Часть 2 Примеры внедрения Nvidia CUDA
В ознакомительной статье по CUDA мы приводили слайд Nvidia, на котором указаны цифры преимущества, которые были достигнуты исследователями, применившими CUDA. Надо сказать, что слайд этот со времени его показа журналистам вызывал некоторые подозрения и даже критику. Так, по слайду и рекламным документам Nvidia совершенно непонятно, каким образом измерены эти приросты скорости. Каждый из исследователей использовал в сравнениях разные системы с различными CPU и GPU. Некоторые могли взять лишь одно из ядер двухъядерного CPU, другие тестировали в сравнении с топовым четырехъядерником. Видеокарты и видеочипы использовались везде разные, и в разном количестве.
Не так давно Nvidia запустила обновленную версию веб-сайта CUDA Zone с удобным приложением на флэше, которое показывает большой список приложений и задач с использованием CUDA. Отлично, что там указаны ссылки на соответствующие программы, исходные файлы, презентации, веб-сайты и т.п. Но очень плохо, что Nvidia нигде не указывает тестовые конфигурации и прочие параметры. Ни на своем сайте, где выделены только красивые цифры прироста производительности, ни на уже известном нам слайде:
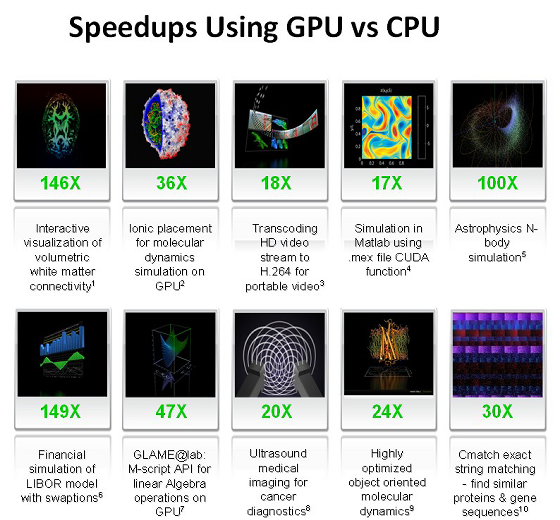
Конечно, номинально у них есть оправдание — видите эти цифры сносок в конце каждого описания? В финале рекламных презентаций есть ссылки на соответствующие документы. Их нужно найти, и прошерстить их в поисках конфигураций и условий тестирования. Что не всегда легко, и что далеко не каждый станет делать.
Итак, чтобы понять, какие преимущества в реальности приносит перенос указанных расчётов на видеочипы при помощи Nvidia CUDA, во второй части статьи мы подробнее рассмотрим и примеры практических применений, и цифры, полученные исследователями на их задачах. С приведением точных конфигураций, насколько это возможно, кратким описанием задачи, а также оценками того, насколько справедливым было сравнение. Разобраться полностью, конечно, просто не представляется возможным. Так как знаний во всех охваченных областях ни у кого не хватит.
Примеры использования Nvidia CUDA
Мини-суперкомпьютер для томографии
Задачей исследовательской группы ASTRA из университета Антверпена является разработка вычислительных методов томографии (восстановление изображения). Томография это техника, используемая в медицинских сканерах, применяемая для создания трёхмерных изображений внутренних органов человека на основе большого количества рентгеновских фотографий, снятых под разными углами. Группа ASTRA разрабатывает новые техники реконструкции, которые дают лучшее качество, по сравнению с классическими.
Такие продвинутые техники требуют очень сложных расчётов, выполнение которых на обычных системах крайне медленное. Восстановление изображения с типичным разрешением трёхмерного снимка в 1024 × 1024 × 1024 элементов займёт несколько дней вычислений на обычном ПК. Но эти вычисления хорошо распараллеливаются, поэтому зачастую используются кластеры на основе сотен ПК. Занимающие много места, дорогие сами по себе и в использовании (электроэнергия, техническое обслуживание и т.п.). Исследователи группы ASTRA решили попробовать перенести часть своих вычислений по восстановлению трёхмерных изображений томографии на графические процессоры. Как оказалось, GPU отлично подходят для подобных вычислений, им хватает и одинарной точности вычислений с плавающей точкой, да и другие ограничения GPU не мешают.
По оценке исследователей из ASTRA, при сравнении в их задаче одного GPU с одним CPU, видеочип оказывается до 40 раз быстрее. Но для полноценного расчёта даже одного GPU мало, время вычислений остаётся слишком большим. Поэтому для самых требовательных задач был сделан настольный суперкомпьютер FASTRA, содержащий четыре двухчиповые видеокарты Nvidia Geforce 9800 GX2. Параллельная работа восьми GPU позволяет FASTRA быть столь же быстрой в данных томографических задачах, что и 350 современных универсальных процессоров! При этом система стоит в десятки, а то и сотни раз меньше! Ещё раз подчеркнём, что речь идет о конкретных задачах томографии.

Конфигурация системы:
- системная плата MSI K9A2 Platinum;
- процессор AMD Phenom X4 9850 (2,5 ГГц, 4 МБ L2+L3);
- память 8 ГБ DDR2 PC6400;
- четыре видеокарты MSI 9800GX2 (восемь G92 по 128 ALU, 1,5 ГГц);
- HDD Samsung Spinpoint F1 750 ГБ;
- блок питания ThermalTake Toughpower 1500 Вт;
- корпус Lian-Li PC-P80 Armorsuit;
- Microsoft Windows XP 64-бит.
Наибольшей сложностью для разработчиков системы стала организация охлаждения четырёх графических карт, которые и по отдельности потребляют много энергии и выделяют много тепла, а тут их целых четыре в почти обычном корпусе. Им даже пришлось оставить открытой боковую стенку. В итоге, в режиме простоя температура чипов составляет около 55 градусов, при полной нагрузке она возрастает до 86 градусов.
