Новая вычислительная архитектура
Содержание
- Вычислительный ускоритель Tesla V100
- Ключевые особенности Tesla V100
- Аппаратная архитектура GV100
- Потоковый мультипроцессор Volta
- Тензорные ядра
- Улучшенные кэширование и разделяемая память
- Независимое управление потоками
- CUDA 9 и новые вычислительные возможности
- Оценка производительности
- Выводы

На своей традиционной конференции GTC 2017, прошедшей в прошлом месяце, компания Nvidia традиционно же представила новую вычислительную архитектуру, ранее известную под кодовым именем Volta. Компания уже много лет занимается далеко не только рынком игровых графических процессоров, успешно участвуя и в других сферах: профессиональных графических и вычислительных решениях, высокопроизводительных вычислениях и автомобильных системах.
Более того, по финансовым отчетам компании на протяжении нескольких кварталов хорошо видно, что хотя игровые решения остаются лидирующими и важнейшими для Nvidia, доходы от поставок в сфере автомобильных решений и сегмента высокопроизводительных вычислений (серверов, дата-центров и т. д.) выросли в несколько раз. Поэтому совершенно неудивительно, что компания вкладывает всё бо́льшие средства в развитие решений, предназначенных именно для неграфических вычислений. Ну, и игрокам от этого тоже некоторая польза есть — если несколько лет назад улучшения в GPU оплачивали в основном они, то теперь к этому добавилась нехилая доля от более серьезных применений.
Высокопроизводительные вычисления сейчас касаются, в первую очередь, различных применений искусственного интеллекта. И эти системы жаждут многократного прироста скорости вычислений каждый год. Нейросети и другие системы искусственного интеллекта, которым раньше не хватало вычислительной производительности, проникают во все больший спектр применений: автономное управление автомобилями, распознавание речи и умный поиск, распознавание объектов и их описание, борьба с болезнями и старением человека и многое другое. Если вам интересны практические применения ИИ в настоящем и будущем, то об этом можно прочитать в отчете с конференции GTC 2017.
По мнению аналитиков, развитие технологий на основе искусственного интеллекта через пять лет принесет индустрии в несколько раз больше доходов, чем сейчас. И, скорее всего, через несколько лет Nvidia будет получать с вычислительных применений уже больше денег, чем с развлекательных. Именно для этого они сейчас и работают активно в этой сфере, и уже имеют на рынке неплохие позиции с еще бо́льшим потенциалом. Nvidia одной из первых занялась высокопроизводительными вычислениями, основанными на процессорах, ранее известных, как графические, и они предлагают рынку отличное аппаратное и программное обеспечение, поддерживая крепкие связи с разработчиками.
В рамках этой статьи для нас особенно важно то, что у Nvidia вполне уже есть мотивация делать отдельные GPU для вычислений, и отдельные GPU для игр, как это и происходит уже некоторое время. Хотя графические и вычислительные процессоры Nvidia одного поколения архитектурно весьма близки и во многом похожи, в них есть уже и важные отличия, уникальные именно для конкретных применений — достаточно вспомнить HBM2-память, применяемую в ускорителе вычислений семейства Pascal, или заметно большее количество блоков для FP64-вычислений.
Возможности и мощность современных вычислительных систем растут, и особенные задачи сейчас перед ними ставит развитие нейронных сетей. Если раньше это было слишком дорого или вообще невозможно для многих компаний, то сейчас глубокое обучение и нейронные сети для решения актуальных задач могут позволить себе даже небольшие компании. Именно ускорение задач глубокого обучения и наложило свой отпечаток на новую вычислительную архитектуру Volta, которую мы сегодня подробно рассмотрим.
Вычислительный ускоритель Tesla V100
Высокопроизводительные вычисления (High Performance Computing, или HPC) являются основой для современной науки и применяются во множестве сфер деятельности: прогнозирование погоды, поиск нефтяных и газовых месторождений, разработка новых лекарств и т. д. — исследователи используют высокопроизводительные вычислительные системы для имитации окружающего мира и прогнозирования событий в нем.
Искусственный интеллект и нейросети расширяют традиционные применения HPC, позволяя анализировать большие объемы данных и быстро обучать ИИ, а симуляция не всегда может точно предсказать события в реальном мире. Решение усложняющихся задач искусственного интеллекта требует обучения все более сложных нейросетей, что занимает на существующих вычислительных системах очень большое количество времени. Сложность задач, поставленных перед ускорителями вычислений, постоянно растет, каждый год требуя большей производительности, и с этим одни CPU уже давно не справляются.
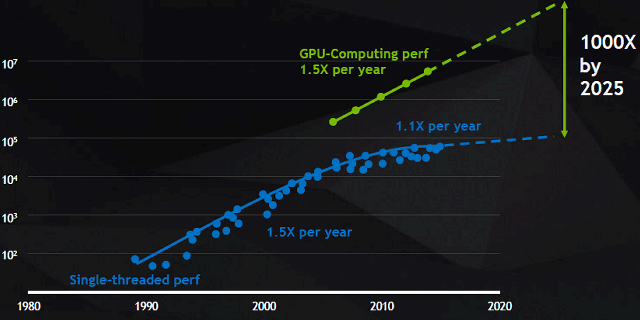
Индустрии высокопроизводительных вычислений сейчас понадобился даже еще больший скачок, чем привычные 1,5 раза ускорения в год. Также на всю индустрию повлияло и появление специализированных решений для машинного обучения, вроде Tensor Processing Unit (TPU) от Google, вторая версия которого была объявлена недавно. Вот и Nvidia решила не отставать, представив новое поколение вычислительной архитектуры Volta, в которое вошли специализированные блоки, обеспечивающие многократное преимущество по скорости в задачах глубокого обучения, по сравнению с Pascal.
Для традиционных вычислительных HPC-задач и новых сфер с применением искусственного интеллекта, компания Nvidia выпустила новый вычислительный ускоритель Tesla V100, основанный на новом графическом (чисто номинально, так как он предназначен для далеко не только и не столько графических вычислений) чипе GV100. Интересно, что электрически и физически новый чип совместим со старым — это сделано для ускорения производства и внедрения новинки, ведь можно использовать те же системные платы, системы питания и так далее.

На фото выше показан вычислительный ускоритель Tesla V100, основанный на чипе GV100 — первенце архитектуры Volta и выполненный в форм-факторе SXM2, точно таком же, что и уже известный нам ускоритель Tesla P100 на основе Pascal GP100. На момент своего анонса это — наиболее высокопроизводительный параллельный процессор в мире, отличающийся высокой вычислительной производительностью как для типичных HPC-применений, так и для задач глубокого обучения (deep learning), требующих специфической обработки очень больших массивов данных.
Кроме этого, в первом GPU архитектуры Volta применяется 16 ГБ высокоскоростной HBM2-памяти, разработанной совместно с Samsung, имеющей пропускную способность в ПСП 900 ГБ/с — на 50% выше, по сравнению с предыдущим поколением. А для связи между графическими процессорами и между графическим и центральным процессорами, применяется высокоскоростной интерфейс NVLink нового поколения, отличающийся вдвое увеличенной пропускной способностью по сравнению с предыдущим решением — 300 ГБ/с.
