимизации в драйвере, так как его версия для систем Nvidia была одинаковой. И всё же, двухчиповый Radeon на база пары Tahiti должен стать сильнее представленной сегодня платы конкурента. Так что вывод о том, что современные чипы AMD в этих задачах эффективнее, подтвердился в очередной раз.
Но это были устаревшие задачи, с упором в текстурирование и филлрейт. Далее мы рассмотрим результаты ещё двух тестов пиксельных шейдеров — но уже версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9. Они наиболее показательны с точки зрения современных игр на ПК, среди которых много мультиплатформенных. Тесты отличаются тем, что сильно нагружают и ALU, и текстурные модули, обе шейдерные программы сложны и длинны, и включают большое количество ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, также описанная в статье Современная терминология 3D-графики.
- Fur — процедурный шейдер, визуализирующий мех.
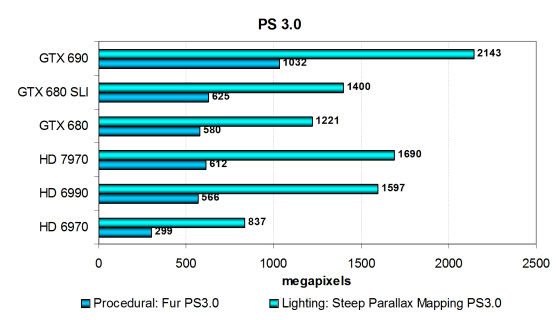
В самых сложных DX9-тестах из первой версии пакета RightMark видеокарты производства Nvidia всегда были весьма сильны, в отличие от других тестов этого пакета, хотя в последней архитектуре компании AMD избавились от некоторых недостатков, сильно подтянув производительность архитектуры GCN в PS 3.0 сравнении.
Данные тесты уже не ограничены производительностью лишь текстурных выборок, а больше всего зависят от эффективности исполнения шейдерного кода. Новый чип AMD чуть лучше справляется со сложными шейдерами, по сравнению с GK104, особенно если сравнивать их в тесте продвинутого параллакс маппинга. Вероятно, так получается из-за большего количества регистров на потоковый процессор.
Но и сегодняшний герой обзора показал неплохой результат, став лидером по этой паре тестов. Удивительно, но и тут Geforce GTX 690 обогнал пару GTX 680 с большущим запасом — примерно в полтора раза! Но Radeon HD 7970 эффективнее выполняет одну из этих тяжёлых задач и поэтому двухчиповый вариант будет ещё сильнее. Ну а пока что и в «Fur» и в «Steep Parallax Mapping» он показывает лучший результат среди всех протестированных решений.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)
Во вторую версию RightMark3D вошли два знакомых теста PS 3.0 под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсэмплинга, что дополнительно увеличивает нагрузку на видеочипы.
Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере.
Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40—80, включение «шейдерного» суперсэмплинга — до 60—120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот.
Проверим сначала режимы без включенного суперсэмплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым.
Производительность в этом тесте зависит в большей степени от количества и эффективности блоков TMU, но также влияет и эффективность выполнения сложных программ. В варианте без суперсэмплинга дополнительное влияние на производительность оказывает ещё и эффективный филлрейт и пропускная способность памяти (в меньшей степени). Результаты при детализации уровня «High» получаются до полутора раза ниже, чем при «Low».
Как и в аналогичных DX9 тестах, в задачах процедурной визуализации меха с большим количеством текстурных выборок, решения Nvidia раньше были заметно сильнее, но за пару поколений GPU компания AMD не только сократила разницу, но и вовсе вырвалась вперёд. И теперь мы видим Radeon HD 7970 в лидерах таких сравнений, что говорит о высокой эффективности выполнения им сложных пиксельных программ.
Рассматриваемая сегодня Geforce GTX 690 показала результат чуть хуже, чем у пары одночиповых GTX 680, что объясняется немного пониженными частотами в случае двухчиповой платы. Но в целом, преимущество над одиночной GTX 680 неплохое, хотя одночиповая Radeon HD 7970 выглядит очень сильно, и соответствующий Radeon на двух таких GPU должен будет перехватить инициативу.
Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсэмплингом, увеличивающим работу в четыре раза: возможно, в такой ситуации что-то изменится, и ПСП с филлрейтом будут влиять меньше:
В этом варианте разница между GTX 680 и двухчиповыми конфигурациями стала ещё более заметной. GTX 680 SLI и GTX 690 идут почти вровень в тяжёлых условиях, а в лёгких двухчиповая плата немного отстаёт. К сожалению, при включении суперсэмплинга, увеличивающего теоретическую нагрузку вчетверо, результаты решений Nvidia в целом ухудшились, по сравнению с показателями видеокарт от AMD.
И теперь протестированная двухчиповая новинка Nvidia лишь немного опережает одночиповую Radeon HD 7970. Топовая плата из серии HD 7000 в этом тесте показывает просто отличный уровень производительности, что явно говорит о будущей победе двухчиповой платы на базе двух графических процессоров Tahiti. Но пока что из одиночных карт GTX 690 стала быстрейшей.
Следующий DX10-тест измеряет производительность исполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок и называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением число выборок возрастает в два раза, а суперсэмплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсэмплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше по сравнению с простым режимом. Проверяем сначала простые варианты без суперсэмплинга:
Второй пиксель-шейдерный тест Direct3D 10 несколько интереснее с практической точки зрения, так как разновидности parallax mapping широко применяются в играх, а тяжелые варианты, вроде steep parallax mapping, используются во многих проектах, например в играх серий Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсэмплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип ещё примерно в два раза — такой режим называется «High».
Диаграмма очень похожа на предыдущую (без включения SSAA), и решения Nvidia в этом тесте не смогли улучшить своё положение. Новая плата Geforce GTX 690 в обновленном D3D10-варианте теста параллакс маппинга без суперсэмплинга в тяжелых условиях опередила две GTX 680, а в лёгких уступила им немного. Преимущество над одночиповой платой приличное, но конкурировать с двухчиповой топовой платой из серии Radeon HD 7000 ей будет сложно. Посмотрим, что изменит включение суперсэмплинга, ведь он обычно вызывает сильное падение скорости на платах Nvidia.
Всё примерно так же, что и в «Fur», но при включении суперсэмплинга и самозатенения, задача получается ещё более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая серьёзное падение производительности. Разница между скоростными показателями протестированных видеокарт изменилась, включение суперсэмплинга сказывается, как и в предыдущем случае — видеокарты производства AMD явно улучшили относительные показатели, по сравнению с платами на чипах Nvidia.
Кроме Geforce GTX 690. На наше удивление новинка именно здесь оказалась гораздо быстрее, чем две платы GTX 680, совместно работающие над рендерингом. Отличие просто поразительное — она на 25-30% быстрее аналогичной конфигурации, но на двух PCB. Вряд ли тут виновато использование чипа-коммутатора на одной плате, больше всего похоже на программные оптимизации, специфичные именно для GTX 690.
В итоге Geforce GTX 690 стала явным лидером, хотя и временным — до выхода двухчиповой платы AMD из нового семейства. Понятно, что такой Radeon будет далеко впереди, так как даже HD 7970 показал отличные результаты. Последние решения AMD отлично справляются со сложными «шейдерными» задачами, заметно лучше даже самых новых плат Nvidia.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (вычисления)
Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере.
Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos.
Результаты предельных математических тестов обычно более-менее соответствуют разнице в частотах и количестве вычислительных блоков, но с небольшим влиянием разной эффективности их использования. Предыдущие архитектуры AMD нескольких последних лет в таких случаях имели значительное преимущество над конкурирующими видеокартами Nvidia, но именно в Kepler число потоковых процессоров и пиковая математическая производительность значительно возросли и ситуация изменилась.
Результаты видеокарт расположились на диаграмме почти соответственно теории, хотя эффективность SLI в таком случае явно далека от 100%. Даже GTX 690 не смогла показать близкое к двукратному превосходству над GTX 680, не говоря уже о паре таких плат. Видимо, недостаток программных оптимизаций не позволил двухчиповым решениям Nvidia показать то, на что они способны в реальности.
А вот GTX 680 вполне себе на уровне лучшего одночипового решения конкурента. Но, судя по эффективности CrossFire на двухчиповой плате HD 6990, при выходе новинки серии Radeon HD 7000 на базе двух топовых GPU, именно она захватит лидерство, и виновата в этом не пиковая производительность, а лучшие программные оптимизации.
