Справочная информация о семействе видеокарт Radeon X
Справочная информация о семействе видеокарт Radeon X1000
Справочная информация о семействе видеокарт Radeon HD 2000
Справочная информация о семействе видеокарт Radeon HD 4000
Справочная информация о семействе видеокарт Radeon HD 5000
Справочная информация о семействе видеокарт Radeon HD 6000
Справочная информация о семействе видеокарт Radeon HD 7000
Справочная информация о семействе видеокарт Radeon 200
Справочная информация о семействе видеокарт Radeon 300
Спецификации чипов семейства R[V]6XX
| кодовое имя | R600 | RV630 | RV610 | RV670 | RV620 | RV635 |
| базовая статья | здесь | здесь | здесь | здесь | здесь | |
| технология (нм) | 80 | 65 | 55 | |||
| транзисторов (М) | 700 | 390 | 180 | 666 | 181 | 378 |
| универсальных процессоров | 64*5 | 24*5 | 8*5 | 64*5 | 8*5 | 24*5 |
| текстурных блоков | 16 | 8 | 4 | 16 | 4 | 8 |
| блоков блендинга | 16 | 4 | 16 | 4 | ||
| шина памяти | 512 | 128 | 64 | 256 | 64 | 128 |
| типы памяти | DDR, DDR2, GDDR3, GDDR4 | |||||
| системная шина чипа | PCI-Express 16х | PCI-Express 2.0 16х | ||||
| RAMDAC | 2 х 400МГц | |||||
| интерфейсы | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link HDMI | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link HDMI DisplayPort | |||
| вершинные шейдеры | 4.0 | 4.1 | ||||
| пиксельные шейдеры | 4.0 | 4.1 | ||||
| точность пиксельных вычислений | FP32 | |||||
| точность вершинных вычислений | FP32 | |||||
| форматы компонент текстур | FP32, FP16 I8 DXTC, S3TC 3Dc | |||||
| форматы рендеринга | FP32 и FP16 (c блендингом и MSAA) I8 I10 (RGBA 10:10:10:2) другие | |||||
| MRT | есть | |||||
| Aнтиалиасинг | 2х-8х MSAA CFAA до 24x | |||||
| генерация Z | 2х в режиме без цвета | |||||
| буфер шаблонов | двусторонний | |||||
| технологии теней | аппаратные карты теней оптимизации геометрических теней | |||||
Спецификации референсных карт на базе чипов семейств R[V]6XX
| карта | чип шина | блоков ALU/TMU | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) бит | тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
| RADEON HD 2400 PRO | RV610 PEG16х | 40/4 | 525 | 400(800) | 128/256 DDR2 | 6.4 (64) | 2100 | |
| RADEON HD 2400 XT | RV610 PEG16х | 40/4 | 700 | 800(1600) | 256 GDDR3 | 13.0 (64) | 2800 | |
| RADEON HD 2600 PRO | RV630 PEG16х | 120/8 | 600 | 400(800) | 256 DDR2/GDDR3 | 13.0 (128) | 4800 | 2400 |
| RADEON HD 2600 XT | RV630 PEG16х | 120/8 | 800 | 1100(2200) | 256 GDDR3/GDDR4 | 35.0 (128) | 6400 | 3200 |
| RADEON HD 2900 XT | R600 PEG16х | 320/16 | 750 | 825(1650) | 512 GDDR3 | 106.0 (512) | 12000 | |
| RADEON HD 2900 XT 1GB | R600 PEG16х | 320/16 | 750 | 1000(2000) | 1024 GDDR4 | 128.0 (512) | 12000 | |
| RADEON HD 2900 PRO | R600 PEG16х | 320/16 | 600 | 800(1600) | 512 GDDR3 | 102.4 (512) | 9600 | |
| RADEON HD 3850 | RV670 PEG16х | 320/16 | 670 | 830(1660) | 256 GDDR3 | 53.1 (256) | 10720 | |
| RADEON HD 3870 | RV670 PEG16х | 320/16 | 775 | 1125(2250) | 512 GDDR4 | 72.0 (256) | 12400 | |
| RADEON HD 3450 | RV620 PEG16х | 40/4 | 600 | 500(1000) | 256 DDR2 | 8.0 (64) | 2400 | |
| RADEON HD 3470 | RV620 PEG16х | 40/4 | 800 | 950(1900) | 256 GDDR3 | 15.2 (64) | 3200 | |
| RADEON HD 3650 DDR2 | RV635 PEG16х | 120/8 | 725 | 500(1000) | 256/512 DDR2 | 16.0 (128) | 5800 | 2900 |
| RADEON HD 3650 GDDR3 | RV635 PEG16х | 120/8 | 725 | 800(1600) | 256/512 GDDR3 | 25.6 (128) | 5800 | 2900 |
| RADEON HD 3850 X2 | 2xRV670 PEG16х | 2x(320/16) | 670 | 830(1660) | 2x512 GDDR3 | 2x53.1 (2x256) | 21440 | |
| RADEON HD 3870 X2 | 2xRV670 PEG16х | 2x(320/16) | 825 | 900(1800) | 2x512 GDDR3 | 2x57.6 (2x256) | 26400 | |
Подробности: R600, серия RADEON HD 2900
Спецификации R600
- Кодовое имя чипа R600
- Технология 80 нм
- ~700 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе и новой шейдерной модели Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 512-бит шина памяти, восемь контроллеров шириной 64 бита, соединенных шиной ring bus
- Частота ядра 750 МГц
- 320 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 4 текстурных блока, поддержка FP16 и FP32 компонент в текстурах
- 32 блока текстурной адресации (см. подробности)
- 80 блоков текстурной выборки (см. подробности)
- 16 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 16 блоков ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 16 отсчетов за такт, в режиме без цвета (Z only) 32 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI (со звуком), HDTV
Спецификации референсной карты RADEON HD 2900 XT
- Частота ядра 750 МГц
- Количество универсальных процессоров 320
- Количество текстурных блоков 16, блоков блендинга 16
- Эффективная частота памяти 1650 МГц (2*825 МГц)
- Тип памяти GDDR3
- Объем памяти 512 мегабайт
- Пропускная способность памяти 106 гигабайт в с.
- Теоретическая максимальная скорость закраски 12.0 гигапикселя в с.
- Теоретическая скорость выборки текстур 12.0 гигатекселя в с.
- CrossFire разъем
- Шина PCI-Express 16х
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Энергопотребление до 215 Вт
- Рекомендуемая цена $399
Подробности: RV630, серия RADEON HD 2600
Спецификации RV630
- Кодовое имя чипа RV630
- Технология 65 нм
- 390 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе и новой шейдерной модели Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 128-бит шина памяти, два контроллера шириной 64 бита
- Частота ядра 600-800 МГц
- 120 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 2 текстурных блока, поддержка FP16 и FP32 компонент в текстурах
- 16 блоков текстурной адресации (см. подробности)
- 40 блоков текстурной выборки (см. подробности)
- 8 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 4 блока ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 4 отсчетов за такт, в режиме без цвета (Z only) 8 отсчетов за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV
Спецификации карты RADEON HD 2600 XT
- Частота ядра 800 МГц
- Количество универсальных процессоров 120
- Количество текстурных блоков 8, блоков блендинга 4
- Эффективная частота памяти 2200 МГц (2*1100 МГц)
- Тип памяти GDDR3/GDDR4
- Объем памяти 256 мегабайт
- Пропускная способность памяти ~35 гигабайт в с.
- Теоретическая максимальная скорость закраски 3.2 гигапикселя в с.
- Теоретическая скорость выборки текстур 6.4 гигатекселя в с.
- CrossFire разъем
- Шина PCI-Express 16х
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Энергопотребление около 45 Вт
- Рекомендуемая цена $199
Спецификации карты RADEON HD 2600 PRO
- Частота ядра 600 МГц
- Количество универсальных процессоров 120
- Количество текстурных блоков 8, блоков блендинга 4
- Эффективная частота памяти 800 МГц (2*400 МГц)
- Тип памяти DDR2/GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти ~13 гигабайт в с.
- Теоретическая максимальная скорость закраски 2.4 гигапикселя в с.
