Примерно год назад компания AMD положила начало новой традиции — ежегодных анонсов, проходящих в самый разгар новогодних каникул, когда разве что IT-журналисты заняты рабочими делами по освещению проходящей в Лас-Вегасе популярной выставки CES. Эта выставка традиционно привлекает к себе внимание индустрии в самом начале года и отличается многочисленными анонсами новых продуктов и технологий в сфере электроники. Как и в прошлом году, компания AMD решила раскрыть некоторые данные о своих будущих решениях на мероприятии, происходящем в рамках CES 2017.
Раскрываемая в начале года порция информации традиционно небольшая, так как до готовых решений еще довольно далеко, какие-то данные в AMD пока что не хотят раскрывать, а другие и вовсе неизвестны до начала массового производства. Нам дали возможность рассказать лишь о некоторых из особенностей следующего поколения графической архитектуры AMD Vega, которые раскрыли узкому кругу журналистов еще в начале декабря на специальном мероприятии AMD Tech Summit, прошедшем в Сономе, штат Калифорния. Мы уже рассказывали в новостях нашего сайта и о центральных процессорах Ryzen и о стратегии компании AMD по ускорению машинного обучения — Radeon Instinct, а сегодня поговорим о будущих графических решениях и новой дисплейной технологии.

Утечек с того мероприятия, относящихся к графической архитектуре Vega, было не очень много, благодаря секретности и полному запрету на фотографирование в части, посвященной графике. Кроме, собственно, снимков счастливого Раджи Кодури (старший вице-президент и главный разработчик архитектуры из Radeon Technologies Group), держащего в руках один из первых образцов GPU, который планируется выпустить в этом году. По сути, сегодня мы прольем свет лишь на некоторые из интересных особенностей Vega — чисто архитектурных, без какой-либо конкретики.
Развитие индустрии компьютерной графики реального времени связано с желанием обеспечить визуализацию живых виртуальных миров, все более богатых деталями, а в перспективе — с бесконечной детализацией, а значит, с постоянным использованием огромных объемов данных: геометрических, текстурных и т.п. Понятно, что это невозможно без постоянного прогресса в сфере аппаратного обеспечения. Потребности в вычислительных мощностях графических процессоров и объеме доступной для них памяти постоянно возрастает.
В игровых применениях последнего времени это обусловлено появлением доступных 4K-мониторов, в том числе с HDR-экранами, наконец-то вышедшими VR-шлемами, повышающими нагрузку на GPU минимум вдвое, появлением новых версий графических API с новыми возможностями, развитием алгоритмов и появлением новых техник компьютерной графики, а также постоянным увеличением значимости мультиплеерного спорта и появлением новых версий игровых консолей — более мощных и открывающих большие возможности.
Вычислительные задачи не отстают, появляются все новые сферы их применения, а старые развиваются не по дням, а по часам: машинное обучение, машинное зрение, распознавание образов и речи, обработка огромных массивов данных и т.п. В профессиональных применениях на рабочих станциях работа для графических процессоров также не облегчается, постоянно растут требования к мощности GPU в части сложного моделирования, физически корректного рендеринга в реальном времени, создания качественного контента в высоком разрешении, моделирования физически корректных эффектов и многом другом.
Компания AMD считает, что существующие сейчас графические архитектуры не слишком хорошо подходят для задач даже не такого уж далекого будущего, и они плохо масштабируются под постоянно растущие потребности графических и вычислительных задач. Ведь объемы данных растут постоянно и экспоненциально — в частности, компания приводит данные о росте объема различных ресурсов, используемых в игровых приложениях с 2000 года по 2016 год в десятки раз:
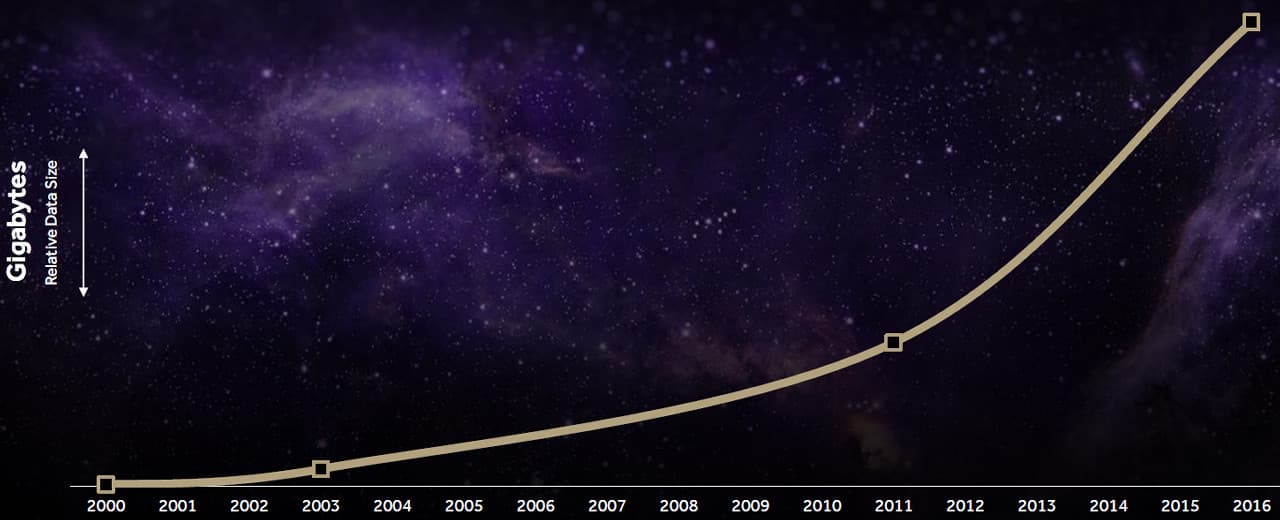
На графике отображены объемы данных, занимаемые на носителях, относящиеся к играм серии Deus Ex, исходя из данных сервиса Steam. Если в начале 2000-х годов было достаточно нескольких сотен мегабайт, то к 2016 году объемы игр выросли до десятков гигабайт. Вы и сами знаете, что многие современные игры легко занимают на накопителях до 70-80 ГБ. Конечно, не все из этих данных являются текстурами и геометрией уровней и персонажей, многое отводится на видео и звук, но все равно — значительный рост объемов очевиден.
