Быстро, быстрее, еще быстрее. Разгоняем Intel Optane
Пожалуй, мало кто будет спорить с тем, что появление накопителей на базе флэшпамяти на замену традиционным жестким дискам является одним из наиболее ярких этапов развития вычислительных систем за последнее время. Кардинальное уменьшение времени случайного доступа и увеличение скорости на последовательных операциях заметно невооруженным взглядом и без специальных тестов. Если взять за точку отсчета Intel X25-M, то за прошедшие десять лет мы были свидетелями революции роста объемов и производительности с одновременным снижением стоимости за мегабайт. Напомним, что тогда эта модель имела объем 80 ГБ, интерфейс SATA 3 Гбит/с и предлагалась примерно за $600.
Участвующие в гонке производители совершенствовали контроллеры и использовали новые технологии флэшпамяти, так что кроме банального увеличения объемов, ограниченного на массовом рынке скорее покупательской способностью, также обеспечивало и рост скорости. В какой-то момент для последней стало тесно в интерфейсе SATA 6 Гбит/с. После некоторых метаний, определился новый лидер – NVMe, работающий с прямым подключением к шине PCI Express. Одновременно был стандартизирован и новый формат устройств – M.2 (NGFF), который позволил заметно сократить физические размеры, что полезно не только для мобильных устройств.
И вот в этом году компания Intel, один из признанных лидеров индустрии, представила SSD накопитель с новым типом памяти – 3D XPoint. Причем речь идет именно о реальном продукте, доступном на массовом рынке, а не лабораторной разработке. Кстати, заявленная стоимость Intel Optane SSD 900P на 480 ГБ составляет все те же $600, как было десять лет назад за Intel X25-M на 80 ГБ. На страницах сайта iXBT.com уже был подробный обзор этого устройства и в нем оно показало себя с наилучшей стороны по производительности. Но конечно надо понимать, что в реальности использование такой модели «из будущего» может быть оправдано финансово только при наличии соответствующих задач или сценариев использования, которые далеки от запросов массового потребителя и скорее характерны для высоконагруженных серверов, виртуализации, баз данных и всего такого «серьезного». Основными особенностями решения, которыми оно существенно отличается от других продуктов, является высокая скорость случайного доступа и стабильная производительность в отсутствие необходимости сборки мусора. В существенные недостатки можно записать высокую стоимость за мегабайт, а относительно невысокая максимальная емкость и формально большое энергопотребление скорее являются особенностями решения.

Для тестирования используется неразмеченный том и утилита fio. Проверяются шаблоны последовательного чтения и записи с блоком 256 КБ и случайные операции с блоком 4 КБ для нескольких вариантов параметра iodepth. В результатах оцениваем скорость в мегабайтах в секунду для последовательных операций, в IOPS для случайных операций, а также средние задержки (clat).
Первая конфигурация (на графиках «chipset») – просто устанавливаем SSD в чипсетный слот PCIe. Второй вариант – дополнительная оптимизация системы прерываний в Linux. Рассматриваемый накопитель поддерживает восемь виртуальных линий прерываний и в конфигурации по умолчанию все они обслуживаются первым (нулевым) ядром процессора. Установка параметров Affinity позволяет выбрать, какие ядра процессора будут обрабатывать какие прерывания. Осуществляется эта операция через команды формата «echo “2” > /proc/irq/149/smp_affinity», где «2» — маска ядер, а 149 – номер прерывания. В результате можно добиться такого результата (см. «cat /proc/interrupts»):

На графиках эта конфигурация подписана «chipset+irq». Третий вариант – переставляем SSD в слот, который обслуживается процессором, и оставляем распределение прерываний по ядрам («cpu+irq»). Ну и напоследок к последней схеме добавляем фиксацию частоты ядер процессора на максимальном значении базовой частоты 4 ГГц («cpu+irq+4ghz»).
На первой паре графиков приводятся результаты для операций последовательного чтения.
