

Введение
Современные трехмерные приложения весьма сложны, и для того, чтобы разработчики могли полноценно использовать все возможности новых видеочипов, нужны соответствующие утилиты, помогающие обнаруживать "узкие" места в производительности. При рендеринге видеочипы выполняют множество различных операций графического конвейера, а общая производительность приложения зависит от наиболее медленного участка, поэтому для достижения высокой производительности требуются удобные средства определения подобных узких мест. Тем более что сложность аппаратного графического конвейера значительно увеличилась за последние годы, и разобраться в этих процессах без удобных инструментов просто невозможно.
В недалеком прошлом разработчикам были доступны лишь простейшие средства отладки, затем появились специализированные инструменты, такие как NVPerfHUD. Эта утилита успешно используется игровыми разработчиками, предоставляет наиболее подробную и полную информацию о работе видеочипа в конкретном 3D приложении. Первые версии NVPerfHUD были просто встроены в драйверы NVIDIA и работали в любом приложении, предлагая только часть современных возможностей по анализу работы GPU. В дальнейшем, NVPerfHUD выросла в отдельный инструмент, предназначенный для 3D разработчиков и предлагающий расширенный список необходимых им возможностей. Теперь последняя версия утилиты включена в состав нового набора утилит для разработчиков — NVPerfKit 2.
NVPerfKit 2 — это часть NVIDIA Developer Toolkit, очень интересный набор программ, при помощи которого удобно анализировать 3D производительность в Direct3D и OpenGL приложениях, определять участки, больше всего влияющие на производительность. Инструменты NVPerfKit уже применяются большим количеством разработчиков по всему миру, они давно используют NVPerfHUD как для поиска ошибок рендеринга, так и для того, чтобы найти узкие места в своем коде и увеличить итоговую 3D производительность. Набор NVPerfKit 2 выложен в свободный доступ на сайте NVIDIA для разработчиков, мы предлагаем вашему вниманию обзор его возможностей.
Описание NVPerfKit 2
NVPerfKit 2 — это набор программ для разработчиков 3D приложений, содержащий мощные средства для анализа производительности Direct3D и OpenGL приложений при помощи низкоуровневых счетчиков производительности драйвера и аппаратных счетчиков видеочипа, которые впервые предоставлены сторонним разработчикам в этом наборе. Счетчики производительности могут использоваться для обнаружения причин низкой производительности трехмерных приложений и для определения того, насколько полно конкретное приложение использует возможности видеочипа.
Компоненты, входящие в состав NVPerfKit 2:
- Инструментальный драйвер (instrumented driver) NVIDIA ForceWare версии 83.60 или выше, с интерфейсом Performance Data Helper (PDH).
- NVPerfHUD 4.0 — мощная утилита для анализа производительности Direct3D 9 приложений.
- Плагин NVIDIA для Microsoft PIX for Windows — плагин, импортирующий данные счетчиков NVIDIA в известную программу отладки, входящую в состав DirectX SDK.
- NVPerfSDK — средство доступа к счетчикам производительности из пользовательских приложений, с примерами исходных кодов для OpenGL и Direct3D приложений.
- GLExpert — программа для анализа производительности и отладки OpenGL приложений.
- gDEBugger (30-дневная пробная версия) — инструмент для профилирования и отладки OpenGL приложений, включающий доступ к счетчикам NVIDIA через NVPerfKit.
Системные требования NVPerfKit 2
- Видеокарта на основе любого видеочипа компании NVIDIA, начиная c GeForce 3. Лучше всего подойдут видеокарты серий GeForce 7, GeForce 6 и соответствующие им профессиональные видеокарты семейства Quadro FX. Ранние видеочипы поддерживаются с ограниченной функциональностью, некоторые возможности NVPerfKit на таких видеокартах недоступны.
- Операционная система Microsoft Windows XP с установленным Microsoft DirectX 9.0c (желательно и последнее обновление MS DirectX SDK).
- Специальные отладочные драйверы NVIDIA версии 83.60 или более поздние (инсталлятор NVPerfKit 2 сам устанавливает такой драйвер, включая возможности отладки по умолчанию).
Установка специального драйвера, дополненного инструментами для отладки и детального мониторинга производительности, необходима для того, чтобы использовать утилиты из набора NVPerfKit. Подобные специфические драйверы называются инструментальными (instrumented driver) или отладочными, они содержат дополнительный код для мониторинга и измерения производительности и поставляются в составе набора. Отладочные инструменты, такие как NVPerfHUD, используют связь с драйверами для получения необходимой информации о работе видеочипа и драйвера NVIDIA. В документации отмечено, что инструментальные драйверы не рекомендуется использовать для сравнительного тестирования производительности, так как их применение оказывает дополнительное влияние на скорость рендеринга. Но это отрицательное влияние не превышает 5-7%, что совсем не так уж страшно. Возможность сбора отладочных данных включена в инструментальном драйвере по умолчанию, но ее можно отключить в панели управления NVIDIA на странице "Driver Instrumentation".
Рассмотрим основные особенности NVPerfKit 2 по отдельности. Начнем с краткого описания самих счетчиков производительности, так как это основа всего набора утилит, в том числе и для NVPerfHUD.
Счетчики производительности NVPerfKit
Счетчики NVPerfKit бывают нескольких типов: аппаратные счетчики, которые считывают данные прямо из видеочипа, программные счетчики для Direct3D и OpenGL, содержащие данные отладочного драйвера. Есть еще упрощенные эксперименты (simplified experiments) — многопроходные операции, дающие подробную информацию о состоянии видеочипа.
Все аппаратные счетчики GPU содержат данные, накопленные со времени прошлого опроса. Например, значение количества треугольников в счетчике triangle_count равно числу полигонов, обработанных за время, прошедшее с момента последнего опроса счетчика, а не за какое-то определенное. При использовании PDH для считывания данных счетчиков, например, из встроенной утилиты Performance Monitor (PerfMon) из поставки Windows, они будут опрашиваться раз в секунду, а при внедрении счетчиков в свои приложения, можно брать отсчеты сколь угодно часто, хоть каждый кадр. В отличие от аппаратных, счетчики драйвера возвращают значения, накопленные за один кадр.
При использовании интерфейса PDH, счетчики могут быть представлены в двух видах: числовом и процентном. Первые содержат численные значения (количество пикселей, треугольников, миллисекунд), накопленные со времени прошлого опроса, а процентные возвращают долю времени, которое определенный блок GPU был занят работой или ожиданием данных от другого блока. Если вызывать значения счетчиков из программы при помощи функций NVPerfAPI, то они возвращают числовые значения и общее количество отработанных циклов GPU. Для счетчиков количества треугольников и вершин возвращается число обработанных элементов.
Примеры программных счетчиков производительности, отдельно для Direct3D и OpenGL приложений: частота кадров в секунду, число треугольников на кадр (с учетом и без учета instancing), занятый объем локальной и нелокальной видеопамяти, несколько специальных счетчиков для режима SLI, показывающих количество и объем передач данных от чипа к чипу, число переданных буферов рендеринга и др.
Аппаратные счетчики производительности видеочипа: общее время простоя видеочипа, процент использования блоков пиксельных и вершинных шейдеров, доля простоя блоков ROP, время ожидания выборки текстур блоком пиксельных шейдеров, время ожидания операций записи во фреймбуфер, количество обработанных вершин, примитивов, треугольников и пикселей. Рассмотрим счетчики GPU более подробно, так как именно они были впервые представлены в NVPerfKit 2 и вызывают наибольший интерес.