Профессиональная графика не отстает, мягко говоря — объемы данных, используемых при работе над спецэффектами и визуальными эффектами в самых зрелищных и кассовых кинофильмах, занимают уже не один петабайт:
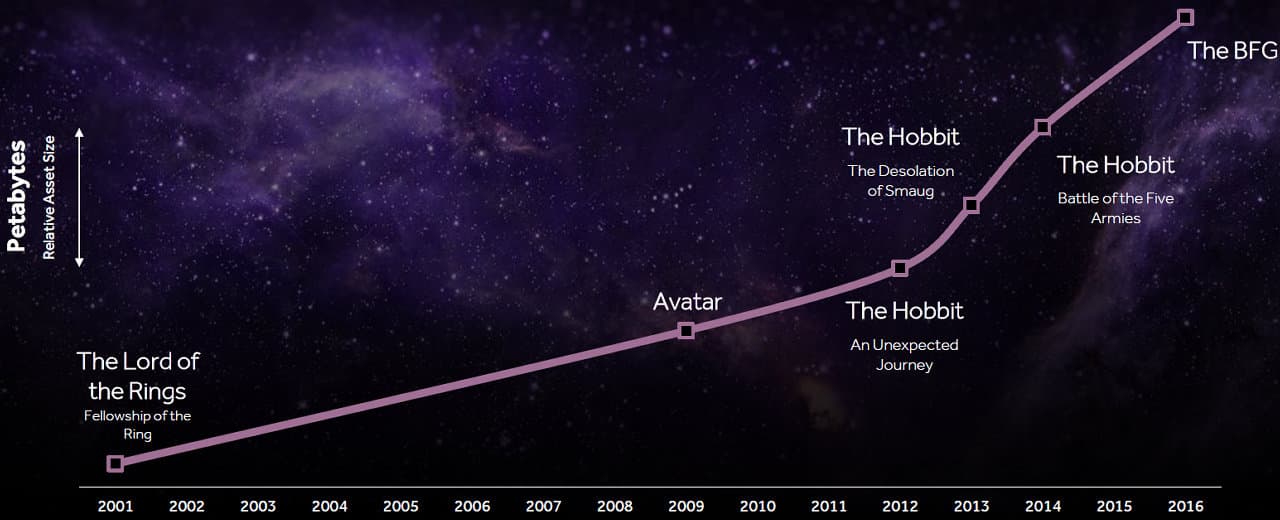
Судя по данным, полученным компанией AMD от представителей киноиндустрии, в фильме «Властелин колец: Братство Кольца» (Lord of Rings, 2001) использовался объем данных в 0,15 петабайт, в «Аватаре» (2009) уже 1 петабайт, в первой части «Хоббита» (The Hobbit, 2012) — 1,4 петабайт, второй части «Хоббита» (2013) — 1,8 петабайт, третьей части трилогии «Хоббит» (2014) — 2,3 петабайт, а в фильме «Большой и добрый великан» (The BFG, 2016) — уже 3 петабайт!
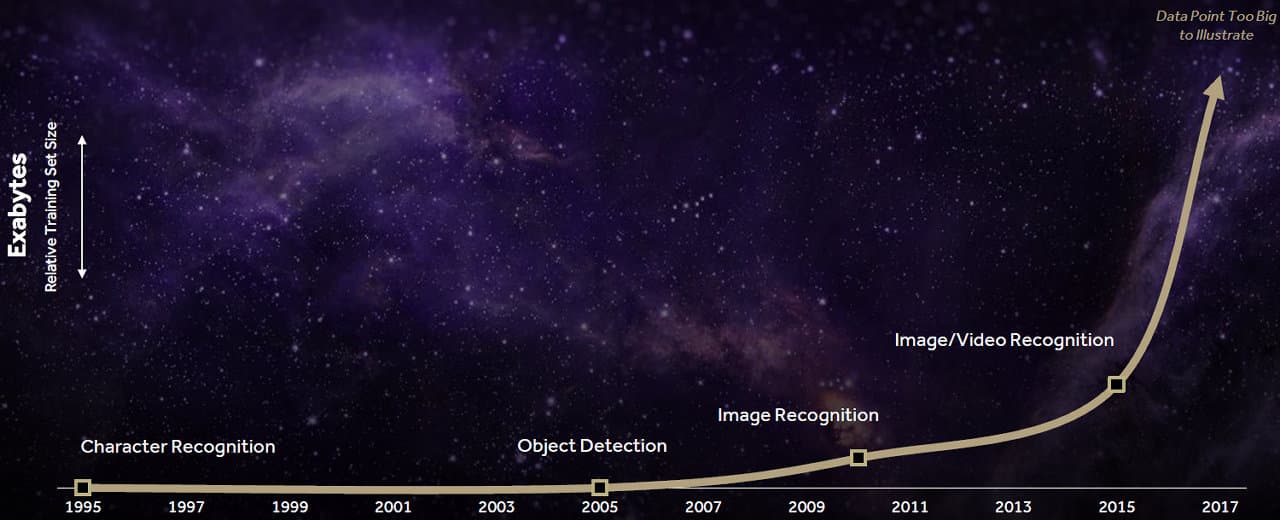
Это не говоря уже об используемых объемах данных в вычислительных задачах, которые растут еще стремительнее. Ведь для распознавания речи, отслеживания объектов, распознавания образов, и уж тем более всех этих вещей в динамике, требуется обрабатывать уже эксабайты данных — на приведенном выше графике даже не хватает масштаба для потребностей, которые возникнут перед индустрией в ближайшие годы, по мнению компании AMD.
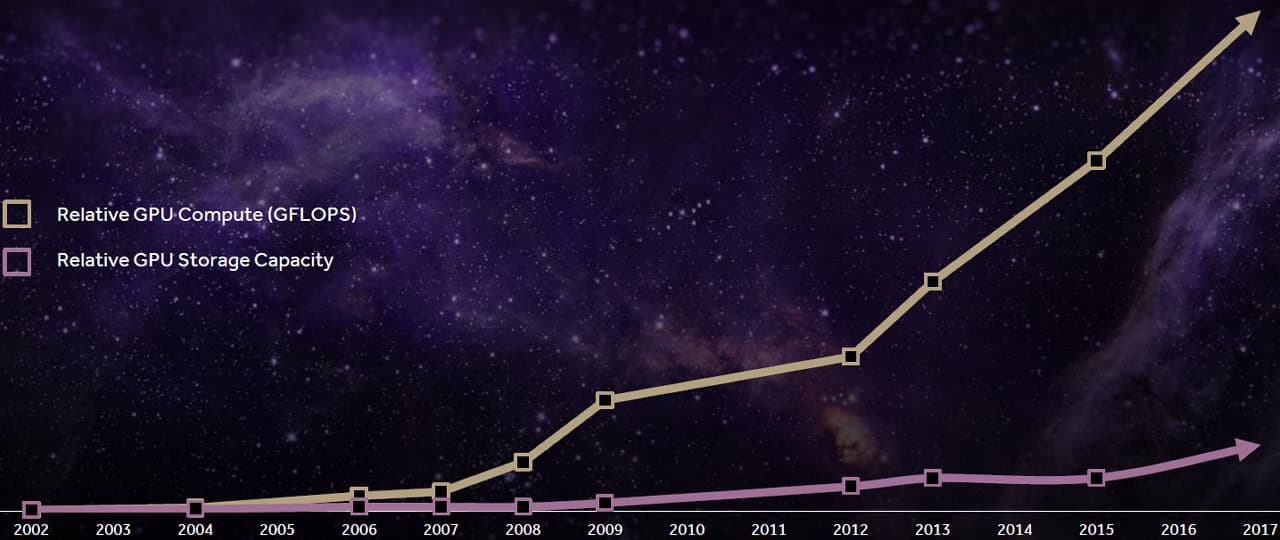
При этом объемы доступной локальной памяти, имеющиеся у графических процессоров, которые все чаще применяются в том числе и в неграфических вычислительных задачах, просто не успевают за ростом их вычислительных мощностей — если производительность GPU за прошедшие несколько лет выросла уже в сотни раз, то рост среднего объема видеопамяти за это же время был где-то на порядок меньше.
