NVIDIA GeForce 7800 GTX 256MB PCI-E
Часть 2: Особенности видеокарты, синтетические тесты

СОДЕРЖАНИЕ
- Части 1 и 2.
- Особенности видеокарты
- Конфигурации стендов, список тестовых инструментов
- Результаты синтетических тестов
NVIDIA GeForce 7800 GTX 256MB PCI-E: Часть 1: Теоретические сведения
В предыдущих частях мы успели рассмотреть теоретические аспекты архитектуры, присущие новому продукту NVIDIA.
В этом разделе мы будем изучать саму карту, представляющую новый GPU, а также посмотрим на то, какую производительность GeForce 7800 GTX демонстрирует в синтетических тестах. В третьей части нас ждет главное, которое интересует всех геймеров — производительность в 3D. Закончим мы небольшим разделом по качеству АА (где исследуем новые режимы).
Итак, кинем взгляд на reference card.
Плата
| NVIDIA GeForce 7800 GTX 256MB PCI-E | |
|---|---|
|
Интерфейс: PCI-Express x16
Частоты (чип/физическая по памяти (эффективная по памяти): 430/600 (1200) MHz (номинал — 430/600 (1200) МГц) Ширина шины обмена с памятью: 256bit Число вершинных конвейеров: 8 Число пиксельных конвейеров: 24 Размеры: 205x100x15mm (последняя величина — максимальная толщина видеокарты). Цвет текстолита: зеленый. Выходные гнезда: 2xDVI, S-Video. VIVO: есть (Philips 7115) TV-out: интегрирован в GPU. |

|
| NVIDIA GeForce 7800 GTX 256MB PCI-E | |
|---|---|
|
Карта имеет 256 МБ памяти GDDR3 SDRAM,
размещенной в 8-ми микросхемах на лицевой и оборотной сторонах PCB.
Микросхемы памяти Samsung (GDDR3). Время выборки у микросхем памяти 1,6 ns, что соответствует частоте работы 625 (1250) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| NVIDIA GeForce 7800 GTX 256MB PCI-E | Reference card NVIDIA GeForce 6800 Ultra PCI |

|

|

|
|

|
|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| NVIDIA GeForce 7800 GTX 256MB PCI-E | Reference card NVIDIA GeForce 6800 Ultra PCI |

|

|
Очевидно, что дизайн карты основан на предыдущем, да и в целом схож с картой на базе NV45 (GeForce 6800 GT/U). Изменения главным образом коснулись силовой части, блок питания значительно переделан, а также мы видим, что PCB расчитана на несение на себе 16-ти микросхем памяти, а следовательно, на данной же плате можно выпускать и 512-мегабайтные версии продукта.
В данном случае установлена только половина микросхем памяти для обеспечения объема в 256 мегабайт. Обратим внимание на то, что микросхемы установлены через одну (а не по принципу: на лицевой стороне PCB есть, на обороте нет, как было бы логичнее всего), поэтому разбросаны по обеим сторонам карты.
Продукт обладает VIVO, где VideoIn основан на Philips 7115. Хочу заметить, что весь предыдущий год мы были очень удивлены тем, что вся серия
карт GeForce 6800 не была снабжена подобными кодерами, хотя посадочные места на PCB имелись. Никто так и не дал объяснения того, почему ни один вендор — партнер
NVIDIA не установил такую микросхему на свои карты. Видимо, какие-то были ошибки при разводке. Теперь же наличие видео входа на плате может только
радовать.

Также стоит упомянуть, что карта снабжена парой гнезд DVI.
Теперь по системе охлаждения. Я не зря выше привел фотографию карты с кулером, но при снятом кожухе. Уже там видно, что при схожем внешнем
подобии на старый эталонный кулер, многое переработано.



Прежде всего видим, что центральный радиатор с помощью тепловой трубки теперь совмещен с радиатором, охлаждающим память. Далее: устройство в целом очень узкое, однослотовое, что не может не радовать (устали уже от этих громоздких ускорителей). Микросхемы памяти с оборотной стороны охлаждаются узкой пластиной. Кулер в целом очень даже нешумный, только на первых секундах после запуска можно слышать небольшой щум от вращащейся на быстрых оборотах турбины. Шум можно оценить на этом ролике (1.5MB, WMV) (обратите внимание, что турбина запускается не сразу после включения компьютера).
Теперь посмотрим на сам процессор.



