Число шейдерных процессоров выросло в 2.5 раза!
Gigabyte GV-R485-512H-B (RADEON HD 4850) 512MB PCI-E
HIS RADEON HD 4850 512MB PCI-E
MSI R4850-72D512 (RADEON HD 4850) 512MB PCI-E
Powercolor RADEON HD 4850 512MB PCI-E

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Часть 1: Теория и архитектура
Несколько дней назад мы писали о линейке Geforce GTX 200 — свежих решениях верхнего ценового диапазона от компании Nvidia, теперь настало время и для новой продукции AMD. Но начнем мы с видеокарты, согласно рыночному позиционированию, не претендующей на конкуренцию с линейкой GTX 200. Для соперничества с GTX 280, самой дорогой одночиповой картой Nvidia, у AMD планируются двухчиповые решения на основе высокочастотной версии RV770. Как наши читатели знают, AMD отошла от ранее используемой стратегии по выпуску специальной версии чипа для high-end сегмента. Вместо этого для верхнего high-end выпускаются мультичиповые решения (два чипа на одной карте работают в режиме CrossFire). AMD отмечает следующие проблемы, присущие крупным high-end чипам: слишком высокие цена и потребление энергии для большинства покупателей, большая временная задержка с освоением новых техпроцессов (менее сложные чипы проще переводить на более «тонкие» технологии) и т.п.
В плюсах же новой («мультичиповой») стратегии AMD: возможность выпуска оптимальных решений для всех ценовых диапазонов, используя карты с разным количеством чипов, низкая себестоимость и быстрое внедрение новых технологий. Разумеется, есть у мультичипов и недостатки. Во-первых, наиболее часто используемый метод мультичипового рендеринга: Alternate Frame Rendering (AFR) хоть и даёт наибольший прирост в количестве кадров в секунду, но не увеличивает плавность рендеринга аналогично росту «одночипового» FPS. В результате, на мультичиповых системах нередки ситуации с высоким FPS, но лагом управления и отсутствием плавности.
Впрочем, о том кто станет «царем горы» на графическом олимпе нынешним летом, мы узнаем не раньше, чем протестируем Radeon HD 4870 X2 в сравнении с Geforce GTX 280. А сейчас перед нами потенциальный лидер в совершенно другом, утилитарном сегменте рынка от $200 до $300, то есть — среди видеокарт достаточно мощных для современных игр в высоких разрешениях с максимальными настройками, но и не слишком дорогих, не особо требовательных по питанию, небольших и не очень греющихся. Справились ли в AMD с задачей выпуска идеальной карты для наиболее массового сегмента рынка? Вот в сегодняшней статье мы с этим и разберёмся.
И в первую очередь радует наличие полноценного архитектурного обновления. Так что, теоретическая часть обещает быть весьма интересной, ведь архитектурные изменения в чипе очень важные и долгожданные. Перед прочтением данного материала мы рекомендуем внимательно ознакомиться с базовыми теоретическими материалами DX Current, DX Next и Longhorn, описывающими различные аспекты современных аппаратных ускорителей графики и архитектурные особенности предыдущей продукции Nvidia и AMD.
- [06.06.05] Longhorn — ускорители и шейдеры для DirectX 10
- [01.03.05] DirectX.Update — Ускорители 3D-графики: полшага вперед
- [09.04.04] DX.Next: ближайшее и ближнее будущее аппаратного ускорения 3D-графики
Эти материалы достаточно точно спрогнозировали текущую ситуацию с архитектурами видеочипов, оправдались многие предположения о будущих решениях. Подробную информацию об унифицированной архитектуре AMD R6xx на примере предыдущих чипов (в том числе и RV670) можно найти в следующих статьях:
- [14.05.07] Долгожданное появление DirectX 10-семейства от AMD/ATI
- [04.07.07] ATI RADEON HD 2400-2600-серии: новые решения от AMD для среднего и бюджетного секторов с поддержкой DirectX 10
- [19.11.07] ATI RADEON 3850/3870 (RV670): 320 шейдерных процессора с 256-битной шиной памяти
Итак, рассмотрим подробные характеристики двух новых видеоплат серии RADEON HD 4800, основанных на новом чипе RV770.
