Ошибка в процессорах AMD Phenom X4. Влияние «заплатки» AMD на низкоуровневые характеристики процессора и платформы
В нашем основном исследовании архитектуры новых процессоров AMD Phenom X4 мы уже затрагивали тему ошибки, содержащейся в этих процессорах, как утверждают источники, в блоке TLB L3-кэша и способной проявить себя в экспериментальных (а по последним данным — возможно, и в реальных) условиях зависанием системы. Как показали результаты нашего исследования архитектуры процессоров Phenom, данная ошибка не имеет отношения к блокам D-TLB и/или I-TLB первого и второго уровня, расположенным в ядре процессора. Возможно, она действительно затрагивает некоторую область контроллера памяти процессора и/или принадлежащего ему L3-кэша, которую условно можно назвать «TLB» (буфером трансляции виртуальных адресов памяти в физические), хотя существование такой структуры не заявлено в официальной документации на эти процессоры (и, тем более, неизвестны ее технические характеристики). Как бы там ни было, факт существования ошибки и ее значимость подтверждает сама компания AMD, а также производители материнских плат, выпускающие новые версии BIOS, которые содержат «заплатку», способную устранить эту ошибку. К сожалению, ее устранение (по-видимому, заключающееся в отключении этой структуры «TLB»), не является «бесплатным» и приводит к снижению производительности системы примерно на 10-15%. Как показали недавно появившиеся в Сети результаты тестов, применение «заплатки» действительно способно снизить производительность системы в различных реальных приложениях (разброс оказывается весьма существенным, в среднем производительность снижается на 14%). Однако сама идея того, что эта ошибка (и «заплатка», ее устраняющая) может затрагивать ядро процессора, т.е. его исполнительные устройства, кажется весьма и весьма маловероятной. Скорее всего, производительность системы в целом снижается за счет ухудшения скоростных характеристик подсистемы памяти и/или L3-кэша контроллера памяти процессора. Чтобы показать, что это действительно так, и как именно изменяются характеристики указанных подсистем при включении «заплатки», мы решили сопоставить низкоуровневые характеристики платформы AMD Phenom X4 с теми, что мы получили ранее, без использования «заплатки».
Конфигурация тестовых стендов
Стенд №1 (без «заплатки»)
- Процессор: AMD Phenom X4 9700 (инженерный образец, CPUID 100F22h, ядро Barcelona rev. B2, частота CPU 2,4 ГГц, частота NB 2,0 ГГц)
- Чипсет: AMD 790FX
- Материнская плата: MSI K9A2 Platinum, версия BIOS V1.1B3 от 16.11.2007
- Память: 2x1 ГБ Corsair XMS2-6400 DDR2-800, тайминги 5-5-5-18, ganged mode
Стенд №2 (с «заплаткой»)
- Процессор: AMD Phenom X4 9700 (инженерный образец, CPUID 100F22h, ядро Barcelona rev. B2, частота CPU 2,4 ГГц, частота NB 2,4 ГГц)
- Чипсет: AMD 790FX
- Материнская плата: Gigabyte MA790GX-DQ6, версия BIOS F3c от 07.12.2007
- Память: 2x1 ГБ Corsair XMS2-6400 DDR2-800, тайминги 5-5-5-18, ganged mode
Реальная пропускная способность кэша данных/памяти
Прежде всего заметим, что приведенные в настоящем исследовании абсолютные результаты тестов платформы AMD Phenom X4 с «заплаткой» могут несколько отличаться от тех, что были получены ранее (без «заплатки») ввиду использования разных материнских плат (см. конфигурацию тестовых стендов). В частности, на момент исследования первой системы (стенд №1, материнская плата MSI K9A2 Platinum) не было известно, какая именно частота северного моста и L3-кэша процессора выставляется по умолчанию на этой системе. На рассматриваемой в настоящей статье второй системе (стенд №2, материнская плата Gigabyte MA790GX-DQ6) утилита AMD Overdrive показала, частота контроллера памяти и L3-кэша процессора по умолчанию устанавливается равной 2.0 ГГц при частоте ядер процессора 2.4 ГГц. Разумно предполагать, что такой же режим «по умолчанию» используется и на первой из исследованных нами материнских плат. В настоящем же исследовании мы увеличили частоту северного моста процессора до 2.4 ГГц вручную с помощью настроек BIOS Setup для обеспечения синхронности функционирования ядер процессора и его интегрированного контроллера памяти, и сравнения такого режима работы процессора с режимом работы «по умолчанию» (CPU 2.4 ГГц, NB 2.0 ГГц).
