Вот уже, совсем скоро, и придет весна. А весна, как известно, время распускаться новым цветам — Next Generation топовых ускорителей ATI и NVIDIA. Но эта статья не о том :-).
Сегодня мы предпримем попытку окинуть взглядом придирчивой препарации синтетическими тестами скромный, и в тоже время решающий сегмент mainstream — тех самых середнячков, искусство балансировки которых во многом определяет реальное, экономическое лидерство компаний-производителей на рынке. Если в нижнем секторе главную роль играет цена, в верхнем — производительность и возможности, то здесь, в mainstream, ее, несомненно, играют оба критерия. Тем самым, предъявляются наиболее строгие требования к балансу подсистем ускорителя, его себестоимости и, что самое главное, к востребованности всех заложенных в него технологий.
Не претендуя на истину в последней инстанции, мы постараемся нащупать узкие места и ошибки балансировки самых популярных середнячков, снабженных уже «устаканившимися» драйверами. Тем самым, мы попытаемся предсказать основные направления и результаты «работы над ошибками», приобрести которые у нас (возможно) появится шанс в середине 2004 года. Никто не сомневается в компетентности разработчиков таких компаний как ATI и NVIDIA — а, следовательно, в том, что ими уже давно и хорошо изучены слабые места их текущих продуктов. Но известны ли они нам? Орешек знаний тверд. Давайте его расколем.
Что мы тестировали
Для тестирования подсистем чипов использовался уже хорошо знакомый нашим читателям пакет D3D RightMark (Beta 3, известная также как версия 1.0.4.9). Вы можете ознакомиться с этим набором тестов, посетив сайт 3d.rightmark.org, где, в том числе доступны для скачивания исходные тексты и дистрибутив этого пакета.
Мы протестировали следующие ускорители (в скобках указана частота ядра / памяти):
- NVIDIA GeForce FX 5600 128MB DDR 3.6ns (325/550 MHz)
- NVIDIA GeForce FX 5700 128MB DDR 3.6ns (425/550 MHz)
- NVIDIA GeForce FX 5700 Ultra 128MB DDR2 2.2ns (475/900 MHz)
- ATI RADEON 9600 128MB DDR 4ns (325/400 MHz)
- ATI RADEON 9600 Pro 128MB DDR 2.8ns (400/600 MHz)
- ATI RADEON 9600XT 128MB DDR 3.3ns (500/600 MHz)
На двух платформах — Pentium 4 3.2 ГГц и AMD64:
Конфигурации тестовых стендов:
- Компьютер на базе Pentium 4 3200 MHz:
- процессор Intel Pentium 4 3200 МГц;
- системная плата DFI LANParty Pro875 (i875P);
- оперативная память 1024 MB DDR400 SDRAM;
- жесткий диск Seagate Barracuda IV 40GB;
- операционная система Windows XP SP1; DirectX 9.0b;
- мониторы ViewSonic P810 (21") и ViewSonic P817 (21").
- драйверы NVIDIA версии 53.03, ATI версии CATALYST 4.1.
- Компьютер на базе Athlon 64 3400+:
- процессор AMD Athlon 64 3400+ (2200 МГц = 220 МГц*10);
- системная плата MSI K8T (VIA KT8);
- оперативная память 1024 MB DDR400 SDRAM;
- жесткий диск Seagate Barracuda 7200.7 SATA 80GB;
- операционная система Windows XP SP1; DirectX 9.0b;
- мониторы ViewSonic P810 (21") и ViewSonic P817 (21").
- драйверы NVIDIA версии 53.03, ATI версии CATALYST 4.1.
VSync отключен.
Забегая вперед, отметим, что разница между платформами проявилась лишь в одном из тестов, что и ожидалось — обе конфигурации способны загрузить вышеописанные ускорители «по самое не хочу». Однако для очистки совести (и в поисках возможных аномалий поведения драйверов или взаимодействия ускорителей с платформами) мы внимательно сравнили результаты обоих тестовых стендов. А затем, с чистой совестью исключили из большинства графиков совпадающие зачастую до 3 или даже 4 знака результаты AMD64.
