Достойна ли архитектура Haswell называться новой и переработанной?
Более пяти лет Intel придерживается стратегии «тик-так», чередуя перевод конкретной архитектуры на более тонкие технологические нормы с выпуском новой архитектуры.
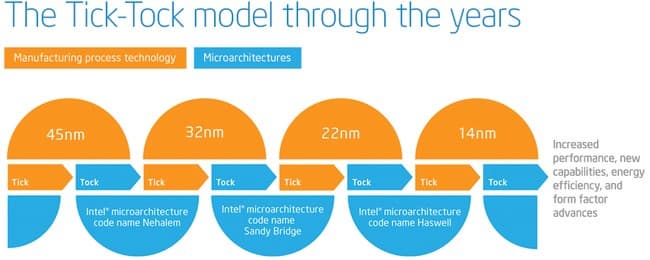
В итоге каждый год мы получаем либо новую архитектуру, либо переход на новый техпроцесс. На 2013 год был запланирован «так», то есть выпуск новой архитектуры — Haswell. Процессоры с новой архитектурой выпускаются по тому же техпроцессу, что и предыдущее поколение Ivy Bridge: 22 нм, Tri-gate. Техпроцесс не поменялся, при этом количество транзисторов увеличилось, а значит, и конечная площадь кристалла нового процессора тоже увеличилась — а вслед за ней и энергопотребление.
Придерживаясь традиций, Intel в день анонса Haswell представила только производительные и дорогие процессоры линеек Core i5 и i7. Анонс двухъядерных процессоров младших линеек как всегда идет с задержкой. Стоит заметить, что цены на новые процессоры остались на том же уровне, что и у Ivy Bridge.
Сравним площади кристаллов разных поколений четырехъядерных процессоров:
| Sandy Bridge | Ivy Bridge | Haswell | |
| Техпроцесс, нм | 32 | 22 | 22 |
| Транзисторы, млрд. шт. | 1,16 | 1,4 (+21%) | 1,6 (+14%) |
| Площадь, мм² | 216 | 160 (−26%) | 177 (+11%) |
| TDP, Вт | 95 | 77 (−19%) | 84 (+9%) |
Как видим, четырехъядерный Haswell имеет площадь всего 177 мм², при этом в него интегрирован северный мост, контроллер оперативной памяти и графическое ядро. Таким образом, количество транзисторов увеличилось на 200 миллионов, а площадь подросла на 17 мм². Если же сравнить Haswell с 32-нанометровыми Sandy Bridge, то количество транзисторов увеличилось на 440 миллионов (38%), а площадь за счет перехода на техпроцесс 22 нм сократилась на 39 мм² (18%). Тепловыделение все эти годы держалось практически на одном уровне (95 Вт у SB и 84 Вт у Haswell), а площадь уменьшалась.
Всё это привело к тому, что с каждого квадратного миллиметра кристалла приходится отводить больше тепла. Если раньше с 216 мм² надо было забирать 95 Вт, то есть 0,44 Вт/мм², то теперь с площади в 177 мм² надо забирать 84 Вт — 0,47 Вт/мм², что на 6,8% больше, чем раньше. Если эта тенденция сохранится, то скоро будет просто физически сложно отводить тепло с таких маленьких площадей.
Рассуждая чисто теоретически, можно предположить, что если в Broadwell, который будет производиться по техпроцессу 14 нм, количество транзисторов возрастет на 21%, как при переходе с 32 на 22 нм, а площадь при этом сократится на 26% (на ту же величину, что и при переходе с 32 на 22 нм), то мы получим 1.9 млрд. транзисторов на площади 131 мм². Если при этом тепловыделение также упадет на 19%, то у нас получится 68 Вт, или 0,52 Вт/мм².
Это теоретические расчеты, на практике будет иначе — переход техпроцесса с 32 на 22 нм также был ознаменован введением 3D-транзисторов, которые снизили токи утечки, а с ними и тепловыделение. Однако про переход с 22 нм на 14 нм пока ничего такого не слышно, так что на практике значения тепловыделения скорее всего будут еще хуже, и на 0,52 Вт/мм² надеяться не стоит. Тем не менее, даже если уровень тепловыделения будет 0,52 Вт/мм², проблема локального перегрева и сложность отвода тепла с маленького кристалла обострятся еще больше.
Кстати, именно сложности с отводом тепла при тепловыделении на уровне 0,52 Вт/мм² могут лежать в основе желания Intel перейти на BGA или попыток упразднить сокет. Если процессор будет распаян на материнской плате, то тепло будет непосредственно передаваться от кристалла к радиатору без промежуточной крышки. Это выглядит еще более актуальным в свете замены припоя на термопасту под крышками современных процессоров. Можно снова ожидать появления «голых» процессоров с открытыми кристаллами по примеру Athlon XP, т. е. без крышки как промежуточного звена в теполоотводе.
На видеокартах давно уже делается именно так, а опасность сколоть кристалл нивелируется железной рамкой вокруг него, поэтому у видеокарт нет таких «актуальных проблем», как термопаста под крышкой процессора. Тем не менее, разгон станет еще более сложным занятием, а правильное охлаждение «более тонких» процессоров — чуть ли не наукой. И всё это нас ожидает совсем скоро, если, конечно, не произойдет чудо…
Но опустимся на землю и вернемся к разговору о Haswell. Как мы знаем, Haswell получил ряд «улучшений/изменений» относительно Sandy Bridge (и, соответственно, Ivy Bridge, являвшегося, по большому счету, переводом SB на более тонкий техпроцесс):
- встроенный регулятор напряжения;
- новые энергосберегающие режимы;
- увеличение объемов буферов и очередей;
- увеличение пропускных способностей кэшей;
- увеличение количества портов запуска;
- добавление новых блоков, функций, API в интегрированном графическом ядре;
- увеличение количества конвейеров в графическом ядре.
Таким образом, обзор новой платформы можно разделить на три части: процессор, встроенный графический ускоритель, чипсет.
