IBM POWER4 — процессор из параллельного мира
1. Параллелизм инструкций
Большинство современных процессоров обладают сходной архитектурой — это конвейерные суперскалярные процессоры с внеочередным (спекулятивным) исполнением инструкций, как RISC, так и X86. Сущность этого подхода заключается в том, что в процессоре присутствует несколько параллельно работающих функциональных устройств (FU), исполняющих по мере возможности инструкции из специального буфера, куда они поступают после декодирования. Плюсом таких процессоров является тот факт, что распараллеливание происходит независимо от программиста (по крайней мере, на языках высокого уровня) и нет необходимости использовать специальные алгоритмы и языковые конструции, использующиеся при разработке программ для машин с несколькими процессорами. Можно подумать, что, увеличивая число FU до необходимой величины, можно достичь очень высокой степени параллелизма инструкций (Instruction Level Parallelism, ILP). В какой-то степени это так. Однако суперскалярная архитектура имеет много ограничений, и они стремительно возрастают с ростом числа исполняющих устройств, в частности:
1. Зависимости между регистрами — число регистров для обеспечения достаточной загрузки FU в среднем должно расти квадратично с увеличением числа FU. Мы видим, что X86 ISA с ее 8-ю GPR имеет очень большие сложности для дальнейшего роста ILP путем увеличения числа функциональных устройств, для чего видимые регистры отображаются на гораздо большее множество скрытых регистров. RISC-архитектуры в этом случае более благополучны, однако и здесь приходится применять ту же технику переименования регистров. Она не является панацеей с точки зрения увеличения производительности и к тому же приводит к усложнению микросхемы. Впрочем, надо отметить, что теоретический предел ILP для суперскалярных процессоров очень велик (десятки инструкций за такт для многих программ, входящих в тесты SPEC), но практически даже о намного более низком уровне параллелизма говорить не приходится.
2. Быстро увеличивающаяся сложность процессора — сложность разработки, отладки и тестирования — выливается в большие финансовые расходы и увеличение сроков разработки микросхем, не компенсирующиеся адекватным увеличением производительности.
3. Возрастающие требования к кэшу 1-го уровня — для того, чтобы эффективно "кормить" большое число FU, кэш должен обладать высокой пропускной способностью и, что не менее важно, емкостью. Расплатой является повышение задержек, что приводит к падению производительности. Также требуется значительное увеличение числа портов к регистрам.
По некоторым оценкам, для удвоения уровня ILP по отношению к современным суперскалярным процессорам необходимо около 128 GPRs и 8 ALU + 8 устройств загрузки/записи. Возможно, это будет реализовано через довольно значительное время в будущих чипах IA-64, однако, уже сейчас для большого числа приложений то же увеличение скорости может быть достигнуто более простыми способами.
2. Параллелизм потоков
Способом увеличения производительности суперскалярных процессоров в настоящее время представляются различные технологии TLP (Thread Level Parallelism). Процессоры, использующие этот подход, одновременно (или почти одновременно ;-)) исполняют несколько потоков инструкций. Прибавку в скорости от TLP получают многопоточные программы — для них имеет смысл использовать уже существующий параллелизм в программах, оптимизированных для исполнения на многопроцессорных системах. Временным решением является внедрение какой-либо разновидности SMT (Simultaneous multithreading), например, HMT (Hardware Multi-Threading) от Intel. Эта технология должна обеспечить более эффективную загрузку FU и оптимизировать доступ к памяти существующих суперскалярных архитектур, при этом потоки разделяют одни и те же функциональные устройства процессора. Оценки показывают, что выигрыш в производительности составляет 10-30% для различных программ на процессорах Xeon (практически Pentium 4). Другим примером реализации SMT является серверный процессор семейства Power PC IBM RS64 IV, предшественник POWER4 в системах pSeries 6000 (RS/6000) и iSeries 400 (AS/400). [1]
В целом SMT выглядит как логичное и достаточно несложное в реализации усовершенствование современных процессоров.