Графические ускорители серии RADEON HD 4800
- Кодовое имя чипа RV770
- Технология 55 нм
- 956 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10.1, в том числе и новой шейдерной модели — Shader Model 4.1, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 256-битная шина памяти: четыре контроллера шириной по 64 бита с поддержкой GDDR3/GDDR5
- Частота ядра 625-750 МГц
- 10 SIMD ядер, включающих 800 скалярных ALU для расчётов с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 и FP64 точности в рамках стандарта IEEE 754)
- 10 укрупненных текстурных блоков, с поддержкой FP16 и FP32 форматов
- 40 блоков текстурной адресации
- 160 блоков текстурной выборки
- 40 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 16 блоков ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 16 отсчетов за такт (в т.ч. и для режимов MSAA 2x/4x, в т.ч. для буферов формата FP16), в режиме без цвета (Z only) — 64 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV, DisplayPort
Спецификации карты RADEON HD 4870
- Частота ядра 750 МГц
- Количество универсальных процессоров 800
- Количество текстурных блоков — 40, блоков блендинга — 16
- Эффективная частота памяти 3600 МГц (4*900 МГц)
- Тип памяти GDDR5
- Объем памяти 512 мегабайт
- Пропускная способность памяти 115 гигабайт в сек.
- Теоретическая максимальная скорость закраски 12.0 гигапикселей в сек.
- Теоретическая скорость выборки текстур 30.0 гигатекселей в сек.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI, DisplayPort
- Энергопотребление до 160 Вт (два 6-штырьковых разъёма)
- Двухслотовый дизайн
- Рекомендуемая цена $299
Спецификации карты RADEON HD 4850
- Частота ядра 625 МГц
- Количество универсальных процессоров 800
- Количество текстурных блоков — 40, блоков блендинга — 16
- Эффективная частота памяти 2000 МГц (2*1000 МГц)
- Тип памяти GDDR3
- Объем памяти 512 мегабайт
- Пропускная способность памяти 64 гигабайта в сек.
- Теоретическая максимальная скорость закраски 10.0 гигапикселей в сек.
- Теоретическая скорость выборки текстур 25.0 гигатекселя в сек.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI, DisplayPort
- Энергопотребление до 110 Вт (один 6-штырьковый разъём)
- Однослотовый дизайн
- Рекомендуемая цена $199
Итак, компания AMD продолжает выпуск графических решений по 55 нм технологическим нормам. По сравнению с используемым Nvidia для топовых чипов 65 нм, более совершенный технологический процесс даёт определённые преимущества: меньшую площадь ядра, увеличенный частотный потенциал и процент выхода годных на высоких тактовых частотах, а также, вероятно, и меньшую себестоимость. По сравнению с RV670, новый чип ещё более эффективен энергетически. Он потребляет довольно мало энергии, а обладает значительно более высокой производительностью, чем предыдущие решения.
Как видно, маркировка разных решений осталась неизменной с предыдущей серии, поменялась только первая цифра. В остальном, позиционирование HD 4870 и 4850 примерно совпадает с положением HD 3870 и 3850 во время их выпуска. Естественно, серия HD 3000 никуда не уходит, а спускается в нижние ценовые диапазоны.
Два варианта в серии, как обычно у AMD, отличаются тактовыми частотами, и видеочипа и памяти. Но это не единственное отличие между моделями карт — на старшей установлена память нового типа — GDDR5, дающая большую полосу пропускания, что особенно сильно сказывается на производительности в сложных режимах со сглаживанием. Из других отличий старшего варианта — более высокое потребление энергии и оснащение двухслотовой системой охлаждения.
Объём видеопамяти у обеих карт в референсном виде одинаков — по 512 мегабайт. Хотя современные игры очень требовательны к объёму видеопамяти, они используют обычно до 500-600 мегабайт, и лишь иногда более. Поэтому объём памяти в 512 мегабайт является оптимальным количеством памяти на данный момент. Хотя было бы очень неплохо, если бы некоторые из выпускаемых партнёрами AMD видеокарт RADEON HD 4870 имели больший объём — один гигабайт. Для самых требовательных игр вроде Crysis это важно.
Архитектура чипа RV770
Основной целью при разработке нового чипа было дальнейшее повышение эффективности. Перед инженерами была поставлена задача: добиться двукратного преимущества в теоретической производительности, по сравнению с чипом предыдущего поколения — RV670. Также, в свете последних тенденций, очень важно было сделать упор на улучшение возможностей чипа по неграфическим вычислениям. Заодно впервые была применена GDDR5 память и перекрыт психологический барьер скорости вычислений в один терафлоп, до которого чуть-чуть не дотянула Nvidia со своим GT200.
