ATI RADEON 8500: Восхождение на восьмитысячник — часть 2
DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипа мы использовали модифицированные нами для большего удобства и контроля примеры из пререлиза последней версии DirectX SDK (релиз пока недоступен). Ввиду заметных изменений пришлось вновь переписать несколько примеров — старый код и компилированные примеры из SDK 8.0 не совместимы с DirectX и DirectX SDK 8.1. Не стоит пугаться — это специфика примеров SDK и большинство других игр и приложений, даже скомпилированные для DirectX 8.0 будут выполнятся на 8.1 без каких либо проблем. Мы же акцентируем ваше внимание на этой несовместимости ввиду возникавших в конференции вопросов о прекращении работы EMBM примеров BumpLens и BumpWaves и примера RTPatch на новых драйверах для GeForce3. Так вот, если два первых примера не работают сугубо "по собственной" вине, и будучи скомпилированны из среды SDK 8.1 начинают прекрасно функционировать, то с RTPatch ситуация обстоит хуже. Как было уже отмечено ранее, на данный момент драйверы от NVIDIA прекратили поддерживать эту аппаратную возможность карты, по неизвестной причине. Впрочем, перейдем к нашим тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности ускорителя по треугольникам. Для
этого используется несколько одновременно выводимых в небольшом окне моделей, каждая из которых состоит
из 50 тысяч треугольников. Текстурирование отсутствуют. Размеры моделей минимальны -
каждый треугольник не превышает одного пиксела. Хочется сразу отметить, что результат этого теста, разумеется,
останется недостижим для реальных приложений, где размеры треугольников значительны, присутствуют текстуры и
освещение. В дальнейшем, мы еще вернемся к этому вопросу. Приведем результаты этого теста для трех моделей —
оптимизированной для оптимальной скорости вывода (в том числе с учетом размера кеша вершин на чипе)
модели — Optimized, неоптимизированной исходной модели — Unoptimized и той-же модели, выводимой в виде одного
Triangle Strip — Strip:
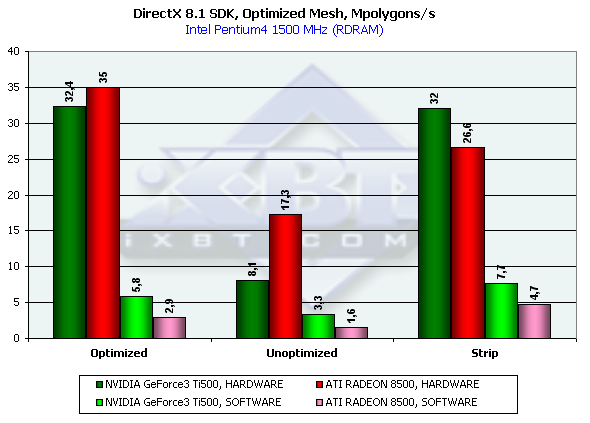
Как мы видим, в случае оптимизированоой модели оба ускорителя показывают внушительную цифры — более 30 миллионов полигонов в секунду, причем преимущество RADEON 8500 ниже ожидаемого благодаря разнице частот. Далее, мы увидим, как хороший баланс чипа смог кардинально перевернуть картину в мало-мальски реальной (а не предельной) сцене. С неоптимизированной моделью RADEON справился очень хоршо, получив двукратное преимущество. Сказались, вероятно, большие размеры вершинных кешей. Но самое интересное - неоптимизированная Strip модель. Она явилась причиной проигрыша RADEON, которому по какой то причине стало крайне неуютно с ней работать. А вот GeForce 3 Ti 500 молодец — для него Strip практически равен Optimized, как в качественном так и в колличественном плане. Чтож, разработчики игр должны взять на заметку оба этих аспекта.
Кроме того, отметим существенное преимущество GeForce 3 в случае принудительной активации програмного рассчета геометрии. Причина этого явления кроется во взаимодействии процессора и ускорителя при передаче рассчитанных процессором данных — GeForce 3 получил значительное преимущество благодаря FastWrites механизму, позволяющему напрямую передавать геометрические данные из процессора в ускоритель, минуя системную память.