Поэтому, посмотрев на тренды и возрастающие запросы, в AMD решили разработать новую графическую архитектуру Vega, использующую «наиболее масштабируемую архитектуру памяти» (по мнению компании), в основе которой лежит уже известная нам по предыдущим решениям очень быстрая память HBM, но уже второго поколения — HBM2. Причем, это уже не просто локальная видеопамять, а высокопроизводительный кэш — High-Bandwidth Cache. По крайней мере, AMD теперь ее называет именно так, а считать ли ее кэшем — мы еще посмотрим.

В достижениях HBM2, по сравнению с первым поколением высокопроизводительной памяти — еще большая пропускная способность — HBM второго поколения может быть вдвое быстрее первого. Также доступна до восьми раз большая емкость на каждый стек (стопку) чипов памяти, что было наибольшим недостатком и самым обидным ограничением HBM1, известным по графическим процессорам Fiji, на которых основаны видеокарты серии Fury.
Отметим и традиционные преимущества перед GDDR5-памятью, вроде более чем вдвое меньшего физического размера, занимаемого на печатной плате — именно поэтому и стало возможно создание таких малогабаритных плат, как Radeon R9 Nano. Также сотрудники AMD заявляют, что новый тип памяти, который планируется применять в Vega, до четырех-пяти раз более энергоэффективен, по сравнению с привычной GDDR5-памятью.
Но главная деталь сегодняшнего анонса вовсе не в том, что в Vega будет применяться HBM2 — об этом то как раз мы давно уже знали. Самое любопытное именно в том, что эта память заявлена в виде кэш-памяти. И для того, чтобы HBM2-память работала как кэш для системной памяти, энергонезависимой памяти (твердотельные SSD-накопители) или даже сетевых накопителей, нужно какое-то управление всей этой иерархией, чтобы GPU брал данные из одного места и сохранял их в других по мере необходимости. Для решения этих задач прямо в графический процессор Vega был внедрен новый контроллер высокопроизводительной кэш-памяти — High-Bandwidth Cache Controller.
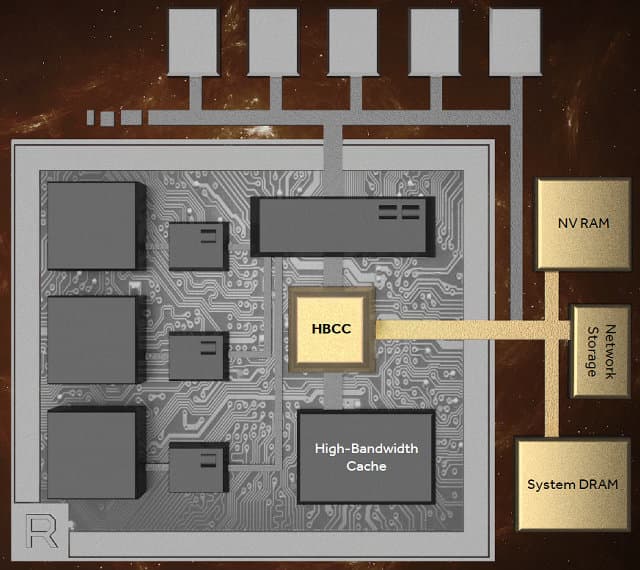
Честно говоря, нам пока что неизвестны подробности того, как именно этот кэш будет работать, а AMD не спешит распространять детали. Но, по словам представителей AMD, высокопроизводительный кэш и его контроллер позволяют использовать плоскую виртуальную адресацию до 512 терабайт данных, и его работа будет полностью прозрачна для пользовательских приложений.
Пока что не приводится никаких данных и об объеме HBM2-памяти (то есть, уже кэша) в будущих игровых решениях на основе Vega. Теоретически возможен объем до 32 ГБ, раз говорят о до 8 раз большей емкости на стек. Мы видели изображения GPU с двумя (см. фото с главой RTG в начале статьи) и четырьмя стеками HBM2 (изображение из презентации чуть выше), что означает 8 ГБ или 16 ГБ — например, первый вариант лучше подойдет для игрового применения, а второй — для профессионального, но это всего лишь наши предположения.