Результаты измерения пропускной способности (ПС) кэшей данных процессора и оперативной памяти приведены в табл. 1.
Таблица 1
| Уровень | Средняя реальная пропускная способность, байт/такт | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| L1, чтение, MMX L1, чтение, SSE2 L1, запись, MMX L1, запись, SSE2 | 15.69 31.69 7.98 15.67 | 15.69 31.69 7.98 15.67 |
| L2, чтение, MMX L2, чтение, SSE2 L2, запись, MMX L2, запись, SSE2 | 7.66 7.98 4.94 5.10 | 7.66 7.98 4.94 5.10 |
| L3, чтение, MMX L3, чтение, SSE2 L3, запись, MMX L3, запись, SSE2 | 3.69 3.71 3.38 3.38 | 3.97 4.02 3.74 3.76 |
| RAM*, чтение (SSE2) RAM, запись (SSE2) | 6.38 ГБ/с (49.9%) 3.49 ГБ/с (27.3%) | 5.23 ГБ/с (40.9%) 3.43 ГБ/с (26.8%) |
*в скобках указаны значения относительно теоретического предела ПС шины памяти
Как и следовало ожидать, скоростные характеристики L1- и L2-кэшей данных ядра процессора при использовании «заплатки» не изменяются. Скоростные характеристики L3-кэша на второй системе несколько возрастают (на 8-11%), тогда как скоростные характеристики подсистемы памяти заметно снижаются (в особенности, ПСП на чтение, примерно на 18%). Уже из результатов этого теста можно сделать предварительный вывод о том, что применение «заплатки» не оказывает существенного влияния на L3-кэш процессора (при этом его ПС увеличивается в связи с увеличением его частоты с 2.0 до 2.4 ГГц, хотя прирост ПС оказывается меньше по сравнению с 20% приростом частоты), но влияет на ПСП (несмотря на увеличение тактовой частоты контроллера памяти). Справедливость утверждения об отсутствии влияния «заплатки» на характеристики L3-кэша подтвердится дальнейшими тестами.
Предельная реальная пропускная способность памяти
Предельные характеристики реальной ПСП, приведенные в табл. 2, в случае применения «заплатки» также оказываются ниже: максимальная реальная ПСП на чтение снижается на 19.5%, на запись — примерно на 4.5%.
Таблица 2
| Операция | Максимальная реальная ПСП, ГБ/с* | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| Чтение, Software Prefetch | 7.49 (58.5%) | 6.03 (47.1%) |
| Запись, Non-Temporal Store | 4.99 (39.0%) | 4.82 (37.7%) |
*в скобках указаны значения относительно теоретического предела ПС шины памяти
Средняя латентность кэша данных/памяти
Перейдем к тестам латентности кэша данных процессора и оперативной памяти, способным показать эффект от «заплатки» уже на качественном уровне (рис. 1).