Производительность блока вершинного шейдера
Этот тесть позволяет определить предельную производительность блока вершинных шейдеров. Выполняется
достаточно сложный шейдер, вычисляющий как видовые преобразования так и геометрические функции. Тест
выполнялся в минимальном разрешении, дабы минимизировать влияние закраски. Z-буфер был отключен, и
HSR таким образом также не мог влиять на результаты. Итак:
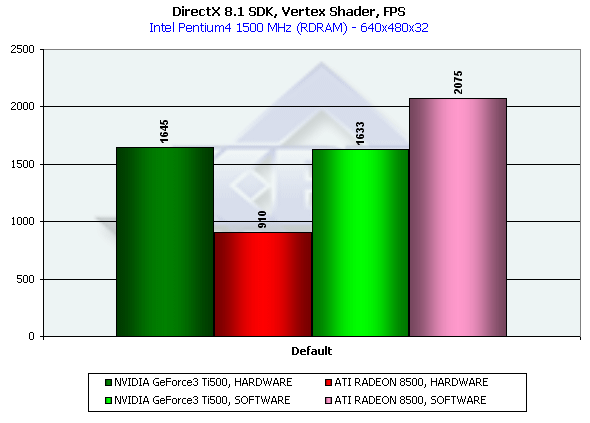
Удивительно, но в случае аппаратного испольнения вершинного шейдера Ti 500 существенно (практически вдвое) опережает RADEON. Кроме того, если вернуться к результатам нашего первого тестирования GeForce3 — мы заметим, что его результат почти вдвое обогнал (если так можно выразится) его самого, полугодовой давности. Кроме того, нас смутила поразительное совпадение результатов программного и аппаратного исполнения шейдеров на GeForce 3. Причем, подобная картина наблюдалась и пол года назад. Разумеется, закралось подозрение — а не выполняются ли все шейдеры на GeForce3 программно? Для проверки этой гипотезы мы снизили тактовую частоту Pentium4 до 1000 МГц. На сей раз, расхождение программного и аппаратного результата увеличилось, программный упал до ~1200 а аппаратный остался практически на том же уровне. Что позволило нас с облегчением вздохнуть — никакого обмана нет, просто новая ревизия чипа NV20 (A05) и/или новые драйверы вызвали практически двукратный прирост производительности вершинных шейдеров. Нам остается только поздравить NVIDIA, посетовать на неопытность ATI в "шейдерных" делах и отметить поразительный результат RADEON в случае программной эмуляции.
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали
блендинг с использованием двух матриц, как в жестком "аппаратном" варианте, так и с использованием вершинного
шейдера выполняющего туже функцию. Кроме того, мы как обычно "подстраховались" результатами полученными
в режиме програмной эмуляции T&L:

Налицо вновь значительное преимущество Ti 500, особенно в случае полностью аппаратной реализации блендинга. Кроме того, отметим повсеместное превосходство аппаратного исполнения над программным — задача умножения матриц для ускорителя привычна и удобна, чего не скажешь о процессоро подобной работе по последовательному исполнению команд вершинного шейдера.
Уже какой раз мы обнаруживаем картину валового превосходства различных блоков GeForce 3. Однако, поможет ли это "предельное" превосходство в реальных приложениях, где важна не только скорость отдельных блоков чипа но и правильная организация взаимодействия между ними (и в первую очередь отсутствие узких мест) мы узнаем чуть далее. А пока оставайтесь с нами.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив производительность карт в высоком
разрешении при выполнении 5 различных по сложности шейдеров, для билинейно фильтрованных текстур:
Интересно, что в случае самого простого, не использующего текстуры шейдера, ATI немного лидирует, но то что начинается дальше, может вызвать только благородное негодование. Сохраняя небольшое отставание в случае двух текстур, RADEON просто проваливается при четырех! И дело тут, как видно, не в сложности самого шейдера, а только в числе используемых им текстур. Использование текстурных модулей второй раз вызывает у творения ATI скачкообразное падение производительности. Остается только надеятся, что это явление исправимо (так или иначе) на уровне драйверов. Впрочем, сия надежда весьма призрачна.