- Теоретическая скорость выборки текстур 4.8 гигатекселя в с.
- CrossFire разъем
- Шина PCI-Express 16х
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI адаптер
- Энергопотребление менее 45 Вт
- Рекомендуемая цена $99
Подробности: RV610, серия RADEON HD 2400
Спецификации RV610
- Кодовое имя чипа RV610
- Технология 65 нм
- 180 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10, в том числе и новой шейдерной модели Shader Model 4.0, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 64-бит шина памяти, один контроллер шириной 64 бита
- Частота ядра 525-700 МГц
- 40 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 1 текстурный блок, поддержка FP16 и FP32 компонент в текстурах
- 8 блоков текстурной адресации (см. подробности)
- 20 блоков текстурной выборки (см. подробности)
- 4 блока билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 4 блока ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 4 отсчетов за такт, в режиме без цвета (Z only) 8 отсчетов за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV
Спецификации карты RADEON HD 2400 XT
- Частота ядра 700 МГц
- Количество универсальных процессоров 40
- Количество текстурных блоков 4, блоков блендинга 4
- Эффективная частота памяти 1600 МГц (2*800 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти ~13 гигабайт в с.
- Теоретическая максимальная скорость закраски 2.8 гигапикселя в с.
- Теоретическая скорость выборки текстур 2.8 гигатекселя в с.
- Шина PCI-Express 16х
- Один DVI-I Dual Link разъем, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Энергопотребление около 25 Вт
- Рекомендуемая цена <$99
Спецификации карты RADEON HD 2400 PRO
- Частота ядра 525 МГц
- Количество универсальных процессоров 40
- Количество текстурных блоков 4, блоков блендинга 4
- Эффективная частота памяти 800 МГц (2*400 МГц)
- Тип памяти DDR2
- Объем памяти 128/256 мегабайт
- Пропускная способность памяти 6.4 гигабайт в сек.
- Теоретическая максимальная скорость закраски 2.1 гигапикселя в сек.
- Теоретическая скорость выборки текстур 2.1 гигатекселя в сек.
- Шина PCI-Express 16х
- Один DVI-I Dual Link разъем, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI адаптер
- Энергопотребление менее 25 Вт
- Рекомендуемая цена <$99
Архитектура R600/RV630/RV610
Архитектура R6xx сочетает в себе некоторые решения из предыдущих: R5xx и Xenos (видеочипа консоли Microsoft Xbox 360), дополняя их различными нововведениями: более мощным диспетчером потоков, суперскалярной архитектурой шейдерных процессоров с выделенными блоками ветвления, обновленной 512-битной шиной ring bus. Так выглядит архитектура топового чипа R600:
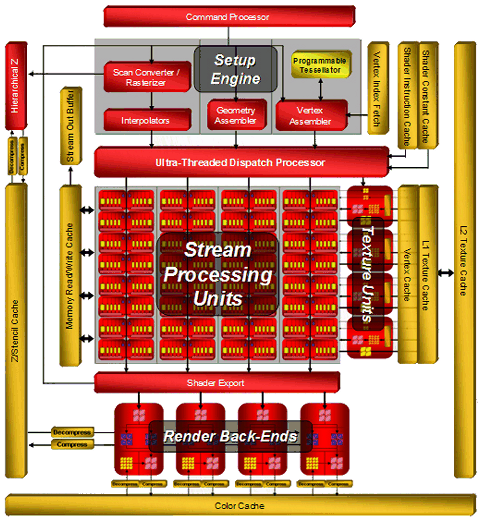
На схеме видно, что основной вычислительной мощью являются 64 суперскалярных потоковых процессора, каждый из которых содержит по 5 ALU и выделенному блоку выполнения ветвлений. AMD предпочитает указывать их количество в целом — как 320 потоковых процессора. Все мы знаем, как любят производители указывать большие цифры, и пиковую производительность они насчитали 475 GigaFLOPS для одиночного R600. Вряд ли эта цифра достижима в реальных алгоритмах.
Диспетчер потоков (Ultra-Threaded Dispatch Processor) управляет выполнением потоков на исполнительных блоках, именно он решает, какой работой будет заниматься тот или иной блок в зависимости от потребностей и приоритетов. Новый диспетчер потоков, реализованный в R6xx, способен обслуживать тысячи потоков одновременно. Это его подробная схема:
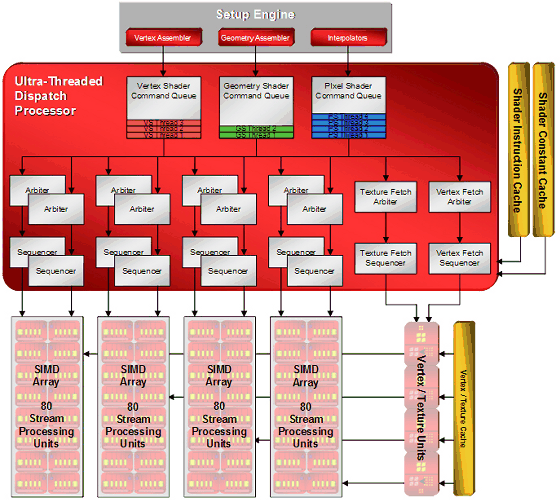
Из других изменений, по сравнению с предыдущими поколениями чипов, можно привести командный процессор (Command Processor), который служит для обработки команд видеодрайвера. Он выполняет микрокод, разгружая центральный процессор, увеличивая производительность в условиях большого количества вызовов функций отрисовки с малым количеством обрабатываемой геометрии (известная проблема small batch в Direct3D). Заявлено, что эффект от командного процессора есть в Direct3D 9 и Direct3D 10 приложениях. Теоретически, снижение потерь времени на разнообразные проверки может вызвать выигрыш до 30%, но реальные цифры ускорения, конечно, будут значительно меньшими.
Похоже, что новая архитектура хорошо масштабируется в обе стороны, что мы и видим на примере low-end и mid-end решений. Схемы чипов RV630 и RV610 выглядят так:
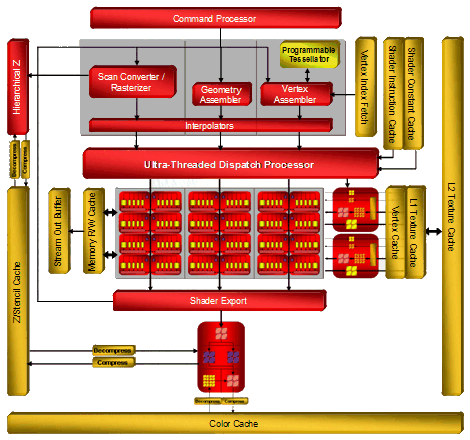
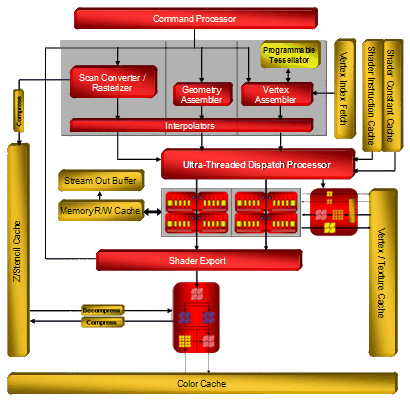
Хорошо видно, что RV630 отличается от R600 только количеством разнообразных блоков: ALU, ROP, TMU, во всем остальном он повторяет старшего брата. У RV610 отличий больше, они не только количественные (блоков ALU и TMU стало еще меньше), но и качественные: нет иерархического Z-буфера, нет второго уровня текстурного кэша, а единственный уровень совмещает кэширование вершинных и пиксельных данных. Основные количественные изменения: число шейдерных процессоров снижено до 24 (120 процессоров) у RV630 и до 8 (40 процессоров) у RV610, число блоков текстурирования до 8 и 4, соответственно, а блоков ROP у младших чипов по четыре у каждого. Естественно, всё это сделано в угоду меньшему числу транзисторов и скажется на производительности. Этот вопрос мы рассмотрим в будущем материале, посвященном новым решениям AMD среднего и нижнего уровней.