По словам участников группы ASTRA, одна система на основе восьми графических процессоров Nvidia обеспечивает более высокую производительность, по сравнению с тремя сотнями процессоров Intel Core 2 Duo, работающими на частоте 2,4 ГГц. Это не говоря уже о сравнении стоимости и потребления энергии.
Для оценки возможностей FASTRA приводится диаграмма, на которой показано время, затрачиваемое на реконструкцию изображения по данным томографа. FASTRA — это система на четырёх Geforce 9800 GX2 (верхнее значение соответствует работе GPU на повышенной частоте, среднее — в штатном режиме), а CalcUA — суперкомпьютер, состоящий из 256 узлов, каждый по два процессора AMD Opteron 250 (2,4 ГГц, 1 МБ L2), купленный университетом весной 2005 года за 3,5 миллиона евро.
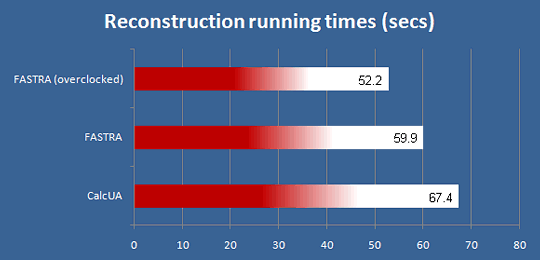
Как вы можете убедиться — результаты потрясающие. Настольная система FASTRA в этой задача обгоняет суперкомпьютер, состоящий из сотен узлов с двумя процессорами каждый. То есть, для узкого круга приложений, подобных рассматриваемому, результаты большого суперкомпьютера могут быть достигнуты за гораздо меньшую цену настольным ПК с несколькими GPU. Конечно, Opteron 250 сейчас далеко не самый лучший CPU. Но даже при сравнении с верхними четырёхъядерными моделями Intel Core 2, результат системы на основе GPU будет просто недостижим в этой задаче.
Пакет молекулярной динамики HOOMD
Highly Optimized Object Oriented Molecular Dynamics (HOOMD) это объектно-ориентированный пакет утилит для молекулярной динамики. Он предназначен для проведения симуляций молекулярной динамики общего назначения, и одним из первых подобных пакетов начал использовать Nvidia CUDA для ускорения расчётов. Объектно-ориентированный дизайн HOOMD делает этот пакет универсальным и расширяемым. В текущей версии пакета представлено большое количество разных силовых полей и интеграторов, а дополнительные могут быть легко добавлены.
Для описания, управления и запуска симуляций используется простой скриптовый язык Python. Скрипты дают полное управление над силовыми полями, интеграторами, всеми параметрами, количеством шагов и т.д. Система скриптов специально сделана максимально простой в использовании для пользователей, не являющихся программистами.
Пока HOOMD симулирует молекулярную динамику на CPU или одиночном GPU производства компании Nvidia, но внедрение мультичипового расчёта планируется в будущих версиях. Пакет работает под следующими операционными системами: Microsoft Windows XP, Linux и Mac OS X. Результат симуляций можно визуализировать при помощи интерфейса VMD.

Разработчик приводит такую таблицу производительности своего пакета и аналога LAMMPS на разных системах и в двух тестовых задачах:
| Software | Machine | OS | GPU | Cores | Polymer TPS | LJ liquid TPS |
| LAMMPS | lightning | Linux x86 64-bit | n/a | 32 CPU | 206.8 | 185.5 |
| HOOMD 0.7.0 | teslahoomd | Linux x86 64-bit | Tesla D870 (G80) | 1 GPU | 157.4 | 175.0 |
| HOOMD 0.7.0 | ISU Office | Linux x86 64-bit | 8800 GTX (G80) | 1 GPU | 155.7 | 171.1 |
| HOOMD 0.7.0 | ISU Office | Windows XP 32-bit | 8800 GTX (G80) | 1 GPU | 155.5 | 171.2 |
| HOOMD 0.7.0 | pion | Linux x86 64-bit | 8800 GTS (G92) | 1 GPU | 143.0 | 149.5 |
| HOOMD 0.7.0 | teslahoomd | Linux x86 64-bit | n/a | 1 CPU | 6.9 | 7.0 |
Конфигурации систем, используемых в тестировании:
- lightning
Atipa cluster, состоящий из 148 узлов, соединённых по InfiniBand, каждый содержит по:
CPU: два двухъядерных AMD Opteron 280 (2.4 ГГц, 2 МБ L2)
RAM: 8 ГБ DDR400 - ISU Office
Dell Precision 470
CPU: один Intel Xeon (Nocona) 3.0 ГГц
RAM: 1 ГБ DDR400
GPU: Nvidia Geforce 8800 GTX (G80, 1.35 ГГц, 128 ALU) - teslahoomd
Sun Ultra 40 M2
CPU: один двухъядерный AMD Opteron 2218 (2.4 ГГц, 2 МБ L2)
RAM: 2 ГБ DDR2-667
GPU: Nvidia Tesla D870 (G80, 1.35 ГГц, 128 ALU) - pion
CPU: один Intel Core 2 Quad 9300 (2.5 ГГц, 6 МБ L2)
RAM: 8 ГБ
GPU: Geforce 8800 GTS 512MB (G92, 1.5 ГГц, 112 ALU)
В тестах использовались и не самые мощные универсальные процессоры, и не последние модели GPU. По сравнению с одним ядром далеко не самого мощного CPU, решение с чипом Nvidia G80 получилось быстрее в 24 раза, что и отражено на слайде Nvidia. Но если использовать мощный четырёхъядерный процессор от Intel и Geforce GTX 280, разница должна сократиться примерно до 8-10 раз. Впрочем, GPU в этой задаче всё равно останется впереди, пусть и не настолько, насколько показано у Nvidia.