На третьем снимке я специально сравнил G70 с предшественником. И что мы видим? Несмотря на то, что техпроцесс стал более тонким, все же наличие 300 млн.транзисторов дало о себе знать — площадь кристалла выросла. А ведь казалось совсем недавно мы охали по поводу того — какой огромный чип у NVIDIA получился... А вот тут еще больше :).
Как видно из маркировки, процессор или сделан или упакован в Корее. Что несколько нас смутило. Как известно, у TSMC свои мощности по упаковке кристаллов, и потому по логике вещей должен стоять TAIWAN на кристалле, если он выпущен TSMC. В Корее есть фабрика упаковки, но туда чаще всего направляются кристаллы от IBM. Неужели снова американский «голубой гигант» взялся за выпуск NV47\G70? Вопрос остался открытым.
И последний момент, связанный с рассмотрением самой карты. Это размеры. Обратите внимание на то, что ныне эта плата — самая длинная из всех
современных ускорителей. Вот это очень хорошо видно на снимке:

Сверху — 6800 Ultra — некогда самый большой по размерам ускоритель. Но не так давно появился RADEON X800 AGP, который показан внизу на снимке, и он занял первенство по длине карты. Однако теперь уже на втором месте, поскольку 7800 GTX оказался самым длинным. Это все надо иметь в виду владельцам огромного числа корпусов, куда такая плата просто может не вместиться (я сам когда-то 6800 Ultra еле вмещал в ThermalTake Xazer II, приходилось HDD ставить выше или ниже карты, иначе уже не умешались вместе на одном уровне).
В заключение раздела хочется продемонстрировать еще несколько снимков. :) Ведь, как известно уже, мы протестировали на самом деле две карты,
поставив их в режим SLI:



На фотографиях, кстати, можно оценить и размеры карт, особенно толщину.
Установка и драйверы
Конфигурации тестовых стендов:
- Компьютер на базе Athlon 64 (939Socket)
- процессор AMD Athlon 4000+ (2400MHz) (L2=1024K);
- системная плата ASUS A8N SLI Deluxe на чипсете NVIDIA nForce4 SLI;
- оперативная память 1 GB DDR SDRAM 400MHz (CAS (tCL)=2.5; RAS to CAS delay (tRCD)=3; Row Precharge (tRP)=3; tRAS=6);
- жесткий диск WD Caviar SE WD1600JD 160GB SATA.
- RADEON X850 XT PE (PowerColor RX850XT PE, PCI-E, 256MB GDDR3, 540/1180 MHz);
- GeForce 6800 Ultra (ASUS EN6800 Ultra, PCI-E, 256MB GDDR3, 425/1100 MHz);
- операционная система Windows XP SP2; DirectX 9.0c;
- мониторы
ViewSonic P810 (21") иMitsubishi Diamond Pro 2070sb (21"). - драйверы ATI версии 6.542 (CATALYST 5.6); NVIDIA версии 77.62.
VSync отключен.
Немного о драйверах. Новая версия 77.62 обладает уже поддержкой NV47 (G70). Ниже я объясню, почему вдруг NV47.

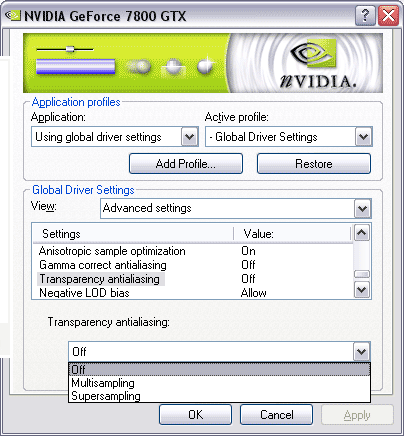
В драйверах (в настройках) именно для серии G70 появилась возможность включать TAA (MSAA, SSAA) и гамма-коррекцию при АА. Более подробно о новых подвидах АА поговорим в третьей части материала.
Надо сказать, что благодаря оперативности автора RivaTuner (А.Николайчук AKA Unwinder) бета-версия 15.6 программы уже поддерживает GeForce 7800:

Как мы видим, программа видит чип не как G70, а как NV47. Дело в том, что внутри регистров чипа сохранено именно это кодовое название — NV47, то есть чип сам о себе извещает, что он не G70, а NV47. Потому и в программе оставлено это наименование.
При помощи драйвера NVStrap мы можем легко уменьшать число активных конвейеров, чем мы и воспользовались, приведя его в состояние 16/6 конвейеров, чтобы сравнить с NV45 (понизив частоты до 425/1100 МГц).
Температурный мониторинг также работает, и должен отметить, что нагрев чипа без дополнительного охлаждения достигает 80 градусов, что сопоставимо
с предшественником в лице 6800 Ultra, то есть вполне нормально.

Но обязательно надо отметить, что карта в целом греется очень сильно, до PCB в задней части после работы платы просто не дотронуться. Очень велик нагрев и радиаторов на памяти. Не исключено, что память работает на увеличенном напряжении, ибо как еще объяснить вдруг появившуюся способность к разгону аж до 1400 МГц, хотя ранее едва удавалось достигать штатной для нее частоты 1250 МГц. Хотя возможно, роль сыграла, обновленная PCB. Кстати по разгону: чип при этом оказался способен работать на частоте 495 МГц (возможно даже на 500 МГц, но за неимением времени я не делал подробных исследований на более высоких частотах работы). И это даже позволяли драйвера при тестировании частот (а они, как известно, перестраховывают ситуацию с оверклокингом).
Таким образом можно констатировать отличный разгонный потенциал нового GPU (несмотря на новый техпроцесс, ведь у ATI например, R430 очень плохо гонится, а сделан по тому же 0.11 мкм техпроцессу). И потому вероятность в будущем выпуска GeForce 7800 Ultra уже маячит на горизонте.
Синтетические тесты
Использованная нами версия пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступна на сайте 3d.rightmark.org
Тесты проводились:
- На GeForce 7800 GTX со стандартными параметрами (7800);
- На GeForce 7800 GTX с параметрами эквивалентными GeForce 6800 Ultra, частоты и число конвейеров были уравнены, чтобы выявить влияние архитектурных изменений (на графиках указана как 7800-16);
- На оригинальной GeForce 6800 Ultra (6800U);
- И на оригинальном RADEON X850XT PE (X850XTPE).
Кроме того, для контроля аномалий мы протестировали синтетические тесты на SLI конфигурации, но не приводим здесь их результаты в виду отсуствия какой либо практической ценности — как известно в режиме SLI КПД очень сильно зависит от конкретного приложения и сделать какие либо прогнозы на основе синтетических тестов невозможно — корреляция данных с результатами игр отсутствует. Итак, приступим:
Тест Pixel Filling
Пиковая производительность выборки текстур (texelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
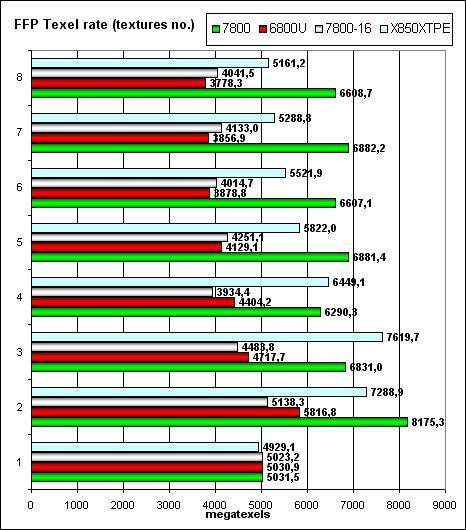
Более высокая тактовая частота ядра и 24 конвейера дают себя знать — теперь NVIDIA лидер даже в традиционно слабых по сравнению с ATI ситуациях. Интересно наблюдать как несколько изменилась зависимость от числа текстур в режиме 7800-16 (одинаковых с 6800U частот и числа конвейеров) — видимо латентность, гранулярность и размер кешей, а также алгоритм работы с ними был несколько изменен, причем баланс сместился в сторону большего числа тесктур — т.е. на более сложных задачах архитектура NV47/G70 предпочтительнее.
А сейчас — скорость закраски буфера кадра (fillrate, pixelrate), режим FFP, для разного числа текстур накладываемых на один пиксель:
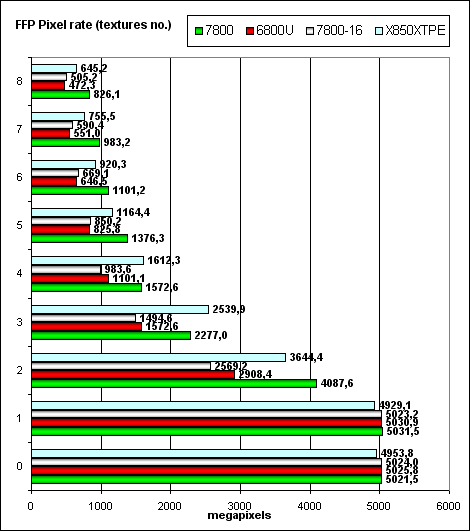
В режиме с 1 текстурой (и с фиксированным цветом) все происходит так быстро, что упирается в блоки записи и блендинга, которых 16 как на NV40/45 так и на G70. от почему на маленьком числе текстур результаты одинаковые. При двух и более текстурах чип получает шанс развернуться во все свои 24 текстурных модуля — что мы и наблюдаем — в наличии скачкообразный отрыв. Даже традиционно более эффективно закрашивающий (без лишних вычислений) буфер кадра X850 перестает быть однозначным лидером и с переменным успехом проигрывает G70 по мере роста числа задействованных текстур (такая тенденция говорит о более крупных кэшах в продукте NVIDIA по сравнению с ATI).
Посмотрим, как скорость закраски зависит от версии шейдеров (1.1):
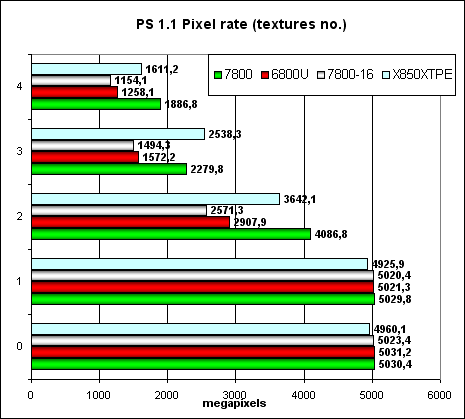
та же картина что и в случае FFP, и версия 2.0:
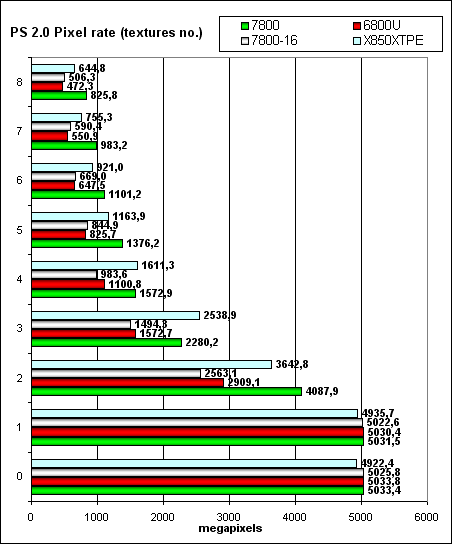
Отметим, что теперь использование разных версий шейдеров практически не влияет на скорость — странности NV3X канули в лету и теперь результаты вполне предсказуемы и линейны — ведь физически все версии шейдеров исполняются одним образом, на одинаковых пиксельных процессорах.
Итак, можно констатировать два факта:
- R4XX потерял пальму первенства и перестал быть чемпионом по закраске, особенно на 2х и более текстурах. Новый лидер G70, причем его параметры очень точно соответствуют небольшому но заметному лидерству.
- Балансировка нового чипа чуть чуть смещена в сторону более сложных задач — видимо за счет несколько иных параметров кэшей и работы с ними. Все верно — время идет и шейдеры в приложения становятся все сложнее и сложнее.