Геометрическая производительность
Для начала FFP — т.е. эмуляция T&L:

На горизонтальной оси — миллионы треугольников в секунду. На вертикальной — различные задачи, по мере роста их сложности — от простого константного освещения (фактически пиковая пропускная способность ускорителя по треугольникам) до сложной системы из трех источников света, каждый из которых снабжен двумя компонентами — диффузной и спекулярной (бликовой) составляющими.
Что мы видим на графике:
- Во всех заданиях кроме самого простого (пиковая ппс) NVIDIA четко лидирует.
- Ускоритель на базе NV31 вдвое медленнее собратьев на базе NV36 — сказывается наличие вдвое (если не втрое) меньшего числа геометрических ALU, но даже он показывает себя наравне с самыми быстрыми продуктами ATI.
- Единственная аномалия AMD64 заметна именно в этом тесте — и только для продуктов NVIDIA. На платформе AMD64 они чуть медленнее, причем вне зависимости от сложности задачи, разница составляет одинаковое значение. Видимо, имеет место какая то дополнительная задержка в драйверах (?). В то же время продукты ATI не замечают разницы между платформами.
Как и ожидалось, все решает частота ядра. За исключением ситуации, когда это ядро другое (NV31/NV36). Геометрическая производительность хороший аргумент в пользу покупки карты из семейства 5700, а не 5600. Теперь посмотрим, как изменится картина при переходе к вершинным шейдерами 1.1:

- Общая картина повторяет предыдущую, однако разрыв сократился.
- В результате 5600 проиграл продуктам ATI.
- Все семейство 5700 показывает себя по-прежнему очень хорошо.
- Сохраняется преимущество ATI в области пиковой пропускной способности.
- Сохраняется небольшая аномалия NVIDIA на платформе AMD64.
Ситуация стала более ровной, но, NVIDIA по-прежнему лидер геометрических задач. А теперь перейдем к шейдерам 2.0:

- Ситуация изменилась — теперь NVIDIA проигрывает (!).
- 5600 можно признать оставленным за бортом — он не выдерживает никакой конкуренции.
- 5700 вполне конкурентоспособен, но лидерства как не бывало.
- Аномалия NVIDIA на платформе AMD64 практически исчезла — видимо мешает что-то другое.
Выводы: наличие циклов или условных переходов в вершинных шейдерах — не сильная сторона NVIDIA: было бы неплохо исправить этот факт в следующем поколении ускорителей. В традиционных задачах (а вершинные шейдеры 2.0 пока не получили сколь бы заметного распространения) NVIDIA лидирует в вопросах геометрической обработки. Кроме того, отметим небольшую аномалию, связанную с драйверами или взаимодействием ускорителя с платформой у связки NVIDIA+AMD64. Сама по себе, в абсолютных значениях, геометрическая производительность mainstream ускорителей значительно превышает требования современных приложений — разве только GeForce FX 5600 может вызывать опасения в этой области. Основные баталии сейчас и в будущем, как и в области High End, будут происходить в вопросах скорости закраски и пиксельных шейдеров.
Скорость закраски и фильтрации текстур
Для начала исследуем пиковые возможности закраски, реализуемые при минимальных (2х2) текстурах, в различных режимах работы пиксельных конвейеров (FFP/PS1.1/PS1.4/PS2.0) при различном числе текстур, накладываемых на пиксель. Для сравнения тотальной эффективности будем приводить не число закрашенных пикселей, а число пикселей, помноженное на число текстур (т.е. число выбранных текселей). Это позволит нам понять, для какого числа текстур на пиксель в среднем лучше всего сбалансированы чипы. Для начала FFP и пиксельные шейдеры 1.1:

По горизонтальной оси отложены миллионы текселей в секунду. Что мы видим:
- Ускорители ATI менее чувствительны к режимам — результаты FFP и PS1.1 совпадают, в то время как NVIDIA, имея более сложную структуру пиксельного конвейера, сильнее зависит от различных факторов. В некоторых сочетаниях: PS1.1 при 0 текстур и FFP при 4 текстурах, конвейер конфигурируется не оптимально, и его производительность скачкообразно падает почти вдвое.
