Конец эпохи анонимности: нейросети научились вычислять пользователей интернета с точностью 90%
Специалисты в области кибербезопасности и компьютерной лингвистики из Швейцарской высшей технической школы Цюриха (ETH Zurich), MATS Research и компании Anthropic опубликовали на сервере препринтов arXiv отчет под названием «Large-scale online deanonymization with LLMs», демонстрирующий критическую уязвимость концепции сетевой анонимности. Согласно представленным данным, большие языковые модели способны деанонимизировать пользователей интернета в промышленных масштабах, достигая точности до 90% при охвате десятков тысяч профилей.

В основе метода лежит четырехэтапный конвейер ESRC (Extract, Search, Reason, Calibrate). На первом этапе LLM анализирует массив неструктурированного текста (публикации, комментарии) и извлекает косвенные идентификационные маркеры: стиль письма, демографические характеристики, случайные упоминания локаций и профессиональные термины. Далее система переводит эти данные в семантические векторы (эмбеддинги), ищет совпадения в пуле кандидатов, проводит логическую верификацию найденных связей и выполняет калибровку для контроля процента ложных срабатываний.
В ходе эксперимента алгоритм сопоставлял обезличенные профили пользователей Hacker News с их реальными аккаунтами в LinkedIn. ИИ-агент успешно идентифицировал 67% пользователей при уровне точности 90%. В наборе данных из 89 000 кандидатов алгоритм показал 45,1% совпадений при пороге точности 99%. Классические методы автоматического сопоставления при аналогичных условиях демонстрировали результат на уровне 0,1%.
Стоимость деанонимизации одной цели с использованием коммерческих API составила от 1,00 до 4,00 долларов США.
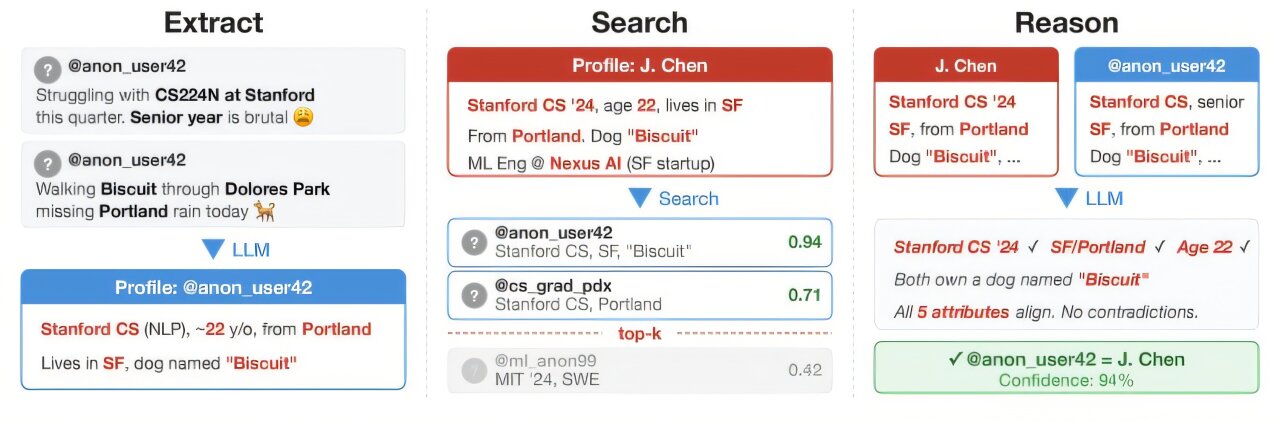
Авторы исследования указывают, что применение LLM нивелирует концепцию «практической неочевидности» (practical obscurity) — состояния, при котором анонимность обеспечивалась высокой стоимостью и технической сложностью ручного сбора разрозненных данных. Тестирование коммерческих фильтров безопасности показало, что ИИ-агенты обходят базовые ограничения с помощью модификации промптов. Разделение процесса на четыре этапа делает запросы похожими на стандартную эксплуатацию алгоритмов, что препятствует выявлению атак на стороне провайдеров ИИ.
В качестве мер противодействия исследователи рекомендуют интернет-платформам внедрять ограничения скорости доступа к данным (rate limits), системы обнаружения скрейпинга и блокировки массового экспорта информации. Исходный код конвейера ESRC и наборы данных не были опубликованы в открытом доступе по соображениям безопасности.
Источник: Techxplore











0 комментариев
Добавить комментарий