Интересно, как в реальных приложениях будет балансироваться нагрузка между исполнением вершинных, пиксельных и геометрических шейдеров, ведь при использовании унифицированной архитектуры нужно думать об эффективном распределении общей мощности потоковых процессоров между разными типами шейдеров. Так, при ограничении производительности пиксельными расчётами, увеличение нагрузки на вершинные блоки в традиционной архитектуре не приводит к падению производительности, а в унифицированной вызовет изменение баланса и уменьшение количества ресурсов, свободных для пиксельных расчетов.
Шейдерные процессоры (ALU)
Уже в прошлом поколении своих чипов ATI сделала решение, отличающееся от того, что было общепринято ранее и использовалось компанией NVIDIA, в R580 реализовали 48 исполнительных шейдерных блоков и 16 блоков текстурирования, тогда как в G70 было 24 блоков TMU и пиксельных процессоров и 16 блоков ROP. Подобная разница в подходе стала очевидной еще со времени выхода чипов RV530 и RV560, в которых было подобное же соотношение TMU и шейдерных процессоров. NVIDIA традиционно уделяет чуть больше внимания текстурированию и скорости заполнения, а AMD(ATI) — операциям над пикселями и вершинами.
Итак, если в предыдущих решениях ATI шейдерные процессоры содержали векторные и скалярные исполнительные блоки, которые могли выполнять по две инструкции за такт над 3+1 или 4+1 компонентами, то теперь каждый процессор из 64 может выполнять по пять инструкций над пятью компонентами. Каждый потоковый процессор состоит из пяти независимых скалярных ALU, которые могут выполнить пять MAD (Multiply-Add) инструкций за такт, а один из пяти ALU способен выполнить более сложную инструкцию: SIN, COS, LOG, EXP и другие. Отдельным блоком в процессоре является блок ветвлений и условных переходов, освобождающий основные ALU от этих задач и нивелирующий потери от переходов на ветвящемся коде шейдера.
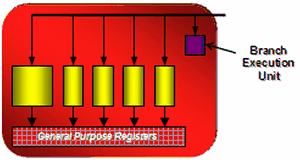
По функциональности ALU у R6xx стандартны для DirectX 10 решений, точность всех расчетов составляет FP32, есть поддержка вычислений в новых целочисленных форматах, при реализации соблюден стандарт IEEE 754, важный для научных, статистических, экономических и других вычислений.
Число таких исполнительных блоков в R600 очень велико, но при сравнении с конкурирующим решением от NVIDIA нужно учитывать удвоенную частоту шейдерных процессоров у последнего. Осторожно нужно относиться и к сравнению скалярной и суперскалярной архитектур: у обеих есть как слабые, так и сильные стороны. Так, суперскалярная отличается тем, что каждый блок может обрабатывать сразу по несколько независимых инструкций (до пяти математических и одну инструкцию ветвления в нашем случае) за один такт.
Но слабая сторона такой архитектуры в том, что приложение и драйвер должны выдавать ей постоянно как можно больше независимых инструкций, чтобы блоки не простаивали и КПД был высоким. У скалярной архитектуры такого ограничения нет, она более гибкая, её КПД всегда будет выше, так как 3D-приложения используют разные комбинации команд, многие из которых зависят от выполнения предыдущих, и набирать по 4-5 независимых не так просто. Для повышения эффективности суперскалярной архитектуры нужен качественный оптимизирующий рекомпилятор шейдеров и оптимизации со стороны приложений. Ярким примером в данном случае является суперскалярная архитектура NV3x, которой рекомпилятор и оптимизации очень сильно помогали. Конечно, у R6xx нет таких явных узких мест, как у NV3x, но это не избавляет архитектуру от полезности оптимизаций.
Сравнивать настолько разные современные архитектуры только по количеству исполнительных блоков неправильно. Нужно пользоваться исключительно анализом результатов синтетических и игровых тестов, чётко понимая, что они значат, и какие блоки в каком тесте служат ограничителем производительности. А все эти большие цифры важны, скорее, для маркетинга, чем для определения реальной скорости.
Текстурные блоки (TMU)
Текстурные блоки (точнее, блоки выборки текстурных и вершинных данных в унифицированных чипах) в архитектуре R6xx используются новые, они полностью отделены от потоковых процессоров, что позволяет начинать выборку данных еще до того, как они запрошены шейдерным блоком (ведь всем управляет диспетчер потоков, он и может дать упреждающее задание), что теоретически может повысить производительность. Текстурные модули R6xx, на примере старшего чипа R600, имеют следующую конфигурацию:
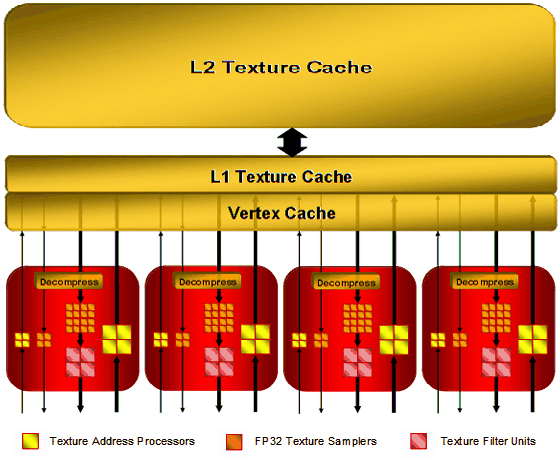
Имеется четыре текстурных блока, каждый из которых состоит из: 8 блоков адресации (всего в чипе 32), 20 блоков выборки (всего в чипе 80), 4 блоков фильтрации (всего в чипе 16). Выборка вершин и текстур обычно выполняется отдельно, часть блоков адресации и выборки у TMU предназначена для вершин (на схеме они не соединены с блоками фильтрации) или для нефильтруемых текстур.
4 блока адресации и 4 блока выборки в каждом из TMU относятся к вершинным выборкам, которые не нуждаются в блоках фильтрации, а оставшиеся 4 блока адресации, 16 блоков выборки и 4 блока фильтрации к текстурным, для которых и нужна фильтрация. То есть, 64 из 80 блоков выборки выбирают 16 пикселей для 16 блоков фильтрации, а оставшиеся 16 выбирают данные вершин (или текстур без фильтрации). Пользуясь тем, что TMU блоки у R6xx полностью отделены от ALU, за один такт они могут выбирать и вершины и пиксели.
Каждый блок выборки может выбирать одно значение за такт, а блок текстурной фильтрации фильтровать по одному 64-битному значению за такт или по одному 128-битному каждые два такта. Из-за указанных выше деталей реализации блоков, для каждого из них возможна выборка до двух текселей за такт, если для одного из них не требуется фильтрация.
Как видно на схеме, для текстурных выборок используется двухуровневая реализация кэш-памяти. Текстурные кэши второго уровня, указанные на диаграмме, имеют следующие размеры: 256 Кбайт у R600, 128 Кбайт у RV630, а на RV610 используется один уровень кэша, общий для вершинных и текстурных данных. Заявлено, что вершинный кэш R600 увеличен в восемь раз, по сравнению с применяемым в R580. Это решение обосновано тем, что производительность универсальных процессоров позволяет обрабатывать данные в несколько раз быстрее, по сравнению с выделенными блоками геометрических шейдеров в предыдущих архитектурах.
Текстурные блоки в чипах R6xx усовершенствованы, одно из главных достоинств в том, что они могут выбирать и билинейно фильтровать FP16 текстуры на той же скорости, что и 32-битные, а FP32 — на половинной, то есть, как и на G80. Поддерживаются новые 32-битные HDR форматы текстур, которые появились в DirectX 10, декларируется поддержка трилинейной и анизотропной фильтраций для всех поддерживаемых текстурных форматов. Максимальное разрешение текстур стало 8192x8192 (как и у G80), представители компании говорят об улучшенном качестве текстурной фильтрации, которое мы проверим в одной из следующих частей данной статьи. Кстати, в материалах AMD не говорится о бесплатной трилинейной фильтрации, так что, скорее всего, она снижает пиковую производительность TMU, как во всех чипах, кроме G80.