Архитектура RV770 сочетает в себе некоторые решения из предыдущей архитектуры R6xx, но в ней было сделано множество изменений, направленных на улучшение производительности и эффективности. Рассмотрим схему нового чипа:
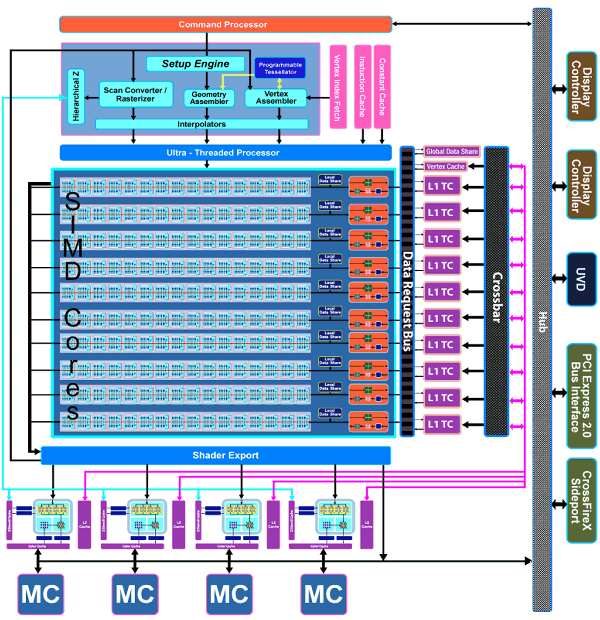
Сразу видно, что архитектура RV770 претерпела достаточно много изменений, по сравнению с архитектурой, известной нам по чипам R600 и RV670. В ней были сделаны как количественные, так и качественные изменения, устранены многие узкие места. Но давайте остановимся на всех изменениях по порядку…
Основная часть видеочипа RV770 состоит из десяти SIMD ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров, всего их в чипе 160 штук. Суперскалярность этих процессоров не изменилась со времён RV670, поэтому можно считать, что чип содержит 160*5=800 скалярных 32-битных потоковых процессоров. Для 64-битных расчётов двойной точности используются эти же блоки, снижается только темп расчётов.
Также в чипе проведены другие модификации: изменены текстурные блоки TMU, увеличено их количество, ускорены блоки ROP при сохранении их количества, кардинально изменена архитектура памяти и кэширования, введена поддержка нового типа памяти GDDR5, также сделаны и другие изменения, увеличивающие производительность исполнения геометрических шейдеров и параллельных неграфических расчётов.

Как мы уже сказали, каждое из 10 ядер SIMD содержит по 16 суперскалярных потоковых процессоров (или 80 скалярных) и 16 килобайт локальной памяти для хранения данных и имеет собственный блок управления потоками. Также, в отличие от R6x0 и RV670, блоки TMU «привязаны» к SIMD, каждый из них имеет по четыре выделенных текстурных модуля и свой L1 текстурный кэш. SIMD ядра могут обмениваться друг с другом информацией при помощи 16 килобайт глобальной памяти. Как видите, мощность текстурников в новом чипе промасштабирована вместе с числом шейдерных процессоров, и соотношение между ALU и TMU равно 4:1.
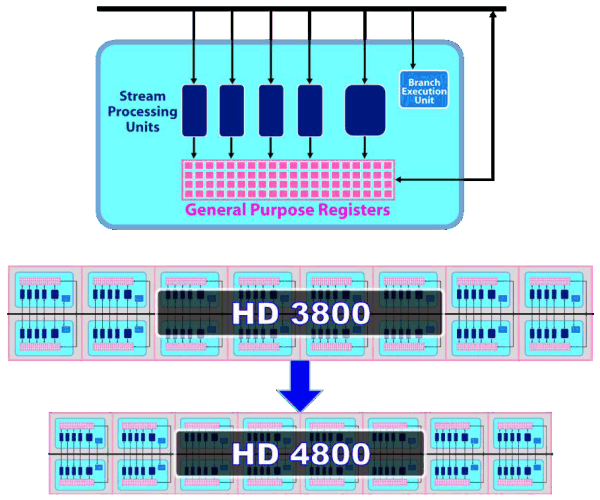
Потоковые процессоры остались, по сути, теми же, что и в RV670, но была увеличена их плотность (на картинке указано в масштабе), что позволило довести число потоковых процессоров до 800 шт при неизменном техпроцессе. А для увеличения энергетической эффективности используется более агрессивный clock gating, позволяющей отключать блоки логики для снижения потребления энергии.
