Интервью с Энди Кином из Nvidia
Вопросы по вычислениям на GPU, архитектуре CUDA и решениям Tesla

Применение графических процессоров в вычислениях общего назначения становится всё более распространенным. GPU помогают решать научно-исследовательские и прикладные расчётные задачи в медицинской, нефтегазовой, финансовой и многих других отраслях. Для обозначения этих расчётов ранее применялся термин — GPGPU, который предполагает использование возможностей графических API, а теперь Nvidia применяет название GPU Computing (вычисления на GPU), что подчёркивает использование стандартных языков программирования (Си, Fortran и др.), а не шейдерных языков OpenGL и DirectX.
Весьма значительную роль в продвижении вычислений на GPU сыграла компания Nvidia. Программно-аппаратная архитектура Nvidia CUDA анонсирована почти три года назад и уже довольно давно применяется на практике. В начале июня мы получили возможность побеседовать с Энди Кином (Andy Keane), генеральным менеджером по высокопроизводительным вычислениям в компании Nvidia, и задали ему несколько вопросов.
iXBT.com: Здравствуйте, Энди! Спасибо за отличную возможность прояснить несколько вопросов по вычислениям на GPU, Nvidia CUDA и Tesla. Начнём с вопроса о CPU и GPU. Лучшие многоядерные процессоры обеспечивают высокую эффективность в некоторых приложениях, особенно в вычислениях с двойной точностью (double precision). Они универсальны и легки в программировании. Есть ли какие-либо преимущества у систем на базе GPU по сравнению с аналогичными решениями, основанными исключительно на универсальных CPU?
Энди Кин: Да, конечно! Вы знаете, я думаю, что CPU относительно просты в программировании только однопоточных приложений. Но когда вы пытаетесь перевести расчёты в параллельные для исполнения на нескольких ядрах, это уже становится не так уж просто.
Цель CUDA в том, чтобы сделать программную модель для решения проблем параллельного программирования, и сделать её как можно более простой, чтобы решить проблемы распараллеливания при переносе программы на более сложное устройство. В CUDA мы внедрили программную модель, которая позволяет людям писать параллельные программы для GPU. Для примера можно взять случай двухлетней давности с переносом алгоритма N-Body на G80, он прекрасно работает и на современных решениях.
Отличие GPU от CPU в том, что его вычислительные ядра работают параллельно, что хорошо подходит для обработки больших объемов данных, а CPU лучше работает с меньшими объемами данных, и исполняет меньше потоков одновременно, так как предназначени для выполнения последовательных задач. Кроме того, CPU нуждается в эффективном кэшировании, и поэтому имеет многоуровневую систему кэш-памяти. Проблемы появляются тогда, когда размер данных превышает размер кэша — производительность CPU в таком случае сильно снижается.
Поэтому одно из слабых мест применения CPU в высокопроизводительных вычислениях — это большие объёмы данных. Даже в том случае, если модель программирования относительно проста, универсальный процессор нуждается в том, чтобы вместить все необходимые данные в кэш.
Программирование на GPU имеет свои особенности. Речь идёт исключительно о параллельных расчётах, так как 3D графика сама по себе очень параллельна. В случае с GPU мы знаем, что данные никогда не поместятся в кэш. Поэтому архитектура GPU использует многопоточность и сокрытие задержек обращения к памяти. Поэтому, если ваша задача хорошо распараллеливается и использует большие объёмы данных, то GPU будет намного более эффективен в таких задачах. Но если задача небольшая, и не очень хорошо подходит для параллельной обработки, то нужно использовать CPU.
И хотя CPU постепенно двигаются в направлении решения задач с большим объёмом данных и высокой степенью параллелизма, а GPU — в сторону эффективного исполнения нерегулярных задач с меньшим количеством параллельных вычислений, всё-таки они совершенно разные. Универсальный процессор предназначен для исполнения всевозможных задач, он обязан быть эффективным при исполнении кода операционной системы и прикладных программ. А GPU, в свою очередь, предназначен для графических задач и задач с высокой степенью параллелизма. И задачи у каждого из них свои специфические.