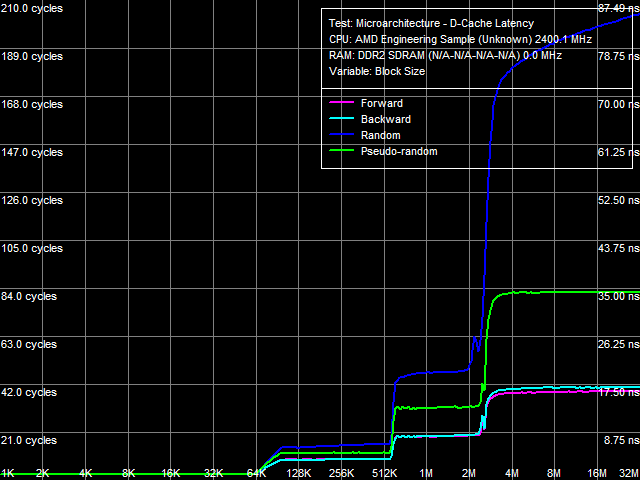
Рис. 1. Средняя латентность кэша данных и памяти
А именно, эффект проявляется в виде резкого и существенного возрастания латентности случайного доступа, начиная с 2-МБ размера блока, в точности соответствующего исчерпанию объема L2 D-TLB ядра процессора. Следовательно, этот тест косвенно подтверждает значительное возрастание штрафа промаха L2 D-TLB, которое мы увидим ниже в специализированном тесте D-TLB.
Таблица 3
| Уровень, режим доступа | Средняя латентность, тактов (нс) | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| L1-кэш, во всех случаях | 3.0 | 3.0 |
| L2-кэш, прямой L2-кэш, обратный L2-кэш, псевдослучайный L2-кэш, случайный* | ~9.2 ~9.0 ~12.1 ~14.5 | ~9.3 ~9.3 ~12.2 ~14.6 |
| L3-кэш, прямой L3-кэш, обратный L3-кэш, псевдослучайный L3-кэш, случайный* | ~19.4 ~19.5 ~31.9 ~47.5 | ~18.2 ~18.7 ~31.7 ~48.3 |
| RAM, прямой RAM, обратный RAM, псевдослучайный RAM, случайный* | 16.2 нс 17.0 нс 34.4 нс 85.3 нс | 18.2 нс 18.6 нс 39.0 нс 225.8 нс |
*размер блока 32 МБ
Количественные характеристики латентности L1-, L2- и L3-кэшей, представленные в табл. 3, демонстрируют практически полную неизменность при применении «заплатки», что вновь подтверждает отсутствие влияния «заплатки» на L3-кэш процессора. А возросшие величины латентности памяти (примерно на 13% при псевдослучайном доступе, и более чем в 2.6 раз(!) при случайном доступе) свидетельствуют о значительном ухудшении скоростных характеристик последней в условии промаха L2 D-TLB ядра процессора (т.е. в том случае, когда эти промахи должны «маскироваться» недокументированной структурой «TLB» контроллера памяти процессора, отключенной при применении «заплатки»).
Минимальная латентность кэша данных и памяти
Выводы, сделанные относительно значений средней латентности кэша данных и памяти, можно полностью распространить и на случай минимальных значений латентности, представленных в табл. 4. Характерно отметить некоторое снижение эффективности аппаратной предвыборки, проявляющееся в увеличении латентности памяти при прямом и обратном обходе при применении «заплатки», хотя это и нельзя считать прямым следствием отключения «TLB» контроллера памяти процессора.
Таблица 4
| Уровень, режим доступа | Минимальная латентность, тактов (нс) | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| L1-кэш, во всех случаях | 3.0 | 3.0 |
| L2-кэш, прямой L2-кэш, обратный L2-кэш, псевдослучайный L2-кэш, случайный* | ~3.3 (3.0**) ~3.3 (3.0**) ~8.2 (3.0**) ~11.3 (12.0**) | ~3.2 (3.0**) ~3.3 (3.0**) ~8.2 (3.0**) ~11.2 (12.0**) |
| L3-кэш, прямой L3-кэш, обратный L3-кэш, псевдослучайный L3-кэш, случайный* | ~5.0 (3.0**) ~5.5 (3.0**) ~28.2 (3.0**) ~46.7 (48.0**) | ~5.0 (3.0**) ~5.6 (3.0**) ~27.6 (3.0**) ~46.9 (48.0**) |
| RAM, прямой RAM, обратный RAM, псевдослучайный RAM, случайный* | 4.6 нс 5.4 нс 33.9 нс 84.6 нс | 7.0 нс 7.6 нс 38.5 нс 225.8 нс |
*размер блока 32 МБ
**в скобках указаны значения, полученные методом №2
Ассоциативность кэша данных
Результат измерения ассоциативности L1-, L2- и L3-кэша данных (рис. 2) не имеет отличий с точки зрения самих значений ассоциативности кэша, но отличается существенным штрафом «промаха по ассоциативности» всех уровней кэша, наблюдающегося при использовании более 48 сегментов кэша. Этот эффект, очевидно, является родственным эффекту промаха L2 D-TLB, когда латентности обращения к памяти должны маскироваться TLB контроллера памяти.