Более радикальным подходом является Chip MultiProcessing (CMP) — размещение нескольких процессорных ядер на одном кристалле, и в настоящее время технология достигла того уровня, когда стало возможным разместить на одном чипе два сложных суперскалярных процессора и достаточное количество кэша. Фактически мы получаем SMP-систему, а благодаря расположению ядер на одном кристалле можно получить намного более высокую скорость обмена между процессорами, чем при использовании любых внешних шин, коммутаторов и т.д. Любопытно, что в самом начале девяностых Intel, по крайней мере, гипотетически рассматривала создание подобного процессора — чип "786" под кодовым названием Micro-2000 должен был обладать 4-мя ядрами, включать дополнительно 2 векторных процессора и работать на частоте 250 МГц. Сравните это с Pentium 4 :). POWER4 представляет собой 2 идентичных процессорных ядра, реализующих набор инструкций PowerPC AS, размер кристалла составляет около 400 mm2, он изготовляется по 0.18 мкм медной SOI-технологии IBM CMOS 8S2 c 7-слоями металлизации, работает на частотах 1.1 и 1.3 GHz, и, несомненно, является самым быстрым в настоящее время микропроцессором. Существует также разновидность POWER4 с одним процессором на кристалле. Впрочем, конкуренты не дремлют — HP и SUN тоже собираются достаточно скоро выпустить CMP-процессоры, но они будут производиться уже с использованием 0.13 мкм техпроцесса. Возможно, этим путем последует и AMD.
3. IBM POWER4 — введение
Чтобы лучше разобраться в архитектуре POWER4, следует учесть основные принципы, которыми руководствовались разработчики при его создании. Прежде всего, это процессор, ориентированный на максимальную производительность, на рынок hi-end серверов и суперкомпьютеров, рассчитанный на создание 32-процессорных SMP-систем. Большое внимание было уделено разработке выскопроизводительных средств коммуникации процессоров между собой и с памятью. Для повышения отказоустойчивости POWER4 разрабатывался таким образом, чтобы в случае критических сбоев по возможности происходило не "зависание" системы, а генерация прерываний, обрабатываемых системой. POWER4 разрабатывался для эффективной работы как коммерческих (серверных), так и научно-технических приложений. Замечу, что ранее в семействе процессоров IBM Power/Power PC существовало разделение на "серверные" и "научные" процессоры — POWER и RS64. Можно сказать, POWER4 — бескомпромиссный процессор, рассчитанный на широкий круг hi-end приложений, использующий все актуальные на сегодняшний момент способы повышения производительности (в рамках набора инструкций PowerPC, конечно). Мы не найдем здесь урезанных кэшей и "нехватающих" функциональных устройств. Несколько подозрительно выглядит заявление о дизайне чипа, специально рассчитанного на высокие тактовые частоты; собственно, дальше мы увидим, по какой причине частота POWER4 подпрыгнула со скромных 600МГц RS64 IV до вполне почтенных 1.3 GHz.
4. Кристалл POWER4
На чипе POWER4 размещено 2 процессора, каждый из которых обладает собственными кэшами первого уровня для данных и инструкций. На кристалле имеется единый для обоих процессоров кэш 2-го уровня объемом 1450 КБ, управляемый тремя раздельными контроллерами, подключенными к процессорным ядрам через коммутатор (Core Interface Unit, CIU). Контроллеры работают автономно и могут выдавать за такт 32 байта данных. Каждый из процессоров использует для коммуникации с CIU две раздельные 256-битные шины для выборки инструкций и загрузки данных, а также отдельную 64-битную шину для сохранения результатов, пропускная способность L2-кэша порядка 100 GB/s. В целом, система L2-кэша выглядит сбалансированной и очень мощной. У каждого из процессоров имеется специальный блок для поддержки некэшируемых операций (Noncacheable Unit). Контроллер кэша 3-го уровня и контроллер памяти также размещены на кристалле. Для связи с кэшем 3-го уровня, работающим на 1/3 частоты процессора, и памятью используются две 128-битных шины, работающих на 1/3 частоты процессора. Пропускная способность интерфейса памяти составляет около 11 GB/s. Потоками данных из памяти, кэшей 2-го и 3-го уровня, а также шинами между чипами управляет устройство, называемое "Fabric Controller":

32-х разрядная шина GX Bus, работающая на 1/3 частоты процессора, используется для соединения с подсистемой ввода-вывода (скажем, мостом PCI) и для связи с коммутатором при соединении большого числа узлов, содержащих чипы POWER4 для создания кластеров.