С точки зрения конкретных приложений, у Nvidia есть много примеров от множества разработчиков из России и других стран. CUDA позволяет программистам очень быстро получить значительное ускорение от переноса вычислений на GPU. Nvidia уже помогла многим разработчикам успешно перенести свои приложения на GPU при помощи С-компилятора и утилит для разработчиков.
iXBT.com: Как Вы уже сказали, не каждое приложение и задача хорошо подходит для параллельных вычислений на GPU. Расскажите нам о наиболее интересных вычислительных проектах, основанных на Nvidia CUDA и Tesla.
Энди Кин: Есть множество повседневных приложений, которые требуют многочисленных параллельных расчётов. Например, любая обработка видео и изображений, но не только это. Мы видим возможности применения для GPU практически в любой сфере: анализе и обработке больших объёмов информации (data mining), вычислительной математике, динамике жидкостей и газов, и многом другом. У нас есть множество активных проектов с разработчиками, которые используют расчеты методом конечных элементов в промышленном дизайне. Использование GPU помогает им выполнять свою работу значительно быстрее, чем ранее.
Но, думаю, что наиболее интересные задачи — это всё же исследовательские проекты. Я могу назвать много примеров таких проектов, в том числе и российских. На GPU решается множество параллельных задач: физика, молекулярная динамика и т.д. Исследователи получают большие приросты при переносе своих задач на GPU: 10-кратные, 20-кратные, 100-кратные… Такие цифры просто невозможны на CPU, так ведь? Новые модели универсальных процессоров дают ускорение обычно менее чем в два раза, а при использовании GPU можно получить ускорения на порядки. И разработчики нуждаются в таких приростах производительности, которые они не могут получить на многоядерных универсальных CPU.
Поиск применений CUDA в Google даёт ссылки на множество документов, которые описывают подобные проекты. Также, на нашем сайте CUDA Zone указаны сотни применений CUDA. Они охватывают почти все сферы, где применяются ресурсоёмкие расчёты: и в коммерции, и в науке.
iXBT.com: Перейдём к вопросам об аппаратной и программной архитектуре. Не так давно Nvidia выпустила OpenCL драйвер для разработчиков. Он пока что не публичный, но заинтересованные разработчики уже начали его использование. Вы считаете, что интерфейсы, не привязанные к одному из вендоров, такие как OpenCL и Compute Shader, важны для Nvidia?
Энди Кин: Почему существует очень много языков программирования для CPU? Почему бы не ограничиться только одним? Дело в том, что все эти языки имеют специфические особенности, которые могут пригодиться в определенной задаче. C++ прекрасно подходит для решения практически любых задач, но программисты используют и Fortran, Java и другие языки. Всё это справедливо и для GPU.
Цель наших партнёров, работающих в разных отраслях, заключается в том, чтобы ускорить расчёты, связанные с их работой. Это позволит им зарабатывать больше денег, эффективнее использовать ресурсы и т.д. И им совершенно не обязательно использовать универсальный язык программирования. К примеру, во многих случаях расчётные задачи нефтегазовой индустрии используют Fortran. И поэтому наши специалисты помогают Portland Group в разработке компилятора Fortran для GPU.
Мы поддержим и OpenCL, и Fortran, а для других языков, таких как Java и Python, будут доступны библиотеки. Например, Image Processing Library, которая поможет при обработке изображений на GPU. Также, как вы знаете, у нас есть и собственный C-компилятор.
Полагаю, что смысл вашего вопроса заключается в выборе между OpenCL и собственным компилятором. Так вот причины, по которым у нас есть свой C-компилятор — те же самые, по которым у компании Intel есть свой компилятор для CPU. Они продают свой компилятор, хотя каждый может скачать C-компилятор и бесплатно (взять тот же GCC). Но Intel продаёт свой программный продукт, и довольно успешно. Они могут вносить изменения и оптимизации в свой компилятор, делать с ним всё, что угодно, не спрашивая никого. Вот и в наш компилятор мы добавили расширения для параллельных расчётов, а в остальном — это обычный Си.
Nvidia поддерживает все стандартные языки, такие как C и Fortran. И мы продолжим улучшать и расширять поддержку GPU для них. Также мы поддерживаем OpenCL, как открытый программный интерфейс, он очень важен для рынка, и на сегодняшний день его поддержка фактически обязательна.
По аналогии с этой ситуацией посмотрите на наиболее популярный графический API — DirectX. Ведь он закрытый. А конкурирующий с ним OpenGL — это открытый стандарт. Поддержка OpenGL обязательна, так как многие проекты используют его, но разработчики выбирают между двумя этими API, и в основном используют DirectX…
iXBT.com: Но ведь DirectX не привязан ни к одному из производителей GPU.
