Время неумолимо движется, словно стрелка часов, сдвигая незримый фокус актуальности с одного бессмертного произведения Вивальди на другое. На календаре осень. Настало время пожать плоды и подбить гербарий итогов весенних анонсов и летних продаж.
Вот почему, осенью мы вновь вернулись к синтетическим тестам пакета D3D RightMark.
Надеемся, что благодаря наличию исходных текстов тестовых модулей, D3D RightMark вызовет интерес не только у любителей померить свои карты, но и у разработчиков, желающих создать собственный тест (изначально совместимый с удобной оболочкой) и не заботиться при этом о программировании достаточно трудоемких интерфейсных функций, таких как представление результатов или настройка параметров.
Смотрите, советуйте, пишите свои отзывы и пожелания!
Перед прочтением данного материала настоятельно рекомендуем обратиться к предыдущим тестированиям содержащим «синтетическую» часть:
- Oбзор ATI RADEON 9800 PRO
- Тестирование линейки RADEON 9500-9700 в DirectX 9.0: Часть 2 — синтетические тесты RightMark 3D
- NVIDIA GeForce FX 5900 Ultra (NV35)
Ибо, эта статья во многом опирается на их результаты, являясь скорее сравнением, развитием и дополнением уже озвученных в предыдущих материалах выводов, нежели неким «самодостаточным» исследованием. Однако, время не ждет, с каждым днем становится все холоднее и нам пора вернуться к сути вопроса:
Карты — участники тестирования
На сей раз, мы решили не ограничиваться самыми производительными чипами конкурирующих DX9 линеек, а протестировали широкий спектр карт различной стоимости. Мы догадываемся, что читателям не только (и даже не столько) интересно сравнивать между собой дорогие и продаваемые в достаточно скромных количествах карты, но и самые доступные по цене (low-end) а также, твердых середнячков (mainstream). Поэтому, нами были сознательно выбраны достаточно типичные (для прилавков) представители средних и недорогих семейств.
Итак, в нашем тестировании приняли участие следующие карты:
- NVIDIA GeForceFX 5900 Ultra 256MB DDR 2.2ns (450/850 MHz)
- NVIDIA GeForceFX 5800 Ultra 128MB DDR2 2.0ns (500/1000 MHz)
- NVIDIA GeForceFX 5600 Ultra 128MB DDR 2.2ns (400/800 MHz)
- NVIDIA GeForceFX 5600 128MB DDR 3.6ns (325/550 MHz)
- NVIDIA GeForceFX 5200 Ultra 128MB DDR 2.8ns (325/650 MHz)
- NVIDIA GeForceFX 5200 128MB DDR 5ns (250/400 MHz)
- ATI RADEON 9800 Pro 128MB DDR 2.8ns (380/680 MHz)
- ATI RADEON 9700 Pro 128MB DDR 2.8ns (325/620 MHz)
- ATI RADEON 9600 Pro 128MB 2.8ns (400/600 MHz)
- ATI RADEON 9600 128MB 4ns (325/400 MHz)
- ATI RADEON 9500 PRO 128MB 3.6ns (275/540 MHz)
- ATI RADEON 9500 128MB 128bit 3.6ns (275/540 MHz)
Конфигурации тестовых стендов:
- Компьютер на базе Pentium 4 3200 MHz:
- процессор Intel Pentium 4 3200 МГц;
- системная плата DFI LANParty Pro875 (i875P);
- оперативная память 1024 MB DDR SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1; DirectX 9.0a;
- мониторы
ViewSonic P810 (21") иViewSonic P817 (21"). - драйверы NVIDIA версии 45.20, ATI версии 6.368.
VSync отключен.