Текстурные блоки в RV630 и RV610 имеют такую же функциональность, что и блоки верхнего решения линейки (за исключением реализации кэша в RV610), но меньшее их количество. Как раз в количестве TMU видится и одна из потенциальных слабых сторон нового семейства чипов. Высокая вычислительная производительность - это очень хорошо, конечно, но ведь она сама по себе нужна разве что для неграфических расчетов. А для 3D-графики до сих пор очень важна скорость выборки из текстур и скорость их фильтрации. Современные игры используют не только сложные пиксельные и вершинные расчеты, они еще и накладывают по несколько текстур на пиксель: основные текстуры, specular текстуры, карты нормалей, карты высот, кубические карты отражений и преломлений и другие. И вполне возможно, что 16-ти текстурных блоков такому мощному чипу, как R600, будет недостаточно, чтобы раскрыть даже свой расчетный потенциал. Мы проверим это далее, в синтетических и игровых тестах.
Блоки записи в буфер кадра (ROP)
Блоки ROP в R6xx претерпели не так много изменений по сравнению с предыдущими чипами. В R600 их четыре, каждый из которых записывает по четыре пикселя, всего получается 16 обрабатываемых и записываемых пикселей в буфер кадра. У RV630 и RV610 — по одному блоку ROP, и всего по четыре записываемых пикселя. Блоками ROP поддерживается двойная производительность при записи данных без цвета, то есть 32 пикселя для R600 и 8 — для RV610/RV630, соответственно. Возможно использование до восьми MRT (буферов рендеринга) с поддержкой мультисэмплинга, это требование DirectX 10 и других цифр здесь ждать не приходится. Конечно, есть полноценная поддержка рендеринга в FP16 и FP32 форматы буфера кадров, включая антиалиасинг.
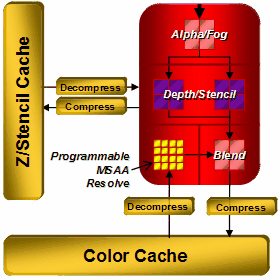
Из интересных нововведений в реализации блоков ROP отметим, что компанией AMD декларируются улучшения в сжатии Z и stencil буферов, до 16:1 против 8:1 у предыдущих решений, и до 128:1 при MSAA с количеством сэмплов 8x. Данные Z и stencil буферов сжимаются отдельно друг от друга, что должно увеличить эффективность компрессии. Также традиционно увеличен порог разрешения, при котором работает сжатие, если раньше значение было ограничено пятью мегапикселями, то теперь граница явно не указывается. Сделано и множество оптимизаций по работе с Z буфером, большая часть которых направлена на ускорение стенсильных теней в распространенных приложениях (DOOM 3, F.E.A.R., Unreal Engine 3 и другие), производительность R600 в которых мы проверим в нашей статье.
Новые режимы антиалиасинга
Чипами R6xx поддерживается мультисэмплинг с максимальным количеством выборок, равным восьми. Чтобы не отставать от конкурентов, которые сделали хитрый ход с CSAA, были введены новые режимы с количеством сэмплов до 24 штук, названные Custom Filter Anti-Aliasing (CFAA). Это специальные режимы постобработки, направленные на дальнейшее улучшение качества антиалиасинга, с программируемым расположением субпикселей, выборкой вне границ пикселей, и разными весами для выборок.
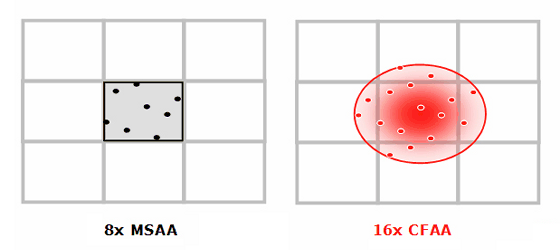
В зависимости от выбранного режима, методом CFAA выбирается от четырех до восьми соседних сэмплов вне пикселя. Несмотря на то, что вес этих выборок меньше, чем у внутренних, метод всё равно будет вызывать размытие всей картинки. И чем больше выборок вне пикселя, тем больше размоется изображение. Одним из основных преимуществ такого подхода является улучшение качества антиалиасинга при помощи обновлений драйвера. Кроме того, возможность управления мультисэмплингом появится у разработчиков приложений в следующих версиях DirectX. Естественно, что все ранее введенные возможности: адаптивный антиалиасинг, temporal antialiasing, гамма-коррекция для MSAA и другие также поддерживаются новыми чипами.
Самый главный недостаток подхода CFAA в том, что дополнительные выборки за границами пикселя могут снижать итоговое качество картинки. Вспомните специальный режим антиалиасинга у NVIDIA под названием Quincunx, он тоже использовал выборку вне пикселя и снижал четкость картинки, за что его не любила основная масса пользователей. У AMD подход, конечно, более гибкий, выборкам вне пикселя будет даваться меньший вес, чем внутренним, но размазывания картинки не избежать всё равно. Будет ли это помехой для притязательного глаза — мы рассмотрим в разделе статьи, посвященном качеству рендеринга.
С нашей точки зрения, гораздо более интересно еще одно нововведение в антиалиасинге R6xx, которое пока не доработано в текущих драйверах — антиалиасинг с применением адаптивного фильтра edge detect. При этом методе производится проход фильтра edge detection по отрендеренному изображению, для определенных фильтром пикселей с высокими частотами (границы полигонов и резкие переходы на некоторых текстурах, которые обычно и нуждаются в сглаживании) используется более качественный метод антиалиасинга с большим количеством сэмплов, а для остальных — с меньшим. Этот подход похож на тот, что применялся в методе антиалиасинга FAA видеокартой Matrox Parhelia и интересен тем, что теоретически должен показывать отличные результаты, как по качеству сглаживания, так и по производительности, ведь он работает больше именно там, где это нужно, снижает текстурный шум и вместе с тем не должен ухудшать детализацию. Но это теория, а практику мы рассмотрим в разделе качества.
512-битная шина памяти ring bus
Одним из несомненных преимуществ чипа R600 является 512-битная шина памяти ring bus, это первый видеочип с поддержкой 512-битного доступа к видеопамяти. Теперь шина ring bus включает восемь 64-битных каналов, соединенных внутренней 1024-битной шиной (два направления по 512-бит), центральный хаб отсутствует. Решение хорошо масштабируется и обеспечивает очень высокую эффективную пропускную способность. Для первых видеокарт на базе R600 она составляет более 100 Гбайт/с при условии обычной и не самой быстрой GDDR3 памяти. В будущих решениях это значение может вырасти ещё, ведь контроллер поддерживает быструю GDDR4 память.
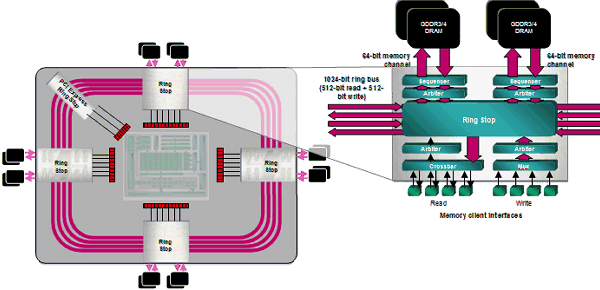
Представители AMD уверяют, что в реализации ring bus были проведены изменения, направленные на дальнейшее увеличение её эффективности. Конечно, таких цифр можно добиться и с 384-битной шиной, что сделала NVIDIA в своей GeForce 8800 Ultra, но для этого нужна гораздо более дорогая и редкая память. С другой стороны, у 512-битности есть и недостаток — сложность PCB увеличивается, как и стоимость остальных производственных работ по сборке плат. Зато большая пропускная способность обязательно скажется в высоких разрешениях, при больших уровнях антиалиасинга и HDR-рендеринге. Именно в таких режимах можно ожидать большого преимущества от RADEON HD 2900 XT по сравнению с конкурирующими решениями NVIDIA.
