Nvidia Geforce GTX 480:
описание видеокарты и результаты синтетических тестов

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Nvidia Geforce GTX480: Часть 1: Теоретические сведения
По ссылке, указанной выше, мы познакомились теоретической частью и все поняли про потенциал нового продукта Nvidia. А теперь перейдем к практической части. А начинается она, как всегда, со знакомства, собственно, с самой видеокартой.
| Nvidia Geforce GTX 480 1536MB PCI-E | |
|---|---|
|

|
| Nvidia Geforce GTX 480 1536MB PCI-E | |
|---|---|
|
Карта имеет 1536 МБ памяти GDDR5 SDRAM,
размещенной в 12 микросхемах на лицевой сторонe PCB.
Микросхемы памяти Hynix (GDDR5). Микросхемы рассчитаны на максимальную частоту работы в 1000 (4000) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| Nvidia Geforce GTX 480 1536MB PCI-E | Reference card Nvidia Geforce GTX 285 |

|

|

|
|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| Nvidia Geforce GTX 480 1536MB PCI-E | Reference card Nvidia Geforce GTX 285 |

|

|
Мы сравнили новый продукт с последним предыдущим однопроцессорным рещением от Nvidia, имеющим 512-битный интерфейс обмена с памятью. Очевидно, что из-за того, что ныне шина уменьшена до 384 бит, а также из-за отсутствия отдельного блока NVIO, дизайн PCB несколько упрощен и стал дешевле. Однако в то же время усилен блок питания, поскольку ускоритель потребляет экстремально много — до 300 Вт, а это сравнимо с двухпроцессорным решением предыдущего поколения GTX 295.
Кстати, про ТВ-выход можно уже забывать. Все реже и реже встречаются современные видеокарты с этим интерфейсом. Считается, что HDMI должен вытеснить старые аналоговые решения. И мы видим, что новинка от Nvidia начисто лишена аналогого вывода на ТВ.
Подключение к аналоговым мониторам с d-Sub (VGA) производится через специальные адаптеры-переходники DVI-to-d-Sub. Также с серийными картами поставляются переходники DVI-to-HDMI (данные ускорители поддерживают полноценную передачу видео и звука на HDMI-приемник, поскольку обладают собственным звуковым кодеком), поэтому проблем с такими мониторами также не должно быть. К тому же продукт уже оснащен один разъемом HDMI. Следует напомнить, что комбинация из двух таких карт в режиме SLI позволяет выводить картинку игры сразу на ТРИ монитора, делая впечатления от игры более яркими, по аналогии с технологией AMD EyeFinity.
Максимальные разрешения и частоты:
- 240 Hz Max Refresh Rate
- 2048 x 1536 x 32bit x85Hz Max — по аналоговому интерфейсу
- 2560 x 1600 @ 60Hz Max — по цифровому интерфейсу (для DVI-гнезд с Dual-Link / HDMI)
По поводу HDTV. Одно из исследований также проведено, и с ним можно ознакомиться здесь.
Есть смысл сказать, что карта требуют дополнительного питания, причем двумя разъемами, один из которых 8-пиновый, а второй 6-пиновый. Если насчет последнего — нет проблем, так как уже все современные БП имеют такие «хвосты», то для запитки через 8-пиновый разъем требуется специальный переходник, который должен поставляться с серийными видеокартами.

Чип был получен на четвертой неделе этого года, то есть в конце января.
О системе охлаждения.
| Nvidia Geforce GTX 480 1536MB PCI-E | |
|---|---|
|
Принципиально кулер не отличается от предыдущих решений семейства GTX — цилиндрический вентилятор прогоняет воздух через радиатор и выводит тепло за пределы системного блока. Однако в виду чрезмерного энергопотребления нового продукта, а следовательно и нагрева, СО претерпела усовершенствования в части усиления теплоотвода с помощью тепловых трубок. Как мы видим, центральный радиатор с трубками охлаждает только ядро. Когда как микросхемы памяти охлаждаются прижимающейся к ним пластиной, находящейся под кожухом. Вероятно уже исчерпаны возможности поиска СО такого типа, чтобы могли справиться с сильно греющимся ядром без шума. Поэтому должны сказать, что СО получилась шумная. Даже в 2D режиме кулер работает на 44% от максимума, хотя раньше такой показатель был где-то 20-25%. Шум начинается после 50%. Поэтому кулер работает на грани слышимости шума, и это в простое! Что говорить про нагрузку, когда СО начинает постепенно усиливать обороты вращения турбины, доводя в среднем до 70-80% при работе карты в трехмерном режиме.
|