Отслеживание объектов в системах видеонаблюдения
Авторы этой работы сделали программу для визуального слежения за положением объектов (в частности, человеческих лиц) в видеопоследовательностях, использующую возможности потоковых процессоров Nvidia. По словам авторов, использование CUDA и эффективные алгоритмы позволили добиться одновременного отслеживания нескольких объектов в видеопотоке высокого разрешения.
Быстрое и точное отслеживание объектов в видеопотоке востребовано многими приложениями из разных сфер: автоматические системы наблюдения, робототехника, системы виртуальной реальности, видеоигры и т.п.

Основным ограничивающим фактором в Brook разработчики системы считают невозможность исполнения их алгоритма в одном ядре (kernel), возможен только многопроходный вариант, когда несколько связанных ядер используют выходные данные от предыдущих. Причина этого в отсутствии поддержки разделяемой памяти и синхронизации разных потоков в Brook. Также авторы отметили негативное влияние графического API в Brook из-за того, что программа исполняется через OpenGL или DirectX. В итоге, разработанное программное обеспечение использует смесь C++ и CUDA.
Сами разработчики получили разницу в производительности между CPU и GPU до 10 раз, протестировав приложение на следующей системе:
- CPU: один двухъядерный Intel Core 2 Duo E6750 (2,66 ГГц, 4 МБ L2);
- RAM: 2 ГБ DDR2;
- GPU: Nvidia Geforce 8800 GTX (G80, 1,35 ГГц, 128 ALU).
Диаграмма производительности приложения, на которой сравнивается скорость программы целиком, в версиях для CPU и GPU. Использовался входной видеопоток разрешением 1024 × 768 точек, 230 точек и 1000 частиц на лицо.
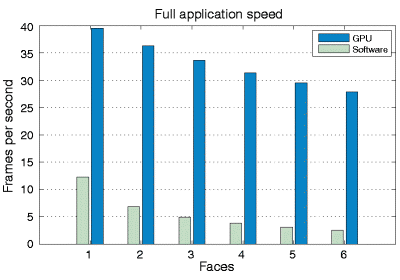
На первый взгляд, показан большой прирост производительности по сравнению с CPU версией алгоритма, особенно при большом количестве одновременно отслеживаемых лиц и частиц. На диаграмме видно, что только использование GPU в расчётах позволяет отслеживать объекты в реальном времени (25-30 кадров в секунду).
Всё было бы хорошо, но в презентации скромно отмечено, что CPU версия приложения использовала один поток (то есть, лишь одно из ядер CPU). Кроме того, что даже ещё важнее, оно не использует SIMD расширений. То есть, если использовать современный четырёхъядерный CPU, да с оптимизированным для SIMD кодом, то разница между CPU и GPU будет заметно меньше, чем получилась на этой диаграмме. Хорошо если 2-3 раза получится. Хотя область применения для GPU интересная, есть и другие аналогичные проекты, один из которых участвовал в конкурсе, проведённом недавно компаниями Nvidia и iXBT.com.
Linzik программа для трассирования лучей при расчете оптических схем
Это — ещё один участник конкурса по CUDA, проведённого Nvidia и iXBT.com. Не просто участник, а победитель.
Linzik программа для трассирования лучей через сферические и асферические оптические поверхности, которая используется для расчета оптических схем. В состав программы входит оптимизатор, подбирающий параметры поверхностей. Программа использует свой внутренний язык Linzik для описания схем и форм анализа систем. Возможности языка позволяют написать собственные оптимизаторы и другие сложные сценарии.
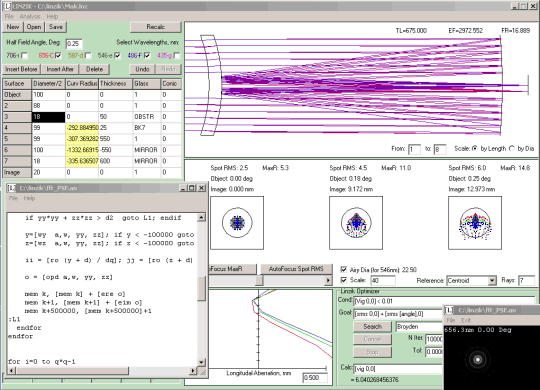
Версию программы 1.1 можно скачать на сайте производителя. Сразу после старта Linzik автоматически загружает относительно сложную оптическую схему телескопа. Для определения производительности CPU и GPU нужно нажать кнопку «Performance test» или выбрать форму -Nvidia_CUDA_TEST в меню Analysis & Tools.
Создатель программы отмечает, что одинарная точность расчетов почти всегда достаточна для целей программы. Впрочем, на сайте написано, что версия Linzik для GPU с расчётами двойной точности (на GT200) уже готова, и точность расчётов на Geforce GTX 260 соответствует точности расчётов на универсальном процессоре. Скорость вычислений на GPU при этом снижается, оставаясь при этом всё равно быстрее, чем на универсальном процессоре.
Автор протестировал свою программу на Nvidia Geforce 8800 GT и Geforce 8600 GT. С видеокартой Nvidia Geforce 8800 GT, использующей чип G92 с 112 потоковыми процессорами, у него получилось ускорение расчётов от 2 до 10 раз, по сравнению с вычислениями центрального процессора Intel Pentium E2180 (два ядра, 2 ГГц, 1 МБ L2). Выигрыш от использования GPU получается выше в случае большего количества оптических поверхностей в схеме.