Программируемый блок тесселяции
Наследственность R6xx в виде консольного чипа Xenos сказалась в том, что все решения серии RADEON HD 2000 содержат программируемый блок тесселяции, новый для ПК. Базовые теоретические данные по тесселяции вы можете прочитать в статьях:
Тесселяция используется для увеличения геометрической сложности моделей, когда из низкополигональной получается более сложная. Использование тесселяции может снизить затраты на анимацию, с небольшими затратами производительности увеличить детализацию моделей, улучшить алгоритмы уровня детализации (LOD). Полностью аппаратное решение позволяет разработчикам посылать в GPU данные с меньшей детализацией, затем видеочипом тесселировать их до нужной сложности и выполнять смещение вершин при помощи специальных текстур (displacement mapping, см. по ссылке выше). Это снижает нагрузку на центральный процессор и уменьшает количество данных, передаваемых по шинам.
Разбиение поверхностей (тесселяция) не имеет единственного алгоритма, оно может выполняться по нескольким правилам. Есть несколько типов поверхностей высокого уровня (higher order surfaces): Bezier, N-Patches, B-Spline, NURBs, subdivision surfaces, которые могут разбиваться на полигоны видеочипом. И, так как тесселятор в R6xx программируемый, его можно использовать для разных алгоритмов, что дает большую гибкость и контроль 3D-разработчикам. AMD дает такую схему работы конвейера:
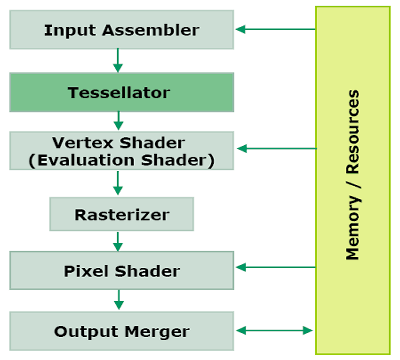
Заявлено, что для использования тесселятора в R6xx не нужно новых типов шейдеров в API, что необходимый вершинный шейдер пишется самими разработчиками. Немного непонятно, каким образом в обычном вершинном шейдере выполнять тесселяцию, но главное, чтобы это знали игровые разработчики.
Преимущества, которые можно получить при использовании возможностей программируемого тесселятора, достаточно велики. Тесселяция поможет увеличить геометрическую детализацию сцены без большого увеличения нагрузки на шины и центральный процессор системы, тесселяция особенно эффективна в сочетании с displacement mapping. Но это всё в теории, практика обычно не такая радужная. Есть вопросы о том, каким образом можно использовать возможности тесселятора в разнообразных API (Direct3D 9, Direct3D 10, OpenGL), но самый важный вопрос - будут ли разработчиками использоваться возможности чипов одного из двух вендоров? Понятно, что портированным играм с Xbox 360, которые на родной платформе используют тесселяцию, это может быть полезно, но как быть с остальными видеокартами?
Улучшенная поддержка CrossFire
В описании особенностей новых решений компании AMD необходимо упомянуть и улучшенную поддержку CrossFire, все новые чипы не требуют использования специальных мастер-карт. Наконец-то, начиная с этой линейки, в чипах для всех ценовых диапазонов встроена «родная» поддержка CrossFire. Как и в случае с картами на базе чипов RV570, можно будет объединять обычные платы при помощи мостиков, похожих на те, что давно используются для NVIDIA SLI.
Новыми чипами поддерживаются все те же старые знакомые режимы рендеринга: Alternate Frame Rendering, SuperTile, Scissor, SuperAA. Максимально возможное разрешение в режимах CrossFire 2560x2048 при частоте обновления 60 Гц. Самое любопытное в описании обновленного CrossFire в том, что там уже заявлена поддержка более чем двух чипов, одновременно работающих над рендерингом одной картинки. С удовольствием протестируем таковую, когда у нас появится подобная возможность.
ATI Avivo HD
Что касается мультимедийных возможностей новых видеочипов, то и здесь не обошлось без изменений в лучшую сторону. Все чипы серии R6xx содержат специализированные блоки: UVD (Universal Video Decoder универсальный видеодекодер) и AVP (Advanced Video Processor видеопроцессор). Технология ATI Avivo никуда не исчезла, как и PureVideo у основного конкурента, она развивается и расширяется, получив модную приставку ATI Avivo HD.
Прошлое поколение видеочипов способно ускорять лишь часть этапов декодирования видео, оставляя самые затратные части для центрального процессора. В новом поколении чипов внедрен выделенный блок для декодирования видео (UVD), который выполняет всю основную работу: аппаратное статистическое декодирование VLC/CAVLC/CABAC, iDCT, компенсацию движения и деблокинг (удаление артефактов блочности), разгружая и CPU, и 3D-конвейер видеочипа. Последнее особенно важно для Windows Vista, которая использует 3D-возможности видеокарт для отрисовки интерфейса Aero.
Всё семейство новых чипов поддерживает обновленную технологию, они обеспечивают полностью аппаратное ускорение декодирования требовательных к ресурсам видео форматов H.264 и VC-1 с максимально высоким битрейтом, которые являются одними из основных для дисков форматов Blu-ray и HD-DVD. Поддержка аппаратного декодирования видео расширена при помощи указанных новых блоков, которые отличаются от предыдущих поколений Avivo аппаратным выполнением функций статистического декодирования, особенно важных для современных видеоформатов. Новая технология ATI Avivo HD позволяет декодировать все указанные форматы с разрешением до 1920x1080 и битрейтами до 30-40 Мбит/с, и всё необходимое для этого поддерживается всеми видеочипами линейки.
При сравнении возможностей своих чипов с конкурирующими, AMD приводит такую таблицу:
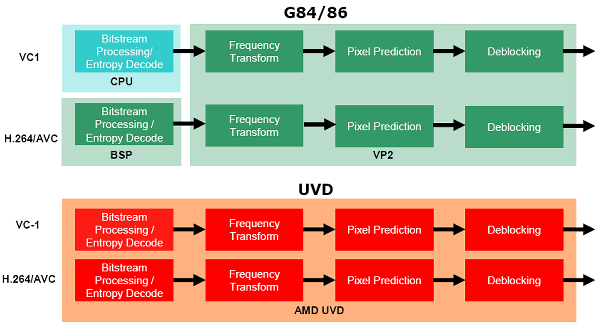
Утверждается, что в отличие от аналогичных блоков обработки видео в чипах NVIDIA G84 и G86, решениями AMD поддерживается аппаратное статистическое декодирование для формата VC-1. Компания приводит примерно такие же цифры загрузки процессора, что и NVIDIA ранее, по их данным, при декодировании HD DVD диска полностью программным методом, современный двухъядерный процессор будет загружен работой примерно на 80%, с аппаратным ускорением на чипах предыдущего поколения — на 60-70%, а полностью аппаратное решение с UVD обеспечивает загрузку CPU лишь чуть больше 10%, что позволяет воспроизводить все существующие диски даже на средних по мощности ПК. В соответствующих материалах мы постараемся проверить это, а пока остается поверить на слово.
Неграфические расчеты
Огромная производительность математических расчетов с плавающей запятой у современных видеоускорителей и гибкость унифицированных архитектур дали толчок применениям GPU в расчетах физики в игровых приложениях и более серьезных задачах: математического и физического моделирования, экономических и статистических моделей и расчетов, распознавания образов, обработки изображений, научной графики и других.
Поэтому в последнее время всеми производителями GPU уделяется много внимания неграфическим расчетам на видеокартах. На базе чипов прошлого поколения ATI(AMD) выпустила специализированные карты на основе RADEON X1900 (Stream Processor) с чипом R580 и гигабайтом GDDR3 памяти. Новые чипы, конечно, обладают всем необходимым для создания таких продуктов, ещё большая мощь по расчетам с плавающей запятой которых может использоваться в большом количестве применений: физические расчеты в играх, обработка медиаданных (например, перекодирование из одного формата в другой, захват и кодирование видео высокого разрешения) и изображений, распознавание речи и изображений, медицинские задачи (виртуальная эндоскопия, интерактивная визуализация), метеорология, динамика жидкостей и газов и многое другое.