Процессорная часть
Изменения в процессоре включают добавление новых инструкций и новых режимов энергосбережения, встраивание регулятора напряжения, а также изменения в самом процессорном ядре.
Наборы инструкций
В архитектуре Haswell появились новые наборы инструкций. Их можно условно разделить на две большие группы: направленные на увеличение векторной производительности и направленные на серверный сегмент. К первым относятся AVX и FMA3, ко вторым — виртуализация и транзакционная память.
Advanced Vector Extensions 2 (AVX2)
Набор AVX был расширен до версии AVX 2.0. Набор AVX2 предоставляет:
- поддержку 256-битных целочисленных векторов (ранее была поддержка только 128-битных);
- поддержку gather-инструкций, которые снимают требование непрерывного расположения данных в памяти; теперь данные «собираются» с разных адресов памяти — интересно будет посмотреть, как это повлияет на производительность;
- добавление инструкций манипуляций/операций над битами.
В целом, новый набор больше ориентирован на целочисленную арифметику, и основной выигрыш от AVX 2.0 будет виден лишь в целочисленных операциях.
Fused Multiply-Add (FMA3)
FMA — это операции совмещенного умножения-сложения, при которых умножаются два числа и складываются с аккумулятором. Данный тип операций достаточно распространен и позволяет более эффективно реализовывать умножение векторов и матриц. Поддержка данного расширения должна значительно увеличить производительность векторных операций. FMA3 уже поддерживается в процессорах AMD с ядром Piledriver, а FMA4 — в Bulldozer.
FMA представляет собой комбинацию операции умножения и сложения: a=b×c+d.
Что касается FMA3, то это трехоперандные инструкции, то есть запись результата производится в один из трех участвующих в инструкции операндов. В итоге мы получаем операцию типа a=b×c+a, a=a×b+c, a=b×a+c.
FMA4 — это четырехоперандные инструкции с записью результата в четвертый операнд. Инструкция приобретает вид: a=b×c+d.
К слову об FMA3: данное нововведение позволит увеличить производительность более чем на 30% при условии адаптации кода под FMA3. Стоит заметить, что когда Haswell еще был далеко на горизонте, Intel планировала внедрять FMA4, а не FMA3, но впоследствии изменила решение в пользу FMA3. Скорее всего, именно из-за этого Bulldozer вышел с поддержкой FMA4: дескать, не успели переделать под Intel (а вот Piledriver вышел уже с FMA3). Причем изначально Bulldozer в 2007 году планировался именно с FMA3, но после обнародования планов Intel внедрить FMA4 в 2008 году AMD свое решение переиграла, выпустив Bulldozer с FMA4. А Intel затем сменила в планах FMA4 на FMA3, поскольку выигрыш от FMA4 по сравнению с FMA3 небольшой, а усложнение электрических логических схем — значительное, что также увеличивает транзисторный бюджет.
Выигрыш от AVX2 и FMA3 проявится после адаптации ПО под эти наборы инструкций, так что роста производительности «здесь и сейчас» ждать не стоит. А поскольку производители ПО достаточно инертны, то с «дополнительной» производительностью придется подождать.
Транзакционная память
Эволюция микропроцессоров привела к увеличению количества потоков — современный десктопный процессор имеет их восемь и более. Большое количество потоков создает все больше сложностей при реализации многопоточного доступа к памяти. Необходим контроль за актуальностью переменных в оперативной памяти: требуется вовремя блокировать данные для записи для одних потоков, разрешать чтение или изменение данных для других потоков. Это сложная задача, и для поддержки актуальности данных в многопоточных программах была разработана транзакционная память. Но до сегодняшнего дня она реализовывалась программно, что снижало производительность.
В Haswell появилось новое расширение Transactional Synchronization Extensions (TSX) — транзакционная память, которая предназначена для эффективной реализации многопоточных программ и повышения их надежности. Данное расширение позволяет реализовать «в железе» транзакционную память, тем самым повысив общую производительность.
Что такое транзакционная память? Это такая память, которая имеет внутри себя механизм управления параллельными процессами для обеспечения доступа к совместно используемым данным. Расширение TSX состоит из двух компонентов: Hardware Lock Elision (HLE) и Restricted Transaction Memory (RTM).
Компонент RTM представляет собой набор инструкций, с помощью которого программист может начать, закончить и прервать транзакцию. Компонент HLE вводит префиксы, которые игнорируются процессорами без поддержки TSX. Префиксы обеспечивают блокировку переменных, позволяя другим процессам использовать (считывать) заблокированные переменные и исполнять свой код до тех пор, пока не произойдет конфликт записи заблокированных данных.
На данный момент уже появились приложения с использованием данного расширения.
Виртуализация
Важность виртуализации постоянно растет: все чаще множество виртуальных серверов расположены на одном физическом, да и облачные сервисы распространяются все шире. Поэтому увеличение скорости работы технологий виртуализации и виртуализированных сред является очень актуальной задачей в серверном сегменте. В Haswell содержатся некоторые улучшения, направленные именно на увеличение производительности виртуализированных сред. Перечислим их:
- улучшения, позволяющие сократить время перехода из гостевых систем в host-систему;
- добавились биты доступа в Extended Page Table (EPT);
- уменьшилось время доступа к TLB;
- новые инструкции вызова гипервизора без выполнения команды vmexit;
В итоге время перехода между виртуализированными средами сократилось и составляет менее 500 тактов процессора. Это должно приводить к сокращению общих потерь производительности, связанных с виртуализацией. А новые Xeon E3-12xx-v3 предположительно будут быстрее в этом классе задач, чем Xeon E3-12xx-v2.
Встроенный регулятор напряжения
В Haswell регулятор напряжения переехал с материнской платы под крышку процессора. Ранее (Sandy Bridge) к процессору требовалось подводить различные напряжения для графического ядра, для системного агента, для процессорных ядер и др. Теперь к процессору через сокет подводится только одно напряжение Vccin 1,75 В, которое поступает на встроенный регулятор напряжения. Регулятор напряжения представляет собой 20 ячеек, каждая ячейка создает 16 фаз с общей силой тока в 25 А. В сумме мы получаем 320 фаз, что значительно больше, чем даже у самых навороченных материнских плат. Такой подход позволяет не только упростить разводку материнских плат (а значит, и снизить их стоимость), но и более точно регулировать напряжения внутри процессора, что, в свою очередь, ведет к большей экономии электроэнергии.