- В общем и целом NVIDIA чуть-чуть опережает ATI. Несмотря на меньшее число пикселей выдаваемых за такт (в большинстве случаев ускорители NVIDIA работают в режиме 2х2, хотя порой и конфигурируются драйвером как 4х1 при соблюдении определенных условий), пиковая скорость закраски не является ее слабым местом.
- В отличие от NVIDIA, ATI показывает более ровные результаты без досадных провалов — сказывается более простая и более предсказуемая структура 4х1 с независимыми пиксельными конвейерами.
- Для ATI оптимальны сцены с двумя текстурами на проход, для NVIDIA разница почти отсутствует — годится любое число текстур (0/1/2/4) за исключением двух провальных вариантов, упомянутых выше.
Теперь посмотрим на производительность закраски в режиме шейдеров 1.4 и 2.0:
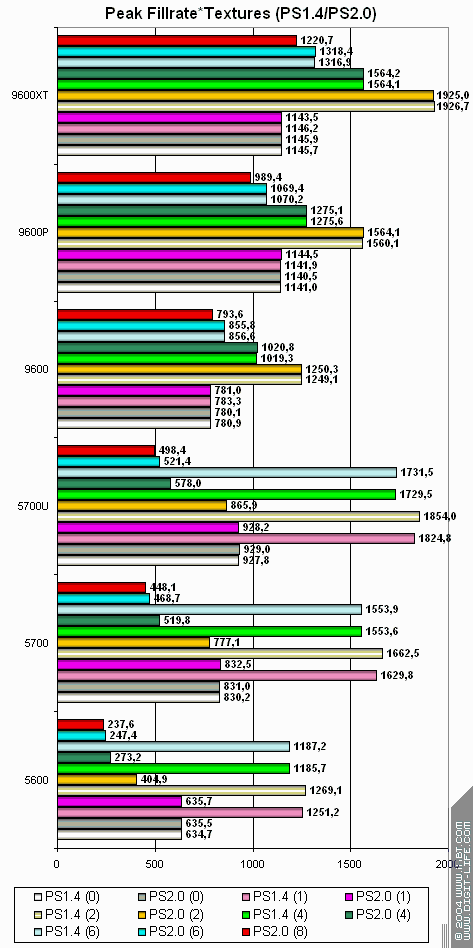
Здесь ситуация становится значительно интереснее:
- Результаты ATI зависят только от числа текстур — оптимально — 2, дальше эффективность падает. Пиксельные шейдеры 1.4 и 2.0 исполняются на конвейерах ATI одинаково.
- NVIDIA очень сильно зависит от конкретной задачи — в шейдерах 1.4 NVIDIA обгоняет ATI (видимо в этом случае в чипах NVIDIA параллельно используются и целочисленные и плавающие ALU) и в то же время в шейдерах 2.0 заметно проигрывает. Однако столь заметной зависимости от числа текстур не наблюдается.
Итак, в вопросах закраски шейдеры 2.0 — не сильное место NVIDIA. Ее пиксельные конвейеры более капризны и могут, как порадовать заметным преимуществом, так и огорчить более чем двукратным падением. «Вы просто не умеете их готовить». Вот почему NVIDIA проводит столько работы с разработчиками приложений — если научить их оптимально использовать продукты NVIDIA, можно добиться заметного преимущества, если не научить — можно серьезно проиграть. ATI не столь чувствительна к вопросам оптимизации и версий шейдеров — результаты на ее ускорителях более предсказуемы. Надеемся, что в будущих поколения NVIDIA сумеет создать менее зависимую от внешнего произвола архитектуру, причем, не скопировав подход ATI (твердая серединка), а именно избавившись от своих слабых мест, при этом, не уменьшив преимущества сильных. ATI же в свою очередь можно пожелать просто нарастить мышцы — увеличить число конвейеров и эффективность работы с памятью.
