Введение
Устройства для превращения персональных компьютеров в маленькие суперкомпьютеры известны довольно давно. Ещё в 80-х годах прошлого века на рынке предлагались так называемые транспьютеры, которые вставлялись в распространенные тогда слоты расширения ISA. Первое время их производительность в соответствующих задачах впечатляла, но затем рост быстродействия универсальных процессоров ускорился, они усилили свои позиции в параллельных вычислениях, и смысла в транспьютерах не осталось. Хотя подобные устройства существуют и сейчас это разнообразные специализированные ускорители. Но зачастую сфера их применения узка и особого распространения такие ускорители не получили.
Но в последнее время эстафета параллельных вычислений перешла к массовому рынку, так или иначе связанному с трёхмерными играми. Универсальные устройства с многоядерными процессорами для параллельных векторных вычислений, используемых в 3D-графике, достигают высокой пиковой производительности, которая универсальным процессорам не под силу. Конечно, максимальная скорость достигается лишь в ряде удобных задач и имеет некоторые ограничения, но такие устройства уже начали довольно широко применять в сферах, для которых они изначально и не предназначались. Отличным примером такого параллельного процессора является процессор Cell, разработанный альянсом Sony-Toshiba-IBM и применяемый в игровой приставке Sony PlayStation 3, а также и все современные видеокарты от лидеров рынка — компаний Nvidia и AMD.
Cell мы сегодня трогать не будем, хоть он и появился раньше и является универсальным процессором с дополнительными векторными возможностями, речь сегодня не о нём. Для 3D видеоускорителей ещё несколько лет назад появились первые технологии неграфических расчётов общего назначения GPGPU (General-Purpose computation on GPUs). Ведь современные видеочипы содержат сотни математических исполнительных блоков, и эта мощь может использоваться для значительного ускорения множества вычислительно интенсивных приложений. И нынешние поколения GPU обладают достаточно гибкой архитектурой, что вместе с высокоуровневыми языками программирования и программно-аппаратными архитектурами, подобными рассматриваемой в этой статье, раскрывает эти возможности и делает их значительно более доступными.
На создание GPCPU разработчиков побудило появление достаточно быстрых и гибких шейдерных программ, которые способны исполнять современные видеочипы. Разработчики задумали сделать так, чтобы GPU рассчитывали не только изображение в 3D приложениях, но и применялись в других параллельных расчётах. В GPGPU для этого использовались графические API: OpenGL и Direct3D, когда данные к видеочипу передавались в виде текстур, а расчётные программы загружались в виде шейдеров. Недостатками такого метода является сравнительно высокая сложность программирования, низкая скорость обмена данными между CPU и GPU и другие ограничения, о которых мы поговорим далее.
Вычисления на GPU развивались и развиваются очень быстро. И в дальнейшем, два основных производителя видеочипов, Nvidia и AMD, разработали и анонсировали соответствующие платформы под названием CUDA (Compute Unified Device Architecture) и CTM (Close To Metal или AMD Stream Computing), соответственно. В отличие от предыдущих моделей программирования GPU, эти были выполнены с учётом прямого доступа к аппаратным возможностям видеокарт. Платформы не совместимы между собой, CUDA это расширение языка программирования C, а CTM виртуальная машина, исполняющая ассемблерный код. Зато обе платформы ликвидировали некоторые из важных ограничений предыдущих моделей GPGPU, использующих традиционный графический конвейер и соответствующие интерфейсы Direct3D или OpenGL.
Конечно же, открытые стандарты, использующие OpenGL, кажутся наиболее портируемыми и универсальными, они позволяют использовать один и тот же код для видеочипов разных производителей. Но у таких методов есть масса недостатков, они значительно менее гибкие и не такие удобные в использовании. Кроме того, они не дают использовать специфические возможности определённых видеокарт, такие, как быстрая разделяемая (общая) память, присутствующая в современных вычислительных процессорах.
Именно поэтому компания Nvidia выпустила платформу CUDA C-подобный язык программирования со своим компилятором и библиотеками для вычислений на GPU. Конечно же, написание оптимального кода для видеочипов совсем не такое простое и эта задача нуждается в длительной ручной работе, но CUDA как раз и раскрывает все возможности и даёт программисту больший контроль над аппаратными возможностями GPU. Важно, что поддержка Nvidia CUDA есть у чипов G8x, G9x и GT2xx, применяемых в видеокартах Geforce серий 8, 9 и 200, которые очень широко распространены. В настоящее время выпущена финальная версия CUDA 2.0, в которой появились некоторые новые возможности, например, поддержка расчётов с двойной точностью. CUDA доступна на 32-битных и 64-битных операционных системах Linux, Windows и MacOS X.
Разница между CPU и GPU в параллельных расчётах
Рост частот универсальных процессоров упёрся в физические ограничения и высокое энергопотребление, и увеличение их производительности всё чаще происходит за счёт размещения нескольких ядер в одном чипе. Продаваемые сейчас процессоры содержат лишь до четырёх ядер (дальнейший рост не будет быстрым) и они предназначены для обычных приложений, используют MIMD множественный поток команд и данных. Каждое ядро работает отдельно от остальных, исполняя разные инструкции для разных процессов.
Специализированные векторные возможности (SSE2 и SSE3) для четырехкомпонентных (одинарная точность вычислений с плавающей точкой) и двухкомпонентных (двойная точность) векторов появились в универсальных процессорах из-за возросших требований графических приложений, в первую очередь. Именно поэтому для определённых задач применение GPU выгоднее, ведь они изначально сделаны для них.