- gpu_idle — время простоя видеочипа в процентах с момента прошлого считывания значения. Данный счетчик полезен при балансировке нагрузки между центральным процессором и видеочипом, он показывает, насколько сильно загружен работой видеочип.
- vertex_attribute_count — количество атрибутов вершин, прошедших блок обработки геометрии. Слишком большое число атрибутов может снижать производительность обработки из-за переполнения кэша вершин.
- culled_primitive_count — количество отброшенных примитивов, включая те, что отобраны алгоритмом отсечения задних граней (backface culling). Счетчик также полезен для проверки эффективности работы отсечения по области отображения (viewport culling), при использовании этой возможности.
- vertex_shader_busy — доля рабочего времени блоков вершинных шейдеров. Счетчик полезен для нахождения баланса между количеством и сложностью обработки вершин и нагрузкой на блоки пиксельных шейдеров (см. счетчик pixel_shader_busy). Если геометрии очень много или ее обработка вершинными шейдерами слишком сложна, то значение vertex_shader_busy будет большим, а pixel_shader_busy — маленьким. В таких случаях рекомендуется перенести часть работы на попиксельную часть, снизив геометрическую детализацию и/или сложность вершинных программ.
- pixel_shader_busy — доля времени, в которое блоки обработки пиксельных шейдеров были заняты работой. Как и в случае с вершинами, значение может использоваться для определения того, ограничена ли производительность приложения скоростью блоков пиксельных шейдеров, что случается в случае сложных пиксельных программ и большом их количестве. Выход в такой ситуации может быть найден в перенесении части попиксельной работы на вершинные блоки, то есть в повышении геометрической детализации и одновременном снижении нагрузки на блоки пиксельных шейдеров.
- rop_busy — доля времени в процентах, когда блок ROP был занят работой. Слишком большие значения счетчика получаются при активном использовании альфа-блендинга трехмерным приложением или при большом значении overdraw, что служит еще одним весьма распространенным ограничителем производительности рендеринга.
- vertex_count — количество вершин, трансформированных блоками обработки геометрии. Может использоваться для определения эффективности форматов хранения треугольников, таких как strips и fans.
- primitive_count — число примитивов (точки, линии и треугольники), прошедших через блок обработки геометрии.
- triangle_count — количество треугольников, прошедших блок обработки геометрии. Аналог предыдущего счетчика, но учитываются только треугольные полигоны.
- fast_z_count — количество блоков, прошедших через FastZ. На z-only проходах помогает определить эффективность использования возможностей современных видеочипов по удвоенной скорости записи значений в подобных случаях.
- shaded_pixel_count — число пикселей, посланных растеризатором на обработку в блоки пиксельных шейдеров. Совместно с числом обработанных треугольников, это значение может использоваться при поиске оптимального соотношения реальной геометрии и ее имитации при помощи бампмаппинга/нормалмаппинга.
- shader_waits_for_texture — время ожидания выборки значений из текстур блоками пиксельных шейдеров. Простои блоков пиксельных шейдеров из-за ожидания выборки текстур часто встречаются в случаях отсутствия в текстурах мип-уровней и при высоких уровнях анизотропной фильтрации. Далее по тексту мы проверим это утверждение на практике.
- shader_waits_for_rop — время ожидания операций блендинга и записи в буфер кадра (ROP) блоками пиксельных шейдеров. Как уже было написано ранее, большие значения будут в случаях частого использования альфа-блендинга и большого overdraw.
Использование счетчиков производительности из приложений
Существует два возможных пути доступа к данным программных и аппаратных счетчиков NVIDIA из пользовательского приложения, для этого можно использовать интерфейсы NVPerfAPI и Performance Data Helper (PDH). PDH — это общий интерфейс доступа к счетчикам производительности, предлагаемый компанией Microsoft в своих операционных системах, он используется программой PerfMon и некоторыми другими утилитами. Применение NVPerfAPI
NVPerfAPI — это специальный программный интерфейс, предоставляющий разработчикам 3D приложений доступ к данным счетчиков производительности и SimExp, которые дают более подробную информацию о нюансах производительности GPU. В комплекте NVPerfKit прилагаются соответствующие библиотеки NVPerfAPI и примеры их использования, в пользовательских приложениях для этого нужно лишь добавить несколько строк кода. В отличие от программных счетчиков, количество считываний которых не ограничено, существует некоторое ограничение по количеству аппаратных счетчиков, которые можно считывать единовременно. Есть возможность получать данные только от определенного их количества, причем, число зависит от установленного видеочипа. Simplified Experiments (SimExp)
Одной из новых возможностей NVPerfKit 2 является поддержка запуска экспериментов на отдельных блоках видеочипа и сбор информации о производительности. Эти эксперименты называются "упрощенные опыты" или "упрощенные эксперименты" (simplified experiments). SimExp показывает значения, названные "Speed of Light" (SOL) и "Bottleneck" для восьми участков графического конвейера. Первая цифра содержит время использования определенного блока GPU, возвращаемое значение "value" показывает, сколько циклов блок был занят работой во время проведения опыта, а значение "cycles" возвращает общее время, потраченное на проведение эксперимента. Похоже работает и "Bottleneck", значение "value" показывает время, когда блок служил ограничивающим (bottleneck) фактором для всего конвейера, а значение "cycles" — общую продолжительность опыта. Использование возможностей NVPerfSDK при помощи Performance Data Helper
Для сбора данных при помощи Performance Data Helper, нужно сначала указать драйверу и системе PDH, значения каких счетчиков им нужно собирать. Это делается в панели управления разработчика NVIDIA (NVIDIA Developer Control Panel), запускаемой из стандартной панели управления (Control Panel) Windows. В NVDevCPL нужно выбрать сигналы, значения которых нужно снимать во время работы 3D приложений.