Проведенные нами испытания показали следующие цифры:
- Intel Core 2 Duo E6600 (2,4 ГГц) 0,69 мс;
- Nvidia Geforce 9800 GTX (G92, 1,69 ГГц, 128 ALU) 0,11 мс.
То есть, разница на тестовой задаче получилась более 6 раз. Впрочем, это только на двухъядерном процессоре, применение топового четырехъядерника и соответствующая оптимизация программы под четыре процессора даст уже значительно меньшую разницу. А с двойной точностью расчётов мощный современный CPU вполне может быть и быстрее…
Ускоренная версия пакета утилит текстурного сжатия Nvidia Texture Tools 2
http://developer.Nvidia.com/object/texture_tools.html
Практически все современные игры используют текстурное сжатие. Причём, текстуры сжимаются на стадии разработки и поставляются уже в сжатом виде для снижения требований к объему носителей. Чаще всего применяется сжатие в DXT--форматах, и при большом количестве и размере текстур эта работа занимает довольно приличное время. Сжатие текстур постоянно используется во время процесса разработки, и ускорение соответствующих утилит облегчает жизнь 3D-разработчиков.
Компания Nvidia выпустила CUDA-ускоренную версию пакета утилит текстурного сжатия, последняя версия которого поддерживает качественное сжатие текстур в распространённые DXT-форматы, поддерживаемые DirectX: DXT1-DXT5 (BC1-BC3), а также сжатие карт нормалей в форматах BC4 и BC5 (ранее известны как ATI1 и ATI2). Также новая версия Texture Tools отличается поддержкой новых текстурных форматов DirectX 10, включает возможности высококачественной фильтрации для мип-уровней и масштабирование изображений.
Следует отметить, что на данный момент не вся функциональность пакета утилит, работающего на CPU, была портирована в эту CUDA-версию, некоторые расширенные возможности в ней недоступны. Поэтому для отдельных специфических целей придётся использовать старые версии пакета или сторонний софт.
По заявлению компании Nvidia, CUDA-ускоренная версия пакета обеспечивает 10-12-кратное превосходство в производительности над предыдущими CPU версиями, при более высоком качестве компрессии (DXT — формат сжатия с потерями). Приводимый ими график показывает сравнительную скорость сжатия текстур размером 1536x1536 пикселей, измеряемую количеством обработанных текстур за секунду. Сравнивались все известные DXT-компрессоры, в качестве центрального процессора использовался Intel Core 2 Duo X6800.
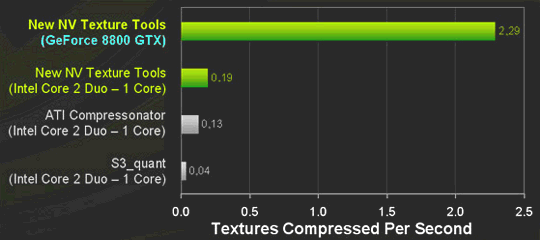
| Утилита | 2048x2048 (DXT1) | 4096x4096 (DXT5) |
| Nvidia Texture Tools 2 (CUDA) | 2.7 | 10.9 |
| Nvidia Texture Tools 2 (CPU) | 16.9 | 67.5 |
| ATI Compressonator (CPU) | 22.5 | 83.7 |
| DirectX Texture Tool (CPU) | 6.8 | 25.2 |
Прежде чем переходить к разбору производительности, нужно упомянуть о качестве сжатия. DXT сжимает с потерями, и эти потери для каждой из утилит разные. DirectX Texture Tool оказалась быстрее всех на CPU, но показывает самые плохие результаты по качеству (для оценки использовалась среднеквадратичная ошибка — RMS). Утилиты Nvidia обеспечивают наивысшее качество, а ATI Compressonator очень близко, но всё же чуть хуже.
Итак, в сравнении Nvidia Texture Tools 2 на CPU и GPU у нас получилась разница не 12.5 кратная, как у Nvidia, а в два раза меньше — лишь 6,2. Также, судя по нашему тестированию, ни одна из CPU утилит не использовала более чем одно ядро центрального процессора. Поэтому при соответствующей оптимизации, разница с топовым четырехъядерником будет ещё меньше, хотя нужно учитывать и не самый быстрый GPU — G92. В целом, снова получается не так радужно, как обрисовывают в Nvidia. Вместо разницы более чем на порядок получается 3-4 раза в лучшем случае. Хотя и это неплохо, конечно, но не феноменальные десятки и сотни раз.
Высокопроизводительный FIR аудио-кроссовер
Аудио-кроссовер — это набор фильтров, разделяющий звуковой спектр на несколько полос, часто используемый в аудиотехнике. Например, чтобы выделить отдельные частоты для нескольких динамиков (сабвуфер, низкочастотник, среднечастотник и высокочастотник) в аудиотракт включают электрические фильтры, которые выделяют одни частотные полосы и подавляют другие. Комбинация нескольких таких фильтров и называется кроссовером.
Быстрый и точный FIR-кроссовер для многих аудиофилов является желанным приобретением. FIR-фильтры отличаются тем, что они имеют конечную импульсную характеристику (КИХ, FIR), обуславливающую отсутствие дополнительных фазовых искажений (эффекта призвука и т.п.).
Автор программы отмечает, что начал разработку GPU-ускоренной версии после того, как купил видеокарту Geforce 8800 GTS и загрузил CUDA SDK, а до этого занимался тем же, но для DSP-производства TI. Первую версию GPU FIR-кроссовера он сделал за неделю, она вышла в марте 2008 года. Сейчас пакет, доступный для скачивания с сайта по данной выше ссылке, включает: генератор параметров FIR, FIR-конвертер, работающий на GPU, исходный программный код, примеры пакетных файлов для обработки.