Например, в видеочипах Nvidia основной блок это мультипроцессор с восемью-десятью ядрами и сотнями ALU в целом, несколькими тысячами регистров и небольшим количеством разделяемой общей памяти. Кроме того, видеокарта содержит быструю глобальную память с доступом к ней всех мультипроцессоров, локальную память в каждом мультипроцессоре, а также специальную память для констант.
Самое главное эти несколько ядер мультипроцессора в GPU являются SIMD (одиночный поток команд, множество потоков данных) ядрами. И эти ядра исполняют одни и те же инструкции одновременно, такой стиль программирования является обычным для графических алгоритмов и многих научных задач, но требует специфического программирования. Зато такой подход позволяет увеличить количество исполнительных блоков за счёт их упрощения.
Итак, перечислим основные различия между архитектурами CPU и GPU. Ядра CPU созданы для исполнения одного потока последовательных инструкций с максимальной производительностью, а GPU проектируются для быстрого исполнения большого числа параллельно выполняемых потоков инструкций. Универсальные процессоры оптимизированы для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа и числа с плавающей точкой. При этом доступ к памяти случайный.
Разработчики CPU стараются добиться выполнения как можно большего числа инструкций параллельно, для увеличения производительности. Для этого, начиная с процессоров Intel Pentium, появилось суперскалярное выполнение, обеспечивающее выполнение двух инструкций за такт, а Pentium Pro отличился внеочередным выполнением инструкций. Но у параллельного выполнения последовательного потока инструкций есть определённые базовые ограничения и увеличением количества исполнительных блоков кратного увеличения скорости не добиться.
У видеочипов работа простая и распараллеленная изначально. Видеочип принимает на входе группу полигонов, проводит все необходимые операции, и на выходе выдаёт пиксели. Обработка полигонов и пикселей независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому, из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU. Кроме того, современные GPU также могут исполнять больше одной инструкции за такт (dual issue). Так, архитектура Tesla в некоторых условиях запускает на исполнение операции MAD+MUL или MAD+SFU одновременно.
GPU отличается от CPU ещё и по принципам доступа к памяти. В GPU он связанный и легко предсказуемый — если из памяти читается тексель текстуры, то через некоторое время придёт время и для соседних текселей. Да и при записи то же — пиксель записывается во фреймбуфер, и через несколько тактов будет записываться расположенный рядом с ним. Поэтому организация памяти отличается от той, что используется в CPU. И видеочипу, в отличие от универсальных процессоров, просто не нужна кэш-память большого размера, а для текстур требуются лишь несколько (до 128-256 в нынешних GPU) килобайт.
Да и сама по себе работа с памятью у GPU и CPU несколько отличается. Так, не все центральные процессоры имеют встроенные контроллеры памяти, а у всех GPU обычно есть по несколько контроллеров, вплоть до восьми 64-битных каналов в чипе Nvidia GT200. Кроме того, на видеокартах применяется более быстрая память, и в результате видеочипам доступна в разы большая пропускная способность памяти, что также весьма важно для параллельных расчётов, оперирующих с огромными потоками данных.
В универсальных процессорах большие количества транзисторов и площадь чипа идут на буферы команд, аппаратное предсказание ветвления и огромные объёмы начиповой кэш-памяти. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд. Видеочипы тратят транзисторы на массивы исполнительных блоков, управляющие потоками блоки, разделяемую память небольшого объёма и контроллеры памяти на несколько каналов. Вышеперечисленное не ускоряет выполнение отдельных потоков, оно позволяет чипу обрабатывать нескольких тысяч потоков, одновременно исполняющихся чипом и требующих высокой пропускной способности памяти.
Про отличия в кэшировании. Универсальные центральные процессоры используют кэш-память для увеличения производительности за счёт снижения задержек доступа к памяти, а GPU используют кэш или общую память для увеличения полосы пропускания. CPU снижают задержки доступа к памяти при помощи кэш-памяти большого размера, а также предсказания ветвлений кода. Эти аппаратные части занимают большую часть площади чипа и потребляют много энергии. Видеочипы обходят проблему задержек доступа к памяти при помощи одновременного исполнения тысяч потоков — в то время, когда один из потоков ожидает данных из памяти, видеочип может выполнять вычисления другого потока без ожидания и задержек.
Есть множество различий и в поддержке многопоточности. CPU исполняет 1-2 потока вычислений на одно процессорное ядро, а видеочипы могут поддерживать до 1024 потоков на каждый мультипроцессор, которых в чипе несколько штук. И если переключение с одного потока на другой для CPU стоит сотни тактов, то GPU переключает несколько потоков за один такт.
Кроме того, центральные процессоры используют SIMD (одна инструкция выполняется над многочисленными данными) блоки для векторных вычислений, а видеочипы применяют SIMT (одна инструкция и несколько потоков) для скалярной обработки потоков. SIMT не требует, чтобы разработчик преобразовывал данные в векторы, и допускает произвольные ветвления в потоках.
Вкратце можно сказать, что в отличие от современных универсальных CPU, видеочипы предназначены для параллельных вычислений с большим количеством арифметических операций. И значительно большее число транзисторов GPU работает по прямому назначению — обработке массивов данных, а не управляет исполнением (flow control) немногочисленных последовательных вычислительных потоков. Это схема того, сколько места в CPU и GPU занимает разнообразная логика:
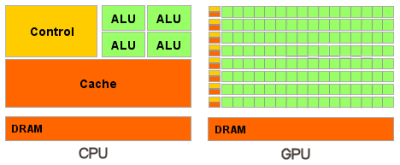
В итоге, основой для эффективного использования мощи GPU в научных и иных неграфических расчётах является распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в видеочипах. К примеру, множество приложений по молекулярному моделированию отлично приспособлено для расчётов на видеочипах, они требуют больших вычислительных мощностей и поэтому удобны для параллельных вычислений. А использование нескольких GPU даёт ещё больше вычислительных мощностей для решения подобных задач.