Рассмотрим второй тест шейдерных вычислений, который носит название Fire. Он тяжелее для ALU, и текстурная выборка в нём только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки:
В этот раз относительный результат плат Nvidia оказался немного ниже, и одночиповая GTX 680 уступила Radeon HD 7970 столько, сколько должна по теории. Система на базе двух Geforce GTX 680 в SLI также показала неэффективную работу в тесте, став второй с конца. А вот рассматриваемый сегодня GTX 690 снова показал результат на уровне старого двухчипового Radeon HD 6990, что в целом не так уж и плохо.
Строгого соответствия теоретическим цифрам пиковой производительности нет и в этот раз, но результаты большинства решений к ним несколько ближе, чем в предыдущем тесте. Скорость рендеринга в данном тесте ограничена исключительно производительностью шейдерных блоков и их эффективностью, поэтому платы Radeon показывают сильные результаты. Но хотя решения AMD до сих пор выигрывают математические сражения, разница между конкурирующими платами не такая существенная, как в предыдущих поколениях.
Direct3D 10: тесты геометрических шейдеров
В пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующие частицу. Аналогичные алгоритмы должны получить широкое использование в будущих играх под DirectX 10.
Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково.
Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности:
Соотношение скоростей при разной геометрической сложности сцен примерно одинаково для всех решений, их производительность соответствует количеству точек, и с каждым шагом падение FPS почти двукратное. Задача эта для современных видеокарт не слишком сложная, и производительность в ней ограничена или скоростью обработки геометрии или пропускной способностью памяти.
Разница между платами Nvidia и AMD тут огромна. Если в предыдущих шейдерных тестах платы AMD показали себя явно лучше, то в первом же тесте геометрии мы видим совершенно иную расстановку сил. Плата Geforce GTX 680 укрепила позиции Nvidia, а Geforce GTX 690 и вовсе вдвое быстрее, ровно как и две платы GTX 680, работающие в режиме SLI — эти две конфигурации показали сравнимые результаты, со скидкой на разность в частотах.
Сравнение новой платы компании Nvidia даже с ещё не вышедшим конкурентом от AMD простое — изделие калифорнийцев точно окажется тут быстрее, так как результат Radeon HD 7970 далёк от скорости Geforce GTX 680. Посмотрим, как изменится ситуация при переносе части вычислений в геометрический шейдер:
При изменении нагрузки в этом тесте цифры всех решений немного улучшились. Видеокарты в данном тесте слабо реагируют на изменение параметра GS load, отвечающего за перенос части вычислений в геометрический шейдер, поэтому и выводы остаются прежними. Geforce GTX 680 всё так же опережает Radeon HD 7970 в полтора раза, поэтому и с двухчиповыми платами будет то же самое. Тем более что эффективность SLI в этом тесте оказалась весьма велика.
К сожалению, «Hyperlight» —следующий тест геометрических шейдеров, который предполагает большую нагрузку именно на геометрические шейдеры и демонстрирующий использование сразу нескольких техник, на всех многочиповых решениях исполняется некорректно, показывая аномальные результаты на обеих SLI-конфигурациях Nvidia и двухчиповой плате Radeon HD 6990. Поэтому смысла в его анализе нет никакого, и мы переходим сразу к тестам вершинных шейдеров.
Direct3D 10: скорость выборки текстур из вершинных шейдеров
В тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути, так что соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет.
Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»:
Наши предыдущие исследования показали, что на результаты этого теста может влиять и скорость текстурирования и пропускная способность памяти, особенно в лёгком режиме. А результаты видеокарт Nvidia зачастую ограничены ещё чем-то неизвестным. И в целом, между схожими по классу платами разница в этом тесте получается очень маленькая.
И в этот раз анализировать результаты очень непросто. Radeon HD 7970 оказалась быстрее своей соперницы Geforce GTX 680, а двухчиповая GTX 690 заметно менее эффективно выполнила задачу, по сравнению с системой на базе двух плат GTX 680. Сказалось или ограничение пропускной способности PCI-E интерфейса или разность в оптимизациях для SLI конфигураций. Но в целом, решения выступили слишком близко друг к другу, все двухчиповые конфигурации очень похоже ведут себя в этом тесте.