- Какие либо досадные неравномерности поведения на пиксельных шейдерах любой версии отсутствуют как класс.
Тест Geometry Processing Speed
Самый простой шейдер — предельная пропускная способность по треугольникам:
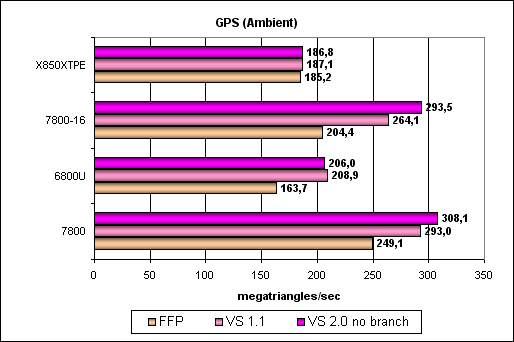
Итак, G70 новый несомненный лидер, его пиковая скорость прекрасно масштабируется вместе с частотой ядра и числом конвейеров. Интересно что на одинаковой частоте геометрически процессоры G70 более эффективны, чем у NV45. Как же так, ведь обещали тоже самое, без изменений? Возможно ответ кроется в промежуточных кешах для геометрии и большей эффективности ее выборки и передачи. Давайте проверим это предположение на более сложных тестах. Более сложный шейдер — один простой точечный источник света:
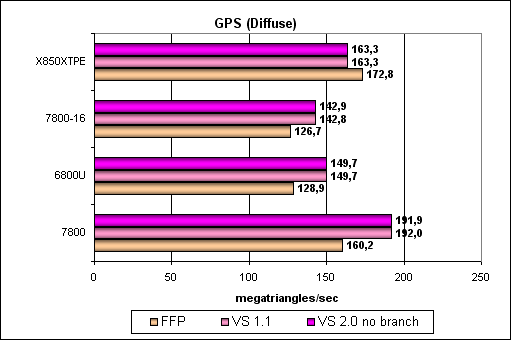
Ага! Все верно, различие между G70 и NV45 на равных частотах и с равным числом конвейеров нивелировалось — дело было действительно в буферах и выборке геометрии. Никаких сюрпризов, G70 лидер, его полная производительность пропорционально больше NV45, с учетом более высокой частоты и 8 вершинных блоков вместо 6.
Усложняем задачу далее:
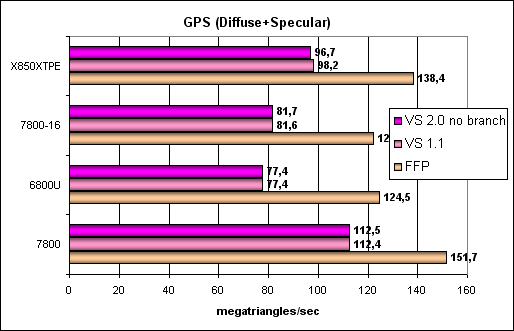
Сходная картина.
А теперь самая сложная задача, три источника света, причем, для сравнения в вариантах без переходов, со статическим и динамическим управлением исполнением:
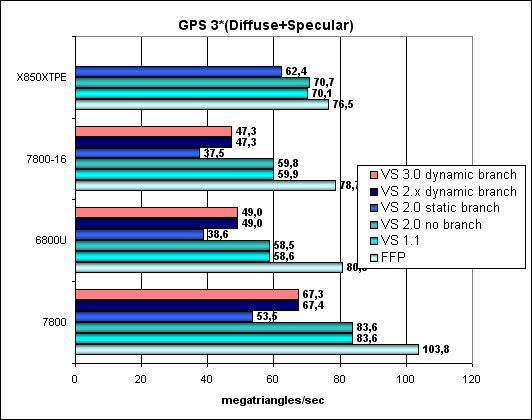
FFP силен, а статические переходы заметно ударяют по чипам NVIDIA. Парадокс в том, что динамические переходы на чипах от NVIDIA выгоднее статических. В случае ATI все достаточно ровно, FFP практически равен шейдерам. Никаких архитектурных новшеств не наблюдается, G70 в этом плане просто ускореный NV45 и все зависимости остались прежними.
По заявлению NVIDIA в новом поколении видеочипов усовершенствован блок растеризатора. Это было необходимо, чтобы растеризатор не стал узким местом в архитектуре видеочипа и успевал обработать все треугольники, трансформированные восемью блоками вершинных шейдеров. Одним из косвенных признаков такой доработки служит изменение размера Post-VS кэша — кэша, расположенного после вершинных шейдеров и до блока растеризатора.
Данный кэш может содержать строго определенное количество вершин уже обработанных вершинными шейдерами. Причем это количество кэшируемых вершин не зависит от количества атрибутов (цветов, текстурных координат), рассчитанных в вершинном шейдере. При обработке растеризатором соседних треугольников, часть вершин которых общие, вершинным шейдерам не приходится еще раз пересчитывать эти вершины.