Выполнение расчётов на GPU показывает отличные результаты в алгоритмах, использующих параллельную обработку данных. То есть, когда одну и ту же последовательность математических операций применяют к большому объёму данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Это предъявляет меньшие требования к управлению исполнением (flow control), а высокая плотность математики и большой объём данных отменяет необходимость в больших кэшах, как на CPU.
В результате всех описанных выше отличий, теоретическая производительность видеочипов значительно превосходит производительность CPU. Компания Nvidia приводит такой график роста производительности CPU и GPU за последние несколько лет:
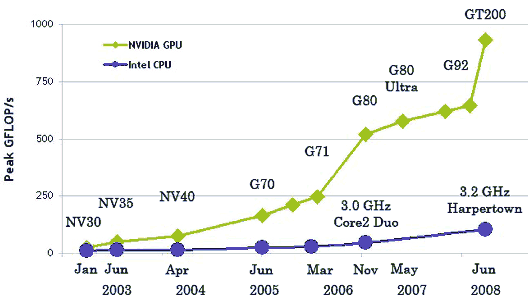
Естественно, эти данные не без доли лукавства. Ведь на CPU гораздо проще на практике достичь теоретических цифр, да и цифры приведены для одинарной точности в случае GPU, и для двойной в случае CPU. В любом случае, для части параллельных задач одинарной точности хватает, а разница в скорости между универсальными и графическими процессорами весьма велика, и поэтому овчинка стоит выделки.
Первые попытки применения расчётов на GPU
Видеочипы в параллельных математических расчётах пытались использовать довольно давно. Самые первые попытки такого применения были крайне примитивными и ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 году на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) — универсальные вычисления на GPU).
Наиболее известен BrookGPU компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл .br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Естественно, у Brook было множество недостатков, на которых мы останавливались, и о которых ещё подробнее поговорим далее. Но даже просто его появление вызвало значительный прилив внимания тех же Nvidia и ATI к инициативе вычислений на GPU, так как развитие этих возможностей серьёзно изменило рынок в дальнейшем, открыв целый новый его сектор — параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook влились в команду разработчиков Nvidia, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы Nvidia стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала Nvidia CUDA (Compute Unified Device Architecture) новая программно-аппаратная архитектура для параллельных вычислений на Nvidia GPU, которой посвящена эта статья.
Области применения параллельных расчётов на GPU
Чтобы понять, какие преимущества приносит перенос расчётов на видеочипы, приведём усреднённые цифры, полученные исследователями по всему миру. В среднем, при переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным Nvidia):
- Флуоресцентная микроскопия: 12x;
- Молекулярная динамика (non-bonded force calc): 8-16x;
- Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
А это табличка, которую очень любит Nvidia, показывая её на всех презентациях, на которой мы подробнее остановимся во второй части статьи, посвящённой конкретным примерам практических применений CUDA вычислений:
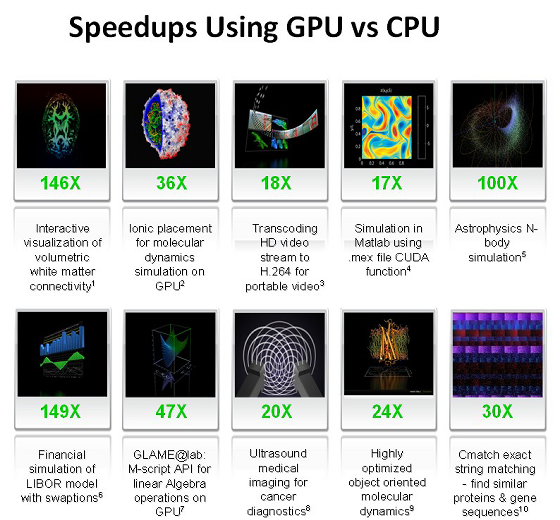
Как видите, цифры весьма привлекательные, особенно впечатляют 100-150-кратные приросты. В следующей статье, посвящённой CUDA, мы подробно разберём некоторые из этих цифр. А сейчас перечислим основные приложения, в которых сейчас применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Подробности о многих применениях можно найти на сайте компании Nvidia в разделе по технологии CUDA. Как видите, список довольно большой, но и это ещё не всё! Его можно продолжать, и наверняка можно предположить, что в будущем будут найдены и другие области применения параллельных расчётов на видеочипах, о которых мы пока не догадываемся.
Возможности Nvidia CUDA
Технология CUDA это программно-аппаратная вычислительная архитектура Nvidia, основанная на расширении языка Си, которая даёт возможность организации доступа к набору инструкций графического ускорителя и управления его памятью при организации параллельных вычислений. CUDA помогает реализовывать алгоритмы, выполнимые на графических процессорах видеоускорителей Geforce восьмого поколения и старше (серии Geforce 8, Geforce 9, Geforce 200), а также Quadro и Tesla.
Хотя трудоёмкость программирования GPU при помощи CUDA довольно велика, она ниже, чем с ранними GPGPU решениями. Такие программы требуют разбиения приложения между несколькими мультипроцессорами подобно MPI программированию, но без разделения данных, которые хранятся в общей видеопамяти. И так как CUDA программирование для каждого мультипроцессора подобно OpenMP программированию, оно требует хорошего понимания организации памяти. Но, конечно же, сложность разработки и переноса на CUDA сильно зависит от приложения.