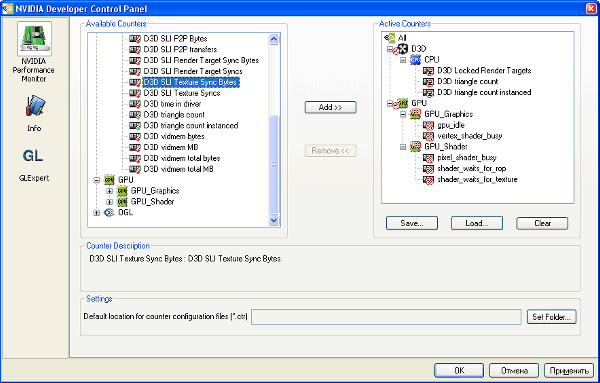
Нужно удостовериться, что вы добавили нужные счетчики в список активных ("Active Counters"). Уже упоминалось, что видеочип может собирать данные с ограниченного количества аппаратных счетчиков, и это число разное для каждой модели GPU. Единовременное количество программных счетчиков не ограничено, но включение каждого сигнала снижает производительность, поэтому лучшим решением будет включение только тех из них, которые действительно нужны в определенный момент. При запуске приложения в оконном режиме, есть возможность изменять набор используемых счетчиков в реальном времени, что позволяет использовать только нужный вам набор. Примеры получения данных от счетчиков производительности из пользовательского приложения посредством PDH поставляются в комплекте NVPerfKit. Применение стандартной утилиты Windows — Performance Monitor
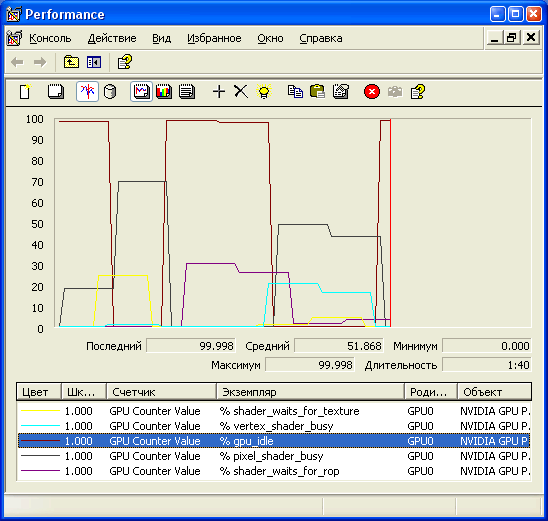
Использование стандартной системной утилиты PerfMon является одной из простейших возможностей по сбору информации со счетчиков производительности. Эта утилита строит несложные графики, основанные на информации счетчиков NVIDIA, если их включить в панели управления разработчика NVIDIA и добавить к графику PerfMon. Для этого нужно выбрать объект "NVIDIA GPU performance" для добавления аппаратных счетчиков, и "NVIDIA Direct3D Driver" или "NVIDIA OpenGL Driver" для программных. Получаемый в итоге график выглядит примерно так:
В составе набора NVPerfKit поставляется плагин для импорта значений счетчиков производительности NVIDIA в утилиту Microsoft PIX for Windows. Плагин для PIX позволяет собирать данные с программных и аппаратных счетчиков NVIDIA в дополнение к возможностям мониторинга PIX, для более качественного анализа производительности и профилирования. Инсталлятор NVPerfKit при его установке автоматически записывает плагин в соответствующий каталог DirectX SDK, где расположена утилита. Для использования этих возможностей нужно не забывать об обязательном применении инструментального драйвера и о необходимых настройках в панели управления разработчика NVIDIA.
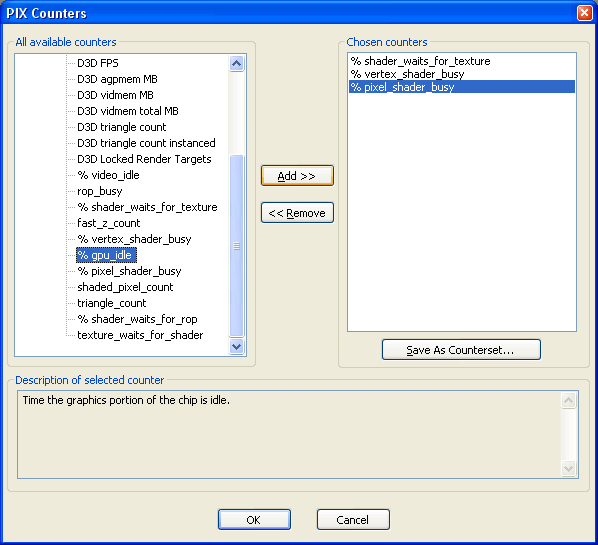
Чтобы настроить сбор информации со счетчиков в PIX, сначала нужно выбрать нужные счетчики в панели управления разработчика NVIDIA, а затем добавить эти счетчики в настройках PIX. Для этого, в окне эксперимента PIX нужно выбрать "More Options", выбрать вид действия "Set Per-Frame Counters" и нажать кнопку "Customize". Затем необходимо выбрать нужные счетчики из списка Plugin Counters — NVIDIA Performance Counters в диалоге "PIX Counters". После этого действия значения счетчиков будут сниматься утилитой PIX в дополнение к ее собственным возможностям. Причем, если возможности PIX по построению графиков и их анализу недостаточны, можно экспортировать данные в CSV формат и анализировать их другим программным обеспечением, Microsoft Excel, например.
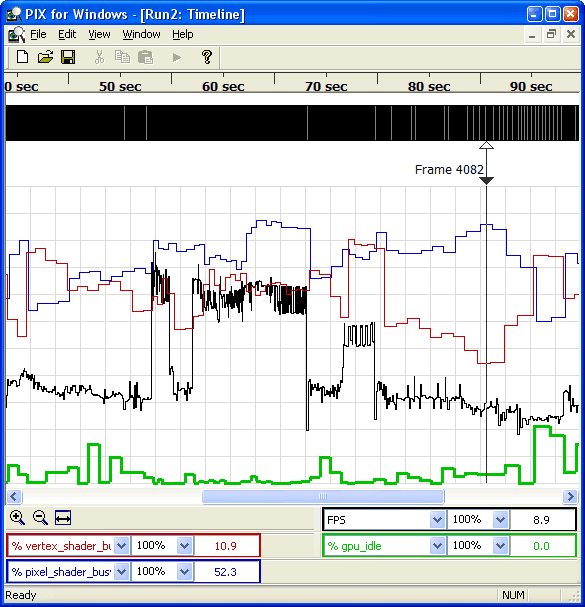
Чтобы проверить действие аппаратных счетчиков, мы сделали анализ производительности одного из игровых тестов бенчмарка Futuremark 3DMark 05 с использованием утилиты PIX. Снимались значения нескольких наиболее интересных аппаратных счетчиков: shader_waits_for_texture, vertex_shader_busy, pixel_shader_busy, shader_waits_for_rop, затем проводился экспорт и анализ полученных данных в Excel.
Проведенные тесты показали, что включение анизотропной фильтрации в этом приложении незначительно влияет на три последних счетчика, то есть ее влияние на занятость блоков пиксельных шейдеров, вершинных шейдеров и ROP в этом случае незначительно. А вот среднее значение первого счетчика, shader_waits_for_texture, показывающее долю времени, которое блок пиксельных шейдеров ожидает выборки данных из текстур, увеличилось с 3.0% до 10.2%. Значение средней частоты кадров при этом снижается на 8%. Для сравнения — при форсировании билинейной фильтрации среднее значение shader_waits_for_texture составило 1%. Аналогичный тест, проведенный встроенным в игре F.E.A.R. бенчмарком, показал увеличение среднего значения shader_waits_for_texture с 7.8% до 15.6% при использовании трилинейной и анизотропной текстурных фильтраций соответственно. Это лишь один небольшой пример из тестов, которые можно проводить при помощи новых средств, впервые появившихся в рассматриваемой версии NVPerfKit.
Усовершенствованная утилита NVPerfHUD 4.0
NVPerfHUD — это удобная утилита для профилирования и отладки Direct3D 9 приложений, помогающая решить сложные проблемы со скоростью и качеством рендеринга при помощи подробного мониторинга производительности, инспекторов состояния графического конвейера и вывода отладочной информации. Вся информация выводится на информационную панель heads-up display (HUD), интерфейс NVPerfHUD рисуется поверх изображения, построенного приложением, и содержит графики, текстовые поля и элементы управления.
NVPerfHUD 4 — это уже четвертое поколение утилиты для анализа производительности компании NVIDIA, одна из главных частей набора NVPerfKit 2. Последняя версия основана на многолетней работе над NVPerfHUD, и дает разработчикам почти те же инструменты по детальному анализу и профилированию, что используются инженерами внутри компании при поиске проблем производительности и качества рендеринга.