Отметим, что карта, как и было обещано, выполняет шейдеры версии 1.4. Среди демо-программ, которые
будут поставляться в комплекте с RADEON 8500, есть интересная программа, которая позволяет увидеть
визуальную разницу между реализациями PS1.1 и PS1.4 (слева 1.1, справа 1.4)


Производительность версии 1.4 адекватна производительности предыдущих версий на аналогичных задачах (что совершенно естественно). Как уже упоминалось ранее в превью нового семейства RADEON, шейдеры 1.4 гораздо более гибки в вопросах выборки значений из текстур, и существует целый класс эффектов, которые реализуются с их использованием проще, либо вообще нереализуемы без их участия. Впрочем, несмотря на очевидное архитектурное превосходство, потребность сравнивать скорость выполнения новой версии шейдеров в предельных тестах не возникнет у нас никогда — NVIDIA не планирует поддерживать шейдеры 1.4, а следующий продукт ATI будет уже совместим с DirectX 9 и, как следствие, c пиксельными шейдерами версии 2.0.


EMBM рельеф
В этом тесте мы измеряем производительность, а точнее ее падение, возникающее при использовании наложения карт
отражения (Environment) и рельефа на основе карт отражения (EMBM — Environment Bump). Для тестирования
использовалось разрешение 1280*1024 — т.к. именно в нем различия между картами и разными режимами
текстурирования выражено наиболее резко:
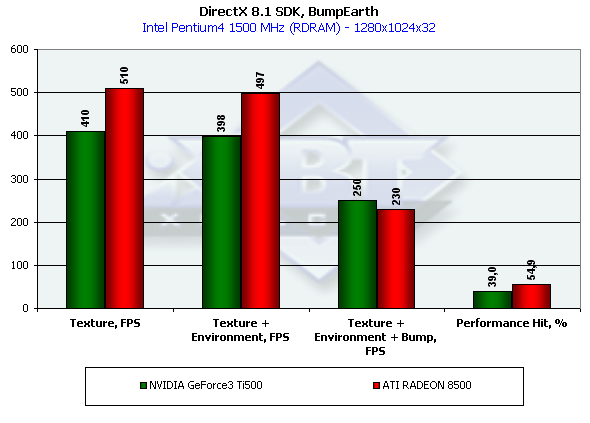
В главном тесте — Environment + Bump мы наблюдаем небольшой проигрыш RADEON 8500, несмотря на превосходство в обычном текстурировании и наложении карт среды. Судя по всему последняя стадия EMBM — пертурбация (смещенная выборка значений из текстуры) выполняется чипом не так уверенно как хотелось бы. О чем и свидетельствует больше падение производительности в %.
