Система «Речь в Реальность»: ИИ и роботы научились создавать физические объекты по голосовой команде
Генеративный ИИ научился рисовать картины за секунды. Он пишет код, сочиняет симфонии и ведет диалоги. Проблема только в том, что всё, что он делает, заперто внутри экрана. Вы можете попросить нейросеть нарисовать стул, но вы не можете на него сесть.
До сегодняшнего дня переход от слова к вещи требовал посредников: CAD-инженеров, долгих часов 3D-моделирования, настройки 3D-принтеров, которые печатают объект сутками.

Исследователи из MIT (CSAIL и Center for Bits and Atoms) представили систему Speech-to-Reality («От речи к реальности»). Вы говорите: «Мне нужен простой стул». Через пять минут перед вами стоит физический объект, собранный роботом.
Как это работает
Система — сложный конвейер, который переводит язык в физику. Процесс разбит на четыре этапа, где каждый последующий шаг заземляет галлюцинации предыдущего.
1. Интерпретация намерения: всё начинается с LLM (GPT-4 Turbo). Пользователь произносит команду. Нейросеть анализирует текст и отсеивает абстракции. Если вы попросите «создать красоту», система откажет. Ей нужны конкретные объекты: стол, полка, буква «Т». Лингвистическая модель извлекает суть запроса и передает его дальше.
2. Генерация формы: здесь вступает text-to-3D модель (в данном исследовании использовалась Meshy. ai). Она создает полигональную сетку (mesh) — цифровую форму объекта. На этом этапе объект выглядит правдоподобно для глаза, но абсолютно непригоден для реального мира. Нейросети часто игнорируют гравитацию, создают висящие в воздухе детали или поверхности с нулевой толщиной.
3. Дискретизация и проверка физики: гладкая 3D-модель разбивается на воксели — объемные пиксели. Система превращает сложную криволинейную форму в набор стандартных кубических блоков размером 10x10x10 см.
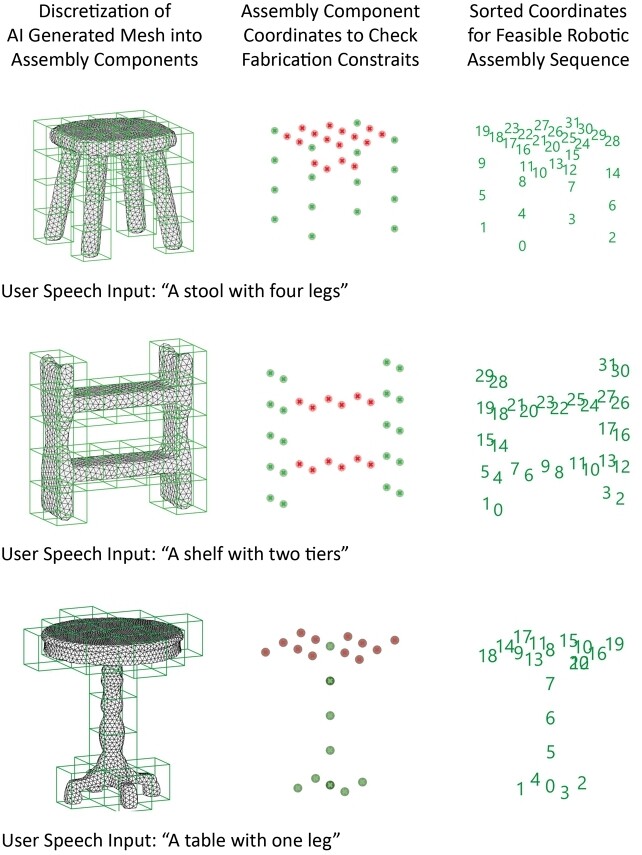
Далее алгоритм проводит жесткую проверку на приложение к реальности:
- Инвентаризация: есть ли у нас столько кубиков? В экспериментальной установке было всего 40 модулей. Если ИИ нарисовал трон из 100 блоков, алгоритм автоматически уменьшает масштаб модели, пока она не впишется в лимит.
- Гравитация и консоли: выдержит ли конструкция? Если ИИ создал стол с трехметровой столешницей на одной ножке, он упадет. Алгоритм ищет «нависающие» элементы без опоры. Если консоль длиннее трех блоков, система сжимает модель по горизонтали, пока физика не сойдется.
- Вертикальная устойчивость: слишком высокие и тонкие колонны (стопки выше 4 блоков) нестабильны. Алгоритм находит их и масштабирует объект по вертикали, снижая центр тяжести.
- Связность: в цифровой модели детали могут висеть в миллиметре друг от друга. В реальности они упадут. Алгоритм совершает подгонку, чтобы каждый новый блок имел грань соприкосновения с уже установленным или с полом.
4. Роботизированная сборка: шестиосевой робот-манипулятор UR10 получает координаты. Он берет унифицированные блоки с конвейера и укладывает их. Блоки не требуют клея или винтов — внутри находятся магниты, которые обеспечивают сцепление и самовыравнивание.

Результат: скорость и осязаемость
Чтобы напечатать простую табуретку на большом 3D-принтере, требуется около 3 дней и 1 часа. Система Speech-to-Reality собирает функциональный стул за 3 минуты 36 секунд.
В ходе экспериментов исследователи собирали столы, полки, буквы и даже стилизованную собаку. Время сборки варьировалось от 1 до 5 минут.
Экология вокселей
Ключевое преимущество этого подхода — обратимость. Традиционное производство или 3D-печать создают монолитную конструкцию. Если стул вам надоел, или сломался — повторно его не пересобрать.
Здесь же используется принцип дискретной сборки. Блоки — это многоразовый ресурс. После того как объект перестал быть нужен, его можно разобрать (вручную или тем же роботом), а блоки вернуть на конвейер. Один и тот же набор из 40 модулей сегодня был столом, завтра станет полкой, а послезавтра — временной конструкцией для выставки.

Минусы будут?
Система, мягко говоря, не идеальная.
- Разрешение: объекты выглядят пиксельными. Вы ограничены размером минимального блока (в данном случае 10 см). Тонкие детали или эргономичные изгибы реализовать не получится.
- Прочность: магнитные соединения уступают сварке или литью. На такой стул можно положить книгу, но вставать на него ногами пока рискованно.
- Сложность восприятия ИИ: генеративные модели всё еще склонны к галлюцинациям, и алгоритмам коррекции приходится агрессивно менять форму объекта, чтобы сделать его устойчивым. Иногда результат отличается от задумки пользователя.
Зачем это нужно?
Speech-to-Reality — это прототип интерфейса будущего, где разрыв между цифровым и осязаемым сводится к минимуму.
MIT показывает, что физический мир может перенять свойства цифрового: стать быстрым, модульным и редактируемым.
Источник: Proceedings of the ACM Symposium on Computational Fabrication
Источник: dl.acm.org











1 комментарий
Добавить комментарий