Теперь посмотрим на более реальную задачу — скорость выборки и фильтрации различными методами текстуры ходового размера 128х128:
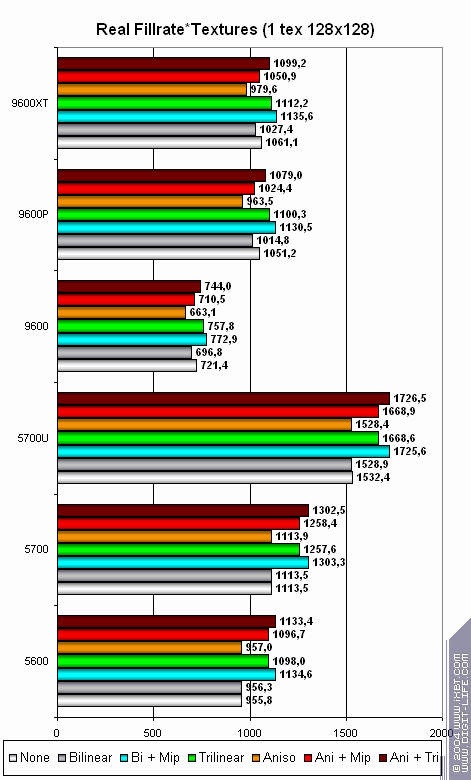
- Как только речь заходит о самой типичной задаче — все чипы показывают примерно одинаковые ровные результаты.
- Оптимизации трилинейной и анизотропной фильтрации сделали их почти бесплатными, по крайней мере, при таком разумном размере текстур.
- Продукты NVIDIA лидируют в вопросах выборки текстур, однако на практических задачах это преимущество не разгромное, а скорее тактическое.
- FX 5600 здесь себя показывает молодцом, даже на фоне 5700. TMU в 5700 остались те же, и их эффективность сравнима.
Теперь две текстуры одновременно:
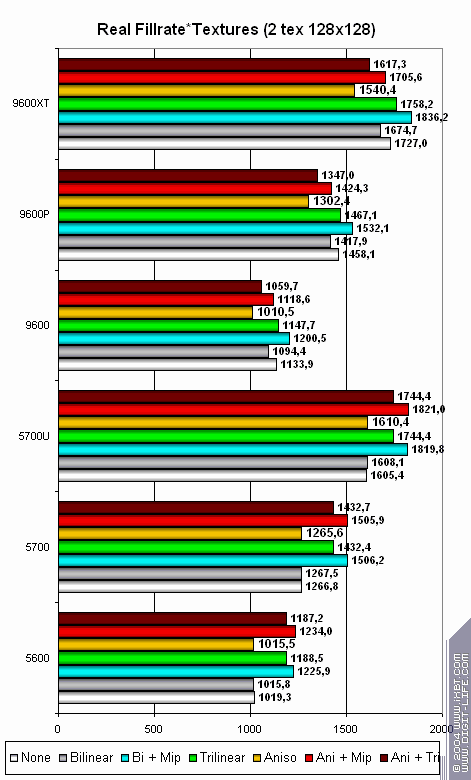
В этой конфигурации ATI и NVIDIA идут нос к носу. Самое ходовое сочетание числа и размера текстур отработано лучше всего. Становится ясно, что вне зависимости от торжества современных технологий, эти чипы нацелены и сбалансированы в расчете на приложения сегодняшнего (и даже вчерашнего) дня, наиболее ходовые среди простых покупателей — основной клиентуры mainstream.
