Физика разума машины: как геометрия помогает нам понять логику нейросетей
Искусственный интеллект сегодня повсюду — от рекомендаций в вашем смартфоне до сложных научных открытий. В основе большинства этих систем лежат глубокие нейронные сети, которые, подобно человеческому мозгу, обучаются на огромных массивах данных. Но вот парадокс: мы создали эти системы, но зачастую не до конца понимаем, что именно происходит в их цифровых «недрах». Процесс обучения ИИ долгое время оставался «чёрным ящиком» — мы видели результат, но внутренняя логика оставалась туманной.
Что если ключ к разгадке этой тайны лежит не в ещё более сложных алгоритмах, а в простой механике, знакомой нам со школьной скамьи? Недавно группа учёных из Швейцарии и Китая предложила поразительно изящную идею: смоделировать работу сложнейшей нейросети с помощью… обычной цепочки из блоков и пружин. Звучит странно? Возможно. Но именно в этой простоте и кроется гениальность, способная изменить наш подход к созданию и настройке ИИ.

От вешалки до землетрясения: как рождаются научные аналогии
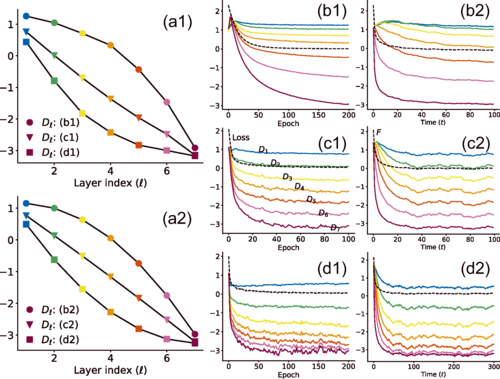
История этого открытия сама по себе похожа на увлекательный детектив. Всё началось с наблюдения за так называемым «законом разделения данных». Учёные заметили, что хорошо обученная нейросеть обрабатывает информацию послойно, и на каждом «этаже» этой структуры данные становятся всё более упорядоченными. Например, если сеть учится отличать кошек от собак, то на каждом новом слое изображения этих животных становятся всё более чётко разделёнными в математическом пространстве. Причём каждый слой вносит примерно одинаковый вклад в это разделение.
Но эта красивая закономерность работала не всегда. Стоило изменить параметры обучения — скорость или уровень «шума» — как гармония нарушалась. Именно эта загадка и натолкнула исследователей на поиск более фундаментального объяснения. И тут, как это часто бывает в науке, помог случай и междисциплинарный опыт.
Один из авторов исследования, Иван Докманич, параллельно занимался геофизикой, где для моделирования землетрясений и движения тектонических плит используются модели из блоков и пружин. Внезапно он увидел поразительное сходство. Рождение аналогии было настолько творческим, что учёные во время отпуска обменивались фотографиями бытовых предметов: складных линеек, раздвижных вешалок, подставок под горячее — пытаясь найти идеальный физический прототип для нейросети. Эта забавная история отлично иллюстрирует, что великие открытия порой рождаются не из сухих формул, а из живой интуиции и умения видеть связи там, где их никто не искал.
Физика «обучения»: что общего у нейросети и цепи из пружин?
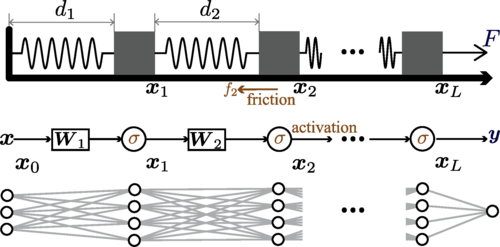
Давайте разберёмся в этой аналогии. Представьте себе несколько деревянных блоков, лежащих на столе и соединённых пружинами. Теперь потянем за крайний блок. Что произойдёт?
- Слои нейросети — это блоки. Каждый блок в нашей цепи — это один слой нейронной сети.
- Процесс разделения данных — это растяжение пружин. Насколько сильно нейросеть «растащила» данные на одном слое, настолько же растянулась пружина между двумя блоками.
- Сложность задачи (нелинейность) — это трение. Если данные очень запутанные и их трудно разделить, это похоже на то, как если бы блоки скользили по шероховатой, липкой поверхности. Сила трения мешает им легко двигаться.
