Часть 1: AMD Phenom II, количество ядер
Во «времена оные», когда новые модели процессоров анонсировались несколько раз в год (два-три раза, на самом деле…), а любая новая архитектура являлась де-факто почти на 100% новой (хорошо, хотя бы на 70%…), сравнительные тестирования было делать достаточно легко: взял пару-тройку CPU, сравнил между собой — вот и новые данные, вполне актуальные, свежие, всем интересные. Нынешние времена — совсем другие: смотришь на якобы новый процессор, и понимаешь: это — от того прототипа (или решения конкурента) взяли, это — от другого, с этим — смирились дешевизны ради, это — добавили, потому что технологии производства позволяют добавить почти задаром, но этот блок — именно таким образом сделан потому, что те же пресловутые технологии производства вынудили сделать его именно таким (хотя, с точки зрения идеала, можно было бы и лучше). И наступает понимание, что результаты сравнения какого-нибудь Core 2 Duo E8500 с каким-нибудь Core 2 Duo E8700 будут настолько банально предсказуемы, что их даже читать не хочется: чтобы относительно точно их предсказать, достаточно результатов любого из них, плюс логики, здравого смысла и знания основ арифметики. И даже в случае с различными архитектурами CPU, вполне хватает пары-тройки сравнений, чтобы результаты всех остальных были ясны даже без проведения тестов.
С другой стороны, наверняка, в точности подобным образом создавались и старые добрые массовые процессоры прошлых времён — нет ничего нового под солнцем. Однако в те времена мы меньше знали, и, согласно мудрости царя Соломона, эти знания приносили нам меньше печали… Данная серия материалов, которая будет включать в себя всего 4 статьи, предназначена именно для тех, чьё душевное состояние состоит в полном согласии с предыдущим абзацем: кто не хочет читать десятки тестовых сравнений, потому что им проще один раз достаточно подробно разобраться в вопросе — а дальше они сами сделают выводы, искренне веря в свои собственные логику и здравый смысл. Данную серию можно назвать, в некотором роде, «материалами для IT-снобов».
Кроме того, это, безусловно, материал для тех, кто верит в закономерности. Если вы не верите в возможность предсказания производительности Core 2 Duo E8700 на основании объективно полученных данных о производительности Core 2 Duo E8500 — то этот материал не для вас. Если вы не верите в то, что быстродействие Phenom X3 8450, однозначно, обуславливает скорость Phenom X3 8750 — то вам не следует читать эту статью. Ибо во многих знаниях, как известно… и далее по тексту. Для всех остальных, мы решили, наконец-то, дать простые тестовые ответы на простые пользовательские вопросы: что случается, если взять одно и то же процессорное ядро — и поставить его в ситуацию, когда оно сможет (с той или иной долей успешности) справиться с простыми пользовательскими задачами? Для этих целей мы взяли два самых «продвинутых» ядра от двух самых популярных производителей x64-процессоров — AMD Phenom II X4 и Intel Core i7. Частота? Какая разница?! Объём кэша? Тоже не важно! Мы попытались оценить перспективность и масштабируемость самой архитектуры. Разумеется, конкретные воплощения могут быть лучше или хуже — однако у них есть общие черты, которые практически невозможно изжить, не меняя общей концепции развития. Мы стремились оценить именно общую концепцию — разумеется, применительно к нынешнему, реальному программному обеспечению.
К слову о реальности. на данный момент наша методика не содержит тестов, в которых бы одно приложение выполнялось на фоне активности другого (как это действительно часто бывает в жизни). О причинах такого (вполне осознанного) решения мы писали не раз, однако в таком масштабном материале можно повториться: суть в том, что multi-application тест практически невозможно сделать хоть сколько-нибудь репрезентативным, с точки зрения получаемых результатов, из-за почти бесконечного количества вариантов комбинаций приложений. То есть, например, мы решим, что тестироваться будет быстродействие в игре Unreal Tournament 3 на фоне архивации с помощью 7-Zip и проверки диска антивирусом Avast. Тут же возникает пять вопросов:
- Почему Unreal Tournament 3, а не, например, World in Conflict?
- Почему 7-Zip, а не, например, WinRAR?
- Почему Avast, а не, например, AVG?
- Наконец, почему игра + архивация + антивирус, а не кодирование видео + рендеринг + математические вычисления?
- И, кстати, имеют ли полученные результаты какую-то ценность за пределами комбинации вышеуказанной тройки конкретных программных продуктов? Что станет с результатами, если заменить, скажем, архиватор другим?
Честный ответ на вопросы 1-4 должен звучать так: «Просто потому, что нам так захотелось», — и другого варианта честного ответа не существует. Действительно, либо нужно тестировать всё многообразие различных комбинаций разного рода ПО (задача невыполнимая) — либо нужно брать одну конкретную комбинацию, осознавая, что она будет выбрана, по сути, с помощью высоконаучного метода тыканья пальцем в небо. Ответ на пятый вопрос тоже один: «Никакой. Неизвестно». Именно по этой причине, мы не используем multi-application тесты: лучше получить корректный результат при тестировании в несколько идеализированном варианте окружения, чем непонятно о чём говорящую цифру при тестировании в псевдореальном окружении (а на самом деле, в одном конкретном варианте реального окружения, произвольно выбранном из многих тысяч других).