И, напоследок — 4 текстуры:
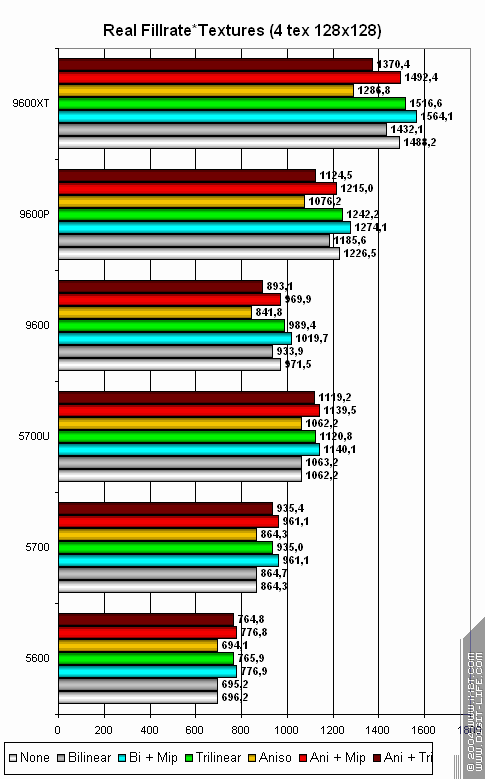
А здесь ATI уже слегка опережает NVIDIA. В чем дело? Сказывается та самая нелюбовь ее пиксельных конвейеров к режиму FFP с 4 текстурами на пиксель. Впрочем, нет повода для паники — в реальных приложениях этот режим встречается реже PS1.1.
Теперь посмотрим на эффективность кэширования текстур — зависимость скорости выборки текстур от их размера (билинейная фильтрация, 1,2 и 4 текстуры):
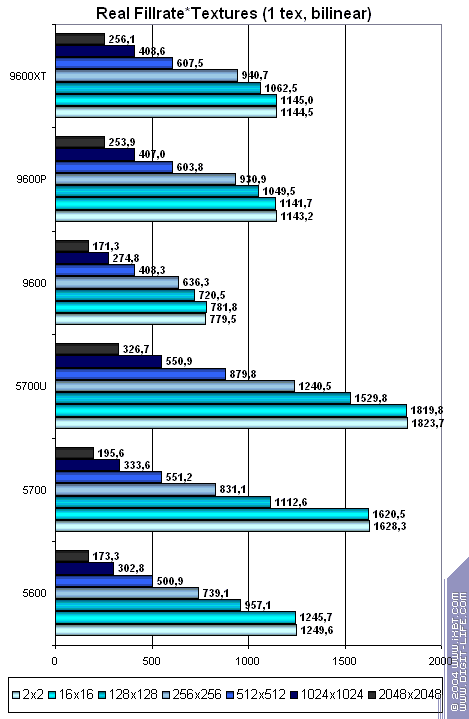
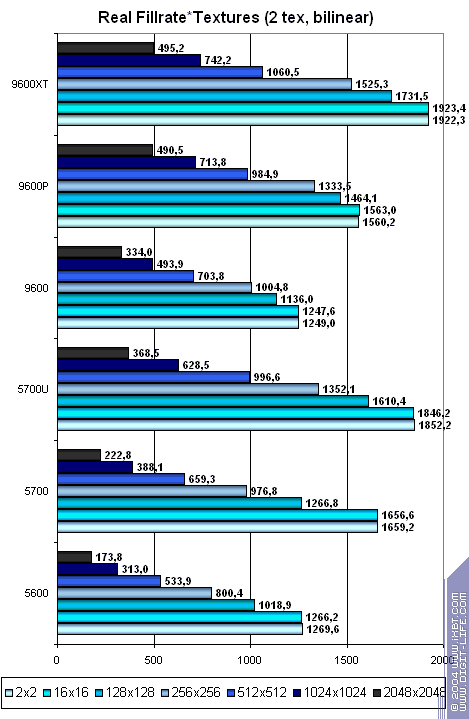
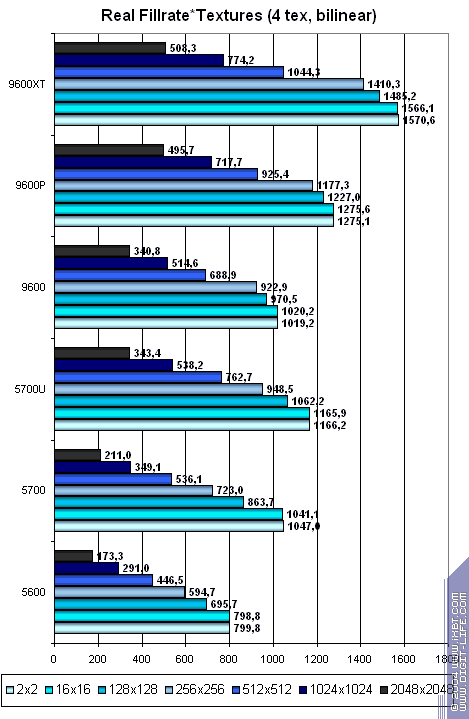
- Чем меньше текстур, тем лучше для NVIDIA.