Новая двухчиповая плата семейства GTX 600 с такой производительностью в тесте вряд ли сможет конкурировать с будущим аналогом Radeon HD 7970 на базе двух GPU. Но более всего непонятно отставание новинки от пары плат GTX 680 в SLI. Посмотрим на производительность в этом же тесте с увеличенным количеством текстурных выборок:
Взаимное расположение карт на диаграмме изменилось в основном за счёт того, что новая плата Nvidia почти не потеряла скорости рендеринга в тяжёлых режимах, в отличие от остальных решений. Особенно плат AMD, которые немного сдали. И теперь результаты GTX 690 приблизились к показателям двух GTX 680, что явно говорит о разнице в программной части, хотя драйверы были идентичными. О сравнении с будущим конкурентом можно сказать то же самое, что и в прошлый раз — скорее всего, будущий двухчиповый аналог от AMD покажет тут более высокую скорость рендеринга.
Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту.
Результаты во втором тесте вершинного текстурирования «Waves» привычно не похожи на то, что мы видели на предыдущих диаграммах. Хотя для Geforce GTX 690 всё стало ещё печальнее — к сожалению, в этом тесте новая видеокарта Nvidia показала очень низкую эффективность двухчипового рендеринга, особенно в тяжёлых условиях. При высоком количестве обрабатываемых полигонов её скорость немногим выше производительности одиночной платы GTX 680.
Интересно, что лучшей стала старая Radeon HD 6990, а пара GTX 680 уступила ей лишь немного. А там и Radeon HD 7970 недалеко. Поэтому двухчиповый Radeon HD 7000 явно будет сильнейшим в тесте текстурных выборок из вершинных шейдеров, осталось лишь его дождаться. Рассмотрим второй вариант этого же теста:
Некоторые видеокарты немного ухудшили свои результаты, но не Geforce GTX 690. Это позволило новой плате Nvidia немного улучшить положение, приблизившись к результатам Radeon, но всё же из-за низкой эффективности SLI именно на этой плате (у пары GTX 680 всё более-менее в порядке, как ни странно) в тяжёлых режимах она хуже даже одночиповой Radeon. Так что тесты вершинного текстурирования остаются скорее показателем драйверной оптимизации, чем аппаратных возможностей.
3DMark Vantage: тесты Feature
Синтетические тесты из пакета 3DMark Vantage покажут нам то, что мы ранее упустили. Feature тесты из этого тестового пакета обладают поддержкой DirectX 10 и интересны тем, что отличаются от наших и до сих пор актуальны. При анализе результатов новой двухчиповой видеокарты Nvidia в этом пакете мы сделаем какие-то новые и полезные выводы, ускользнувшие от нас в тестах семейства RightMark.
Feature Test 1: Texture FillПервый тест — тест скорости текстурных выборок. Используется заполнение прямоугольника значениями, считываемыми из маленькой текстуры с использованием многочисленных текстурных координат, которые изменяются каждый кадр.
Тест компании Futuremark не показывает теоретически возможного уровня производительности текстурных выборок, но эффективность видеокарт от AMD и Nvidia в нём достаточно высока и сравнительные цифры моделей близки к соответствующим теоретическим параметрам. Представленная сегодня двухчиповая модель Geforce GTX 690 показала неплохую эффективность SLI-рендеринга в этом тесте, хотя и не 100%-ную. Разница между одноплатной GTX 690 и двумя GTX 680 в SLI составила примерно 10%.
Ранние видеокарты Nvidia в этом тесте были весьма слабы из-за малого количества TMU, а теперь всё стало намного лучше. Учитывая чуть большую производительность Radeon HD 7970 в этом тесте, по сравнению с GTX 680, а также неплохую эффективность CrossFire в таких тестах, можно предположить, что несмотря на несколько худшие теоретические показатели, будущее двухчиповое решение AMD должно немного опередить новинку Nvidia. Но пока что из всех видеокарт лидирует именно она, прилично обгоняя двухчиповую Radeon HD 6990 предыдущего поколения.
Feature Test 2: Color FillЭто тест скорости заполнения. Используется очень простой пиксельный шейдер, не ограничивающий производительность. Интерполированное значение цвета записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется 16-битный внеэкранный буфер формата FP16, наиболее часто используемый в играх, применяющих HDR-рендеринг, поэтому такой тест является вполне своевременным.