Энди Кин: Конечно, но он контролируется одной компанией. Та же CUDA также не имеет привязки к одному производителю. Ведь это язык C, и тот же самый подход к программированию, что и в OpenCL. И во многом похожий на DirectX Compute Shader. Вы даже можете сказать, что это случайное совпадение, или что Nvidia помогла сделать поддержку вычислений на GPU в OpenCL и DirectX, настолько они похожи.
А вообще, выбор языка программирования не так уж важен, это просто метод решения проблемы. Вот вы, журналисты, следуете примерно тому же процессу при написании статей, что и программист, пишущий код. Когда программист берётся за задачу, он не начинает сразу писать код на языке программирования. Он сначала думает о подходе, о необходимой для решения задачи информации, входных данных, о структуре программы.
Примерно так же и вы делаете, когда садитесь за статью. Сначала думаете, как решить стоящие перед вами задачи, и только потом начинаете писать текст. И будет ли это текст на русском или английском языках, саму задачу Вы уже решили ранее, в голове. И это решение одинаково, независимо от выбранного языка. Многие люди придают слишком много значения выбору языка программирования. Но по сути это неважно, ведь путь к решению задачи — это анализ задачи в голове. А затем её выполнение любым удобным способом.
Во многом, языки программирования GPU весьма схожи. Так, компания Apple показывала примеры N-Body и FFT для OpenCL. Их очень легко перенесли из CUDA SDK, так как они очень близки. Это был практически прямой перенос из CUDA в OpenCL.
В общем, всё, что понадобится разработчикам, мы будем поддерживать. Но вот ещё про OpenCL… Можно сказать, что на данный момент этот стандарт пока что не существует на рынке. Вот мы выпустили OpenCL драйвер, и он по качеству и оптимизации постепенно будет приближаться к нашему C-компилятору. Посмотрим, что выберут разработчики.
iXBT.com: Итак, CUDA, Compute Shader и OpenCL основаны на языке Си. Но некоторые из программистов хотели бы программировать GPGPU приложения на C++. Будет ли это возможным в будущих версиях Nvidia CUDA?
Энди Кин: Мы слышали те же самые пожелания от разработчиков, и в следующем году мы планируем поддержать C++ в CUDA. Но я думаю, что многие разработчики используют язык C, не C++. И мы начали разработку именно C-компилятора потому, что этот язык относительно прост, он появился ещё в 1960-х. А компилятор C++ имеет много компонентов, которые должны работать совместно, и сделать подобный продукт намного сложнее.
Наш план заключается в том, чтобы начать с языка Си, убедиться, что GPU хорошо взаимодействует с разработанным компилятором, и лишь затем добавлять поддержку новых инструкций C++. Ведь любой C++ программист может писать и код на C, им просто предпочтительнее возможности и структурность C++. И мы обязательно дадим им такую возможность в будущем.
iXBT.com: Изначально Nvidia CUDA была собственной средой разработки с Си-подобным языком программирования. Почему теперь CUDA позиционируется как архитектура для вычислений на GPU, а не свой язык программирования?
Энди Кин: В самом начале, мы называли всё связанное с вычислениями на GPU одним именем — CUDA. Архитектуру, язык, драйвер, утилиты… Даже Си-компилятор. Но мы также всегда подразумевали под CUDA и аппаратную архитектуру, потому что когда GPU работает в виде GPGPU, он действительно переключается в другой режим. При работе с 3D графикой GPU работает весьма специфично, а когда он работает в режиме CUDA, все блоки, которые работают с текстурами, вершинами, треугольниками и другими графическими примитивами, используют другие типы данных. Работа над графикой и вычислениями общего назначения — это разные режимы, и архитектуру для работы в «вычислительном» режиме мы называем CUDA.
Также мы называем CUDA и наш набор утилит для разработки GPGPU приложений, и это действительно может немного запутать людей. Но язык программирования там — обычный Си. Некоторые разработчики могут сказать: «Я не умею программировать на CUDA!», но язык CUDA — это тот же Си. На самом деле, мы используем C++ frontend от Edison Design Group (EDG), и основной компилятор — PathScale Open64. Мы опубликовали исходный код, и любой человек может его скачать: открытый код EDG, открытый код Open64, публичные спецификации нашего низкоуровневого языка PTX для GPU.