|

|
|
Мы провели исследование температурного режима с помощью утилиты EVGA Precision (автор А. Николайчук AKA Unwinder) и получили следующие результаты:
Nvidia Geforce GTX 480 1536MB PCI-E
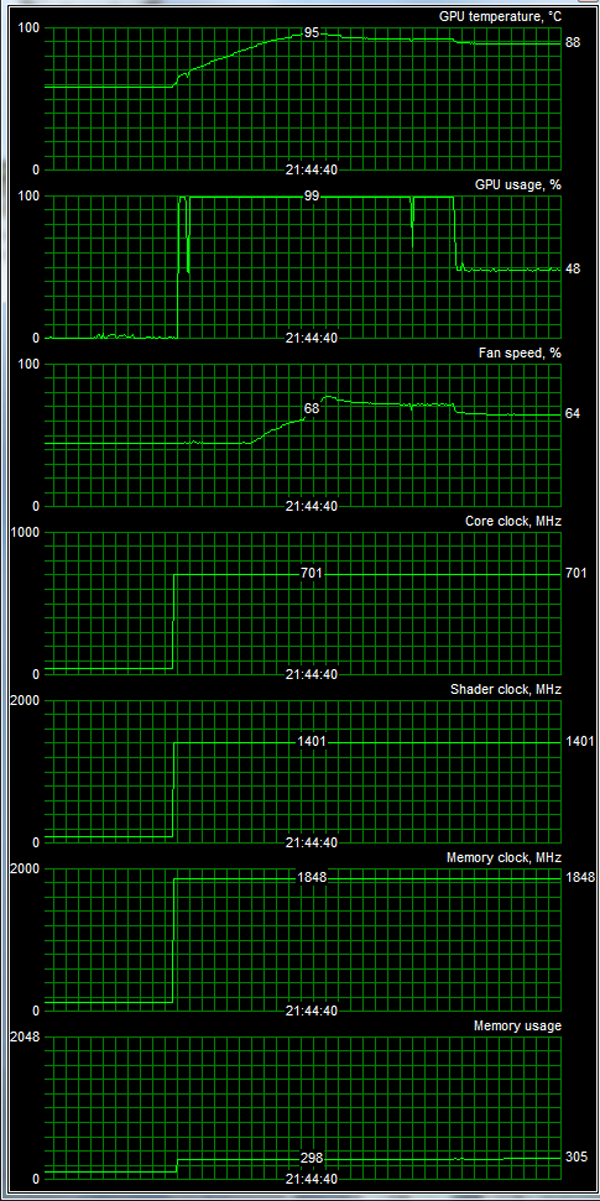
И это неудивительно, ведь нагрев ядра достигает 95 градусов, и даже такой высокий показатель достигается ценой очень шумной работы СО. Так что любителям самой передовой и быстрой трехмерной игровой графики придется забыть — что такое тишина, если гонять игры или какие-либо тесты. Даже в 2D при нагрузке карты всяким сложным контентом (типа флеша или видео) кулер уже весьма слышим.
Комплектация.
Это референсный продукт, поэтому комплектации и упаковки нет.
Теперь перейдем к тестам. Вначале покажем конфигурацию тестового стенда.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core I7 CPU 920 (Socket 1366 LGA)
- процессор Intel Core I7 CPU 920 (2667 MHz);
- системная плата Asus P6T Deluxe на чипсете Intel X58;
- оперативная память 3 GB DDR3 SDRAM Corsair 1066MHz;
- жесткий диск WD Caviar SE WD1600JD 160GB SATA;
- блок питания Tagan TG900-BZ 900W.
- операционная система Windows 7 32bit; DirectX 11;
- монитор
Dell 3007WFP (30"); - драйверы ATI версии CATALYST 10.3; Nvidia версии 197.17.
VSync отключен.
Синтетические тесты
Используемые нами пакеты синтетических тестов можно скачать здесь:
- D3D RightMark Beta 4 (1050) с описанием на сайте http://3d.rightmark.org.
- D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3 — тесты пиксельных шейдеров версий 2.0 и 3.0 ссылка.
- RightMark3D 2.0 с кратким описанием: Vista без SP1, Vista c SP1.
Для работы RightMark3D 2.0 требуется установленный пакет MS Visual Studio 2005 runtime, а также последнее обновление DirectX runtime.
Так как у нас нет своих синтетических DirectX 11 тестов, то нам пришлось воспользоваться примерами из различных пакетов SDK и демонстрационными программами. Во-первых, это HDRToneMappingCS11.exe и NBodyGravityCS11.exe из комплекта DirectX SDK (February 2010).
Также мы взяли по два примера от обоих производителей: Nvidia и AMD, чтобы ни от кого не было никаких претензий в предвзятости. Из ATI Radeon SDK были взяты примеры DetailTessellation11.exe и PNTriangles11.exe (они есть и в DX SDK, кстати). Ну а со стороны Nvidia были представлены две демонстрационные программы: Realistic Character Hair и Realistic Water Terrain, которые скоро должны стать доступными для скачивания на сайте компании.
Синтетические тесты проводились на следующих видеокартах:
- Geforce GTX 480 со стандартными параметрами (далее GTX 480)
- Geforce GTX 295 со стандартными параметрами (далее GTX 295)
- Geforce GTX 285 со стандартными параметрами (далее GTX 285)
- Radeon HD 5970 со стандартными параметрами (далее HD 5970)
- Radeon HD 5870 со стандартными параметрами (далее HD 5870)
Для сравнения результатов новой модели Geforce GTX 480 были выбраны именно эти видеокарты по следующим причинам: Radeon HD 5870 и HD 5970 являются наиболее производительными одночиповой и двухчиповой моделями от конкурирующей компании AMD, с наиболее близкими к GTX 480 ценами. С решениями Nvidia всё даже ещё проще: Geforce GTX 285 — наиболее производительная одночиповая карта на GPU прошлого поколения, по ней мы будем судить об архитектурных изменениях, а GTX 295 — самая мощная до выхода новых решений двухчиповая плата от Nvidia.
Direct3D 9: тесты Pixel Filling
В тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:
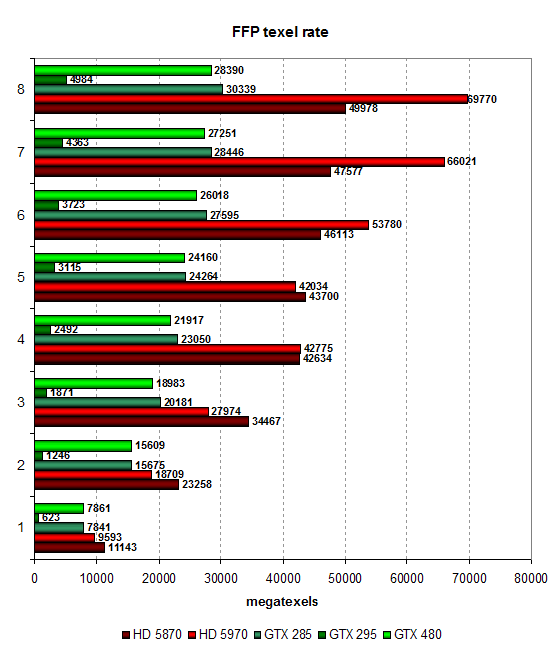
Наш тест немного устарел, и видеокарты в нём не достигают теоретически возможных значений, но пиковую скорость текстурирования видеокарт относительно друг друга он всё же показывает верно. Как обычно, результаты синтетики не дотягивают до пиковых значений, по ней получается, что GTX 480 выбирает до 40 текселей за один такт из 32-битных текстур при билинейной фильтрации в этом тесте, что в полтора раза ниже теоретической цифры в 60 отфильтрованных текселей.
Этого не хватает, чтобы достать хотя бы до GTX 285, выбирающей текстурные данные на 5-7% быстрее. Не говоря уже о том, чтобы догнать конкурирующий HD 5870, более чем в полтора раза производительный, почти во всех режимах, если судить по нашей DX9 синтетике. Двухчиповая карта Nvidia явно пала жертвой программных проблем, а вот HD 5970 ещё более производительна, по сравнению с HD 5870.
Разница между GTX 480 и GTX 285 почти всегда одинаковая, кроме случаев с небольшим количеством текстур, где больше сказывается ограничение в ПСП. И HD 5870 в этих тестах не так уж далеко впереди. А вот при 4-8 текстурах разница становится большей, что намекает о недостатке скорости текстурирования GF100 для того, чтобы всегда быть впереди конкурента в устаревших игровых приложениях. Посмотрим на эти же результаты в тесте филлрейта:
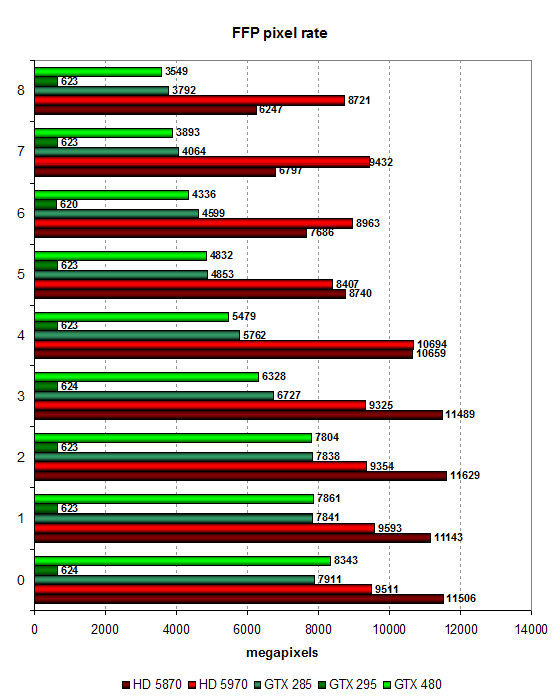
Второй синтетический тест показывает скорость заполнения, и в нём мы видим ту же самую ситуацию, но уже с учетом количества записанных в буфер кадра пикселей. Максимальный результат остаётся за решениями AMD, имеющими большее количество TMU и более эффективными по достижению высокого КПД в нашем синтетическом тесте. В случаях с 0-3 накладываемыми текстурами разница между решениями значительно меньше, в таких режимах производительность ограничена ПСП, прежде всего.
Direct3D 9: тесты Pixel Shaders
Первая группа пиксельных шейдеров, которую мы рассматриваем, является очень простой для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0, встречающихся в старых играх.
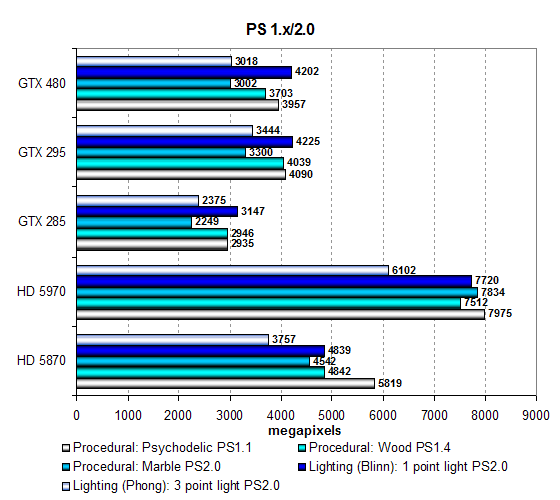
Тесты очень и очень просты для современных архитектур и показывают не все возможности современных GPU, но интересны для оценки баланса между текстурными выборками и математическими вычислениями, особенно при смене архитектур, которая и произошла в этот раз у Nvidia.
В данных тестах производительность ограничена в основном скоростью текстурных модулей, но уже с учётом эффективности блоков и кэширования текстурных данных в реальных задачах. Посмотрим, как сказались изменения в архитектуре, по сравнению с GT200? Хорошо видно, что архитектура изменилась, и новая карта GTX 480 показывает результат выше, чем одночиповая карта на основе предыдущей архитектуры. Причём в большинстве тестов GTX 480 догоняет двухчиповую GTX 295, что уже неплохо само по себе.
Пропускная способность памяти в этих тестах лишь немного ограничивает новые решения, и скорость зависит от текстурирования, что не позволяет карте на базе GF100 показать результаты даже на уровне Radeon HD 5870, не говоря уже о двухчиповом решении AMD. Видеоплаты на чипах производства Nvidia в этом наборе тестов явно отстают, что является тревожным звоночком для других наших тестов, где важна скорость текстурирования. Посмотрим на результаты несколько более сложных пиксельных программ промежуточных версий:
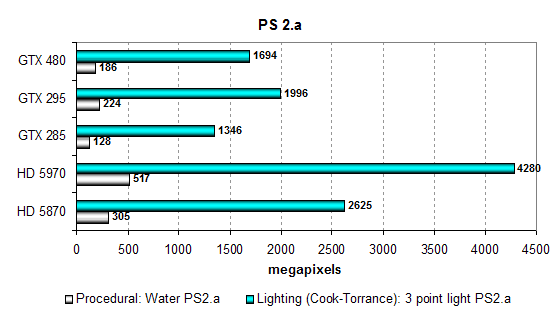
В тестах пиксельных шейдеров версии 2.a всё даже ещё хуже, если сравнивать со скоростью конкурентов. В сильно зависящем от скорости текстурирования тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, и карты всегда располагаются по скорости текстурирования, но с поправкой на разную эффективность использования TMU.
Карты на основе чипов RV870 показывают максимальные результаты, ну а скорость GTX 480 оказалась где-то между одночиповой и двухчиповой моделями на GPU предыдущей архитектуры. Слабовато, конечно, но хотя бы быстрее GTX 285, что говорит о более эффективном использовании имеющихся TMU.
Результаты второго теста почти такие же, хотя он более интенсивен вычислительно, и всегда лучше подходил для архитектуры AMD, обладающей большим количеством вычислительных блоков. Современные решения AMD тут далеко впереди, особенно двухчиповый вариант.
GTX 480 обгоняет GTX 285 лишь на 25%, да и отстаёт от двухчиповой модели почти на столько же. Это явно указывает на ограничение производительности GTX 480 из-за малого количества TMU, по сравнению с архитектурой нового поколения. Подтверждаются наши опасения в виде основного недостатка архитектуры GF100.
Direct3D 9: тесты пиксельных шейдеров Pixel Shaders 2.0
Эти тесты пиксельных шейдеров DirectX 9 сложнее предыдущих, они близки к тому, что мы сейчас видим в мультиплатформенных играх, и делятся на две категории. Начнем с более простых шейдеров версии 2.0:
- Parallax Mapping — знакомый по большинству современных игр метод наложения текстур, подробно описанный в статье Современная терминология 3D графики.
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами.
Существует два варианта этих шейдеров: с ориентацией на математические вычисления, и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:
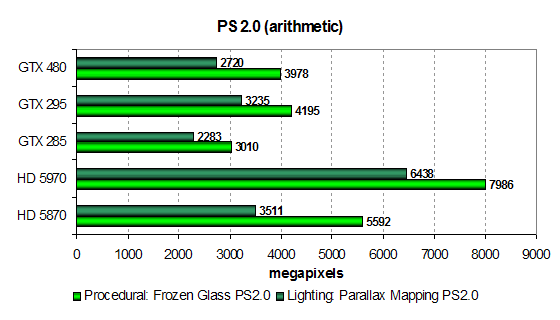
Это универсальные тесты, зависящие и от скорости блоков ALU и от скорости текстурирования, в них важен общий баланс чипа. Видно, что производительность видеокарт в тесте «Frozen Glass» ограничена не только математикой, но и скоростью текстурных выборок. Ситуация в нём схожа с той, что мы видели чуть выше в «Cook-Torrance», но новая GTX 480 в этот раз гораздо ближе к двухчиповому GTX 295 на основе GPU старой архитектуры Nvidia. С другой стороны, даже одночиповый HD 5870 всё равно далеко впереди.
Во втором тесте «Parallax Mapping» результаты снова очень похожи на предыдущие. Впрочем, в этот раз HD 5870 оторвался от карт Nvidia не так сильно, как в первом тесте. Посмотрим, что будет дальше, но игры обычно многограннее, чем синтетика, и не упираются так явно в одно лишь текстурирование. Но всё-таки для таких устаревших задач количество текстурных модулей в GF100 явно недостаточное. Рассмотрим эти же тесты в модификации с предпочтением выборок из текстур математическим вычислениям, чтобы убедиться в наших промежуточных выводах окончательно:
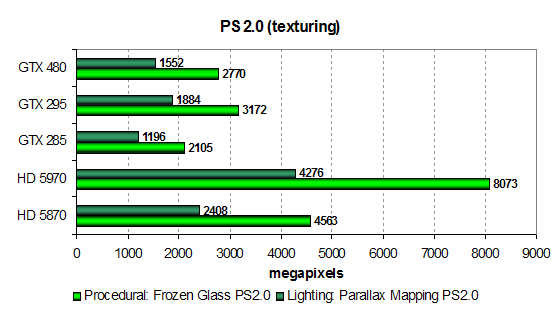
Картинка в чём-то схожая, но с текстурными выборками карты AMD справляются явно лучше, особенно двухчиповый HD 5970 тут хорош! Сегодняшний герой в виде GTX 480 снова показывает средний между GTX 285 и GTX 295 результат, так как тут ещё более явно виден упор производительности в скорость текстурных блоков, и их количество у GF100 для новой мощной графической архитектуры всё же явно недостаточное.
Но то были устаревшие задачи, с упором в текстурирование, да и не особенно сложные. А сейчас мы рассмотрим результаты ещё двух тестов пиксельных шейдеров — версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9, которые намного показательнее с точки зрения современных эксклюзивных игр на ПК. Тесты отличаются тем, что сильнее нагружают и ALU, и текстурные модули, обе шейдерные программы сложные и длинные, включают большое количество ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, также описанная в статье Современная терминология 3D графики.
