Обзор NVIDIA GeForce3 — часть 2
Возможности GPU GeForce3 на примерах из DirectX 8.0 SDK
Итак, попробуем подробно рассмотреть все технологические новшества нового графического процессора.
Для тестирования мы будем использовать различные примеры из DirectX 8.0 SDK, некоторые из которых
были нами модифицированы, дабы получить возможность наглядно продемонстрировать выигрыш, получаемый
благодаря использованию сжатого формата Z буфера или HSR. Но для начала продемонстрируем несколько
скриншотов из прекрасных технологических демо-программ NVIDIA, использующих пиксельные шейдеры:



На скриншотах выше последовательно демонстрируются попиксельные отражение, преломление и тени. Итак, первое, с чем нам предстоит иметь дело, — это пиксельные шейдеры. Для начала отметим, что физически, в GeForce3 нет никакого интерпретатора для пиксельных шейдерных команд — последовательное исполнение слишком медлительно для подобных задач. Код пиксельного шейдера транслируется в параметры настройки 8 стадий комбинационного конвейера чипа, которые, по сравнению с предыдущим поколением ускорителей, были обогащены множеством новых возможностей, позволяющих не только исполнять все шейдерные команды, но и реализовывать некоторые другие, дополнительные эффекты, которые вскоре станут доступны через соответствующие расширения OGL, а позже, возможно, и в виде новой версии ассемблера для пиксельных шейдеров. Итак, важно понимать, что это лишь 8 ступенчатый конвейер, хотя и чрезвычайно гибко настраиваемый.
Мы модифицировали программу mfcpixelshader, так, чтобы она позволяла нам измерить производительность
исполняемого шейдера. Также мы добавили в нее загрузку четырех текстур:
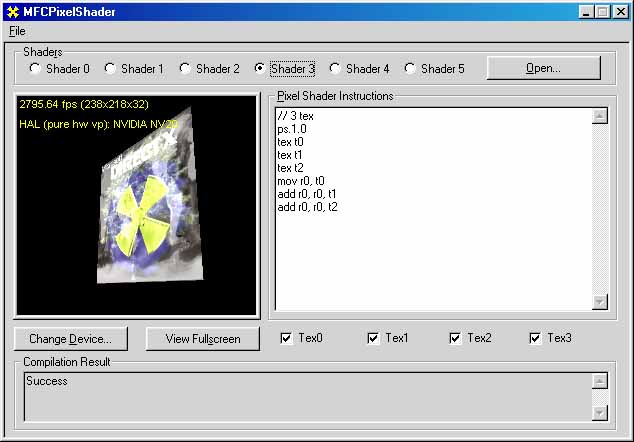
Тестирование проводилось с использованием нескольких шейдеров, начиная с самого простого, не
использующего ни одной текстуры и заканчивая достаточно сложным шейдером из 8 команд, задействующим
все текстурные блоки и оба значения освещения. Итак:
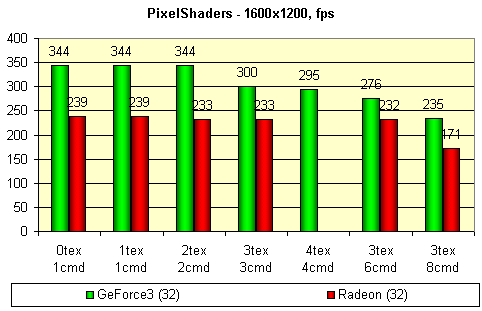
Для сравнения приведены результаты, полученные на RADEON. Тест проводился в режиме 1600x1200@32, дабы максимально снизить зависимость результатов от параметров, связанных с геометрическими преобразованиями. Внизу приведены кодовые обозначения шейдеров в виде Xtex Ycmd — где X количество одновременно используемых текстур, а Y — длина шейдера в стадиях конвейера.
На результатах хорошо заметна задержка в такт, вызываемая использованием более 2-х текстур одновременно у GeForce3 и странное, резкое падение производительности в случае шейдера максимальной длины. Я не нашел этому никакого разумного объяснения, кроме как наличия перезагрузки комбинационного конвейера, например, при достижении края полигона. Как известно, время перезагрузки зависит от количества стадий. Но, в таком случае неясно, почему результаты первых 4 шейдеров практически идентичны.