Тест GPS — геометрическая производительность
В этот раз мы поставили перед собою две основные цели. Во-первых, выяснить, как теперь, после нескольких месяцев интенсивной отладки драйверов и DirectX 9, обстоит ситуация с различной производительностью вершинных шейдеров версий 1.1 и 2.0. Для полноты картины мы протестировали и производительность эмуляции фиксированного TCL (aka FFP). Во-вторых, мы обратим внимание на то, как соотносятся между собой с точки зрения геометрической производительности недорогие и средние карты. Разумеется, мы не будем приводить результаты всех доступных геометрических тестов из пакета D3D RightMark, а остановимся на четырех из них:
- Ambient — самое простое освещение и трансформация, фактически, показывает нам практический предел пропускной способности карты по треугольникам;
- 1 Diffuse — один простейший источник света, нетребовательное освещение;
- 3 Diffuse — три простых источника света, типичная ситуация;
- 3 Specular — три сложных источника с бликами — достаточно интенсивная с вычислительной точки зрения ситуация;
Итак, прокомментируем результаты:
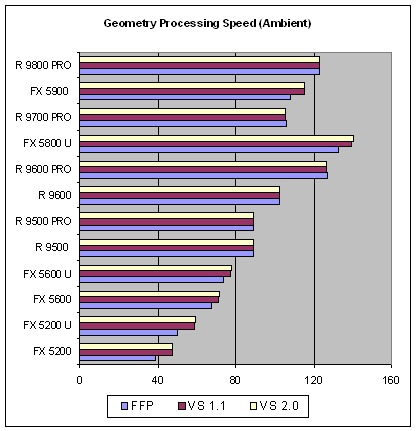
Число на графике обозначает миллионы трансформированных и освещенных треугольников в секунду. Для каждой карты приведены три результата — TCL и вершинные шейдеры 1.1 и 2.0 версий. Сразу бросается в глаза тот факт, что для продуктов ATI пиковая (напомним — это простейший случай) производительность не зависит от версии шейдера или факта использования эмуляции TCL (которая, как мы уже упоминали, в случае всего семейства RADEON третьего поколения является обычным шейдером). Отметим, что на этом, и всех последующих графиках мы разместили карты, в порядке приближенном к некой «ожидаемой» от них производительности — такой вариант видится нам более наглядным, ибо позволяет оценивать результаты сразу с точки зрения позиционирования карты на рынке. Есть и исключения — GeForce FX 5800 Ultra приведена скорее для сравнения, как известно, эта карта с точки зрения обычного потребителя весьма призрачна. Вернемся к нашим результатам. У всех чипов NVIDIA заметно различие производительности разных версий шейдеров и эмуляции. Картина приблизительно одинаковая как для серии 5200, так и для 5900. А теперь самое интересное: весной и в начале лета мы наблюдали существенную разницу в производительности вершинных шейдеров 1.1 и 2.0 в этом тесте, у продуктов на базе ускорителей NVIDIA. Теперь, этой разницы практически нет, она находится в пределах близких к погрешности теста. Как мы и предполагали — вопрос имел отношение не к железу, а к драйверам и/или DirectX и теперь, он наконец-то решен. Что лишний раз подтвердило наш постулат, о необходимости считать геометрическую производительность, как и цыплят по осени ;-). Впрочем, это вполне логично — создатели и отладчики программного обеспечения как обычно идут в хвосте разработчиков железа.
Относительную диспозицию чипов читатели могут оценить на свой собственный вкус, приняв во внимание распространенные в их регионе цены, мы же в свою очередь выделим заметное преимущество (в этом тесте) пары середнячков RADEON 9600 и 900PRO над сходно позиционируемыми чипами NVIDIA.