Зато публике дали интересную статистику о том, насколько эффективно используется локальная видеопамять современными игровыми проектами. Так, игры The Witcher Wild Hunt и Fallout 4 в 4K-разрешении при ультра-настройках качества в реальности используют примерно вдвое меньше данных из локальной видеопамяти, чем они заполнили ее объем. К примеру, если игра заняла всю имеющуюся локальную видеопамять объемом в 8 ГБ, то при рендеринге кадра осуществляется доступ к ресурсам, занимающим вдвое меньший объем:
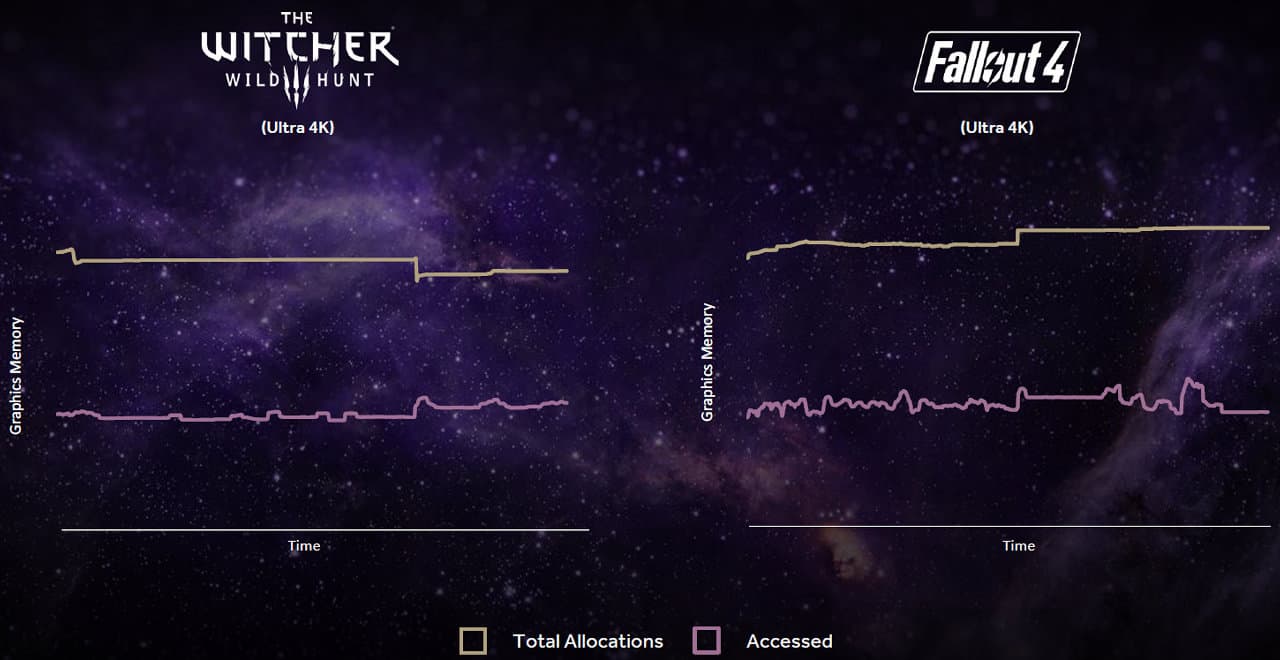
То есть, указанным играм технически совсем не обязательно было занимать 8 ГБ, можно было бы обойтись и 4 ГБ локальной памяти. Иными словами, в играх видеопамять зачастую уже и так используется как общее адресное пространство, которое графический движок заполняет геометрией и текстурами. Фактически, можно хранить только самые важные данные в быстрой кэш-памяти, постепенно подгружая из более медленной все новые и новые ресурсы, требуемые при работе над кадром.
В дальнейшем объемы, занимаемые ресурсами игр и других приложений продолжат свой неумолимый рост, и этот вопрос нужно решать. Путь тупого наращивания объема видеопамяти — это самый простой, но неоптимальный вариант, да и при этом потребление энергии микросхемами памяти будет расти слишком быстро, поэтому в AMD и решили пойти другим путем, сделав быстрый кэш, подгружающий ресурсы с более медленной памяти большего объема.
Они предлагают решение вопроса роста требований к объему данных, не требующее какого-либо вмешательства со стороны разработчиков программного обеспечения, когда аппаратная кэш-память (точнее — ее контроллер, встроенный в GPU) сама определяет, какие ресурсы будут нужны в каждый момент времени, и подгружает их в быструю память. Эта HBM2-память будет как бы быстрым кэшем ко всем необходимым ресурсам, которые можно брать из других мест: дополнительной GDDR5-памяти (мы теоретизируем, представители AMD ничего об этом не говорили!), из системной памяти, да хоть даже с SSD (а мы знаем, что для профессиональный применений уже существуют такие решения в виде Radeon Pro).
Технически, такой подход позволяет использовать больший объем данных, чем помещается в видеопамяти, но лишь при правильной работе контроллера кэш-памяти. И то — вряд ли он сможет решить все проблемы, когда объем данных, требуемых при работе над сценой, значительно превышает объем быстрой кэш-памяти. Но в теории все выглядит красиво — с точки зрения ПО будет некая общая память, размещением данных в каждой из составляющих которой и их менеджментом не нужно заниматься разработчику ПО, а все делается автоматически контроллером в графическом процессоре и видеодрайвером.
Но все ли так прекрасно? У нас есть и некоторые сомнения. Ожидается, что Vega будет иметь пропускную способность в 512 ГБ/с с HBM2-памятью. Но ведь такого значения (и даже большего!) можно добиться и с применением GDDR5X и 512-битной шиной памяти, например. Стоила ли овчинка выделки, если применение GDDR5X, скорее всего, обошлось бы дешевле в производстве и абсолютно точно — в разработке. А соответственно, можно было просто увеличить объем локальной видеопамяти, если использовать не HBM2, а GDDR5(X). Похоже, что в AMD просто нацелились несколько лет назад на применение HBM в своих решениях и видят в ранней разработке гипотетическую возможность обогнать своих конкурентов. Получится это или нет — покажет только время. Ведь Nvidia тоже уже применяет HBM2-память, хоть и исключительно в дорогих вычислительных решениях Tesla.
И еще. Важное отличие кэш-памяти от виртуальной памяти заключается в наличии тегов адресов у кэш-памяти, которых вряд ли получилось бы разместить в GPU достаточно много. Больше похоже на то, что упомянутая «кэш-память» в Vega просто является физической памятью, а остальная память (ОЗУ, SSD и т.п.) — виртуальная, примерно как это сделано в Radeon Pro SSG. Виртуальная адресация в графических процессорах уже не нова, преобразование адресов из виртуальных в физические делается аппаратно на GPU, а в семействе Pascal, судя по документации к вычислительным процессорам GP100 от Nvidia, были добавлены аппаратные page fault, и эти решения также предоставляют возможность плоской виртуальной 49-битной адресации в виде тех же 512 ТБ.
Кстати, почему именно 49 бит? Этого как раз достаточно для того, чтобы с большим запасом покрыть 48-битную виртуальную адресацию современных CPU вместе с локальной видеопамятью GPU, что позволяет получить доступ к полному и единому адресному пространству памяти CPU и GPU, а также к дополнительным данным на накопителях, например. По остальному же нужно дождаться более подробных деталей о том, как работает аппаратный кэш-контроллер и сама высокопроизводительная HBM2-память в будущем GPU. Но нововведения в графической архитектуре Vega не заканчиваются на изменениях, связанных лишь с подсистемой памяти. Также в новом GPU были сделаны и улучшения в геометрическом конвейере, к примеру.