Ключевые особенности Tesla V100
- Новый дизайн потокового мультипроцессора (Streaming Multiprocessor — SM), оптимизированный в том числе для задач глубокого обучения — в архитектуре Volta мультипроцессор SM был серьезно переделан, став на 50% более энергоэффективным, по сравнению с дизайном мультипроцессора Pascal. Серьезные архитектурные изменения позволили повысить производительность FP32- и FP64-вычислений при том же уровне энергопотребления, что является важнейшей задачей любого производителя чипов. Новые тензорные ядра (Tensor Cores), разработанные специально для тренировки и инференса нейросетей в задачах глубокого обучения (deep learning) способны дать превосходство в скорости вплоть до 12-кратного (при тренировке нейросети и вычислениях смешанной точности). Обладая независимыми параллельными потоками данных для целочисленных вычислений и вычислений с плавающей запятой, мультипроцессор Volta также намного более эффективен при смешанной загрузке с использованием вычислительных и других операций. Новая возможность независимого управления потоками в Volta позволяет тонко синхронизировать и обеспечивать взаимодействие между параллельными потоками. Ну а новая объединенная подсистема кэширования данных первого уровня (L1-кэш) и разделяемой памяти (Shared Memory) значительно повышает производительность в некоторых задачах, заодно упрощая и их программирование.
- Поддержка второго поколения технологии высокоскоростных соединений NVLink позволяет увеличить пропускную способность, обеспечить большее число линий данных и улучшить масштабируемость для систем с несколькими GPU и CPU. Новый процессор GV100 поддерживает до шести 25 ГБ/с каналов NVLink, что дает общую пропускную способность в 300 ГБ/с. Вторая версия NVLink поддерживает также новые возможности серверов, основанных на процессорах IBM Power 9, включая когерентность кэша. Новая версия суперкомпьютера Nvidia DGX-1, основанная на Tesla V100, использует NVLink для обеспечения лучшей масштабируемости и сверхбыстрой тренировки нейросетей в задачах глубокого обучения.
- Высокопроизводительная и эффективная HBM2-память объемом в 16 ГБ обеспечивает пиковую пропускную способность памяти до 900 ГБ/с. Сочетание быстрой памяти второго поколения производства компании Samsung и улучшенного контроллера памяти в GV100, обеспечило полуторакратный прирост в пропускной способности памяти по сравнению с предыдущим чипом GP100 архитектуры Pascal, при этом эффективное использование ПСП новым GPU достигает более чем 95% в реальных рабочих нагрузках.
- Функция Multi-Process Service (MPS) позволяет нескольким процессам использовать совместно один и тот же GPU. В архитектуре Volta осуществляется аппаратное ускорение критических компонентов CUDA MPS-сервера, что позволяет повысить производительность, изоляцию и обеспечить лучшее качество обслуживания (QoS) для множества вычислительных приложений, использующих один GPU. Также в Volta было втрое увеличено максимальное количество клиентов MPS — с 16 для Pascal до 48 для Volta.
- Улучшенная общая память и трансляция адресов — в GV100 общая память использует новые указатели, позволяющие переносить страницы памяти на процессор, который чаще обращается к этим страницам. Это повышает эффективность доступа к диапазонам памяти, разделяемым между разными процессорами. При условии использования платформ IBM Power, новые сервисы преобразования адресов (Address Translation Services — ATS) позволяют графическому процессору напрямую обращаться к страницам CPU.
- Совместные группы и новые API для совместного запуска — совместные группы (Cooperative Groups) это новая программная модель, введенная в CUDA 9 и предназначенная для организации групп связанных потоков. Совместные группы позволяют разработчикам задать гранулярность, с которой потоки обмениваются данными, помогая организовать более эффективные параллельные вычисления. Основная функциональность совместных групп поддерживается на всех графических процессорах компании, начиная с Kepler, но в Pascal была включена поддержка новых Cooperative Launch API, поддерживающих синхронизацию между блоками потоков CUDA, а в Volta была добавлена поддержка новых шаблонов синхронизации (synchronization patterns).
- Режимы максимальной производительности и максимальной энергоэффективности позволяют эффективнее использовать GPU в различных случаях. В режиме максимальной производительности, ускоритель Tesla V100 будет работать без ограничения частоты при потреблении питания до уровня TDP в 300 Вт — этот режим нужен для приложений, требующих наивысшей скорости вычислений и максимальной пропускной способности. Режим максимальной эффективности позволяет настроить энергопотребление ускорителей Tesla V100 так, чтобы получить оптимальную отдачу в пересчете на каждый ватт потребления энергии. При этом можно установить верхнюю планку потребляемой мощности для всех графических процессоров в серверной стойке, снизив энергопотребление при сохранении достаточной производительности.
- Оптимизированное программное обеспечение — новые версии фреймворков глубокого обучения, такие как Caffe2, MXNet, CNTK, TensorFlow и другие могут использовать все возможности Volta для того, чтобы значительно повысить производительность тренировки и снизить время обучения нейросетей. Оптимизированные для Volta библиотеки cuDNN, cuBLAS и TensorRT, способны использовать новые возможности архитектуры Volta для повышения производительности задач глубокого обучения и привычных применений высокопроизводительных вычислений (HPC). Новая версия CUDA Toolkit 9.0 уже включает в себя новые и оптимизированные API с поддержкой функций Volta.
Аппаратная архитектура GV100
Инженеры Nvidia сделали множество изменений в GV100, по сравнению с чипами предыдущих поколений, которые позволили повысить производительность и эффективность новинки. Это касается как типичных HPC-применений, так и задач с применением глубокого обучения, которые способны ускоряться на Volta буквально в несколько раз. Давайте рассмотрим все по порядку.
Как и аналогичный процессор GP100 из предыдущего поколения Pascal, новый GV100 состоит из нескольких вычислительных кластеров Graphics Processing Cluster (GPC), которые включают в себя кластеры Texture Processing Cluster (TPC), а также контроллеров памяти. В свою очередь, кластеры TPC состоят из нескольких потоковых мультипроцессоров Streaming Multiprocessor (SM), подробно о составе которых мы поговорим чуть позже.