Кроме того, суперскалярный дизайн потоковых процессоров позволил AMD проще и эффективнее реализовать поддержку вычислений двойной точности (FP64), используя те же вычислительные блоки. В результате, даже с учетом того, что в GT200 были добавлены специальные SP для FP64 расчётов, RV770 обладает значительно большей производительностью в таких вычислениях, теоретическая пиковая цифра — до 240 гигафлопов.
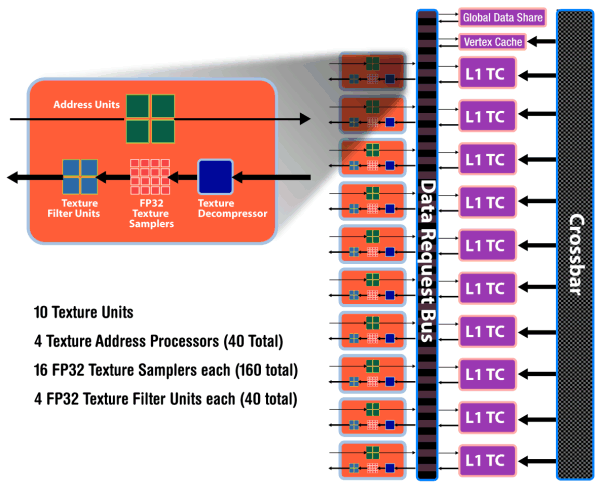
А вот блоки текстурирования изменились очень сильно, теперь они привязаны к SIMD, а их эффективность значительно улучшена. Проектировщики убрали выделенный пул TMU, известный по предыдущим поколениям чипов, реализовав решение, очень похожее на то, что мы видим у Nvidia, с блоками TMU, включенными в состав SIMD ядер.
Была убрана возможность выборок без фильтрации, которая применялась ранее отдельно для вершинных данных. В новом чипе и тексели и вершины выбираются одними и теми же блоками, что также аналогично решению в G8x и далее. С другой стороны, каждый из 40 блоков текстурирования в RV770 стал несколько слабее, чем каждый из 16-ти в RV670, но увеличенное их количество, вместе с повышенными частотами, должно дать приличный прирост скорости текстурирования.
В целом, можно ожидать до 2.5-кратного увеличения производительности при билинейной фильтрации 32-битных текстур, и 1.25-кратного — для 64-битных. Из других особенностей — удвоенная полоса пропускания к текстурному кэшу, по сравнению с RV670 и возможность выборки до 160 текстурных значений Fetch4/Gather4 за один такт, что также должно повлиять на увеличение производительности.
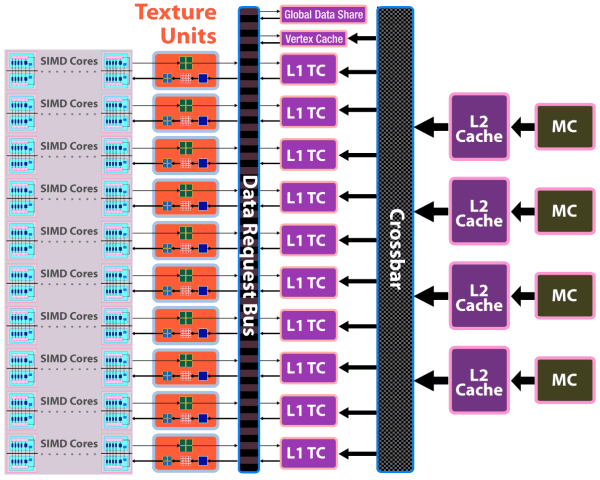
В чипе применен новый дизайн блоков кэширования: вершинный кэш отдельный, кэш второго уровня привязан к четырём 64-битным каналам памяти, L1 кэши хранят уникальные данные для каждого блока SIMD, что увеличивает эффективность кэширования. Также увеличена и пропускная способность: до 480 ГБ/с для текстурного кэша первого уровня, до 384 ГБ/с между кэшем L1 и L2.