Не секрет, что одной из наиболее существенных проблем 3D-графики с давних времен является так называемый overdraw — многократная прорисовка одних и тех же пикселей на экране, относящихся к разным геометрическим моделям, которые загораживают друг друга так, что камере виден лишь ближайший пиксель. Простой пример wireframe-скриншота из игры Deus Ex: Mankind Divided показывает, насколько больший объем данных обсчитывает GPU, начиная с дальних объектов:

В кадре после всех оптимизаций и так присутствует несколько миллионов полигонов, но если прорисовывать всю геометрию уровня, то это значение вырастет в десятки раз, и графический процессор большую часть времени будет заниматься бесполезной работой по отрисовке тех пикселей, которые пользователь никогда не увидит. Для оптимизации overdraw существует множество алгоритмов, включающих сравнение Z-координат и другие методы, предназначенные для отбрасывания невидимой геометрии, но ее все равно остается достаточно много.
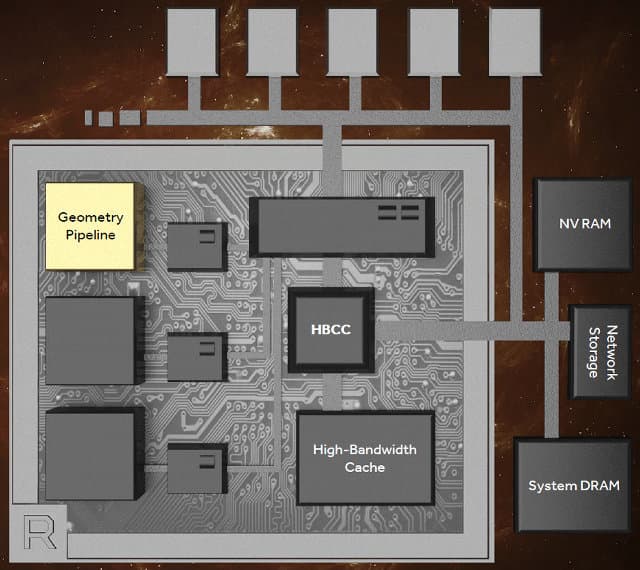
Новый программируемый геометрический движок в графическом процессоре следующего поколения AMD Vega включает несколько нововведений (пока что без конкретизирующих уточнений), позволяющих увеличить итоговый темп обработки геометрии — по данным AMD, новый GPU способен обрабатывать геометрию до двух раз быстрее, по сравнению с решениями предыдущих поколений.
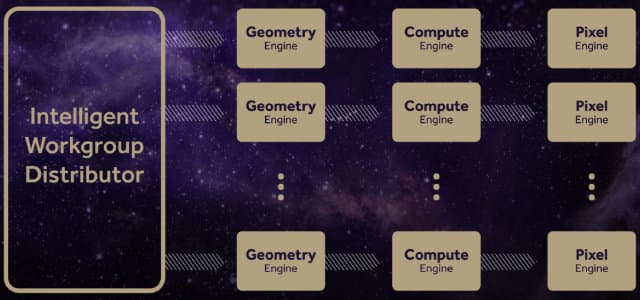
Если графический процессор Fiji имеет четыре движка геометрии и обрабатывает четыре полигона за такт, то чип новой архитектуры Vega с тем же количеством геометрических движков способен обрабатывать уже до 11 полигонов за такт. Также специалисты компании AMD смогли улучшить балансировку загрузки различных вычислительных блоков работой при помощи продвинутого блока распределения работы Intelligent Workgroup Distributor, имеющегося в новой архитектуре.
Пока что нам известны лишь поверхностные теоретические данные о работе улучшенных геометрических блоков, и мы можем только прикинуть возможный прирост их производительности, исходя из удвоенного темпа обработки геометрии. Для получения более конкретных данных придется подождать следующей порции информации от AMD. Из других важных изменений отметим улучшения, связанные с вычислительными блоками нового поколения, которые назвали Vega NCU — Next-Generation Compute Unit.
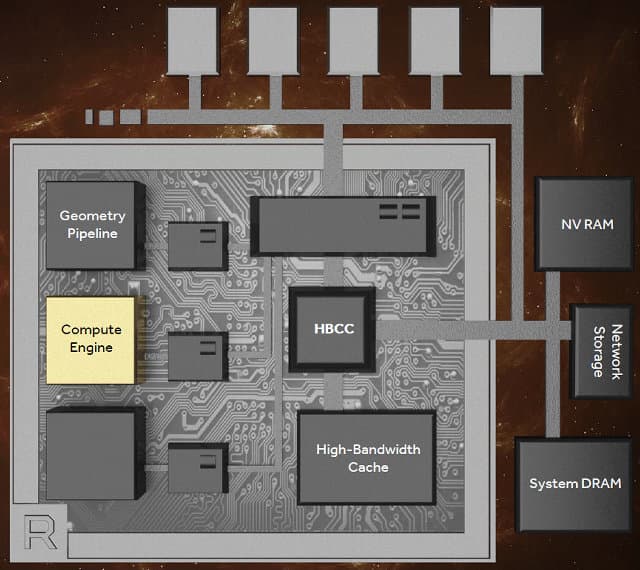
Все отличия NCU от предыдущих CU нам также пока неизвестны, но одной из самых важных новых возможностей вычислительного блока следующего поколения является двойной темп операций вычислений над данными с плавающей запятой половинной точности — то есть, FP16 (по сравнению с общепринятыми FP32). Каждый из имеющихся в новом графическом процессоре Vega блоков NCU умеет исполнять 128 операций с привычной 32-битной точностью (FP32) за такт, или вдвое больше — 256 уже 16-битных (FP16) операций, так называемых packed-вычислений.
То же самое касается и операций над 8-битными данными, которые могут выполняться с еще более высоким темпом — 512 операций за такт. А вот что касается 64-битных вычислений двойной точности (FP64), то эти возможности архитектуры Vega пока что не разглашаются, кроме указания того, что это будет конфигурироваться для каждой конкретной модели графического процессора отдельно. Вероятно, для топовых GPU будет доступен больший темп FP64-вычислений, а для бюджетных — меньший, как это всегда было ранее.

Вычисления в формате FP16 имеют достаточную точность для использования во множестве современных вычислительных задач, таких как машинное зрение и обучение, а удвоенный темп исполнения FP16 по сравнению с FP32 позволяет ускорить такие вычисления ровно вдвое по сравнению с предыдущими поколениями GPU. Также сниженная точность вычислений может подойти и для некоторых игровых применений, не требующих привычной точности 32-битных вычислений, и в этом очень поможет поддержка ускоренных FP16-вычислений современными консолями, которые никогда не испытывают избытка вычислительных ресурсов. Не зря же решения AMD применяются чуть ли не во всех консолях текущего поколения.