Как бы там ни было, желающие поэкспериментировать могут самостоятельно скачать SDK с сайта Microsoft и проверить все свои предположения.
Следующий тест измеряет скорость выполнения достаточно сложного вершинного шейдера:

Для сравнения мы приведем значения, полученные в режиме с программной эмуляцией вершинных шейдеров
(напомню, что наш стенд оснащен процессором Pentium III 1000 MHz).
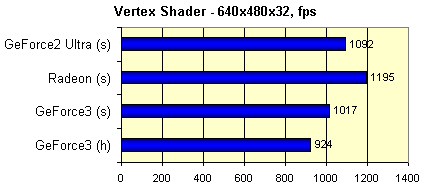
Где (h) обозначает использование аппаратного, а (s) программного исполнения шейдера. Как мы видим, аппаратная реализация шейдеров GeForce3 сравнима по производительности с самыми мощными из современных процессоров. Но не следует забывать, что при программном исполнении шейдера в данном синтетическом тесте ресурсы центрального используются по максимуму, а в случае программной эмуляции в реальном приложении мы получили бы заведомо более низкие значения, т.к. ресурсы CPU пришлось бы делить между множеством других, не менее важных задач, нежели эмуляция шейдера.
Кстати, вершинные шейдеры являются настоящей программой, последовательно выполняемой блоком HW T&L. И здесь, от ее длины, или используемых команд зависит многое. Однако столь подробное исследование выходит за рамки данной статьи.
Следующий тест — матричный блендинг, с использованием двух матриц:

Для сравнения мы приведем значения полученные аппаратным блендингом, и программной эмуляцией, как для
самого матричного блендинга, так и для эквивалентного ему шейдера.
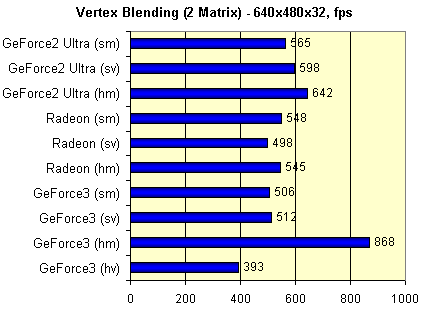
Здесь (hm) обозначает аппаратный двухматричный блендинг, (hv) эквивалентный вершинный шейдер, а (sm) и (sv) их программную эмуляцию соответственно. Цифры удивительно близки, но как бы там ни было, следует отметить, что в случае программной эмуляции выгоднее вершинный шейдер, а в случае аппаратного исполнения — простой матричный блендинг. Здесь GeForce3 существенно производительнее чипов предыдущих поколений. Очевидно, что для получения наибольшей отдачи программистам необходимо комбинировать аппаратный матричный блендинг и шейдеры (для прочих геометрических нужд), исполняя их на аппаратном уровне.
Далее мы детально протестировали производительность HW T&L и его взаимодействие с растеризатором,
использовав для этой цели модифицированный пример optimized mesh:

Мы получили предельные значения для этого несложного синтетического теста с непростой моделью,
состоящей из 40000 полигонов, выводя одновременно 32 уменьшенных модели в маленьком окне, изменение
размера которого уже переставало сказываться на количестве обрабатываемых в секунду треугольников.
Это верный признак "насыщения" системы CPU-HW T&L. Но не следует забывать, что с
появлением новых, более производительных центральных процессоров, GeForce3 может показать несколько
большие результаты. Для сравнения мы приводим максимальные значения, полученные на программной эмуляции:
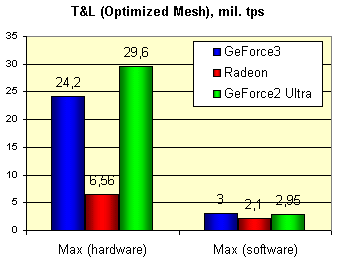
Цифры означают миллионы треугольников в секунду. Что интересно, для GeForce2 Ultra мы практически
достигли заявленного производителем значения (31 миллион). А вот до цифры 60 млн. GeForce3 еще далеко.