- Fur — процедурный шейдер, визуализирующий мех.
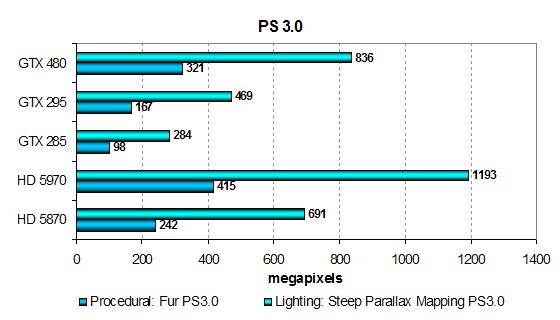
Ну наконец-то! Вот тут совсем другое дело. Оба PS 3.0 теста очень сложные, совсем не зависят от ПСП и текстурирования, они чисто математические, но с большим количеством переходов и ветвлений, с которыми, похоже, отлично справляется новая архитектура GF100.
В этих тестах GTX 480 показывает свою реальную силу и обгоняет все решения, кроме нового двухчипового от конкурента. Мало того, GTX 295 в этих сложнейших тестах чуть ли не вдвое медленнее, а GTX 285 вообще втрое! На результаты явно повлияли архитектурные изменения нового графического процессора, направленные на повышение эффективности вычислений.
Итак, с новой архитектурой GF100 мы отмечаем очень большой прирост производительности в сложнейших PS 3.0 тестах. В которых важнее всего не пиковая математическая мощь, которая имеется у решений AMD, а эффективность выполнения сложных шейдерных программ с переходами и ветвлениями. Ну и удвоенная математическая мощь, по сравнению с GT200, тоже сказалась. Очень хороший результат, ведь обогнать решение архитектуры AMD, имеющей большее количество исполнительных блоков ALU, это дорогого стоит.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)
Во вторую версию RightMark3D вошли два знакомых PS 3.0 теста под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсемплинга, что дополнительно увеличивает нагрузку на видеочипы.
Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами, при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере.
Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40-80, включение «шейдерного» суперсемплинга — до 60-120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот.
Проверим сначала режимы без включенного суперсемплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым.
Производительность в этом тесте зависит и от количества и эффективности блоков TMU, и от филлрейта с ПСП в меньшей степени. Результаты в «High» получаются примерно в полтора раза ниже, чем в «Low», как и должно быть по теории. В Direct3D 10 тестах процедурной визуализации меха с большим количеством текстурных выборок решения Nvidia традиционно сильны, но последняя архитектура AMD уже подобралась к ним вплотную.
GTX 480 почти на треть быстрее GTX 285, но не дотягивает до GTX 295, что мы видели и в DX9 тестах. Это говорит скорее о влиянии филлрейта и ПСП, где новое решение Nvidia имеет преимущество над одночиповой картой предыдущей серии. Примерно так же расположен по скорости GF100 и относительно двух карт на основе RV870. Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсемплингом, увеличивающим работу в четыре раза, возможно в такой ситуации что-то изменится, и ПСП с филлрейтом будут влиять меньше:
Включение суперсемплинга теоретически увеличивает нагрузку в четыре раза, и в этот раз Geforce GTX 480 сдаёт позиции, как ни странно. А обе Radeon становятся немного сильнее. Разница между GTX 480 и GTX 285 совсем небольшая, что говорит скорее всего об упоре всё же в текстурирование. Или ПСП, которая у GTX 480 увеличилась по отношению к GTX 285 не слишком сильно. Влияния производительности ALU и эффективного выполнения ветвлений в этом тесте явно не видать.
Второй тест, измеряющий производительность выполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением, число выборок возрастает в два раза, а суперсемплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсемплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше, по сравнению с простым режимом. Проверяем сначала простые варианты без суперсемплинга:
Данный тест интереснее с практической точки зрения, так как разновидности parallax mapping давно применяются в играх, а тяжелые варианты, вроде нашего steep parallax mapping используются во многих проектах, например, в Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсемплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип примерно в два раза, такой режим называется «High».
Диаграмма почти полностью повторяет предыдущую, показаны близкие результаты даже по абсолютным цифрам. В обновленном D3D10 варианте теста без суперсемплинга, GTX 480 чуть лучше справляется с поставленной задачей, чем одночиповый топ предыдущего поколения, но отстаёт от двухчиповой карты GTX 295. Также, новая видеокарта на GF100 немного обгоняет и своего соперника HD 5870, двухчиповый вариант которого становится победителем в абсолютном зачёте.
Посмотрим, что изменит включение суперсемплинга, он всегда вызывает несколько большее падение скорости на картах Nvidia.
При включении суперсемплинга и самозатенения задача получается более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая большое падение производительности. Разница между скоростными показателями несколько видеокарт изменилась, включение суперсемплинга сказывается как и в предыдущем случае — карты производства AMD явно улучшили свои показатели относительно решения Nvidia.
Обе двухчиповые карты остаются впереди GTX 480, но в этот раз новое решение немного проигрывает и своему прямому конкуренту HD 5870. Похоже, что так оно и будет в игровых тестах — где-то GTX 480 окажется далеко впереди, а где-то — немного отстанет. Впрочем, карта на GF100 хотя бы обгоняет свою предшественницу, в лёгком режиме заметно, а в тяжёлом — совсем чуть-чуть. Архитектурные изменения в новом GPU компании Nvidia не дали особенного преимущества в этих тестах, к сожалению.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (вычисления)
Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере.
Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos.
А вот в математических тестах мы должны увидеть большие изменения, так как графический процессор GF100 отличается удвоенной мощью ALU, по отношению к GT200. Впрочем, теоретически решения AMD в наших синтетических тестах должны быть ещё быстрее, так как в вычислительно сложных задачах современная архитектура AMD имеет явное преимущество перед конкурентами от Nvidia. Подтверждается положение и в этот раз, новая плата GTX 480 хотя и сократила разрыв между картами Nvidia и AMD, но он остался более чем полуторакратным.
А вот сравнение с GTX 285 и GTX 295 получилось интересное. Ни двукратной разницы с предыдущей одночиповой, ни обгона старой двухчиповой карты предыдущего поколения у Nvidia в этот раз не получилось. Подтверждается вывод о том, что данный тест не полностью зависит от скорости ALU, но и на разницу в ПСП результаты не списать. У GF100 получилось лишь 38% прироста по сравнению с GTX 285, что весьма странно и очень-очень мало, как нам кажется.
Рассмотрим второй тест шейдерных вычислений, который носит название Fire. Он тяжелее для ALU, и текстурная выборка в нём только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки:
Во втором тесте скорость рендеринга ограничена почти исключительно производительностью шейдерных блоков, но всё же разница между GTX 285 и GTX 480 слишком мала — всего 58%, хотя теоретически должно быть ближе к двукратной разнице. Но новое решение хотя бы догнало двухчиповую GTX 295, в отличие от предыдущего теста. Впрочем, конкуренты в лице Radeon HD 5870 и уж тем более HD 5970 в этом тесте показывают скорость ещё значительно выше.
Подводим итог по математическим D3D10 тестам. Все видеокарты Nvidia далеко позади, даже новый GF100 медленнее конкурента в пиковых синтетических задачах почти вдвое! И всё это несмотря на то, что GTX 480 быстрее одночипового варианта GTX 285 теоретически почти вдвое. Реальность показывает гораздо меньшую цифру, и даже приблизиться к картам AMD по простым математическим тестам Nvidia не удалось.
В общем, итог по предельным математическим вычислениям остаётся неизменным и в этот раз — явное и неоспоримое преимущество решений компании AMD, которое не изменил выход линейки GTX 400. Посмотрим на результаты тестирования геометрических шейдеров — уж там-то новое решение должно быть сильно, как никакое другое.
Direct3D 10: тесты геометрических шейдеров
В пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующих частицу. Аналогичные алгоритмы должны получить широкое использование в будущих DirectX 10 играх.
Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково.
Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности:
Соотношение скоростей при разной геометрической сложности сцен примерно одинаковое у всех решений, производительность соответствует количеству точек, с каждым шагом падение FPS составляет около двух раз. Задача для современных видеокарт не особенно сложная, а производительность в целом ограничена скоростью обработки геометрии и не упирается в пропускную способность памяти.
И вот тут новый графический процессор показывает свою настоящую силу. Geforce GTX 480 во всех режимах показывает близкие к двухчиповому решению конкурента результаты, в полтора раза обгоняя и HD 5870 и двухчиповую карту на базе GT200. Отличный результат! Как и ожидалось, выполнение геометрических шейдеров у GF100 весьма и весьма эффективное, примерно в 2,5 раза быстрее, чем может GT200. Посмотрим, изменится ли ситуация при переносе части вычислений в геометрический шейдер:
Нет, цифры при изменении нагрузки в этом тесте почти не изменились. Все карты в этом тесте не замечают изменения параметра GS load, отвечающего за перенос части вычислений в геометрический шейдер, и показывают аналогичные предыдущей диаграмме результаты. Смотрим, что изменится в следующем тесте, который предполагает большую нагрузку именно на геометрические шейдеры.
«Hyperlight» — это второй тест геометрических шейдеров, демонстрирующий использование сразу нескольких техник: instancing, stream output, buffer load. В нем используется динамическое создание геометрии при помощи отрисовки в два буфера, а также новая возможность Direct3D 10 — stream output. Первый шейдер генерирует направление лучей, скорость и направление их роста, эти данные помещаются в буфер, который используется вторым шейдером для отрисовки. По каждой точке луча строятся 14 вершин по кругу, всего до миллиона выходных точек.
Новый тип шейдерных программ используется для генерации «лучей», а с параметром «GS load», выставленном в «Heavy» — ещё и для их отрисовки. То есть, в режиме «Balanced» геометрические шейдеры используются только для создания и «роста» лучей, вывод осуществляется при помощи «instancing», а в режиме «Heavy» выводом также занимается геометрический шейдер. Сначала рассматриваем лёгкий режим:
Обе двухчиповые конфигурации показали себя в этом тесте как обычно, что Geforce GTX 295, что Radeon HD 5970. Видимо, с методом многочипового рендеринга AFR этот тест несовместим вообще. В остальном относительные результаты в разных режимах соответствуют нагрузке: во всех случаях производительность неплохо масштабируется и близка к теоретическим параметрам, по которым каждый следующий уровень «Polygon count» должен быть менее чем в два раза медленней.