- При двух текстурах достигается паритет практически на всех размерах текстур.
- Большие текстуры обрабатываются ATI чуть лучше. В какой раз мы отмечаем балансировку чипа в расчете на чуть более «передовые» приложения.
Теперь тоже самое, но с трилинейной фильтрацией для одной и двух текстур:
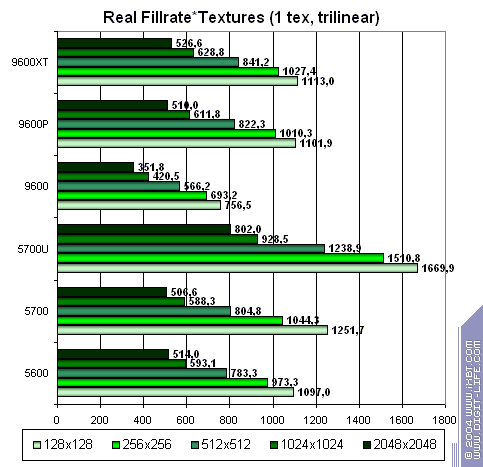

- Здесь сохраняется паритет, а в области небольших текстур, NVIDIA даже лидирует — трилинейная фильтрация ее более сильная сторона.
- Трилинейная фильтрация сильно сглаживает различия между разными чипами линейки.
А сейчас посмотрим на зависимость от формата текстур:

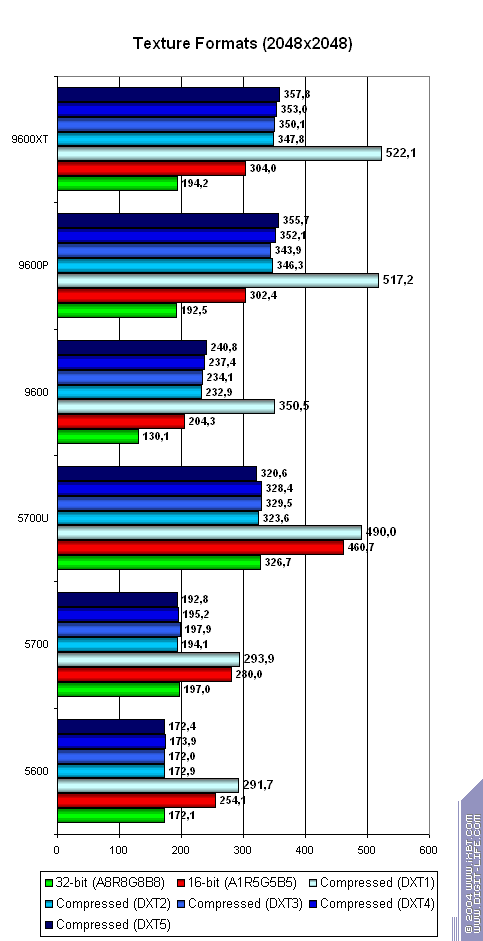
- Сжатие сильнее сказывается в случае продуктов ATI.
- 16-бит формат текстуры дает заметное преимущество для продуктов NVIDIA.
- Еще раз отметим тот факт, что NVIDIA предпочитает средние, а ATI большие текстуры.
