24 мая, в Москве, в самый разгар жаркой весны, сотрудники фирмы ATI провели конференцию, посвященную описанной в этой статье технологии, подробностям новой игровой приставки Xbox 360 и другим не менее полезным вещам. Было здорово, спасибо Николаю Радовскому и другим представителям компании за полезную информацию и очень компетентные ответы на вопросы!
А теперь, не мешкая, перейдем к сути статьи:
ATI CrossFire — так официально называется канадский ответ на NVIDIA SLI, о котором шептались и «подозревали» технологические форумы сети еще полгода назад. Есть ли отличия? Да, несомненно. Есть ли преимущества? Судя по всему, да, и весьма значительные. Через некоторое время мы опубликуем тесты и практические исследования аспектов качества, а пока исследуем теоретические и архитектурные стороны и попробуем спрогнозировать тенденции и результаты.
Общая архитектура CrossFire
Основная цель технологии — организация совместной работы двух графических ускорителей над построением изображения. Причем, архитектура должна быть не только эффективной (высокий КПД, низкая стоимость дополнительных схем, доступность для простых частных покупателей и энтузиастов), но и удобной в использовании (совместимость с уже существующими программами и даже с уже существующими аппаратными решениями, прозрачность, простота и надежность). Требований очень много, и, забегая вперед, похвалим ATI за качественный и очень продуманный подход при решении этих задач. Итак, нам предложена вот такая архитектура:
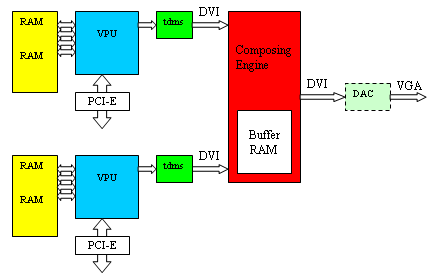
Несколько ускорителей (в варианте для пользователей их два) формируют собственную часть изображения, и выводят её через TMDS трансмиттеры в общепринятом цифровом стандарте DVI. Затем информация попадает в «черный» (на схеме — красный) ящик под названием Composing Engine, устройство, которое собственно и осуществляет совмещение результатов работы ускорителей для получения финального изображения. На выходе из этого красного ящика — вновь стандартный цифровой DVI сигнал, но на этот раз — уже финального кадра, собранного из двух порций данных, рассчитанных обоими VPU. Для устранения проблем с синхронизацией, Composing Engine содержит собственную буферную память, что позволяет этому устройству накапливать данные асинхронно, и, затем, по мере готовности обоих ускорителей, формировать и выдавать результирующий кадр. Таким образом, четкая синхронизация работы VPU не требуется, достаточно двух фактов — каждый VPU должен знать, какую часть данных ему надо рассчитать, и каждый VPU должен закончить передачу рассчитанных данных в этот «красный ящик», Composing Engine. После этого будет осуществлена передача кадра на устройство вывода, в формате DVI или (если нам нужен аналоговый сигнал) на внешний графический DAC, преобразующий цифровой DVI поток в стандартный аналоговый VGA сигнал.
Теперь самый актуальный вопрос как VPU будут делить между собой рассчитываемые данные? Небольшая теоретическая часть на эту тему:
Основные алгоритмы взаимодействия ускорителей
Можно легко выделить три основных алгоритма, применяемых в наше время для этой цели в различных потребительских и профессиональных решениях:
- Разделение экрана на несколько непересекающихся зон (Scissor, также известно как Slicing). Это решение используется в современной технологии NVIDIA SLI, и во многих специальных решениях, таких как симуляторы для обучения пилотов (несколько окон тренировочной установки, модели самолета), большие информационные мультиэкраны и т.д.