В этом тесте производительность нового Geforce GTX 480 лишь немного превосходит скорость Radeon HD 5870 в сложном режиме, зато в лёгких разница заметна больше. Сравнивать GTX 480 с GTX 285 на основе GPU предыдущего поколения вообще смешно, новый видеочип оказывается быстрее примерно в два раза.
Цифры должны измениться на следующей диаграмме, в тесте с более активным использованием геометрических шейдеров. Также будет интересно сравнить друг с другом результаты, полученные в «Balanced» и «Heavy» режимах.
Настало время ещё раз удивиться возможностям GF100 по обработке геометрии и скорости исполнения геометрических шейдеров. Вот это — как раз тот результат, ради которого были сделаны глобальные изменения в графическом конвейере GF100. Хотя исполнение геометрических шейдеров было неплохо улучшено и в GT200 и в RV870, но GF100 просто рвёт их на куски в этой задаче.
Новое решение GTX 480 в этом тесте почти вдвое быстрее, чем Radeon HD 5870 и до 2,75 раз быстрее своей одночиповой предшественницы GTX 285. Инженеры компании Nvidia постарались повысить эффективность предыдущей архитектуры по обработке геометрии, и это им явно удалось. Все предыдущие решения просто не способны на столь же эффективное исполнение геометрических шейдеров. Что же будет в тестах тесселяции, которые должны показать ещё большую разницу, исходя из теории? Но не будем заглядывать слишком далеко вперёд.
Direct3D 10: скорость выборки текстур из вершинных шейдеров
В тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути и соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет.
Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»:
Предыдущие исследования показали, что на результаты этого теста влияет и скорость текстурирования и пропускная способность памяти. Но разница между решениями совсем небольшая. GTX 480 показывает схожий с двухчиповой GTX 295 результат, немного опережает HD 5870, но совсем немного уступает во всех режимах наиболее производительной в этом тесте карте Radeon HD 5970. Результаты явно странные... Посмотрим на производительность в этом же тесте с увеличенным количеством текстурных выборок:
Взаимное расположение карт на диаграмме немного изменилось, это видно по немного ухудшившимся показателям почти всех карт. Кроме рассматриваемой сегодня GTX 480. Она почти не потеряла в производительности относительно этого же теста в лёгких условиях. Вот что значит — увеличенная эффективность текстурных модулей и особенно подсистемы кэширования. Теперь новая карта на GF100 быстрее всех при среднем и большом количестве полигонов и наравне с двухчиповыми картами в наиболее простом режиме.
Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту.
Интересно, что результаты в тесте «Waves» не похожи на те, что мы видели на предыдущих диаграммах. Преимущество продукции AMD несколько усилилось, и теперь GTX 480 показывает схожую с HD 5870 и Geforce GTX 295 производительность, немного проигрывая конкуренту в тяжёлом режиме. Предыдущее топовое решение Nvidia на одном чипе осталось позади, новая модель семейства Geforce GTX 400 опережает её, хоть и не в разы. Рассмотрим второй вариант этого же теста:
Изменений снова почти нет, хотя с ростом сложности условий результаты новейшего графического процессора Nvidia во втором тесте вершинных выборок стали чуть лучше, относительно скорости видеокарт AMD. Перевес над HD 5870 хоть и небольшой, но есть, да и с Geforce GTX 295 новая одночиповая карта справилась, за исключением самого лёгкого режима.
3DMark Vantage: Feature тесты
В данный обзор мы снова решили включить синтетические тесты из пакета 3DMark Vantage. Пакет хоть уже и не новый, но его feature тесты обладают поддержкой D3D10 и интересны уже тем, что отличаются от наших. При анализе результатов нового решения Nvidia в этом пакете мы сможем сделать какие-то новые и полезные выводы, ускользнувшие от нас в тестах семейства RightMark.
Feature Test 2: Color FillТест скорости заполнения. Используется очень простой пиксельный шейдер, не ограничивающий производительность. Интерполированное значение цвета записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется 16-битный внеэкранный буфер формата FP16, наиболее часто используемый в играх, применяющих HDR-рендеринг, поэтому такой тест является вполне своевременным.
Показатели производительности в этом тесте не соответствуют тому, что мы видели в своих аналогичных тестах, даже с учетом разных форматов: у нас используется целочисленный буфер с 8-бит на компоненту, а в тесте Vantage — 16-бит с плавающей точкой. Цифры Vantage скорее показывают не производительность блоков ROP, а примерную величину пропускной способности памяти. Для двухчиповых карт всё несколько сложнее, GTX 295 показывает меньшую цифру, чем должна.
Результаты теста примерно соответствуют теоретическим цифрам, и зависят от ширины шины памяти, её типа и частоты. GTX 285 показывает неплохой результат из-за применения 512-битной памяти, а GTX 480 не слишком сильно её опережает из-за того, что GDDR5 память работает на не особенно высокой частоте, и ширина шины памяти соответствует 384-бит. Ну и Radeon HD 5870 тоже где-то там недалеко, хотя у неё лишь 256-битная шина памяти, зато GDDR5 довольно быстрая.
Несмотря на использование GDDR5 памяти с большей ПСП, новое решение Nvidia вместе с HD 5870 показывает результат лишь немного выше уровня GTX 285, имеющего 512-битную шину и GDDR3 память. Это может служить потенциальным ограничением производительности в случае использования буферов рендеринга в FP16 формате, что массово наблюдается в современных играх.
Feature Test 3: Parallax Occlusion Mapping
Один из самых интересных feature тестов, так как подобная техника уже используется в играх. В нём рисуется один четырехугольник (точнее, два треугольника), с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются довольно ресурсоёмкие операции по трассировке лучей и карта глубины большого разрешения. Также эта поверхность затеняется при помощи тяжёлого алгоритма Strauss. Это тест очень сложного и тяжелого для видеочипа пиксельного шейдера, содержащего многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss.
К сожалению, GTX 480 показывает посредственный результат в этом тесте, лишь на 23% быстрее, чем предыдущее решение на одном чипе — GTX 285. Представленная сегодня видеоплата Nvidia отстаёт и от двухчиповой GTX 295, и от главного конкурента Radeon HD 5870, а двухчиповый HD 5970 вообще остался недосягаемым.
Не очень понятно, что повлияло так негативно на результаты этого теста. Возможно, виновата низкая скорость текстурных выборок, которые активно используются в тесте, так как эффективность ветвлений у GF100 довольно высока, что доказали наши тесты пиксельных шейдеров третьей версии. Решения Nvidia всегда были эффективны в этом тесте, но HD 5870 обгоняет даже новую GTX 480. Может быть, в тестах физических симуляций GF100 покажет себя с лучшей стороны?
Feature Test 4: GPU Cloth
Тест интересен тем, что рассчитывает физические взаимодействия (имитация ткани) при помощи видеочипа. Используется вершинная симуляция, при помощи комбинированной работы вершинного и геометрического шейдеров, с несколькими проходами. Используется stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров и скорость stream out.
GF100 в этом тесте почти вдвое производительнее предыдущего решения, что неплохо соответствует двукратно усиленной шейдерной мощи нового чипа. Преимущество над конкурирующим решением Radeon HD 5870 столь же впечатляющее. В общем, за нашим сегодняшним героем можно закрепить статус лидера по выполнению геометрических шейдеров и скорости обработки геометрии в целом, как и должно быть по теории.
Feature Test 5: GPU Particles
Тест физической симуляции эффектов на базе систем частиц, рассчитываемых при помощи видеочипа. Также используется вершинная симуляция, каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот. Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующих частицу. Но тест больше всего загружает шейдерные блоки вершинными расчётами, также тестируется stream out.
Налицо даже ещё более сильный результат. В синтетических тестах имитации тканей и частиц пакета Vantage, где используются геометрические шейдеры, новый чип GF100 просто оставляет в пыли всех своих соперников. В этот раз он опережает предыдущий графический процессор Nvidia почти втрое, а конкурирующий Radeon HD 5870 показывает в тесте имитации частиц примерно вдвое худший результат.
Результаты мультичипов снова такие же — и у карты AMD, и у Nvidia явно не работает метод мультичипового рендеринга, так как результаты расчётов текущего кадра используются в следующем, что не даёт начать его рассчитывать до того, как закончится рендеринг текущего. В этом — очевидная слабость двухчиповых карт, они не могут работать эффективно, когда в кадре используются данные из предыдущего.
Feature Test 6: Perlin Noise
Последний feature тест пакета Vantage является математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Каждый цветовой канал использует собственную функцию шума для большей нагрузки на видеочип. Perlin noise — это стандартный алгоритм, часто используемый в процедурном текстурировании, он использует очень много математических расчётов.
Так, в этом математическом тесте GTX 480 на базе нового GF100 наконец-то обогнал GTX 285 ровно вдвое, что соответствует теории. А вот от HD 5870 отставание нового решения оказалось слишком большим — 1,7 раза. Это мы ещё двухчиповый HD 5970 не рассматриваем...
В общем, видеокарты AMD закономерно всухую выигрывают у конкурентов от Nvidia этот тест, но новое решение на основе графического процессора Nvidia GF100 всё-таки смогло к нему приблизиться. Напомним, что этот математический тест довольно прямолинеен и призван показать производительность, близкую к пиковой теоретической. В более сложных вычислительных тестах, таких как физические расчёты, получается несколько иная картина. А вот простая, но интенсивная математика, выполняется на картах AMD значительно быстрее.
Direct3D 11: вычислительные и геометрические шейдеры
Чтобы протестировать новые решения компаний Nvidia и AMD в задачах, использующих возможности DirectX 11, мы воспользовались примерами из пакетов для разработчиков (SDK) от Microsoft, AMD и Nvidia, а также некоторыми демонстрационными программами этих компаний.
Сначала рассмотрим тесты, использующие новый тип шейдеров — вычислительные (Compute). Их появление — одно из наиболее важных нововведений в последних версиях DX API, они используются для различных задач: постобработки, симуляций и т.п. В первом тесте показан пример HDR рендеринга с tone mapping из DirectX SDK с постобработкой, использующей пиксельные или вычислительные шейдеры.