Вероятно, через некоторое время после анонса графических карт серии RADEON HD 2000, последует запуск новых продуктов категории «Stream Processor» на базе R600 с поддержкой вычислений с плавающей запятой и целочисленных вычислений, появившихся в новой архитектуре, которые будут использовать значительно увеличенную мощь 320 потоковых процессоров. Неполный список нововведений, появившихся в чипах серии R6xx, важных для неграфических расчетов: целочисленные операции, поддержка текстур размером до 8192x8192 пикселей, неограниченная длина шейдера, неограниченная память для регистров, специальный командный процессор для снижения потерь времени на проверку правильности вызовов и состояний.
В небольшом отступлении мы в очередной раз посетуем на то, что реальных примеров физических вычислений в играх, переложенных на GPU, мы так до сих пор и не увидели. Даже не хочется в очередной раз приводить картинки, предоставленные производителями видеочипов, ведь для обычных пользователей так ничего и не изменилось — толка от GPU в неграфических расчетах в современных играх нет, к сожалению.
Поддержка HDMI и других внешних интерфейсов
Одним из ожидаемых решений в серии HD 2000 стал встроенный аудиочип, нужный для поддержки передачи звука по HDMI. С применением решений на чипах R600, RV610 и RV630 необходимость во внешнем аудио и соответствующих соединительных кабелях отпадает, передавать аудиосигнал с интегрированной на системную плату или внешней звуковой карты не нужно. Да и сертификация Vista Premium требует, чтобы весь аудиотракт был интегрированным и HDCP-защищенным. Решение AMD поддерживает следующие 16-битные форматы PCM данных: 32 кГц, 44.1 кГц и 48 кГц, а также AC3 сжатые потоки, такие как Dolby Digital и DTS.
Передача видео- и аудиосигнала по одному HDMI-разъему во многих случаях может быть удобным решением, нет нужды во множестве проводов, прекрасно заменяемых единственным. Интересно, что у карт серии HD 2000 нет установленных разъемов HDMI, только DVI. И для вывода HDMI-сигнала в комплекте с ними поставляется специальный DVI-to-HDMI переходник, который используется и для передачи аудиоданных (ведь формат цифровой, его полосы пропускания хватит и на видео и на звук одновременно), чего не могут предложить обычные переходники. В свою очередь, новые переходники совместимы и с обычными DVI-разъемами без вывода звука.
Эта новая возможность реально полезна, но не во всех случаях. Она, скорее, будет востребована для карт среднего и низшего уровней, которые можно устанавливать в маленькие и тихие баребоны, используемые в качестве медиацентров. Ведь нет смысла в покупке high-end видеокарты только лишь для просмотра видео на большом HDTV-экране. Вполне вероятно, что именно из-за встроенного аудио, видеокарты RADEON HD 2400 и HD 2600 будут иметь определенный успех среди сборщиков подобных систем — мультимедийных центров, так как эти решения предлагают отличные возможности по декодированию видео, а также передачу защищенных видео- и аудиоданных по одному HDMI-разъему.
В отличие от NVIDIA GeForce 8800, всеми новыми решениями AMD поддерживаются Dual-Link DVI выходы с одновременной поддержкой HDCP, аналогично GeForce 8600 GTS, которая стала первой видеокартой с подобными возможностями. На старших картах устанавливается по два DVI-выхода, к которым прилагаются соответствующие специальные DVI-to-HDMI переходники, а для младших используется консервативное решение — один D-Sub и один DVI-разъем.
Подробности: RV670, серия RADEON HD 3800
Спецификации RV670
- Кодовое имя чипа RV670
- Технология 55 нм
- 666 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10.1, в том числе и новой шейдерной модели Shader Model 4.1, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- 256-битная шина памяти: четыре контроллера шириной 64 бита, соединенных шиной ring bus
- Частота ядра 670-775 МГц
- 320 скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 4 укрупненных текстурных блока, с поддержкой FP16 и FP32 компонент в текстурах
- 32 блоков текстурной адресации (см. подробности выше)
- 80 блоков текстурной выборки (см. подробности выше)
- 16 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 16 блоков ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 16 отсчетов за такт, в режиме без цвета (Z only) 32 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV
Спецификации карты RADEON HD 3870
- Частота ядра 775 МГц
- Количество универсальных процессоров 320
- Количество текстурных блоков 16, блоков блендинга 16
- Эффективная частота памяти 2250 МГц (2*1125 МГц)
- Тип памяти GDDR4
- Объем памяти 512 мегабайт
- Пропускная способность памяти 72 гигабайта в c.
- Теоретическая максимальная скорость закраски 12.4 гигапикселя в с.
- Теоретическая скорость выборки текстур 12.4 гигатекселя в с.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Энергопотребление до 105 Вт
- Рекомендуемая цена $219
Спецификации карты RADEON HD 3850
- Частота ядра 670 МГц
- Количество универсальных процессоров 320
- Количество текстурных блоков 16, блоков блендинга 16
- Эффективная частота памяти 1660 МГц (2*830 МГц)
- Тип памяти GDDR3
- Объем памяти 256 мегабайт
- Пропускная способность памяти 53 гигабайта в с.
- Теоретическая максимальная скорость закраски 10.7 гигапикселя в с.
- Теоретическая скорость выборки текстур 10.7 гигатекселя в с.
- Два CrossFireX разъема
- Шина PCI Express 2.0 x16
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Энергопотребление до 95 Вт
- Рекомендуемая цена $179
Архитектура RV670
Подробное описание архитектурных особенностей семейства чипов R6xx компании AMD см. выше. В RV670 в наличии всё то же, что и в предыдущих решениях (320 универсальных блоков по обработке данных, 16 блоков текстурных выборок, 16 блоков растровых операций, программируемый тесселятор и т.п.), лишь с небольшими изменениями, предназначенными для поддержки возможностей Direct3D версии 10.1, о которых подробно написано далее.
Схема нового чипа RV670 абсолютно идентична схеме R600. По сути, RV670 не отличается от R600 ничем, количество всех блоков (ALU, ROP, TMU) у него такое же. Единственное ухудшающее характеристики отличие нового mid-end чипа в том, что у него нет поддержки 512-битной шины, она «всего лишь» 256-битная, но всё остальное, написанное в том материале, относится к нему полностью.
Конечно, AMD заявляет, что контроллер памяти в RV670 был оптимизирован для более эффективного использования полосы пропускания, что 256-битная шина снаружи является 512-битной внутри и т.п. На одном из слайдов презентации даже написана любопытная фраза о том, что HD 3870 обладает равной производительностью с RADEON HD 2900 при одинаковых тактовых частотах.
Поддержка Direct3D 10.1
Обновленная версия DirectX будет доступна только в первом полугодии 2008 года, вместе с обновлением для операционной системы MS Windows Vista. Service Pack 1 для неё, в состав которого и должен войти DirectX 10.1, появится не скоро, не говоря уже о том, когда обновленный API принесёт что-то новое в реальные игровые проекты. Основным изменением в этой версии стало улучшение некоторых возможностей: обновленная шейдерная модель Shader Model 4.1, независимые режимы блендинга для MRT, массивы кубических карт (cube map arrays), чтение и запись значений в буферы с MSAA, одновременная текстурная выборка нескольких значений Gather4 (ранее известная как FETCH4 у чипов ATI), обязательное требование блендинга целочисленных 16-битных форматов и фильтрации 32-битных форматов с плавающей запятой, а также поддержка MSAA как минимум с четырьмя выборками и другое.
Новые возможности, которые появятся в DirectX 10.1, облегчат реализацию некоторых техник рендеринга (например, глобального освещения в реальном времени). Все нововведения можно поделить на группы: улучшения, связанные с шейдингом и текстурированием, изменения антиалиасинга и спецификаций. Что каждое из них даёт на практике сейчас разберёмся.
- Массивы кубических карт чтение и запись нескольких кубических карт за один проход рендеринга. Упрощает эффективные техники глобального освещения в реальном времени для сложных сцен. Глобальное освещение включает в себя расчет отраженного (непрямого) освещения, мягких теней, преломлений, размытых отражений и переноса или перетекания цвета (color bleeding).
- Независимые режимы блендинга для MRT при выводе данных пиксельными шейдерами в несколько буферов сразу (MRT), каждый из них может использовать свой режим блендинга. Это улучшает эффективность и быстродействие алгоритмов отложенного затенения («deferred shading»), часто применяющихся в современных игровых проектах.