Набор для разработчиков содержит множество примеров кода и хорошо документирован. Процесс обучения потребует около двух-четырёх недель для тех, кто уже знаком с OpenMP и MPI. В основе API лежит расширенный язык Си, а для трансляции кода с этого языка в состав CUDA SDK входит компилятор командной строки nvcc, созданный на основе открытого компилятора Open64.
Перечислим основные характеристики CUDA:
- унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia;
- большой набор поддерживаемых решений, от мобильных до мультичиповых
- стандартный язык программирования Си;
- стандартные библиотеки численного анализа FFT (быстрое преобразование Фурье) и BLAS (линейная алгебра);
- оптимизированный обмен данными между CPU и GPU;
- взаимодействие с графическими API OpenGL и DirectX;
- поддержка 32- и 64-битных операционных систем: Windows XP, Windows Vista, Linux и MacOS X;
- возможность разработки на низком уровне.
Касательно поддержки операционных систем нужно добавить, что официально поддерживаются все основные дистрибутивы Linux (Red Hat Enterprise Linux 3.x/4.x/5.x, SUSE Linux 10.x), но, судя по данным энтузиастов, CUDA прекрасно работает и на других сборках: Fedora Core, Ubuntu, Gentoo и др.
Среда разработки CUDA (CUDA Toolkit) включает:
- компилятор nvcc;
- библиотеки FFT и BLAS;
- профилировщик;
- отладчик gdb для GPU;
- CUDA runtime драйвер в комплекте стандартных драйверов Nvidia
- руководство по программированию;
- CUDA Developer SDK (исходный код, утилиты и документация).
В примерах исходного кода: параллельная битонная сортировка (bitonic sort), транспонирование матриц, параллельное префиксное суммирование больших массивов, свёртка изображений, дискретное вейвлет-преобразование, пример взаимодействия с OpenGL и Direct3D, использование библиотек CUBLAS и CUFFT, вычисление цены опциона (формула Блэка-Шоулза, биномиальная модель, метод Монте-Карло), параллельный генератор случайных чисел Mersenne Twister, вычисление гистограммы большого массива, шумоподавление, фильтр Собеля (нахождение границ).
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:
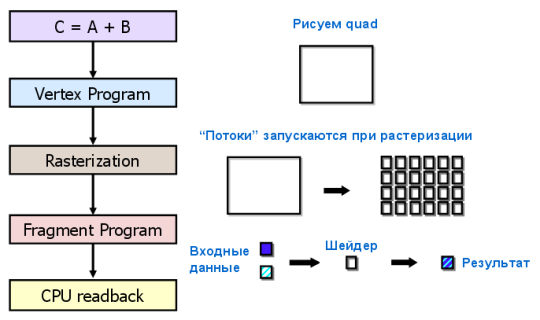
Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании Nvidia отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям:
- интерфейс программирования приложений CUDA основан на стандартном языке программирования Си с расширениями, что упрощает процесс изучения и внедрения архитектуры CUDA;
- CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
- более эффективная передача данных между системной и видеопамятью
- отсутствие необходимости в графических API с избыточностью и накладными расходами;
- линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
- аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
- отсутствие поддержки рекурсии для выполняемых функций;
- минимальная ширина блока в 32 потока;
- закрытая архитектура CUDA, принадлежащая Nvidia.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
Кроме того, CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись — неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
История развития CUDA
Разработка CUDA была анонсирована вместе с чипом G80 в ноябре 2006, а релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. Версия 1.0 вышла в июне 2007 года под запуск в продажу решений Tesla, основанных на чипе G80, и предназначенных для рынка высокопроизводительных вычислений. Затем, в конце года вышла бета-версия CUDA 1.1, которая, несмотря на малозначительное увеличение номера версии, ввела довольно много нового.
Из появившегося в CUDA 1.1 можно отметить включение CUDA-функциональности в обычные видеодрайверы Nvidia. Это означало, что в требованиях к любой CUDA программе достаточно было указать видеокарту серии Geforce 8 и выше, а также минимальную версию драйверов 169.xx. Это очень важно для разработчиков, при соблюдении этих условий CUDA программы будут работать у любого пользователя. Также было добавлено асинхронное выполнение вместе с копированием данных (только для чипов G84, G86, G92 и выше), асинхронная пересылка данных в видеопамять, атомарные операции доступа к памяти, поддержка 64-битных версий Windows и возможность мультичиповой работы CUDA в режиме SLI.
На данный момент актуальной является версия для решений на основе GT200 CUDA 2.0, вышедшая вместе с линейкой Geforce GTX 200. Бета-версия была выпущена ещё весной 2008 года. Во второй версии появились: поддержка вычислений двойной точности (аппаратная поддержка только у GT200), наконец-то поддерживается Windows Vista (32 и 64-битные версии) и Mac OS X, добавлены средства отладки и профилирования, поддерживаются 3D текстуры, оптимизированная пересылка данных.
Что касается вычислений с двойной точностью, то их скорость на текущем аппаратном поколении ниже одинарной точности в несколько раз. Причины рассмотрены в нашей базовой статье по Geforce GTX 280. Реализация в GT200 этой поддержки заключается в том, блоки FP32 не используются для получения результата в четыре раза меньшем темпе, для поддержки FP64 вычислений в Nvidia решили сделать выделенные вычислительные блоки. И в GT200 их в десять раз меньше, чем блоков FP32 (по одному блоку двойной точности на каждый мультипроцессор).