Посмотрим на скорость растеризации треугольников в зависимости от количества вершин:
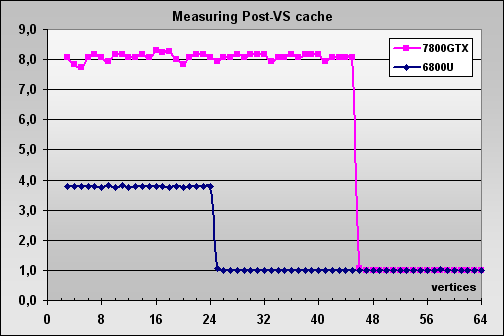
ВНИМАНИЕ: данные на графике были промасштабированы чтобы отразить соотношение скорости растеризации треугольников к скорости трансформации вершин в разных поколениях чипов NVIDIA.
Из графика видно что Post-VS был увеличен с 24 до 45 вершин, а также что инженеры NVIDIA подняли скорость растеризации еще больше чем того требовало увеличение количества вершинных шейдеров с 6 до 8 штук. В случае когда все вершины, необходимые для растеризации, уже находятся в кэше, скорость обработки треугольников увеличивается в 8 раз! Такое решение вновь говорит о сдвиге баланса в сторону более сложных сцен, конкретно сдесь — более сложных геометрических моделей, состоящих из большего числа более мелких треугольников. Т.е. более детализированных моделей.
Также интересным фактом является то, что драйвер при запросе о размере Post-VS кэша для GeForce 7800 возвращает все то же значение в 16 вершин, что и для GeForce 6800, не известно, это недоработка или сознательный шаг для сохранения совместимости.
В качестве исторической справки ниже приведена таблица, отражающая размеры Post-TNL / Post-VS кэша в разных поколениях видеочипов NVIDIA.
| Card | Driver reports | Measured |
| GeForce2 | 12 | 16 |
| GeForce3 / GeForce4 | 16 | 24 |
| GeForce FX / GeForce 6xxx | 16 | 24 |
| GeForce 7xxx | 16 | 45 |
Итак :
- Более эффективная выборка и кеширование обработанной геометрии — больше треугольников в пиковом случае на один конвейер и единицу частоты по сравнению с NV45.
- Никаких архитектурных отличий самих вершинных блоков не выявлено.
Тест Pixel Shaders
Первая группа шейдеров — достаточно простых для исполнения в реальном времени, 1.1, 1.4 и 2.0:
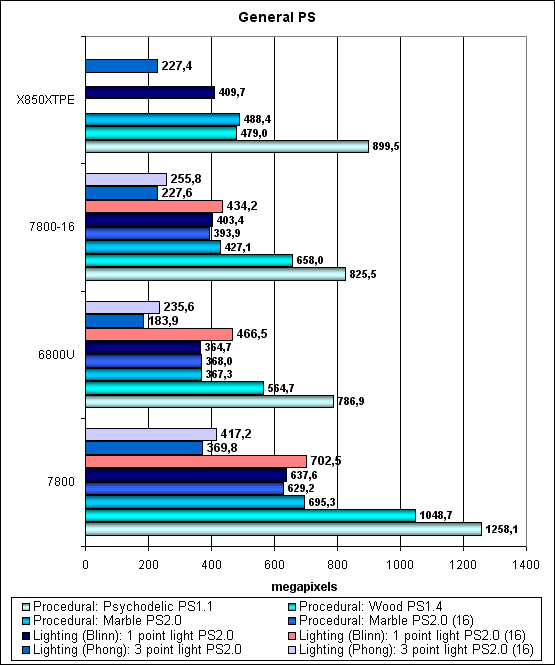
С учетом более высокой тактовой частоты и 24 конвейеров G70 четкий лидер. Однако сравнение с NV45 один к одному дает нам понять, что хотя пиксельные конвейеры и были улучшены, как упоминалось в теоретической части статьи, практическая польза от этих улучшений не очень велика, по крайней мере для наших синтетических тестов. Расточка цилиндров — быстрее, но не радикально, а в некоторых тестах и без разницы вообще. Что-ж, не медленнее, и это главное — большее число конвейеров и разгонный потенциал простят нам отсутствие архитектурных новшеств. А вот маркетинговый отдел NVIDIA как обычно добавил через чур много розового света к этому небольшому тюнингу пиксельных конвейеров — о двукратном увеличении скорости исполнения шейдеров в обычных задачах речь судя по всему не идет ну никак. И о полутора кратном тоже.