Все вышеуказанные изменения в текстурных блоках и кэшировании привели к тому, что текстурирование у RV770, судя по feature тесту из 3DMark Vantage, в два раза более эффективно, чем у конкурирующих чипов Nvidia (и G92 и GT200). Рассмотрим схему блоков ROP:
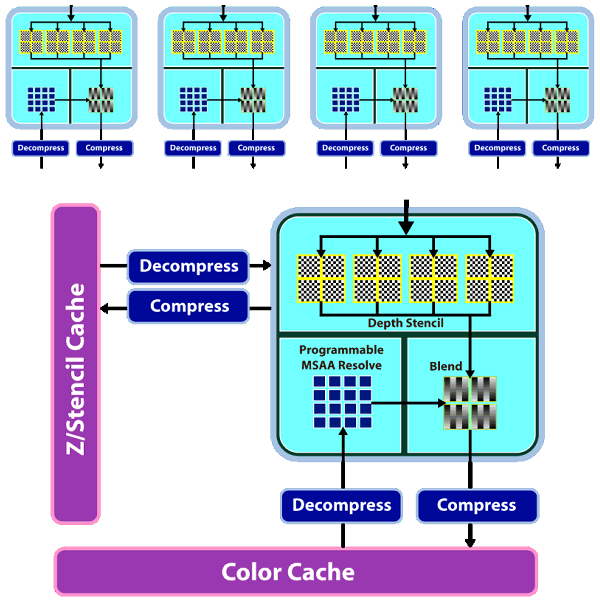
Как видно на схеме, качественных изменений в блоках ROP не так много. Зато, хоть блоки ROP и остались в том же количестве, что и в RV670, теперь они умеют обрабатывать за такт вдвое большее количество пикселей в большинстве случаев, что особенно важно при включенном MSAA. Теперь алгоритмы MSAA 2x и 4x вообще почти что «бесплатны», по крайней мере, с точки зрения работы ROP. Вот сравнительная таблица темпа записи пикселей во фреймбуфер в различных режимах:
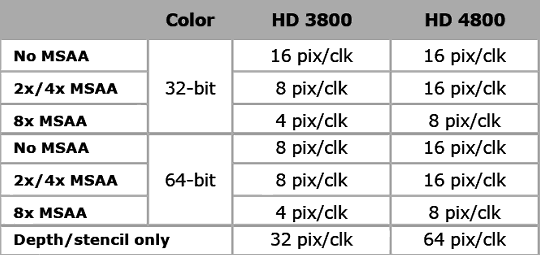
Почти во всех режимах эффективность ROP удвоена, кроме самого простого — 32-битного цвета без MSAA. Нужно отметить и Custom Filter Anti-Aliasing (CFAA). Уже прошлое поколение видеочипов AMD предлагало специализированные фильтры сглаживания, названные Custom Filter Anti-Aliasing. Мы довольно подробно рассматривали этот метод в предыдущих материалах, и наиболее интересной возможностью по сглаживанию на чипах AMD является метод краевого сглаживания (edge detect), используемый в алгоритмах 12x и 24x CFAA.
Это наиболее качественный метод, который использует шейдерную мощь чипов RV670 и RV770 по обработке изображения, к которому уже был применен MSAA. Метод основан на поиске краёв полигонов (специальный фильтр) и дополнительной фильтрации этих участков изображения. Метод не требует дополнительной видеопамяти по сравнению с режимами 4x и 8x MSAA, а также работает вместе с адаптивным сглаживанием. RV770 отличается небольшими улучшениями, направленными на ускорение этого и других методов, в том числе специальным быстрым линком между ROP и шейдерными процессорами.
Интересно, что по некоторым данным, RV770 не использует шейдерные процессоры при MSAA, как это было сделано в чипах R6xx и RV670. Для стандартных алгоритмов MSAA используются возможности аппаратных блоков ROP, и только для упомянутого программируемого CFAA — шейдерный ресолв.