Нужно признать явную победу одночипового решения AMD над новой видеокартой Nvidia Geforce GTX 480 в этом тесте. Анонсированная сегодня плата на новом чипе GF100 отстаёт от конкурирующего Radeon HD 5870 в обоих режимах, и с использованием пиксельного, и с использованием вычислительного шейдеров. Причём отставание довольно ощутимое — до полутора раз. У двухчипового HD 5970 в этом тесте работает только один GPU, поэтому его результат даже ниже, чем у HD 5870.
Второй тест вычислительных шейдеров также взят из DirectX SDK от Microsoft, в нём показана расчётная задача гравитации N тел (N-body) — симуляция динамической системы частиц, на которую воздействуют физические силы, такие как гравитация.
И в этом вычислительном тесте новое решение Nvidia снова проигрывает ближайшему конкуренту в лице Radeon HD 5870. В данном случае — около 25%, что также довольно много. Двухчиповый HD 5970 в очередной раз не может показать свои возможности, и ограничивается работой одного из двух установленных на плате GPU.
Следующий тест — демонстрационная программа от Nvidia под названием Realistic Character Hair. В ней используется не чисто синтетический код вычислительных или геометрических шейдеров, а комплекс геометрических и вычислительных шейдеров и тесселяции, поэтому он несколько ближе к реальным задачам, чем чистая синтетика первых двух тестов.