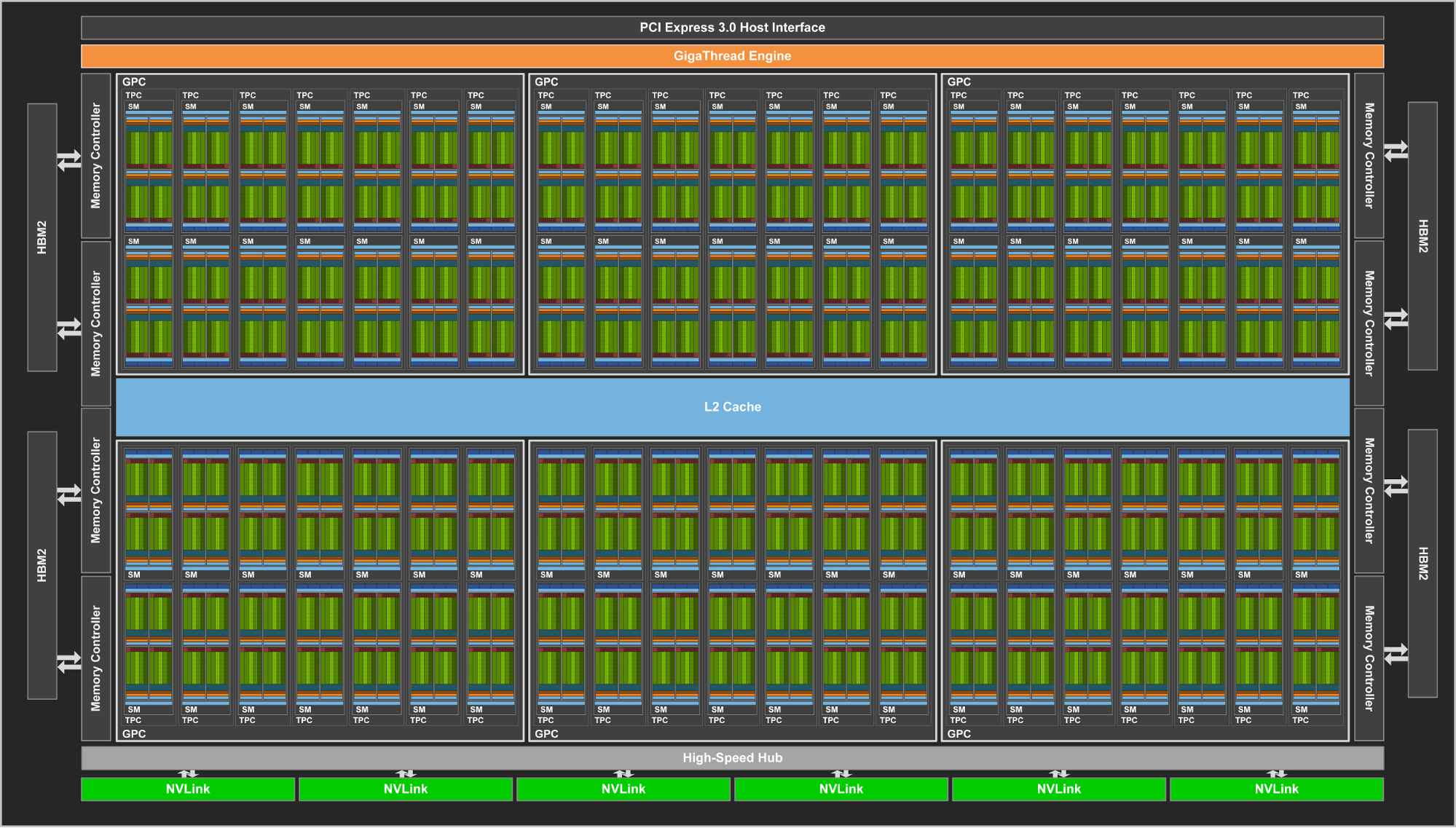
На иллюстрации показан полноценный чип GV100 с 84 мультипроцессорами, а в ускорителе Tesla V100 используется его версия с 80 активными мультипроцессорами SM. Полная версия вычислительного процессора архитектуры Volta содержит шесть кластеров GPC и 42 кластера TPC, каждый из которых содержит по два мультипроцессора SM. То есть, всего в чипе есть 84 мультипроцессора SM, каждый из которых содержит 64 вычислительных ядра FP32, 64 ядра INT32, 32 ядра FP64 и 8 новых тензорных ядер, специализирующихся на ускорении нейросетей. Также каждый мультипроцессор содержит по четыре текстурных модуля TMU.
Соответственно, с 84 рабочими мультипроцессорами, полный чип GV100 предлагает мощь 5376 ядер FP32 и INT32, 2688 ядер FP64, 672 тензорных ядер и 336 модулей текстурирования. Для доступа к локальной видеопамяти в GPU имеется восемь 512-битных контроллеров HBM2-памяти, совместно дающих 4096-битную шину памяти. Каждый стек быстрой HBM2-памяти управляется собственной парой контроллеров памяти, а каждый из контроллеров памяти соединен с разделом кэш-памяти второго уровня объемом в 768 КБ, то есть, всего в GV100 получается 6 МБ L2-кэша.
Давайте сравним ускорители вычислений компании Nvidia, вышедшие за последние пять лет, по их характеристикам и пиковым показателям производительности (все расчеты сделаны на основе турбо-частот GPU):
| Модель ускорителя | Tesla K40 | Tesla M40 | Tesla P100 | Tesla V100 |
| Модель GPU | GK180 | GM200 | GP100 | GV100 |
| Архитектура | Kepler | Maxwell | Pascal | Volta |
| Техпроцесс | 28 нм | 28 нм | 16 нм FinFET+ | 12 нм FFN |
| Кол-во транзисторов, млрд | 7,1 | 8,0 | 15,3 | 21,1 |
| Размер ядра, мм² | 551 | 601 | 610 | 815 |
| Кол-во SM | 15 | 24 | 56 | 80 |
| Кол-во TPC | 15 | 24 | 28 | 40 |
| Ядер FP32 на SM | 192 | 128 | 64 | 64 |
| Ядер FP32 всего | 2880 | 3072 | 3584 | 5120 |
| Ядер FP64 на SM | 64 | 4 | 32 | 32 |
| Ядер FP64 всего | 960 | 96 | 1792 | 2560 |
| Тензорные ядра всего | - | - | - | 640 |
| Турбо-частота GPU, МГц | 810/875 | 1114 | 1480 | 1455 |
| Пиковая пр-сть FP32, терафлопс | 5,0 | 6,8 | 10,6 | 15,0 |
| Пиковая пр-сть FP64, терафлопс | 1,7 | 2,1 | 5,3 | 7,5 |
| Пиковая пр-сть тензор, терафлопс | - | - | - | 120 |
| Кол-во TMU | 240 | 192 | 224 | 320 |
| Шина памяти, бит | 384 | 384 | 4096 | 4096 |
| Тип памяти | GDDR5 | GDDR5 | HBM2 | HBM2 |
| Объем памяти, ГБ | До 12 ГБ | До 24 ГБ | 16 ГБ | 16 ГБ |
| Объем L2-кэша, КБ | 1536 | 3072 | 4096 | 6144 |
| Объем разделяемой памяти на SM, КБ | 16/32/48 | 96 | 64 | До 96 КБ |
| Объем регистрового файла, КБ | 3840 | 6144 | 14336 | 20480 |
| TDP, Вт | 235 | 250 | 300 | 300 |
Хорошо видно явный прогресс, произошедший всего за несколько лет даже при условии не слишком быстрого развития новых техпроцессов на TSMC. За прошедшие годы, даже если не учитывать новые возможности тензорных ядер по матричным вычислениям, используемым в задачах глубокого обучения, производительность FP32-вычислений выросла втрое, для FP64 разница более чем четырехкратная, да и новый тип высокоскоростной памяти дал возможность серьезно повысить ПСП.
Естественно, что все это вылилось в постоянное усложнение чипов — GV100 (Volta) стал втрое сложнее, чем GK180 (Kepler), но из-за совершенствования технологических процессов размер GPU вырос лишь в полтора раза. Вычислительный процессор GV100 имеет физический размер кристалла 815 мм². Это впечатляющий по размеру чип, особенно для еще не идеально отлаженного нового 12 нм FFN техпроцесса — скорее всего, его размер близок к предельному для фабрики TSMC. Чтобы хорошо понимать, насколько это много, можно сравнить размер чипа с размером сенсоров в полнокадровых цифровых камерах, которые имеют лишь чуть больший размер в 864 мм², но сделаны с использованием гораздо менее сложной литографии.