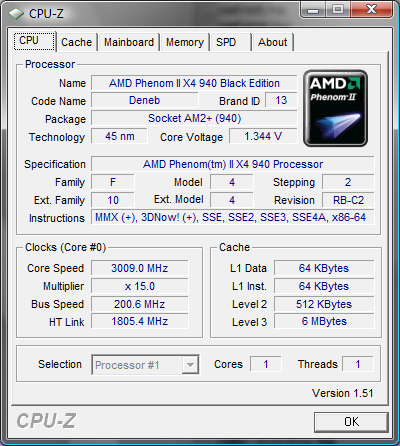
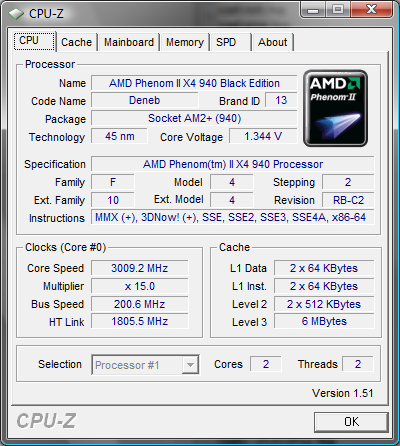
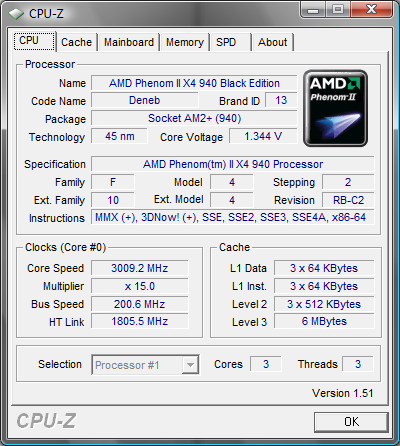
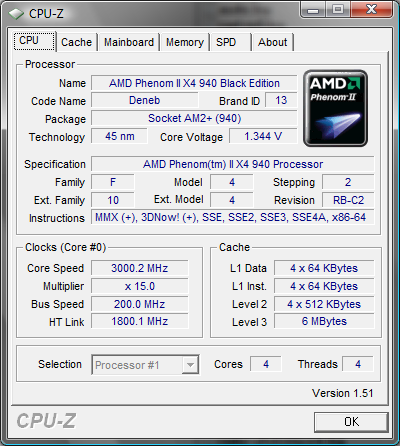
В данной части обещанного сериала, мы оценим масштабируемость производительности систем на базе AMD Phenom II в зависимости от количества процессорных ядер, взяв в качестве примера систему на базе AMD Phenom II X4 940 Black Edition, и протестировав её быстродействие с одним включенным ядром, двумя, тремя, и четырьмя. Таким образом, мы создали идеальную для исследования ситуацию: в тестируемой системе не меняется ничего, кроме количества ядер у центрального процессора, а физически — так и вовсе ничего не меняется. Разумеется, некоторые могут возразить, что реальным одно- двух- и трёхъядерникам недоступны такие размеры кэша, там всё намного скромнее. Однако мы и не пытались сделать сравнение процессоров. Мы ставим топовое решение в различные ситуации — и исследуем его поведение в них. Для вышеупомянутых «IT-снобов», как нам кажется, данных сведений будет вполне достаточно. Остальное они наверняка додумают сами — руководствуясь, опять-таки, вышеупомянутыми логикой и здравым смыслом.
Конфигурация тестовых стендов
Относительно конфигурации тестовых стендов, хотелось бы сделать только одно замечание — о принятом нами способе размещения модулей памяти. Как мы уже писали ранее, полностью корректным образом уравнять системы на базе LGA1366 и Socket AM2+ не возможно, так как логичная для трёхканального контроллера памяти платформы LGA1366 конфигурация «3 модуля по 2 ГБ», на Socket AM2+ воспроизведена быть не может — у данной платформы всего два канала контроллера памяти. Соответственно, для получения того же объёма ОЗУ, придется, так или иначе, комбинировать двух- и одногигабайтные модули. Подробнее, проблема выбора режимов контроллера памяти на платформе Socket AM2+ будет освещена в следующей статье, а пока просто скажем, что в данном тестировании использовался вариант «2+1 на каждый канал в unganged-режиме».
| Конфигурация 1 | Конфигурация 2 | Конфигурация 3 | Конфигурация 4 | |
| Процессор | Phenom II X4 940 (1 core*) | Phenom II X4 940 (2 core*) | Phenom II X4 940 (3 core*) | Phenom II X4 940 (4 core*) |
| Системная плата | ASUS M3A32-MVP Deluxe | |||
| Память | 2x(2+1) GB DDR2-800 4-4-4-12-22-2T | |||
| Видеокарта | Palit GeForce GTX 275 | |||
| Блок питания | Cooler Master Real Power M1000 | |||
* — разумеется, использовался один и тот же процессор, требуемое количество ядер включалось с помощью настройки BIOS системной платы.