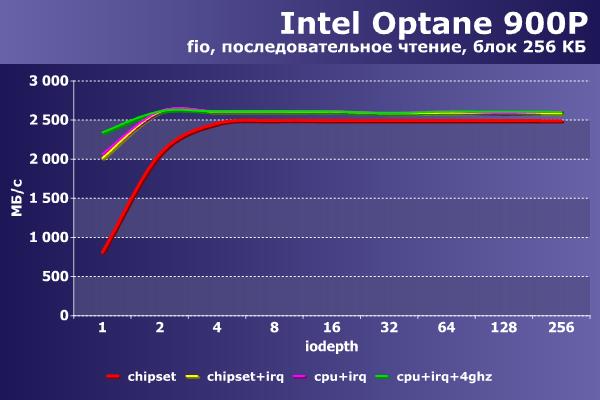 |  |
В этом сценарии заметно отстает от других только первый вариант и преимущественно при небольшой нагрузке. При ее увеличении разница сокращается до стабильных 100-120 МБ/с. Задержки также отличаются только если идет работа в один или два потока. Если их больше – можно считать цифры одинаковыми.
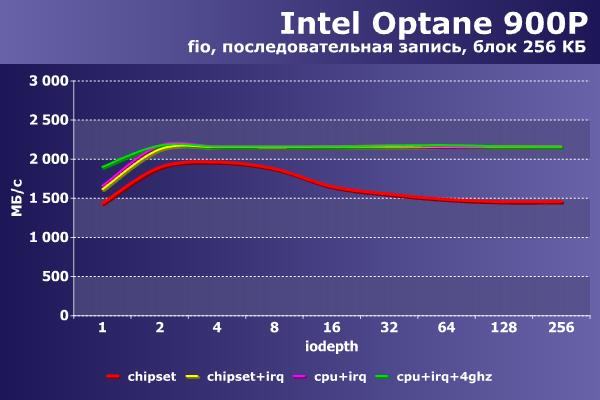 | 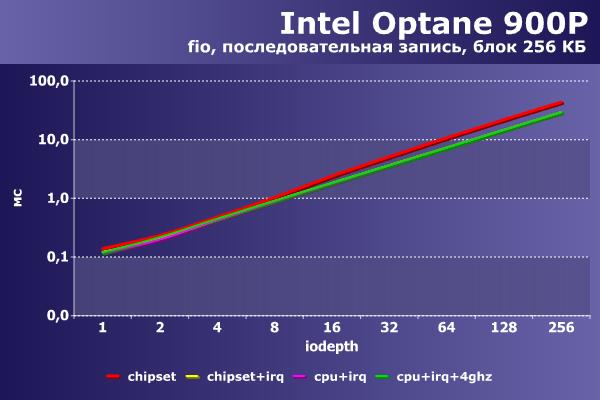 |
На последовательной записи ситуация иная – первая конфигурация при росте нагрузки ограничивает производительность на уровне 1 500 МБ/с, тогда как остальные способны показать более 2 200 МБ/с. Задержки также при числе потоков 64 и выше оказываются больше почти в полтора раза (хотя в абсолютном значении не превышают 45 мс).
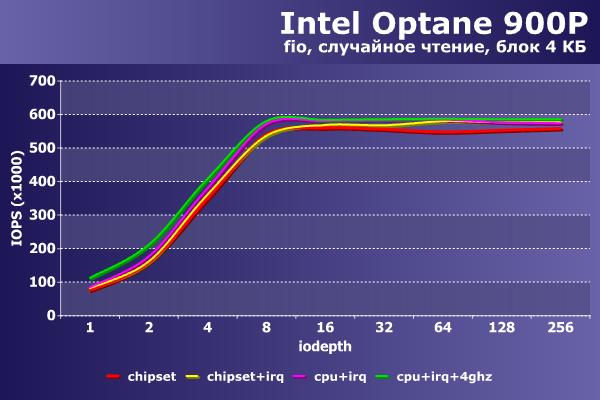 | 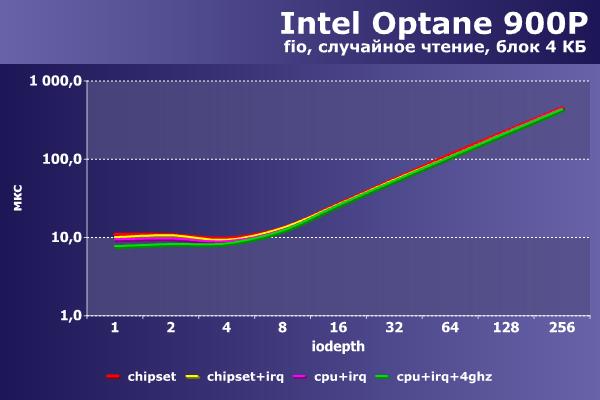 |
Случайное чтение блоками по 4 КБ все конфигурации выполняют примерно на одной скорости. В IOPS это соответствует значениям около 580 000, а в мегабайтах в секунду – 2 300 МБ/с. Как раз этим Intel Optane 900P и может быть интересен – скорость случайного чтения практически не отличается от скорости последовательного чтения. По задержкам (обратите внимание, что на этом и следующем графике используются нс, против мс для последовательных операций) разницы тоже почти нет, с минимальным опережением выигрывает максимально «разогнанный» вариант.