Как мы уже говорили, четырёхполосный FIR-кроссовер нуждается в большой вычислительной мощности. Автор приводит такую формулу:
44100 sample/sec * 2 (L,R) * 4 (way) * 1024 (taps) = 352.8 Mtap/sec
Производительность используемого им ранее DSP (TI C6713) была недостаточна для достижения его цели, позволяя выделять только две частотные полосы с необходимой точностью. Тогда автор программы сделал оптимизированную версию кроссовера для CPU. И на процессоре AMD Phenom X4 9600 (2,3 ГГц, 2 МБ L2) он достиг высокой производительности 1100 Mtap/sec, используя в работе все четыре ядра. Но этого оказалось недостаточно для расчета с 8192 taps, к которым он стремился:
44100 sample/sec * 2 (L,R) * 4 (way) * 8192(taps) = 2.9 Gtap/sec
Используя неоптимизированный CUDA-код на Nvidia Geforce 8800 GTS, автор добился производительности в 38,78 Gtap/sec. То есть, в 35 раз быстрее, чем на его CPU, и в 140 раз быстрее, чем на одном ядре. В дальнейшем он смог оптимизировать CUDA-код при помощи раскрутки цикла так, что получил на той же системе уже 79 Gtap/sec. То есть, достиг на GPU более чем в 70 раз большую производительность, по сравнению с CPU-версией.
В итоге, даже маломощные видеокарты вроде Geforce 8400 GS достигают производительности до 8-9 Gtap/sec. Это не просто достаточно для данной задачи и в несколько раз быстрее мощного четырёхъядерного CPU, но и позволяет сделать действительно тихий аудиофильский ПК с пассивным охлаждением.
К сожалению, нам не удалось протестировать производительность на своей системе, но использование автором в своих опытах довольно мощного четырёхъядерного CPU с оптимизированным для него многопоточным кодом, в сочетании с не самым быстрым GPU, даёт понять, что в данной задаче практически любой видеочип Nvidia с поддержкой CUDA будет значительно быстрее любого современного универсального процессора. Да, расчёты на GPU несколько менее точные (за счет использования вычислений с плавающей точкой одинарной точности), но автор утверждает, что её вполне достаточно для FIR-кроссовера.
Distributed Password Recovery высокоскоростное восстановление паролей
Программа Distributed Password Recovery компании ElcomSoft предназначена для распределенного нахождения забытых паролей к различным типам документов (см. далее список форматов). Ещё в прошлом году ElcomSoft заявила о возможности использования мощностей GPU при восстановлении паролей путём перебора. Сразу же они пообещали ускорение при подборе паролей по сравнению с CPU в 20 раз и более.
Версия EDPR 2.0 с поддержкой видеокарт Nvidia была выпущена в конце 2007 года. Сейчас уже доступна версия 2.7, которая может использовать до 64 ядер CPU, и до четырёх GPU в одной системе. К сожалению, одновременное использование CPU и GPU пока не поддерживается.

Distributed Password Recovery подбирает забытые пароли к большому количеству различных типов документов и операционным системам семейства Windows при объединении мощностей нескольких компьютеров в локальной или глобальной сети. Подбор для некоторых из форматов (документы Microsoft Office, пароли Windows, MD5 хеши) может ускоряться при использовании GPU производства Nvidia при помощи CUDA. Аппаратное ускорение на Geforce на данный момент работает в операционных системах Windows XP, Windows Server 2003 и Windows Vista (32-бит и 64-бит), требуется лишь установить программу и свежие драйверы Nvidia.
Технология ускорения на GPU разгружает CPU от наиболее ресурсоёмких частей алгоритма, перенося их на CUDA-совместимые графические процессоры. Требования к видеокартам просты, главное, чтобы объём видеопамяти был не менее 256 МБ. Из дополнительных рекомендаций можно отметить то, что желательно иметь в системе как минимум столько же процессорных ядер, сколько и GPU в системе.
При наличии видеокарт значительно отличающейся мощности в одном ПК, EDPR может использовать лишь наиболее мощную из них. Так, если в слотах расширения стоят Geforce 9600 GT и Geforce GTX 280, то будет использоваться только последняя. В случае разных GPU близкой производительности (например, Geforce 8800 GT и 8800 GTX), будут использоваться обе.
Текущая версия программы поддерживает следующие форматы документов:
- Word 2007, Excel 2007, PowerPoint, Project 2007 (CUDA-ускорение);
- Word 97-2003, Excel 97-2003, PowerPoint XP-2003);
- Microsoft Money;
- Microsoft OneNote;
- OpenDocument (ODF): текстовые документы, электронные таблицы, презентации, графика, формулы;
- Секретные ключи PGP (*.skr), PGP Disk (*.pgd), ZIP архивы PGP (*.pgp), PGP whole disk encryption;
- Сертификаты PKCS #12 (*.pfx);
- Adobe Acrobat PDF с длиной ключа 128 бит (owner и user пароли);
- Adobe Acrobat PDF с длиной ключа 40 бит (owner и user пароли);
- пароли пользователей Windows 2000/XP/2003/Vista (LM/NTLM) (CUDA-ускорение);
- загрузочные пароли Windows SYSKEY;
- пароли Windows Domain Cached Credentials;
- Intuit Quicken;
- ID файлы Lotus Notes;
- Хеши MD5 (CUDA-ускорение);
- пароли Oracle;
- пароли Unix.
В дальнейших версиях программы количество поддерживаемых форматов будет увеличиваться. Прежде всего, планируется сделать восстановление паролей беспроводных сетей WPA/WPA2 при помощи ноутбуков и ПК, оснащённых видеочипами Nvidia. Кстати, в следующем году возможно появление поддержки и видеокарт производства компании AMD.