Реально производительность может быть даже ещё меньше, так как архитектура оптимизирована для 32-битного чтения из памяти и регистров, кроме того, двойная точность не нужна в графических приложениях, и в GT200 она сделана скорее, чтобы просто была. Да и современные четырехъядерные процессоры показывают не намного меньшую реальную производительность. Но будучи даже в 10 раз медленнее, чем одинарная точность, такая поддержка полезна для схем со смешанной точностью. Одна из распространенных техник — получить изначально приближенные результаты в одинарной точности, и затем их уточнить в двойной. Теперь это можно сделать прямо на видеокарте, без пересылки промежуточных данных к CPU.
Ещё одна полезная особенность CUDA 2.0 не имеет отношения к GPU, как ни странно. Просто теперь можно компилировать код CUDA в высокоэффективный многопоточный SSE код для быстрого исполнения на центральном процессоре. То есть, теперь эта возможность годится не только для отладки, но и реального использования на системах без видеокарты Nvidia. Ведь использование CUDA в обычном коде сдерживается тем, что видеокарты Nvidia хоть и самые популярные среди выделенных видеорешений, но имеются не во всех системах. И до версии 2.0 в таких случаях пришлось бы делать два разных кода: для CUDA и отдельно для CPU. А теперь можно выполнять любую CUDA программу на CPU с высокой эффективностью, пусть и с меньшей скоростью, чем на видеочипах.
Решения с поддержкой Nvidia CUDA
Все видеокарты, обладающие поддержкой CUDA, могут помочь в ускорении большинства требовательных задач, начиная от аудио- и видеообработки, и заканчивая медициной и научными исследованиями. Единственное реальное ограничение состоит в том, что многие CUDA программы требуют минимум 256 мегабайт видеопамяти, и это одна из важнейших технических характеристик для CUDA-приложений.
Актуальный список поддерживающих CUDA продуктов можно получить на вебсайте Nvidia. На момент написания статьи расчёты CUDA поддерживали все продукты серий Geforce 200, Geforce 9 и Geforce 8, в том числе и мобильные продукты, начиная с Geforce 8400M, а также и чипсеты Geforce 8100, 8200 и 8300. Также поддержкой CUDA обладают современные продукты Quadro и все Tesla: S1070, C1060, C870, D870 и S870.


Особо отметим, что вместе с новыми видеокартами Geforce GTX 260 и 280, были анонсированы и соответствующие решения для высокопроизводительных вычислений: Tesla C1060 и S1070 (представленные на фото выше), которые будут доступны для приобретения осенью этого года. GPU в них применён тот же — GT200, в C1060 он один, в S1070 — четыре. Зато, в отличие от игровых решений, в них используется по четыре гигабайта памяти на каждый чип. Из минусов разве что меньшая частота памяти и ПСП, чем у игровых карт, обеспечивающая по 102 гигабайт/с на чип.
Состав Nvidia CUDA
CUDA включает два API: высокого уровня (CUDA Runtime API) и низкого (CUDA Driver API), хотя в одной программе одновременное использование обоих невозможно, нужно использовать или один или другой. Высокоуровневый работает «сверху» низкоуровневого, все вызовы runtime транслируются в простые инструкции, обрабатываемые низкоуровневым Driver API. Но даже «высокоуровневый» API предполагает знания об устройстве и работе видеочипов Nvidia, слишком высокого уровня абстракции там нет.
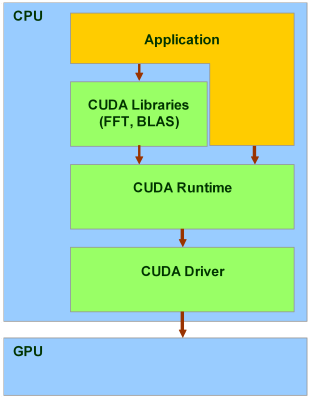
Есть и ещё один уровень, даже более высокий две библиотеки:
CUBLAS CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 это векторно-векторные операции, уровень 2 векторно-матричные операции, уровень 3 матрично-матричные операции.
CUFFT CUDA вариант функции быстрого преобразования Фурье широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства Nvidia без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Основы создания программ на CUDA
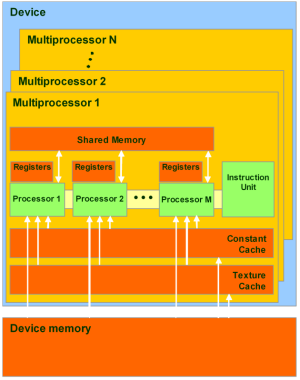
Для понимания дальнейшего текста следует разбираться в базовых архитектурных особенностях видеочипов Nvidia. GPU состоит из нескольких кластеров текстурных блоков (Texture Processing Cluster). Каждый кластер состоит из укрупнённого блока текстурных выборок и двух-трех потоковых мультипроцессоров, каждый из которых состоит из восьми вычислительных устройств и двух суперфункциональных блоков. Все инструкции выполняются по принципу SIMD, когда одна инструкция применяется ко всем потокам в warp (термин из текстильной промышленности, в CUDA это группа из 32 потоков минимальный объём данных, обрабатываемых мультипроцессорами). Этот способ выполнения назвали SIMT (single instruction multiple threads одна инструкция и много потоков).

Каждый из мультипроцессоров имеет определённые ресурсы. Так, есть специальная разделяемая память объемом 16 килобайт на мультипроцессор. Но это не кэш, так как программист может использовать её для любых нужд, подобно Local Store в SPU процессоров Cell. Эта разделяемая память позволяет обмениваться информацией между потоками одного блока. Важно, что все потоки одного блока всегда выполняются одним и тем же мультипроцессором. А потоки из разных блоков обмениваться данными не могут, и нужно помнить это ограничение. Разделяемая память часто бывает полезной, кроме тех случаев, когда несколько потоков обращаются к одному банку памяти. Мультипроцессоры могут обращаться и к видеопамяти, но с большими задержками и худшей пропускной способностью. Для ускорения доступа и снижения частоты обращения к видеопамяти, у мультипроцессоров есть по 8 килобайт кэша на константы и текстурные данные.