Аппаратная реализация N-Patches
Так как на данный момент не существует приложений, в которых можно было бы нормально протестировать зависимость
производительности аппаратной реализации N-Patches в зависимости от уровня детализации, мы попросили
автора RADEON Screen Saver Филиппа Герасимова модифицировать его
программу (одна из загружаемых сцен которой демонстрирует N-Patches), добавив туда возможность регулировать
детализацию. Филипп любезно согласился, и мы получили следующую тестовую сцену
(на представленных скриншотах слева — без N-Patches, справа — с использованием технологии Truform):
На основании полученных результатов мы построили график:
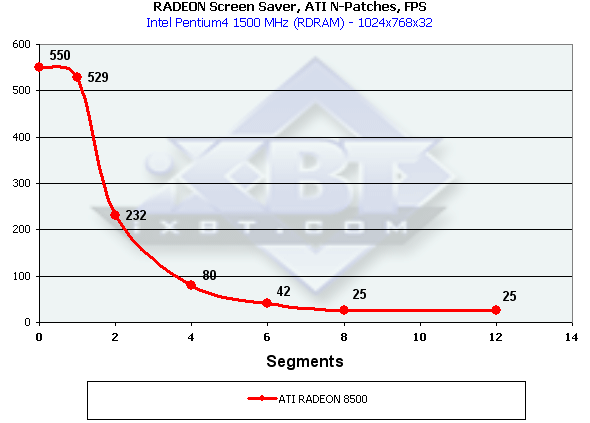
Очевидно, что реальное практическое использование N-Patches возможно только с числом разбиений порядка 2
или менее. В случае одного разбиения (треугольник превращается в 4) эта возможность практически бесплатна,
но уже в случае двух мы наблюдаем двукратное падение производительности. Большие уровни детализации практически
беcсмысленны — скорость падает почти на порядок. В защиту RADEON отметим что этот тест несколько
синтетичен — в реальных приложениях N-Patches как правило используются только с моделями, в то время как
вся окружающая сцена выводится обычным образом, да и уровень детализации 2 уже сам по себе существенно
сглаживает модель. Но как бы там ни было — бесплатного обеда опять не получилось. И тем не менее, надо отметить,
что данная технология позволяет воплотить в трехмерных объектах образы, уже очень близкие по форме к человеку:


А ведь это "лицо прекрасной девушки" состоит из неимоверного числа полигонов (уже после отработки TruForm):

Подытожим предельные тесты. Эта информация будет несомненно полезна как разработчикам, так и просто пытающимся проинтерпретировать результаты производительности в реальных приложениях энтузиастам. Несколько раз отдельные блоки GeForce3 демонстрировали подавляющее преимущество над RADEON 8500. Однако, несколько раз и RADEON как минимум вдвое опережал GeForce 3. В общем и целом нет смысла выделять на этой фазе тестирования конкретного лидера — оставайтесь с нами и именно реальные приложения далее покажут "кто есть кто".
Тестирование эффективности HSR
Для того, чтобы оценить эффективность реализации HSR мы использовали тест с большим уровнем OverDraw -
VillageMark v.1.17. Приводим результаты обеих карт со включенным и отключенным HSR:
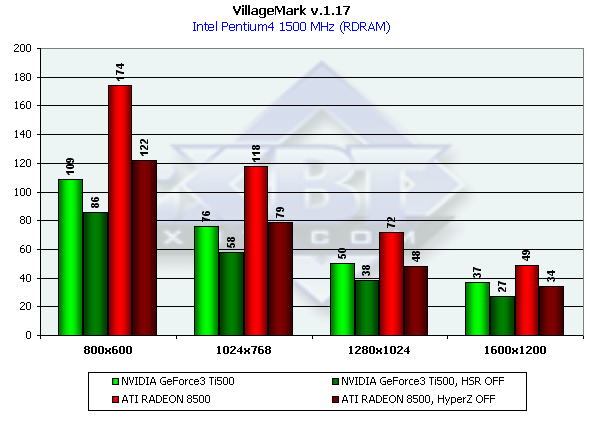
Очевидно что эффективность HSR у RADEON существенно выше, но с ростом разрешения выигрышь от включения HyperZ II падает быстрее нежели в случае Ti 500. Итак, RADEON 8500 вновь лидер, налицо добротная реализация HSR.
3D Mark 2001 — синтетические тесты
Скорость закраски
Мы измеряли этот параметр только для 32 битной глубины цвета. Читатель наверняка поддержит нас во мнении, что современные топовые игровые ускорители если и будут работать в 16 битном цвете, то лишь у нерадивого тестера. Более того, можно ожидать полного исчезновения поддержки 16 бит буфера кадра в течении нескольких ближайших поколений ускорителей — все современные приложения могут совершенно спокойно выполняться в 32 бит цвете, а наличие поддержки 16 бит только немного усложняет чип.