На подобном незатейливом тесте карта на базе GeForce3 проигрывает GeForce2 Ultra строго в соответствии
с разницей в тактовой частоте, что наводит на мысль о практически идентичной валовой
производительности блока HW T&L. RADEON смотрится бедным родственником на этом фоне, но мы то
знаем, что современные игры (за исключением считанных единиц, таких как Giants) еще не исчерпали
потенциала его HW T&L. Когда же они будут способны переварить GeForce3, нам остается только
догадываться. Далее мы измерили это же число в реальных разрешениях, дабы проследить, насколько
растеризация оказывается сдерживающим фактором для HW T&L. Приведем величину падения производительности
в процентах для различных разрешений:
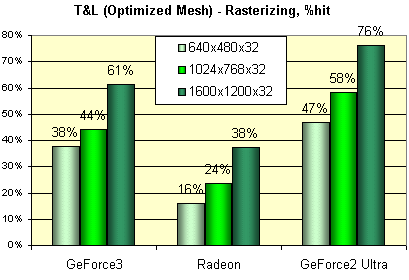
Видно, что с этой точки зрения наиболее сбалансированной картой (в данном синтетическом тесте) является RADEON. А GeForce2 Ultra явный аутсайдер — производительность ее HW T&L практически всегда остается невостребованной.
Теперь выполним три эксклюзивных теста. Отключим Z буфер и исследуем влияние этого фактора на скорость
вывода сцены, а также отключим отсечение обратных граней и оптимизацию модели перед выводом
(оптимизация — сортировка ее вершин так, чтобы вершины, используемые одним треугольником, находились
поблизости в буфере вершин, упрощая жизнь кэшу вершин и блоку их выборки):
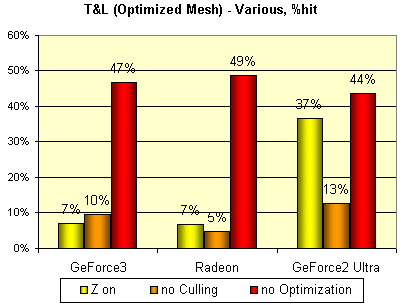
Полученные результаты говорят о том, что по сравнению с GeForce2 Ultra работа RADEON и GeForce3 c Z буфером организована чрезвычайно эффективно. И, что самое главное, вероятно, они используют схожие технологии сжатия Z — величина падения производительности совершенно идентична. Наиболее эффективное (с точки зрения оптимизированной модели) кэширование имеют RADEON и GeForce3, а GeForce2 Ultra вновь аутсайдер. От технологии HSR в данном тесте зависело немного, но все равно, сознательно внесенные обратные грани меньше всего ударили по RADEON. Позднее мы попробуем найти более весомое подтверждение гипотезе о высокой эффективности реализованного в GeForce3 метода HSR.
Приведем изображение модели, нарисованное с отключенным Z буфером (1) и обратными гранями (2):


В заключение, посмотрим на величину падения производительности при использовании (средствами DX, из
самой программы) 2х и 4х FSAA:
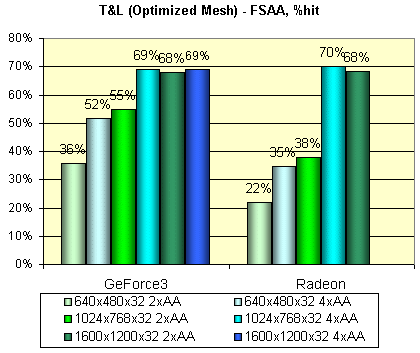
Очевидно, что в случае GeForce3, MSAA абсолютно не бесплатен на подобных сценах — большое количество полигонов дает о себе знать. Кроме того, есть подозрение, что 2x MSAA режим, активизируемый из DX 8 программ, есть не просто 1х2 MSAA, а полноценный Quincunx, о качестве которого будет сказано чуть ниже.
Теперь протестируем производительность аппаратной тесселяции гладких поверхностей.


Сравнивать тут, к сожалению, не с чем — программная эмуляция HW T&L эту
возможность не поддерживает. Поэтому просто приведем зависимость производительности
от числа разбиений сторон патча:
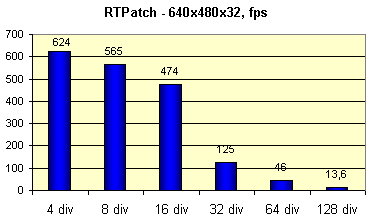
Видно, что где-то после значения 16 наступает перелом и производительность заметно снижается, но уже и при такой детализации модель выглядит весьма гладкой.