Мультипроцессор использует 8192-16384 (для G8x/G9x и GT2xx, соответственно) регистра, общие для всех потоков всех блоков, выполняемых на нём. Максимальное число блоков на один мультипроцессор для G8x/G9x равно восьми, а число warp 24 (768 потоков на один мультипроцессор). Всего топовые видеокарты серий Geforce 8 и 9 могут обрабатывать до 12288 потоков единовременно. Geforce GTX 280 на основе GT200 предлагает до 1024 потоков на мультипроцессор, в нём есть 10 кластеров по три мультипроцессора, обрабатывающих до 30720 потоков. Знание этих ограничений позволяет оптимизировать алгоритмы под доступные ресурсы.
Первым шагом при переносе существующего приложения на CUDA является его профилирование и определение участков кода, являющихся «бутылочным горлышком», тормозящим работу. Если среди таких участков есть подходящие для быстрого параллельного исполнения, эти функции переносятся на Cи расширения CUDA для выполнения на GPU. Программа компилируется при помощи поставляемого Nvidia компилятора, который генерирует код и для CPU, и для GPU. При исполнении программы, центральный процессор выполняет свои порции кода, а GPU выполняет CUDA код с наиболее тяжелыми параллельными вычислениями. Эта часть, предназначенная для GPU, называется ядром (kernel). В ядре определяются операции, которые будут исполнены над данными.
Видеочип получает ядро и создает копии для каждого элемента данных. Эти копии называются потоками (thread). Поток содержит счётчик, регистры и состояние. Для больших объёмов данных, таких как обработка изображений, запускаются миллионы потоков. Потоки выполняются группами по 32 штуки, называемыми warp'ы. Warp'ам назначается исполнение на определенных потоковых мультипроцессорах. Каждый мультипроцессор состоит из восьми ядер потоковых процессоров, которые выполняют одну инструкцию MAD за один такт. Для исполнения одного 32-поточного warp'а требуется четыре такта работы мультипроцессора (речь о частоте shader domain, которая равна 1.5 ГГц и выше).
Мультипроцессор не является традиционным многоядерным процессором, он отлично приспособлен для многопоточности, поддерживая до 32 warp'ов единовременно. Каждый такт аппаратное обеспечение выбирает, какой из warp'ов исполнять, и переключается от одного к другому без потерь в тактах. Если проводить аналогию с центральным процессором, это похоже на одновременное исполнение 32 программ и переключение между ними каждый такт без потерь на переключение контекста. Реально ядра CPU поддерживают единовременное выполнение одной программы и переключаются на другие с задержкой в сотни тактов.
Модель программирования CUDA
Повторимся, что CUDA использует параллельную модель вычислений, когда каждый из SIMD процессоров выполняет ту же инструкцию над разными элементами данных параллельно. GPU является вычислительным устройством, сопроцессором (device) для центрального процессора (host), обладающим собственной памятью и обрабатывающим параллельно большое количество потоков. Ядром (kernel) называется функция для GPU, исполняемая потоками (аналогия из 3D графики — шейдер).
Мы говорили выше, что видеочип отличается от CPU тем, что может обрабатывать одновременно десятки тысяч потоков, что обычно для графики, которая хорошо распараллеливается. Каждый поток скалярен, не требует упаковки данных в 4-компонентные векторы, что удобнее для большинства задач. Количество логических потоков и блоков потоков превосходит количество физических исполнительных устройств, что даёт хорошую масштабируемость для всего модельного ряда решений компании.
Модель программирования в CUDA предполагает группирование потоков. Потоки объединяются в блоки потоков (thread block) одномерные или двумерные сетки потоков, взаимодействующих между собой при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel) исполняется над сеткой (grid) блоков потоков (thread blocks), см. рисунок ниже. Одновременно исполняется одна сетка. Каждый блок может быть одно-, двух- или трехмерным по форме, и может состоять из 512 потоков на текущем аппаратном обеспечении.
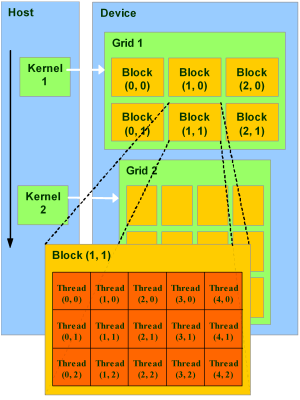
Блоки потоков выполняются в виде небольших групп, называемых варп (warp), размер которых 32 потока. Это минимальный объём данных, которые могут обрабатываться в мультипроцессорах. И так как это не всегда удобно, CUDA позволяет работать и с блоками, содержащими от 64 до 512 потоков.
Группировка блоков в сетки позволяет уйти от ограничений и применить ядро к большему числу потоков за один вызов. Это помогает и при масштабировании. Если у GPU недостаточно ресурсов, он будет выполнять блоки последовательно. В обратном случае, блоки могут выполняться параллельно, что важно для оптимального распределения работы на видеочипах разного уровня, начиная от мобильных и интегрированных.
Модель памяти CUDA
Модель памяти в CUDA отличается возможностью побайтной адресации, поддержкой как gather, так и scatter. Доступно довольно большое количество регистров на каждый потоковый процессор, до 1024 штук. Доступ к ним очень быстрый, хранить в них можно 32-битные целые или числа с плавающей точкой.