Итак, как же обстоят дела со скоростью закраски — наглядным критерием мощи и архитектурного совершенства
современного ускорителя:
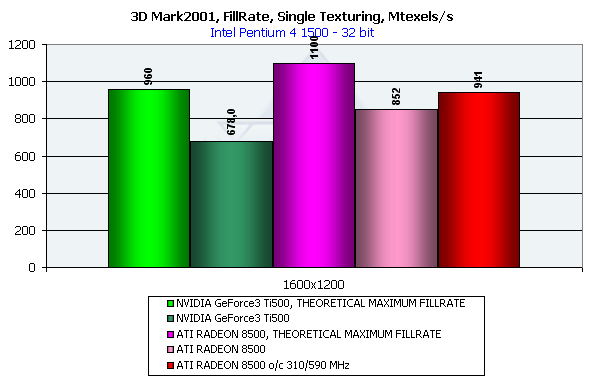
Мы приводим данные для разрешения 1600*1200 для того, чтобы зависимость от других аспектов производительности
чипа (например геометрической) стала минимальной. Наибольший результат этого теста всегда достигается при
максимальном разрешении — здесь чипу остается только красить, красить и еще раз красить бескрайние поля
экрана. Напомним, что теоретические пределы для данного теста (также изображены на диаграмме) составляют
960 миллионов пикселей в секунду для Ti 500 и 1100 для RADEON 8500 соответственно. Последний наиболее близко
подобрался к своему потенциальному потолку, продемонстрировав тем самым отличную организацию кеширования и
работы с памятью, а также прекрасную сбалансированность архитектуры.
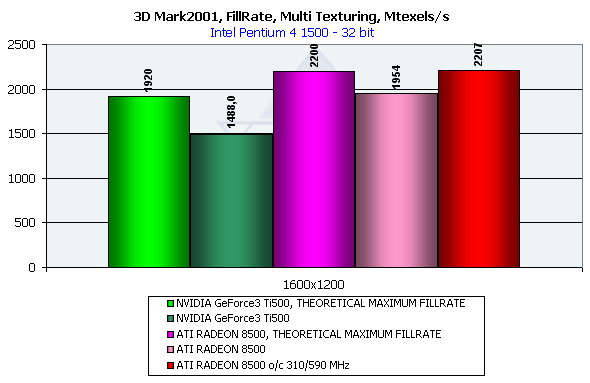
И в случае максимального использования мультитекстурирования (4 текстуры для Ti 500 и 6 текстур для RADEON 8500) ситуация вновь повторяется. Теоретические пределы в этом тесте составили соответсвенно 1920 для Ti 500 и 2200 для RADEON 8500. Нет никаких сомнений в совершенстве архитектуры нового RADEON, особенно если вспомнить факт успешной и "холодной" работы с более медленной формально, нежели у Ti 500 памятью на более высоких частотах.
Сцена с большим количеством полигонов
Этот тест мы проводили в небольшом разрешении, дабы снизить влиянее закраски на полученные результаты. Итак:
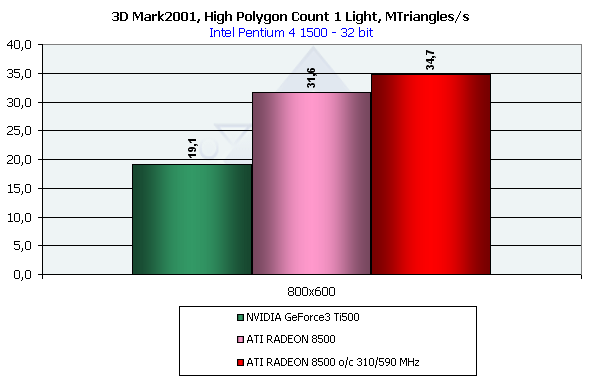
При наличии одного источника света новый RADEON показывает себя абсолютным лидером. Его результат не только
значительно (более чем на разницу частот) превосходит Ti 500, но и (что более важно) вплотную приблизился к
значению практического предела пропускной способности по треугольникам, полученному нами ранее с помощью
Optimized Mesh из DX8.1 SDK. Т.е. даже в реальной динамической сцене RADEON 8500 демонстрирует производительность
близкую к практическому лимиту своей пропускной способности по треугольникам, в отличии от GeForce 3 -
продемонстрировавшей прекрасные предельные характеристики в тесте из SDK, но существенно сдавшей в этом
более менее "реальном" тесте. Еще одно свидетельство мощи T&L RADEON 8500 и прекрасного баланса всей архитектуры
чипа.