Наша задача в том, чтобы язык мог быть поддержан другими GPU и CPU. Фактически, используемый в CUDA язык открыт, и нет никаких преград для того, чтобы компилятор начали использовать все заинтересованные лица. Посмотрите, почти у всех вендоров есть Си-компиляторы, кроме ATI. У AMD есть, у Intel есть, у Nvidia есть, а у ATI нет. Не знаю почему, но они его не сделали.
iXBT.com: А получит ли какие-либо преимущества разработчик при использовании компилятора Nvidia, по сравнению с OpenCL и другими средами программирования?
Энди Кин: В общем, единственное преимущество состоит в том, что CUDA существует уже сейчас. А OpenCL — это новый API, который ещё не вышел. И в этом — огромная разница по сравнению с CUDA. Хотя, повторюсь, OpenCL выглядит очень похоже на CUDA. И если вы сейчас пишете на CUDA, то сможете очень легко перенести свой код и на OpenCL. А вот обратный переход не так прост, так как OpenCL имеет опции для CPU, и он не так чётко описан, по сравнению с CUDA.
Одним из отличий между этими API является то, что OpenCL больше похож на шейдерный язык, и для людей, которые используют OpenGL для графики, OpenCL будет удобен потому, что они схожи. Но некоторые возможности из языка Си, которые есть в CUDA, недоступны в OpenCL. Поэтому людям, которым близок код на Си, OpenCL предлагает новую концепцию. Это другой язык, он параллельный и с немного отличающимся подходом, но в целом с его помощью можно решать примерно те же самые задачи.
iXBT.com: Вопрос по аппаратной архитектуре. Как вы считаете, тренды развития 3D GPU и GPGPU расходятся, или GPGPU — это дальнейшее развитие 3D графики? Специфические изменения для CUDA пригодятся и для 3D приложений?
Энди Кин: Да, на данный момент всё так и есть. Развитие 3D графики, идущее от фиксированной функциональности к программируемости и развитие возможностей вычислений на GPU во многом совпадают. Нет никаких гарантий, что оба тренда всегда будут идти параллельно друг другу, и не разделятся в какой-то момент, но сейчас 3D расчёты и вычисления на GPU, а также то, что мы делаем для программирования графики и GPGPU расчётов в будущем — это в целом одна и та же аппаратная архитектура.
Конечно, у каждой архитектуры есть свои особенности, такие как расчёты с двойной точностью. К видеочипам добавляются такие возможности, как специфические для расчётных задач на GPU, ведь графике не нужна двойная точность.
iXBT.com: А видит ли Nvidia смысл в разработке отдельного чипа специально для рынка HPC? Только для решений Tesla, не для Geforce.
Энди Кин: Основная причина того, что мы этого не делаем, заключается в том, что рынок HPC сам по себе недостаточно велик, чтобы разрабатывать для него специальный процессор. Я думаю, это было доказано неоднократно, и как наиболее свежий пример можно взять банкротство ClearSpeed. Посмотрите на стоимость разработки высокопроизводительных CPU и GPU, это цифры порядка 400-500 миллионов долларов. И мы хотим выйти на рынок, который не только отработает стоимость разработки, но и принесёт нам прибыль, которой мы поделимся с акционерами.
Для примера можно посмотреть на компанию Intel. Разработка их процессора Xeon, который используется в серверах на HPC рынке, во многом оплачена покупателями обычных настольных процессоров. Это стандартная практика, которая приносит деньги.
На рынке GPU работает тот же самый принцип. Мы продаём наши технологии игрокам в виде решений для настольных компьютеров и ноутбуков, а потом те же самые технологии, хотя и с небольшой разницей, переходят в HPC решения. Это — общепринятая модель развития бизнеса. Мы получаем прибыль с предыдущего чипа, и можем использовать её для разработки нового чипа. Получаем дополнительные деньги с рынка HPC и инвестируем их в следующий GPU.