К слову о 12-нанометровом FFN-техпроцессе TSMC. Это действительно самый продвинутый на сегодня техпроцесс тайваньской компании, подходящий для производства таких больших и сложных чипов, как GV100. Единственный момент, который нужно знать — по сути, это уменьшенная версия известного техпроцесса 16 нм FinFET, четвертый вариант этой технологии с улучшенными характеристиками, отличающийся не так сильно, как числа 12 и 16. TSMC просто решила назвать его по-новому — для того, чтобы им было легче конкурировать с компаниями Samsung и GlobalFoundries, предлагающими техпроцесс 14 нм. Все эти цифры давно не говорят ничего особенного о реальных качествах техпроцесса, они очень примерны и могут «гулять» туда-сюда в зависимости от желания производителей.
При такой огромной площади кристалла неудивительно, что даже использование самого передового 12-нанометрового FFN-техпроцесса позволило сделать его лишь на самой грани нынешних возможностей фотолитографии. Чип получился очень большой и дорогой во всем, и инженерная команда Nvidia в лице Джона Албена, старшего вице-президента по проектированию GPU, высказала благодарность президенту компании Дженсену Хуангу за то, что он дал им возможность работать над столь сложным и многообещающим проектом. Для понимания сложности задачи в целом, Дженсен привел такие данные: в процессе разработки архитектуры Volta и первого вычислительного процессора на его основе компанией было потрачено три миллиарда долларов.
Потоковый мультипроцессор Volta
Потоковые мультипроцессоры SM известны нам уже по нескольким поколениям вычислительных и графических процессоров компании Nvidia. В архитектуре Volta были проведены очередные глобальные изменения и модификации, позволившие увеличить их производительность и эффективность. SM новой модели имеет меньшие задержки для кэша и выполнения инструкций, по сравнению с предыдущими дизайнами SM, а также включает в себя совершенно новые возможности для ускорения приложений искусственного интеллекта.
Основные особенности мультипроцессоров Volta:
- Новые тензорные ядра со смешанной точностью вычислений (FP16/FP32), предназначенные для матричных вычислений, используемых в задачах глубокого обучения;
- Улучшенная кэш-память первого уровня с лучшей производительностью и сниженными задержками доступа;
- Оптимизированный набор инструкций для упрощения декодирования и сокращения задержек при исполнении инструкций;
- Специальные оптимизации для достижения высокой тактовой частоты и лучшей энергоэффективности.
Аналогично предыдущему вычислительному процессору GP100, основанному на архитектуре Pascal, мультипроцессоры в новом GV100 включают по 64 FP32-ядер и по 32 FP64-ядер на каждый SM. Однако для улучшения утилизации вычислительных блоков и повышения общей производительности новые SM используют новую схему разделения ресурсов.
Если мультипроцессор в GP100 разделен на два блока обработки, каждый из которых имеет по 32 FP32-ядра, 16 FP64-ядер, буфер инструкций, один планировщик варпов, два блока диспетчера и регистровый файл на 128 KB, то мультипроцессор в GV100 разбит уже на четыре блока обработки, каждый из которых имеет по 16 FP32-ядер, 8 FP64-ядер, 16 INT32-ядер, два новых тензорных ядра, новый кэш инструкций нулевого уровня (L0), один планировщик варпов, один блок диспетчера и регистровый файл на 64 КБ. Вот довольно подробная схема SM:
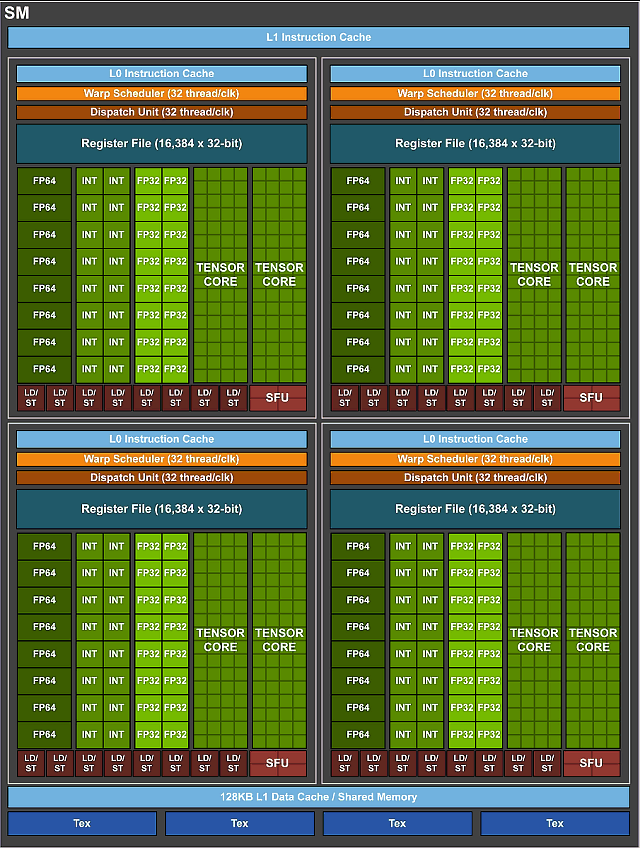
В каждом разделе теперь есть новый кэш инструкций нулевого уровня, который обеспечивает большую эффективность, по сравнению с буферами инструкций, используемых в предыдущих вычислительных и графических процессорах компании Nvidia. И хотя мультипроцессоры в GV100 имеют то же количество регистров, что и SM в GP100, вычислительный процессор в целом имеет гораздо больше блоков SM и больше регистров. Эти изменения привели к тому, что GV100 поддерживает больше одновременно выполняемых потоков, варпов и блоков потоков, по сравнению с предыдущими поколениями GPU.
Общий объем разделяемой памяти для всего вычислительного процессора GV100 стал больше за счет увеличения количества мультипроцессоров и возможности сконфигурировать объем разделяемой памяти до 96 КБ на каждый SM (из 128 КБ, предназначенного для L1-кэша данных и разделяемой памяти вместе), по сравнению с 64 КБ в GP100 предыдущего поколения.
Одно из самых важных изменений в новых мультипроцессорах Volta состоит в том, что в них входят раздельные FP32 и INT32 ядра, позволяющие одновременно исполнять FP32- и INT32-инструкции на полной скорости, что повышает утилизацию блоков и общую производительность GPU. Декодеры и планировщик запускают по одной инструкции и одному варпу за каждый такт, и всего выполняется вдвое больше инструкций и варпов на каждый мультипроцессор за такт, по сравнению с Pascal.
Предыдущие семейства GPU, включая Pascal, не могут выполнять FP32 и INT32 инструкции одновременно, а только по очереди, что негативно сказывается на производительности в некоторых задачах. Новая архитектура мультипроцессоров позволяет запускать FP32-инструкции в полном темпе и использовать оставшуюся половину слотов выдачи для выполнения других типов инструкций: INT32, FP64, загрузки/сохранения, ветвления, специальных функций SFU и т. д., повышая эффективность использования вычислительных возможностей GPU.
Повысился и темп выполнения инструкций и для математических операций умножения-сложения с однократным округлением (fused multiply-add — FMA), требующих лишь четырех тактов на Volta, по сравнению с шестью циклами на Pascal. А раз меньше стадий на исполнение, то и соответствующие исполнительные блоки, скорее всего, занимают меньше площади на чипе. Правда, более длинные конвейеры обычно способны работать на более высокой частоте, но это зависит еще много от чего: физического дизайна, техпроцесса, энергопотребления и т. д. Судя по первым данным, с частотой процессора у GV100 все в порядке.