EDPR состоит из трех компонентов: сервер, агент и консоль. Сервер устанавливается на один из компьютеров в сети, он управляет процессом перебора паролей. На остальные компьютеры в сети устанавливается агент, перебирающий порции паролей. По заявлению разработчиков, система с несколькими видеокартами Nvidia способна перебрать до 1 млрд. паролей в секунду (зависит от формата), прирост быстродействия по сравнению с универсальными процессорами достигает десятков раз. Такие цифры получились у разработчиков программы на разных форматах документов (MD5, NTLM, LM, Office 2007):
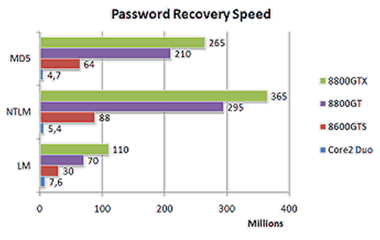
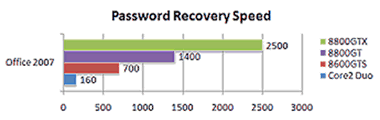
Как видно на диаграммах, производительность очень сильно зависит от метода шифрования. В случае NTLM расчёт на GPU быстрее более чем в 60 раз, для MD5 50 раз, зато для LM превосходство GPU над CPU не достигает и 15 кратного, а для документов MS Office чуть больше этого значения.
Не совсем понятно, какой конкретно универсальный процессор из линейки Core 2 Duo был взят для сравнения производительности, и использовалась ли многопоточность, но цифры порядка 50-60 для определённых видов паролей, в любом случае, впечатляют. Для перебора паролей расчёты на GPU явно подходят очень хорошо, пусть и не для всех методов одинаково.
Ультразвуковой сканер TechniScan UltraSound CT
Небольшая компания TechniScan, производящая ультразвуковые сканеры, разработала новое устройство — UltraSound CT. Оно использует ультразвук для сканирования груди, что комфортнее для пациента по сравнению с маммограммой, и даёт более подробные результаты. Основная отличительная особенность метода в том, что оно позволяет сканировать всю грудь и выдаёт трёхмерные изображения высокого разрешения, позволяющие точнее локализовать и характеризовать области для дальнейшей работы. Также, в отличие от маммографии, UltraSound CT не использует ионизирующее излучение и в целом проще в применении.

Для врачей этот метод не был удобен из-за невысокой скорости получения результатов для анализа и отрисовки качественного изображения нужны большие вычислительные мощности. Так, кластер из 12 узлов, построенный в TechniScan несколько лет назад, был основан на процессорах Pentium M, и получение готового снимка на этой системе занимало почти два часа. В дальнейшем, шестиузловой кластер работал 135 минут, но был дешевле. Использование появившихся позднее универсальных процессоров Intel Pentium 4, Core 2 Duo и Core 2 Quad позволило сократить время ожидания снимка на 16-процессорном кластере на базе Core 2 (непонятно, правда, Duo или Quad) лишь до 45 минут.
Поэтому было решено попробовать использовать вычислительные способности GPU при помощи Nvidia CUDA. Решением этой задачи занялся программист компании Джим Хардвик (Jim Hardwick), который использовал видеокарты Geforce 8800 GTX и Nvidia CUDA SDK. Портированный им на CUDA код показал очень высокую производительность, и в дальнейшем в системах ультразвукового сканирования UltraSound CT были использованы платы Tesla C870, выпущенные компанией Nvidia более года назад и основанные на базе всё того же чипа Nvidia G80.
По данным компании TechniScan, с новым устройством врачи будут ожидать появления снимка всего 15 минут, это достигается значительно большей потоковой производительностью четырёх GPU Nvidia, установленных в систему вместо 16-процессорного кластера на базе Core 2. По данным компании, одна видеокарта Geforce 8800 GTX оказывается более чем в восемь раз быстрее процессора Core 2 Quad Q6700 (2,66 ГГц, 8 МБ L2) при обработке изображения. А четыре графических процессора Tesla, установленных в одну систему, смогли значительно ускорить процесс обработки и получения снимка:
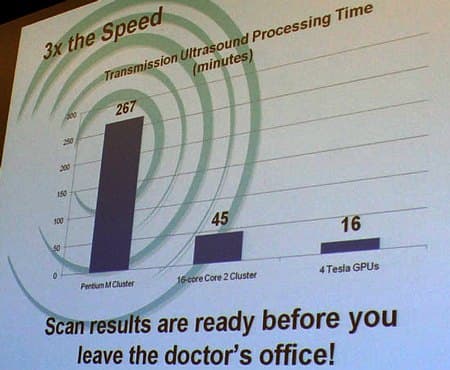
Отмечается и финансовая сторона вопроса. Система на основе GPU выиграет и по стоимости владения, которая составляет в десятки раз меньшие суммы, по сравнению с традиционными кластерами на универсальных CPU. Пока специалисты TechniScan исследуют возможности новых решений из линейке Tesla производства Nvidia, данная модель сканера проходит клинические испытания и в течение двух лет должна появиться на рынке.
Ascalaph Liquid GPU программа для симуляции молекулярной динамики в жидкой фазе
Ascalaph DNA GPU программа создания моделей нуклеиновых кислот и их комплексов с лигандами
Ascalaph Liquid GPU — это аппаратно ускоренная на GPU версия программы Ascalaph Liquid, идентичная CPU-версии во всём, кроме производительности. То же и насчёт Ascalaph DNA GPU — это аналог Ascalaph DNA. Ascalaph Liquid GPU использует аппаратные и программные возможности Nvidia CUDA, ускоряя расчёт невалентных взаимодействий. Расчёт делается специальным образом, все валентные параметры силового поля игнорируются. Вместо этого используется гибкая модель SPC Toukan и Rahman.