Тестирование
Для начала имеет смысл описать специфику данной статьи. Специфика связана, прежде всего, с тем, что это «как бы тестирование»… только не совсем — ведь тестируемых «процессоров» не существует в реальности (за исключением одного — оригинального AMD Phenom II X4 940 Black Edition со всеми включенными ядрами). Соответственно, нет смысла рассуждать о полезности того или иного выбора, ибо никакого реального выбора в статье тоже не имеется. Поэтому нам предстоит задуматься, скорее, о глобальном: какие тенденции в развитии современного программного обеспечения иллюстрируют результаты сегодняшних тестов? Реально ли выявить эти тенденции, и осмыслить их? Для этого вряд ли хватит одной только сравнительной диаграммы по группе ПО, поэтому в данном материале на каждую группу иногда будет по две диаграммы и вдобавок таблица с подробными результатами тестов.
Первая диаграмма — традиционная. На ней приведены баллы каждого «процессора», вычисленные, согласно нашей методике тестирования. Правда, сегодня мы решили привести их не в виде столбиков, а в виде графика — чтобы было видно, насколько стремительно (или, наоборот, неохотно) «рвётся ввысь» кривая производительности системы, по мере включения всё большего количества ядер. Вторая диаграмма представляет собой график, на котором каждая линия олицетворяет прирост производительности по мере добавления количества ядер для каждого приложения из данной группы в отдельности. Отсчёт начинается с одноядерной системы, производительность которой, соответственно, принята за 100% (поэтому все линии выходят из одной точки). Данная диаграмма позволяет более точно отследить поведение отдельных программ, что в контексте наших желаний может быть очень полезно. И, наконец, — таблица с результатами тестов (также по каждому приложению в отдельности). Начиная со столбика «2 ядра», в ней присутствуют не только абсолютные величины результатов, но и некие проценты. Что это? Это цифра, отражающая прирост производительности данной системы по отношению к предыдущей. Запомните, это очень важно: по отношению к предыдущей, а не к исходной одноядерной. Таким образом, если мы видим в столбике трёхъядерной системы цифру 12% — это значит, что трёхъядерная система в данном приложении показала на 12% более хороший результат, чем двухъядерная. А для двухъядерной системы эта же цифра будет означать её превосходство над одноядерной.
Кстати, советуем освежить в памяти некоторые знания по арифметике, чтобы не удивляться тому, чему удивляться вовсе не стоит: совершенно очевидно, что только двухъядерная система может (и то в идеальном случае*) оказаться на 100% быстрее одноядерной. Трёхъядерная система, даже в идеальной ситуации не может быть быстрее двухъядерной более чем на 50%. Четырёхъядерная быстрее трёхъядерной — не более чем на 33%.
* — На самом деле, как вы увидите позже, при анализе результатов тестирования, практика иногда успешно опровергает все самые стройные теории… но об этом — позже.
Также, традиционно, мы даём любознательным читателям ссылку на таблицу в формате Microsoft Excel, в которой приведены все результаты тестов в самом подробном виде. А также, для удобства их анализа, присутствуют две дополнительные закладки — «Compare #1» и «Compare #2». На них, как и в таблицах, присутствующих в статье, произведено сравнение четырёх систем в процентном отношении. Разница очень простая: в случае с Compare #1, проценты вычисляются так же, как в таблицах в статье, — по отношению к предыдущей системе, а в случае с Compare #2, все системы сравниваются с базовой одноядерной (как на второй диаграмме, только в текстовом виде).
3D-визуализация
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| 3ds max ↑* | 11,95 | 12,06 | +1% | 12,21 | +1% | 12,83 | +5% |
| Maya ↑ | 2,04 | 2,58 | +26% | 3,15 | +22% | 3,18 | +1% |
| Lightwave ↓ | 22,75 | 19,76 | +15% | 19,44 | +2% | 18,94 | +3% |
| SolidWorks ↓ | 64,11 | 62,62 | +2% | 63,16 | -1% | 61,99 | +2% |
| Pro/ENGINEER ↓ | 1477 | 1304 | +16% | 1381 | -1% | 1223 | +4% |
| UGS NX ↑ | 2,1 | 2,14 | +2% | 2,14 | 0 | 2,17 | +1% |
* — здесь и далее в таблицах стрелочкой вверх (↑) помечены те тесты, где лучшим является больший результат, стрелочкой вниз (↓) — тесты, где лучшим является меньший результат.
Нас уже давно «терзали смутные сомненья» по поводу того, насколько хорошо трёхмерные пакеты умеют задействовать возможности многоядерных систем не в процессе рендеринга, а в процессе обычной интерактивной работы. Именно по этой причине визуализация трёхмерных объектов и была выделена в отдельную группу новой методики. Взгляд на первую диаграмму совершенно не внушает оптимизма: «в среднем по больнице» переход с одного ядра на четыре даёт жалкие 17% прироста быстродействия. Однако может быть у некоторых приложений ситуация всё-таки лучше? Обратим внимание на вторую диаграмму и таблицу к ней.