Тем временем, нас ждут результаты остальных геометрических тестов:
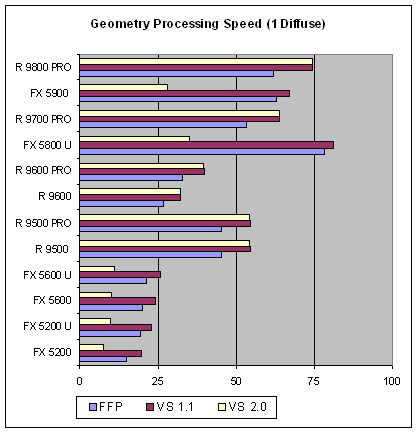
А вот и первые сюрпризы. Как мы видим, пиковая производительность в предыдущем тесте еще ни о чем не говорит — в более-менее реальной задаче мы получили совершенно иную картину. Во-первых, в глаза бросается факт ужасающего падения производительности вершинных шейдеров 2.0 на всех ускорителях линейки NVIDIA. Более чем в два раза (!). Во вторых, разница между эмуляцией TCL и вершинными шейдерами версии 1.1 увеличилась как у продуктов ATI так и у продуктов NVIDIA. Причем, последние показали себя в этом вопросе чуть более стойко. Безраздельному царствованию RADEON 9600/9600 PRO пришел конец — его предшественник RADEON 9500/9500 PRO расправил крылья и большее число геометрических ALU. GeForce FX 5600/5600 Ultra по прежнему проигрывает семейству 9600 но уже не столь значительно. Посмотрим, что будет происходить далее, по мере все большего и большего усложнения задачи:
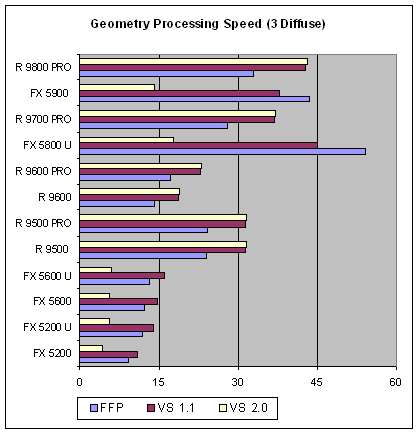
Картина взаимной расстановки практически не изменилась, за исключением двух фактов для чипов NVIDIA: падение на вершинных шейдерах 2.0 стало еще более значительным и эмуляция TCL вдруг вырвалась вперед на старших продуктах (5800/5900) NVIDIA. А теперь самый сложный вариант:
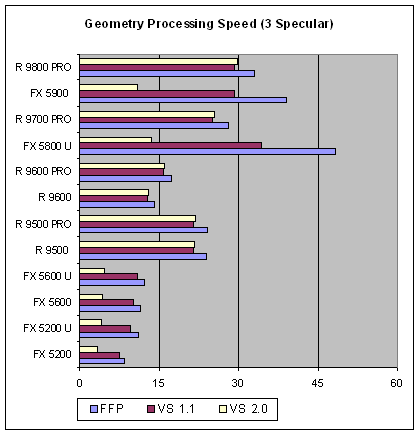
Сохранились тенденции предыдущего теста, хотя и преимущество ATI несколько поблекло, результаты RADEON упали сильнее, чем результаты конкурирующих продуктов. С ростом сложности задачи NVIDIA пытается расправить крылья, но, тенденции еще недостаточно. С точки зрения абсолютного результата — ATI на высоте.
Сразу хотим отметить важнейший момент, имеющий отношение к любым синтетическим тестам. Вершинная производительность это только вершинная производительность и не более того. Мы не можем однозначно делать выводы об относительной производительности тех или иных ускорителей в играх, только на основе полученных нами в этом тесте результатов, даже, имея достаточное представление о сложности геометрических задач которые эти игры ставят перед ускорителем. Ведь реальное приложение может упереться в другой фактор, например скорость закраски и выборки текстур или CPU и даже (в случае особенно неудачно написанных приложений) в какие либо аспекты драйверов. Не забывайте, что общая картина должна складываться из множества кирпичиков и геометрическая производительность лишь один из них. Впрочем, весьма существенный.
PS2 — пиксельные шейдеры 2.0
Мы опять разумно ограничили число тестов, результаты которых мы приводим в статье (слишком большое обилие одинаковой информации вряд ли добавит ясности) и остановились на четырех ситуациях:
- 1 Diffuse — попиксельное освещение с одним источником света и рассеянной составляющей.
- 1 Specular — попиксельное освещение с одинм источником света и двумя (рассеянной и отраженной) составляющими.
- 3 Specular — сложный вариант с попиксельным освещением сразу тремя источниками, причем с двумя составляющими каждый.
- Procedural — вычисление процедурной анимированной текстуры.