5. SMP-возможности
Четыре чипа POWER4 могут быть упакованы в один модуль, образуя 8-процессорный SMP. Для связи с другими чипами POWER4 на одном модуле логически используются четыре 128-битные шины, работающие на половинной частоте процессора. Физически они реализованы как шесть однонаправленных шин, три в одном, три в другом направлении, их суммарная пропускная способность порядка 35 GB/s.

А вот как 4-х чиповый модуль выглядит в "железе": (такие кусочки кремния можно найти, например, в 32-процессорном сервере pSeries 690 Model 681).

IBM особенно заостряет внимание на том, что для соединения 4-х чипов POWER4 вместо центрального коммутатора используется множество быстрых независимых шин типа "точка-точка". Тот же подход собирается использовать AMD в своих будущих системах на основе процессоров Hammer.
Для создания многомодульных систем может использоваться до 4-х модулей, что дает 16-ти, а с учетом того, что на каждом чипе POWER4 размещено два процессора, 32-процессорную SMP-систему. Для связи с другими модулями используются две однонаправленные 64-битные шины, они соединяются, используя кольцевую топологию:

POWER4 не рассчитан на создание SMP-систем с числом процессоров больше 32.
6. Ядро POWER4
Ядро POWER4 достаточно резко выделяется на фоне предыдущих процессоров семейства POWER, т.к. использует подход, применяемый в современных X86, — применяется трансформация "родных" PowerPC-инструкций во внутренние инструкции и формирование "групп".
Итак, отдельный процессор POWER4 представляет собой суперскалярное ядро со спекулятивным "беспорядочным" исполнением. Всего имеется 8 конвейерных исполняющих устройств — два одинаковых конвейера плавающей точки, каждый из которых способен за такт производить сложение и умножение, т.е. максимум 4 операции с плавающей точкой за такт, два устройства загрузки/записи, два целочисленных исполняющих устройства, устройство исполнения переходов и устройство для выполнения логических операций. Операции деления и вычисления квадратного корня для чисел с плавающей точкой не конвейеризированы и могут очень сильно "просаживать" производительность POWER4. Взглянем на конвейер POWER4:
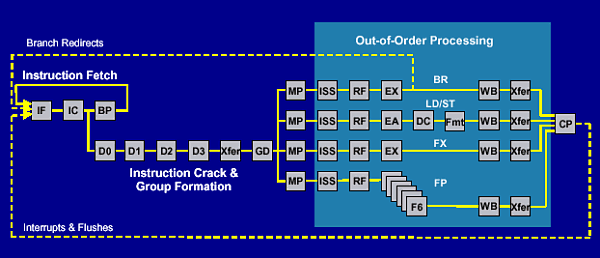
Сразу впечатляет длина целочисленного конвейера — целых 17 стадий! Многовато и необычно для RISC -процессора, что и говорить. Это резко контрастирует с предыдущими чипами IBM c их 5-ти стадийным конвейером. Кратко рассмотрим основные интересные моменты ядра POWER4.
Кэш 1-го уровня способен выдавать на фронтальную часть конвейера до 8 инструкций за такт по адресу, задаваемому регистром IFAR, содержимое которого определяется блоком предсказания ветвлений. Затем происходит декодирование инструкций, их "взлом" (crack) и формирование групп. Для упрощения логики, отвечающей за отслеживание большого числа "беспорядночно" исполняющихся инструкций используется формирование групп. Группа может содержать до 5-ти внутренних инструкций, называемых IOPs. На стадии декодирования старшая инструкция помещается в слот 0 группы, следующая в слот 1 и так далее, слот 4 зарезервирован исключительно для инструкций ветвеления. Для достижения высокой тактовой частоты POWER4 использует технику "взлома" и разбиения многих инструкций PowerPC на большее число более простых инструкций, которые затем объединяются в группы и исполняются. Команды, разбивающиеся на 2 микроинструкции, называются "взломанными" (cracked), на 3 — "милликодированными" (millicoded). В POWER4 широко используется переименование регистров — в частности, 32 GPRs отображаются на 80 внутренних регистров, 32 FPRs — на 72 регистра. Ясно, что многие когда-то привлекательные особенности набора команд PowerPC уже несколько устарели, и в процессор приходится вводить дополнительные блоки для преобразования инструкций к более "удобному" для исполнения виду. Процессору с таким длинным конвейером жизненно необходим эффективный алгоритм предсказания ветвлений. Для динамического предсказания POWER4 использует 2 варианта алгоритма и дополнительную таблицу, в которой отслеживается наиболее эффективный алгоритм для конкретной инструкции ветвления. Разумеется, динамическое предсказание может быть перекрыто специальным битом в инструкции ветвления. Кстати, такая возможность появилась и в линейке X86 вместе с процессором Pentium 4. Для ускорения трансляции виртуальных адресов в физические POWER4 использует 3 разновидности буферов — translation lookaside buffer (TLB) на 1024 записи, segment look-aside buffer (SLB) — полностью ассоциативный кэш на 64 записи, effective-to-real address table (ERAT). Таблица ERAT разделена на две — отдельно для данных и инструкций по 128 элементов.