А вот в этом тесте новый графический процессор Nvidia показывает отличный результат, значительно опережая одночиповый Radeon HD 5870 и двухчиповый HD 5970, второй GPU которого снова не сработал. При этом интересна не только сама по себе разница в производительности между одночиповыми картами до 1,5-1,8 раз, но и разное их поведение при включении аппаратной тесселяции.
Новая видеокарта Geforce GTX 480 на базе чипа GF100 в таком случае ускоряется при включении тесселяции на 15%, а решение AMD на основе RV870 замедляется почти на 5%. Иными словами, в данном случае тесселяция для решения Nvidia выгодна, а для AMD — нет. Видимо, сказывается различная организация геометрического конвейера, к рассмотрению производительности которого мы сейчас и переходим.
Direct3D 11: производительность тесселяции
Самым важным нововведением в Direct3D 11 по праву считается аппаратная тесселяция. Мы очень подробно рассматривали её в своей теоретической статье про Nvidia GF100. Существует несколько различных схем разбиения графических примитивов (тесселяции). Например, phong tessellation, PN triangles, Catmull-Clark subdivision.
Тесселяцию уже начали использовать в первых DirectX 11 играх, таких как STALKER: Зов Припяти, DiRT 2, Aliens vs Predator, Metro 2033. В некоторых из них тесселяция используется для моделей персонажей (все игры жанра FPS из перечисленных), в других — для имитации реалистичной водной поверхности (DiRT 2). Схема PN Triangles используется в STALKER: Зов Припяти, в Metro 2033 — Phong tessellation. Эти методы сравнительно быстро и просто внедряются в процесс разработки игр и существующие движки, что и было проделано.
Первым тестом тесселяции у нас будет пример Detail Tessellation из ATI Radeon SDK. Собственно, он показывает не только тесселяцию, но и две разные техники бампмаппинга: обычное наложение карт нормалей и parallax occlusion mapping. Что ж, сравним DirectX 11 решения от Nvidia и AMD в различных условиях:

