Мозг способен воспринимать «невидимый» текст: как мы понимаем значение слов, которые не успели рассмотреть
Группа когнитивных нейробиологов из Франции и Великобритании экспериментально доказала, что человек способнен осознать абстрактный смысл визуального стимула, даже если его физические характеристики полностью стерты зрительными помехами. Результаты исследования, опубликованного в научном журнале Communications Psychology, показывают, что механизмы сознательного доступа к информации могут работать независимо от процессов раннего построения зрительного образа.
В ходе серии из семи экспериментов исследователи показывали добровольцам слова на экране на экстремально короткое время — от 12 до 48 миллисекунд. Стимулы были зажаты между быстро меняющимися строками случайных символов, которые блокировали нормальную обработку изображения зрительной корой. В обычных условиях испытуемые не могли различить буквы и утверждали, что ничего не видели.
Однако когда через 215 миллисекунд после исчезновения текста участники слышали через наушники подсказку — семантически связанное аудиослово (например, «дикобраз» после замаскированного слова «ёж»), — точность распознавания скрытого слова резко возрастала. Более того, участники уверенно заявляли, что действительно почувствовали присутствие этого слова на экране.

Самым примечательным оказалось то, что успешное осознание смысла происходило на фоне полной слепоты к физическим деталям стимула. Испытуемые, верно назвавшие скрытое слово, не могли определить, какими буквами оно было написано — заглавными или строчными, и в какой части экрана оно находилось. Точность ответов на эти вопросы оставалась на уровне случайного угадывания.
Это открытие ставит под сомнение классическую модель зрительного восприятия, согласно которой осознание смысла всегда происходит строго после успешного анализа физических параметров объекта.
Чтобы понять, почему этот результат стал неожиданностью для когнитивной науки, необходимо рассмотреть, как именно мозг обрабатывает входящую информацию и какие теории сознания конкурируют между собой в современных лабораториях.
Содержание
Теоретический спор: три фазы обработки информации
Процесс обработки любого сенсорного сигнала (будь то изображение, звук или тактильное ощущение) состоит из трех последовательных стадий, различающихся по своим нейрофизиологическим характеристикам:
- Прямой поток активации. Зрительный сигнал передается от сетчатки глаза через латеральное коленчатое тело в первичную зрительную кору (зона V1), а затем последовательно поднимается к высшим зрительным отделам (зоны V2, V3, V4, теменная и височная области). Этот путь занимает около 100 миллисекунд. Информация кодируется точно, но процесс протекает полностью неосознанно.
- Локальная обратная связь. Когда сигнал достигает высших отделов зрительной коры, запускаются обратные связи: высшие зоны отправляют сигналы обратно в нижележащие (например, из V2 в V1). Этот двусторонний обмен сигналами стабилизирует образ, позволяя мозгу отделить объект от фона и зафиксировать его форму.
- Глобальное вещание. На этом этапе функциональная связанность выходит за пределы зрительной коры. В процесс вовлекаются лобные, теменные и поясные области мозга. Информация становится доступной для сознания.
Современные теории сознания по-разному оценивают важность этих фаз. Сторонники теории локальной рекуррентной обработки утверждают, что сознательное восприятие возникает уже на второй фазе, внутри самой зрительной коры. С их точки зрения, если обратная связь заблокирована внешними помехами, осознать стимул невозможно.
Напротив, сторонники теории глобального нейронного рабочего пространства утверждают, что локальной обратной связи в зрительной коре недостаточно. Осознание происходит только на третьей фазе, когда сигнал транслируется на общемозговом уровне.
Из теории глобального рабочего пространства следовало теоретическое предсказание: если сознательный доступ относительно независим от ранних зрительных процессов, мозг может получить доступ к высокоуровневой абстрактной информации (смыслу слова) даже тогда, когда низкоуровневая сенсорная информация (форма букв) была уничтожена помехами. Прошедшее исследование было направлено на проверку этого предсказания.