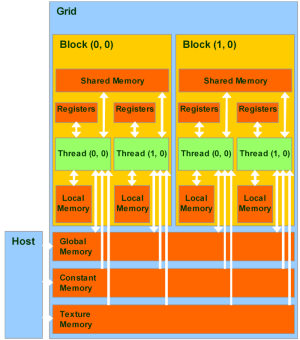
Каждый поток имеет доступ к следующим типам памяти:
Глобальная память самый большой объём памяти, доступный для всех мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5 гигабайт на текущих решениях (и до 4 Гбайт на Tesla). Обладает высокой пропускной способностью, более 100 гигабайт/с для топовых решений Nvidia, но очень большими задержками в несколько сот тактов. Не кэшируется, поддерживает обобщённые инструкции load и store, и обычные указатели на память.
Локальная память это небольшой объём памяти, к которому имеет доступ только один потоковый процессор. Она относительно медленная такая же, как и глобальная.
Разделяемая память это 16-килобайтный (в видеочипах нынешней архитектуры) блок памяти с общим доступом для всех потоковых процессоров в мультипроцессоре. Эта память весьма быстрая, такая же, как регистры. Она обеспечивает взаимодействие потоков, управляется разработчиком напрямую и имеет низкие задержки. Преимущества разделяемой памяти: использование в виде управляемого программистом кэша первого уровня, снижение задержек при доступе исполнительных блоков (ALU) к данным, сокращение количества обращений к глобальной памяти.
Память констант — область памяти объемом 64 килобайта (то же — для нынешних GPU), доступная только для чтения всеми мультипроцессорами. Она кэшируется по 8 килобайт на каждый мультипроцессор. Довольно медленная — задержка в несколько сот тактов при отсутствии нужных данных в кэше.
Текстурная память блок памяти, доступный для чтения всеми мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков видеочипа, поэтому предоставляются возможности линейной интерполяции данных без дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор. Медленная, как глобальная сотни тактов задержки при отсутствии данных в кэше.
Естественно, что глобальная, локальная, текстурная и память констант — это физически одна и та же память, известная как локальная видеопамять видеокарты. Их отличия в различных алгоритмах кэширования и моделях доступа. Центральный процессор может обновлять и запрашивать только внешнюю память: глобальную, константную и текстурную.
Из написанного выше понятно, что CUDA предполагает специальный подход к разработке, не совсем такой, как принят в программах для CPU. Нужно помнить о разных типах памяти, о том, что локальная и глобальная память не кэшируется и задержки при доступе к ней гораздо выше, чем у регистровой памяти, так как она физически находится в отдельных микросхемах.
Типичный, но не обязательный шаблон решения задач:
- задача разбивается на подзадачи;
- входные данные делятся на блоки, которые вмещаются в разделяемую память;
- каждый блок обрабатывается блоком потоков;
- подблок подгружается в разделяемую память из глобальной;
- над данными в разделяемой памяти проводятся соответствующие вычисления;
- результаты копируются из разделяемой памяти обратно в глобальную.
Среда программирования
В состав CUDA входят runtime библиотеки:
- общая часть, предоставляющая встроенные векторные типы и подмножества вызовов RTL, поддерживаемые на CPU и GPU;
- CPU-компонента, для управления одним или несколькими GPU;
- GPU-компонента, предоставляющая специфические функции для GPU.
Основной процесс приложения CUDA работает на универсальном процессоре (host), он запускает несколько копий процессов kernel на видеокарте. Код для CPU делает следующее: инициализирует GPU, распределяет память на видеокарте и системе, копирует константы в память видеокарты, запускает несколько копий процессов kernel на видеокарте, копирует полученный результат из видеопамяти, освобождает память и завершает работу.
В качестве примера для понимания приведем CPU код для сложения векторов, представленный в CUDA:

Функции, исполняемые видеочипом, имеют следующие ограничения: отсутствует рекурсия, нет статических переменных внутри функций и переменного числа аргументов. Поддерживается два вида управления памятью: линейная память с доступом по 32-битным указателям, и CUDA-массивы с доступом только через функции текстурной выборки.
Программы на CUDA могут взаимодействовать с графическими API: для рендеринга данных, сгенерированных в программе, для считывания результатов рендеринга и их обработки средствами CUDA (например, при реализации фильтров постобработки). Для этого ресурсы графических API могут быть отображены (с получением адреса ресурса) в пространство глобальной памяти CUDA. Поддерживаются следующие типы ресурсов графических API: Buffer Objects (PBO / VBO) в OpenGL, вершинные буферы и текстуры (2D, 3D и кубические карты) Direct3D9.
Стадии компиляции CUDA-приложения:
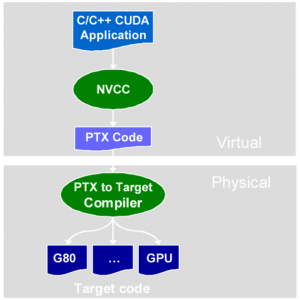
Файлы исходного кода на CUDA C компилируются при помощи программы NVCC, которая является оболочкой над другими инструментами, и вызывает их: cudacc, g++, cl и др. NVCC генерирует: код для центрального процессора, который компилируется вместе с остальными частями приложения, написанными на чистом Си, и объектный код PTX для видеочипа. Исполнимые файлы с кодом на CUDA в обязательном порядке требуют наличия библиотек CUDA runtime library (cudart) и CUDA core library (cuda).
Оптимизация программ на CUDA
Естественно, в рамках обзорной статьи невозможно рассмотреть серьёзные вопросы оптимизации в CUDA программировании. Поэтому просто вкратце расскажем о базовых вещах. Для эффективного использования возможностей CUDA нужно забыть про обычные методы написания программ для CPU, и использовать те алгоритмы, которые хорошо распараллеливаются на тысячи потоков. Также важно найти оптимальное место для хранения данных (регистры, разделяемая память и т.п.), минимизировать передачу данных между CPU и GPU, использовать буферизацию.