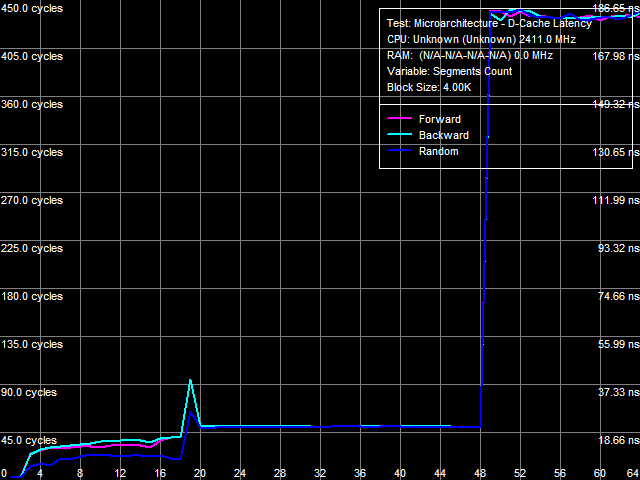
Рис. 2. Ассоциативность кэша данных
Реальная пропускная способность шины L1-L2 кэша
Как и средняя реальная ПС L2-кэша, реальная ПС шины L1-L2 (см. табл. 5) также не претерпевает изменений при использовании «заплатки».
Таблица 5
| Режим доступа | Реальная пропускная способность L1-L2, байт/такт | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 7.98 7.99 4.71 4.67 | 7.99 7.99 4.73 4.67 |
Реальная пропускная способность шины L2-L3 кэша
Что касается реальной ПС шины L2(ядро процессора)-L3(контроллер памяти), ее скоростные характеристики (см. табл. 6), как и измеренная ранее ПС L3-кэша, на рассматриваемой системе оказываются несколько выше (примерно на 8%) в связи с более высокой частотой контроллера памяти процессора (2.4 против 2.0 ГГц).
Таблица 6
| Режим доступа | Реальная пропускная способность L2-L3, байт/такт | |
|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 3.73 3.73 3.46 3.46 | 4.03 4.03 3.68 3.68 |
Кэш инструкций, реальная пропускная способность декодирования/исполнения кода
Очевидно отсутствие влияния «заплатки» и на скорость декодирования/исполнения инструкций из L1-I, а также L2-кэша ядра процессора (см. табл. 7). В то же время, скорость исполнения кода из L3-кэша вновь возрастает (примерно на те же 8%, что и ПС L3-кэша) в связи с увеличением частоты последнего с 2.0 до 2.4 ГГц.