Наибольшую отдачу от многоядерных систем получает пакет Maya: он с достаточно большим оптимизмом (+26%) реагирует на включение второго ядра, почти так же «бодро» (ещё +22%) реагирует на включение третьего — и только на четвёртом «сдувается», демонстрируя всего лишь 1% прироста. Кое-как умеют задействовать 2-е ядро при визуализации Lightwave и Pro/ENGINEER, но существенно хуже, и только второе — уже на 3-е ядро они практически не реагируют. Для проформы, мы выделили красным фоном два результата, когда при включении большего количества ядер система начинала работать медленнее, но пока мы не видим в этом серьёзного повода для беспокойства: расхождение в 1% вполне может быть объяснено элементарной погрешностью измерений. Впрочем, на всякий случай, поставим в уме «флажок»: в обоих случаях это произошло при переходе с двух ядер на три.
Трёхмерный рендеринг
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| 3ds max ↑ | 3,41 | 7,62 | +123% | 10,26 | +35% | 12,89 | +26% |
| Maya ↑ | 00:11:23 | 00:05:53 | +93% | 00:03:57 | +49% | 00:03:01 | +31% |
| Lightwave ↓ | 502,78 | 212,34 | +137% | 144,85 | +47% | 109,21 | +33% |
Существенно более оптимистичная диаграмма: в среднем, в группе рендеринга переход одного ядра на два даёт прирост производительности на 116% (!), а переход с одного ядра на четыре — 400% (то есть максимально возможный теоретически идеал). Однако взгляд на вторую диаграмму и таблицу к ней заставляет нас здорово удивиться: в двух случаях из трёх, при переходе от одного ядра к двум, скорость рендеринга возросла существенно, более чем на 100%! То есть превысила теоретически допустимый предел. Была бы разница хотя бы процентов на 5-6 — можно было бы (слегка сомневаясь в собственной правоте, но всё же…) списать всё на ту же погрешность измерений. Однако 23% и 37% на неё списать никак не получается. Что же произошло?
В принципе, можно напридумывать массу гипотез. В конце концов, теория предусматривает и условия работы ПО «теоретически-стерильные», а у нас ПО работает под управлением операционной системы, которая сама по себе имеет сотни фоновых процессов. В процессе написания материала автор из любопытства даже завёл отдельную тему в конференции iXBT.com, где предложил всем желающим высказывать свои предположения. Прозвучала масса предположений, но наиболее правдоподобными, с нашей точки зрения, выглядят два: об эффекте увеличения общего объёма кэша всего процессора при включении второго ядра (у AMD Phenom II L2-кэш является «собственностью» ядра, и при его отключении также отключается), а также о не очень удачной параллелизации процессов на уровне самого ПО (то есть, получается, что одноядерные системы движок рендеринга искусственно тормозит). К слову — довольно печально, если правильным окажется и второе предположение. С другой стороны, если попытаться проследить в этом некую тенденцию, то получается довольно забавно: выходит, что на компьютерах разработчиков ПО уже настолько прочно обосновались как минимум двухъядерные системы, что об эффективности своего кода применительно к системам одноядерным, они просто перестали думать* — и всплывают странные эффекты.
* — Можно, конечно, заняться конспирологией, и предположить и вовсе злой умысел и наличие тайного сговора с производителями процессоров… однако это, с нашей точки зрения, уже перегиб.
На диаграмме чётко видно, что наиболее хорошо распараллелен движок рендеринга Lightwave: он стабильно показывает почти максимальные для каждого случая цифры прироста. Стабильнее всего движок Maya (MentalRay) — у него линия роста почти абсолютно прямая, без «горба» в районе перехода с одного ядра на два.
Научные и инженерные расчёты
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| MAPLE ↑ | 0,1525 | 0,1399 | -8% | 0,1560 | +12% | 0,1586 | +2% |
| Mathematica ↑ | 2,1972 | 2,3784 | +8% | 2,5288 | +6% | 2,5968 | +3% |
| MATLAB ↓ | 0,0920 | 0,0648 | +42% | 0,0565 | +15% | 0,0525 | +8% |
| SolidWorks ↓ | 54,4 | 46,64 | +17% | 45,74 | +2% | 44,71 | +2% |
| Pro/ENGINEER ↓ | 2284 | 1951 | +17% | 1917 | +2% | 1934 | -1% |
| UGS NX ↑ | 4,18 | 4,29 | +3% | 4,28 | 0 | 4,33 | +1% |
В данном разделе, как вы, наверное, помните (если читали описание методики тестирования; если нет — советуем почитать: данный материал без знания некоторых её нюансов будет достаточно сложно понять) мы собрали все результаты, относящиеся к различного рода вычислениям. Состав группы делится надвое на программные инструменты больше инженерные (SolidWorks, Pro/ENGINEER, UGS NX) и больше научные (MAPLE, Mathematica, MATLAB). Легко заметить, что даже внутри групп «согласья нет» — в «научной» группе MAPLE при переходе с одного ядра на два снизила производительность на целых 8% (ох, уж этот переход! Вечно с ним что-то не то!), а в «инженерной» группе умеренно оптимистичные SolidWorks и Pro/ENGINEER (+17 при включении второго ядра) соседствуют с совершенно индифферентным UGS NX (при включении второго ядра — +3%, при включении третьего — 0).