Программа собирает данные от приложения, драйвера, API и видеочипа. После запуска она работает вместе с приложением и отображает собранную и информацию на экране поверх картинки приложения. NVPerfHUD использует специальный код в драйвере, собирающий данные со счетчиков видеочипа, а также перехватывающий вызовы API для сбора статистики и интеграции с приложением. Поэтому, по сравнению с обычным режимом, без специального драйвера и включенного HUD, наблюдается небольшое падение производительности, впрочем, ничуть не мешающее работе. На приложенном рисунке представлено взаимодействие NVPerfHUD с другими программными компонентами:
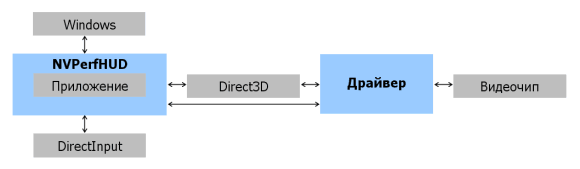
Так как NVPerfHUD является мощнейшим инструментом по анализу 3D приложений, в NVIDIA сделали защиту для того, чтобы исключить доступ третьих лиц к анализу пользовательских приложений без разрешения их разработчика. Чтобы воспользоваться NVPerfHUD, нужно, чтобы в приложение была встроена соответствующая поддержка в виде нескольких строк кода в подпрограмме инициализации DirectX. Когда приложение запущено из-под NVPerfHUD, драйвером создается специальный видеоадаптер NVIDIA NVPerfHUD и пользовательское приложение должно выбрать его использование. В дополнение к этому, сделано так, чтобы NVPerfHUD работал только при использовании референсного растеризатора, хотя при выборе рабочего видеоадаптера NVIDIA NVPerfHUD приложение все равно будет использовать аппаратные возможности видеочипа.
Такое решение применяется, начиная с версий NVPerfHUD 2.x, поэтому разработчики смогут использовать новую версию без изменений в своих программах. Приложения, в которых не включена поддержка NVPerfHUD описанным в документации образом, не могут быть исследованы при помощи этой утилиты. В таких случаях интерфейс хотя и показывается, но все возможности утилиты, кроме среднего FPS и количества треугольников в сцене, не могут быть использованы.
Чтобы запустить Direct3D приложение совместно с NVPerfHUD, нужно задать путь к исполнимому файлу в командной строке утилиты или перетащить приложение или ссылку на него на ярлык NVPerfHUD. Интерфейс программы использует горячие клавиши для быстрого доступа к функциям, также есть элементы управления, которыми можно управлять мышью. Активность интерфейса переключается между пользовательским приложением и утилитой NVPerfHUD при помощи основной горячей клавиши, задаваемой в настройках утилиты. При первом запуске программы показывается конфигурационное окно, где можно задать основные настройки.
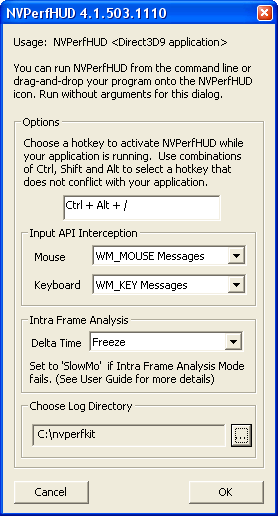
В настройках выбирается горячая клавиша для вызова NVPerfHUD, указывается место на жестком диске для хранения лог-файлов, выбирается способ перехвата сигналов мыши и клавиатуры (используя DirectInput или стандартные системные методы), и изменяется настройка для режимов Frame Debugger и Frame Profiler. Позднее, конфигурационное окно можно вызвать, запустив программу без указания имени приложения для анализа.
Режимы экранного интерфейса NVPerfHUD:
- Performance Dashboard — общий анализ производительности и поиск узких мест при помощи графиков и диаграмм со статистикой использования различных ресурсов видеокарты.
- Debug Console — просмотр отладочных сообщений библиотек DirectX, предупреждений NVPerfHUD и сообщений вашего приложения.
- Frame Debugger — подробное исследование работы каждого этапа графического конвейера внутри кадра при помощи "заморозки" текущего кадра 3D рендеринга и анализа построения сцены по отдельным вызовам.
- Frame Profiler (появился в NVPerfHUD 4) — мощный режим отладки, позволяющий определить, насколько полно приложение использует возможности видеочипа, в нем автоматически определяются и показываются наиболее требовательные вызовы функции отрисовки (draw call).
При старте Direct3D приложения под NVPerfHUD запускается начальный режим интерфейса — Performance Dashboard, изображение которого накладывается поверх результата рендеринга запущенной из-под NVPerfHUD программы. Этот режим удобен для начальных исследований, он дает общие данные о работе графического конвейера в пользовательском приложении. Затем нужно вывести на экран сцену, которую хотелось бы исследовать подробнее. Если в ней наблюдаются ошибки рендеринга, их причины проще всего обнаружить в режиме Frame Debugger, где можно просмотреть построение сцены вызов за вызовом и для каждого вызова отрисовки увидеть используемую геометрическую модель, текстуры, шейдеры и растровые операции. Ну а в решении проблем производительности поможет режим Frame Profiler. В нем есть возможность продвинутого профилирования, помогающего найти проблемные места с точки зрения производительности. Frame Profiler выдает много полезной статистики в виде результатов автоматического анализа с полной информацией о всех вызовах отрисовки и о времени, затраченном в них на работу различных блоков видеочипа. Давайте рассмотрим все предлагаемые утилитой режимы подробнее. Панель производительности Performance Dashboard
Это наиболее общий режим, знакомый нам с самых первых версий утилиты и позволяющий проводить детальный мониторинг и анализ общей производительности приложения. Здесь показывается статистика 3D приложения и использования ресурсов видеочипа и видеокарты в реальном времени.