Выводы: Сложный пиксельный конвейер NVIDIA можно назвать капризным. Он требует бережного отношения со стороны программистов. В случае успеха наградой будет заметное преимущество, в случае неудачи — неожиданное падение скорости. Надеемся, что в будущем NVIDIA закрепит сильные и устранит слабые стороны своего подхода. В то время как ATI достаточно просто нарастить мышцы на простых задачах выборки и фильтрации текстур.
Пиксельные шейдеры 2.0 — вычислительные задачи
Теперь исследуем вычислительную мощь пиксельных шейдеров 2.0:
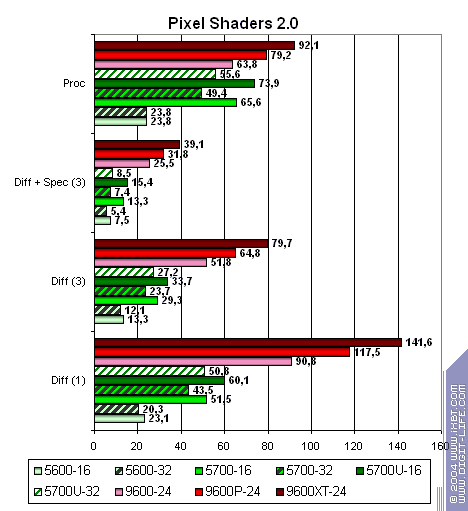
Для NVIDIA приведены результаты как для 16-, так и для 32-бит точности, для ATI она всегда составляет 24 бита.
- NVIDIA заметно проигрывает ATI в вопросах вычислительной производительности пиксельных шейдеров 2.0.
- Оптимизация точности до 16-бит не спасает ситуацию, хотя разница и заметна, она не является решающей. По мере отладки оптимизирующего компилятора шейдеров в драйверах былая разница между 16 и 32 бит точностью сошла «на нет».
- В вопросах вычислений сказывается тот факт, что NVIDIA обрабатывает, как правило, 2, а ATI 4 пиксела за такт. Даже с учетом большей суперскалярности NVIDIA (сложный конвейер позволяет распараллеливать операции), на вычислительных задачах она смотрится слабее.
Для интереса скомпилируем шейдеры с профилем 2.a — возможно небольшое различие результатов компиляции:
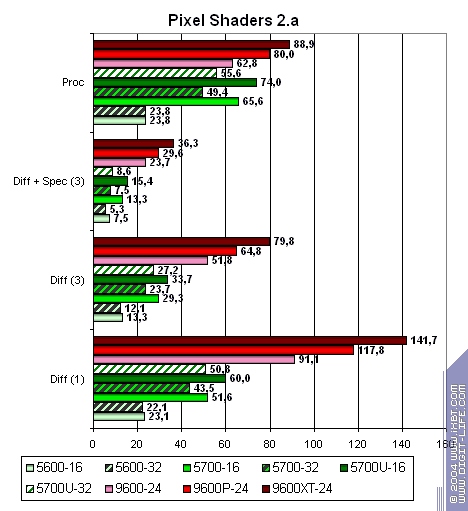
На графике практически не заметно, но если приглядеться, становится ясно, что иногда компиляция с профилем 2.a дает для NVIDIA чуть более успешные результаты. Сказываются большие функциональные возможности ее пиксельного конвейера.
Ну, и напоследок посмотрим, спасет ли ситуацию широкое использование заранее просчитанных таблиц данных (LUT) в виде текстур — ведь чипы NVIDIA, как известно, выбирают значения текстур куда как более успешно, нежели выполняют математические операции в шейдерах 2.0:

Разница есть, особенно она заметна в шейдере процедурной текстуры, но вновь мы приходим к выводу, что решающей ее назвать нельзя. В случае самой тщательной оптимизации шейдеров NVIDIA сравняется с продуктами ATI. Но не начнет их превосходить.
Выводы: Основная работа над ошибками в следующем поколении у NVIDIA должна быть проведена в области пиксельных шейдеров 2.0. Если фирме удастся поднять их производительность хотя бы до того уровня, который демонстрируется сейчас для шейдеров 1.1 и 1.4 — можно будет считать эту работу выполненной. У ATI в этой области все отлично. Ее куда больше должна волновать простая выборка текстур.