Включение третьего ядра демонстрирует ещё более печальную картину: фактически, им сумел более-менее эффективно воспользоваться только MATLAB (не забывайте, что +12% на трёх ядрах у MAPLE — это, по сравнению с минус 8% на двух ядрах). Четвёртое ядро задействовать эффективно не смог даже MATLAB — но он хотя бы пытается, но остальные пакеты «сдулись» совсем, Pro/ENGINEER на четырех ядрах даже ушёл в незначительный минус.
Помнится, примерно похожая ситуация наблюдалась в группе 3D-визуализации: подавляющее большинство программного обеспечения если и смогло более-менее эффективно задействовать несколько ядер, то имя этим нескольким — два. Не более. И, опять-таки, как и в случае с визуализацией, наблюдается одна хорошо распараллеленная программа, которая на общем слабеньком фоне смотрится просто чемпионом параллелизма. В данном случае — это MATLAB. За счёт него общий прирост в группе между двумя крайними значениями (1 ядро и 4 ядра) чуть больше, чем в визуализации — 24%. Впрочем, раздумывающим над приобретением четырёхъядерника, такая «высокая» эффективность вряд ли внушит оптимизм.
Растровая графика
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| ACDSee ↓ | 00:08:15 | 00:07:01 | +18% | 00:07:02 | 0 | 00:06:44 | +4% |
| Paint.NET ↓ | 00:01:38 | 00:00:50 | +96% | 00:00:34 | +47% | 00:00:26 | +31% |
| PaintShop Pro ↓ | 00:13:25 | 00:12:46 | +5% | 00:12:46 | 0 | 00:12:51 | -1% |
| PhotoImpact ↓ | 00:10:41 | 00:09:32 | +12% | 00:09:24 | +1% | 00:09:34 | -2% |
| Photoshop ↓ | 00:15:08 | 00:10:09 | +49% | 00:08:23 | +21% | 00:07:40 | +9% |
Кривая на первой диаграмме не настолько оптимистичная, как в случае с рендерингом, — но, по крайней мере, явно выраженное стремление ввысь присутствует. За счёт чего оно присутствует, и почему не такое выраженное, становится ясно при взгляде на вторую диаграмму и таблицу.
Получается следующая картина:
- ACDSee использовать несколько ядер как-то умеет, но явно не большее их количество, чем 2; +4% при включении четвертого ядра дают какую-то смутную надежду, но поскольку от включения третьего ядра пользы ноль — надежда очень смутная.
- PaintShop Pro и PhotoImpact 2 ядра используют ещё хуже ACDSee, если используют вообще: конечно, +12% — это немаленькая цифра, но не будем забывать о том, что второе ядро взяло на себя выполнение всех системных сервисов, а их у Windows Vista очень немало… С третьим и четвертым ядром PaintShop и PhotoImpact работать не умеют точно.
- Adobe Photoshop, хоть и приблизился к идеалу лишь наполовину (+49% там, где, в идеале, могло бы быть 100, +21% там, где, в идеале, могло быть 50, +9% там, где, в идеале, могло быть 33), однако на нынешний момент даже такой результат следует признать очень неплохим. Видно, что с увеличением количества ядер эффективность их использования Photoshop падает: если на двухъядерной системе реальная эффективность составляет порядка половины максимальной теоретической, то уже на трех ядрах она меньше трети теоретической. Можно предположить, что при дальнейшем увеличении количества ядер, эффективность продолжит падать.
- Прекрасную масштабируемость и наивысшую во всей группе эффективность использования многоядерных систем демонстрирует Paint.NET. Напомним, что это единственный в группе графический редактор, написанный полностью на платформе Microsoft.NET. Искреннюю радость по поводу наличия такой превосходно распараллеленной программы омрачает лишь одно: всё-таки, это довольно примитивный графический редактор. Пожалуй, самый простой из всех представленных в группе.
Сжатие данных без потерь
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| 7-Zip ↓ | 00:07:25 | 00:04:53 | +52% | 00:04:47 | +2% | 00:04:46 | 0 |
| WinRAR ↓ | 00:02:49 | 00:02:01 | +40% | 00:01:55 | +5% | 00:01:54 | +1% |
И первая, и вторая диаграммы в данном случае говорят нам об одном и том же, и, положа руку на сердце: то, о чём они нам говорят, мы и так давно знали. Как было сказано недавно другим автором в другой статье на процессорную тематику: «…уже ни для кого не секрет [что] пока для архиваторов "многопоточность" означает "двухпоточность"…» Так оно и есть: и 7-Zip, и WinRAR демонстрируют вполне хорошую эффективность при переходе от одного ядра к двум, и… всё. Включение третьего ядра даёт +2% и +5%, соответственно, результат от включения четвертого и вовсе находится где-то в рамках погрешности измерения. Если анализировать сами результаты, то можно сказать, что у 7-Zip чуть повыше эффективность задействования второго ядра — зато WinRAR, судя по всему, хотя бы пытается задействовать третье. Кроме того, он просто существенно быстрее в абсолютных временных величинах.