Для двух VPU будет происходить вертикальное разделение финального кадра на две зоны. Интересно, что граница зон не обязательно должна проходить по середине кадра и может выбираться динамически, исходя из сложности той или иной части изображения — грубо говоря, в верхней половине может оказаться меньше объектов, чем внизу (небо) и тогда один из ускорителей будет простаивать, что может быть скомпенсировано увеличением его зоны ответственности. Задача подобной динамической балансировки нетривиальна, и требует анализа сцены, что не всегда удобно. Этот метод хорош для сбалансированных по критерию геометрических вычислений / закраска приложений, так как в идеале (при правильном адаптивном делении кадра на зоны ответственности), позволит им поровну распределить и геометрическую и пиксельную нагрузку по двум ускорителям. - Построчное или шахматное или иное чередование рассчитываемых пикселей (Tiling) самый удобный и прозрачный, с точки зрения организации, метод, когда ускорители рассчитывают соседние строчки (SLI от 3dfx, где чередовались четные и нечетные строки) или пиксели в шахматном порядке (фактически почти тоже самое) или соседние отсчеты для AA в рамках одного результирующего пикселя. Таким образом, нагрузка по закраске делится строго поровну, вне зависимости от конкретной сцены, а вот геометрическую нагрузку VPU приходится дублировать — оба ускорителя рассчитывают одни и те же геометрические данные. Получается, что в случае приложений, не упирающихся в геометрическую производительность ускорителя (а в наше время это практически все игровые приложения), этот метод может обеспечить серьезный прирост скорости закраски, вплоть до двукратного (если запас простаивающей геометрической производительности двукратный). Таким образом, мы распараллеливаем пиксельную работу поровну, имея близкий к 100% КПД, без каких-либо видимых проблем совместимости или сложностей в организации балансировки и разделения потока данных. Метод требует минимальных вмешательств в драйверы, прозрачен для приложений и выглядит наиболее оптимальным, сейчас, для игрового пользовательского рынка. Особенно, учитывая все большее число приложений с тяжелой пиксельной нагрузкой и шейдерными спецэффектами. Более того, по ходу дела, этот метод может быть использован для эффективного FSAA, основанного на усреднении отсчетов, рассчитанных разными ускорителями. Что в дополнение к MSAA, реализованному в каждом VPU, даст нам еще и суперсэмплинг (SSAA), способный решить некоторые проблемы не достаточно эффективно устраняемые MSAA.
- Чередование рассчитываемых кадров (Alternate Frame Rendering) методика знакомая нам еще по самому первому многочиповому решению ATI в пользовательской нише — RAGE Fury MAXX. Хороша для приложений, упирающихся в геометрическую производительность ускорителя и не критичных к плавности смены кадров, что, надо отметить, редкость в наше время в игровых приложениях, но может иметь место в DCC/CAD/CAM/CAE применениях (например, при интерактивном редактировании моделей в приложениях для создания реалистичной графики).
Итак, суммируем плюсы и минусы вышеописанных подходов:
Метод | Плюсы | Минусы |
Scissor |
|
|
Tiling |
|
|
Alternate Frame Rendering |
|
|




Какой из них избрали специалисты ATI? Оставайтесь с нами, об этом чуть позже. А пока перейдем к конкретике реализации CrossFire в «железе». Как же вышеописанный метод «красного ящика», объединяющего изображения, был исполнен ATI на практике? Вот так:
Конкретика CrossFire
Итак, у нас есть две карты, установленные в одной системе (требуется материнская плата CrossFire Edition), с двумя графическими PCI-Express слотами форм-фактора x16. Обычная карта ATI и специальная карта ATI с технологией CrossFire:
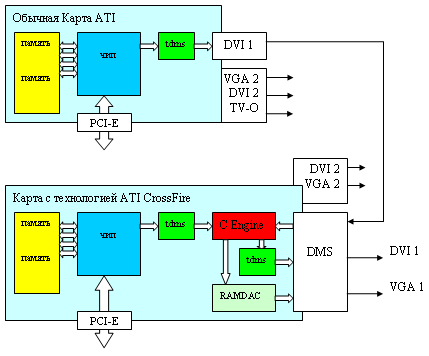
Вот почему статья называется «Асимметричный ответ» ;-) Оказывается, инженеры ATI решили поместить описанный выше «красный ящик» (С Engine на схеме) на одну карту, «главную», и передавать на него данные со второй карты через обычный внешний DVI разъем. Тем самым, создав решение, совместимое с уже существующими картами, выпущенными до появления CrossFire! Разве это не здорово — если у вас уже есть PCI-Express карта ATI с DVI выходом, то вам достаточно докупить специальную CrossFire карту, соединить DVI выход старой карты с новой при помощи специального провода, который идет в комплекте. И ваша суперсистема готова. На выходе новой карты вы получите уже собранное Composing Engine, по результатам работы обоих ускорителей изображение, в DVI или аналоговом VGA формате.