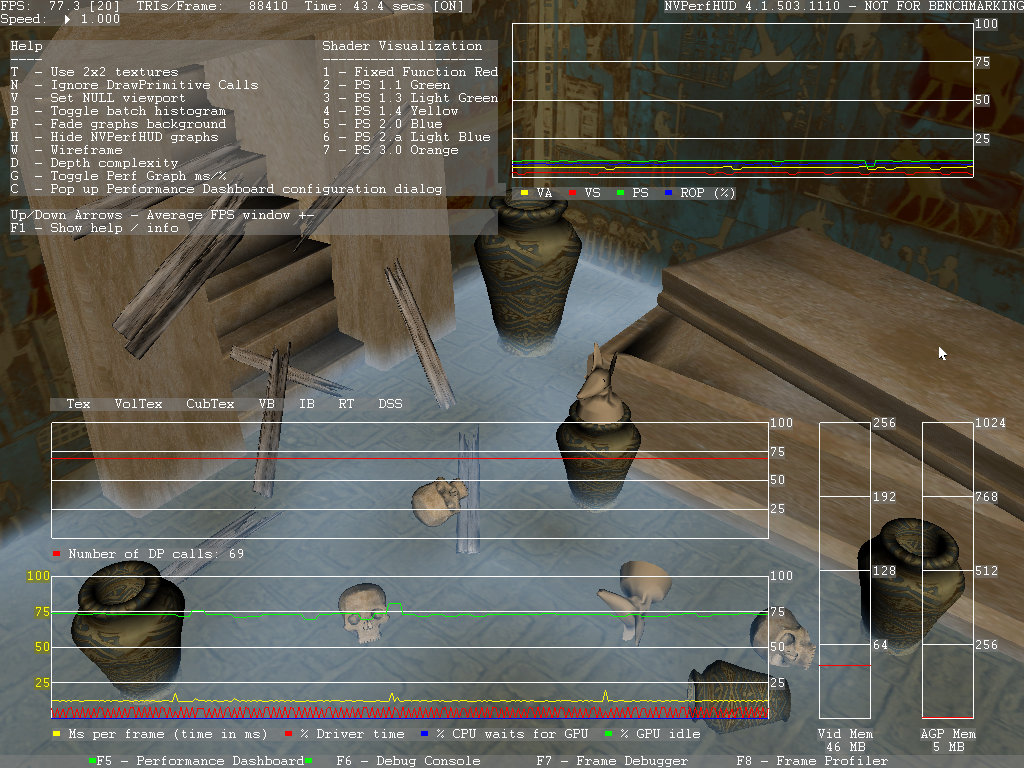
В этом режиме NVPerfHUD'ом отображаются основные графики производительности. Прокручивающийся график в верхнем правом углу показывает загрузку различных блоков видеочипа. По умолчанию график показывает время в миллисекундах, которое затрачивает каждый блок GPU на рендеринг текущего кадра, но его можно переключить и в проценты. Этот график может использоваться для балансировки нагрузки на разные блоки видеочипов. Желтым цветом на графике выделен блок установки вершин, красным — блок выполнения вершинных шейдеров, зеленым — блок пиксельных шейдеров и синим — блок записи данных во фреймбуфер (ROP). Важно отметить, что у видеочипов, выпущенных до семейства GeForce 6, нет внутренних счетчиков производительности, требуемых для построения графика использования блоков GPU.
Другие элементы интерфейса в данном режиме: информационная полоса в верхней части экрана, монитор ресурсов посередине и несколько графиков по краям экрана. Информационная полоса показывает текущее количество кадров в секунду (мгновенный FPS), количество треугольников в кадре, прошедшее со времени запуска приложения время и версию NVPerfHUD. Монитор ресурсов — это список создаваемых ресурсов, таких как текстуры и вершинные буферы. Другие графики показывают количество вызовов DrawPrimitive, использование локальной и нелокальной (AGP/PCI/PCI-Express) видеопамяти. Графики использования памяти наиболее просты, они показывают текущее количество занятой ресурсами локальной и системной памяти.
Основной график этого режима NVPerfHUD, расположенный снизу посередине, содержит четыре линейных графика, показывающих общее время рендеринга кадра, время проведенное в драйвере, время простоя GPU и время ожидания GPU центральным процессором. График расположен в нижней части экрана, выше него находится график Draw Primitives, показывающий число вызовов функций отрисовки DrawPrimitive, DrawPrimitiveUP и DrawIndexedPrimitive в процессе рендеринга кадра. Над последним расположен индикатор создания ресурсов, мигающий при динамическом создании различных Direct3D ресурсов: 2D текстур, объемных текстур, кубических карт, вершинных и индексных буферов и т.п. Этот индикатор полезен потому, что динамическое создание ресурсов в Direct3D приложениях негативно влияет на производительность и при возможности от них нужно отказываться.
Также можно включить гистограмму Batch Size, нажав после активации NVPerfHUD клавишу "B". В этом случае вышеупомянутый график Draw Primitives заменяется гистограммой, где показывается количество батчей в зависимости от объема геометрии. В первом столбце графика расположена полоска, представляющая число батчей с количеством треугольников менее 100, во второй — с 100-200 треугольниками, и т.д. Другие дополнительные возможности также вызываются при помощи горячих клавиш. Например, есть возможность выборочного отключения пиксельных шейдеров разных версий. Можно отключить рендеринг каждой версии отдельно, вплоть до 3.0, при этом результат расчетов заменяется определенным цветом для каждой версии шейдеров. Подобным же образом можно включить каркасный режим (wireframe) и режим визуализации уровня перекрытия (overdraw).
Есть еще одна интересная возможность в режиме Performance Dashboard — эксперименты по определению узких мест графического конвейера при помощи их отключения, полезная для старых видеочипов. Эта работа требует отдельного анализа каждой стадии конвейера, и на новых видеочипах, начиная с GeForce 6, есть соответствующие аппаратные счетчики, показывающие загрузку каждого блока. На старых чипах приходится пользоваться отключением отдельных частей графического конвейера, что может дать похожий эффект, хотя и значительно менее удобно в использовании. Например, можно форсировать применение специальной текстуры размером 2х2 пикселя вместо всех текстур, для значительного снижения влияния текстурирования на общую производительность. Эта возможность может применяться для определения того, является ли текстурирование основным ограничивающим фактором. Аналогично и с другими частями конвейера, есть возможность уменьшения влияния блоков ROP и пиксельных шейдеров при помощи прямоугольника, отсекающего всю работу по растеризации и затенению, а также возможность отключения всех ступеней конвейера (игнорирование вызовов DrawPrimitive и DrawIndexedPrimitive), для определения того, не ограничена ли производительность 3D конвейера кодом пользовательского приложения. Отладочная информация Debug Console
Это самый простой режим NVPerfHUD — отладочная консоль. В Debug Console можно просмотреть список диагностических сообщений об ошибках и предупреждениях отладочных библиотек DirectX, список событий создания ресурсов, а также дополнительные предупреждения самого NVPerfHUD и сообщения пользовательского приложения, выводимые при помощи функции OutputDebugString.
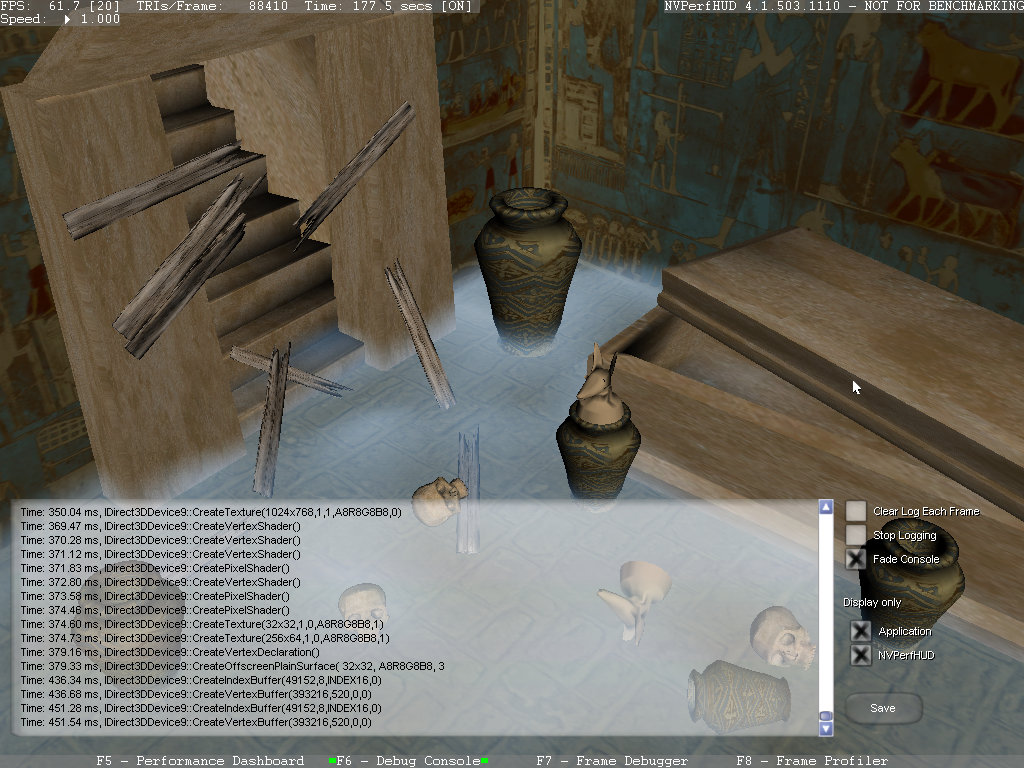
В данном режиме есть возможность очистки содержимого окна после каждого следующего кадра, чтобы видеть только относящиеся к текущему кадру сообщения. Это может быть полезно в случае большого числа ошибок и предупреждений. Также можно вообще отключить сбор данных при помощи опции "Stop Logging". Режим покадровой отладки Frame Debugger
Режим анализа построения кадра Frame Debugger — это один из наиболее зрелищных режимов NVPerfHUD, рендеринг приостанавливается на текущем кадре и становится возможным просмотр его построения шаг за шагом, отдельно по одному вызову DrawPrimitive. Данный режим NVPerfHUD помогает быстро найти проблемы, связанные с неправильным порядком отрисовки объектов, с его помощью легко определить, из-за чего возникают ошибки рендеринга в процессе построения кадра. Используя полосу прокрутки внизу экрана, можно пошагово пройти весь кадр, что особенно полезно в случае сложных сцен с большим количеством вызовов функции отрисовки и несколькими буферами рендеринга (render target).