В общих чертах, при оптимизации программы CUDA нужно постараться добиться оптимального баланса между размером и количеством блоков. Большее количество потоков в блоке снизит влияние задержек памяти, но снизит и доступное число регистров. Кроме того, блок из 512 потоков неэффективен, сама Nvidia рекомендует использовать блоки по 128 или 256 потоков, как компромиссное значение для достижения оптимальных задержек и количества регистров.
Среди основных моментов оптимизации программ CUDA: как можно более активное использование разделяемой памяти, так как она значительно быстрее глобальной видеопамяти видеокарты; операции чтения и записи из глобальной памяти должны быть объединены (coalesced) по возможности. Для этого нужно использовать специальные типы данных для чтения и записи сразу по 32/64/128 бита данных одной операцией. Если операции чтения трудно объединить, можно попробовать использовать текстурные выборки.
Выводы
Представленная компанией Nvidia программно-аппаратная архитектура для расчётов на видеочипах CUDA хорошо подходит для решения широкого круга задач с высоким параллелизмом. CUDA работает на большом количестве видеочипов Nvidia, и улучшает модель программирования GPU, значительно упрощая её и добавляя большое количество возможностей, таких как разделяемая память, возможность синхронизации потоков, вычисления с двойной точностью и целочисленные операции.
CUDA это доступная каждому разработчику ПО технология, её может использовать любой программист, знающий язык Си. Придётся только привыкнуть к иной парадигме программирования, присущей параллельным вычислениям. Но если алгоритм в принципе хорошо распараллеливается, то изучение и затраты времени на программирование на CUDA вернутся в многократном размере.
Вполне вероятно, что в силу широкого распространения видеокарт в мире, развитие параллельных вычислений на GPU сильно повлияет на индустрию высокопроизводительных вычислений. Эти возможности уже вызвали большой интерес в научных кругах, да и не только в них. Ведь потенциальные возможности ускорения хорошо поддающихся распараллеливанию алгоритмов (на доступном аппаратном обеспечении, что не менее важно) сразу в десятки раз бывают не так часто.
Универсальные процессоры развиваются довольно медленно, у них нет таких скачков производительности. По сути, пусть это и звучит слишком громко, все нуждающиеся в быстрых вычислителях теперь могут получить недорогой персональный суперкомпьютер на своём столе, иногда даже не вкладывая дополнительных средств, так как видеокарты Nvidia широко распространены. Не говоря уже об увеличении эффективности в терминах GFLOPS/$ и GFLOPS/Вт, которые так нравятся производителям GPU.
Будущее множества вычислений явно за параллельными алгоритмами, почти все новые решения и инициативы направлены в эту сторону. Пока что, впрочем, развитие новых парадигм находится на начальном этапе, приходится вручную создавать потоки и планировать доступ к памяти, что усложняет задачи по сравнению с привычным программированием. Но технология CUDA сделала шаг в правильном направлении и в ней явно проглядывается успешное решение, особенно если Nvidia удастся убедить как можно разработчиков в его пользе и перспективах.
Но, конечно, GPU не заменят CPU. В их нынешнем виде они и не предназначены для этого. Сейчас что видеочипы движутся постепенно в сторону CPU, становясь всё более универсальными (расчёты с плавающей точкой одинарной и двойной точности, целочисленные вычисления), так и CPU становятся всё более «параллельными», обзаводясь большим количеством ядер, технологиями многопоточности, не говоря про появление блоков SIMD и проектов гетерогенных процессоров. Скорее всего, GPU и CPU в будущем просто сольются. Известно, что многие компании, в том числе Intel и AMD работают над подобными проектами. И неважно, будут ли GPU поглощены CPU, или наоборот.
В статье мы в основном говорили о преимуществах CUDA. Но есть и ложечка дёгтя. Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии Geforce 8 и 9 и соответствующих Quadro и Tesla. Да, таких решений в мире очень много, Nvidia приводит цифру в 90 миллионов CUDA-совместимых видеочипов. Это просто отлично, но ведь конкуренты предлагают свои решения, отличные от CUDA. Так, у AMD есть Stream Computing, у Intel в будущем будет Ct.
Которая из технологий победит, станет распространённой и проживёт дольше остальных — покажет только время. Но у CUDA есть неплохие шансы, так как по сравнению с Stream Computing, например, она представляет более развитую и удобную для использования среду программирования на обычном языке Си. Возможно, в определении поможет третья сторона, выпустив некое общее решение. К примеру, в следующем обновлении DirectX под версией 11, компанией Microsoft обещаны вычислительные шейдеры, которые и могут стать неким усреднённым решением, устраивающим всех, или почти всех.
Судя по предварительным данным, этот новый тип шейдеров заимствует многое из модели CUDA. И программируя в этой среде уже сейчас, можно получить преимущества сразу и необходимые навыки для будущего. С точки зрения высокопроизводительных вычислений, у DirectX также есть явный недостаток в виде плохой переносимости, так как этот API ограничен платформой Windows. Впрочем, разрабатывается и ещё один стандарт — открытая мультиплатформенная инициатива OpenCL, которая поддерживается большинством компаний, среди которых Nvidia, AMD, Intel, IBM и многие другие.
Не забывайте, что в следующей статье по CUDA вас ждёт исследование конкретных практических применений научных и других неграфических вычислений, выполненных разработчиками из разных уголков нашей планеты при помощи Nvidia CUDA.