Еще один тест — PointSprites. Система частиц, отражающихся от поверхности. Результаты приведем без
комментариев, отметив только, что реализация оных у RADEON очень хороша с точки зрения производительности
(если принять во внимание его тактовую частоту), но подкачала в качестве — текущие драйверы
накладывают текстуру на спрайты неединичного размера неверно.
Следующий тест измеряет производительность закраски для наложения карт среды (EM) и EMBM:

У всех карт, участвующих в этом тесте, EMBM не бесплатен:
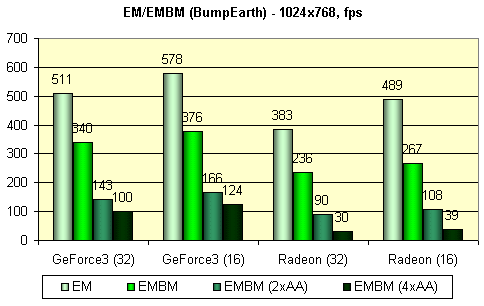
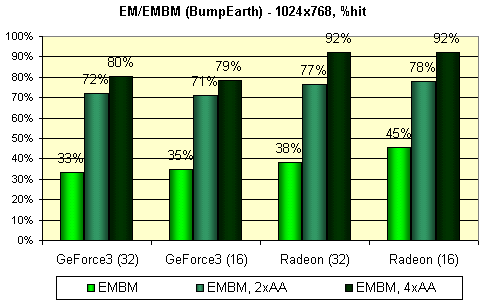
Налицо практически идентичные результаты в 16 и 32 бит цвете и несколько меньшее падение производительности для GeForce3. Также удивляет существенное падение скорости при включенном FSAA - даже у GeForce3 в 2х режиме. Как мы видим, существуют несложные DX 8 приложения, способные, по той или иной причине, существенно проиграть при включенном FSAA. Возможно, причина в том, что хотя они и несложны, но построение изображения занимает сравнимое с проходом сглаживания время.
Теперь проведем несколько распространенных синтетических тестов. 3DMark 2000 позволил нам проследить
за зависимостью производительности HW T&L от числа источников света:
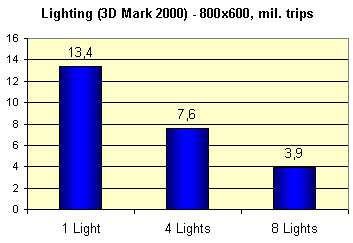
Все то же существенное линейное падение, хорошо знакомое нам по картам на базе GeForce2. Но, не следует забывать, что вершинные шейдеры позволяют нам подсластить этот факт возможностью использовать большее число источников света или более сложные техники освещения на наш выбор. Для GeForce3 он ограничен только длиной программы шейдера (до 128 команд) и нашей фантазией. Приведем значения fillrate, теоретические и измеренные на практике:
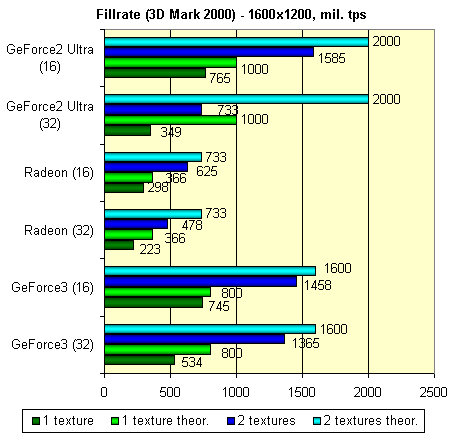
Наименее сбалансированной архитектурой оказался GPU GeForce2 Ultra, наиболее сбалансированными являются GPU RADEON и GeForce3, с попеременным успехом. Именно величины их fillrate наиболее близки к теоретическим значениям, а, следовательно, сильнее раскрывают потенциал своей тактовой частоты и числа конвейеров.