Это одна из основных причин, по которым Haswell физически не может быть совместимым со старым сокетом LGA1155. Да, можно говорить о желании Intel зарабатывать деньги, каждый год выпуская новую платформу (новый чипсет) и каждые два года — новый сокет, но в данном случае для смены сокета есть объективные причины: физическая/электрическая несовместимость.
Однако за все приходится платить. Регулятор напряжения — еще один заметный источник тепла в новом процессоре. А учитывая, что Haswell производится по нормам того же техпроцесса, что и его предшественник Ivy Bridge, стоит ожидать, что процессор будет горячее.
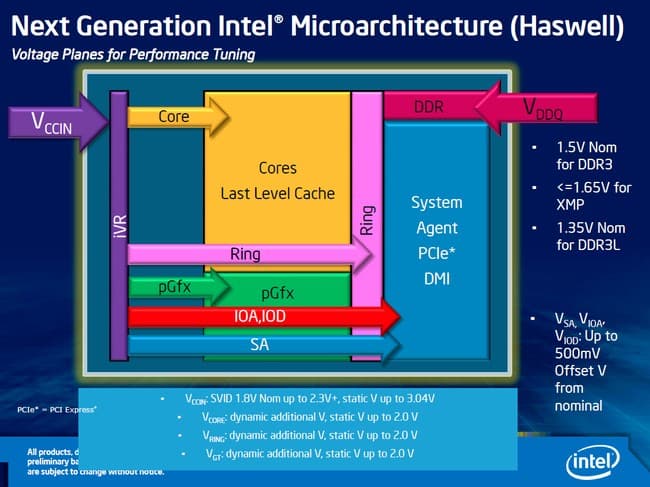
Вообще, это улучшение больше пользы принесет в мобильном сегменте: более быстрое и точное изменение напряжения позволит снизить энергопотребление, а также более эффективно управлять частотой процессорных ядер. И судя по всему, это не пустое маркетинговое заявление, потому как Intel собирается анонсировать мобильные процессоры со сверхнизким потреблением энергии.
Новые энергосберегающие режимы
В Haswell появились новые состояния сна S0ix, которые похожи на состояния S3/S4, но только с гораздо меньшим временем перехода процессора в рабочее состояние. Также было добавлено новое состояние простоя С7.
Режим С7 сопровождается выключением основной части процессора, при этом изображение на экране остается активным.
Минимальная частота процессоров в простое составляет 800 МГц, это также должно снизить энергопотребление.
Архитектура процессора
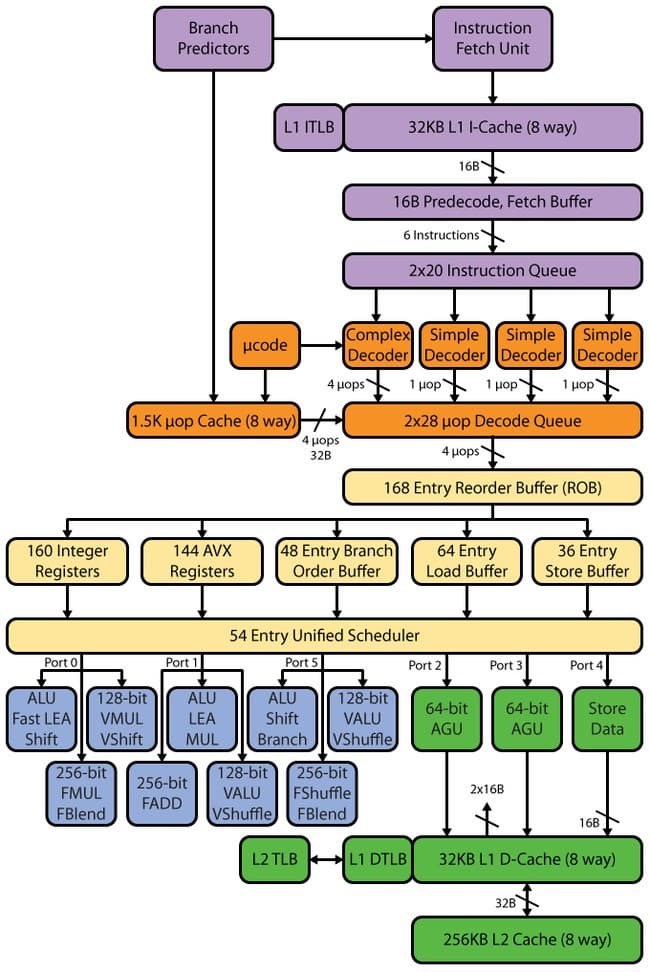
Sandy Bridge:
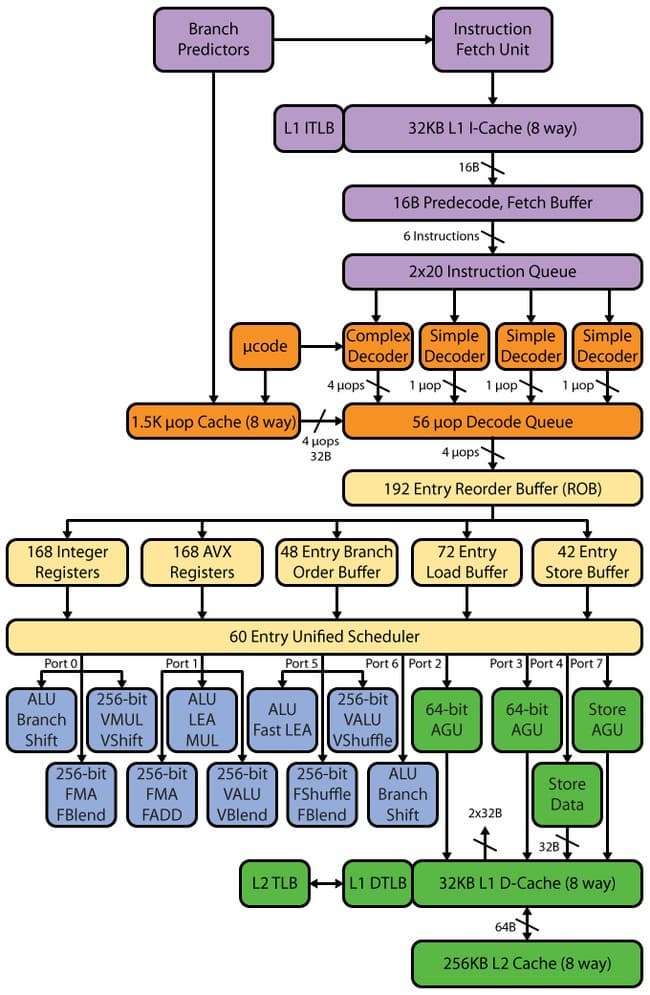
Haswell:
Фронт-энд
Sandy Bridge:
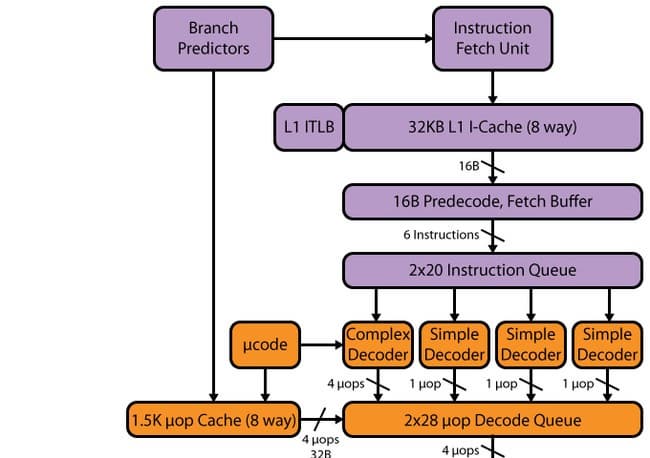
Haswell:
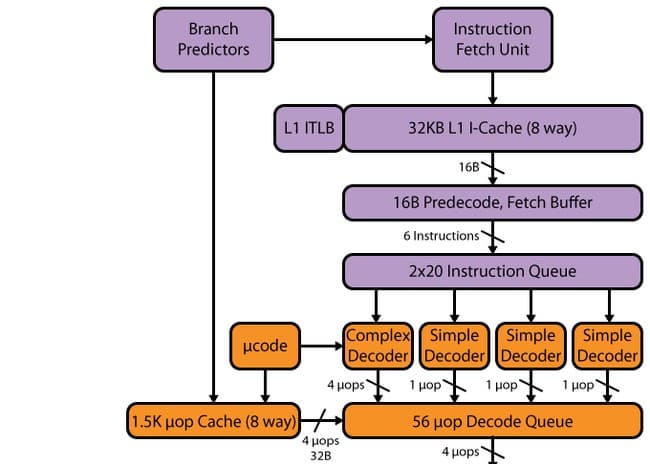
Конвейер Haswell, как и в SB, имеет 14–19 стадий: 14 стадий при попадании в µop-кэш, 19 — при промахе. Объем µop-кэша не изменился по сравнению с SB — 1536 µop. Организация кэша мопов осталась такой же, как и в SB — 32 набора по восемь строк, в каждой из которых по шесть мопов. Хотя в связи с увеличением количества исполнительных устройств, а также последующих после кэша мопов буферов можно было бы ожидать увеличения кэша мопов — до 1776 мопов (почему именно такой объем — будет сказано ниже).
Декодер
Декодер, можно сказать, не изменился — остался четырехпутным, как у SB. Он состоит из четырех параллельных каналов: одного сложного транслятора (complex decoder) и трех простых (simple decoder). Сложный транслятор может обрабатывать/декодировать сложные инструкции, порождающие более одного мопа. В трех остальных каналах декодируются простые инструкции. К слову, благодаря наличию слияния макроопераций, инструкции загрузки с исполнением и выгрузки порождают, например, один моп и могут быть декодированы в «простых» каналах декодера. Инструкции SSE тоже порождают один моп, поэтому могут быть декодированы в любом из трех простых каналов. Учитывая появление 256-битных AVX, FMA3, а также увеличенное количество портов запуска и функциональных устройств, такой скорости декодера может попросту не хватить — и он может стать узким местом. Частично данное узкое место «расшивает» кэш мопов L0m, но все равно, имея процессор с 8 портами запуска, Intel следует задуматься о расширении декодера — в частности, не помешало бы увеличить количество сложных каналов.