- Увеличенное количество регистров для вершинных шейдеров количество входных и выходных регистров вершинных шейдеров в DX 10.1 увеличено вдвое, с 16 до 32. Это позволит увеличить производительность сложных шейдеров и упростит их оптимизацию.
- Поддержка текстурной выборки Gather4 текстурная выборка 2x2 нефильтрованного пиксельного блока вместо одного билинейно отфильтрованного значения. Эта возможность была ранее известна как FETCH4, она используется в алгоритмах качественной фильтрации карт теней, также может быть полезна в процедурном текстурировании и неграфических расчетах на GPU.
- Новая инструкция LOD новая шейдерная инструкция, возвращающая уровень детализации для отфильтрованной текстурной выборки. Может использоваться в алгоритмах специфической текстурной фильтрации в шейдерах и в алгоритмах parallax occlusion mapping.
- Улучшения антиалиасинга: маски покрытия пикселя (Pixel Coverage Masks) и чтение/запись мультисэмплового буфера чтение и запись буфера позволяет читать и записывать данные цвета и глубины отдельных сэмплов в/из буфера из шейдеров, а pixel coverage masks позволяют использовать программируемый антиалиасинг из пиксельного шейдера. Это даёт возможность создания собственных edge detect фильтров для нахождения пикселей, требующих применения сглаживания, то есть быстрого и качественного адаптивного алгоритма антиалиасинга. Также новые возможности полезны для улучшения качества антиалиасинга буферов при HDR-рендеринге и отложенном затенении, и некоторых других эффектах.
- Программируемые положения выборок при мультисэмплинге возможность дает разработчикам приложений определять своё размещение субпиксельных выборок, что полезно при temporal и мультичиповом антиалиасинге, например.
- Стандартные сетки расположения субпикселей при антиалиасинге сетки с заранее заданным стандартным положением субпикселей для всех режимов антиалиасинга. Это гарантирует, что антиалиасинг будет выглядеть идентично на всех совместимых с DirectX 10.1 решениях.
- Улучшенные фиксированные спецификации API включают в себя обязательную поддержку фильтрации для 32-битных форматов с плавающей запятой и блендинг для 16-битных целочисленных, а также минимально необходимую поддержку MSAA с четырьмя сэмплами (4x MSAA). Для DirectX 10.1 видеочипов поддержка этих возможностей обязательна, а не опциональна, как в DX10. Хотя преимуществ это не даёт, но разработчикам не нужно будет задумываться, поддерживает ли та или иная карта такую фильтрацию и блендинг такого формата, или нет.
- Увеличенная точность расчетов для операций с плавающей запятой увеличенная точность расчетов для математических расчетов (сложение, вычитание, деление, умножение) и операций блендинга.
Как мы уже сказали выше, некоторые из новых возможностей DirectX 10.1 упрощают реализацию техник и алгоритмов, повышающих качество 3D-графики. Например, AMD в своих материалах приводит пример реализации глобального освещения (Global Illumination, GI) и ambient occlusion, подробнее о них написано в базовой статье по RV670. Преимущество DirectX 10.1 в расчете GI состоит в том, что разработчики могут использовать массивы кубических карт совместно с геометрическими шейдерами в эффективном алгоритме GI реального времени.
Также в DirectX 10.1 ввели возможность использования специализированных фильтров антиалиасинга из пиксельных шейдеров. Такие методы улучшают качество в случаях, когда у обычного алгоритма MSAA есть определенные проблемы, например, при использовании HDR-рендеринга или отложенного затенения. Подобные алгоритмы используют появившийся в DX 10.1 доступ ко всем экранным буферам из шейдеров, в то время как раньше можно было читать и писать данные только в мультисэмпловые буферы цвета. В Direct3D 10.1 стало возможно читать и писать информацию из буфера глубины для каждого сэмпла по отдельности, что позволяет 3D-разработчикам использовать продвинутые техники антиалиасинга по своим алгоритмам, и даже комбинации методов привычного антиалиасинга и «шейдерного».
Естественно, многие перечисленные нововведения в DirectX 10.1 полезны и удобны, но в оценке их значения не нужно забывать то, что сам обновленный API появится через полгода, распространение видеокарт с его поддержкой займет ещё какое-то время (кстати, у NVIDIA поддержка DirectX 10.1 запланирована для следующего поколения архитектуры GPU, представители которой появятся не раньше Service Pack 1 для Vista). Кроме того, первые видеокарты явно не дадут возможности использования всех новинок API с приемлемой производительностью для реальных применений.
PCI Express 2.0
Полноценным нововведением в RV670 стала поддержка шины PCI Express 2.0. Вторая версия PCI Express увеличивает стандартную пропускную способность в два раза, с 2.5 гигабит/с до 5 гигабит/с, в результате, по стандартному для видеокарт разъему x16 можно передавать данные на скорости до 8 ГБ/с в каждом направлении (в маркетинговых материалах любят суммировать цифры, указывая 16 ГБ/с), в отличие от 4 ГБ/с для версии 1.x. При этом PCI Express 2.0 совместим с PCI Express 1.1, старые видеокарты будут работать в новых системных платах, а новые видеокарты с поддержкой второй версии останутся работоспособными в платах без его поддержки. При условии достаточности внешнего питания и без увеличения пропускной способности интерфейса, естественно.
Реальное влияние большей пропускной способности шины PCI Express на производительность оценить непросто, нужны тесты в равных условиях, сделать которые довольно проблематично. Но большая пропускная способность точно не помешает, особенно для SLI/CrossFire систем, обменивающихся данными, в том числе и по PCI Express шине. И многие современные игры требуют большого объема быстрой памяти, и при недостатке локальной, будет использоваться системная, и тогда от PCI Express 2.0 обязательно будет толк.
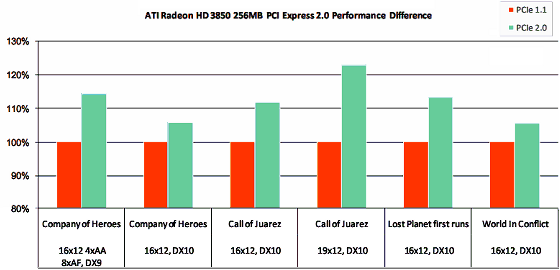
Для обеспечения обратной совместимости с существующими PCI Express 1.0 и 1.1 решениями, спецификация 2.0 поддерживает как 2.5 Гбит/с, так и 5 Гбит/с скорости передачи. Обратная совместимость PCI Express 2.0 позволяет использовать прошлые решения с 2.5 Гбит/с в 5.0 Гбит/с слотах, которые будут работать на меньшей скорости, а устройство, разработанное по спецификациям версии 2.0, может поддерживать и 2.5 Гбит/с и 5 Гбит/с скорости. Как обычно, абсолютно гладко бывает разве что на бумаге, и кто-нибудь сталкивается на практике с проблемами совместимости с некоторыми сочетаниями системных плат и карт расширения.
ATI PowerPlay
Ещё одним реальным улучшением, заметным пользователям, стала технология ATI PowerPlay технология динамического управления питанием, пришедшая с видеочипов для ноутбуков. Суть технологии в том, что специальная управляющая схема в чипе отслеживает загрузку видеочипа работой (процент загрузки GPU, к слову, показывается на панели Overdrive в CATALYST Control Center) и определяет необходимый рабочий режим, управляя рабочей частотой чипа, памяти, напряжением питания и другими параметрами, оптимизируя энергопотребление и тепловыделение.
Иными словами, в 2D-режиме при невысокой загрузке, GPU напряжение и частоты будут максимально снижены, как и частота вращения вентилятора, охлаждающего радиатор видеокарты (в некоторых случаях теоретически возможно и полное выключение вентилятора). В режиме небольшой 3D-нагрузки все параметры установятся на средние значения, а при максимальной работе GPU и частоты с напряжением будут выставлены в наибольшее значение. В отличие от предыдущих решений AMD и NVIDIA, эти режимы управляются не драйвером, а аппаратно, самим чипом. То есть более эффективно, с меньшими задержками и без известных проблем, связанных с определением 2D/3D режимов, когда 3D-приложение, запущенное в оконном режиме, не считается драйверами 3D-приложением.