Первым же выводом напрашивается следующий: попиксельная техника parallax occlusion mapping (средние столбики на диаграмме) и на Geforce GTX 480 и на RADEIN HD 5870 выполняется менее эффективно, чем тесселяция (нижние столбики). То есть, имитация геометрии при помощи пиксельных расчётов обеспечивает меньшую производительность, чем реальная геометрия, отрисованная при помощи тесселяции. Это к слову о перспективности тесселяции там, где сейчас используется parallax mapping.
Далее, что касается производительности GTX 480 и карт AMD относительно друг друга. Двухчиповый HD 5970 опережает одночиповые варианты, что вполне понятно. А вот GTX 480 впереди HD 5870 на 5-15%. Больше при включенной тесселяции, меньше при попиксельных расчётах. Что соответствует нашим ожиданиям — в играх с поддержкой только DX9 или DX10 разница между GTX 480 и HD 5870 тоже должна быть меньше, чем в DX11 играх с тесселяцией.
Вторым тестом на производительность тесселяции у нас будет ещё один пример для 3D-разработчиков из ATI Radeon SDK — PN Triangles. Собственно, оба примера входят также и в состав DX SDK, так что на их основе будут создавать свой код множество игровых разработчиков. Этот пример мы протестировали с различным коэффициентом разбиения (tessellation factor), чтобы понять, как сильно влияет его изменение на общую производительность.