Посмотрим, изменится ли что либо для более сложных шейдеров:
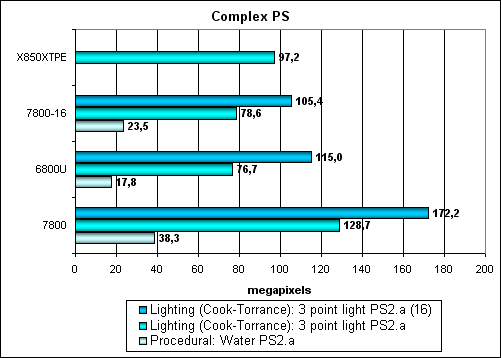
Нет, картина прежняя. Наши тесты показывают лишь небольшое преимущество новых оптимизированных пиксельных конвейеров. Учитывая вполне типовой шейдерный код этих тестов, можно предположить отсутствие сильного выигрыша и в игровых приложениях, впрочем, не будем торопиться до следующей части статьи, где это предложение можно будет проверить или опровергнуть на практике. Итого, по пиксельным шейдерам :
- Производительность в полном варианте вне конкуренции.
- Вредных аномалий нет.
- Никаких особых оптимизаций на практике не выявлено, хотя скорость и стала несколько больше на единицу частоты, даже о 1.5 кратном преимуществе реч не идет. Маркетологи NVIDIA перестарались, расхваливая улучшения пиксельных конвейеров в новом чипе — реально преимущество дает их большее число, более емкие кеши и более высокая частота, а архитекстура осталась практически прежней можно говорить о ~15% повышении эффективности шейдерных вычислений.
Тест HSR
Пиковая эффективность (без текстур и с текстурами) в зависимости от сложности геометрии: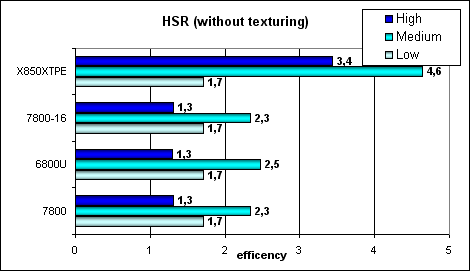
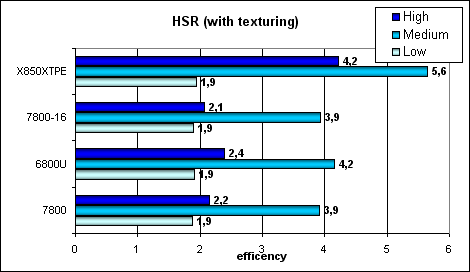
Заметно, что ATI лучше переносит средние и сложные сцены — сказывается наличие двух уровней уменьшенных Z буферов (кроме базового). У NVIDIA традиционно один дополнительный уровень, поэтому эффективность HSR в случае оптимального баланса сцены (средняя сложность) заметно ниже. Видно, что сам алгоритм HSR не поменялся — эффективность G70 и NV45 эквивалентна — разница в пределах погрешности, а значит и соотношение отбрасываемых за такт и закрашиваемых пикселей не изменилось. Зато абсолютные цифры существенно возросли, с учетом 24 конвейеров.
Вывод :
- Алгоритм HSR не претерпел никаких изменений по сравнению с NV45
Тест Point Sprites.
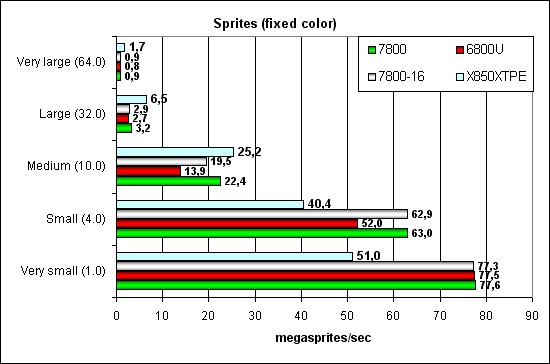
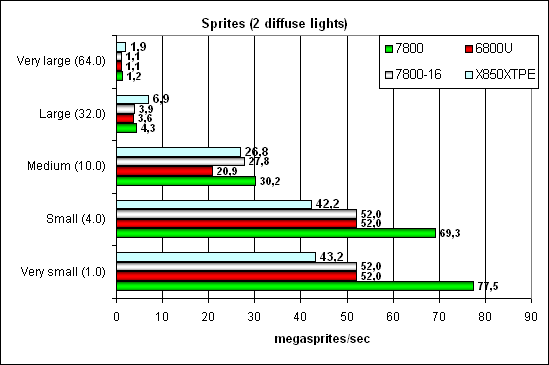