Авторы программы провели анализ производительности своих программ, и получили следующие результаты:
Ascalaph Liquid GPU (0.1 ps dynamics of water box)
| Молекулы воды | 512 | 768 | 1536 |
| Атомы | 1536 | 2304 | 4608 |
| Core 2 Quad Q6600 | 27.4 | 40.5 | 156.5 |
| Geforce 8800 GTS 320 MB | 2.67 | 3.97 | 12.3 |
| Ускорение | 12.7 | 12.3 | 17.9 |
Ascalaph DNA GPU (1 ps dynamics of DNA fragments of varied length)
| Атомы | 774 | 1536 | 3214 | 5134 |
| Core 2 Due E4300 | 43.9 | 147.1 | 544.4 | 1327 |
| Geforce 8800 GTS 320 MB | 17.5 | 32.8 | 65.7 | 105.6 |
| Ускорение | 2.5 | 4.5 | 8.3 | 12.6 |
В тестах использовались центральные процессоры:
- Intel Core 2 Quad Q6600 (2,4 ГГц, 8 МБ L2);
- Intel Core 2 Duo E4300 (1,8 ГГц, 2 МБ L2).
Не совсем понятно, использовались ли все ядра универсальных процессоров в опытах, или нет. Если программы многопоточные и нагружают все ядра CPU, тогда результат на GPU для Ascalaph Liquid показан неплохой, ведь старая Geforce 8800 GTS далеко не самая быстрая видеокарта Nvidia, а Core 2 Quad Q6600 не так сильно отстаёт от лучших четырёхъядерников.
У Ascalaph DNA результаты хуже, ведь в опытах использовался слабый и двухъядерный процессор. И тем более результаты ускорения от GPU-версий завышены, если программы используют только по одному ядру CPU. Тогда ускорение от переноса части вычислений на GPU если и обеспечивается, то очень небольшое. В любом случае, мы видим, что даже сходные задачи ускоряются на GPU с разной эффективностью, есть у такого метода свои ограничения.
Nvidia PhysX физические расчёты в играх и DCC приложениях
http://www.Nvidia.ru/object/Nvidia_physx_ru.html
Пожалуй, многие игроки согласятся с тем, что усложнение физических взаимодействий между объектами в играх сильно влияет на геймплей, и по важности вполне может соперничать с качеством 3D-графики. И при помощи переноса части физических расчётов на GPU можно получить прирост, как в скорости, так и в сложности этих физических взаимодействий.
Конечно, часть ресурсов видеочипа при этом будет вынуждена заниматься не задачами 3D-рендеринга, но во многих случаях некоторые блоки и так простаивают. Усложнение физических эффектов нужно потому, что важна не только и не столько статическая картинка, сколько динамика, объекты в движении. Для статической фигуры человека, например, не нужно делать симуляцию динамики одежды и волос, а поверхность воды прекрасно будет выглядеть без симуляции жидкости.
И сегодня производители видеочипов всерьёз взялись за перенос выполнения части физических расчётов на GPU. Сначала они работали над этой задачей совместно с Havok. Но эту компанию в дальнейшем купила Intel, и развитие разработки GPU-физики в неё замедлилось. Тогда Nvidia приобрела другую компанию, занимающуюся физическими расчётами в играх и DCC приложениях, — Ageia. Эта компания выпускала в том числе и аппаратные ускорители физики, но для Nvidia был интересен больше всего сам по себе PhysX SDK, а не аппаратные физические ускорители, роль которых теперь отдана видеокартам.
Nvidia PhysX это распространённый физический движок реального времени, используемый в большом количестве игровых приложений на разнообразных системах ПК и игровых консолях. В список игр с поддержкой PhysX входит не одна сотня игр, которые выпущены или разрабатываются для нескольких платформ: ПК, Sony Playstation 3, Microsoft Xbox 360 и Nintendo Wii. Конечно, далеко не все из них аппаратно ускоряются на GPU, но чем дальше, тем таких проектов будет больше.
PhysX API изначально использовал возможности универсальных CPU и специализированных ускорителей физики Ageia PPU, но после его портирования на CUDA, расчёты ускоряются и на всех видеокартах компании Nvidia, которые поддерживают CUDA, то есть, начиная с Geforce 8 и заканчивая современными решениями Geforce GTX 260 и 280. А это ни много, ни мало — более 90 миллионов видеокарт Geforce 8 и 9 серий, имеющих поддержку PhysX, в том числе и в некоторых из ранее вышедших игровых проектов.
Используя мощные современные видеочипы, PhysX способен предложить в играх дополнительные эффекты: динамические эффекты дыма и пыли, симуляция тканей, симуляция жидкостей и газов, гибких тел и т.п. Конечно, эти эффекты принципиально возможно выполнить и на универсальных процессорах, но скорость будет значительно выше на GPU. Чтобы наглядно увидеть, что даёт перенос физических расчётов на GPU, Nvidia приводит диаграмму, показывающую относительную производительность наиболее распространенных физических алгоритмов PhysX:
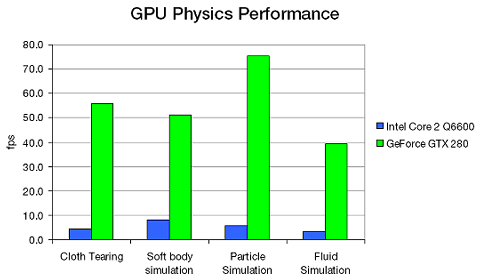
Как видите, для демонстрации преимущества GPU выбраны такие типы задач, как имитация тканей, частиц, жидкостей и гибких тел. В среднем, видеочип Geforce GTX 280 оказывается более чем в 10 раз быстрее, чем четырехъядерный центральный процессор Intel Core 2 Quad Q6600. Процессор хоть и не самый быстрый, но результат очень неплохой, особенно если перенос физики на GPU не снижает общую производительность в случае её упора в скорость 3D.