На карте с технологией CrossFire установлен специальный разъем, напоминающий DVI, но имеющий большее число контактов, на схеме он обозначен как DMS. Через этот разъем в карту попадает DVI сигнал с первой карты, через него же из карты выходят сигналы DVI и аналогового VGА результирующего изображения, собранного красным ящиком. Кроме того, на исходной карте остается незадействованным второй выход (DVI+VGA или только VGA), а также TV-Out, а на карте CrossFire — тоже есть второй DVI+VGA. Все эти выходы, не участвующие в совместном построении изображения, разумеется, могут быть использованы для дополнительных мониторов и других стандартных применений в «мирное», не игровое время, но на них естественно нельзя выводить совместное изображение, рассчитанное обоими ускорителями в режиме CrossFire — оно поступает только на выходы разъема DMS.
А теперь самый интересный вопрос. Внимание, знатоки. Какой алгоритм разбиения изображения был выбран ATI для реализации в своем «красном ящике»?
Правильный ответ любой из трех описанных выше!
Физически, на CrossFire карте «красный ящик» представляет собою не специальный чип с жестко запрограммированным в него алгоритмом работы, а небольшой универсальный чип с программируемым массивом логических вентилей. Этот небольшой чип содержит в себе гибко настраиваемую схему логических элементов и буферную память для хранения промежуточных результатов, а алгоритм его работы задается драйверами, загружающими в него соответствующую схему связей. На данный момент ATI реализовали все три выше описанные методики, но это не значит, что в будущем не появятся новые, улучшенные или гибридные решения по разделению нагрузки на два ускорителя. Все, что будет необходимо — просто обновить драйверы. Не удержусь и второй раз похвалю инженеров ATI за элегантное решение — мало того, что такой подход существенно снизил стоимость разработки и внедрения CrossFire, он позволил выбирать для каждого конкретного применения режим, оптимальный с точки зрения КПД (из доступных) и, тем самым, во многом застраховал наши инвестиции в мультичиповое решение от капризов конкретных игр и приложений.
Итак, задействуя CrossFire:
- Мы можем использовать старую карту, уже установленную в нашей системе*, надо купить вторую CrossFire карту и системную плату с двумя графическими слотами PCI-Express (если такой еще нет).
- Мы можем выбирать для каждого конкретного приложения оптимальный метод взаимодействия ускорителей при построении изображения. Причем, мы можем предоставить этот выбор драйверу, и тогда он будет сверяться со списком заранее проверенных ATI приложений, для которых уже подобрана оптимальная установка, или установит самый надежный с точки зрения прозрачности для приложения Tiling метод, если приложение ему не известно. А можем выбрать метод самостоятельно, поэкспериментировав с результатами в конкретном приложении, заботясь о КПД или о максимальном качестве изображения.
- Мы можем получить, в будущем, новые режимы и методы взаимодействия.
- Мы можем на лету, не перезагружая систему, включать и выключать CrossFire, а также менять режимы его работы.
- У нас появляются новые методы AA — когда к 2, 4 или 6 семпловому MSAA в каждом чипе, добавляется еще и 2хSSAA — усреднение результатов в Composing Engine. В итоге получается уже знакомая нам по продуктам NVIDIA гибридная формула. В случае ATI, доступны два новых режима (пока) — SS2х(MS4x) SS2х(MS6х), которые почему-то названы ATI «10хAA» и «14хАА», что не совсем точно ;-) скорее, надо было назвать их «2*4хAA» и «2*6xAA». Разумеется, в таких режимах устанавливается различное расположение отсчетов MSAA для первого и второго ускорителя, только тогда это сглаживание будет иметь смысл. Но, как мы знаем, у чипов ATI паттерн отсчетов гибко задается на сетке 4х4, и таким образом мы можем разместить там два набора по 6 отсчетов так, чтобы они не пересекались.
- Мы можем использовать совместно карты разных производителей (например, ASUS и Sapphire в одной упряжке)!
* При условии, что у вас есть системная плата CrossFire Edition
Какие конкретные ограничения есть у этой технологии на данный момент:
- Технология будет доступна (вначале) только для карт серии X800 и X850. Причем для обычных карт серии X800 необходима X800 карта с технологией CrossFire, а для карты X850 соответствующая CrossFire карта серии X850.
- Любые карты семейства можно сочетать (любая X800 с X800 CrossFire и любая X850 с X850 CrossFire), но число конвейеров будет ограничено до минимального общего — то есть, если одна из карт 12 конвейерная, то и вторая, даже будучи 16 конвейерной, будет работать в режиме CrossFire как 12 конвейерная. Это сделано для балансировки производительности.