Причем, все эти тесты выполнялись в четырех вариантах:
- 32 бит точность вычислений (24 для ATI) с вычислением нормализации арифметическими операциями
- 32 бит точность вычислений (24 для ATI) с вычислением нормализации с помощью заранее рассчитанной таблицы — более ориентированный на выборку текстур, чем на вычисления подход.
- 16 бит точность вычислений (на ATI тест не прогонялся) с вычислением нормализации арифметическими операциями
- 32 бит точность вычислений (на ATI тест не прогонялся) с вычислением нормализации с помощью заранее рассчитанной таблицы — более ориентированный на выборку текстур, чем на вычисления подход.
Тесты с уменьшенной точностью вычислений не прогонялись на ускорителях ATI. В силу аппаратных особенностей семейства RADEON третьего поколения, все пиксельные вычисления идут с компромиссной (но достаточной для практически любых задач) 24 битной точностью и использование в шейдерах форсированных (16 битных) вычислений ничего не дает.
Итак, первые результаты:
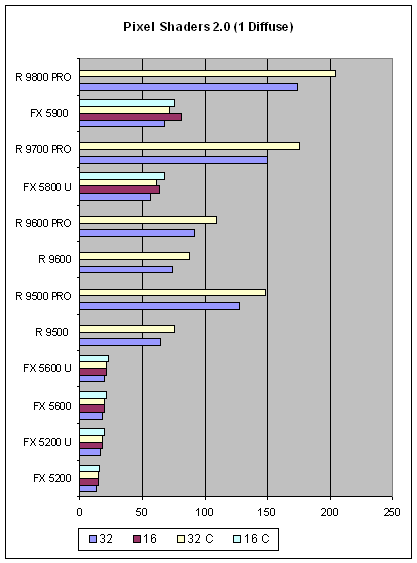
В легенде графика, 32 и 16 соответственно обозначают затребованную точность вычислений, а суффикс «С» - вариант с использованием для нормализации выборки значений из таблицы (вместо арифметических операций) смещающий баланс шейдера из вычислительной области в сторону выборки текстур. На оси отложены кадры в секунду (напомним, что в нашем тесте, в каждом кадре всегда закрашивается одинаковое число пикселей, а точнее, 1280х1024, т.е., около 1.3 миллиона пикселей).
Что мы видим? В простейшем случае производительность NVIDIA не сильно зависит от выбранной точности или метода, выборка текстур предпочтительнее, но лишь на небольшую толику, так же как и вычисления с пониженной точностью. В общем и целом продукты ATI существенно выигрывают в этом тесте, в среднем вдвое опережая адекватно позиционированные карты NVIDIA. И в этом нет ничего удивительного — мы уже неоднократно отмечали более высокую производительность пиксельных шейдеров ATI. Посмотрим, что будет происходить по мере усложнения задачи:
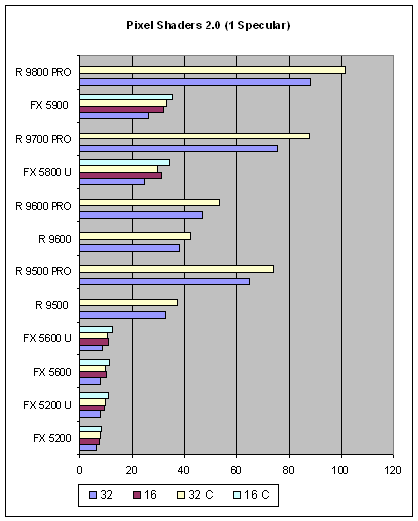
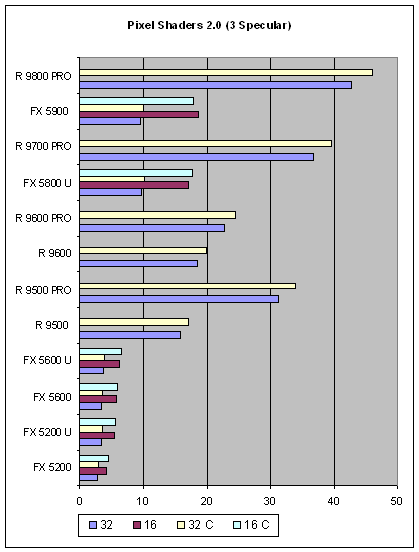
Намеченные в первом тесте тенденции и взаимное расположение сохранились. По мере усложнения задачи становится все более и более заметной разница между 16 битными и 32 битными вычислениями у NVIDIA — оптимизация точности при написании шейдеров для этих карт стоит потраченных на освещение рабочего места программиста свечей. Однако, сам по себе метод нормализации практически не дает разницы — в отличии от ATI, где она заметна и колеблется между 5 и 10%. Констатируем, что в данных, достаточно распространенных задачах попиксельного освещения, NVIDIA способна худо-бедно состязаться с ATI только при использовании 16 битной точности вычислений. И то, проигрывая в разы.