Спрайты давно перестали быть популярным новшеством и зачастую проигрывают треугольникам по скорости вывода. Как бы там нибыло, раньше ATI лучше справлялась с этой задачей, а теперь лидирует G70, в области небольших и средних спрайтов (большие не имеют особого смысла — там лучше использовать полигоны). Но, все это заслуга грубой силы — зависимость не изменилась — алгоритм тот-же. Интересно, что версия с 16 конвейерами все равно заметно быстрее NV45 — видимо есть отдельные блоки отвечающие за какие то аспекты работы со спрайтами, и их не стало меньше, после урезания пиксельных конвейеров до 16 а вершинных до 6.
Тест MSAA
Мы не приводим результаты этого теста, т.к. какие либо архитектурные отличия от NV45 отсутствуют, и даже эффективность осталась прежней — сказываются 16 блоков записи и блединга в обоих чипах. Просто повторим вывод из сравнения R420 и NV40:В пиковом случае MSAA NVIDIA эффективнее. Падение на 4х ниже. Но, надо это признать, сглаживание NVIDIA несколько ниже качеством. Хорошо заметно, что 8х у NV40 является гибридной установкой с использованием SSAA — скорость падает ниже допустимого уровня. Зато MSAA 6х практически не отличается по производительности от 4х (в семействе R4XX )и это можно только приветствовать.
Далее, в третьей части статьи, мы исследуем производительность, качество и скорость нового режима АА связанного с прозрачными полигонами.
Выводы по синтетическим тестам
- Производительность пиксельных ковейеров, даже на одинаковой частоте, и правда порой выше. Но не всегда, и не очень сильно — имеет место лишь небольшой архитектурный тюнинг
- С учетом 24 пиксельных и 8 вершинных процессоров, а также более высокой частоты и хорошего разгонного потенциала эта карта несомненно становится новым лидером в синтетических тестах, потеснив ATI даже в традиционно сильных для нее областях, где NV40 ранее проигрывала канадскому флагману. Иначе говоря — в данный момент на рынке производительность новой карты вне конкуренции.
- Никаких иных архитектурных отличий, кроме небольшой оптимизации пиксельных процессоров не наблюдается, по крайней мере, ЗАМЕТНЫХ в синтетических тестах отличий. Что и ожидалось — этот чип можно считать NV47 на все 100% — немного оптимизированной и усиленной численно версией NV40.
- Пока что частоты ядра и памяти выбраны так, чтобы превзойти ATI, но не на много — видимо, после выхода следующего продукта ATI мы можем ожидать от NVIDIA Ultra версию 7800 с более высокими частотами ядра и памяти, призванную конкурировать уже с R520.
NVIDIA GeForce 7800 GTX 256MB PCI-E: Часть 3: Игровые тесты, новые виды АА, выводы.

| 22 июня 2005 г. |

|
| Дополнительно |
|
|||||||||||||||||||||||||||||||||||||||||||