Интересно, что в решениях конкурирующей с AMD компании Nvidia аналогичная аппаратная возможность FP16-вычислений с двойным темпом появилась в графических процессорах несколько раньше, но... только в профессиональных и мобильных решениях, но не в GPU, предназначенных для установки в массовые настольные ПК. Так что у будущих видеокарт AMD может появиться некоторое преимущество, если разработчики действительно начнут использовать FP16 массово. Правда, еще не до конца понятно, насколько широко применимы вычисления со сниженной точностью в играх — помнится, несколько лет назад за это критиковали решения Nvidia того времени.
Вероятно, лишь часть алгоритмов и техник в графических задачах может довольствоваться сниженной точностью вычислений, в том числе и потому, что ошибки накапливаются при нескольких проходах, например. Даже если на «рельсы» FP16 переведут весомую часть вычислительных алгоритмов в играх, то реальное влияние на общую производительность вряд ли превысит несколько процентов. Другое дело — чисто вычислительные задачи нового поколения, вроде распознавания образов, машинного зрения и обучения. Вот там удвоенный темп FP16-вычислений точно принесет очень большой прирост в скорости.

Продолжая разговор об изменениях в вычислительных блоках следующего поколения, нужно отметить, что новые блоки были специально оптимизированы для работы на более высокой тактовой частоте, по сравнению с CU в графическом процессоре Polaris, а также они способны достигать большего темпа исполнения инструкций за такт (IPC) — до двух раз большего по сравнению с предыдущими CU. Проверить это мы пока что не можем, естественно, и может быть этот рост IPC относится как раз к FP16-вычислениям, детали пока что не уточняют, ограничиваясь лишь схематичными иллюстрациями.
Все ближе мы подходим к блокам нового графического процессора Vega, занимающимся исключительно графическими задачами. Инженеры компании AMD давно работают над повышением эффективности использования имеющейся полосы пропускания, несмотря на традиционно большое внимание и к новым типам памяти, таким как GDDR5 и HBM(2).

Полоса пропускания памяти (ПСП) — это штука, которой всегда не хватает, и для более эффективного ее использования ранее были внедрены такие технологии экономии ПСП, как HiZ, FastZ Clear и алгоритмы сжатия данных во фреймбуфере без потерь. Продолжает эту историю экономии пропускной способности блок обработки пикселей (pixel engine) нового поколения, который работает в последней стадии графического конвейера и формирует значения пикселей для их вывода.
Улучшенный пиксельный движок был спроектирован для повышения производительности, более эффективного использования данных и соответствующего увеличения энергоэффективности. Он отличается от предыдущих тем, что использует тайловую растеризацию, аналогично тому, что было сделано инженерами Nvidia в Maxwell (и далее). В процессе этого используется начиповый кэш для промежуточного хранения данных и новая логика работы растеризатора, который разбивает буфер на тайлы.
Далее пиксельный движок определяет, какие геометрические примитивы попадают в каждый тайл (binning), генерируется список примитивов и вызовов функций отрисовки (draw stream) для каждого тайла, и каждый тайл затем отдельно растеризуется с большей эффективностью, используя при работе специальный начиповый кэш. При этом отрисовываются только видимые камере пиксели, а значения невидимых отбрасываются, что и повышает производительность и эффективность.
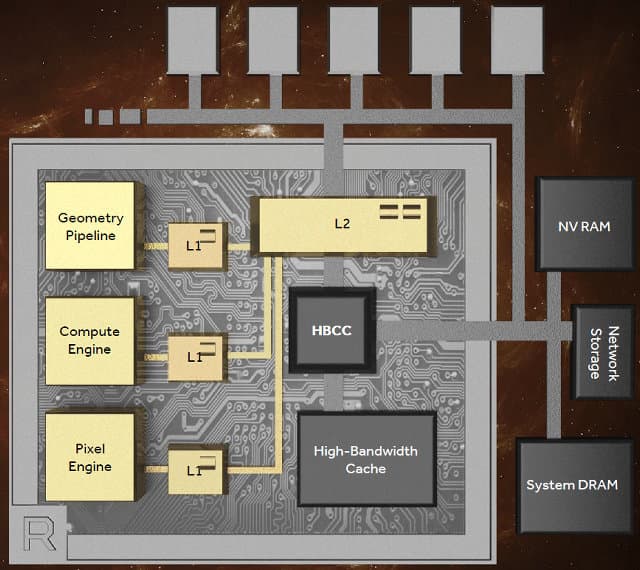
Ну и последнее важное отличие Vega от ранних графических архитектур, которое мы рассмотрим сегодня — если пиксельные и текстурные блоки предыдущих GPU не могли обращаться к памяти одновременно (когерентность памяти), то теперь блоки растеризации RBE (render back-end) имеют быстрый доступ к кэш-памяти второго уровня и используют ее для экономии ПСП видеопамяти. Все это должно помочь серьезно увеличить производительность в игровых и профессиональных приложениях, использующих отложенное затенение (deferred shading), в частности.
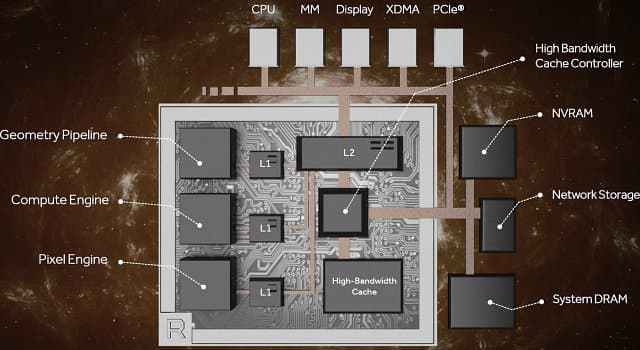
После рассмотрения всех изменений в новой архитектуре, нам остается привести полную схему графического процессора Vega в упрощенном схематичном виде — со всеми укрупненными блоками, которых мы сегодня коснулись:
Для подтверждения высокой производительности Vega специалисты из AMD провели демонстрацию, показав новый графический процессор в действии. Так, в игре Doom в 4K-разрешении при ультра-настройках и использовании Vulkan API, система на базе инженерного образца Vega показала производительность около 70 FPS, что в целом довольно неплохо — примерно на уровне GeForce GTX 1080.
Остается самый главный вопрос — когда? И на него у нас пока что нет точного ответа. AMD говорит расплывчато: то «позднее в 2017 году», то «в первой половине года». Что чаще всего означает июнь, ну или хотя бы май. Снова где-то рядом с Computex? И это скорее всего так и есть, и сейчас еще очень рано говорить как о каких-то деталях, которые еще изменятся, так и о финальных характеристиках по частотам и итоговой производительности. Пока что нам дали только предварительные данные о некоторых из архитектурных улучшений в Vega. Ну и запустили рекламную кампанию, продолжающую тему Radeon Rebellion с плакатами и лозунгами в «революционном» стиле, известную по прошлому году.