Взаимное расположение плат в тесте производительности блоков ROP почти такое же. Как мы определили ранее, цифры этого подтеста из 3DMark Vantage хоть и показывают производительность блоков ROP, но с огромным влиянием величины пропускной способности видеопамяти (т.н. «эффективный филлрейт»). Тест часто измеряет скорее пропускную способность памяти, чем производительность ROP.
В прошлой статье мы отметили, что в Kepler явно видны улучшения в эффективности работы этих блоков. И новая двухчиповая модель Geforce GTX 680 неплохо справилась с задачей, показав результат на одном уровне с двумя платами GTX 680 и почти вдвое выше, чем показала одиночная GTX 680. Так что двухчиповому аналогу Radeon HD 7970 будет тяжело обогнать Geforce GTX 690, хотя эта плата явно будет иметь значительно более высокую пропускную способность памяти.
Feature Test 3: Parallax Occlusion MappingОдин из самых интересных feature-тестов, так как подобная техника уже используется в играх. В нём рисуется один четырехугольник (точнее, два треугольника) с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются довольно ресурсоёмкие операции по трассировке лучей и карта глубины большого разрешения. Также эта поверхность затеняется при помощи тяжёлого алгоритма Strauss. Это тест очень сложного и тяжелого для видеочипа пиксельного шейдера, содержащего многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss.
Этот тест отличается от всех проведённых нами выше тем, что результаты в нём зависят не исключительно от скорости математических вычислений, эффективности исполнения ветвлений или скорости текстурных выборок, а от всего сразу. А для достижения высокой скорости тут важен верный баланс GPU, а также эффективность выполнения сложных шейдеров.
Интересно, что в синтетике из 3DMark Vantage новая плата Geforce показала почти вдвое больший результат, по сравнению с одной Geforce GTX 680, но пара таких карт отработала в этот раз заметно хуже, не догнав даже одиночную Radeon HD 7970. Ну а лидером ожидаемо стала наша сегодняшняя героиня — двухчиповая GTX 690, оказавшаяся быстрее всех. Хотя преимущество над Radeon HD 7970 слишком мало, чтобы удержать лидерство после выхода двухчиповой платы от конкурента. В подобных вычислительных задачах платы серии Radeon всё же более эффективны.
Feature Test 4: GPU ClothТест интересен тем, что рассчитывает физические взаимодействия (имитация ткани) при помощи видеочипа. Используется вершинная симуляция, при помощи комбинированной работы вершинного и геометрического шейдеров, с несколькими проходами. Используется stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров и скорость stream out.
Скорость рендеринга в этом тесте также зависит сразу от нескольких параметров, но основными факторами влияния являются производительность обработки геометрии, эффективность выполнения уже геометрических шейдеров и производительность блоков ROP. Из-за большого влияния геометрических блоков вполне логично, что видеокарты производства Nvidia, имеющие по несколько штук таких устройств, чувствуют себя в этом приложении очень неплохо, а SLI-система на базе двух плат Geforce GTX 680 стала лидером теста. Она справилась с работой явно лучше новой двухчиповой модели GTX 690.
Хотя сильнейшая одночиповая модель конкурента — Radeon HD 7970 — и усилила позиции компании, но даже она не смогла дотянуться до Geforce GTX 680. Но, учитывая лишь полуторакратное ускорение от двух GPU производства Nvidia в этом тесте, двухчиповый Radeon имеет все шансы догнать новинку калифорнийцев.
Feature Test 5: GPU ParticlesТест физической симуляции эффектов на базе систем частиц, рассчитываемых при помощи видеочипа. Также используется вершинная симуляция, каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот.
Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующие частицу. Но тест больше всего загружает шейдерные блоки вершинными расчётами, также тестируется stream out.
Результаты этого теста из пакета 3DMark Vantage похожи на те, что мы видели на предыдущей диаграмме, кроме того, что эффективность двухчипового рендеринга на Geforce GTX 690 несколько увеличилась. В этом тесте чипы с архитектурой Kepler немного уступают последнему представителю архитектуры Fermi из-за меньшего количества блоков ROP и филлрейта, но их скорости хватило, чтобы удержать позиции.