Тензорные ядра
Ускоритель прошлого поколения Tesla P100 уже обеспечивал заметно более высокую производительность при тренировке нейросетей, если сравнивать его с решениями, основанными на GPU еще более ранних поколений: Maxwell и Kepler, но потребности в тренировке и инференсе нейросетей все большего размера и сложности постоянно растут, и возможностей Pascal исследователям уже не хватает. Они используют нейросети из тысяч слоев и миллионов нейронов, что требует еще большей скорости вычислений.
И обычный полуторакратный прирост скорости, получаемый от каждой новой модели GPU, тут явно недостаточен. Именно для того, чтобы рост производительности соответствовал потребностям рынка, компания Nvidia решила внедрить в свой вычислительный процессор Volta новый тип ядер — тензорные ядра (Tensor Core). Эти ядра — самая важная особенность новой архитектуры Volta, которая и поможет получить многократный рост производительности в задачах обучения и инференса больших нейросетей.
Операции матричного перемножения (BLAS GEMM) лежат в основе обучения и инференса (процесс, обратный обучению — выводы на основе уже «умной» нейросети) нейронных сетей, они используются для умножения больших матриц входных данных и весов в связанных слоях сети. Тензорные ядра специализируются на выполнении этих перемножений и способны значительно увеличить производительность таких вычислений с плавающей запятой при сохранении сравнительно небольшой сложности в транзисторах и площади, занимаемой этими ядрами на GPU. Заодно значительно вырастает энергоэффективность.
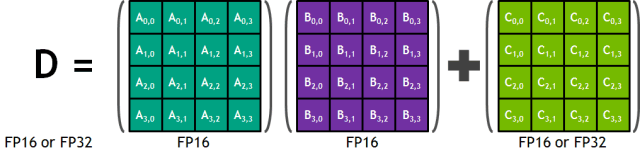
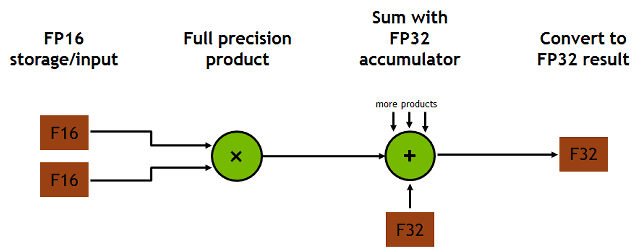
GPU архитектуры Volta поддерживает новые инструкции и форматы данных, удобные для обработки массивов матриц 4×4. Каждое тензорное ядро обрабатывает матричный массив 4×4×4, выполняя операцию D = A × B + C, где A, B, C и D — это матрицы размером 4×4. Вычислительные ядра считывают два значения с FP16-точностью, упакованные в один регистр (матрицы A и B), их перемножение осуществляется с FP32-точностью, результат суммируется с FP32- или FP16-значением и записывается с 32-битной или 16-битной точностью. Для задач глубокого обучения такой точности вполне достаточно, и вполне может быть, что способности тензорных ядер пригодятся также и в других задачах.
Каждое тензорное ядро осуществляет 64 операции умножения-сложения с однократным округлением (fused multiply-add — FMA) с плавающей запятой смешанной точности за один такт. Точность вычислений в этой операции смешанная, многократное перемножение двух FP16-матриц осуществляется с FP32-точностью, накопление также совершается с FP32-точностью, и результат выдается в FP32-формате.
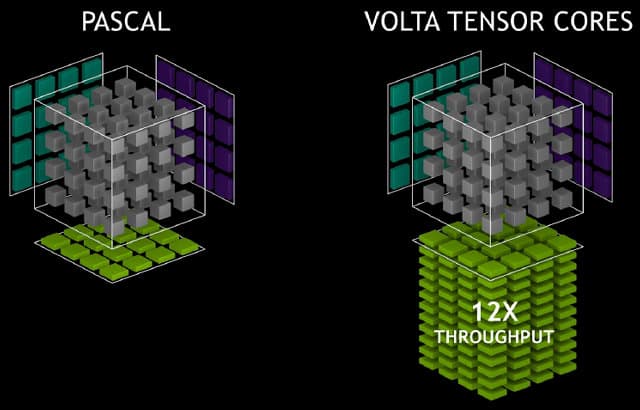
Восемь тензорных ядер в каждом мультипроцессоре SM выполняют в общем 1024 операции с плавающей запятой за такт, что в восемь раз быстрее, чем может обеспечить мультипроцессор архитектуры Pascal с использованием стандартных FP32-операций. В целом, если сравнивать GV100 с вычислительным процессором GP100, это приводит к увеличению производительности в задачах глубокого обучения в 12 раз.
Во время выполнения заданной программы, исполнительным варпом используются несколько тензорных ядер одновременно. Несколько потоков внутри варпа обеспечивают большую операцию над матрицей размером 16×16×16, которая и обрабатывается тензорными ядрами. Возможность исполнения таких операций предоставляется в CUDA C++ API, этот интерфейс обеспечивает специализированную загрузку матриц, умножение и накопление матриц, а также операции хранения матриц для более эффективного использования тензорных ядер в CUDA-программах.
Дополнительно к новым возможностям CUDA, для прямого программирования тензорных ядер можно также использовать библиотеки из CUDA 9: cuBLAS и cuDNN включают новые возможности для использования тензорных ядер в приложениях и фреймворках задач глубокого обучения. Специалисты Nvidia работают вместе с разработчиками популярных фреймворков глубокого обучения, таких как Caffe2 и MXNet для того, чтобы все желающие могли использовать тензорные ядра архитектуры Volta в научных разработках с применением нейросетей.
Всего тензорных ядер в чипе GV100 имеется 640 штук — по 8 на каждый мультипроцессор. Все они вместе способны обеспечить до 120 специализированных тензорных терафлопс при тренировке и инференсе, что в 12 раз больше пикового значения для GP100, если использовать FP32-точность, и в 6 раз больше, если применять FP16-операции. На практике получается пусть и не 12, а несколько меньше, но тоже очень прилично.
На следующей иллюстрации показано, как применение тензорных ядер вычислительного процессора Tesla V100 повышает производительность операций библиотеки cuBLAS (ускоренная на GPU библиотека основных операций линейной алгебры) более чем в 9 раз — по сравнению с ускорителем Tesla P100, основанным на чипе архитектуры Pascal.
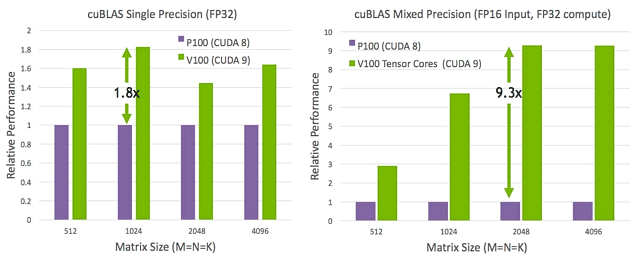
Предпродажный образец Tesla V100 под управлением CUDA 9 за счет специализированных на определенных операциях тензорных ядрах, оказался способен выполнить перемножение матриц (GEMM) большого размера в 9,3 раза быстрее, чем Tesla P100 (при смешанной точности). Конечно, если у разработчика есть требование использовать FP32-точность для входных данных, тогда разница получится заметно меньшей — 1,8 раза, но даже в таком случае прирост вполне ощутим.