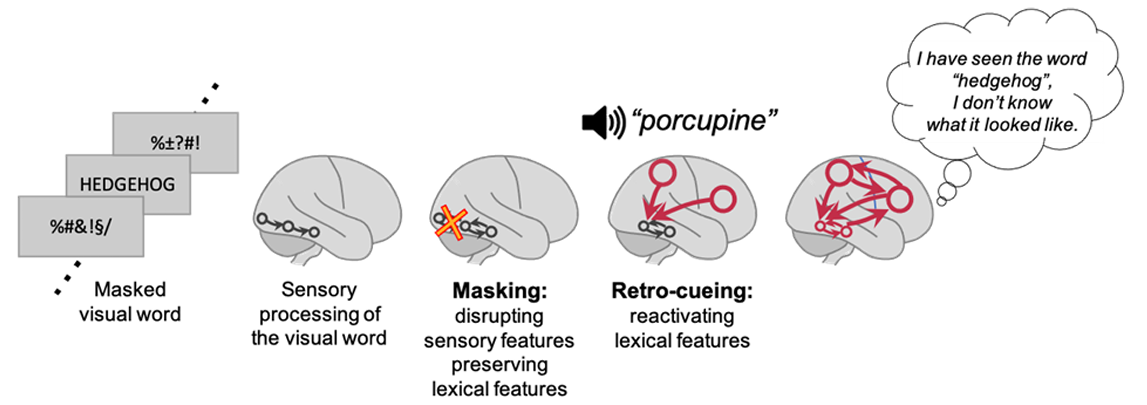
Как устроен эксперимент: метод маскировки и ретро-подсказки
Для прерывания локальной обратной связи в зрительной коре авторы использовали метод зрительной маскировки.
Целевое слово предъявляли участникам на CRT-мониторе с частотой обновления 85 Гц. Слово показывалось на сером фоне на 12, 24, 36 или 48 миллисекунд. Непосредственно до и сразу после него на экране демонстрировались маски — строки случайных символов (%#?&/!), полностью совпадающие по размеру, шрифту и контрастности с целевым словом. Это визуальное зашумление блокировало возможность обратной связи в зрительной коре: мозг фиксировал вспышку света, но не успевал распознать очертания букв.
Через 215 миллисекунд после исчезновения финальной маски участникам через наушники подавали аудиослово-подсказку. Ученые использовали два типа подсказок:
- Конгруэнтные (связанные по смыслу): например, скрытое слово «ёж» (hedgehog) и подсказка «дикобраз» (porcupine).
- Инконгруэнтные (несвязанные): скрытое слово «ёж» и подсказка.
Связи между словами определяли заранее на основе масштабных лингвистических тестов на свободные ассоциации.
После прослушивания подсказки участники выполняли несколько задач. Сначала они должны были произнести скрытое слово в микрофон. Если они не видели слова, инструкция требовала назвать любое слово наугад. Затем они указывали регистр букв (прописные или строчные) или пространственное положение слова (вверху или внизу экрана в зависимости от серии эксперимента). Наконец, они оценивали видимость слова по девятибалльной шкале.