В этом примере, пожалуй, мы впервые увидели настоящую геометрическую мощь графической архитектуры GF100. Да, это лишь синтетический тест и такие экстремальные коэффициенты разбиения вряд ли будут использоваться поначалу. Но синтетика для того и нужна, чтобы помочь оценить перспективность решений в будущих задачах.
И Geforce GTX 480 тут отлично показывает, на что способен GF100 в задачах тесселяции. Единственный чип в разы опережает двухчиповую карту конкурента. Преимущество над HD 5970 достигает четырёх раз, а одночиповая HD 5870 в этом тесте повержена с просто разгромным счётом. По сути, GF100 позволяет использовать коэффициент тесселяции на несколько ступеней больше, по сравнению с RV870. Вот что значит архитектура, специально разработанная с учётом возможностей нового API в виде тесселяции.
Но давайте рассмотрим ещё один тест — демонстрационную программу Nvidia Realistic Water Terrain, также известную как Island. Кстати, автор этой программы — известный 3D-энтузиастам Тимофей Чеблоков aka Smalltim. Его демка Island использует тесселяцию и карты смещения (displacement mapping) для рендеринга реалистично выглядящей поверхности океана и ландшафта. Смотрится она просто отлично:

Вообще, Island не является чистым синтетическим тестом для тесселяции, а содержит и довольно сложные пиксельные и вычислительные шейдеры, поэтому разница в производительности может быть меньше, чем в предыдущем случае, но зато это положение будет ближе к реальности.
В данном случае мы протестировали демо при четырёх разных коэффициентах тесселяции, здесь эта настройка названа Dynamic Tessellation LOD. Если при самом низком коэффициенте разбиения карта на GF100 лишь немного опережает одночиповый вариант от AMD, и даже уступает HD 5970, то при росте коэффициента разбиения и итоговой сложности сцены производительность GTX 480 снижается далеко не так сильно, как скорость рендеринга у конкурирующих решений.
В итоге мы снова получили ситуацию, когда чип GF100 новой графической архитектуры Nvidia обеспечивает схожую с RV870 производительность тесселяции при значительно отличающейся сложности сцены. Так, при максимальном коэффициенте LOD равном 100 в этой программе GTX 480 показывает такую же производительность, как и Radeon HD 5870, но при коэффициенте лишь 25 — то есть при в несколько раз большем количестве треугольников (28 млн. против 4 млн. в данном случае). Это просто огромная разница!
Выводы по синтетическим тестам
По результатам проведённых синтетических тестов новой модели Nvidia Geforce GTX 480, основанной на графическом процессоре GF100, а также результатам других моделей видеокарт основных производителей видеочипов, мы можем сделать вывод о том, что это — очень мощная графическая архитектура Nvidia, которая отличается значительно улучшенными производительностью и возможностями. Новые модели видеокарт на основе GF100 стали одними из самых быстрых среди всех одночиповых.
Увеличенное количество блоков обработки геометрии и их параллельная работа позволили значительно улучшить производительность тесселяции и геометрических шейдеров. В синтетических задачах тесселяции новому решению компании Nvidia просто нет равных. Конкуренту не помогает даже двухчиповое решение, а уж при сравнении видеоплат с одним GPU, решение на основе GF100 выигрывает в таких тестах у лучшей карты на основе RV870 до 4-6 раз. И до выхода архитектуры конкурента, специально усиленной для эффективной обработки геометрии, ситуация не изменится.
Если же судить о производительности в 3D-приложениях без тесселяции, то можно предположить, что в игровых тестах будет то же самое, что и в наших синтетических — где-то Geforce GTX 480 окажется впереди конкурента, а где-то — немного отстанет. Причём слишком больших проигрышей быть не должно, так как нет игр, которые были бы полностью ограничены математическими вычислениями или производительностью текстурных выборок — единственными параметрами, по которым к архитектуре GF100 у нас возникают некоторые вопросы.
В синтетических тестах тесселяции, геометрических шейдеров и физических расчётов (имитации тканей и частиц в пакете Vantage, где также используются геометрические шейдеры), новый чип Nvidia GF100 значительно сильнее других. Как и в других вычислительных тестах со сложными программами. А вот прямолинейная математика вроде чисто вычислительных тестов из RightMark или Vantage, как и ожидалось, была проиграна решениям AMD, и отставание у Nvidia до сих пор приличное. Получается, что GF100 приблизился к CPU по своим особенностям, стал ещё универсальнее (вспоминаем про C++ и кэширование как у CPU), но по сравнению с RV870 он обладает несколько меньшей «числодробильной» мощью, которой всегда отличались GPU от CPU.
Сравнительно невысокая пиковая вычислительная и текстурная производительность, которые мы отметили в нашей статье, приводит к отставанию от конкурента в некоторых искусственных тестах, но в целом GTX 480 показала весьма приличные результаты, которые должны подтвердиться в следующей части нашего материла. В ней вы ознакомитесь с тестами свежего решения компании Nvidia, основанного на новом GPU, в самых современных игровых приложениях.
Предполагаем, что игровые результаты будут примерно соответствовать нашим выводам, сделанным при анализе результатов синтетических тестов. Хотя разницы в разы не будет, потому что скорость рендеринга в играх зачастую зависит сразу от нескольких характеристик видеокарт, и гораздо сильнее зависит от филлрейта и пропускной способности памяти, чем синтетика. Думаем, что модель Geforce GTX 480 должна немного опережать своего одночипового конкурента Radeon HD 5870 в играх без тесселяции и уж точно будет впереди в тестах с её применением.
Nvidia Geforce GTX480 - Часть 3: Игровые тесты (производительность)
Блок питания для
тестового стенда предоставлен
компанией TAGAN |
Корпус ThermalTake 8430 для
тестового стенда предоставлен
компанией 3LOGIC |
Монитор Dell 3007WFP для
тестовых стендов предоставлен
компанией Nvidia |
| 27 марта 2010 |
|
|