И, наконец, достаточно передовое (кинематографичное) применение пиксельных шейдеров — вычисление анимированной процедурной текстуры:
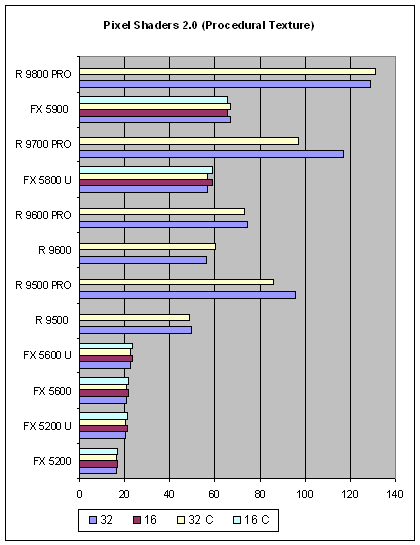
от точности вычислений зависит не так много. NVIDIA немного реабилитировала свои позиции, но по прежнему вдвое менее производительна. Пиксельные шейдеры 2.0 не являются коньком этой марки.
HSR — раннее удаление невидимых точек
Напоминаем, что в этом тесте мы измеряем эффективность раннего (до вычисления шейдеров и закраски) удаления невидимых поверхностей и точек, выраженную в двух характеристиках:
- Предельная (Maximal) практически достижимая эффективность HSR — соотношение между производительностью вывода сцены отсортированной наихудшим образом (из далека к нам) и наилучшим (от нас вдаль).
- Средняя типичная (Typical) эффективность HSR — соотношение между производительностью вывода сцены отсортированной случайным образом и сцены отсортированной наилучшим образом (от нас вдаль).
Выигрыш от наличия HSR в чипе в в реальных приложениях будет близок ко второму параметру, а превый, предельный параметр, позволяет нам прикинуть эффективность аппаратной реализации (алгоритма) HSR в конкретных семействах чипов.
Для начала приведем три графика с обеими значениями эффективности (пиковая и типичная) для трех сцен с различной степенью детализации, от простой (Low), характерной для DX7 игр, до сложной (High) достойной будущих блокбастеров:
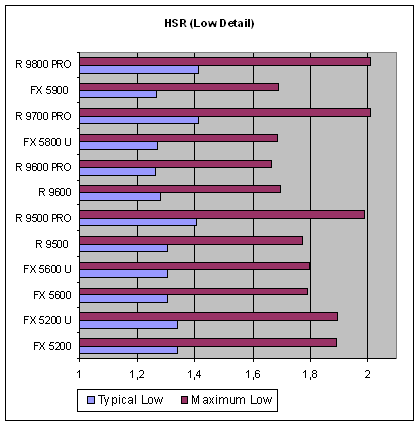
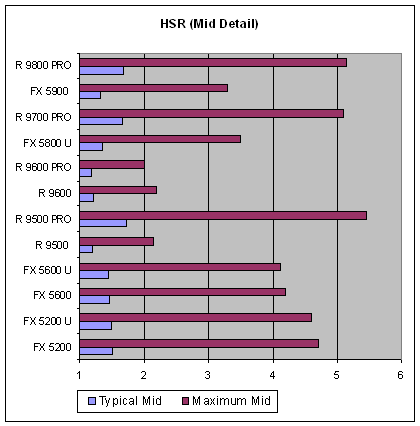
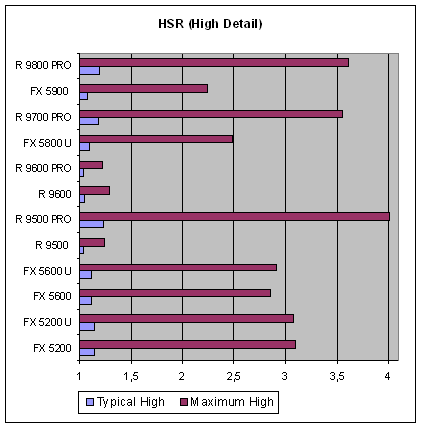
Итак, отметим два факта. Во-первых, с ростом сложности сцены меняется и эффективность HSR, причем как предельная, так и типичная. Во-вторых, отличие первой от второй очень значительно, а это значит, что выигрыш в приложениях вряд ли будет зависеть от активации HSR «в разы», и очень сильно чувствителен к тому, как приложение выводит сцену. Самое страшное — неоптимальный вариант, сцена которая строится издалека. Его необходимо всячески избегать. Даже с отсутствием какой либо сортировки, в случае равномерного, хаотического вывода сцены все выглядит куда как лучше, а та или иная (например, портальная) сортировка, даже в грубой форме способна добавить до 30% скорости.
Отметим, так же, что измеренная здесь эффективность зависит от того, как выполняется закраска — т.е. чем сложнее шейдеры и больше текстур, тем более ощутимо будет влияние HSR, избавляющей чип от необходимости вычислять невидимые пиксели. А теперь попробуем представить эти данные несколько иным образом, сгруппировав по сложности, возможно, так мы сумеем увидеть более четкую картину:
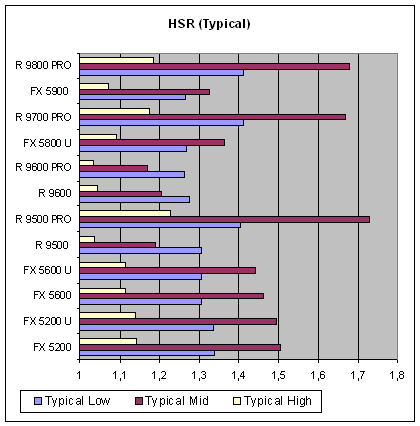
Как мы видим наиболее существенное типичное преимущество получат приложения со сценами средней сложности (ATI) и частично низкой (NVIDIA). Т.е. HSR алгоритм NVIDIA более терпимо относится к простым сценам старых игр. Кроме того, хорошо заметно, что эффективность HSR у продуктов ATI меняется скачкообразно — RADEON 9500 PRO, 9700 PRO и 9800 PRO демонстрируют завидное преимущество на средних по сложности сценах а вот RADEON 9500 и 9600/9600 PRO подобным всплеском похвастать не могут, имеют нормальные результаты в сценах простых, слабые в сценах средней сложности и совершенно разгромные на тяжелых сценах. Видимо, сказывается отсутствующий или отключенный иерархический Z буфер. Итак, в этом тесте сложно назвать однозначных лидеров, ибо для среднего и тем более нижнего класса это NVIDIA а вот среди дорогих карт лидирует скорее ATI. Нам искренне не понятно желание последней убрать HSR из дешевых и средних решений — тем самым, они закладывают потенциальный проигрыш NVIDIA по мере роста сложности сцен выводимых реальными приложениями. Копеечная экономия и желание разнести результаты адекватно с уровнем цены способна в будущем сыграть ATI недобрую службу.