Если сравнивать Geforce GTX 690 с потенциальным конкурентом в виде будущего двухчипового решения серии Radeon HD 7000, то плата Nvidia явно останется сильнее, так как в синтетических тестах имитации тканей и частиц из тестового пакета 3DMark Vantage, в которых активно используются геометрические шейдеры, в борьбе Nvidia и AMD есть явный победитель — производитель видеокарт Geforce.
Feature Test 6: Perlin NoiseПоследний feature-тест пакета Vantage является математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Каждый цветовой канал использует собственную функцию шума для большей нагрузки на видеочип. Perlin noise — это стандартный алгоритм, часто применяемый в процедурном текстурировании, он использует много математических расчётов.
В чисто математическом тесте из пакета компании Futuremark, показывающем пиковую производительность видеочипов в предельных задачах, мы видим несколько иное распределение результатов, по сравнению с аналогичными тестами из нашего тестового пакета Rightmark. В этом случае производительность решений с диаграммы расходится с тем, что мы видели ранее в математических тестах из нашего тестового пакета.
Видно, что конкурирующая с Kepler архитектура GCN от AMD справляется с данной задачей просто отлично, и видеокарты от AMD всегда показывают лучшие результаты в случаях, когда выполняется простая и интенсивная математика. Топовое одночиповое решение компании AMD обгоняет соответствующий Geforce с большим запасом и нет никаких причин, чтобы помешать сделать это и будущей двухчиповой видеоплате.
Ну а пока что именно Geforce GTX 690 стала временным лидером в данном тесте. Как ни странно, но эффективность SLI-рендеринга в её случае оказалась довольно высокой, в отличие от скорости двух плат GTX 680 в SLI-конфигурации. И всё же, эффективность GK104 в этом тесте сравнительно низка. По какой-то причине платы на первых Kepler не могут показать теоретически возможные результаты, отставая от аналогичных решений конкурента. Вероятно, виновата несколько сниженная эффективность новой архитектуры при выполнении сложных шейдерных программ.
Direct3D 11: Производительность тесселяции
Чтобы протестировать новое решение компании Nvidia в задачах, использующих такие новые возможности DirectX 11, как тесселяция, мы воспользовались примерами из пакетов для разработчиков (SDK) и демонстрационными программами компаний Microsoft, Nvidia и AMD. К сожалению, в тестах из DX SDK, использующих вычислительные (Compute) шейдеры, обе двухчиповые конфигурации Nvidia работают некорректно, показывая одинаковый результат во всех условиях, что явно не соответствует действительности.
Поэтому в данном обзоре придётся обойтись без примера HDR-рендеринга с tone mapping из DirectX SDK, с постобработкой, использующей пиксельные и вычислительные шейдеры, а также расчётной задачи гравитации N тел (N-body) — симуляции динамической системы частиц, на которую воздействуют физические силы. Так что переходим сразу к тестам производительности в задачах тесселяции.
Аппаратная тесселяция считается одним из самых важным нововведений в Direct3D 11. Мы очень подробно рассматривали её в своей теоретической статье про Nvidia GF100. Тесселяцию уже довольно давно начали использовать в DX11-играх, таких как STALKER: Зов Припяти, DiRT 2, Aliens vs Predator, Metro 2033, Civilization V, Crysis 2, Battlefield 3 и других. В некоторых из них тесселяция используется для моделей персонажей, в других — для имитации реалистичной водной поверхности или ландшафта.
Существует несколько различных схем разбиения графических примитивов (тесселяции). Например, phong tessellation, PN triangles, Catmull-Clark subdivision. Так, схема разбиения PN Triangles используется в STALKER: Зов Припяти, а в Metro 2033 — Phong tessellation. Эти методы сравнительно быстро и просто внедряются в процесс разработки игр и существующие движки, поэтому и стали популярными.
Первым тестом тесселяции будет пример Detail Tessellation из ATI Radeon SDK. В нём реализована не только тесселяция, но и две разные техники попиксельной обработки: простое наложение карт нормалей и parallax occlusion mapping. Что ж, сравним DX11-решения AMD и Nvidia в различных условиях:

Мы уже видели ранее, что parallax occlusion mapping (средние столбики на диаграмме) на видеокартах обоих производителей выполняется менее эффективно, чем тесселяция (нижние столбики), а тесселяция не даёт падения производительности в разы. То есть, качественная имитация геометрии при помощи пиксельных расчётов обеспечивает даже меньшую производительность, чем реальная оттесселированная геометрия с displacement mapping.
