Вступление
В данной статье рассматривается оригинальный графический движок для компьютерных игр, основанный на методе трассировки лучей — совершенно отличном от используемых в современных популярных трёхмерных играх. Соответственно, движком не используются(!) 3D-акселераторы, без которых, казалось бы, немыслима игровая графика.
Речь пойдет о необычных возможностях, предоставляемых движком, и принципах его работы. Кроме того, будут рассмотрены аспекты оптимизации приложений под SIMD расширения. В первую очередь, под SSE — дополнительный набор процессорных команд, впервые реализованный в процессорах Pentium III, Celeron II. Наконец, будут приведены показатели производительности программы на новейших процессорах.
Автор выражает надежду, что чтение данной статьи не вызовет затруднений у любого читателя iXBT.com, для которого эта статья будет не первой.
Зачем?
Действительно, зачем нужно изобретать ещё один движок, когда их и так огромное количество? Что ещё нужно, когда есть потрясающие по качеству движки Quake III и Unreal?
Возьмите в руки самую мощную базуку, развернитесь к какой-нибудь стене и стреляйте бесконечно долго. Ничего не случится: уровень современной трёхмерной игры выточен из абсолютно твёрдого тела. Это не сильно обедняет gameplay, игровой процесс, если вы спустились в эти катакомбы пострелять пару часов. А если вам тут жить? Что-то хочется достроить, что-то — расширить. Может, вам самому захочется построить себе дворец. Может, другим игровым персонажам захочется его разрушить.
Все подобные возможности должны поддерживаться графическим движком игры. Играющему дано делать только то, что позволяет движок и ничего более. А если играющий захочет всё взорвать? А если захочет выключить один светильник и включить другой в другом месте? В ответ подобным поползновениям движок лишь промолчит.
Соответственно, и игр таких в полном 3D нет. Почему так? Всё просто: чтобы быстро рисовать большие уровни, их заранее долго просчитывают и при отрисовке кадра используют записанную информацию. Например, есть комната, заранее определяется, какие другие комнаты видны из неё и, когда играющий находится внутри этой комнаты, рисуются только эта комната и видимые из неё. Это позволяет многократно уменьшить количество рисуемых за кадр треугольников. Зато, выломать стену комнаты нельзя: алгоритм даст сбой, не будет рисовать то, что открылось. Так как это не просчитано заранее.
Ладно бы были проблемы только с видимостью: рисовали бы уровни поменьше, пока ускорители недостаточно мощные. Проблема гораздо глубже. Дело в том, что нужно ещё рассчитывать тени от объектов, стен, лестниц и т.д. Чтобы сцена выглядела реалистично, она должна быть реалистично освещена. Под лестницей темновато, около окна светловато. Сломайте лестницу, закройте окно — освещение никто не изменит, поскольку его очень долго вычислять на базе современных алгоритмов рисования треугольников с помощью z-буфера. Доказывать тут нечего: если бы было легко, это давно бысделали, благо акселераторы уже весьма мощные. Источник света даже подвигать нельзя — как в таком доме жить?
Подойдём к проблеме с другой стороны. Уровень, вместе со всей предварительно просчитанной информацией, занимает весьма нехило — мегабайты. А если уровни нужно очень часто подгружать в многопользовательской игре по интернет?
Что?
Я решил создать графический движок, удовлетворяющий следующим требованиям: нет никакой предварительной обработки сцены, положение и количество источников света и объектов может меняться произвольным образом в любое время. То есть, каждый кадр рисуется как бы новая сцена. Это должно позволить создавать новые оригинальные игры и расширить известные жанры.
Ничто не даётся задаром, всегда приходится чем-то жертвовать. Я пожертвовал представлением объектов посредством треугольников. В качестве базовых примитивов были выбраны сферы. То есть, объекты будут представляться не совокупностью треугольников, а совокупностью сфер.
Ясное дело, что как из треугольников, так и из сфер можно составить любой объект. Вопрос стоит лишь в количестве необходимых примитивов. Надо стараться обойтись как можно меньшим, иначе производительность упадёт ниже нижнего.
Почему в качестве примитивных элементов выбраны именно сферы, а в качестве метода — метод трассировки лучей? Дело в том, что при полигональном представлении объектов, треугольниками, например, очень много труда уходит на рассчет тени от объекта. Существуют разные методы — см. статью "Обзор алгоритмов построения теней в реальном времени". Они либо неявно требуют предварительную информацию об объекте, как метод теневых объёмов — иначе этот метод будет страшно долго работать на сложных объектах, либо требуют многократной отрисовки объекта (в текстуру) и нещадно эксплуатируют видео-ускоритель, как методы наложения теней с помощью проективных текстур. Отмечу ещё один их существенный недостаток, который не очень заметен в различных демонстрационных программах: если объект отбрасывает тень на удалённый предмет, то тень от него будет очень угловатой. Чтобы этого не случилось, объект необходимо отрисовывать в теневую текстуру с гигантским разрешением.