Таблица 7
| Тип инструкций (размер, байт) | Реальная пропускная способность декодирования / исполнения, байт/такт (инструкций/такт) | |||||
|---|---|---|---|---|---|---|
| Phenom X4 без «заплатки» | Phenom X4 с «заплаткой» | |||||
| L1-I кэш | L2 кэш | L3 кэш | L1-I кэш | L2 кэш | L3 кэш | |
| NOP (1) | 3.00 (3.00) | 3.00 (3.00) | 1.88 (1.88) | 3.00 (3.00) | 3.00 (3.00) | 1.88 (1.88) |
| SUB (2) XOR (2) TEST (2) XOR/ADD (2) CMP 1 (2) | 6.00 (3.00) | 3.78 (1.89) | 1.99 (0.99) | 6.00 (3.00) | 3.78 (1.89) | 2.15 (1.08) |
| CMP 2 (4) | 11.99 (3.00) | 3.78 (0.95) | 1.99 (0.50) | 11.99 (3.00) | 3.78 (0.95) | 2.15 (0.54) |
| CMP 3-6 (6) | 17.97 (3.00) | 3.78 (0.63) | 1.99 (0.33) | 17.97 (3.00) | 3.78 (0.63) | 2.15 (0.36) |
| Prefixed CMP 1-4 (8) | 23.22 (2.90) | 3.78 (0.47) | 1.99 (0.25) | 23.22 (2.90) | 3.78 (0.47) | 2.15 (0.27) |
Ассоциативность кэша инструкций
Тест ассоциативности кэша инструкций (рис. 3) показывает довольно интересную картину. А именно, на ней исчезает выявленный в предыдущей серии тестов (без «заплатки») второй перегиб ассоциативности L3-кэша в области примерно 50 сегментов кэша. В то же время, как и в тесте ассоциативности кэша данных, значительно возрастает штраф «промаха по ассоциативности» последнего уровня кэша процессора. Отсюда можно сделать вывод о том, что эффективная ассоциативность L3-кэша при кэшировании кода равняется 14 (32 за вычетом 18), а ранее наблюдаемый второй перегиб в области 50 сегментов является артефактом.