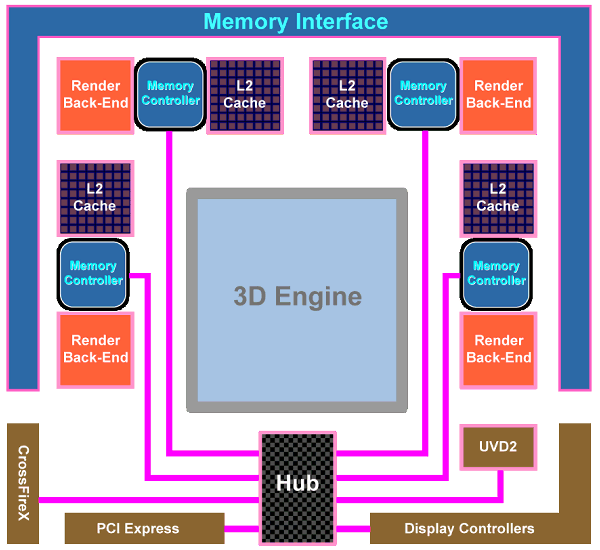
Из других важных изменений в чипе — смена ранее широко разрекламированной, но так и не ставшей удачной, кольцевой шины памяти (ring bus) на архитектуру с центральным хабом. В RV770 контроллеры памяти расположены по краям чипа, рядом с основными потребителями трафика, а хаб распределяет потоки данных между уже упомянутыми блоками, а также PCI Express, CrossFireX, UVD2, контроллерами вывода.
По оценкам компании, новый дизайн интерфейса памяти вызвал значительное увеличение эффективности использования полосы пропускания. В дополнение к этому, контроллер поддерживает новые модули памяти GDDR5, работающие на эффективно учетверённой частоте до 3.6-4 ГГц и выше, что даёт ПСП до 120 ГБ/с с применением недорогого 256-битного интерфейса.
Себестоимость важна, ведь для повышения ПСП у GDDR3 памяти приходится использовать 512-битную шину, это приводит к тому, что и чип увеличивается, и его упаковка. Да и сами карты становятся больше и сложнее, потребляя всё больше энергии. Переход на использование GDDR5 позволяет увеличить производительность в 2-3 раза при даже меньших размерах чипов при меньшем потреблении энергии.
Компания AMD активно участвовала в разработке стандарта GDDR5, вместе со всеми основными производителями памяти (Hynix, Qimonda и Samsung) и JEDEC. Разработка этого типа памяти заняла около трёх лет от начала разработок до окончательной спецификации, а в AMD — ещё больше. Предполагается, что GDDR5 будет работать на скоростях вплоть до 7 ГГц эффективной (учетверённой) частоты. Первые чипы, поддерживающие напряжение 1.5 В (в отличие от 2.0 В для GDDR3) и имеющие плотность 0.5-2 Гбит, предлагают скорость до 1000*4=4.0 ГГц.
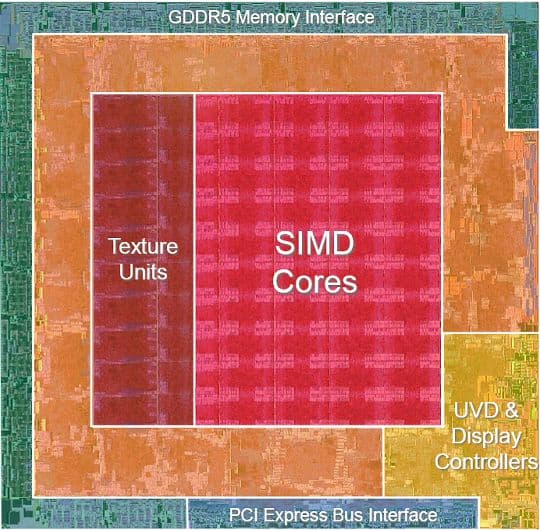
В архитектурной части остаётся привести схему чипа, где указаны занимаемые различными блоками площади GPU. Как видно, большую часть чипа занимают 800 потоковых процессоров, значительные части чипа остались за текстурными процессорами и различными контроллерами. А оставшаяся часть, судя по всему, занята блоками ROP, кэшами второго уровня и другой вспомогательной логикой.
Точно как и в GT200, в RV770 была увеличена эффективность исполнения геометрических шейдеров, а точнее — производительность создания вершинных данных. Вчетверо увеличено количество поддерживаемых потоков исполнения геометрических шейдеров, и сгенерированные в них вершины могут храниться на чипе в большем количестве.