Планировщик, буфер переупорядочивания, исполнительные устройства
Sandy Bridge:
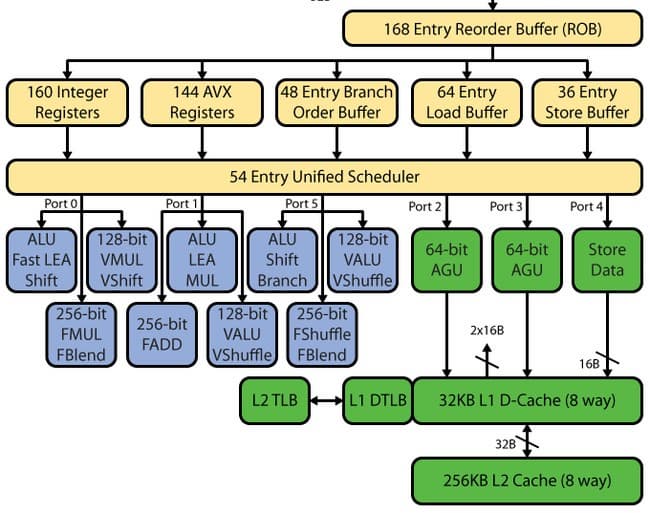
Haswell:
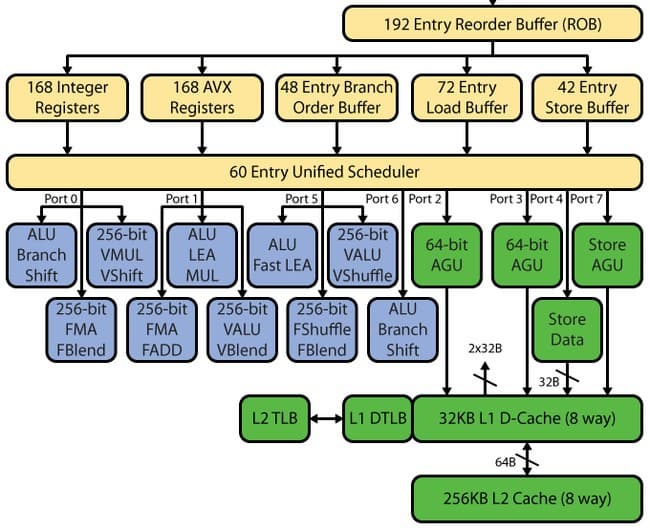
После декодера следует очередь декодированных инструкций, и вот тут мы видим первое изменение. В SB было две очереди по 28 записей — одна очередь на один виртуальный поток Hyper-Threading (НТ). В Haswell две очереди объединили в одну общую для двух потоков HT на 56 записей, то есть объем очереди не изменился, но изменилась концепция. Теперь весь объем в 56 записей доступен одному потоку при отсутствии второго — следовательно, можно ожидать прироста как в малопоточных приложениях, так и в многопоточных (это связано с тем, что единую очередь два потока могут использовать более эффективно).
Изменению подвергся также буфер переупорядочивания — он был увеличен со 168 до 192 записей. Это должно повысить эффективность HT за счет большей вероятности наличия «независимых» друг от друга мопов. Очередь декодированных микроопераций увеличена с 54 до 60. Физические регистровые файлы, которые появились в SB, также были увеличены — со 160 до 168 регистров для целочисленных операндов и со 144 до 168 для операндов с плавающей запятой, что должно положительно сказаться на производительности векторных вычислений.
Сведем все данные об изменениях в буферах и очередях в единую таблицу.
| Sandy Bridge | Haswell | |
| Буфер переупорядочивания | 168 | 192 (+14%) |
| Буфер загрузки | 64 | 72 (+12%) |
| Буфер выгрузки | 36 | 42 (+17%) |
| Очередь декодированных микроопераций | 54 | 60 (+11%) |
| Физический регистровый файл для целочисленных операндов | 160 | 168 (+5%) |
| Физический регистровый файл для операндов с плавающей запятой | 144 | 168 (+17%) |
| Allocation Queue | 2×28 | 56 |
| Средний процент прироста по первым четырем позициям | ≈14% |
В принципе, изменения параметров в Haswell выглядят вполне ожидаемыми, учитывая общую логику развития процессорной архитектуры Intel. Исходя из этой же логики, можно предположить, что в следующем поколении Core размеры буферов и очередей увеличатся не более чем на 14%, то есть размер буфера переупорядочивания будет в районе 218. Но это уже чисто теоретические предположения.
Следом за очередью декодированных операций располагаются порты запуска и прикрепленные к ним функциональные устройства. На этом этапе остановимся более подробно.
Как мы знаем, у Sandy Bridge было шесть портов запуска, которые он унаследовал от Nehalem, а тот, в свою очередь, от Conroe. То есть с 2006 года, когда Intel добавила еще два порта к имевшимся в распоряжении Рentium 4 четырем, количество портов запуска не менялось — только добавлялись новые функциональные устройства. Правда, стоит оговориться, что P4 имел своеобразную самобытную архитектуру NetBurst, в которой два его порта могли выполнять по две операции за один такт (хотя и далеко не со всеми операциями). Но наиболее правильным будет проследить эволюцию количества портов запуска не на примере P4, а на примере PIII, так как P4 имеет и длинный конвейер, и порты запуска с «удвоенной» производительностью, и кэш трасс, да и вся его архитектура заметно отличается от общепринятной. А Pentium III очень близок по функциональной схеме портов запуска к Conroe, и также имеет короткий контейнер. Так что в общем и целом можно сказать, что Conroe является прямым наследником PIII. Исходя из этого можно заявить, что в 2006 году был добавлен лишь один порт запуска по сравнению с PIII, который имел пять портов запуска.
Таким образом, количество портов запуска растет достаточно медленно, а если уж добавляются новые, то по одному. В Haswell же добавили сразу два, суммарно получив целых восемь портов — еще чуть-чуть, и дойдем до Itanium. Соответственно, Haswell показывает теоретическую производительность на исполнительном тракте в 8 моп/такт, из которых 4 мопа расходуются на арифметические операции, а остальные 4 приходятся на операции с памятью. Напомним, что у Conroe/Nehalem/SB было 6 моп/такт: 3 мопа арифметических операций и 3 мопа операций с памятью. Данное улучшение должно поднять показатель IPC, и, таким образом, в архитектуре Haswell действительно присутствуют очень серьезные изменения, которые вполне оправдывают его место «так» в плане развития Intel.
Изменения ФУ в Haswell
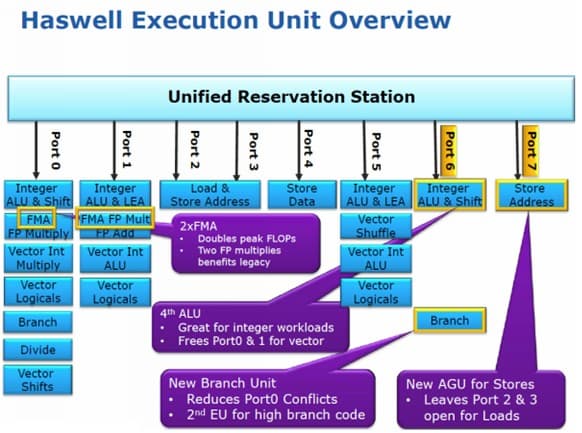
Количество исполнительных устройств также было увеличено. Новый шестой (седьмой по счету) порт добавил два дополнительных исполнительных устройства — устройство целочисленной арифметики и сдвига и устройство предсказания переходов. Седьмой (восьмой) порт отвечает за выгрузку адреса.