Не думаю, что текущее состояние индустрии и экономики позволяет нам делать процессоры, которые предназначены исключительно для HPC. Предполагаю, что скоро последуют вопросы по Larrabee, и считаю, что как раз описанные выше проблемы делают Larrabee сложным проектом для Intel. Потому что этому чипу обязательно нужно будет конкурировать и на рынке GPU. А чтобы быть успешным на этом рынке, нужно выпускать видеочипы лучше, чем у ATI и Nvidia. И если Larrabee таким не будет, то его выпуск не будет оправдан экономически, что не обеспечит возможности двигаться вперёд, и не понравится акционерам. У Intel отличный бизнес по производству универсальных процессоров, и слабый GPU будет не самым удачным вложением средств.
iXBT.com: Поддержка расчётов с двойной точностью необходима не только для Tesla, но и для видеочипов нижнего ценового диапазона?
Энди Кин: Да, основные возможности всей линейки GPU должны быть одинаковы. С точки зрения разработчика программного обеспечения нужна одна программная модель для всех чипов. Пусть чипы обеспечивают разную скорость, GPU в ноутбуке медленнее, чем в настольном ПК, но все они должны одинаково программироваться. Nvidia и разработчики заинтересованы в том, чтобы один код работал на всех решениях одинаково.
Профессиональные решения, такие как Quadro и Tesla, по сравнению с Geforce могут иметь дополнительные возможности, но основная программная модель должна быть единой. Так что ответ — да, поддержка расчётов двойной точности обязательна для всех решений Nvidia.
iXBT.com: А как Вы считаете, достаточно ли хороша и эффективна поддержка расчётов с двойной точностью в последних GPU компании Nvidia?
Энди Кин: Она хороша с точки зрения разработчиков ПО, и некоторые из них уже используют эту возможность на наших GPU. Существует определённый круг приложений, которые требуют и используют расчёты с двойной точностью. И это традиционный код для HPC приложений, например в финансовой сфере. Но не все приложения нуждаются в двойной точности, некоторым достаточно одинарной, а в других двойная точность нужна, но не во всех расчётных алгоритмах. И в таких случаях очень высокая производительность расчётов с двойной точностью не требуется.
Ранние GPU поддерживали только одинарную точность, а с современными чипами мы можем создать основу для серьёзных расчётных задач с вычислениями двойной точности. Если посмотреть на цикл разработки большинства приложений, это время около 6-12 месяцев. Поэтому начать разработку можно и нужно на нынешних чипах, а затем новые решения выйдут на рынок, и будут иметь большую производительность в расчётах двойной точности.
Посмотрите на эволюцию CPU. Математические сопроцессоры 8087, 80287, 80387 были намного быстрее программных расчётов, но значительно медленнее последующих аппаратных решений. Затем появились SSE, SSE2, SSE3 — каждое расширение из этого списка было развитием предыдущих, но быстрее и эффективнее. Примерно то же самое происходит и с GPU. В G80 не было двойной точности, в GT200 она появилась, как и большее количество вычислительных блоков и т.д. Это просто процесс развития GPU.
iXBT.com: Что Вы можете рассказать о наиболее важных планируемых изменениях в CUDA 3.0?
Энди Кин: В основном, CUDA 3.0 — это развитие предыдущих версий. Там не будет действительно больших изменений, в основном планируются модификации программной модели, которые ждут от нас разработчики. Для примера можно привести поддержку 3D текстур в CUDA 2.2. Вот что-то вроде таких не очень крупных изменений будет в следующей версии CUDA.
Сейчас мы занимаемся теми улучшениями, которые делают работу программистов более удобной. Зарегистрированные разработчики шлют нашей группе поддержки CUDA запросы тех функциональных возможностей, в которых они нуждаются, и мы их постепенно вводим. В целом же, базовое развитие CUDA закончено, язык обладает всеми основными возможностями. В CUDA 3.0 не будет полной поддержки C++, это будет несколько улучшенная и дополненная версия по запросам разработчиков.
iXBT.com: Пришло время долгожданных всеми вопросов по Intel Larrabee, если Вы не возражаете.
Энди Кин: Я так и знал! Ничего-ничего, задавайте, вопросы про Larrabee довольно забавны… А Вы принесли Larrabee с собой? Я очень надеюсь увидеть его воочию, а то пока что видел только на картинках…
iXBT.com: Нет, к сожалению, у нас его тоже нет. Но мы слышали, что Larrabee — это GPU, основанный на x86 архитектуре. Считаете ли Вы такой путь правильным, или набор инструкций x86 плохо подходит для GPU, на Ваш взгляд?