Компиляция
В детализированных диаграммах нет нужды, так как в данной подгруппе всего один тест. Разница в 322% между крайними значениями (для одного ядра и для четырех) при максимально теоретически возможных 400%, свидетельствует о том, что нам, наконец-то, удалось разработать очень хорошо распараллеленный бенчмарк для тестирования скорости компиляции с помощью Microsoft Visual C++*. В нынешней реинкарнации, наши тесты успешно подтверждают давно теоретически обоснованный постулат: компиляция большого проекта действительно может быть существенно ускорена при грамотном задействовании многоядерной системы.
* — На самом деле, конкретно в данном случае хорошо распараллеленный бенчмарк действительно являлся серьёзной проблемой, так как «лобовой» подход, использованный в предыдущей методике, привёл к тому, что тест не совсем адекватно отражал реальную ситуацию: возможность задействования параллельной компиляции была заложена в продукте (MS VC++), но мы не смогли ей воспользоваться. Нынешний бенчмарк, в отличие от прошлого, устранил эту ошибку: сейчас возможности MS VC++ по распараллеливанию процесса компиляции проекта используются максимально возможным образом.
К слову, о забавных подробностях разработки бенчмарка: при сборке проекта с помощью vcbuild, этой утилите можно указать опцию /M<…> — количество потоков сборки. Разумеется, напрашивается самый простой вариант: указать его равным количеству процессорных ядер. Тут-то мы и натолкнулись на совершенно неожиданный подводный камень: при указании опции /M3 (для системы с тремя ядрами, соответственно) — сборщик VC++ вёл себя так, как будто была указана опция /M2. То есть третье ядро не задействовалось никак. Пришлось в качестве исключения при обнаружении трех ядер указывать принудительно опцию /M4 — тогда прирост от включения третьего ядра наблюдается, что вы и имеете возможность видеть на диаграмме.
Кодирование аудио
В данном случае, в детализированных диаграммах тоже нет нужды, но по другой причине: в новой версии методики мы используем для тестирования скорости кодирования аудио оболочку dBpoweramp, которая обладает способностью практически идеально распараллеливать процесс кодирования за счёт запуска нескольких (равных числу найденных процессорных ядер) однопоточных кодеков одновременно. Таким образом, мы имели полное право ожидать эффективности, близкой к идеальной: несколько процессов, запущенных на исполнение параллельно, и при этом не очень критичных к подсистеме памяти и объёму кэша (данное свойство аудиокодеков давно известно), как правило, совершенно не мешают друг другу. В реальности, всё именно так и произошло, о чём красноречиво свидетельствуют результаты тестов: +392%, если сравнивать одноядерную и четырёхъядерную системы.
Забавно, что даже на достаточно грубом графике чётко виден небольшой «провал» в районе результата 3-ядерной системы. Если вы скачаете xls-табличку с подробными результатами, вы сами с помощью элементарных подсчётов сможете убедиться, что он действительно существует. То есть — эффективность использования ядер на 3-ядерной системе чуть проседает по сравнению с 2-ядерной и 4-ядерной.
Кодирование видео
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| Canopus ProCoder ↓ | 00:04:45 | 00:04:00 | +19% | 00:03:46 | +6% | 00:03:46 | 0 |
| DivX ↓ | 00:08:19 | 00:06:18 | +32% | 00:05:19 | +18% | 00:05:04 | +5% |
| Mainconcept ↓ | 00:20:00 | 00:12:01 | +66% | 00:09:16 | +30% | 00:07:54 | +17% |
| x264 ↓ | 00:37:27 | 00:20:55 | +79% | 00:15:16 | +37% | 00:10:48 | +41% |
| XviD ↓ | 00:08:58 | 00:07:19 | +23% | 00:06:21 | +15% | 00:05:46 | +10% |
Первая диаграмма демонстрирует нам, что эффект увеличения производительности при увеличении количества ядер в данной группе, несомненно, прослеживается даже невооружённым взглядом, однако он существенно меньше идеального (примерно в два раза), поэтому дополнительная диаграмма с таблицей, конечно, будут необходимы. Начинаем разбираться, что к чему в группе кодирования видео…
К сожалению, явный аутсайдер — это Canopus (GrassValley) ProCoder. Это достаточно пожилое ПО (версия не обновлялась уже несколько лет) по-прежнему является одним из самых качественных программных кодировщиков MPEG2, однако возможности современного железа он использует весьма поверхностно: даже прирост от включения второго ядра равен всего лишь 19%, а дальше эффективность падает ещё больше…
Кодек DivX пытается быть эффективным до конца, но у него это получается с каждым добавляемым ядром всё хуже и хуже. Впрочем, примерно такое же поведение демонстрирует его брат-близнец из рода open source — XviD. Небольшие различия между их поведением всё-таки имеются: DivX более эффективно использует второе ядро, зато XviD умудряется извлечь большую пользу из четвертого. Впрочем, различия не очень принципиальны.
«Монстры параллельной оптимизации» — это коммерческий кодек Mainconcept, и, как ни странно, — open source разработка x264. Причём последний умудряется везде почти приблизиться к максимуму возможного, а при переходе с трех ядер на четыре даже превысить его! Но мы-то с вами уже знаем, в чём тут дело: «псевдопревышение» теоретического лимита, видимо, связано с тем, что x264 «недобрал скорости» на трех ядрах. Мы уже встречались с подобным феноменом 3-ядерной системы раньше, не так ли?