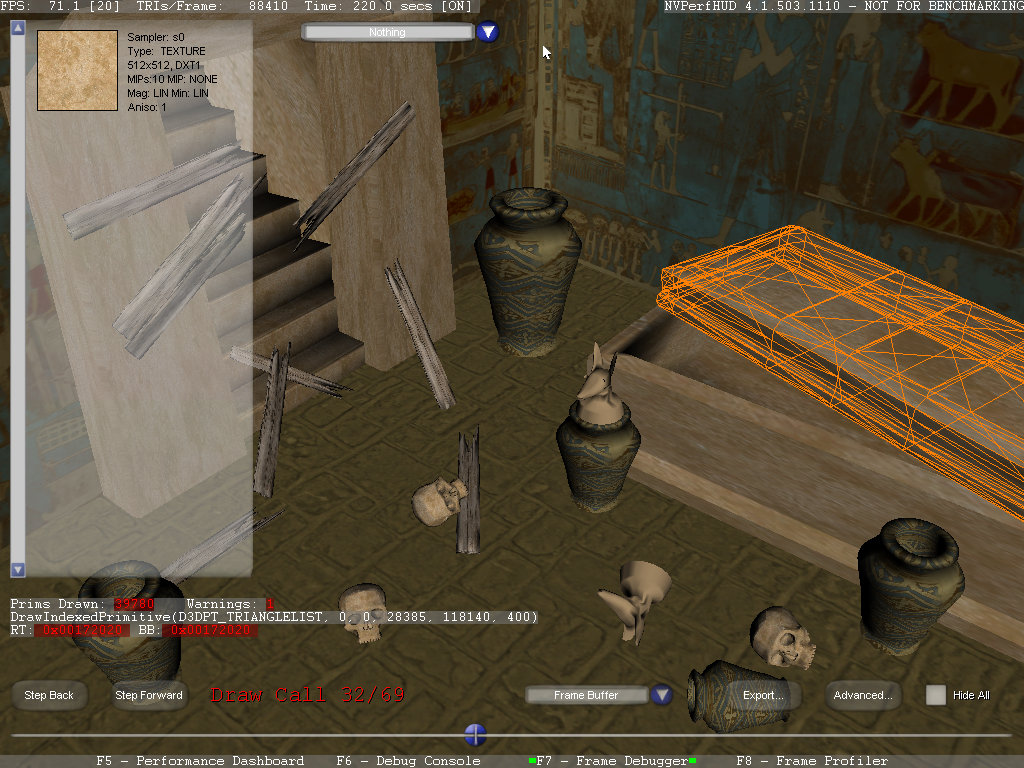
После того, как в основном режиме Performance Dashboard обнаружен кадр с артефактами рендеринга, нужно переключиться в режим Frame Debugger, и, просматривая по одному вызову отрисовки, проверить порядок и правильность отрисовки сцены. Так как режим "замораживает" пользовательское приложение, существуют определенные ограничения. Так, режим Frame Debugger будет корректно работать, только если приложение использует стандартные системные вызовы QueryPerformanceCounter или timeGetTime, также есть и некоторые другие ограничения, о которых подробно написано в документации NVPerfKit.
При первом запуске режима на экране показываются результаты первого вызова отрисовки. Пользуясь полосой прокрутки внизу экрана или клавиатурными стрелками "влево" и "вправо", можно просматривать результаты каждого последующего вызова функции draw call. Геометрические данные, используемые в текущей функции отрисовки, подсвечиваются оранжевой wireframe сеткой, а используемые текстуры показываются в поле слева. Информация, отображаемая для текстур и внеэкранных буферов рендеринга (render to texture target) включает в себя изображение текстуры и ее параметры (вид текстуры: 1D, 2D, объемная, кубическая, ее разрешение, метод фильтрации, формат текстуры, количество мип-уровней). Если вызов отрисовки при рендеринге использует внеэкранную поверхность, то его содержимое показывается в центре экрана. При включенном показе предупреждений, их список показывается в верхней части экрана, при нажатии на любом из них вызывается соответствующий DrawPrimitive вызов.