А этот тест (на основе несложного скринсэйвера) позволяет проследить падение производительности GeForce3 в различных принудительных режимах MSAA, описанных нами ранее и выбираемых в панели настроек драйвера:
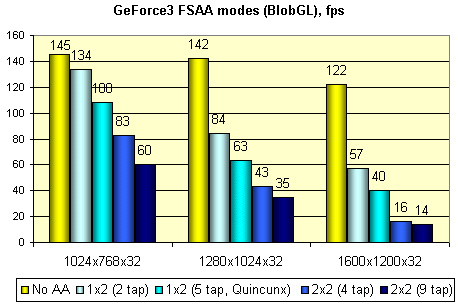
Как видно, в разрешении 1024x768 мы вольны выбирать любые методы сглаживания, режим 1280x1024 оставляет нам метод 1x2 и Quincunx, а в 1600x1200 лучше использовать "как есть". Эта картина очень характерна для GeForce3, но об этом чуть позднее, при обсуждении результатов реальных игровых тестов. И, напоследок, хорошо известный тест эффективности HSR, VillageMark (сцена с огромным значением overdraw):

А вот и полученные в этом тесте результаты:
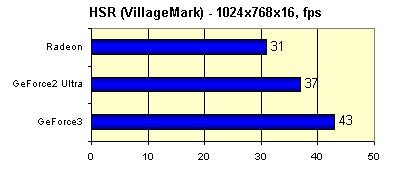
Высокая эффективность реализации HSR у GeForce3 — вне всяких сомнений. А близость к нему значения, полученного у карты на базе GeForce2 Ultra, объясняется более высокой тактовой частотой ядра у этого GPU. Но и RADEON, что называется, приятно удивил… Схожесть результатов снова наводит на мысли о схожести реализованных аппаратно методик — вероятно, GeForce3 также имеет дело с иерархическим Z буфером и HSR на его основе.
А теперь запустим TreeMark — родное детище NVIDIA. Ну разве можно не померить им их же новый GPU?
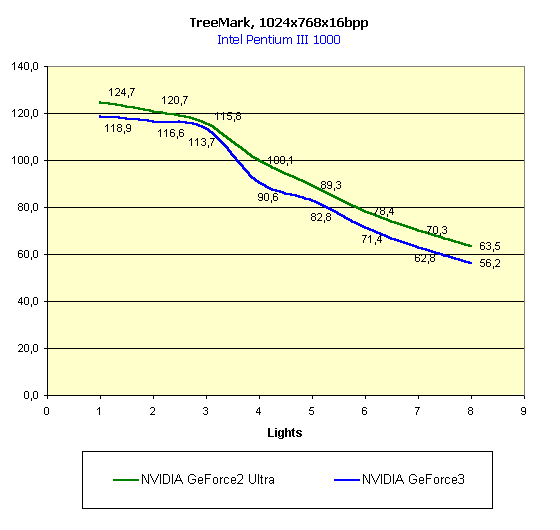
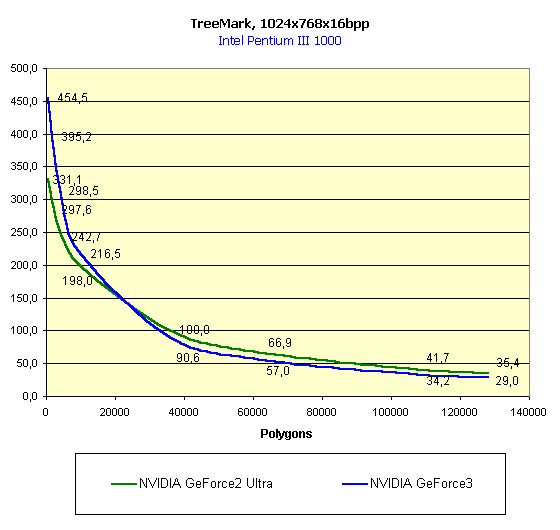
Грубо говоря, HW T&L у GeForce2 Ultra снова впереди, а вот малое число полигонов, наоборот, дает
фору GeForce3 — есть где развернуться HSR и Z компрессии. Что же, на этом все, перейдем к
немногочисленным реальным приложениям.
[ Следующая часть ]
| 27 февраля 2001 г. |
|
|