- Технология совместного рендеринга работает только на один монитор.
- Пока что объявлена гарантированная (!) совместимость только материнскими платами на чипсетах ATI серии Xpress 200 с приставкой CrossFire Edition для процессоров Intel и AMD, однако по мере тестирования и обкатки будут анонсироваться и совместимые платы на чипсетах других производителей никаких принципиальных проблем в такой совместной работе нет, но могут возникать конкретные несовместимости.

Какие перспективы есть у этой технологии на будущее:
- Ее очень легко адаптировать к другим существующим (X700 и иже) и будущим решениям ATI. Фактически, любая новая флагманская карта ATI может выходить сразу и в исполнении с этой технологией
- Будут проверены и признаны совместимыми новые системные платы с двумя графическими слотами, в том числе на чипсетах Intel и, возможно, даже на чипсетах NVIDIA.
- Позже эта технология может быть масштабирована дальше, не секрет, что по аналогии с процессорами через пару лет могут появиться многоядерные или многочиповые ускорители в одном корпусе, и тогда станут возможными схемы 2*2 (две карты с двумя ускорителями на каждой).
Цены, даты, прогнозы
Теперь немного совсем приземленной конкретики. Для начала цены и доступность:

Причем, на прилавках магазинов CrossFire карты будут уже в конце июня, начале июля.
Вот такие данные по производительности решений с двумя картами, CrossFire X850 XT в сравнении с NVIDIA SLI 6800 Ultra приводит ATI (внимание: в обоих случаях задействованы две карты):
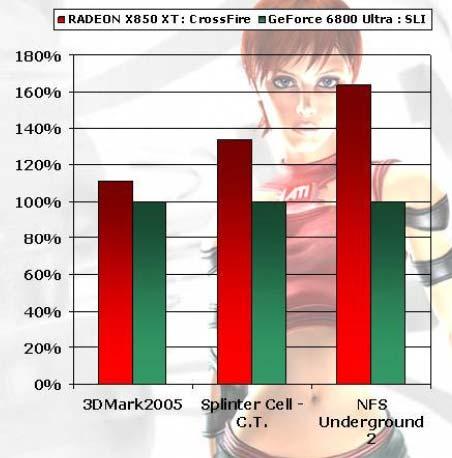
Для разрешения 1600х1200 (4xAA 8xAF)
Воздержимся от комментариев до получения собственных результатов скорости и качества работы этой технологии, а пока же отметим, что SLI работает лишь с ограниченным (причем сильно ограниченным) числом игр, в чем очень заметно проигрывает CrossFire, и, требует покупки двух новых карт, что также не может считаться большим плюсом по сравнению с CrossFire. Которая (потенциально) применима к практически миллиону уже существующих владельцев продуктов на базе всех карт семейства X800 и X850, без необходимости продавать свою старую карту.
Два самых актуальных вопроса: удастся ли ATI удержать это технологическое первенство? Ведь следующее поколение продуктов NVIDIA может взять на вооружение лучшие находки канадских специалистов в том или ином виде. И почему технология называется CrossFire — не имелась ли в виду одноименная машина фирмы Chrysler ? ;-)
Разумеется, реально очень многое будет зависеть от соотношения цена / производительность в конкретных играх. А также от наличия проблем с качеством изображения и совместимостью. Все эти аспекты мы исследуем в ближайшее время, а пока же подведем промежуточный итог:
Инженеры ATI создали очень выгодную, гибкую и удобную архитектуру многочипового рендеринга, нацеленную на конечных пользователей и игровые приложения. На бумаге перспективы CrossFire выглядят более заманчиво, чем NVIDIA SLI, а архитектурное решение можно (и нужно) признать более изящным и продуманным. В активе и совместимость с уже существующими картами и работа со всеми приложениями, и гибкий выбор метода совместной работы ускорителей. Разумеется, подобная технология нацелена на достаточно узкую нишу энтузиастов, и не принесет компании особенной сверхприбыли, но не следует забывать, что лидерство в абсолютном зачете, которое может обеспечить CrossFire, несомненно, скажется на продажах mainstream продукции ATI в лучшую сторону, а технологическое лидерство в такой области — не менее осязаемый и ценный вклад в имидж компании.