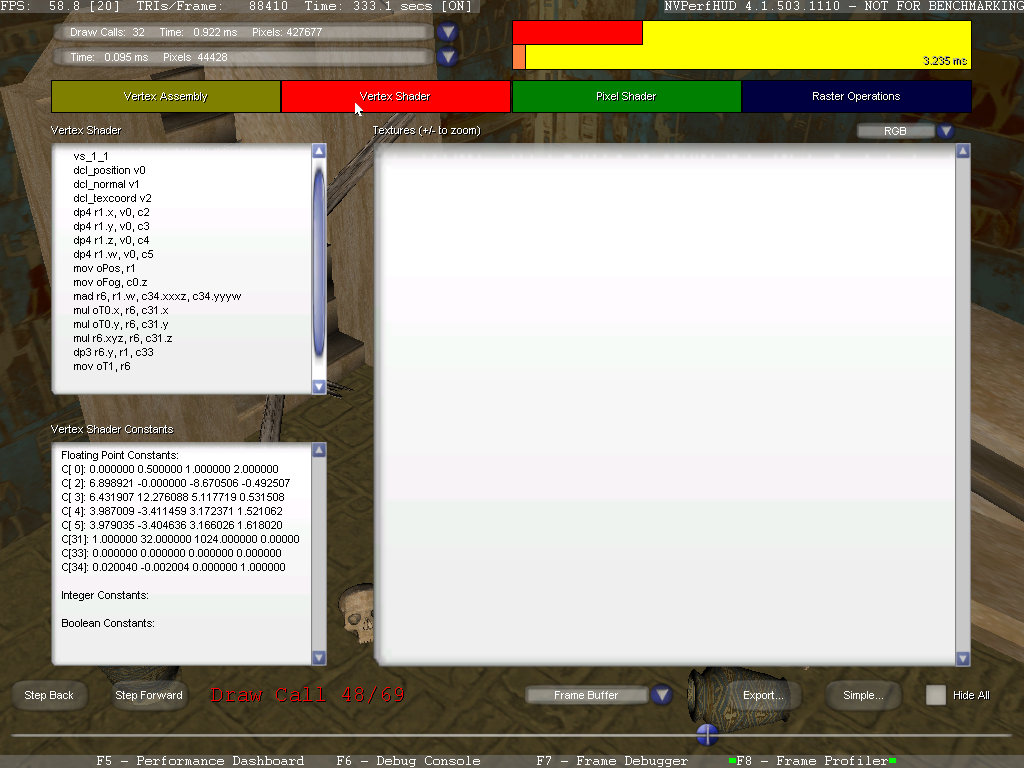
Нажатием на кнопку "Advanced" можно перейти в "продвинутый" режим, который предлагает подробный анализ каждого вызова отрисовки при помощи так называемых инспекторов состояния (state inspectors). В advanced режиме все так же доступна полоса прокрутки внизу экрана, а остальная его часть делится на четыре части — по количеству стадий в графическом конвейере: выборка вершин (Vertex Assembly), вершинный шейдер (Vertex Shader), пиксельный шейдер (Pixel Shader), растровые операции записи во фреймбуфер (Raster Operations). Соответствующие инспекторы позволяют просматривать геометрические модели, используемые вершинные и пиксельные шейдеры, операции растеризации для выбранного вызова отрисовки.
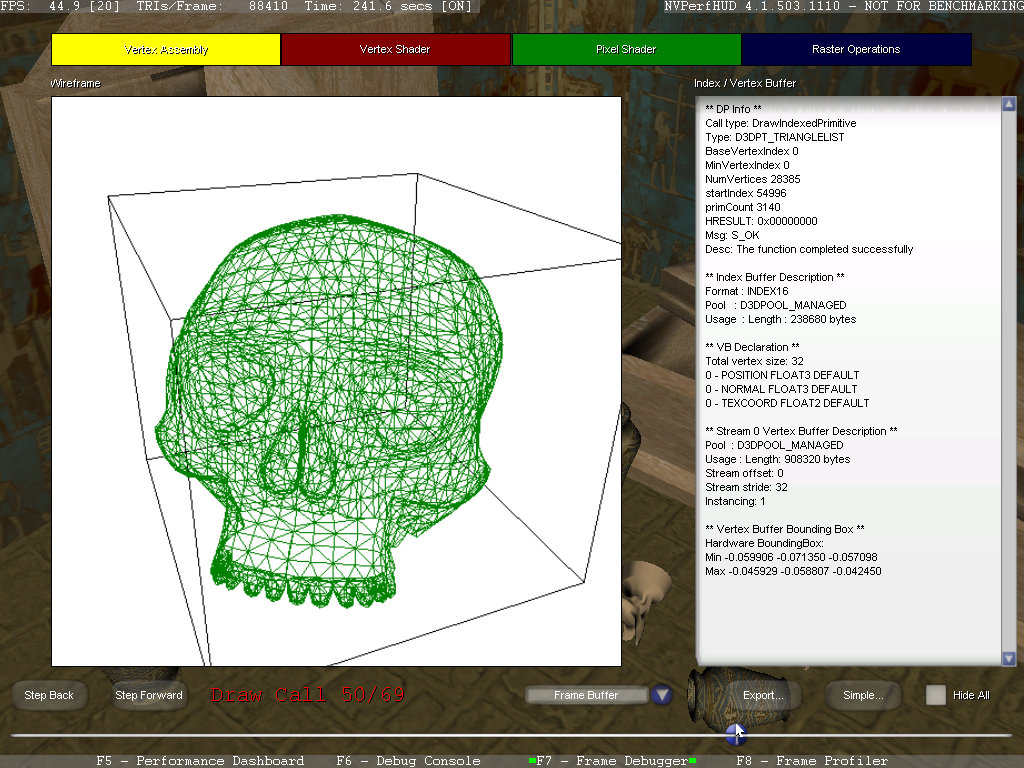
Так, когда выбран инспектор состояния Vertex Assembly, NVPerfHUD отображает на экране информацию о состоянии блока выборки вершин в текущем вызове отрисовки. В центре экрана в каркасном режиме показывается геометрия, используемая в данном вызове, а сбоку расположено поле с параметрами вызова отрисовки, форматами индексного и вершинного буферов, их размерами и т.п. В этом режиме можно убедиться, что все геометрические данные посылаются корректно. В режиме Vertex Shader State Inspector и Pixel Shader State Inspector окно отображает информацию об используемом в вызове отрисовки коде вершинного и пиксельного шейдера, соответственно. Показывается сама вершинная/пиксельная программа и используемые в ней константы и текстуры. А окно режима растровых операций (Raster Operations) выводит информацию об операциях, производимых блоком ROP в текущем вызове draw call. Показывается формат буфера кадра, состояние рендера (render state) и т.п. Этот инспектор полезен для проверки правильности работы альфа-блендинга. Например, можно посмотреть, содержит ли необходимые данные буфер, если блендинг не работает корректно. Анализ производительности в Frame Profiler
Режим NVPerfHUD под названием Frame Profiler, появившийся в NVPerfHUD 4 впервые, призван помочь в увеличении 3D производительности. Frame Profiler использует специальные аппаратные блоки видеочипа и инструментальный код драйвера для измерения загрузки отдельных блоков GPU пользовательским приложением, помогает найти узкие места графического конвейера. При вызове режима, NVPerfHUD выполняет несколько опытов по анализу производительности текущего кадра, и после этого выдает детальный отчет по вызовам отрисовки. Необходимо отметить, что из-за использования специальной аппаратной поддержки, появившейся в видеочипах серии GeForce 6, Frame Profiler работает только на современных сериях видеокарт NVIDIA.
Режим профилирования является эффективным методом нахождения проблемных мест в отдельных сценах, он показывает самые требовательные вызовы функции отрисовки в кадре, а также предоставляет подробную информации о каждом вызове функции отрисовки, что позволяет определить те из них, которые требуют особого внимания. Суть работы режима в том, что текущий кадр рендерится несколько раз и в это время производится замер использования ресурсов видеочипа, отдельно по вызовам отрисовки. Исходя из этой информации, вызовы отрисовки группируются в так называемые блоки состояния (state buckets). Все вызовы в одном блоке имеют общие характеристики, поэтому устранение узкого места в одном из вызовов отрисовки вызовет увеличение производительности остальных вызовов этого блока.