Мы провели свои тесты PhysX, чтобы проверить заявленные в Nvidia цифры. Приложения были хоть и синтетические, но использовали сравнительно сложную 3D-сцену, в отличие от чисто синтетических тестов, представленных выше. Причём, мы использовали как одну видеокарту Geforce 9800 GTX (G92, 1,69 ГГц, 128 ALU) для физических расчётов, так и связку Geforce 9800 GTX + Geforce 8600 GT, в которой для физики была выделена слабая карта. Что получилось (цифры — число кадров в секунду):
| Приложение | Настройки | C2D Q6600 | GF9800GTX | GF9800GTX GF8600GT |
| FluidMark | 1280x1024 1xMSAA | 21 | 103 | 59 |
| FluidMark | 1920x1200 4xMSAA | 20 | 69 | 58 |
| Fluid Demo | closeup + refraction | 2 | 24 | 15 |
| Fluid Demo | solid particles | 2 | 33 | 15 |
Какие выводы можно сделать из этих результатов? Во-первых, даже слабый Geforce 8600 GT в тестовых задачах справляется с ними в 3-7 раза быстрее четырёхъядерника. В случае с Geforce 9800 GTX разница больше — от 5 до 16 раз. В среднем, получится действительно где-то около 10 раз. Даже с учётом того, что наш CPU работает на сравнительно низкой частоте. Второй вывод — влияние сложности 3D-сцены сказывается на общей производительности, так как видеочипу приходится работать и над рендерингом и над физическими расчётами. В случае использования CPU или отдельного GPU для «физики» такой зависимости нет.
Физические эффекты в играх и DCC приложениях отлично работают на GPU, обеспечивая большой прирост в производительности, который даёт возможность появления новых эффектов в играх. Но своя ложка дёгтя в PhysX на GPU, несомненно, есть — аппаратное ускорение поддерживается только для CUDA-совместимых видеокарт Nvidia. То есть, разработчику, чтобы заставить алгоритм работать на системах с видеокартами других производителей, придётся делать отдельный код с упрощённой физикой для CPU. Поэтому есть вероятность, что некоторые разработчики будут ждать OpenCL или вычислительных шейдеров DirectX 11 и переноса на них задач ускорения физических эффектов. Или продолжать пользоваться чисто CPU физическими движками, вроде Havok.
Выводы
Итак, во второй части статьи мы на нескольких примерах убедились в том, что представленная компанией Nvidia программно-аппаратная архитектура для расчётов на видеочипах CUDA неплохо подходит для решения многих задач, требующих большого количества параллельных расчётов. В плюсах у CUDA то, что она работает на всех современных решениях Nvidia, удобна в применении (по сравнению с другими моделями программирования GPGPU, но не CPU, тут пока есть место для улучшений) и уже довольно долгое время находится в разработке, что минимизирует количество недоработок и ошибок.
Как видно по представленным выше примерам внедрения, CUDA использует и сама Nvidia, и одиночные исследователи в своих любительских проектах, и учебные заведения, и компании, производящие программно-аппаратные средства для множества сфер применения. Ведь CUDA — это технология, доступная любому разработчику ПО, неважно в какой сфере и компании он работает. Если применяемые в работе алгоритмы хорошо распараллеливаются в принципе, и GPU их ничем не ограничивает (точность вычислений, объём разделяемой памяти и т.п.), то нужно привыкнуть к иной парадигме программирования, присущей параллельным вычислениям, и тогда затраты времени на программирование на CUDA вернутся в виде хорошего прироста производительности.
Однако далеко не в любом случае получаются приросты в 100 раз и даже более, как красноречиво заявляет Nvidia в своих маркетинговых материалах. Более того — круг таких задач с огромным приростом не очень и широк. Чаще всего это те задачи, которые так или иначе относятся к обработке изображения (текстурное сжатие, видеонаблюдение, томография и т.п.), и лишь в некоторых случаях приложения из других сфер, которые плохо поддаются оптимизации для SIMD-расширений в универсальных процессорах, например.
Также, судя по рассмотренным примерам, чаще всего достижимы приросты не в десятки и сотни раз, а в несколько раз. Что тоже весьма неплохо, конечно, ведь ни один новый CPU не даёт такого прироста (в этих конкретных задачах). Но у универсальных процессоров по-прежнему есть свои преимущества — программировать для них значительно проще, и не нужно напрягаться, чтобы заставить задачу работать, в отличие от более сложных в этом смысле графических процессоров. Конечно, GPU в последнее время стали ближе к CPU по универсальности, но им до сих пор не хватает многого, чтобы успешно применить свои возможности в ещё более широком круге задач. Однако существуют и те сферы, в которых применение CUDA оправдано уже сейчас, и представленные примеры это отлично подтверждают.
Подробности об остальных применениях можно найти на сайте компании Nvidia в разделе по технологии CUDA. Список уже довольно большой, и в дальнейшем он будет только расти, в дальнейшем будут найдены и другие области применения параллельных расчётов на видеочипах. Надеемся, что дальнейшая универсализация GPU позволит им ещё лучше раскрыть свои способности, а пока можно порадоваться за тех, кто уже сейчас получил преимущество от использования Nvidia CUDA.