Несмотря на то, что никаких дат не называлось и даны лишь предварительные данные о новинках компании AMD, включая процессоры семейства Ryzen и новую графическую архитектуру Vega, у нас есть ощущение, что 2017 год будет удачным для компании. Они наконец-то должны выпустить конкурентоспособный CPU и очень интересный GPU для энтузиастов, имеющий уникальную особенность в виде HBM2-кэша. Причем, если AMD выпустит игровое решение с HBM2 раньше конкурента, то существенного ограничения по объему (как было для HBM1 в виде 4 ГБ) уже не будет в этот раз, ведь даже 8 ГБ вполне достаточно сейчас для любой современной игры.
А если немного помечтать, то теоретически можно вообще сделать видеокарту с разными типами памяти, поставив на новый графический процессор, скажем 2 или 4 ГБ HBM2-кэша и 8 ГБ GDDR5-памяти уже на саму плату — но это лишь наши мечты, напомним. Для такой реализации в GPU потребуется ставить контроллеры двух типов памяти, что точно не обойдется дешево, особенно в случае широкой шины для GDDR5. И вряд ли в игровых решениях подобное будет востребовано. Зато мы почти уверены в том, что менее дорогие и производительные графические процессоры архитектуры Vega могут вовсе не использовать HBM2-память, а ограничиться привычной GDDR5-памятью, что как раз подойдет для решений среднего ценового уровня.
Что касается конкретных характеристик будущего топового решения, то если продолжать наши догадки, основанные на полученных от AMD данных и добавить к ним информацию о профессиональном решении в виде Radeon Instinct MI25, основанном на графическом процессоре Vega 10, то мы предполагаем, что будущий топовый GPU будет производиться при помощи 14 нм FinFET-техпроцесса, иметь на борту 8 или 16 гигабайт HBM2-памяти с 2048-битной шириной шины памяти и пропускной способностью в 512 ГБ/с.
Судя по озвученным для Radeon Instinct MI25 данным о 25 терафлопс для FP16-точности (и 12,5 терафлопс для FP32, соответственно), а также 128 операций с FP32 за такт для каждого NCU, графический процессор Vega предположительно может включать 64 таких блока (и 4096 ALU всего, соответственно), работающих на частоте чуть выше 1,5 ГГц. При этом, весь GPU должен потреблять менее чем 300 Вт энергии, как в случае специализированной вычислительной карты. Пожалуй, на данный момент это все, что можно предположить о графическом процессоре Vega 10.
Технология вывода на дисплей FreeSync 2
Почти в одно время с анонсом Vega компания AMD решила обновить свою дисплейную технологию FreeSync. Мы уже неоднократно рассказывали о том, почему понадобилось придумывать какие-то новые режимы синхронизации и выпускать программно-аппаратные решения вроде технологии AMD FreeSync, которая помогает устранять артефакты, возникающие при выводе изображения на экран, а также неплавность частоты кадров и увеличенные задержки между действиями пользователя и выводом изображения.
Компания AMD вышла на рынок со своей технологией динамической синхронизации в марте 2015 года, значительно позднее конкурирующей G-Sync от Nvidia. Зато, вместо создания собственного проприетарного решения, компания решила использовать опциональную возможность стандарта VESA DisplayPort, известную под названием Adaptive-Sync, которая позволяет использовать динамически изменяемую частоту обновления на поддерживающих это мониторах. Со временем AMD отыграли имеющееся отставание по возможностям FreeSync по сравнению с G-Sync, и смогли добиться как минимум паритета по техническим показателям.

Технология компании постоянно улучшалась, в августе того же 2015 года на рынке появился первый монитор с поддержкой FreeSync, работающей в пределах от 30 до 144 Гц частоты обновления, в ноябре появилась компенсация низкой частоты кадров (LFC), позволяющая еще больше улучшить плавность, а в феврале 2016 вышел первый FreeSync-монитор уже с поддержкой HDMI (прежде аналогичные технологии работали исключительно через DisplayPort). А из самого нового можно отметить то, что технология FreeSync стала поддерживать приложения, работающие в полноэкранном оконном режиме (borderless window).
Несмотря на более поздний анонс, поддержка стандартной технологии позволила получить более широкое сотрудничество с производителями аппаратного обеспечения. По данным компании AMD, у них сейчас есть соглашения с 20 партнерами по производству мониторов с поддержкой их технологии FreeSync, по сравнению всего лишь с восемью у конкурирующей технологии G-Sync от Nvidia. Также уже вышел 121 монитор с поддержкой FreeSync, а поддержка аналогичной технологии конкурента имеется только в 18 мониторах, доступных на рынке.
Среди сравнительно новых устройств с поддержкой FreeSync можно отметить такие интересные модели, как:

BenQ XL2540 — монитор с размером экрана 24,5", разрешением 1920×1080 пикселей, работающий с частотой обновления 48—240 Гц и обладающий поддержкой компенсации низкой частоты кадров LFC.

Acer XF270HU — дисплей с 27-дюймовым экраном разрешения 2560×1440 пикселей, поддержкой частоты обновления 40—144 Гц и LFC.

Samsung C34F791 — изогнутый монитор с размером экрана в 34" и технологией производства на основе квантовых точек, с разрешением 3440×1440 пикселей, частотой обновления экрана от 48 до 100 Гц, также обладающий поддержкой LFC.
Сама по себе технология динамического изменения частоты обновления экрана явно исчерпала свои возможности по улучшению и дальнейшему развитию, но в AMD нашли иной путь для продолжения работы по снижению задержек вывода изображения, связанный с HDR-дисплеями. Общеизвестно, что в скором времени ожидается массовый выход и соответствующий всплеск интереса к HDR-устройствам: мониторам и телевизорам, позволяющим выводить изображение с большим динамическим диапазоном яркости и большим количеством отображаемых цветов. К примеру, общепринятый стандарт HDR10 позволяет отображать в 8 раз большее количество цветов, по сравнению с sRGB:

Пока что поддержка HDR-дисплеев продвигается в ПК-играх с большим скрипом, и это связано с некоторыми сложностями, включающими отличающиеся характеристики таких дисплеев. В AMD нашли возможность для стандартизации и упрощения процесса. При текущем положении дел, для вывода HDR-изображения приходится делать tone mapping (приведение одного диапазона отображения к другому) дважды: в игровом движке приводить внутренний диапазон HDR к стандарту HDR10, а затем еще один процесс tone mapping делает и сам HDR-дисплей, приводя изображение, соответствующее стандарту HDR10 к своим конкретным возможностям, которые у продающихся сейчас моделей ниже характеристик HDR10.