В тесте простого бампмаппинга видно, что платы могут упираться в ПСП, а эффективность SLI зависит от рассматриваемой конфигурации. В случае двух плат Geforce GTX 680 она достаточно высока, а вот для GTX 690 явно ниже, чем должна быть по теории. В любом случае, судя по сравнительным результатам одночиповых плат AMD и Nvidia, будущий топовый Radeon на двух Tahiti будет победителем этого подтеста.
Второй подтест со сложными пиксельными расчётами показывает, что эффективность выполнения сложных математических вычислений у чипов архитектуры GCN гораздо выше, чем у плат Nvidia. Топовая одночиповая плата семейства Radeon HD 7000 показала отличный результат в тесте parallax mapping, обогнав Geforce GTX 680 более чем на 40%, а значит и в случае двухчиповых плат будет примерно такое же соотношение. Интересно, что в этом случае эффективность SLI выше уже у GTX 690, а пара GTX 680 в SLI работает явно неэффективно.
То же самое касается им самого интересного подтеста тесселяции, где новая модель чуть быстрее пары GTX 680. Печально другое — в этом тесте особого толка от SLI нет ни в одном случае — двухчиповые конфигурации лишь чуть быстрее одиночной GTX 680. Скорее всего виновато ещё и весьма умеренное разбиение треугольников в этом тесте, но и недостатки оптимизации драйверов для SLI очевидны.
Вторым тестом производительности тесселяции будет ещё один пример для 3D-разработчиков из ATI Radeon SDK — PN Triangles. Собственно, оба примера входят также и в состав DX SDK, так что мы уверены, что на их основе создают свой код игровые разработчики. Этот пример мы протестировали с различным коэффициентом разбиения (tessellation factor), чтобы понять, как сильно влияет его изменение на общую производительность.

В этом примере мы видим уже более правдоподобное сравнение геометрической мощи различных решений. Хотя все современные чипы вполне неплохо справляются даже с серьёзной геометрической нагрузкой, но графические процессоры Nvidia остаются непревзойдёнными по этому показателю.
Очень любопытно сравнение GTX 690 и пары GTX 680 в SLI. Такое впечатление, что во втором случае одна из видеокарт просто не работала в тяжёлых режимах, хотя в лёгких разница есть. Но нас сегодня больше интересует двухчиповая Geforce GTX 690, и вот как раз она даже в тяжёлых режимах показала приличную эффективность от SLI. В самом тяжёлом режиме разница между GTX 680 и GTX 690 приближается к двукратной.
Собственно, все чипы архитектур Fermi и Kepler весьма хороши в таких задачах, и хотя чипы архитектуры GCN от AMD в задачах тесселяции заметно увеличили скорость, это не позволило догнать чипы нового поколения Kepler. Так что даже когда выйдет двухчиповая модель на двух чипах из семейства Radeon HD 7000, то в синтетических и псевдоигровых тестах с применением тесселяции представленная сегодня двухчиповая плата Nvidia всё равно останется в лидерах.
Давайте рассмотрим результаты ещё одного теста — демонстрационной программы Nvidia Realistic Water Terrain, также известной как Island. В этой демке используется тесселяция и карты смещения (displacement mapping) для рендеринга реалистично выглядящей поверхности океана и ландшафта.

Island не является чисто синтетическим тестом для измерения исключительно геометрической производительности, он содержит и сложные пиксельные и вычислительные шейдеры в том числе, и такая нагрузка ближе к реальным играм, в которых используются сразу все блоки GPU, а не только геометрические, как в предыдущем бенчмарке.
Мы протестировали программу при четырёх разных коэффициентах тесселяции, в данном случае настройка называется Dynamic Tessellation LOD. И если при самом первом коэффициенте разбиения треугольников, когда скорость не ограничена производительностью геометрических блоков, видеокарты компании AMD очень сильны, то при усложнении работы платы компании Nvidia вырываются вперёд. При увеличении коэффициента разбиения и сложности сцены производительность любых плат Radeon падает заметно сильнее.