Энди Кин: Знаете, некоторые люди из компьютерной индустрии говорят, что архитектура процессоров Intel не очень хороша и для обычных вычислений… Вообще, x86 появилась в 70-х годах прошлого века как процессорная архитектура, и ещё большой вопрос, как она покажет себя в графических приложениях.
Я думаю, что это вполне понятное решение для компании Intel. Может быть вы знаете, есть такая английская фраза: «Если у вас есть только молоток, то всё вокруг кажется похожим на гвоздь.» («If all you have is a hammer, everything looks like a nail.»). Так вот у них есть этот молоток, и это архитектура x86. Они стараются решить все свои задачи, используя один и тот же инструмент.
Никто ведь не нуждается в запуске Windows и существующих программ на GPU. А вот представители Intel в прошлом году сделали несколько заявлений о том, что можно взять любой x86 код и выполнить его на Larrabee. Мы попросили некоторых журналистов, чтобы они пошли и спросили Intel: «Правда? Я могу взять любое приложение, и без изменений запустить его на Larrabee?» И ответы были такие: «Ну, может и не любое… Возможно, потребуются некоторые изменения…»
Иными словами, бинарной совместимости нет, как нет и необходимости в ней. Все пишут программы на высокоуровневых языках, таких как C и C++, и для них каждый процессор выглядит одинаково. И я не уверен, что архитектура x86 — это преимущество Larrabee.
iXBT.com: Кроме архитектуры, Larrabee отличается иерархией кэш-памяти с когерентностью для всех исполнительных ядер. Что Вы думаете о такой реализации и предвыборке данных (prefetching), поддерживаемой этим GPU, пусть пока и на бумаге?
Энди Кин: Думаю, что это разработчики CPU в Intel настояли на такой концепции кэш-памяти. Для графических чипов такая система неэффективна, и до сих пор не существует графических чипов, имеющих слишком большой объём кэш-памяти. Это будет первый подобный GPU.
Larrabee имеет весьма радикальный дизайн во многих областях. Это шаг в сторону от основного направления развития графических чипов. Вообще, я не рассматриваю его как GPU, скорее это CPU, используемый и для графических расчётов в том числе. И я не знаю, как он покажет себя в графике. Думаю, что пока этого никто не знает, даже Intel.
Кроме того, они опаздывают со сроками выхода решения. Intel ранее объявляла, что Larrabee выйдет в этом году, но я не думаю, что он выйдет в 2009. Возможно, свой GPU они выпустят в следующем году. Трудно сказать что-то определённо…
iXBT.com: Хорошо, с Larrabee закончили, давайте перейдём к вопросам по Nvidia Tesla. Насколько успешным был запуск персональных суперкомпьютеров и кластеров Tesla Preconfigured Cluster на рынке высокопроизводительных вычислений (HPC)? Насколько широко системы Tesla используются в кластерах и суперкомпьютерах?
Энди Кин: Решения были приняты на рынке очень хорошо. Список кластеров, в которых используется Tesla, большой, я расскажу вам только о некоторых из них. Например, это суперкомпьютерный центр в Австралии (CSIRO), состоящий из 800 вычислительных ядер CPU Xeon на частоте 2,8 ГГц и 50 Tesla S1070 систем (200 GPU), с производительностью более 200 TFLOPS. Исследователи CSIRO уже получили 10-100-кратные приросты в научных приложениях при вычислениях на видеочипах Nvidia. Есть кластеры в Argonne National Lab, Гарварде, Кэмбридже и других университетах, лабораториях и центрах.

Очень много систем используется в европейских странах, у нас есть небольшие кластеры и в России. Как видите, системы Tesla используются по всему миру. Так что можно уверенно сказать, что запуск кластеров и суперкомпьютеров на основе Tesla был весьма успешным.
В первых числах июня мы анонсировали разработанный совместно с компанией SuperMicro вычислительный сервер формата 1U, использующий GPU Tesla. Эта система обладает вычислительной мощностью более чем в 2 терафлопа, что значительно превышает производительность обычных 1U-серверов, использующих только CPU.

Эти серверы оснащены двумя четырёхъядерными процессорами Intel Xeon 5500, поддерживают работу с DDR3 памятью до 48 Гб на процессор, и включают две карты Nvidia Tesla M1060 или C1060. Размещение в формате 1U важно потому, что люди хотят объединять сотни таких систем в одном кластере.