Заявлено, что модификации подвергся и блок тесселяции. Теперь он совместим (что бы это ни значило) с DirectX 10 и 10.1, и также поддерживает instancing. На скорость исполнения геометрических шейдеров мы обязательно посмотрим в наших синтетических тестах в следующей части статьи, а про тесселяцию подробнее написано в базовом материале R600.
Подводя итоги, чип можно назвать RV-«работа над ошибками»-770. Как мы видим, были исправлены все явные ошибки и недостатки дизайна RV670. Блоки ROP хоть и остались в неизменном количестве, но теперь они работают вдвое быстрее, выполняя за такт вдвое большее количество работы в большинстве случаев. Это привело к тому, что алгоритмы MSAA 2x и 4x для серии RADEON HD 4800 почти «бесплатные» с точки зрения работы ROP, хотя ограничения ПСП всё же могут снизить производительность.
Но это не единственные изменения, работа над ошибками продолжилась и для TMU, которые были переработаны полностью. Убран выделенный пул TMU, а новое решение включает блоки TMU в состав каждого из десяти SIMD ядер. Из других важных изменений можно отметить смену кольцевой шины памяти ring bus на хабовую архитектуру. Интересно, что почти все исправления приводят чип RV770 ближе к тому, что мы видим в решениях Nvidia. Похоже, в ATI(AMD) научились признавать свои ошибки и исправлять их. Похвально, остаётся проверить скорость новых решений на практике.
Неграфические вычисления
Немудрено, что оба основных производителя видеочипов в последнее время уделяют особое внимание неграфическим вычислениям на видеокартах. Постепенно, вычисления на GPU начинают внедряться и в научные сферы, и в обычное ПО, которое используется нами в повседневных задачах. Так, уже вышли или скоро выйдут обновленные версии решений по обработке изображений (Adobe Photoshop), обработке и перекодированию видеоданных (Adobe Premier, Cyberlink PowerDirector). А аппаратное ускорение физических расчётов в играх уже используется в Nvidia PhysX.
Для того чтобы увеличить производительность и гибкость неграфических параллельных расчётов, в RV770 было сделано несколько изменений:
- Ускоренные расчёты с плавающей точкой (FP64). Пиковая производительность текущих решений на основе чипа RV770 достигает 240 гигафлопов, что примерно в пять раз превышает производительность самого быстрого CPU с четырьмя ядрами. Точность расчётов соответствует требованиям стандарта IEEE 754.
- Увеличенная производительность случайной записи и чтения (MemExport/MemImport). Операции scatter и gather выполняются на удвоенной скорости, по сравнению с RV670, максимальная производительность — шестнадцать 64-битных операций экспорта или восемь 128-битных за один такт.
- Быстрое создание вычислительных потоков, означающее сниженные накладные расходы для параллельных вычислений.
- Обмен данными между вычислительными потоками. На каждый блок SIMD выделена локальная память, отдельная от текстурного кэша, также возможен глобальный обмен данными между всеми блоками SIMD. По данным компании, эти изменения вызвали семикратный прирост производительности в расчётах быстрого преобразования Фурье (FFT).
- Быстрые операции битового сдвига, доступные всем блокам SP. По сравнению с предыдущим поколением, достигнуто увеличение производительности в 12.5 раз. Это изменение ускоряет задачи обработки и кодирования видеоданных, а также алгоритмов сжатия и шифрования.
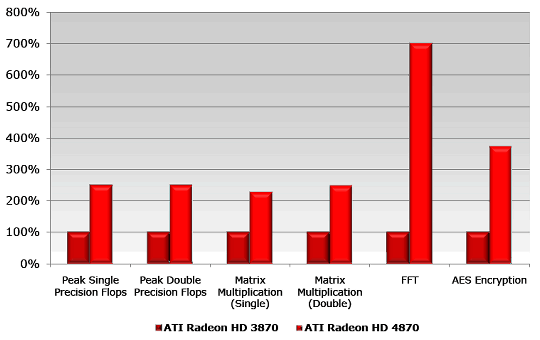
Компания AMD приводит такой график относительной производительности RV670 и RV770 в синтетических расчётных задачах. Средняя разница в скорости между двумя поколениями равна 2.5-3 раза (что примерно соответствует увеличенному числу потоковых процессоров), но максимальный прирост был получен в алгоритме быстрого преобразования Фурье (FFT) — разница в скорости составила семь раз. Почти в 4 раза ускорилось шифрование по алгоритму AES. Вот это уже — влияние изменений в архитектуре.