Эффективность HSR
Измерим пиковую эффективность подсистемы HSR, достижимую на данных чипах:

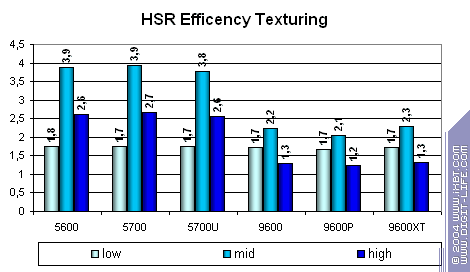
Эффективность NVIDIA выше, особенно в сценах со средней сложностью геометрии (mid). Имея более низкий теоретический предел скорости закраски, NVIDIA отыгрывается на эффективной выборке текстур и HSR. Вот что значит качественный общий баланс подсистем чипа. Но, как и любой баланс, он возможен только в поле некой узкой области параметров (в данном случае — сложности сцены). Если подход ATI более адаптивен, то подход NVIDIA к HSR позволяет добиваться заметного преимущества в одном классе задач и, как минимум, не проигрывать в остальных. Что ж, здесь это оказалось вполне оправдано.
Спрайты
Рассмотрим скорость отрисовки спрайтов (первая диаграмма — без освещения, вторая — с двумя источниками света):
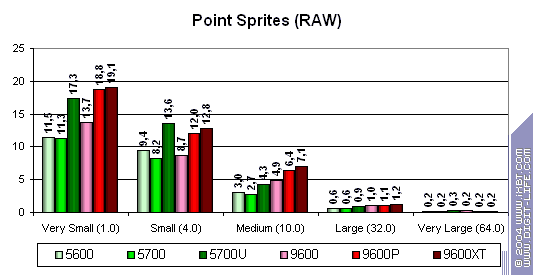
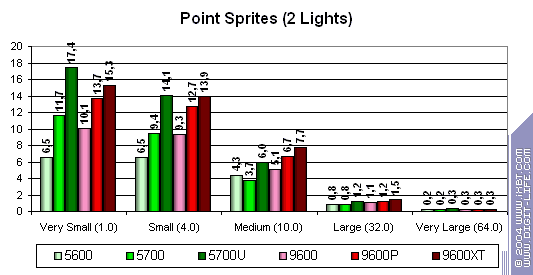
По вертикали отложены миллионы спрайтов в секунду.
- В случае освещения NVIDIA показывает себя чуть лучше — сказывается геометрическая производительность.
- В общем и целом, эта задача более успешно выполняется у ATI — сказывается пиксельная скорость закраски.
- Спрайты имеют смысл только в случае их небольшого размера — дальше эффективность стремительно падает.
Выводы
Что бы мы сделали на месте NVIDIA (кроме простого наращивания частоты и числа модулей):
- При сохранении той же конфигурации пиксельного конвейера устранили бы его слабые места. В первую очередь вычислительную производительность в пиксельных шейдерах 2.0, а также некоторые режимы, в которых он резко замедляет эффективность своей работы. В частности, один из возможных подходов (довести скорость шейдеров 2.0 до 1.1) — сделать все ALU плавающими.
- Избавились бы от досадного падения производительности на циклах и переходах в вершинных шейдерах.
- Обратили бы внимание на обработку больших текстур.
- Чуть-чуть сдвинули бы балансировку HSR подсистемы чипа в сторону более сложных геометрически сцен.
Что бы мы сделали на месте ATI (кроме простого наращивания частоты и числа модулей):
- В первую очередь нарастили бы таки частоту ядра и число конвейеров, ну или хотя бы текстурных блоков.
- Увеличили бы геометрическую производительность.
- Максимум внимания уделили бы вопросам выборки и фильтрации текстур, а точнее производительности этого процесса. Перепроектировали бы текстурные блоки.
- Повысили бы эффективность (вклад в общее дело) HSR подсистемы.
Ничего не забыли? Скоро узнаем!