Shadowcast — демонстрационная программа от NVidia. Не самая новая, GF3 не требует.
Видимо, не случайно затеняемая площадка мала. Но всё равно заметно, как с увеличением расстояния от объекта до тени, тень огрубляется.
Далее, возникают проблемы с самозатенением объекта: когда объект отбрасывает тень сам на себя, а не на отделённый от него предмет. Эти проблемы носят на самом деле фундаментальный характер, в том смысле, что они органически присущи методу визуализации посредством отрисовки треугольников и применения z-буфера.
Рассчитывать тень от сферических объектов легко, рисовать сферы методом трассировки лучей тоже относительно легко — это и определило мой выбор.
Скорость трассировки лучей
Одним из свойств алгоритмов трассировки лучей заключается в большой зависимости скорости работы от разрешения экрана. Типичная формула времени работы выглядит таким образом: c1*n*ln(n)+c2*n*n+c3*ScreenWidth*ScreenHeight. c1, c2, с3 — некоторые константы, n-количество объектов на сцене. В первую очередь, рассмотрим главный член — c2*n*n, имеющий второй порядок по количеству объектов на сцене. Его происхождение просто: это время расчёта теней. Как ни крути, в этом вопросе от квадратичной зависимости далеко не уйти. Различные методы оптимизации, кластеризация объектов и т.п., в общем случае позволяют лишь уменьшить константу c2, не более. Этот член жестко лимитирует количество объектов на сцене. Начиная с некоторого момента, незначительное увеличение числа объектов вызывает очень большое падение производительности.
Влияние первого члена на общее время работы не очень существенно. Таким образом, когда сцена заполнена объектами в наибольшем возможном количестве, на первое место выходит последний член, зависящий от разрешения экрана. Эта величина отражает скорость собственно трассировки лучей, соответствующих точкам экрана. Это константа, но гигантская! Гигантская благодаря большой величине площади экрана в пикселях. Например, 800*600=480000, 1024*768=786432. Для современных процессоров получается всего около 100 тактов на обработку луча при частоте кадров около 25.
Некоторое недоумение вызывает независимость c3 от количества объектов. Дело в том, что анализ сцены перед запуском цикла трассировки позволяет существенно оптимизировать расчёты в самом цикле. За счёт этого, сколько бы ни было объектов на сцене, будет искаться пересечение луча с фиксированным количеством объектов. В принципе, с3 зависит от n, но этой зависимостью можно пренебречь.
Одним из главных последствий существования этой константы стала невозможность осуществления трассировки лучей в реальном времени на старых персональных компьютерах, оснащённых процессорами PentiumII и ниже. Эта константа даже на маленьких разрешениях — 400х300 — полностью съедала всю мощность процессора. Но сейчас этот барьер пройден! Производительности новейших процессоров для персональных компьютеров хватает для осуществления трассировки лучей в высоких разрешениях.
Далее я приступаю к описанию созданного мною графического движка VirtualRay, умеющего рисовать только объекты из сфер, зато позволяющего радикально изменять сцену в реальном времени.
Движок VirtualRay
Рабочими разрешениями движка VirtualRay на процессорах Pentium III с SSE являются разрешения 640x480 и 800x600 с глубиной цвета 32бит, то есть, движок работает в true color.
Естественно, очень много произвольно расположенных сфер отрисовывать не получилось. С приемлемой скоростью рисуются сцены, состоящие из нескольких тысяч сфер. Соответственно, движок хорошо рисует те объекты, для которых представление сферами легко возможно. Например, космос: планеты, звёзды, космические корабли и космические станции. Чудовищ, инопланетян, иномирян и их жилища. Технические объекты. Символы, абстрактные создания и сюрреалистические миры.
Поддерживается наложение и билинейная фильтрация текстур, что обеспечивает качественное изображение.
В угоду быстродействию выбрана простейшая модель освещённости, все источники света считаются точечными.
Возможна прозрачность сфер, причём коэффициенты прозрачности могут динамически меняться, и могут быть различными для каждого цветового канала.
Источника света также могут быть цветными.
Движок может работать в произвольном разрешении, как 320x240 и ниже, так и 1600x1200 и выше. Весь вопрос в скорости работы.