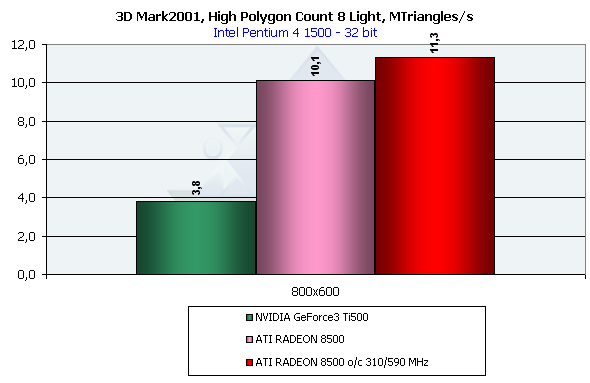
В случае с 8 источниками света мы можем отметим следующие моменты. Добавление новых источников света до сих пор не бесплатно для любого чипа. Производительность RADEON упала втрое. Но, если так можно выразится, для Ti 500 эти источники дались еще более небесплатно. Сделаем вывод: в играх будущего (например Next Doom), вероятно интенсивное использование большого числа аппаратных источников света. Именно в таких приложениях RADEON сможет "во всей красе" продемонстрировать свое архитектурное преимущество над семейством GeForce3.
Рельефное текстурирование
Этот тест мы проводили в разрешении 1024*768 как в наиболее характерном для современных игровых
приложений. Необходимо учесть, что слишком маленькое разрешение чревато заметной зависимостью от
геометрической производительности карты, а слишком большое от пропускной полосы шины памяти. Мы имеем:
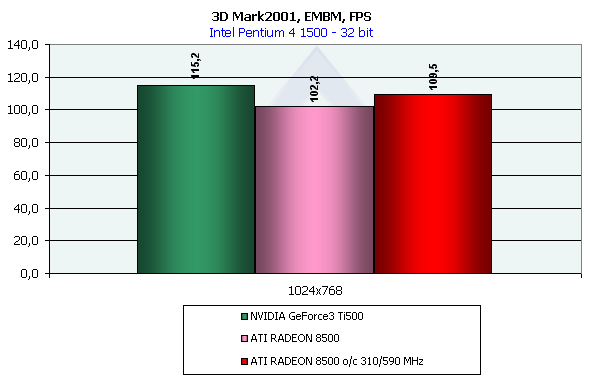
Сюрприз — более медленная по скорости закраски Ti 500 справилась с этим тестом существенно лучше, даже
в сравнении с разогнанным RADEON. Впрочем, именно это и предвещал нам упомянутый ранее предельный тест
EMBM производительности из DirectX SDK. Минорные недостатки реализации EMBM в новом RADEON по прежнему
налицо. Перейдем более перспективному DOT3 рельефу:
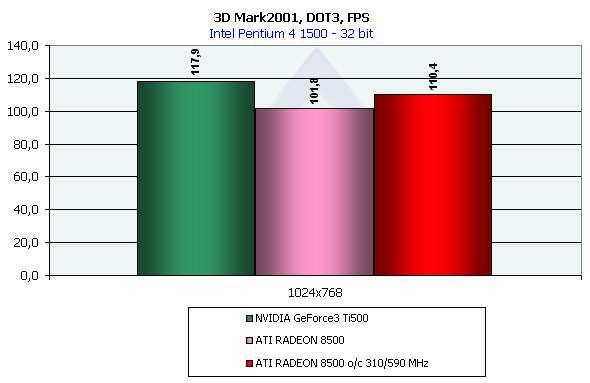
И здесь GeForce3 на коне. Остается поздравить инжинеров NVIDIA c удачной реализацией этой возможности, или наоборот посетовать на потенциальные "драйверные" проблемы RADEON, которые не дают ему полностью раскрыть свой частотный запас в этих тестах. Мы предоставим читателям право выбирать наиболее приглянувшийся им сценарий :-). Со своей же стороны хочу подлить масло в огонь заявив что с приходом пиксельных шейдеров эти два теста начинают терять свою важность — ибо с помошью шейдеров можно реализовать много различных методов рельефного текстурирования, в том числе с попиксельным рассчетом освещения.