Теперь, давайте посмотрим на зависимость эффективности от разрешения (типичная и максимальная, на сцене самой высокой степени сложности):
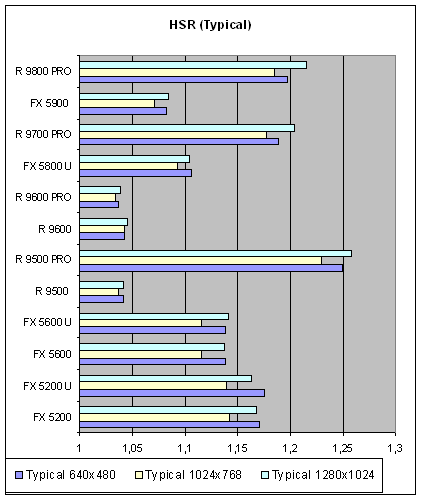
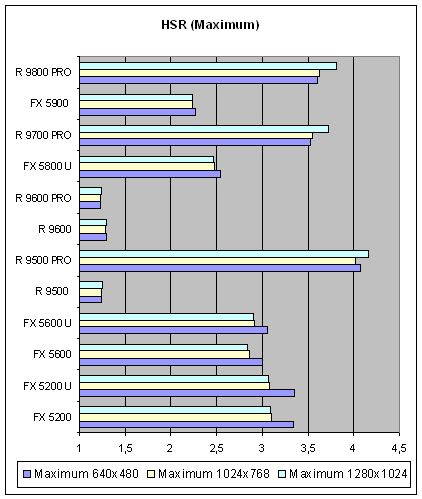
Как мы видим, зависимость не очень велика, чтобы принимать ее во внимание. А вот слабая эффективность работы HSR для средних и недорогих решений ATI вновь налицо. И если в случае с 9500 этот вопрос может быть решен взломом драйверов тем или иным методом (например, подстройкой параметров в реестре) то в случае семейства 9600 иерархический буфер может отсутствовать и на аппаратном уровне. Таким образом, ATI отрезает себе путь к «волшебному» скачку производительности с новыми драйверами, который, мог бы быть неплохим козырем в конкурентной борьбе, например, в момент выхода DOOM III.
PF — закраска и выборка текстур
В этом тесте, очень точно выявляющем предельные параметры железа, практически ничего не изменилось — весенние результаты уже хорошо соответствовали нашим представлениям о железе и, поэтому, мы не будем приводить заново зависимости от числа текстур или другие базовые параметры скорости закраски, а обратим наше внимание на потенциально более менее зависящий от драйвера аспект: зависимость скорости выборки текстур от размера оных ( а следовательно и от менеджмента локальной памяти ускорителя).
Итак, для начала приведем зависимость производительности билинейной и трилинейной фильтраций от размера текстур:
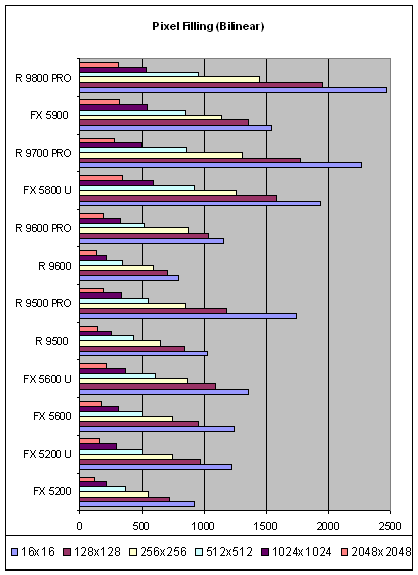
Видно, что в случае продуктов ATI, особенно старших моделей, зависимость очень четко выражена — ситуация достаточно быстро упирается в пропускную способность памяти и эффективность кеширования. В случае 9600 последняя достаточно высока — по мере роста размера текстур ему удается сравниться с 9500 PRO. У старших продуктов NVIDIA скорость падает не так быстро — чем больше текстуры тем ближе они подбираются к ATI и при размере порядка 512х512 уже догоняют последнюю. Интересно отметить что общая расстановка сил достаточно равномерна, в вопросах брутальной закраски, в отличии от вопросов пиксельных вычислений NVIDIA составляет вполне успешную конкуренцию ATI. А в случае среднего и дешевого сегментов — имеет и некое преимущество, особенно если принять во внимание цену самых младших моделей.