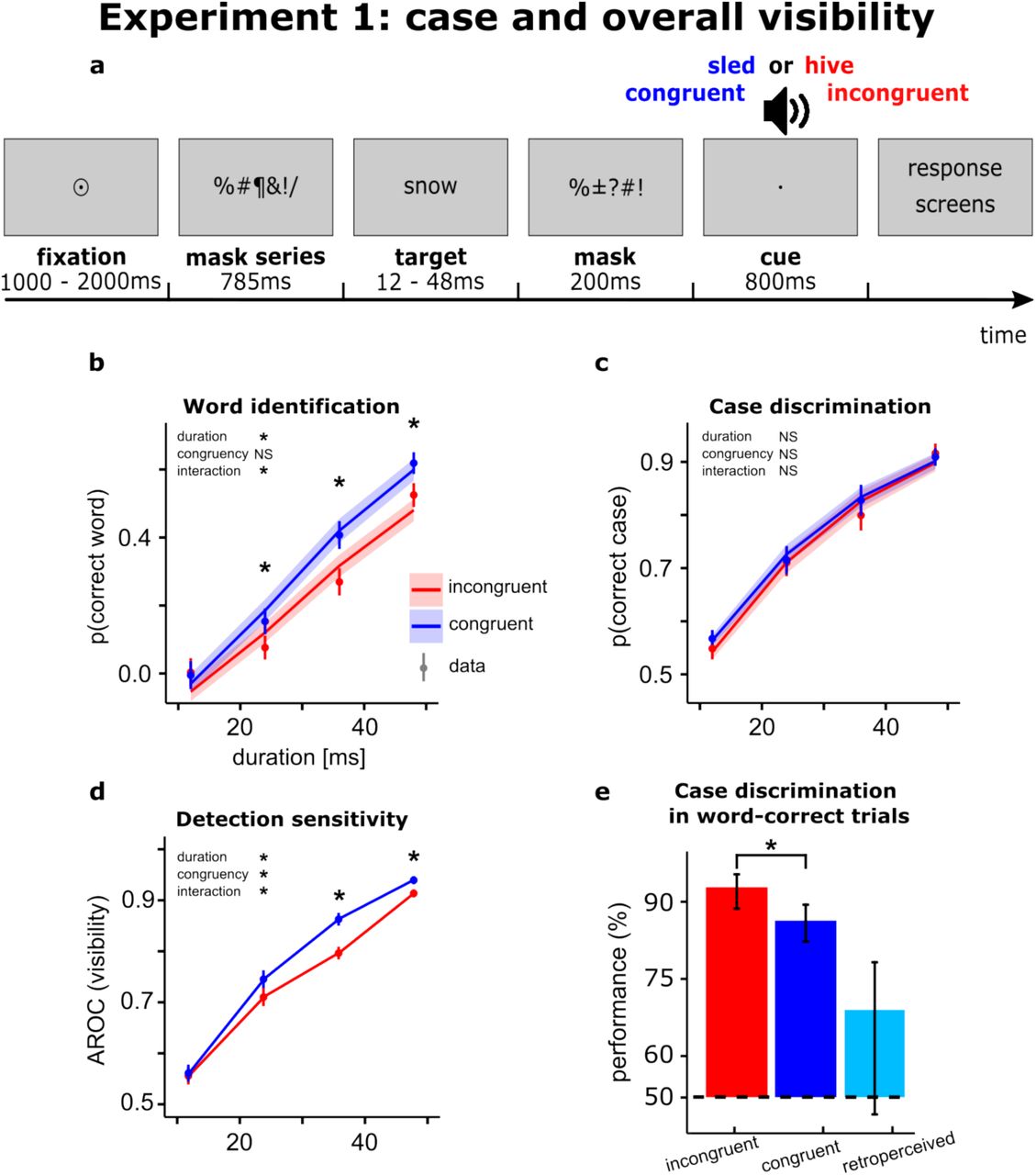
Защита от ошибок: как ученые исключили логическое угадывание
Главная трудность подобных исследований — доказать, что испытуемые действительно осознали скрытое слово, а не просто угадали его, основываясь на подсказке или случайных обрывках информации. Авторы работы применили четыре независимых метода математического и методологического контроля.
1. Коррекция показателей угадывания
Исследователи применили иерархический байесовский анализ и построили модель логистической регрессии, чтобы учесть чистую вероятность угадывания. Модель вычисляла базовый уровень ложных срабатываний в инконгруэнтных пробах (где подсказка никак не помогала угадать скрытое слово) и вычитала этот показатель из результатов конгруэнтных проб.
Даже после этой строгой математической коррекции чувствительность обнаружения слова (показатель AROC, рассчитанный по теории обнаружения сигналов) в условиях со связанной подсказкой оставалась высокой. Это доказывает, что ретро-подсказка действительно улучшала способность участников обнаруживать стимул.