Но обычно тренировке нейросетей достаточно FP16-точности, в этом случае возможности тензорных ядер по перемножению матриц могут использоваться полностью, и разница в скорости получается почти на порядок — многим исследователям, использующим глубокое обучение, такой рывок очень понравится. К примеру, если тренировка нейросети займет вместо недели лишь день или даже полдня, то такую разницу будет очень легко ощутить и оценить.
Теоретически, тензорные ядра можно использовать не только в задачах глубокого обучения, но и в любых других, где используются аналогичные операции над матрицами. Если таковые найдутся, а это может быть какая-то постобработка, например, то их можно будет использовать в будущем и в графических задачах. Нужно только будет раскрыть эти возможности в графических API, хотя даже если они не будут включены в будущие их версии, то у Nvidia всегда есть возможность предложить разработчикам эти функции теми же способами, которые применяются для других специфических технологий компании.
Впрочем, это лишь голое теоретизирование, так как еще неизвестно, сохранят ли тензорные ядра в «игровых» GPU. С одной стороны, ускорение того же инференса полезно и на конечных устройствах, а не только серверах, которые тренируют нейросети. С другой — возможно, эти ядра обойдутся в игровых чипах слишком дорого, а использование этих возможностей будет слишком редким. В любом случае, решение за Nvidia — если они найдут достаточную мотивацию для того, чтобы оставить тензорные ядра в игровых решениях, то сделают это. Но нужно быть готовыми к тому, что в игровых Volta их может и не оказаться.
Улучшенные кэширование и разделяемая память
Не обошлось в GV100 и без изменений в подсистеме кэширования. В архитектуре Volta применяется новая комбинированная быстрая начиповая память, сочетающая кэш-память первого уровня для данных и разделяемую память. Такая реализация улучшает производительность, упрощает сложность программирования для некоторых задач и снижает необходимость в ручной оптимизации, необходимой для достижения производительности, близкой к пиковой.
Объединение кэша L1 для данных и разделяемой памяти в один блок позволяет обеспечить лучшие характеристики для обоих типов доступа к памяти. Суммарная емкость этих типов памяти в GV100 составляет 128 КБ на каждый мультипроцессор, что в несколько раз больше, чем кэш данных у GP100, и всю эту память также можно использовать и в качестве кэш-памяти теми программами, которые не используют разделяемую память. Текстурные блоки в SM также используют эту же кэш-память. Самый простой пример разделения — поровну, когда разделяемая память сконфигурирована в объеме 64 КБ, а для текстурных операций и операций загрузки и хранения можно использовать оставшиеся 64 КБ в виде L1-кэша.
Интеграция L1-кэша с разделяемой памятью гарантирует, что этот кэш у GV100 имеет гораздо меньшие задержки и большую пропускную способность, по сравнению с L1-кэшем в предыдущих графических процессорах компании. Кэш первого уровня в архитектуре Volta работает как канал потоковой передачи данных с высокой пропускной способностью, одновременно обеспечивая доступ к часто используемым данным с низкой задержкой, сочетая эти две характеристики.
Основной причиной для такого слияния L1-кэша данных с разделяемой памятью в GV100 является достижение более высокой производительности разделяемой памяти для операций с L1-кэшем. Разделяемая память дает высокую пропускную способность и низкие задержки, но программистам приходится самостоятельно управлять такой памятью. Новая вычислительная архитектура Nvidia сокращает разницу в скорости между приложениями, которые самостоятельно управляют разделяемой памятью и теми, которые предпочитают обращаться к данным в видеопамяти и полагаться на их кэширование в L1-кэше.
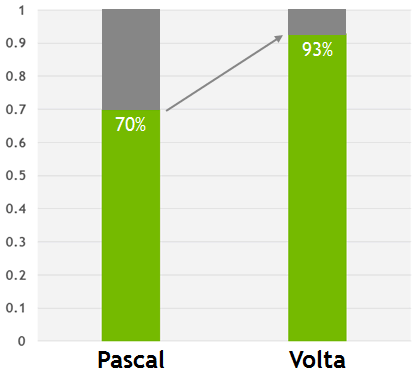
L1-кэш в Volta нивелирует разницу между приложениями, которые вручную настроены для хранения данных в разделяемой памяти, и тех, которые обращаются к данным, хранящимся в локальной памяти напрямую. На приведенной выше диаграмме значение 1,0 равно производительности приложения, настроенного для использования исключительно разделяемой памяти, а два столбца для Pascal и Volta представляют производительность эквивалентных приложений, не использующих разделяемую память.
Соответственно, новая архитектура позволяет приблизиться к идеальной ситуации, когда не так важно, какой метод доступа к памяти используется. Хотя разделяемая память все равно остается лучшим выбором для достижения максимальной производительности (7% совершенно не лишние), но новая комбинированная кэш-память в Volta позволяет программистам легко получить достаточно высокую производительность с отсутствием необходимости в ручной оптимизации.
Независимое управление потоками
Одно из самых больших и сложных изменений в Volta — новые планировщики потоков и декодеры (dispatch unit), а соответственно и алгоритмы управления потоками и варпами, которые стали более эффективными. Архитектура Volta в целом была спроектирована для дальнейшего упрощения программирования GPU по сравнению с предыдущими поколениями, что должно сделать работу программистов более продуктивной, что особенно важно в случае сложных приложений.
Вычислительный процессор GV100 стал первым GPU, который поддерживает независимое управление (планирование) потоками, что обеспечивает более точную синхронизацию и лучшее взаимодействие между параллельными потоками. Одной из главных целей при разработке новой архитектуры было сокращение времени разработки, необходимого для эффективной работы программ на GPU, а также для обеспечения большей гибкости во взаимодействии между потоками.
Модели исполнения SIMT (single instruction, multiple thread — одна инструкция и много потоков) в предыдущих GPU компании и Volta несколько отличаются. Модель SIMT в Volta позволяет использовать равный параллелизм между всеми потоками, независимо от варпа, поддерживая состояние выполнения для каждого потока, включая счетчик программы и стек вызовов.
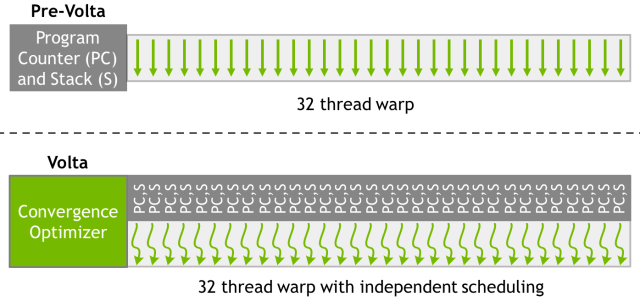
На иллюстрации показана архитектура независимого планирования потоков Volta по сравнению с Pascal и ранними архитектурами. Volta сохраняет ресурсы планирования для каждого потока, такие как счетчик программ (PC) и стек вызовов (S), в то время как ранние архитектуры сохраняли эти ресурсы только для каждого варпа. Независимое управление потоками в Volta позволяет вычислительному процессору выполнять любой поток, чтобы эффективнее использовать вычислительные ресурсы или позволить одному потоку ждать данных от другого.