Альтернативой 1U могут быть две отдельные системы, одна с CPU, другая с GPU. Для тех, кто хочет постоянно улучшать показатели производительности своих кластеров, будут интересны и отдельные решения, так они позволяют модернизировать парк CPU и GPU отдельно друг от друга. Но во многих отраслях, таких как нефтегазовая промышленность, исследователи выберут систему в одном 1U корпусе, и будут использовать её несколько лет.
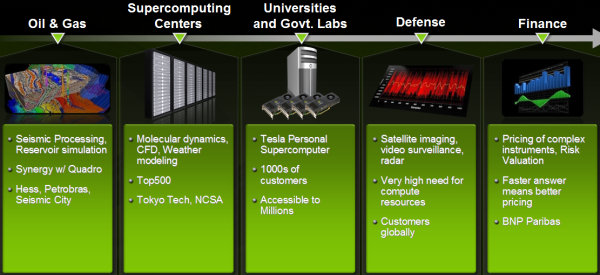
Наши системы используются в разных отраслях: нефтегазовой промышленности, университетах и лабораториях, вычислительных центрах, оборонной промышленности, финансовых учреждениях. Множество государственных агентств по всему миру используют GPU для анализа сигналов. В финансовой сфере Tesla применяют BNP Paribas, Bloomberg и другие известные компании.

Представленные кластеры в формате 1U на базе Tesla отличаются лучшим соотношением производительности на Ватт, по сравнению с конкурентами, основанными на CPU. Это важнейшие показатели, потому что почти все вычислительные центры ограничены именно количеством потребляемой электроэнергии. Вы можете построить большое здание, но если вы не можете обеспечить его электропитанием, то это бесполезно.
iXBT.com: На слайдах указаны цифры реальной производительности?
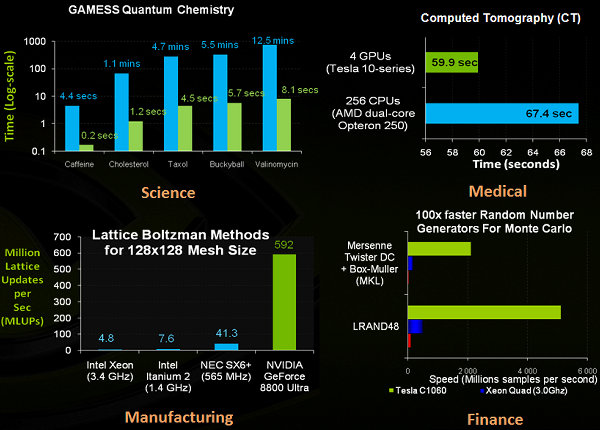
Энди Кин: Да, это производительность приложений, расчёты в которых перенесены на Tesla GPU. Вот более подробные цифры, полученные исследователями при помощи наших решений из разных сфер. Все эти расчёты очень важны для исследователей в медицине, науке, финансах и промышленном производстве.
Когда мы начали заниматься высокопроизводительными вычислениями, то люди в основном сами собирали системы, кластеры и рабочие станции, использующие GPU для расчётов. А теперь мы объединили всё необходимое, и предлагаем готовые сконфигурированные кластеры в виде модульных компонентов для создания высокопроизводительных вычислительных систем.
iXBT.com: А какие ещё приложения для GPGPU Вы могли бы выделить?
Энди Кин: Мы уже говорили о разных типах приложений, но я расскажу вам ещё о том, как GPU используется в компании Nvidia. Мы используем CUDA в двух применениях. Первое — TCAD (Technology Computer Aided Design), мы используем инструменты от компании Agilent, часть расчётов в которых перенесена на GPU.
Расчёты на графических процессорах помогают при анализе электромагнитной интерференции в разработке печатных плат для видеокарт и ноутбуков. Эти вычисления проводятся намного быстрее, чем при использовании CPU: 4 часа на GPU, против 8 дней на CPU. И наши дизайнеры получают ответы на интересующие их вопросы в тот же день, они не должны ждать следующей недели.
Также CUDA применяется при тестировании и диагностике работоспособности собранных плат после припаивания на них чипов. У чипов в BGA (ball grid array) упаковке контакты выполнены в виде маленьких шариков из припоя, а на печатной плате — медные площадки. В процессе сборки платы, GPU помещается на печатную плату, и конструкция нагревается в специальной машине (reflow soldering). В результате нагрева шарики из припоя плавятся и образуют контакт между чипом и проводниками на PCB.