 | 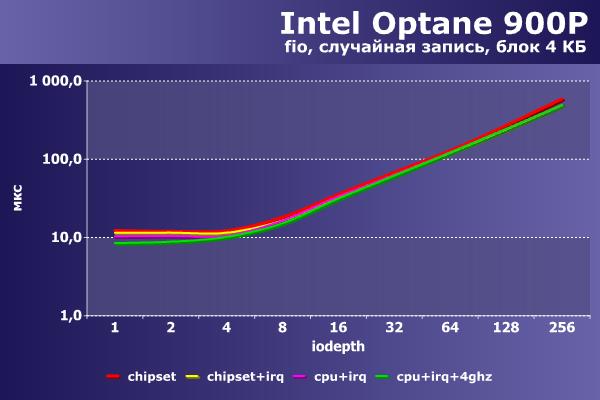 |
В случайной записи первый раз в этой статье мы видим три группы – отставание первой конфигурации, идущие рядом вторую и третью и четвертую с небольшим отрывом при глубине очереди до 32. Абсолютные значения IOPS в этом тесте достигают 520 000, а скорость превышает 2 000 МБ/с. Аналогичная расстановка сил и на графике задержек.
По результатам проведенных тестов можно сделать несколько выводов. Во-первых, накопитель можно эффективно использовать и в достаточно старых системах. Во-вторых, он неплохо чувствует себя и на чипсетной шине PCIe. Так что при необходимости (например, если нужно поставить сразу несколько штук или в рабочей станции мало слотов), их можно использовать и в такой конфигурации. Единственное, на что стоит обратить внимание – на настройку распределения прерываний. Во-третьих, особого смысла разгонять процессор для повышения скорости работы диска нет (конечно, если речь идет об обычной работе, а не соревнованиях «на цифры»). Но если число потоков невелико, фиксация высокой частоты ядер имеет заметный эффект.
Напоследок приведем аналогичные цифры на том же оборудовании и программном обеспечении для конфигурации «chipset+irq» NVMe-накопителя Intel 760p объемом 256 ГБ, выполненного в виде платы расширения M.2.