2. Контроль частичного считывания букв (расстояние Левенштейна)
Существовала гипотеза, что участники могли заметить лишь отдельные буквы слови, услышав в наушниках «дикобраз», логически вычислить ответ.
Для проверки этой версии ученые проанализировали орфографическую структуру ошибочных ответов с помощью расстояния Левенштейна. Эта метрика оценивает количество замен, вставок и удалений букв, необходимых для превращения одного слова в другое.
Если бы испытуемые опирались на обрывки букв, их ошибочные ответы в конгруэнтных пробах все равно содержали бы те же буквенные элементы, что и скрытое слово. Однако статистический анализ показал, что ретро-подсказка не влияла на орфографическое сходство ошибок с целевым словом. Распознавание не строилось на частичном считывании букв.
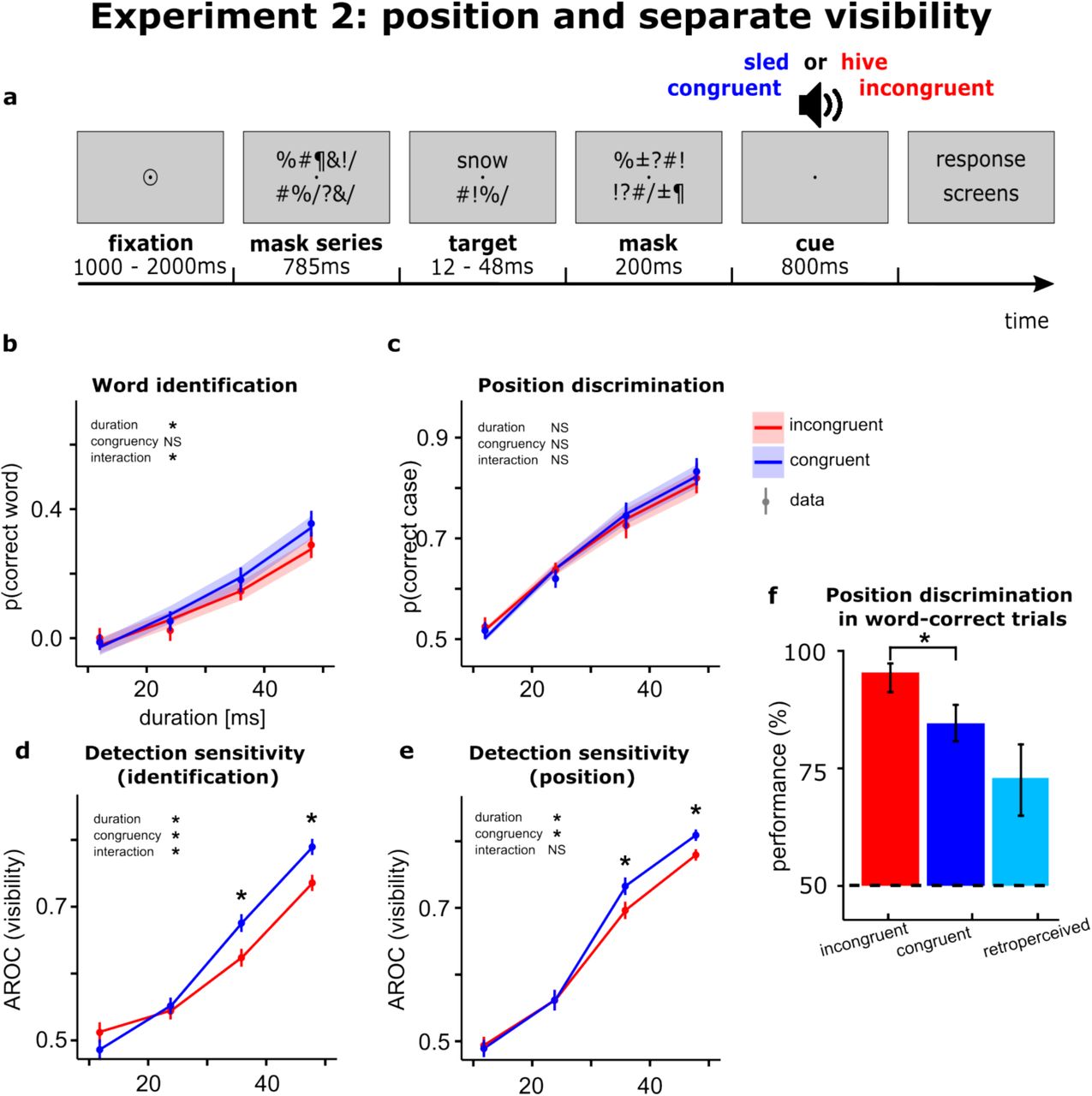
3. Анализ условных вероятностей
Ученые проанализировали точность определения регистра букв (прописные или строчные) исключительно в тех пробах, где скрытое слово было названо абсолютно правильно.