В своей презентации AMD сравнивает потребление HD 2900 XT и HD 3870, если в 2D и интенсивном 3D-режимах разница между потребляемой и выделяемой мощностью решений составляет привычные два раза, то в так называемом «легком игровом» режиме (честно говоря, не понятно, что за игры имеются в виду, видимо, игры многолетней давности и современные casual игры в 3D) разница достигает уже четырех крат, что весьма и весьма много.
Графический ускоритель RADEON HD 3870 X2
- Кодовое имя чипа R680 (2 x RV670)
- Технология 55 нм
- 2 x 666 миллионов транзисторов
- Унифицированная архитектура с массивом общих процессоров для потоковой обработки вершин и пикселей, а также других видов данных
- Аппаратная поддержка DirectX 10.1, в том числе и новой шейдерной модели Shader Model 4.1, генерации геометрии и записи промежуточных данных из шейдеров (stream output)
- Двойная 256-битная шина памяти: по четыре контроллера шириной 64 бита, соединенных шиной ring bus
- Частота ядра 825 МГц
- 640 (2 x 320) скалярных ALU с плавающей точкой (целочисленные и плавающие форматы, поддержка FP32 точности в рамках стандарта IEEE 754)
- 2 x 4 укрупненных текстурных блока, с поддержкой FP16 и FP32 компонент в текстурах
- 2 x 32 блоков текстурной адресации (см. подробности в базовой статье)
- 2 x 80 блоков текстурной выборки (см. подробности в базовой статье)
- 2 x 16 блоков билинейной фильтрации с возможностью фильтрации FP16 текстур на полной скорости и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов
- Возможность динамических ветвлений в пиксельных и вершинных шейдерах
- 2 x 16 блоков ROP с поддержкой режимов антиалиасинга с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16 или FP32 формате буфера кадра. Пиковая производительность до 16 отсчетов за такт, в режиме без цвета (Z only) 32 отсчета за такт
- Запись результатов до 8 буферов кадра одновременно (MRT)
- Интегрированная поддержка двух RAMDAC, двух портов Dual Link DVI, HDMI, HDTV
Спецификации видеокарты RADEON HD 3870 X2
- Частота ядра 825 МГц
- Количество универсальных процессоров 640 (2 х 320)
- Количество текстурных блоков 2 x 16, блоков блендинга 2 x 16
- Эффективная частота памяти 1800 МГц (2*900 МГц)
- Тип памяти GDDR3
- Объем памяти 2 x 512 мегабайт
- Пропускная способность памяти 2 x 57.6 гигабайта в с.
- Теоретическая максимальная скорость закраски 2 x 13.2 гигапикселя в с.
- Теоретическая скорость выборки текстур 2 x 13.2 гигатекселя в с.
- Разъем CrossFireX
- Шина PCI Express 1.1
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
- Рекомендуемая цена $449
Спецификации видеокарты RADEON HD 3850 X2
- Частота ядра 670 МГц
- Количество универсальных процессоров 640 (2 х 320)
- Количество текстурных блоков 2 x 16, блоков блендинга 2 x 16
- Эффективная частота памяти 1660 МГц (2*830 МГц)
- Тип памяти GDDR3
- Объем памяти 2 x 512 мегабайт
- Пропускная способность памяти 2 x 53.1 гигабайта в с.
- Теоретическая максимальная скорость закраски 2 x 10.7 гигапикселя в с.
- Теоретическая скорость выборки текстур 2 x 10.7 гигатекселя в с.
- Разъем CrossFireX
- Шина PCI Express 1.1
- Два DVI-I Dual Link разъема, поддерживается вывод в разрешениях до 2560х1600
- TV-Out, HDTV-Out, поддержка HDCP, HDMI-адаптер
Архитектура
К ранее написанному ничего нового мы добавить не можем, чип RV670 остался неизменным, его архитектура была подробно описана нами в соответствующем материале. Вкратце повторим, что RV670 мало отличается от R600, количество всех блоков (ALU, ROP, TMU) у него такое же. Единственное значительное отличие более нового чипа состоит в том, что у него вместо 512-битной шины реализована 256-битная.
Естественно, RADEON HD 3870 X2, как и его одночиповый собрат, полностью поддерживает ещё не вышедший DirectX 10.1 API, новые и улучшенные возможности которого были описаны нами в предыдущем материале, посвященном выходу RADEON HD 3850 и 3870. Также AMD очень гордится тем, что их двухчиповое решение объединяет 640 потоковых процессоров, пиковая производительность которых на определенных операциях достигает 1 терафлопа, впервые для одиночной карты. Не понятно, зачем этот терафлоп обычным пользователям, применяющим видеокарту по прямому назначению, особенно с учетом того, что CrossFire система обладает явными недостатками по сравнению с одночиповыми топовыми картами...
Любопытно, что с поддержкой второй версии шины PCI Express рассматриваемой двухчиповой картой дела обстоят непросто. Несмотря на то, что одним из важнейших нововведений в RV670 стала поддержка шины PCI Express 2.0, рассматриваемое сегодня решение не может похвастать улучшениями в плане увеличения пропускной способности. Для обеспечения работы двух чипов и их связи между собой в текущей версии RADEON HD 3870 X2 используется специальный PCI Express мост PLX PEX 8547, который поддерживает 48 линий PCI-E версии 1.1. Этот чип размером 37.5 x 37.5 мм потребляет примерно 5 Вт дополнительно к энергопотреблению двух комплектов GPU и памяти. К слову, в будущем AMD планирует интегрировать подобную логику PCI Express моста в следующие модели GPU, для упрощения разводки и снижения себестоимости.
Несмотря на отсутствие поддержки PCI Express 2.0, так как эта версия совместима с PCI Express 1.1, можно почти честно сказать, что новая видеокарта обладает его поддержкой, просто работать в режиме увеличенной пропускной способности она не будет. Впрочем, влияние этой большей пропускной способности шины на практике обычно малозаметно. С другой стороны, она могла бы помочь как раз CrossFire системам, видеочипы в которых обмениваются большим потоком данных по связывающей их шине. По возможности мы постараемся определить разницу в скорости между 2.0 и 1.1 версиями в наших исследованиях, но вряд ли она будет больше нескольких процентов...
Помимо того, что HD 3870 X2 сама по себе работает как двухчиповая система, новые возможности технологии ATI CrossFireX позволяют объединять две такие платы в одной системной плате. Ведь именно решения на основе RV670 в своё время были объявлены первыми видеокартами с поддержкой одновременной работы четырех карт или двух карт на основе двух чипов.
Производители видят в многочиповых конфигурациях один из наиболее простых путей роста производительности, заметный, прежде всего, в бенчмарках. Хотя обе основные компании, производящие видеочипы, заявляют о том, что эффективность их технологий высока, и ускорение достигает 80-90%, это наблюдается лишь в высоких разрешениях и всё больше в бенчмарках, а не во всех играх.
Радует то, что в HD 3870 X2 по-прежнему есть поддержка технологии ATI PowerPlay. Напомним, что это — технология динамического управления питанием, суть которой в специальной управляющей схеме в чипе, которая отслеживает загрузку видеочипа работой и определяет необходимый рабочий режим, изменяя рабочую частоту чипа и памяти, а также напряжением питания и другими параметрами, оптимизируя энергопотребление и тепловыделение видеокарты. Без подобной технологии в 2D-режиме двухчиповая карта потребляла бы много больше энергии.
Справочная информация о семействе видеокарт Radeon X
Справочная информация о семействе видеокарт Radeon X1000
Справочная информация о семействе видеокарт Radeon HD 2000
Справочная информация о семействе видеокарт Radeon HD 4000
Справочная информация о семействе видеокарт Radeon HD 5000
Справочная информация о семействе видеокарт Radeon HD 6000
Справочная информация о семействе видеокарт Radeon HD 7000
Справочная информация о семействе видеокарт Radeon 200
Справочная информация о семействе видеокарт Radeon 300