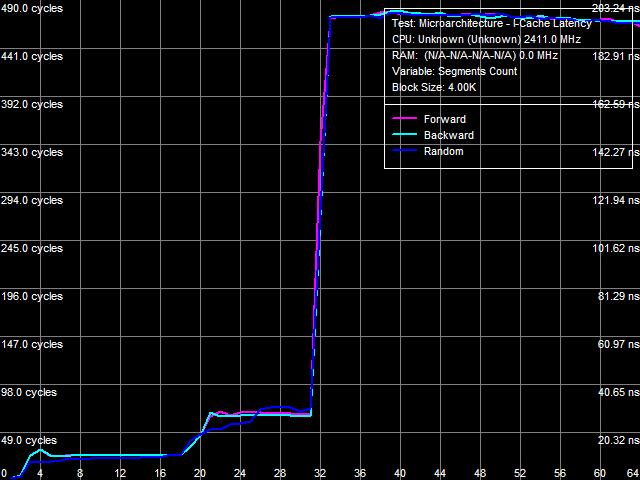
Рис. 3. Ассоциативность кэша данных
Характеристики TLB
Как и следовало ожидать, наибольший эффект от включения «заплатки» демонстрируют тесты TLB процессора. Естественно, при этом сами характеристики TLB никак не изменяются (поскольку эти элементы архитектуры относятся к ядру процессора), но существенно возрастает штраф промаха последнего уровня TLB как «по размеру», так и «по ассоциативности».
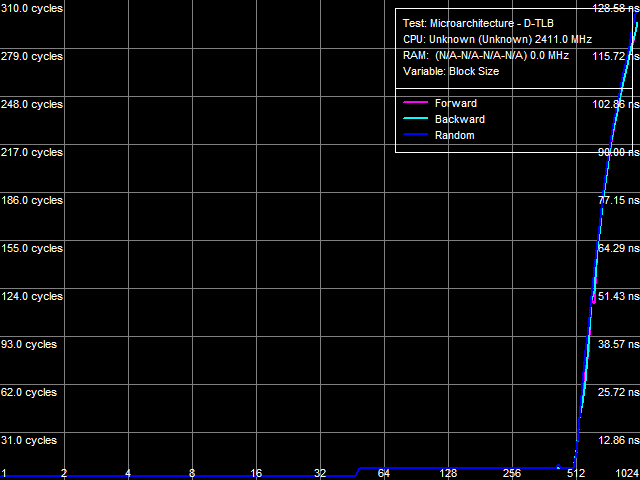
Рис. 4. Размер D-TLB
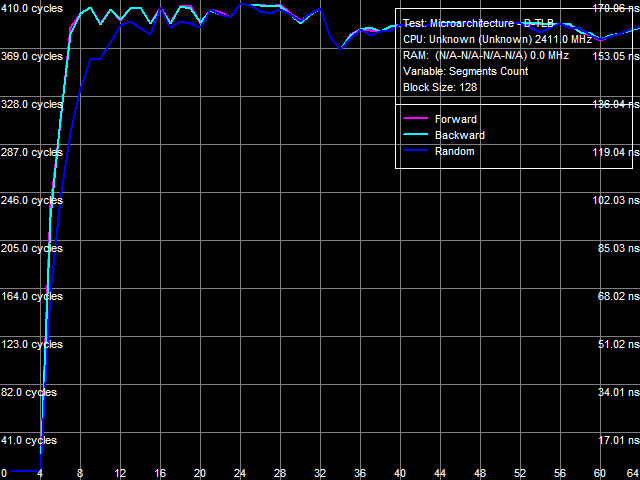
Рис. 5. Ассоциативность L2 D-TLB
На рис. 4 представлен результат теста размера D-TLB, а на рис. 5 — тест ассоциативности L2 D-TLB. В обоих случаях налицо существенное возрастания штрафа промаха L2 D-TLB — примерно 290 тактов при исчерпании его объема и до 400 тактов при исчерпании его ассоциативности.
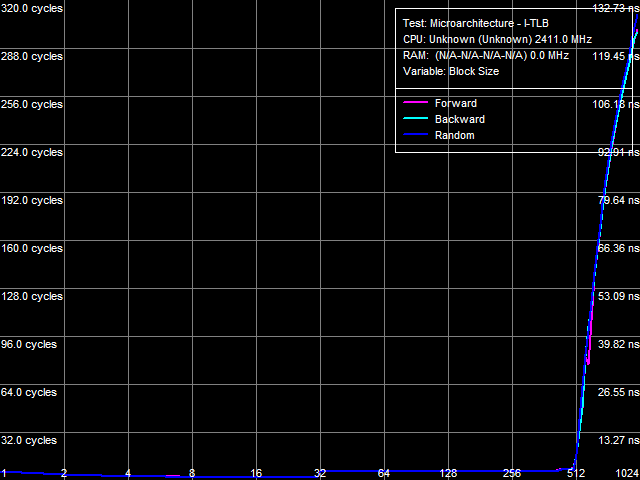
Рис. 6. Размер I-TLB
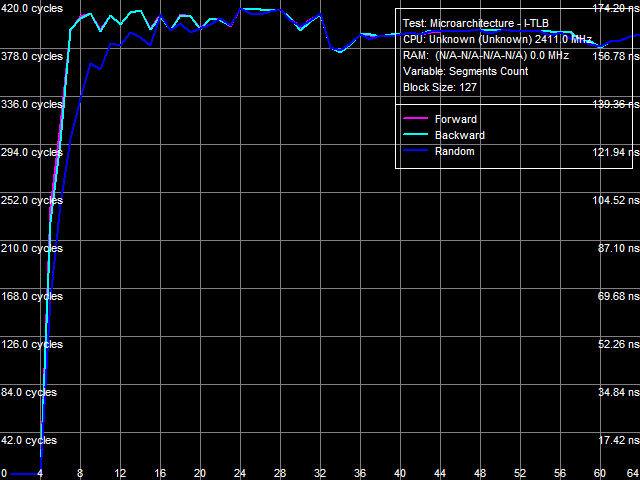
Рис. 7. Ассоциативность L2 I-TLB
Аналогичный результат показывают тесты размера (рис. 6) и ассоциативности (рис. 7) I-TLB. Штраф промаха L2 I-TLB «по размеру» составляет примерно 300 тактов, а «по ассоциативности» — порядка 400 тактов, что близко к соответствующим величинам, полученным в тестах D-TLB.