Теперь посмотрим, что произойдет при использовании трилинейной фильтрации:
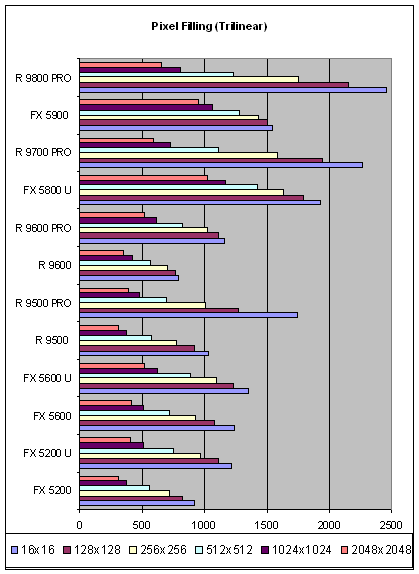
Падение NVIDIA стало еще менее ярко выраженным — сказывается два момента — наличие двух текстурных блоков на одном пиксельном конвейере и более оптимизированный алгоритм трилинейной фильтрации (уже обсуждался нами в обзорах ранее). Теперь, на больших размерах текстур NVIDIA даже поучила преимущество. Младшие продукты линейки выглядят еще более заманчиво, опережая сходно позиционируемые разработки ATI.
Теперь посмотрим, как сказывается на скорость фильтрации наличие или отсутствие MIP уровней:
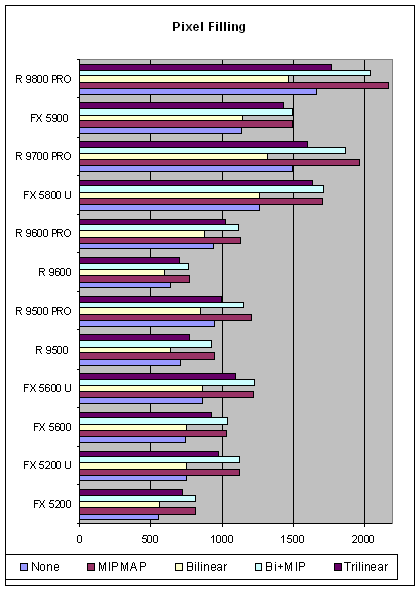
Очевидно, что билинейная фильтрация почти бесплатна. А в случае NVIDIA она совершенно бесплатна. Также, хорошо заметно, что наличие MIP уровней существенно увеличивает производительность закраски, оптимизируя работу текстурного кэша. В общем и целом NVIDIA вполне конкурентно способна в вопросах фильтрации (особенно трилинейной), в отличие например от тех же сложных вычислений с помощью пиксельных и вершинных шейдеров 2.0, которые как мы уже неоднократно замечали, даются ей не просто нелегко а очень нелегко. Заметно выбивается из общего ряда RADEON 9600 — он проигрывает соклассникам из NVIDIA.
Напоследок приведем интересный факт:

В случае анизотропной и совместной (анизотропия плюс трилинейка) фильтрации в этой версии драйверов NVIDIA практически игнорирует установки степени анизотропии приходящие из приложений — разница невелика, а вот ATI демонстрирует достаточно четкую зависимость от выбранной приложением установки.
Итак, подводя итоги тестирования закраски, отметим, что в этой области продукты NVIDIA вполне реабилитируют себя.
Выводы
ATI любит:
- Средние размеры геометрии сцен.
- Интенсивные вычисления + пиксельные шейдеры 2.0 высокой точности
- Вершинную производительность как таковую
- И особенно вершинные шейдеры 2.0
- Высокую тотальную производительность дорогих ускорителей
NVIDIA любит:
- Грубую интенсивную закраску и большие текстуры
- Простые и средние размеры геометрии сцен
- Много текстур, интенсивную трилинейную и анизотропную фильтрацию
- Малую точность пиксельных шейдеров
- Сложные приложения на средних и недорогих ускорителях
И наконец, говоря о соотношении сил NVIDIA и ATI не забывайте о ценах! При такой плотной линейке продуктов, главное это сравнить между собой не производителей, а скорее конкретные модели ускорителей с конкретной ценой. Особенно в среднем сегменте.