- Шум при обучении — это вибрация. В реальном обучении ИИ всегда есть элемент случайности, или «шума». В нашей модели это эквивалентно тому, что мы начинаем слегка трясти стол. Блоки подпрыгивают, на мгновение отрываясь от поверхности, и трение ослабевает. Это позволяет пружинам перераспределить натяжение и выровняться.
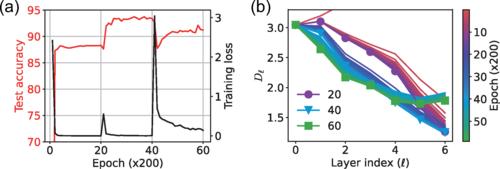
Именно этот последний пункт оказался ключевым. Когда в обучении нейросети есть оптимальный уровень «шума», он, подобно вибрации, помогает всем слоям работать согласованно, и каждый вносит свой равный вклад в разделение данных. Если же шума нет, а задача сложная (высокое трение), то вся нагрузка ложится на последние, «глубокие» слои, в то время как первые почти не работают. Они «застревают», не в силах преодолеть трение.
Карта для «чёрного ящика»: фазовая диаграмма обучения
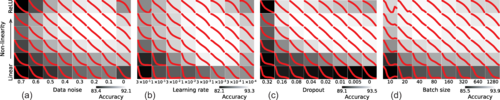
Самое ценное в этом подходе — его предсказательная сила. На основе своей модели учёные смогли построить нечто вроде карты, или фазовой диаграммы, подобной тем, что в физике описывают состояния вещества (лёд, вода, пар). Эта диаграмма наглядно показывает, как будет вести себя нейросеть в зависимости от двух ключевых параметров: уровня нелинейности (трения) и шума (вибрации).
Глядя на эту карту, разработчик может сразу понять, в каком «режиме» работает его модель. Находится ли она в «замороженном» состоянии, где ранние слои бездействуют? Или, может, в ней слишком много «шума», и обучение идёт хаотично? Или же она находится в той самой «золотой середине», где все слои работают слаженно, как хорошо смазанный механизм? Это превращает абстрактную настройку миллиардов параметров в понятный физический процесс.
Практический смысл: зачем инженеру ИИ знать про пружины?
Это исследование — не просто красивое теоретическое упражнение. Оно открывает вполне конкретные практические возможности.
- Диагностика и оптимизация. Представьте, что нейросеть — это мост. Используя эту модель, можно создать «карту напряжений» для ИИ, которая покажет, какие слои «перегружены» (что может вести к переобучению и ошибкам), а какие — «простаивают» (что говорит об избыточности архитектуры). Это позволит точно настраивать даже гигантские модели, вроде больших языковых моделей (LLM).
- Ускорение обучения. Понимая, как шум и сложность влияют на процесс, можно целенаправленно «встряхивать» нейросеть на нужных этапах, чтобы ускорить её сходимость к правильному решению. Это может сэкономить колоссальные вычислительные ресурсы и время.
- Новый путь развития ИИ. Сегодня доминирует подход «законов масштабирования»: чтобы сделать ИИ умнее, мы просто увеличиваем его размер и количество данных. Новый метод предлагает более изящный путь — не бездумно наращивать мощь, а тонко настраивать внутреннюю динамику системы, опираясь на понятные физические принципы.
От интуиции к инструменту: новый взгляд на интеллект машин
Работа Докманича и его коллег — яркий пример того, как фундаментальная наука может дать мощный толчок прикладным технологиям. Она возвращает в мир больших данных и сложных алгоритмов человеческую интуицию. Ведь интуитивно понять, как ведут себя пружинки и кубики, гораздо проще, чем оперировать миллиардами математических параметров.
Это исследование превращает «чёрный ящик» в прозрачный механизм, который можно не только наблюдать, но и целенаправленно конструировать. Возможно, в будущем инженеры ИИ будут говорить не о «скорости обучения», а о «коэффициенте трения», и не о «регуляризации», а о «силе вибрации». И этот новый язык, заимствованный у физики, поможет нам создавать более эффективный, надёжный и, что самое главное, понятный искусственный интеллект.











1 комментарий
Добавить комментарий