Экспресс-исследование
В сравнении со сходно позиционируемыми продуктами ATI, чистая производительность пиксельных и вершинных шейдеров у продуктов на базе семейства NV3X, вызывает справедливые нарекания — она заметно ниже конкурентов ATI и потенциально является самым узким местом в реальных игровых приложениях, интенсивно использующих пиксельные шейдеры версии 2.0.
Новое поколение драйверов NVIDIA (версия 50.XX и старше) включает переработанные и оптимизированные компиляторы вершинных и пиксельных шейдеров, поддержку новых форматов текстур и некоторые другие оптимизации из числа не приводящих к снижению качества изображения и при этом нацеленные на повышение скорости отрисовки. Итак, в этом экспресс исследовании мы сравним производительность драйверов 40 и 50 версии, дабы наглядно выявить степень оптимизации вершинных и пиксельных шейдеров в новом поколении драйверов. Для тестирования мы выбрали типичного середнячка — карту на базе GeForce FX 5600 Ultra 128 Мбайт со стандартными частотами ядра и памяти. Как обычно, использовался последний доступный релиз DirectX 9 и операционная система Windows XP Professional.
Надеемся, что благодаря наличию исходных текстов тестовых модулей, D3D RightMark вызовет интерес не только у любителей померить свои карты, но и у разработчиков, желающих создать собственный тест (изначально совместимый с удобной оболочкой) и не заботиться при этом о программировании достаточно трудоемких интерфейсных функций, таких как представление результатов или настройка параметров.
Смотрите, советуйте, пишите свои отзывы и пожелания!
Перед прочтением данного материала настоятельно рекомендуем обратиться к предыдущим тестированиям содержащим «синтетическую» часть:
- Oбзор ATI RADEON 9800 PRO
- Тестирование линейки RADEON 9500-9700 в DirectX 9.0: Часть 2 — синтетические тесты RightMark 3D
- NVIDIA GeForce FX 5900 Ultra (NV35)
- Осенний урожай синтетических тестов DX9
Эта статья во многом опирается на их результаты, являясь экспресс дополнением к уже озвученным в предыдущих материалах выводам. Однако, нам пора вернуться к сути вопроса:
PS2 — пиксельные шейдеры 2.0
Для уменьшения зависимости от других факторов тестирование производилось при разрешении 1280*1024. Вертикальная синхронизация отключена. Мы вновь разумно ограничили число тестов, результаты которых мы приводим в статье (слишком большое обилие одинаковой информации вряд ли добавит ясности) и остановились на пяти ситуациях:
- 1 Diffuse — попиксельное освещение с одним источником света и рассеянной составляющей.
- 3 Diffuse — попиксельное освещение с тремя источниками света и рассеянной составляющей.
- 1 Specular — попиксельное освещение с одинм источником света и двумя (рассеянной и отраженной) составляющими.
- 3 Specular — сложный вариант с попиксельным освещением сразу тремя источниками, причем с двумя составляющими каждый.
- Procedural — вычисление процедурной анимированной текстуры.
Причем, все эти тесты выполнялись в четырех вариантах:
- 32 бит точность вычислений с вычислением нормализации арифметическими операциями (Math);
- 32 бит точность вычислений с вычислением нормализации с помощью заранее рассчитанной таблицы (Cube Maps) — более ориентированный на выборку текстур, чем на вычисления подход.
- 16 бит точность вычислений с вычислением нормализации арифметическими операциями (Math);
- 32 бит точность вычислений с вычислением нормализации с помощью заранее рассчитанной таблицы (Cube Maps) — более ориентированный на выборку текстур, чем на вычисления подход.
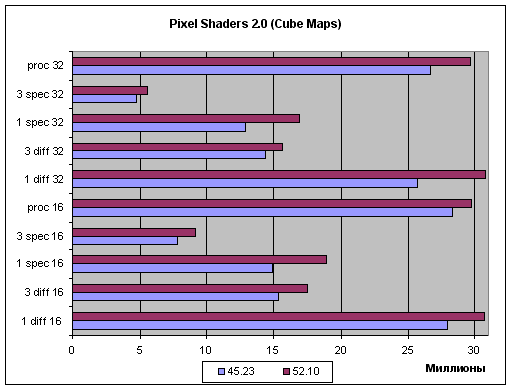
Итак, посмотрим на результаты тестов. Нормализация на основе таблицы:
и нормализация на основе арифметических операций:
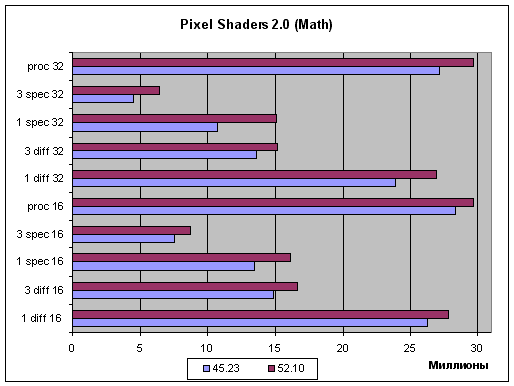
На горизонтальной оси отложены миллионы пикселей закрашиваемых в секунду. Очевидно, что в обоих тестах на лицо заметный прирост производительности для нового поколения драйверов. Причем, речь не идет о тотальном или выборочном снижении точности вычислений — прирост наблюдается также и в режиме пониженной точности (16 бит) в котором снижать эту точность уже некуда.