Более описывать нет смысла, как говорится, лучше один раз увидеть, чем сто раз услышать. На сайте www.virtualray.ru, находится текущая демо-версия движка и скриншоты. Ввиду моих низких художественных и моделлерских способностей создать высокоэстетичную демо-версию со стильными текстурами не очень получилось, получилось — технологическую демо-программу. Однако, её можно использовать в качестве игрушечного строительного конструктора из шаров.
Для ознакомления с демкой требуется компьютер с процессором PentiumMMX и выше и видео-карточка, поддерживающая true color в 32-битном формате. (совместимости с Intel 740 нет, так как там true color только в формате 24 бита. Но практически все современные карточки поддерживают необходимый формат). Одно замечание: иногда формат представления цвета в видеокарте определяется неправильно и, например, небо получается желтым вместо голубого. В этом случае рекомендуется угадать и выбрать в меню более подходящий формат. Так как на больших мониторах низкие разрешения выглядят слишком зернисто, для повышения быстродействия вместо уменьшения разрешения лучше слегка уменьшить площадь экрана.
Ниже я приведу несколько скриншотов из демо-версии. Они весьма неполно передают возможности движка, так как одним из его достоинств является динамическая игра света и тени, непередаваемая статическим изображением.

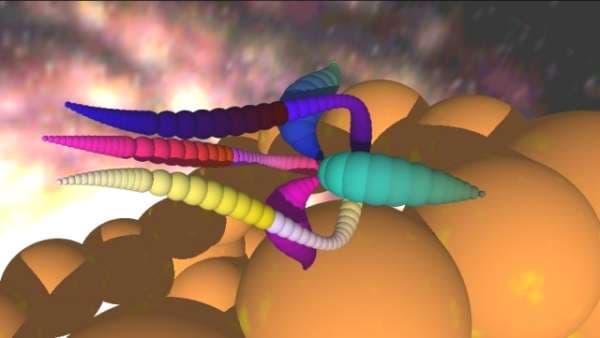

Производительность
Частота кадров — показатель, на который обращают внимание в первую очередь. Мы ещё коснёмся производительности движка на различных системах, сейчас же рассмотрим показатели на системе на базе PentiumIII800EB. Отмечу, так как движок не использует видео-ускорители, его производительность практически полностью определяется мощностью процессора.
Типичная частота кадров — 20 в разрешении 800x600x32 (800x450x32). Вроде бы совсем не впечатляет на сегодняшний день. Однако, FPS движка обладает двумя очень полезными свойствами, которые отчасти компенсируют её относительно небольшую величину. Первое свойство заключается в близости минимального и среднего FPS. Среднее FPS может быть 25, а минимальное — 22. А минимальное FPS, это даже более важный параметр, чем среднее. Во многих играх когда ходишь — частота кадров около 50, а только начнётся стрельба, враги появятся, FPS сразу упадёт вдвоё и больше.
Второе важное свойство — стабильность частоты кадров. Что это такое? Допустим, есть 50 кадров в секунду. Вроде бы, много. По идее, каждый кадр отрисовывается за 20 миллисекунд. Но в реальности некоторые кадры могут рендерится значительно дольше 20 миллисекунд, а другие — соответственно быстрее. В частности, такое может быть из-за необходимости периодически кэшировать данные, например, при повороте камеры. В результате, при формально высоком среднем FPS движение может не быть плавным. Движок VirtualRay рисует кадры независимо и демонстрируемый FPS реалистичен.
В общем, для чемпионата профессиональных квакеров не подойдёт, но играть вполне возможно. Особенно в игры, жанр которых не требует исключительно стрельбы.
Хочу также отметить, что не все оптимизирующие алгоритмы проверены, не все оптимизирующие алгоритмы придуманы. Я надеюсь, что ещё удастся увеличить скорость работы движка.
Устройство Сферического движка
Сферический движок почти полностью основан на алгоритмах, хорошо известных в компьютерной графике и многократно и детально описанных в книжках, посвящённых методу трассировки лучей. Мне практически не пришлось придумывать оригинальные алгоритмы, только адаптировать известные к сферам и real-time. Я отсылаю заинтересованного читателя, например, к книжке Е.В. Шикина, А.В. Борескова "Компьютерная графика. Динамика, реалистические изображения" Москва.: "Диалог-МИФИ". В интернете можно найти достаточно примеров из этой книжки. Видимо, где-то есть и текст. Если же у вас нет трудностей при чтении английских текстов, то просто море информации о трассировке лучей к вашим услугам в англоязычном интернете. Правда, я в большей степени основывался на знаниях из учебника по аналитической геометрии.
Рассмотрим принципиальную схему работы движка. Engine разбит на две существенно различающиеся части: в первой части осуществляется предварительный анализ сцены, вторая часть — двойной цикл трассировки лучей, отвечающих точкам экрана.