Таким образом, мы получаем четыре исполнительных устройства целочисленной арифметики, тогда как Sandy Bridge нам предоставлял только три. Следовательно, можно ожидать увеличения скорости целочисленной арифметики. Кроме того, теоретически это должно нам позволить одновременно выполнять и расчеты с плавающей запятой, и целочисленные расчеты, что, в свою очередь, может увеличить эффективность НТ. В SB вычисления с плавающей запятой осуществлялись на тех же портах, где использовались целочисленные функциональные устройства, поэтому по большому счету происходила блокировка, т. е. нельзя было иметь «разнородную» нагрузку. Также следует отметить, что добавление дополнительного устройства перехода в Haswell позволит предсказывать переход без «блокировки» при арифметических вычислениях — ранее при целочисленных вычислениях единственный предсказатель перехода блокировался, т. е. была возможна работа либо арифметического исполнительного устройства, либо предсказателя. Порты 0 и 1 также претерпели изменения — в них появилась поддержка FMA3. Седьмой (восьмой) порт Intel ввела для увеличения эффективности и снятия «блокировки» — когда второй и третий порты работают на загрузку, седьмой (восьмой) порт может заниматься выгрузкой, что раньше было просто невозможно. Данное решение необходимо для обеспечения высокого темпа исполнения AVX/FMA3-кода.
Вообще, такой широкий исполнительный тракт вполне может привести к изменению HT — сделав ее четырехпоточной. В сопроцессорах Intel Xeon Phi с гораздо более узким исполнительным трактом HT является четырехпоточной, при этом, как показывают исследования и тесты, сопроцессор достаточно хорошо масштабируется. То есть даже более узкий исполнительный тракт в принципе позволяет эффективно работать с четырьмя потоками. А уж тракт с восемью портами запуска вполне эффективно может выполнять четыре потока, и более того, наличие четырех потоков сможет лучше загрузить восемь портов запуска. Правда, для большей эффективности необходимо будет увеличить буферы (в первую очередь — буфер переупорядочивания) для большей вероятности «независимых» данных.
Также в Haswell вдвое увеличили пропускную способность L1—L2, при этом остались прежние величины задержки. Такая мера была просто необходима, так как 32-байтной записи и 16-байтного чтения попросту не хватило бы при наличии восьми портов запуска, а также 256-битных AVX и FMA3.
| Sandy Bridge | Haswell | |
| L1i | 32k, 8-way | 32k, 8-way |
| L1d | 32k, 8-way | 32k, 8-way |
| Латентность | 4 такта | 4 такта |
| Скорость загрузки | 32 байта/такт | 64 байта/такт |
| Скорость записи | 16 байт/такт | 32 байта/такт |
| L2 | 256k, 8-way | 256k, 8-way |
| Латентность | 11 тактов | 11 тактов |
| Пропускная способность между L2 и L1 | 32 байта/такт | 64 байта/такт |
| L1i TLB | 4k: 128, 4-way 2M/4M: 8/thread | 4k: 128, 4-way 2M/4M: 8/thread |
| L1d TLB | 4k: 128, 4-way 2M/4M: 7/thread 1G: 4, 4-way | 4k: 128, 4-way 2M/4M: 7/thread 1G: 4, 4-way |
| L2 TLB | 4k: 512, 4-way | 4k+2M shared: 1024, 8-way |
TLB L2 был увеличен до 1024 записей, появилась поддержка двухмегабайтных страниц. Увеличение TLB L2 повлекло за собой и увеличение ассоциативности с четырех до восьми.
Что касается кэша третьего уровня, то с ним ситуация неоднозначная: в новом процессоре задержка доступа должна увеличиться из-за потерь при синхронизации, ведь теперь кэш L3 работает на собственной частоте, а не на частоте процессорных ядер, как было раньше. Хотя доступ по-прежнему осуществляется в 32 байта за такт. С другой стороны, Intel говорит об изменениях в System Agent и улучшениях блока Load Balancer, который может теперь обрабатывать параллельно несколько запросов к кэшу L3 и разделять их на запросы к данным и «не-данным». Это должно повысить пропускную способность кэша L3 (некоторые тесты подтверждают это, ПС кэша L3 оказывается чуть выше IB).
Принцип работы кэша L3 в Haswell чем-то схож с Nehalem. У Nehalem кэш L3 находился в Uncore и имел собственную фиксированную частоту, а в SB кэш L3 привязали к процессорным ядрам — его частота стала равна частоте процессорных ядер. Из-за этого возникали проблемы — например, когда процессорные ядра работали на сниженных частотах при отсутствии нагрузки (и LLC «засыпал»), а GPU была необходима высокая ПС LLC. То есть это решение ограничивало производительность GPU, и к тому же требовалось выводить процессорные ядра из состояния простоя лишь для того, чтобы разбудить LLC. В новом процессоре для улучшения ситуации с энергопотреблением и повышения эффективности работы GPU в вышеописанных ситуациях кэш L3 работает на собственной частоте. Наибольшую пользу из этого решения должны извлекать мобильные, а не настольные решения.