Давайте более подробно проанализируем графики. Во-первых, нельзя сказать, что оптимизация тяготеет к коротким (простым) или длинным шейдерам — и там и там встречается приблизительно равный прирост. Однако надо отметить что лучше всего оптимизируется длинный разнообразный код (что логично), больший прирост мы получили в случае одного сложного источника света или большой программы генерации процедурной текстуры, в то время как три простых источника (код которых по сути три раза повторяется в теле шейдера) были оптимизированы менее радикально. Оптимизация заметна и в случае использования таблиц и в случае математических операций, но последние выигрывают больше. Разумеется — доступ к текстуре не станет быстрее благодаря новому компилятору шейдеров а вот вычисления вполне могут получить прирост за счет более оптимального распределения временных регистров (которые, как известно существенно влияют на производительность шейдерных процессоров семейства 3X) и других характерных для всех оптимизирующих компиляторов приемов. В 32 битах прирост от оптимизации заметен больше — опять таки это логично. Мы знаем, что штраф за каждую лишнюю временную переменную в этом случае выше вдвое а следовательно и эффект от оптимизации должен наблюдаться более четко.
Итак, резюме: на лицо значительная оптимизация компиляции пиксельных шейдеров версии 2.0. Интересно, смогут ли программисты NVIDIA выжать в следующих драйверах еще больше производительности? Вспомнив, как разительно отличается скорость оных у первых драйверов R3XX и какой скачек был в скором времени достигнут, именно благодаря удачной оптимизации драйверов. Впрочем, необходимо трезво осознавать, что какое либо «двукратное чудо» в этой области вряд ли возможно и даже 20% прирост является существенным достижением разработчиков компилятора.
Геометрическая производительность
Тесты производились в традиционном разрешении 1024*768. Прогонялись следующие задачи:
- Ambient — самое простое освещение и трансформация, фактически, показывает нам практический предел пропускной способности карты по треугольникам;
- 1 Diffuse — один простейший источник света, нетребовательное освещение;
- 3 Diffuse — три простых источника света, типичная ситуация;
- 1 Specular — один сложный источник с бликами;
- 3 Specular — три сложных источника с бликами — достаточно интенсивная с вычислительной точки зрения ситуация;
В режиме исполнении эмуляции фиксированного TCL (известного также как FFP — Fixed Function Pipeline), в исполнении вершинных шейдеров 1.1 и 2.0.
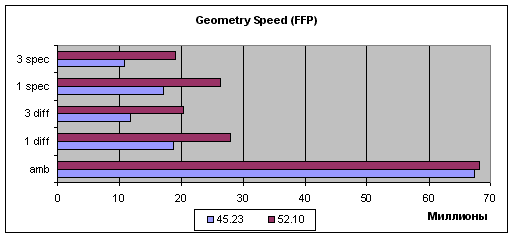
Итак, эмуляция TCL:
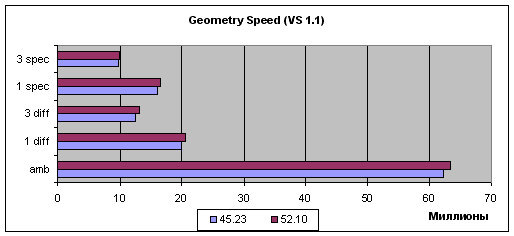
шейдеры версии 1.1:
шейдеры версии 2.0:
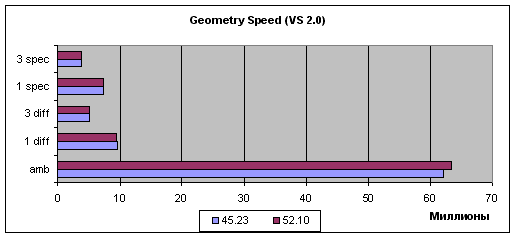
Судя по самому простому случаю (Ambient), т.е. пиковой производительности, та или иная оптимизация присутствует, но она скорее связана с организацией передачи геометрических данных чем с вершинными шейдерами. В случае любых мало-мальски интенсивных геометрических вычислений (прочие задачи) прирост наблюдается только у вершинных шейдеров версии 1.1, и его значение хотя и стабильно, но крайне не велико. В случае вершинных шейдеров 2.0 повторяется печально известная картина двукратного падения производительности при использовании циклов (единственное отличие между шейдерами 1.1 и 2.0 в этом тесте). Этот вопрос так и не был решен разработчиками NVIDIA — видимо, столь заметное падение скорости, не соизмеримое ни с одним из известных нам методов реализации циклов (ведь реально исполняется лишь одна команда цикла на десятки прочих вычислительных команд и разница должна составлять проценты но никак не разы), имеет под собою некие аппаратные причины, связанные с архитектурой ускорителя и не может быть исправлено на уровне драйверов. Что ж, жаль — фактически это приговор использованию возможностей вершинных шейдеров 2.0 на картах NVIDIA — вряд ли кто из разработчиков игр захочет добровольно обрекать свои шейдеры на двукратное падение скорости.