Чтобы повысить эффективность параллельного исполнения, в Volta есть оптимизатор планирования (schedule optimizer), который группирует активные потоки из одного и того же варпа в блоки SIMT. Это сохраняет высокий темп исполнения SIMT, как в предыдущих процессорах Nvidia, но с большей гибкостью: в Volta потоки могут расходиться и сходиться в варпе, а GPU будет группировать потоки, выполняющие один и тот же код, и запускать их параллельно.
Выполнение происходит по-прежнему по модели SIMT, при любом такте ядра CUDA выполняют одинаковую инструкцию для всех активных потоков в варпе, сохраняя эффективность выполнения на уровне предыдущих архитектур. Способность Volta управлять потоками в рамках варпа позволяет реализовать более сложные алгоритмы и структуры данных. Хотя планировщик поддерживает независимое выполнение потоков, он оптимизирует не синхронизированный код для обеспечения максимально возможной эффективности исполнения модели SIMT.
CUDA 9 и новые вычислительные возможности
Анонс нового вычислительного процессора вызвал и появление новой версии программной платформы для вычислений на GPU — CUDA 9, получившей обновленные вычислительные возможности. Девятая версия пакета полностью поддерживает архитектуру Volta и ускоритель вычислений Tesla V100, а также содержит начальную поддержку специализированных тензорных ядер, обеспечивающих большой прирост скорости при матричных операциях со смешанной точностью вычислений, широко распространенных в задачах глубокого обучения.
Вычислительный процессор GV100 поддерживает новый уровень вычислительных возможностей — Compute Capability 7.0. На таблице показаны отличия в вычислительных возможностях и пределов мультипроцессоров для разных архитектур и решений компании Nvidia: Kepler, Maxwell, Pascal и Volta.
| GPU | GK180 | GM200 | GP100 | GV100 |
| Архитектура | Kepler | Maxwell | Pascal | Volta |
| Compute Capability | 3.5 | 5.2 | 6.0 | 7.0 |
| Потоков на варп | 32 | 32 | 32 | 32 |
| Кол-во варпов на SM | 64 | 64 | 64 | 64 |
| Кол-во потоков на SM | 2048 | 2048 | 2048 | 2048 |
| Кол-во блоков потоков на SM | 16 | 32 | 32 | 32 |
| Кол-во 32-битных регистров на SM | 65536 | 65536 | 65536 | 65536 |
| Кол-во регистров на блок | 65536 | 32768 | 65536 | 65536 |
| Кол-во регистров на поток | 255 | 255 | 255 | 255 |
| Размер блока потоков | 1024 | 1024 | 1024 | 1024 |
| FP32-ядер на SM | 192 | 128 | 64 | 64 |
| Кол-во регистров на FP32-ядра | 341 | 512 | 1024 | 1024 |
| Разделяемая память на SM, КБ | 16/32/48 | 96 | 64 | До 96 |
Из других изменений в девятой версии отметим ускоренные библиотеки линейной алгебры, обработки изображений, FFT и других, улучшения в программной модели, поддержке унифицированной памяти, компиляторе и утилитах для разработчиков. Подробнее читайте на сайте Nvidia по ссылке выше.
Оценка производительности
Нам уже понятно, что новый вычислительный процессор GV100 обеспечивает значительно более высокую производительность, по сравнению с предыдущими решениями Nvidia вроде GP100 на архитектуре Pascal, также дополненную и новыми возможностями, вроде тензорных ядер. При том, что новый GPU продолжает упрощать задачу его программирования и переноса приложений с других систем, он обеспечивает лучшую эффективность и загрузку имеющихся вычислительных ядер.
GV100 является еще более энергоэффективным вычислительным процессором, обеспечивающим очень высокую производительность в пересчете на каждый ватт. Так, пиковая вычислительная производительность в целочисленных вычислениях и вычислениях с плавающей запятой при том же потреблении энергии в 300 Вт для новинки составляет:
- 7,5 терафлопс для вычислений с двойной точностью (FP64);
- 15 терафлопс для вычислений с одиночной точностью (FP32);
- 120 тензорных терафлопс для матричных операций со смешанной точностью (FP16/FP32).
Это теоретические цифры, а если говорить о практике в типичных HPC-применениях, то ускоритель Tesla V100 также обеспечивает наибольшую в индустрии производительность, даже если не учитывать способности тензорных ядер. На следующей диаграмме показана производительность предпродажного образца ускорителя Tesla V100, по сравнению с Tesla P100:
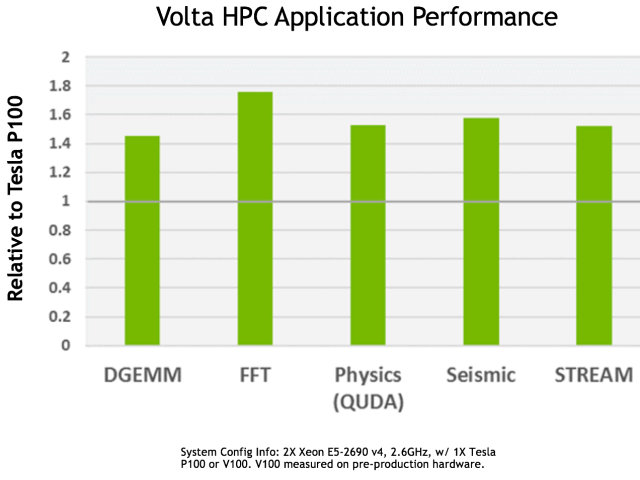
Как видите, новинка на чипе архитектуры Volta на тестовой системе из пары Xeon E5-2690 v4 обеспечила в среднем полуторакратный прирост в скорости в типичных HPC-задачах. Если в DGEMM (перемножение матриц с двойной точностью) V100 опережает P100 более чем в 1,4 раза, то в других применениях, таких как быстрое преобразование Фурье (FFT) прирост достигает 1,75 раза, что весьма неплохо.
А если говорить о задачах глубокого обучения, таких как тренировка и инференс нейросетей с использованием возможностей новых тензорных ядер Volta, то приросты в них еще более впечатляющие:
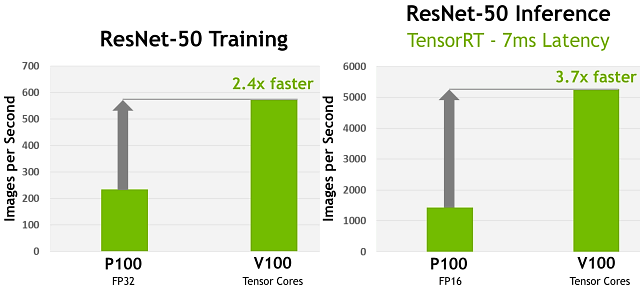
По приложенной выше диаграмме хорошо видно, насколько новый ускоритель Tesla V100 быстрее в задачах глубокого обучения на примере тренировки и инференса нейросети ResNet-50. На левой части иллюстрации показано 2,4-кратное ускорение тренировки этой нейросети на Tesla V100 по сравнению с Tesla P100, а справа — 3,7-кратное ускорение инференса при целевом значении задержки в 7 мс при смене Tesla P100 на V100.