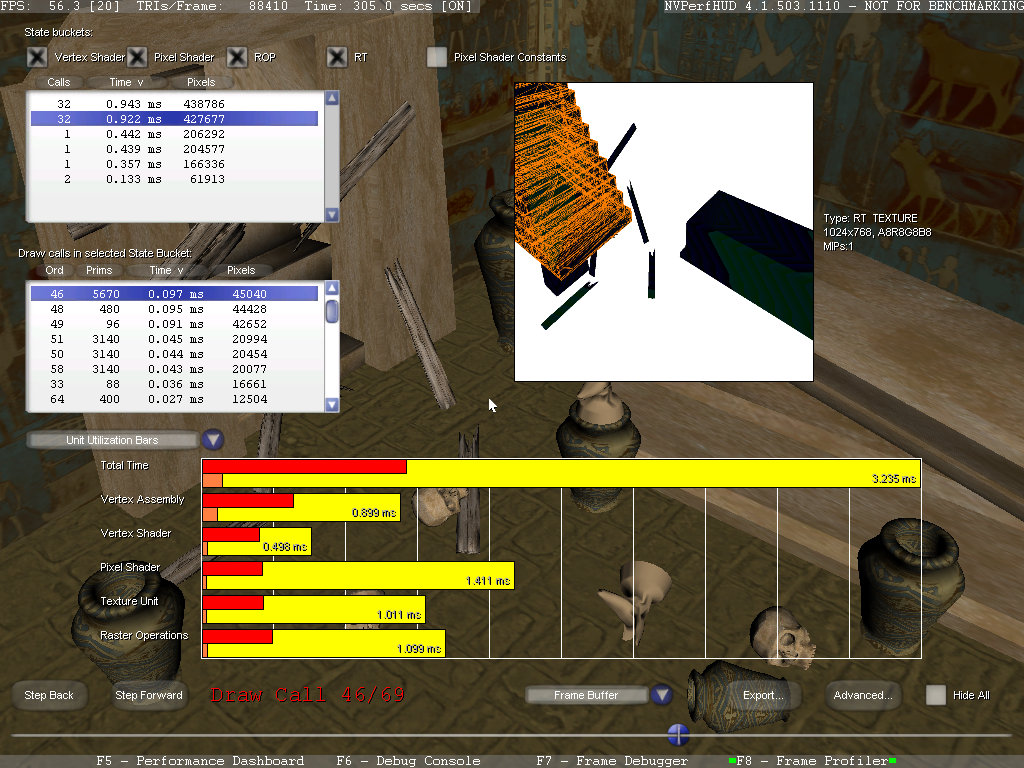
В нижней части экрана по умолчанию отображается диаграмма использования блоков видеочипа. На этом графике верхняя полоска (бар) показывает весь кадр целиком, а бары, расположенные ниже, показывают степень загруженности отдельных блоков видеочипа (блок установки вершин, блок вершинных шейдеров, блок пиксельных шейдеров, блок текстурирования и блок ROP) во время текущего вызова отрисовки и всех вызовов в блоке состояния state bucket. Желтая секция каждой полоски показывает общее время кадра в миллисекундах, красная — время использования блоков видеочипа всеми вызовами блока состояния, а оранжевая полоска показывает время использования блока в текущем вызове функции отрисовки.
График использования блоков чипа похож на тот, что показывается в режиме Performance Dashboard, но рассматриваемый график в режиме Frame Profiler основан на анализе единственного кадра и показывает использование блоков процессора отдельно для каждого вызова отрисовки. Также есть возможность просмотра графиков: продолжительности вызовов отрисовки, показывающий время в миллисекундах, которое занимает каждый вызов отрисовки в кадре; продолжительности использования блока depth/stencil удвоенной производительности (FastZ), показывающий время активности данного блока в миллисекундах и счетчик количества обработанных пикселей в каждом вызове draw call.
Как и в предыдущем режиме, в Frame Profiler есть второй вид интерфейса — Advanced, для доступа к инспекторам состояния. Этот вид в Frame Profiler позволяет просматривать детали отдельных вызовов отрисовки (геометрические данные, применяемые пиксельные и вершинные шейдеры, растровые операции) с одновременным просмотром времени, затрачиваемого на каждый вызов draw call в выбранном кадре. Режим сделан в том же стиле, что и Advanced во Frame Debugger, а цветная временная диаграмма схожа с тем, как сделаны бары в описанных выше графиках использования блоков видеочипа.
Выводы
Оптимизация 3D приложений без удобных инструментов по поиску узких мест невозможна, ее суть состоит в циклическом проведении следующих шагов: нахождении причины низкой производительности, оптимизации кода программы и возврата к первому шагу, если производительность после этого недостаточна. NVPerfKit помогает тем, что используя NVPerfAPI или NVPerfHUD, можно узнать влияние каждого блока графического конвейера на общую производительность. Затем, зная узкое место, нужно снизить нагрузку на этот блок, достигнув желаемого уровня производительности. Все это приходится повторять с самого начала до того момента, как общая скорость рендеринга станет приемлемой.
Возможности NVPerfKit 2 позволяют значительно упростить поиск подобных узких мест, все доступные программные и аппаратные счетчики производительности предоставляют весьма полезную информацию о подробностях работы видеочипов NVIDIA. С их помощью можно определить, какие блоки GPU загружены больше, а какие меньше, где узкие места у приложения и как можно повысить общую производительность. Возможностей по считыванию значений счетчиков масса, можно использовать как вызовы NVPerfAPI из своего приложения, так и анализ в известных программах PerfMon и PIX. А если нужен еще более наглядный и удобный инструмент по анализу Direct3D приложения, то можно воспользоваться NVPerfHUD, который предоставит полную информацию о работе приложения и видеочипа в удобной форме, прямо на экране во время работы пользовательской программы.
Единственное, что не совсем понятно, так это причины того, что в NVPerfHUD для "не разрешенных" приложений не оставили возможности простейшего мониторинга: объемов используемой видеопамяти, загрузки отдельных блоков видеочипа в целом и др. Понятно, что некоторые детали (текстуры, шейдеры, прочие подробности draw call) разработчики могут не захотеть показывать всем желающим, но простейшие то данные почему бы им не предоставить? Появились бы интересные возможности, если в NVPerfHUD для всех приложений оставили бы полностью работоспособной первую страницу Performance Dashboard, а уж для "разрешенных" — еще и Debug Console, Frame Debugger и Frame Profiler. Тем же журналистам и тестерам это бы не помешало, можно было бы узнать, какие блоки видеочипа больше всего загружены тестовым приложением, во что производительность уперлась в конкретном тесте и даже отдельной сцене. При желании, такие данные можно получить через счетчики производительности в PIX for Windows или системной программе PerfMon, но это менее удобно, чем в NVPerfHUD. Кроме того, PIX даже дает возможность захвата ресурсов (шейдеров, текстур и т.п.), что также запрещено в NVPerfHUD для приложений, специально не предназначенных для отладки.
Но для самих 3D разработчиков все возможности утилиты NVPerfHUD доступны при соответствующем изменении исходного кода. Если раньше у них были лишь примитивные утилиты без подробной документации, то теперь они получили мощное средство по профилированию и отладке трехмерных приложений, публично доступное и практически идентичное тому, что используется в самой NVIDIA. Набор NVPerfKit 2 помогает решить большинство вопросов, возникающих в процессе разработки: определение узких мест в производительности, нахождение ошибок рендеринга, полное использование возможностей современных видеочипов, нахождение баланса между геометрической сложностью сцены и сложностью попиксельной обработки и др.
Можно с уверенностью утверждать, что набор утилит NVPerfKit 2 будет весьма полезен для всех разработчиков современных трехмерных приложений, использующих в своей работе как Direct3D, так и OpenGL. Набор также может быть интересен тестерам, журналистам и просто энтузиастам, так как он предоставляет новые возможности по анализу производительности даже сторонних приложений, хотя и с некоторыми ограничениями.