Сразу же видны недостатки: во-первых, делать дважды tone mapping нелогично, если это можно сделать лишь один раз, приведя яркостный и цветовой диапазон сразу же к возможностям дисплея, а во-вторых, из-за второго процесса tone mapping, проходящего в дисплее, значительно увеличиваются задержки вывода изображения, что ухудшает играбельность в динамичных проектах. И как раз для улучшения всего HDR-конвейера AMD и выпустила новое поколение технологии — FreeSync 2, которое служит для решения этой проблемы, снижая лаг (input lag):

Вместо того, чтобы делать tone mapping дважды, AMD предлагает делать его один раз — исключительно в игровом движке, выводя HDR-изображение на дисплей сразу же в яркостный и цветовой диапазон, точно поддерживаемый HDR-монитором. Такой подход позволяет получить качественное изображение, снижает количество работы и уменьшает задержки между действиями игрока и выводом изображения.
Нам обещано упрощение использования HDR-дисплеев и снижение задержек, которое будет строго контролироваться AMD (они говорят о нескольких миллисекундах), а также увеличение динамического диапазона и количества цветов вдвое, по сравнению с возможностями sRGB. Вдвое — это для начала, в будущем диапазон HDR может измениться, но на данный момент в AMD считают именно удвоенный sRGB оптимальным для первых HDR-дисплеев на рынке, включая самые лучшие из них по диапазону отображаемой яркости и цветов.

Но почему бы просто не использовать стандарт HDR10? Все просто — это в любом случае потребует второго шага tone mapping, так как даже лучшие HDR-дисплеи сейчас пока что далеки по возможностям от HDR10 — стандарта, рассчитанного на несколько лет развития дисплеев. Соответственно, даже лучшие из HDR-устройств, которые выйдут в ближайшие годы, не могут выводить весь диапазон яркости и цвета, поддерживаемый HDR10, и придется приводить его к возможностям монитора, что и приводит к повышению задержек.
Также очень полезно, что FreeSync 2 поддерживает автоматическое переключение между режимами SDR (вывод обычных приложений и рабочего стола) и HDR (игры и видеоролики), только тогда, когда это необходимо, чтобы не приходилось делать это вручную, так как некоторые настольные приложения некорректно выглядят в HDR.
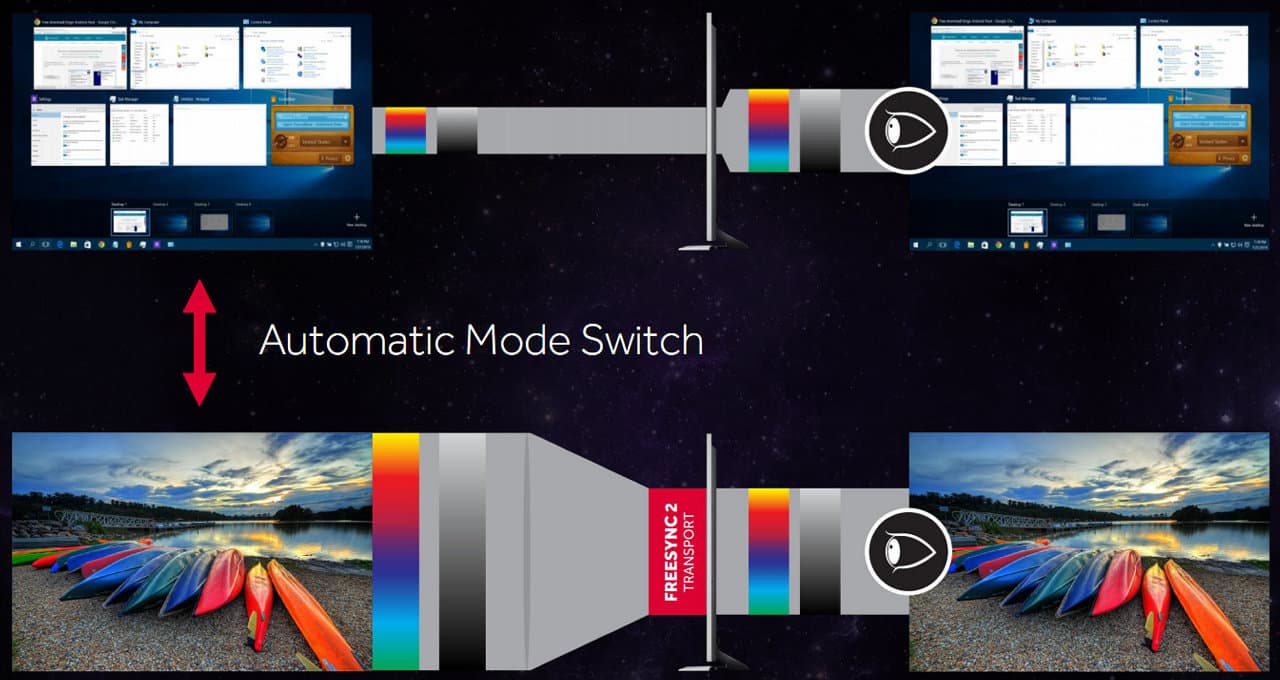
Игровым проектам, использующим HDR, нужно будет вызывать функции специального FreeSync 2 API, который позволит движку игры определить возможности подключенного к системе HDR-дисплея и привести изображение к соответствующему виду самостоятельно. Получается, что FreeSync 2 — это уже далеко не просто технология для синхронизации и повышения плавности вывода кадров на монитор, но и для достижения максимально качественной картинки с наименьшими задержками.
По сути, FreeSync 2 — это полноценный HDR-конвейер для вывода изображений от AMD, который будет поддерживаться всеми устройствами с сертификацией FreeSync 2. Появление на рынке мониторов с поддержкой анонсированной технологии ожидается в 2017 году. Пока что FreeSync 2 является проприетарной технологией, но в AMD работают над его стандартизацией. Еще одна важная деталь — новая версия технологии не ограничена новейшим графическим процессором Vega, а будет работать на всех решениях компании, поддерживающих технологию FreeSync первого поколения.
Отдельно отметим, что для получения сертификата соответствия FreeSync 2, дисплей обязательно должен поддерживать и компенсацию низкой частоты кадров LFC. То есть, монитор должен будет уметь работать в достаточно широком диапазоне частоты обновления, что не было обязательным для мониторов с поддержкой первой версии FreeSync. А сертификация FreeSync 2 будет гарантировать игроку максимально возможный комфорт.