Можно констатировать, что без «старичка» Canopus и первая диаграмма выглядела бы веселее. С другой стороны — формат MPEG2 многие продолжают по старинке использовать для изготовления любительских DVD, а пока жив этот формат — будет жив и лучший по качеству кодек для него, пусть даже он не очень эффективно задействует современные компьютеры.
Java
Мы специально продублировали диаграмму, указав вместо баллов проценты, чтобы вы могли увидеть, как выглядит стандартно хорошо сделанная многопроцессорная оптимизация на данный момент. Смотрите: при переходе с одного ядра на два, она демонстрирует практически идеальный результат: 196% из 200 возможных. При включении третьего ядра, результат уже меньше — 272% из 300 возможных. И лишь на четвертом ядре всё становится понятно: 337% из 400 возможных — дальнейшее наращивание количества ядер, скорее всего, уже почти ничего не даст. На данный момент, повторимся, такое поведение — это лучшее, на что можно рассчитывать. Разумеется, бывают и исключения (вроде рендеринга или кодека x264) — но это именно исключения. А последствия простой, хорошо сделанной ремесленной работы по распараллеливанию кода, будут выглядеть сегодня примерно так.
Трёхмерные игры
| 1 ядро | 2 ядра | 3 ядра | 4 ядра | ||||
| STALKER: Clear Sky ↑ | 45,2 | 53,9 | +19% | 54,4 | +1% | 54,4 | 0 |
| Devil May Cry 4 ↑ | 132 | 202 | +53% | 202 | 0 | 202 | 0 |
| Far Cry 2 ↑ | 17,6 | 33,3 | +89% | 36,6 | +10% | 41,1 | +12% |
| Unreal Tournament 3 ↑ | 61 | 106 | +74% | 127 | +20% | 133 | +5% |
| Crysis: Warhead ↑ | 26,5 | 43,4 | +64% | 47,4 | +9% | 47,4 | 0 |
| World in Conflict ↑ | 17,4 | 25,8 | +48% | 33,6 | +30% | 40,4 | +20% |
| Grand Theft Auto 4 ↑ | 9 | 37,1 | +312% | 54,9 | +48% | 60,8 | +11% |
| Left 4 Dead ↑ | 67 | 114 | +70% | 128 | +12% | 120 | -6% |
Первая диаграмма сразу привлекает наш взгляд знакомым «горбом» в районе результатов двухъядерной системы. Да, так оно и есть: для большинства игровых приложений «многопоточность» тоже означает «двухпоточность». Однако, прежде чем перейти к анализу предпочтений компьютерных игр, давайте для начала разберёмся с одним вопиющим безобразием — с результатами Grand Theft Auto IV.
В данном случае мы скажем чётко и уверенно: ничем, кроме «головотяпства» программистов, такая ситуация объяснена быть не может (нашей ошибкой она, увы, тоже объяснена быть не может — мы перепроверили результаты раз 15). И даже если для немыслимого прироста в 312% (!!!) от включения второго ядра и есть какие-то объективные причины, всё равно — надо же, право слово, как-то тестировать свою продукцию! Или в отделе разработки Rockstar Games просто нет ни одного компьютера с одноядерным процессором*? Похоже на то… К слову, результаты GTA4 мы не включили во вторую диаграмму, так как тогда на ней только эти 312% и были бы хорошо видны.
* — C другой стороны, вспоминая о том, откуда GTA4 пришла на PC, появляется ещё одна гипотеза — спустя рукава, отнеслась к своей работе та группа, которая занималась адаптацией кода. И действительно: программисты, разрабатывающие игры для приставок, не обременены вечной PC-шной борьбой за совместимость со всем и вся — аппаратная конфигурация приставки неизменна. Тогда, наоборот, «основных» разработчиков следует похвалить за вполне адекватную оптимизацию, позволяющую задействовать ресурсы даже четырёхъядерной системы, но портировщиков — поругать за отсутствие адекватного восприятия реалий платформы, на которую они портировали данную игру.
Что касается остальных игр, то тут всё более-менее понятно и предсказуемо.
- STALKER: Clear Sky звёзд с небес не хватает — явно задействованы только два потока. На второй поток разработчики движка вроде бы собирались «вынести» всю физику… видимо, там её не очень много, судя по результатам.
- Devil May Cry 4 — честный двухпотоковый, честнее не бывает. Но хотя бы второе ядро умеет задействовать более-менее прилично.
- Far Cry 2 — кажется, действительно «много-» (не «двух-») поточная. Но остальные ядра кроме двух основных толком нагрузить не умеет, используя их чисто формально. Аналогичная ситуация наблюдается с Unreal Tournament 3, но ему хотя бы удаётся нагрузить трёхъядерник.
- Crysis: Warhead тоже, по сути «сдувается» после второго ядра.
- Left 4 Dead ведёт себя совсем странно: вполне толерантно относится к третьему ядру и даже пытается его как-то задействовать, а после включения четвертого реагирует падением производительности. Не исключено, что это тоже следствие какой-то ошибки программистов.