Подробнее об архитектуре POWER4 и оптимизации программ под нее, в т.ч. и многопоточных, можно прочитать в руководстве IBM [3].
7. Кэши и память
Основная информация по подсистеме памяти приведена в таблице:
| Компонент | Организация | Емкость на чип |
|---|---|---|
| L1 кэш инструкций | С прямым отображением, строка 128 байт разделена на 4 сектора | 128 KB (64 KB на процессор) |
| L1 кэш данных | 2-way, строка 128 байт | 64 KB (32 KB на процессор) |
| L2 | 8-way, строка 128 байт | 1.41 MB |
| L3 | 8-way, 512 байт строка разделена на 4 сектора | 32 MB |
| Память | 0 — 16 GB |
Латентность кэша 1-го уровня составляет 4 такта (для Pentium 4 — 2 такта, Athlon — 4 такта). Кэш 2-го уровня реализует MESI — протокол для поддержки когерентности, его средняя латентность — 12 тактов (для Pentium 4 — 18 тактов, Athlon — 20 тактов). Впрочем, из-за особенностей его архитектуры, в ряде случаев латентность может увеличиваться до 20 тактов. Контроллеры кэша 3-го уровня и памяти, а также каталог тэгов для кэша 3-го уровня интегрированы в чип, сам кэш состоит из 2х16MB чипов памяти eDRAM, расположенных на отдельном модуле, он разделен на 8 банков по 2 MB. Важной особенностью L3-кэша является возможность объединять отдельные кэши чипов POWER4 до 4-х (128 MB), что позволяет использовать для ускорения доступа чередование адресов.
Через две двунаправленные 64-битные шины к кэшу 3-го уровня подключен контроллер памяти. Частота шин составляет 1/3 частоты процессора. Сама память (200 МГц DDR SDRAM) подключена к контроллеру через два порта, каждый из которых состоит из 4-х 32-битных шин, работающих на частоте 400 МГц. Таким образом, пропускная способность памяти при использовании 2-х портов составляет немного больше 11 GB/s (аналогичная величина еще не выпущенного Intel McKinley — 6.4 GB/s). Замечу, что каждый чип имеет свою собственную шину к кэшу 3-го уровня и памяти.
POWER4 имеет аппаратный префетчер, загружающий данные в кэш L1 из всей иерархии памяти, также существуют инструкции, позволяющие программно управлять этим процессом.
8. Happy End
А теперь взглянем на текущую сводку с поля боя:
| CPU | CPU MHz | CINT2000 base/peak | CFP2000 base/peak |
|---|---|---|---|
| AMD Athlon XP 1900+ | 1600 | 677/701 | 588/634 |
| HP PA-8700 | 750 | 568/604 | 526/576 |
| IBM POWER4 (1CPU) | 1300 | 790/814 | 1098/1169 |
| Intel Itanium | 800 | 314/314 | 645 |
| Intel Pentium 4 | 2200 | 771/784 | 766/777 |
| SUN UltraSPARC III-Cu | 900 | 470/533 | 629/731 |
С угасанием архитектуры Alpha у POWER4 не осталось конкурентов в процессорной мощи. Обновленный Pentium 4 выглядит очень солидно, в противовес бледным Itanium и PA-8700, несмотря на все заверения о моральной смерти IA-32 и передовой технологии IA-64. Сможет ли McKinley с его потенциально более мощной IA-64 противостоять POWER4 если не в плане масштабируемости, то хотя бы в вычислительных тестах? Встроят ли SMT в индивидуальные процессоры POWER4? Какими станут CMP-чипы от других компаний?
Список литературы
| 12 марта 2002 г. |
|
|