Вот еще несколько примеров сравнения V100 с P100 в некоторых задачах, использующих фреймворки глубокого обучения: Caffe 2, Microsoft Cognitive Toolkit и MXNet, в которых уже применяются вычислительные возможности специализированных тензорных ядер:
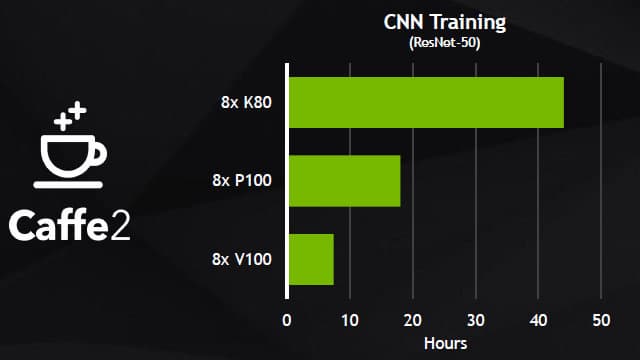
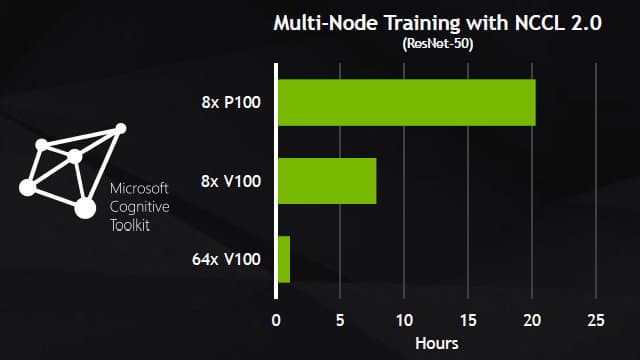
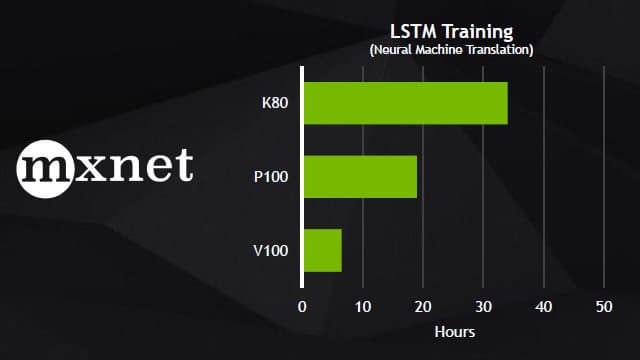
На этих диаграммах явно видно преимущество новой архитектуры в несколько раз, пусть оно и не достигает пиковых 12 и 6 раз, но оно вполне ощутимое, особенно когда дело касается многих суток, потраченных на тренировку нейросети. В случае нового ускорителя Volta в таких задачах используются специализированные тензорные ядра, позволяющие ускорить работу нейросетей в несколько раз, снизив время подготовки алгоритмов искусственного интеллекта к работе.
Выводы
Появление тензорных ядер в решениях Volta стало одним из самых интересных нововведений этой архитектуры. Они позволяют сразу же получить приличный выигрыш по скорости вычислений в задачах глубокого обучения, которые становятся все более популярными. Благодаря объединению уже привычных нам, но серьезно модифицированных CUDA-ядер вместе с новыми тензорными, всего один сервер на базе ускорителей Tesla V100 может заменить сотни CPU в специализированных высокопроизводительных вычислениях. Понятно почему решениями Nvidia на основе Volta уже заинтересовались такие известные компании, как Amazon, Baidu, Facebook, Google, Microsoft, Oak Ridge National Laboratory, Tencent и многие другие.
На данный момент, архитектура Nvidia Volta — это самая современная и продвинутая вычислительная архитектура, которая призвана ускорить не только привычные нам высокопроизводительные и графические вычисления, но и вычисления в сфере искусственного интеллекта. По сравнению с Pascal, новые решения Volta должны обеспечить еще большую энергоэффективность в обычных задачах, а в задачах, в которых применимы специализированные тензорные ядра (глубокое обучение и некоторые другие операции с матрицами), и вовсе обеспечить преимущество в несколько раз.
Ускоритель вычислений Tesla V100 имеет 640 таких специализированных тензорных ядер, и это первое анонсированное вычислительное решение, имеющее пиковую производительность в задачах глубокого обучения более чем 100 тензорных терафлопс. Нейронные сети, ранее требующие нескольких недель для тренировки, теперь можно натренировать за несколько дней, и столь значительная разница в скорости обучения должна содействовать успешному решению новых проблем при помощи искусственного интеллекта.
Новое вычислительное решение Tesla V100 в традиционных высокопроизводительных вычислениях имеет производительность в 1,5 раза выше, по сравнению с Tesla P100 на архитектуре Pascal, а в задачах глубокого обучения, где включаются в работу тензорные ядра, теоретический максимальный прирост скорости составляет от 6 до 12 раз, в зависимости от задачи. Реальные же цифры варьируются от 2,5 до 9 раз, что тоже совсем неплохо.
При этом начинать программировать для будущих вычислительных систем компании Nvidia на основе Volta можно уже сейчас, так как для этого есть все необходимое в виде богатой экосистемы для разработки, включающей продвинутые программные средства. А будущие ускорители после их выхода просто позволят получить преимущество по скорости вычислений, в том числе и для ранее написанных приложений.
Кроме новой вычислительной архитектуры Volta, на GTC 2017 были сразу представлены и ускоритель Tesla V100 на основе первого ускорителя вычислений GV100, а также новая линейка суперкомпьютерных систем с искусственным интеллектом — Nvidia DGX, базирующаяся на этом же процессоре и использующая оптимизированные для задач искусственного интеллекта специализированные тензорные ядра. Обо всем этом читайте в нашем отчете с конференции GTC 2017.
Благодаря грамотной многолетней стратегии, компания Nvidia стала одной из важнейших сил на рынке высокопроизводительных вычислений, и решения компании уже сейчас используются многими ее партнерами. Новые технологии Nvidia помогают развитию индустрии визуальных и прочих вычислений, а также исследованиям в сфере искусственного интеллекта. Дальнейшее развитие может еще больше разделить вычислительные и развлекательные применения, но именно их сочетание позволяло и позволяет компании получать максимум от разных рынков.
В свое время прогресс в развитии GPU оплачивали только игроки, теперь к ним присоединились и куда более серьезные ребята, которые вскоре станут не менее, а то и более важной силой, к которой нужно будет прислушиваться все сильнее. Существующие вычислительные решения на основе чипа GP100 уже сейчас отличаются от игровых карт на схожем, но далеко не идентичном GP102, а в дальнейшем разница может и увеличиться — к примеру, не факт, что игровым решениям на основе Volta нужны тензорные ядра. По крайней мере, на данный момент.
Но и совсем разделять вычислительные и графические решения нет смысла — они как чисто с технологической точки зрения до сих пор весьма близки, так как выполняют во многом схожие задачи, так и с финансовой точки зрения правильнее учитывать две сферы, получая прибыль и там и там. Поэтому пока что от «графических» решений архитектуры Volta можно ожидать схожей с вычислительным флагманом функциональности и производительности (с учетом разного количества функциональных блоков и возможного отсутствия тензорных ядер, конечно), по крайней мере, для самых распространенных FP32-вычислений. В общем — посмотрим, благо ждать остается все меньше и меньше.