Сравнивать тут платы Nvidia и AMD очень просто — первые всегда быстрее в несколько раз. И никакие двухчиповые Radeon HD 7000 тут не помогут. Поэтому сравним платы семейства Geforce GTX 600, в их результатах есть интересные моменты. Во-первых, удивительно поведение SLI-системы из двух GTX 680. Двухчиповый рендеринг работает в самых лёгких условиях, но скорость быстро «просаживается» при увеличении нагрузки. В случае Geforce GTX 690 всё совсем не так, что снова наводит на мысли о программных оптимизациях, сделанных в драйверах специально для этой модели. По результатам тестирования она оказывается почти до двух раз быстрее, по сравнению с одночиповым аналогом на том же GPU — это отличный результат!
Итог тестов тесселяции неизменен который год — в условиях очень тяжёлой геометрической нагрузки чипы Nvidia заметно производительнее. И хотя AMD в семействе GCN в очередной раз улучшили геометрическую производительность и в реальных применениях их платы практически не уступают решениям Nvidia, то в синтетических они всё ещё проигрывают платам Geforce. Чип GK104 даже в одиночку отлично справляется с такими задачами, не говоря уже о двухчиповой плате Geforce GTX 690, которая ожидаемо стала лучшей в этой категории тестов.
Выводы по синтетическим тестам
Проведённые нами синтетические тесты новой модели видеокарты из серии Geforce GTX 600, основанной на двух графических процессорах GK104, а также результатам других моделей видеокарт производства обоих производителей дискретных видеочипов, позволяют сделать выводы о том, что новое решение Nvidia совершенно точно станет быстрейшим графическим решением на рынке как минимум до выхода двухчипового конкурента.
Собственно, каких-то свежих выводов в обзоре двухчиповой платы сделать невозможно, всё уже описано в базовом обзоре первой видеокарты на базе графического процессора GK104. Чип новой архитектуры Kepler имеет массу улучшений, направленных на увеличение энергоэффективности и ускорение математических расчётов, обработки геометрических данных и текстурирования. Он отлично подошёл и для двухчипового решения — наш набор синтетических тестов показал, что производительность этой видеокарты зачастую почти вдвое выше, чем у Geforce GTX 680 и близка к конфигурации с двумя такими платами, работающими в режиме SLI.
Есть у решения и недостатки, как и у любой другой двухчиповой видеокарты. О них мы уже неоднократно рассказывали, нет смысла повторяться. Плюс к этому, в некоторых тестах сложных пиксельных шейдеров, вроде Parallax Occlusion Mapping и Fur, эффективность новинки явно недостаточна, чтобы сражаться с ожидаемым в скором будущем топовым решением от конкурента, которое явно будет иметь в таких тестах определённое преимущество.
Кроме того, топовую видеоплату Geforce GTX 690 может подвести недостаток пропускной способности видеопамяти и объём видеопамяти в размере лишь 2 ГБ на каждый чип. Ведь у конкурента и ПСП будет явно выше, и объём видеопамяти будет в полтора раза больше. Пусть эти недостатки скажутся в малой части игр и настроек, но именно в тех, которые интересны энтузиастам, готовым выложить большие деньги. Можно предположить, что в некоторых играх эти ограничения не дадут новой плате Nvidia остаться лидером после выхода реального конкурента.
Ну а пока что мы можем отметить то, что в большинстве тестов именно новая плата от Nvidia стала быстрейшим на данный момент решением. Что стало возможным благодаря применению двух новых чипов GK104, отличающихся высокой производительностью и низким потреблением энергии, а также улучшению эффективности технологии многочипового рендеринга в некоторых из наших тестов. Видеокарта Geforce GTX 690 является отличным приобретением для энтузиастов, любящих всё самое лучшее и готовых закрыть глаза на его высокую цену. На сегодняшний день это наиболее производительная видеокарта на рынке. Без каких-либо оговорок.
Nvidia Geforce GTX 690 — Часть 3: производительность в игровых тестах →
Блок питания Platimax для
тестового стенда предоставлен
компанией Enermax |
Корпус ThermalTake 8430 для
тестового стенда предоставлен
компанией 3Logic |
Монитор Dell UltraSharp U3011 для
тестовых стендов предоставлен
компанией Юлмарт |

| 3 мая 2012 г. |
|
|