Интересны данные полученные в режиме эмуляции старого доброго и не гибкого TCL. Прирост значителен! Причем не на пиковой задаче, а на реальных заданиях с несколькими источниками света. Это не может не радовать — все еще существует множество приложений полностью или частично использующих TCL для отрисовки геометрии, более того, не требующие вершинных шейдеров задачи современных и еще только создаваемых игр могут быть ускорены на чипах NVIDIA таким образом.
Вывод: был существенно оптимизирован встроенный в драйверы шейдер, отвечающий за эмуляцию TCL, что не может не сказаться на использующих TCL приложениях в лучшую сторону. С другой стороны, производительность вершинных шейдеров 1.1 выросла незначительно, а в случае вершинных шейдеров 2.0 осталась прежней. Печальный факт двукратного падения производительности последних при наличии в шейдере циклов остается в силе.
На сладкое приведем графики зависимости скорости обработки геометрии от сложности сцены (три уровня сложности — low, mid и, наибольший, high для вершинных шейдеров 1.1 и 2.0):
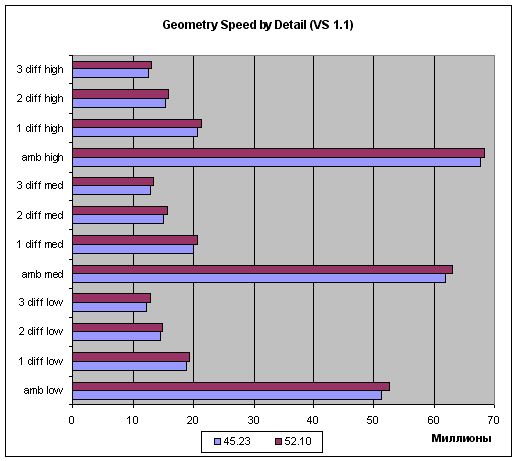
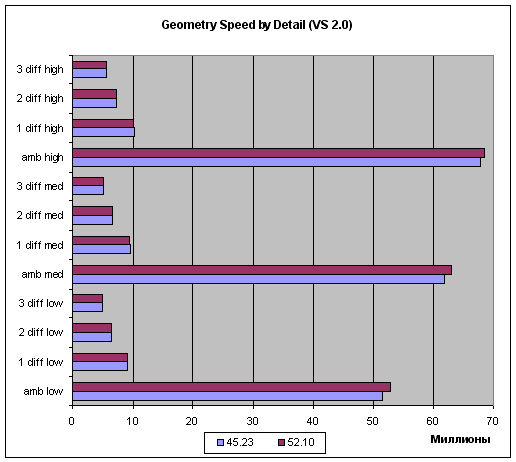
Как мы видим, в случае простых задач предпочтительнее сцены с более высокой детализацией, но, на более-менее сложных задачах (и соответственно длинных шейдерах), эта разница нивелируется.
Заключение
Итак, для окончательного вердикта будем ожидать выхода следующей официальной версии драйверов 50 поколения, которая, судя по всему будет WHQL сертифицирована. Однако, уже сейчас можно с высокой вероятностью предсказать что какие либо улучшения могут ожидать нас в пиксельных шейдерах 2.0 (которые впрочем и есть самое слабое место всех чипов серии NV3X) и эмуляции старого доброго TCL. В численном измерении эту улучшения будут весьма разумными — не слишком большими но и достаточно заметными в реальных приложениях. Однако, как ни крути — драйверы не способны сыграть роль панацеи для NVIDIA и реальное решение упомянутых в статье проблем производительности может быть только аппаратным, будь это NV38 или что более вероятно NV40.