- А сияет яркой звездой на небосводе параллелизма одна-единственная (причём, заметим, не такая и новая) игра: World in Conflict. Ей единственной удалось получить с четвертого ядра +20% производительности при 33 теоретически возможных, каковой результат и для «серьёзного» ПО можно считать весьма неплохим, а уж для компьютерной игры — шикарным.
Заключение
Общая температура по больнице демонстрирует нам результат, на редкость, «круглый», но от этого ещё более неожиданный: в среднем, чтобы достичь идеальной производительности двухъядерника… в реальности, нам понадобился четырёхъядерник. Однако давайте разбавим нашу общую картину некоторым количеством деталей. Например, какова средняя загрузка процессора при исполнении всех задач, используемых в нашей методике тестирования? Понятно, что для одноядерной системы она равна 100% — если работа есть, то нет вариантов, кто будет её выполнять, а кто простаивать. В системе с большим количеством ядер варианты уже есть: если задача не может создать более одного активного потока — второе ядро будет простаивать. Таким образом, для данного случая общую загрузку всего CPU можно принять равной 50%. Однако отвлечёмся от теории и перейдём к практике. Такова средняя загрузка процессора на 1- 2- 3- и 4-ядерной системе при выполнении тестов, входящих в нашу методику тестирования.
Как видите, результат очень хорошо «бьётся» с выводами из первой диаграммы: средняя загрузка 4-ядерной системы находится в районе 50%, то есть в среднем, половина ядер не работает. Каким бы ещё вопросом задаться? Давайте зададимся таким: на сколько процентов, в среднем, повысится производительность системы, если к ней добавить ещё одно процессорное ядро? Смотрим на диаграмму…
Итак: если к одному ядру мы добавим второе — средняя производительность системы возрастёт на 56%. Хорошая, «серьёзная» величина. А что если к двум ядрам добавить третье? Увы — по отношению к двухъядерной системе, производительность у трёхъядерной будет всего на 18% выше. Уже намного более скромный результат. А добавление четвертого ядра приносит и вовсе смешные дивиденды в виде 12% прибавки. Тем более: мы-то с вами знаем, что «вытянуть» хотя бы такой прирост удалось за счёт весьма небольшого количества приложений, умеющих эффективно утилизировать четвёртое ядро — а остальные за их счёт в этом балле «едут пассажирами», не умея его задействовать практически никак.
Что мы наблюдаем в итоге? Результаты тестирования совершенно однозначно свидетельствуют о том, что двухъядерность на сегодня вполне состоялась в качестве способа сравнительно легко и эффективно повысить быстродействие компьютерной системы: её хорошо принимает даже вполне «домашнее» по ориентации программное обеспечение, и уже достаточно трудно найти программу, которая бы напрочь игнорировала наличие в системе второго ядра. К слову, похоже, что немалую лепту в формирование данной ситуации внесла ОС Microsoft Windows Vista, которая вполне способна «нагрузить» своими фоновыми сервисами отдельно взятое ядро — пусть и не на 100%, но настолько, чтобы польза от второго была ощутима даже в том случае, когда конкретное приложение эффективно использовать многоядерность практически неспособно.
Трёхъядерность (на данный момент, являющаяся «фирменной фишкой» компании AMD), вызывает несколько противоречивые ощущения: не все программы способны адекватно воспринимать наличие в системе количества ядер, не кратного степеням двойки, и не все способны задействовать этот «альтернативный» потенциал. С другой стороны, явного вреда от трёх ядер, по сравнению с двумя, практически не наблюдается, а корректно написанное ПО вполне адекватно реагирует на появление ещё одного ядра, и способно его задействовать. Таким образом, если принять за данность, что одноядерники сейчас уже однозначно уходят в сферу low-end, а двухъядерники позиционируются как разумное решение для среднего класса — трёхъядерники можно позиционировать как решение для «умеренно-оптимистичных энтузиастов»: вроде бы кое-где быстрее, и к тому же достаточно недорого стоит.
Четырёхъядерники, как по соотношению количества ядер к эффективности, так и по соотношению эффективности к цене — по-прежнему, являются решением для профессионалов, чётко понимающих, какие задачи они будут решать с помощью данных процессоров, и уверенных в том, что четвёртое ядро будет востребовано этими задачами. Для рядового пользователя они остаются либо предметом престижа, либо просто неразумным приобретением, сделанным под давлением агрессивного «многоядерного маркетинга» производителей процессоров.
Такие выводы позволяет нам сделать сегодняшнее тестирование. Разумеется, мы не исключаем полностью того варианта, что исследование влияния количества ядер на производительность, проведенное на базе другой архитектуры (Intel Core i7), скорректирует их в ту или иную сторону. Однако такой шанс нами расценивается как весьма маловероятный.
Следующая часть серии тоже будет посвящена особенностям систем на базе AMD Phenom II. В ней мы исследуем вопросы влияния на производительность подсистемы памяти и настроек встроенного контроллера.
Следующая статья серии: AMD Phenom II, подсистема памяти
Процессор AMD Phenom II X4 940 Black Edition предоставлен компанией Ulmart



{kind=link}
{kind=link}
{kind=link}
{kind=link}