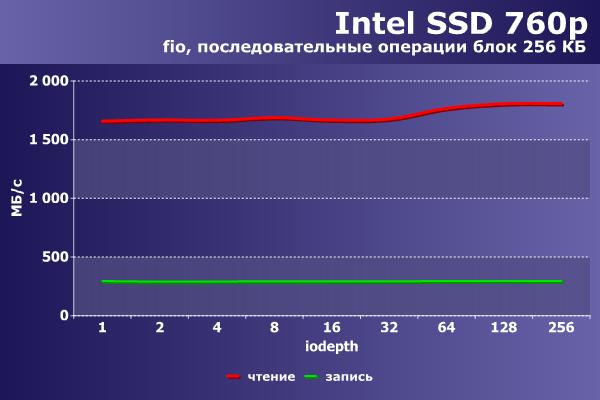 | 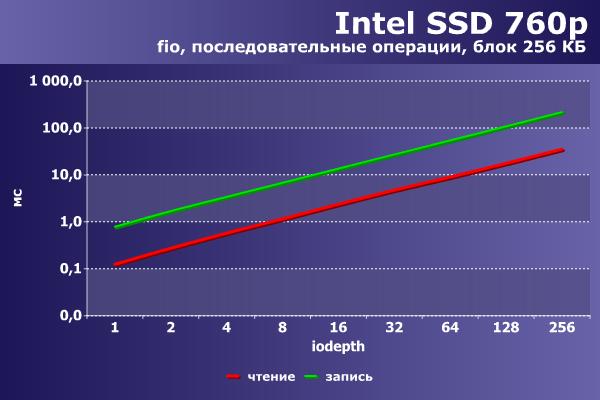 |
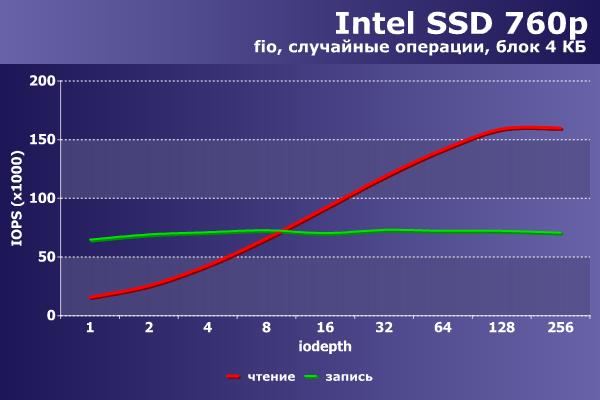 | 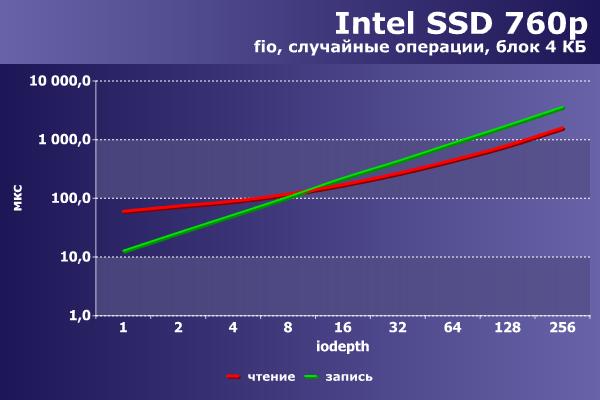 |
По скорости разница более чем заметна. Впрочем, как и по стоимости – 6 500 руб против 28 000 руб.











14 комментариев
Добавить комментарий
Автор — красавчик! Только укрепил меня в моём предположении о подобном ограничении. Вот объясните мне, кто-нибудь, зачем для дисковых операций ограничивать обработку потоков 1 (одним!!) ядром ЦПУ? Только не отвечайте идиотскими «это кроме тебя больше никому не нужно». И, ведь, такое же делает даже софт для Рамдрайва (рамдиска). Любой. Я в тестах вместо ожидаемых разумных, ну, хотя бы 70% от теоретической ПСП (у меня это ~100 GB/s по Аиде), я получаю только 10%. Всего 10%, Карл! /фейспалм.жпг/ Ладно, мне повезло и хоть один найденный Рамкеш этим не страдал и вместе с ним я в итоге получил-таки вменяемые цифры (под 50%). Эксперименты с Рамдрайвом я поэтому отложил в сторонку (иначе, как я спокойно людям буду в глаза смотреть и объяснять, почему и зачем Рамкеш стоит сверху на вешать Рамдрайв, ЛОЛ), т.к. Рамкеш почти также эффективен и верхом на nvme диске. Вот такие дела…
А за статью и эксперимент, автору — большой респект! Ещё бы у нас на overclockers.ru это опубликовали (там с недавних пор приплачивают за подобное).
Ответ Guest_N на комментарий
В целом да. Слишком большая пропасть между ними по объемам и скорости. Хотя конечно дружба разная бывает. Сценариев/конфигураций/вариантов в любом случае не меньше, чем заказчиков.
Добавить комментарий