Стоит заметить, что объемы кэшей имеют определенную зависимость. Кэша третьего уровня приходится два мегабайта на ядро, кэша второго уровня — 256 КБ, что в восемь раз меньше объема L3 на ядро. Объем кэша первого уровня, в свою очерердь, в восемь раз меньше L2 и составляет 32 КБ. Кэш мопов прекрасно вписывается в эту зависимость: его объем в 1536 мопов в 7-9 раз меньше L1 (точно это определить невозможно, так как битовый объем мопа неизвестен, а Intel вряд ли будет распространяться на эту тему). В свою очередь, буфер переупорядочивания в 168 мопов ровно в восемь раз меньше кэша мопов в 1536 моп, хотя, исходя из повсеместного увеличения буферов и очередей, следовало ожидать увеличения кэша мопов на 14%, то есть до 1776. Таким образом, объемы буферов и кэшей имеют пропорциональные размеры. Это, наверное, еще одна причина, почему Intel не увеличивает кэши L1/L2, считая такие пропорции в объемах наиболее эффективными с точки зрения увеличения производительности на увеличение площади. Стоит заметить, что в процессорах со встроенным топовым графическим ядром присутствует промежуточная быстрая память с широкой шиной доступа, которая кэширует все запросы к оперативной памяти — как процессора, так и видеоускорителя. Объем этой памяти составляет 128 МБ. Для процессорных ядер, если расценивать эту память как кэш L4, объем должен был быть 64 мегабайта, а с добавлением еще и графического ядра использование 128 МБ выглядит вполне логичным.
Что касается контроллера памяти, то он не получил ни увеличения числа каналов, ни увеличения частоты работы с оперативной памятью, то есть это всё тот же контроллер памяти с двухканальным доступом на частоте 1600 МГц. Такое решение выглядит довольно странно, ведь переход с SB на IB увеличил частоту функционирования ИКП с 1333 МГц до 1600 МГц, хотя это был всего лишь переход архитектуры на новый техпроцесс. А сейчас мы имеем новую архитектуру, при этом частота функционирования памяти осталась на прежнем уровне.
Еще более странным это выглядит, если вспомнить об улучшениях в графическом ядре — ведь мы помним, что даже младшая видеокарта HD2500 в IB полностью утилизировала пропускную способность в 25 ГБ/с. Теперь же подросла и производительность ЦП, и производительность графики, а пропускная способность памяти осталась на прежнем уровне. Если взглянуть более широко, то конкурент постоянно увеличивает пропускную способность памяти в своих гибридных процессорах, и она выше, чем у Intel. Логично было ожидать в Haswell поддержку памяти с частотой 1866 МГц или 2133 МГц, что повысило бы пропускную способность до 30 и 34 ГБ/с соответственно.
Как итог, данное решение Intel не совсем понятно. Во-первых, конкурент ввел поддержку более быстрой памяти без особых проблем. Во-вторых, стоимость модулей памяти, функционирующих на частоте 1866 МГц, ненамного выше по сравнению с 1600-мегагерцовыми модулями, к тому же никто не обязывает покупать 1866-мегагерцовую память — выбор оставался бы за пользователем. В-третьих, никаких проблем с поддержкой не то что 1866 МГц, но и 2133 МГц быть не может: с самого анонса Haswell были поставлены мировые рекорды разгона оперативной памяти, то есть ИКП без проблем «потянул» бы более быструю память. В-четвертых, в серверной линейке Xeon E5-2500 V2 (Ivy Bridge-EP) заявлена поддержка 1866 МГц, а ведь Intel обычно внедряет поддержку более быстрых стандартов памяти на этом рынке много позже настольных решений.
В принципе, можно было бы предположить, что в отсутствие конкуренции Intel нет необходимости «просто так» наращивать мускулы и еще больше увеличивать превосходство, но данное предположение абсолютно некорректно, так как увеличение пропускной способности памяти, как правило, увеличивает производительность встроенного графического ядра и почти не увеличивает производительность процессора. При этом Intel пока отстает от AMD именно в производительности графики, и в последние годы сама же Intel всё больше и больше уделяет внимание именно графике, и темпы улучшений для нее гораздо выше, чем для процессорного ядра. Кроме того, если опираться на результаты тестирований встроенного графического ядра предыдущего поколения HD4000, которые показали, что увеличение ПСП приводит к увеличению производительности графики до 30%, а также учитывая, что новое графическое ядро HD4600 заметно быстрее, чем HD4000, то зависимость производительности графического ядра от ПСП становится еще более явной. Новое графическое ядро будет еще больше упираться в «узкую» пропускную способность памяти. Суммируя все факты, решение Intel совершенно непонятно: компания собственноручно «задушила» свою графику, а ведь увеличение ПСП могло бы подтянуть ее производительность.
Возвращаясь к архитектуре кэшей, выскажем просто мысль в пустоту: раз уж был добавлен промежуточный кэш (кэш мопов), то почему бы не добавить еще промежуточный кэш данных объемом порядка 4-8 КБ и с меньшей задержкой доступа между кэшем L1d и исполнительными устройствами, как у P4 (раз уж концепция кэша мопов была взята именно у Netburst)? Напомним, что в P4 этот промежуточный кэш данных имел время доступа в два такта, причем один такт Р4 был равен примерно 0,75 тактам обычного процессора, то есть время доступа было около полутора тактов. Впрочем, может быть, мы еще увидим что-то подобное — Intel любит вспоминать хорошо забытое старое.
Как можно было заметить, большинство архитектурных изменений Intel направила на увеличение производительности кода AVX/FMA3: это и увеличение пропускной способности кэшей, и увеличение количества портов, и увеличение темпа выгрузки/загрузки в исполнительном тракте. В итоге, основной выигрыш в производительности должен быть именно в ПО, написанном с использованием AVX/FMA3. В принципе, судя по результатам тестов, похоже, что так оно и есть. Сухая производительность на одинаковой частоте в «старых» приложениях получила прирост около 10% по сравнению с предыдущим ядром, а приложения, написанные с использованием новых наборов инструкций, показывают прирост более 30%. Так что преимущества архитектуры Haswell будут раскрываться по мере оптимизации приложений под новые наборы инструкций. Вот тогда превосходство Haswell над SB станет очевидным.
Основной выигрыш от значительной части нововведений получат мобильные устройства. Им помогут и новый подход к кэшу L3, и встроенный регулятор напряжения, и новые режимы сна, и более низкие минимальные частоты функционирования процессорных ядер.