В пробах с несвязанными подсказками точность определения регистра в таких случаях была очень высокой — 92,9%. Это логично: назвать скрытое слово без подсказки участники могли только тогда, когда зрительная маскировка не сработала и они четко рассмотрели его на экране.
Однако в пробах со связанными подсказками точность определения регистра среди правильно названных слов снизилась до 86,3%. Это статистически значимое снижение доказывает, что часть правильных ответов была получена исключительно за счет семантической активации через аудиоподсказку, без визуального доступа к очертаниям букв.
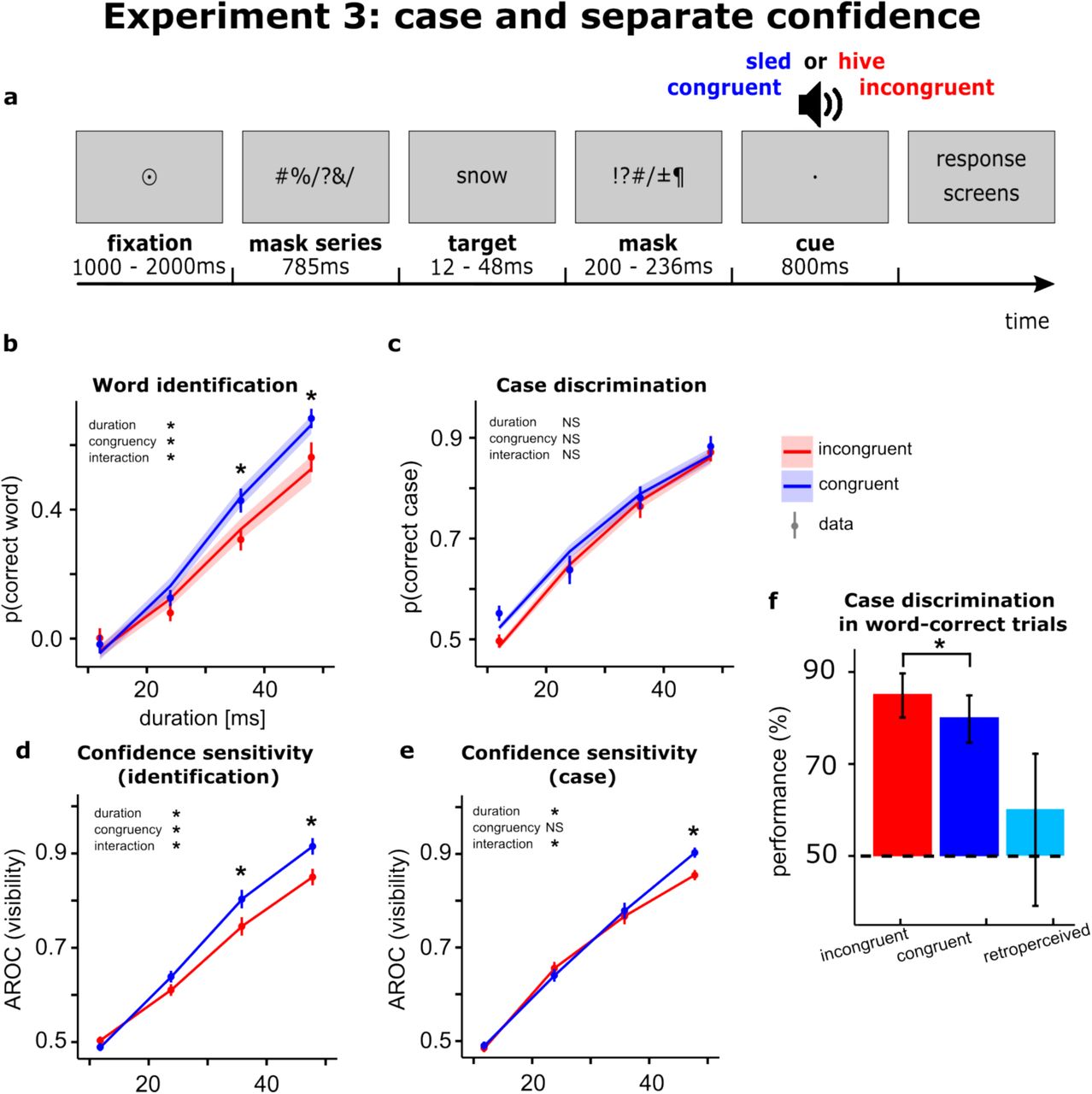
4. Временной контроль (пред-подсказки против ретро-подсказок)
В экспериментах с 4-го по 7-й ученые проверили, играет ли роль время подачи аудиосигнала. Они сравнили ретро-подсказки (подаваемые через 248 миллисекунд после стимула) с пред-подсказками (подаваемыми за 1,6 секунды до стимула).
При подаче пред-подсказки у участников значимо улучшалось как обнаружение слова, так и способность правильно определять его шрифт. Мозг заранее настраивал зрительную систему на восприятие конкретного объекта.
При подаче ретро-подсказки улучшалось только обнаружение слова, но точность распознавания регистра букв оставалась на уровне случайного угадывания. Это подтверждает, что ретро-подсказка работает иначе: она не предотвращает разрушение зрительного образа маской, а извлекает уже угасший абстрактный лексический след из памяти.
Новая модель восприятия: предиктивный мозг и обратная иерархия