Вершинные шейдеры
Мы приводим результаты этого теста в нескольких разрешениях. Читатель легко подметит интересную зависимость:
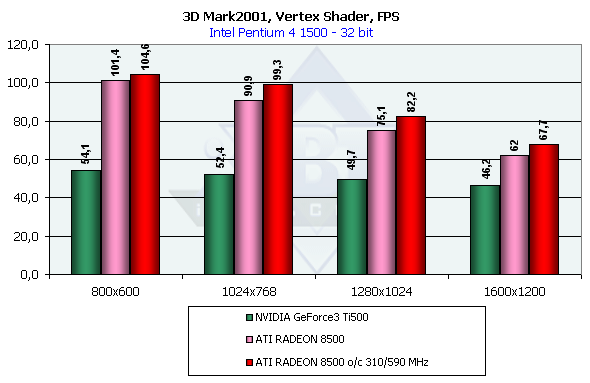
Если производительность Ti 500 практически остается постоянной, крайне медленно падая с ростом разрешения, что говорит о довлеющей зависимости от геометрической производительности чипа (что мы и хотели бы видеть от этого теста) то RADEON явно упирается не столько в собственный интерпретатор шейдеров, сколько в скорость закраски! Т.е. даже интенсивный синтетический тест не смог застать программируемый TCL блок RADEON в расплох — его производительность всегда оставалась "достаточной". Чтож, нам остается пожелать создателям 3DMark2001 усовершенствовать этот тест сделав его еще более тяжелым для геометрического блока ускорителя, и констатировать факт как минимум двукратного преимущества RADEON над Ti 500. Вспомнив полученные ранее на предельный тестах из DirectX SDK результаты (где RADEON отнюдь не блистал по сравнению с GeForce3 Ti 500), отметим что в менее синтетической (если так можно выразится) сцене из 3D Mark 2001, RADEON полностью реабилитирует себя, показав завидную производительность в условиях реальной сцены.
Пиксельный шейдер
Руководствуясь высказанными выше соображениями о том что слишком малые разрешения "упираются" в
геометрию, а слишком большие в пропускную полосу памяти, проведем этот тест в привычных многим 1024*768:
Мы вновь наблюдаем преимущество RADEON, впрочем не столь уверенное, как бы хотелось. Фактически, оно коррелирует с разницей в тактовых частотах соперников, и даже чуть ниже ожидаемого из этих соображений результата. Что только подтверждает полученные ранее на предельном тесте MFCPixelShader результаты. Впрочем, общий баланс чипа оказался очень даже удовлетворителен в этом тесте — в реальном применении мы уже не наблюдаем потенциально возможного двукратного проигрыша RADEON.
Спрайты
Здесь мы приведем наименьшее разрешение, т.к. в остальных разрешениях взаимная картина ничуть не меняется:
RADEON существенно обыгрывает Ti 500, причем, восновном благодаря своей геометрической производительности. Закраска плоских спрайтов крайне проста, скорость их вывода все время упирается в геометрический аспект - спрайтов очень много, и перед закраской надо преобразовать множество координат.
Подытожив синтетические тесты из 3D Mark 2001 отметим, что при переходе от предельных тестов SDK к
более "реальным", если так можно выразится, но все же синтетическим сценам 3D Mark, RADEON как правило
получает преимущество благодаря хорошо сбалансированной архитектуре. Далее, мы посмотрим получит ли эта
тенденция свое логичное продолжение в реальных играх. Оставайтесь с нами.
| 17 октября 2001 г. |
|
|