Заключение (процессорная часть)
Чего можно ожидать от Haswell?
В связи с увеличением количества портов запуска можно ожидать увеличения показателя IPC, поэтому небольшое преимущество у новой архитектуры Haswell над Sandy Bridge на одинаковой частоте будет уже сейчас, даже при неоптимизированном программном обеспечении. Инструкции AVX2/FMA3 — это задел на будущее, и это будущее зависит от разработчиков ПО: чем быстрее они адаптируют свои приложения, тем быстрее конечный пользователь получит прирост производительности. Однако не стоит рассчитывать на рост всего и везде: SIMD-инструкции в основном используются в работе с мультимедийными данными и в научных расчетах, так что роста производительности стоит ожидать именно в этих задачах. Основной выигрыш от увеличения энергоэффективности получат мобильные системы, где этот вопрос действительно важен. Таким образом, два основных направления, по которым новая архитектура Intel Haswell существенно выигрывает — это увеличение SIMD-производительности и увеличение энергоэффективности.
Что касается применимости новых процессоров Haswell, то стоит разобрать несколько разных вариантов их применения: в настольных компьютерах, в серверах, в мобильных решениях, для геймеров, для оверклокеров.
Десктоп
Энергопотребление не является ключевым аспектом для десктопного процессора, поэтому даже в Европе с ее дорогой электроэнергией вряд ли кто-то будет переходить на Haswell с предыдущих поколений только из-за этого. Тем более, что TDP у Haswell выше, чем у IB, так что экономия будет лишь в случае минимальных нагрузок. При такой постановке вопроса сомнений быть не может — оно того не стоит.
С точки зрения производительности переход тоже не выглядит таким уж выгодным делом: максимальный прирост скорости в процессорных задачах сейчас составит не более 10%. Переход на Haswell с Sandy Bridge или Ivy Bridge будет оправдан только в том случае, если вы планируете использовать приложения с грамотной поддержкой FMA3 и AVX2: поддержка FMA3 может дать прирост в некоторых приложениях от 30% до 70%. Улучшения, связанные с виртуализацией и внедрением транзакционной памяти, для десктопа малоинтересны и малополезны.
Серверы и рабочие станции
Учитывая, что серверы работают непрерывно все 24 часа в сутки и имеют достаточно высокую постоянную нагрузку на процессор, по чистому энергопотреблению Haswell вряд ли будет лучше IB, хотя по производительности на ватт и может дать некоторый выигрыш. Поддержка AVX2/FMA3 вряд ли пригодится в серверах, а вот в рабочих станциях, занимающихся научными расчетами, данная поддержка будет весьма и весьма полезна — но лишь при условии поддержки новых инструкций в применяемом ПО. Транзакционная память — вещь достаточно полезная, но тоже не всегда: она может дать прирост в многопоточных программах и в программах, работающих с базами данных, но для ее эффективного использования также необходима оптимизация ПО.
А вот все улучшения, связанные с виртуализацией, скорее всего дадут неплохой эффект, так как виртуальные среды сейчас используются очень активно, и на большинстве физических серверов работает по несколько виртуальных. Причем распространенность виртуализации объясняется не только заметным снижением издержек виртуальной среды в плане производительности, но и экономической эффективностью: содержать много виртуальных серверов на одном физическом и дешевле, и позволяет более эффективно использовать ресурсы, в том числе ресурсы процессора.
Так что на серверном рынке появление Haswell должны встретить положительно. После смены серверов на базе Xeon E3-1200v1 и Xeon E3-1200v2 на серверы с Xeon E3-1200v3 (Haswell) вы сразу получите прирост эффективности, а после оптимизации ПО под AVX2/FMA3 и транзакционную память производительность подрастет еще сильнее.
Мобильные решения
Основной выигрыш от внедрения Haswell в мобильном сегменте, конечно же, лежит в сфере улучшенного энергопотребления. Судя по презентациям Intel, а также результатам тестов, которые уже появляются в Сети, эффект действительно есть, и заметный.
Что касается чистой производительности, то переход с Ivy Bridge на Haswell не представляется таким уж обоснованным мероприятием: чистый прирост должен быть отностительно небольшим, а улучшения в отдельных компонентах (те же виртуализация или мультимедийные инструкции) вряд ли много дадут пользователю мобильной системы, так как на ноутбуках и планшетах редко занимаются созданием сред или сложными научными расчетами.
В общем и целом, с точки зрения процессорной производительности многого ждать не стоит, зато в мобильных системах наверняка будет востребован рост производительности графического ядра. Поэтому если вопросы энергопотребления для вас не критически важны, то серьезно рассматривать вопрос апгрейда с Sandy Bridge или Ivy Bridge не стоит — лучше продолжать эксплуатировать имеющиеся системы, пока они окончательно не устареют. Если же вы часто работаете от батарей, то Haswell способен обеспечить существенный прирост времени автономной работы.
Геймеры
Вопрос энергопотребления у геймеров в России, как правило, не стоит — да и с чего бы ему стоять, когда геймерские видеокарты потребляют по 200 и более ватт? Виртуализация и транзакционная память геймеру тоже не нужны. Не факт, что AVX2/FMA3 будут востребованы именно для игр, хотя они могут пригодиться в расчетах физики. Остается чистая производительность процессора, а тут разница с тем же Ivy Bridge невелика. Как итог, для этой категории пользователей прямой переход с SB или IB на Haswell также не выглядит актуальным. Зато разумно переходить на новые процесоры с Nehalem и Lynifield, и уж тем более Conroe.
Оверклокеры
Для оверклокеров новый процессор (но, конечно, лишь его «разблокированная» K-версия) может быть интересен, особенно если удастся его «скальпировать», то есть снять металлическую крышку и охлаждать кристалл напрямую. Если этого не сделать, то результаты по разгону выглядят еще более скромными, чем у Ivy Bridge. Плюс, сдерживающим фактором может стать интегрированный регулятор напряжения. Подробнее об этом читайте в нашей статье.