Результаты исследования предоставляют новые доказательства в пользу двух фундаментальных концепций когнитивной науки.
Теория обратной иерархии
Теория обратной иерархии утверждает, что при восприятии информации первый неосознанный поток сигналов быстро доходит до высших отделов мозга, обеспечивая мгновенное понимание общей сути и значения объекта (так называемое gist-perception). Детализация же изображения (определение точного шрифта, регистра букв или координат) требует обратного процесса — направления внимания сверху вниз, обратно к первичным сенсорным зонам.
Если эти первичные зоны заблокированы маскировкой, нисходящий поиск деталей завершается неудачей. Однако высокоуровневое представление о значении слова уже сформировано в височной коре и может быть успешно извлечено при помощи слухового сигнала.
Ретроспективный мозг
Исследование расширяет рамки концепции предиктивного кодирования. Мозг работает не только в режиме прогнозирования будущего. Он постоянно осуществляет ретроспективную реконструкцию — использует информацию из настоящего времени (звук в наушниках), чтобы стабилизировать, переписать и вывести в сознание события, которые уже произошли в прошлом и физически исчезли из органов чувств.
Сознание как мозаика
Данная работа демонстрирует, что наше сознательное восприятие устроено гораздо более фрагментарно и модульно, чем принято считать. Субъективный когнитивный опыт не является неделимым блоком. Мозг способен обрабатывать, стабилизировать и выводить в сознание смысловое значение стимула полностью независимо от его физической и сенсорной формы.