Выводы
Какие же выводы можно сделать из результатов проделанного исследования? Прежде всего, очевиден и важен вывод о том, что процессоры семейства AMD Phenom (K10), а также AMD Athlon 64 (K8) действительно содержат в своем интегрированном контроллере памяти некую структуру, которую можно считать буфером TLB достаточно большого размера, эффективном как при обращении к данным (D-TLB), так и при исполнении кода (I-TLB). Существование этой структуры в обоих семействах процессоров доказывается умеренным порядком величин штрафа промаха последнего уровня (L2) D-TLB и I-TLB ядра процессора, находящихся в пределах 20-40 тактов. В то же время, ее отключение (а это — наиболее разумное объяснение того, как действует «заплатка» для процессоров AMD Phenom) приводит к существенному возрастанию рассмотренных величин штрафа промаха (до 300-400 тактов, т.е. практически на порядок!). В этой связи интересно также упомянуть «энергоэффективные» процессоры AMD Athlon 64 X2 EE, в которых штраф промаха L2 D-TLB и I-TLB изначально является высоким. Можно предположить, что в этих процессорах структура «TLB» контроллера памяти либо отсутствует вовсе (что маловероятно, ибо нельзя сказать, что она настолько сложна в реализации и потребляет так много энергии, что ее потребовалось совсем исключить из «энергоэффективных» вариантов процессоров), либо… отключена изначально вследствие наличия ошибки, сходной с ошибкой в контроллере памяти процессоров Phenom (что намного более вероятно).
Следующий вывод, который можно сделать по результатам нашего исследования, заключается в том, что упомянутая выше структура «TLB» относится именно к контроллеру памяти процессора, а не его L3-кэшу (о чем писалось в ранних сообщениях об ошибке в процессорах Phenom). Это подтверждается практически полным отсутствием негативного влияния «заплатки» на скоростные характеристики (ПС и латентность) L3-кэша процессора. Таким образом, снижение производительности системы в целом при применении «заплатки» объясняется исключительно снижением скоростных характеристик подсистемы памяти и, в особенности, существенным возрастанием латентности случайного доступа к памяти. Для удобства, представим их в сводной таблице.
| Характеристика | Значение без «заплатки» | Значение с «заплаткой» | Изменение |
|---|---|---|---|
| Средняя ПСП на чтение | 6.38 ГБ/с | 5.23 ГБ/с | -18.0% |
| Средняя ПСП на запись | 3.49 ГБ/с | 3.43 ГБ/с | -1.7% |
| Максимальная ПСП на чтение | 7.49 ГБ/с | 6.03 ГБ/с | -19.5% |
| Максимальная ПСП на запись | 4.99 ГБ/с | 4.82 ГБ/с | -3.4% |
| Средняя латентность памяти, псевдослучайный доступ | 34.4 нс | 39.0 нс | +13.4% |
| Средняя латентность памяти, случайный доступ | 85.3 нс | 225.8 нс | +164.7% |
| Штраф промаха L2 D-TLB по размеру | 28 тактов | 290 тактов | 10.4 раз |
| Штраф промаха L2 D-TLB по ассоциативности | 34 такта | 400 тактов | 11.8 раз |
| Штраф промаха L2 I-TLB по размеру | 30 тактов | 300 тактов | 10.0 раз |
| Штраф промаха L2 I-TLB по ассоциативности | 36 тактов | 400 тактов | 11.1 раз |
Идея привести некую усредненную величину эффекта «заплатки» по столь разрозненным низкоуровневым характеристикам представляется довольно бессмысленной — разброс значений составляет от 1.7% до 11.8 раз, а сами эффекты (например, возрастание штрафов промаха TLB) не проявляют себя столь же значительным образом в реальных приложениях ввиду исключительной «синтетичности» самих характеристик. В то же время, в общую группу можно выделить снижение скоростных характеристик подсистемы памяти (18-20%), достаточно близких к реальности, которое оказывается сопоставимым со снижением производительности системы в большинстве реальных приложений, оперирующих с данными скорее «поточным», нежели «случайным» образом. При случайном же доступе к данным можно ожидать и большего снижения производительности системы в целом, поскольку латентность доступа к памяти в таком режиме возрастает весьма ощутимо.
Комментарии