Технология ATI Avivo
В RV770 встроен чип обработки видеоданных Unified Video Decoder второго поколения (UVD 2). Он аппаратно декодирует видеоданные во всех важнейших форматах: H.264, VC-1 и MPEG2, имеет возможность одновременного декодирования двух полноформатных (1080p) потоков, улучшенные возможности по постобработке видео, в дополнение к ранее известным добавились масштабирование DVD видео до HD разрешений, а также динамическая регулировка контрастности.
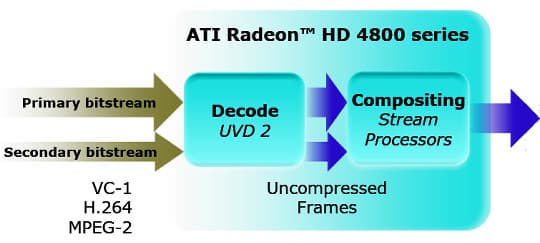
Из других важных нововведений — поддержка 24- и 30-битных устройств вывода изображения на разрешениях до 2560x1600 по новому разъему DisplayPort. Никуда не делась и поддержка HDMI вывода при помощи специальных переходников DVI-2-HDMI, поддерживающего разрешения до 1920x1080. А из реальных улучшений можно отметить звуковой контроллер. Теперь он поддерживает несжатый поток стереозвука с частотой дискретизации 48 кГц или восьмиканальный (7.1) поток формата AC3 с битрейтом до 6.144 Мбит/с.
Произошел новый всплеск интереса к аппаратно ускоренному кодированию и перекодированию видеоданных из одного формата в другой. У AMD это называется Accelerated Video Transcoding (AVT), поддерживаются форматы H.264 и MPEG2. Заявлено перекодирование видеопотоков формата 1080p быстрее, чем 30 FPS — то есть, быстрее реального времени, «на лету».
По сути, скоростные характеристики кодирования на GPU заявлены примерно те же, что и у Nvidia — перекодирование часового ролика видео в формате 1080p заняло почти 10 часов на универсальном процессоре Core 2 Duo E8500 и 32 минуты на решении из серии RADEON HD 4800. То есть, новые GPU около 20 раз быстрее, чем довольно быстрые двухъядерники. Для полного счастья вскоре должен выйти Cyberlink PowerDirector 7 с поддержкой кодирования при помощи видеочипов.
Управление питанием PowerPlay
Технология динамического управления питанием ATI PowerPlay, пришедшая с видеочипов для ноутбуков, получила дальнейшие усовершенствования. Напомним, что суть технологии в том, что специальная управляющая схема в чипе отслеживает его загрузку работой и определяет оптимальный рабочий режим, управляя рабочей частотой чипа, памяти, напряжением питания и другими параметрами, оптимизируя энергопотребление и тепловыделение. Так, в 2D режиме при невысокой загрузке GPU напряжение и частоты будут максимально снижены, как и частота вращения вентилятора, в режиме небольшой 3D нагрузки все параметры установятся на средние значения, а при максимальной работе GPU частоты с напряжением будут выставлены в наибольшее значение.
Для управления питанием на чип интегрирован соответствующий микроконтроллер, постоянно проводящий мониторинг температурных датчиков и активность шин, как внутричиповых, так и внешней PCI Express. Управляет всем драйвер, контролируются и изменяются частоты чипа и памяти, напряжения, обороты вентилятор, также могут быть отключены простаивающие блоки GPU. За счёт обновленной технологии управления питанием и других модификаций в чипе, по сравнению с предыдущим поколением видеокарт, было достигнуто двукратное увеличение эффективности, выраженное в производительности на Ватт.
Итак, сегодня мы познакомились с теоретическими особенностями нового чипа RV770, в следующей части статьи будет практическая часть исследования, в которой мы узнаем, как производительность новых решений на основе чипа RV770 соотносится со скоростью предыдущих решений компании AMD и конкурирующих видеокарт Nvidia. Самое интересное в том, как сильно сказались упомянутые выше архитектурные улучшения в RV770 на его производительности.