В некоторых случаях, платы могут оказаться неработоспособными. После нагрева и последующего охлаждения печатная плата может изменить форму и контакт с чипом нарушится. Чтобы обнаружить подобные проблемы, плату просвечивают рентгеновскими лучами и изучают снимки. Но даже так выяснить истинную причину неполадки остаётся непростым делом.
Кроме этого, если припой нагревается слишком сильно, возле контактов могут возникать пузырьки газа, влияющие на надёжность соединения. Для изучения подобных эффектов используется специальное программное обеспечение, которое реконструирует поверхность контактов в трёх измерениях, используя анализ серии рентгеновских снимков высокого разрешения. Процесс этот весьма ресурсоемкий, и может быть ускорен при помощи CUDA. Например, на процессоре Core 2 Duo подобный анализ занимает более часа, на видеокарте с одним GPU — 7 минут, на четырех GPU — около минуты.
В общем, есть множество очень важных приложений для CUDA. Например, сканирование груди при исследовании раковых опухолей. Компания TechniScan из США разработала технологию, использующую ультразвуковое сканирование, а не рентгеновское. Это даёт возможность сканирования груди без риска облучения, при этом оно ещё и проводится быстрее и даёт более точные результаты, по сравнению с рентгеновским.
Одним из моих любимых применений CUDA является дизайн одежды. Израильская компания OptiTex разработала пакет ПО OptiTex 3D, при помощи которого дизайнеры одежды могут моделировать внешний вид своих коллекций в движении, увидеть недостатки в виртуальном воплощении и усовершенствовать одежду. Пакет использует очень точную симуляцию поведения ткани, и в этой программе можно увидеть, как будет двигаться одежда в реальном времени. Применение специального движка для симуляции материи на CUDA позволило перенести вычислительные алгоритмы на GPU, что дало примерно 10-кратный прирост производительности.
У нас есть ещё очень много примеров применения CUDA, кроме перечисленных. Например, в промышленном дизайне различных продуктов, таких как мобильные телефоны. Все основные производители телефонов используют GPU в промышленном дизайне, так как это позволяет сократить время разработки. И таких примеров множество, я могу продолжать очень долго.
iXBT.com: Что бы Вы хотели пожелать нашим читателям?
Энди Кин: Новые технологии зачастую вызывают большие изменения в жизни человечества. И я хочу, чтобы ваши читатели думали не о возможных проблемах, а об открывающихся возможностях. О том, как можно их использовать. Мы показали вам множество примеров, которые могут оказать большой эффект в науке, работе и жизни людей. Эти технологии способны изменить многое.
И мы хотим, чтобы люди задумались о том, что возможно сделать ещё. Любая технология может быть очень-очень полезной в некоторых случаях, а иногда не очень полезной. Но вы всегда должны размышлять о том, что может открыть вам новая технология.
iXBT.com: Спасибо большое за столь подробные ответы!
От автора: Очень важно отметить работу Nvidia по продвижению использования GPU для общих вычислений в нашей стране. Чтобы расширить области применения GPU, Nvidia проводит Tesla University Tour в крупнейших научных центрах России и СНГ. Основная задача этих конференций — познакомить научное сообщество с технологиями компании в области высокопроизводительных вычислений, рассказать об особенностях программной модели CUDA, предоставить исследователям площадку для обмена опытом и получить обратную связь.
Первая научно-практическая конференция «Высокопроизводительные вычисления на персональных суперкомпьютерах TESLA от Nvidia» в России состоялась на базе ВМК МГУ. Подобные конференции также прошли в Санкт-Петербурге, Новосибирске, Киеве, Перми, Дубне и других крупных университетских центрах нашей страны.
Эти конференции показали большой интерес российских исследователей к технологиям Nvidia. Некоторые научные лаборатории уже используют архитектуру CUDA для вычислительных задач, а многие ученые собираются перенести вычисления на CUDA. В следующем сезоне Nvidia планирует продолжить проведение таких конференций.
Также на базе ВМК МГУ проходят лекции по Nvidia CUDA, которые читает Алексей Викторович Боресков, кандидат физико-математических наук, сотрудник кафедры «Нелинейных динамических систем» МГУ. Подробнее об этом можно прочитать здесь.
| 9 июля 2009 г. |
|
|