Этот вывод открывает новые перспективы в изучении природы когнитивных различий у людей (например, при афантазии — неспособности к визуализации образов при сохранении понятийного мышления). Кроме того, понимание механизмов независимой обработки смысла и физической формы может быть использовано при создании архитектур искусственного интеллекта, способных раздельно обрабатывать семантическую информацию и низкоуровневые сенсорные параметры сигналов.
Источник: Communications Psychology











2 комментария
Опираясь на полученные данные, хотелось бы предложить несколько теоретических шагов для расширения интерпретации, которые могут помочь еще глубже интегрировать эти результаты в современный научный контекст:
1. Восприятие и память как единый реконструктивный континуум
Авторы обоснованно вводят концепт «ретроспективного мозга». Логичным развитием этой идеи может стать отказ от жесткого механистического разделения «онлайн-восприятия» и «кратковременной памяти». В рамках парадигмы предиктивного кодирования оба процесса опираются на одну и ту же генеративную модель, различаясь лишь временным масштабом и источниками сенсорных ошибок. Аудиоподсказка не «реактивирует угасший энграммный след» в классическом смысле, а выступает новым апостериорным контекстом (prior), позволяющим системе пересобрать (reconstruct) перцептивный опыт. Граница между «я вижу это сейчас» и «я вспомнил это только что» оказывается не столько архитектурным барьером, сколько феноменологической иллюзией, возникающей при разной степени уверенности (precision weighting) предсказательной модели.
2. Вычислительная экономика: диссоциация семантики и физических атрибутов
Наблюдаемая диссоциация (осознание смысла при слепоте к регистру и локации) отлично иллюстрирует принцип минимизации свободной энергии. Физические детали (шрифт, координаты) несут высокую энтропию; их удержание требует ресурсоемкой локальной рекуррентной обработки в ранних зрительных зонах. Маскировка прерывает этот цикл, и система, минимизируя метаболические затраты, отбрасывает этот уровень. Семантический же уровень (например, концепт «ёж») представляет собой высокоабстрагированную, сжатую предсказательную модель (low-entropy prior). Для закрытия ошибки предсказания на этом уровне системе не нужны пиксели — ей достаточно активировать семантический указатель. Мозг оптимизирует не хранение сырых данных, а вычислительную стоимость их предсказания.
3. От «театра сознания» к глобальной доступности интегрированных сигналов
В тексте отмечается «мозаичность» сознания. В свете этих данных классическую метафору «театра сознания» (где неявно предполагается скрытый наблюдатель-гомункулус, смотрящий на целостную сцену) продуктивнее заменить моделью глобальной доступности (global availability). Сознательный отчет формируется только из тех модулей, которые успешно завершили цикл минимизации ошибки и получили доступ к фронто-париетальной сети. Если ранние зрительные зоны не смогли разрешить неопределенность из-за маски, этот сигнал просто не проходит порог глобального вещания. Отсутствие у испытуемых жалоб на «неполноту картинки» подтверждает, что единого центрального наблюдателя нет: феноменологический опыт складывается исключительно из успешно интегрированных предсказаний, доступных системе в данный момент.
Данный сдвиг фокуса — от пассивного извлечения признаков к активному конструированию реальности на основе ресурсных ограничений — имеет значение не только для нейрофизиологии (например, для понимания механизмов афантазии), но и для машинного обучения. Архитектуры ИИ, способные разделять семантическое ядро (latent space) и сенсорную оболочку, опираясь на вычислительную стоимость их обработки, могут стать принципиально более устойчивыми к шуму и состязательным атакам (adversarial attacks).
Спасибо команде за сильную эмпирическую работу!
Кстати! Косвенно, эти результаты подтверждают некоторую обоснованность опасности «25-го кадра», возникающего перед глазами, как раз на 40 мс. Интересное совпадение с диапазоном времени, используемым исследователями, не правда ли?
Добавить комментарий