На входе движок получает описание сцены: положение и свойства сфер, расположение и параметры источников света. Эти данные попадают в блок первичного анализа — первую часть блока предварительного анализа сцены. В нём происходит отсечение не попавших в кадр сфер и источников света, зоны действия которых не видны. Происходит приведение координат объектов относительно положения наблюдателя, рассчитываются часто используемые далее величины, вроде расстояний до сфер.
Далее начинает работу блок распределения сфер по областям экрана. Экран разбивается на много прямоугольных областей, для каждой из которых вычисляется массив потенциально видимых сфер. То есть тех сфер, с которыми могут пересечься лучи, отвечающие точкам экрана, составляющим данную область.
Путём измельчения областей можно добиться, что бы почти на любую область приходилось всего несколько сфер, что сильно снижает затраты в гигантском цикле трассировки лучей.
Затем осуществляется расчёт отношения затенённости. Для каждой сферы определяется, сколько источников света её освещают. Если их много, то выбираются несколько, вносящие основной вклад в освещённость.
Для каждой сферы находятся все сферы, затеняющие её. Это несложно сделать благодаря простоте геометрической формы сферы. Теперь, когда затенители определены, точка сферы в цикле трассировки проверяется на затенение лишь ограниченным кругом сфер. Информация о затеняющих сферах, как то относительное положение и расстояние, упаковывается в оптимальный для вычислений при помощи SSE. Подробно об оптимизации под SSE — позднее.
Всё, можно запускать цикл трассировки.
Замечание к реализации. Первая часть, реализующая сложные и разнообразные алгоритмы, целиком написана на языке C++. Вторая часть, исходный код которой значительно меньше в размере, полностью написана на ассемблере и имеет три варианта, написанные для различных процессоров. Варианты различаются набором используемых команд. Оптимально использование SSE, но возможна работа и на компьютерах без SSE, необходима только поддержка технологии MMX. Конечно, на стареньком Pentium166MMX программа будет работать в режиме слайд-шоу, но в маленьком окошке можно посмотреть.
| Набор команд | Процессоры |
|---|---|
| SSE + Enhanced MMX | Pentium III, Pentium4, Celeron II, AthlonXP |
| FPU + Enhanced MMX | Athlon, Duron, (K6-III, K6-2+) |
| FPU + MMX | Pentium MMX, Pentium II, Celeron, K6-2 |
Отмечу, что для работы с вещественными числами используется SSE/FPU, для работы с целыми числами и числами с фиксированной точкой используется MMX. Обычные регистры (eax, ebx, ecx, edx, esi, edi) используются для хранения и вычисления адресов и флагов.
Программа откомпилирована при помощи IntelC++Compiler4.5, встроенного в Microsoft Visual C++ 6.0.
Области применения Сферического движка
Где можно использовать столь необычный движок, очень хорошо делающий одно и крайне плохо другое? Область применения сферического движка можно разделить на две части: использование в компьютерных играх и применение в иных целях. Начнём с не совсем игровых приложений.
Очевидно узкоспециальное приложение к визуализации моделей молекул и атомов. Правда, тени там выглядят неуместными: атом ведь не шарик. Описание шара занимает даже меньше места, чем описание треугольника, а шар всё-таки более богатая фигура. Это наталкивает на мысль о применении движка в интернете. Можно рисовать и легко пересылать эмблемы, логотипы, символические анимированные сценки. Для этих целей производительности движка вполне хватит — это же не на полный экран выводить сцену с большой частотой кадров. Плюс — практически полная независимость от видео-карточки: не нужно возится с драйверами, не нужно тестировать на миллионе конфигураций, не нужно обращать внимание на поддержку операционной системой графических библиотек. Есть ли DirectX, какая версия OpenGL — все эти вопросы особой роли не играют. Обеспечивается идентичность изображения у всех пользователей, с точностью до монитора, конечно. Это не так, как у видео-ускорителей: один поддерживает одно, другой — другое. На одном тени видны, на другом — нет, на третьем видны, но жутко тормозят.
Плавно перейдём в другую область применения движка. Онлайновые игры через интернет — вот где замечательно проявляются достоинства сферического движка. Как хорошо в многопользовательских играх дать возможность участникам в полном 3D в режиме реального времени строить и разрушать игровой уровень по своему усмотрению! И относительная низость FPS не так важна — всё равно связь мешает точному прицеливанию. Да и суть многопользовательской игры не всегда полностью состоит из одной стрельбы.
Игровую вселенную можно разбить на анклавы, представленные автономными сценам, между ними организовать какие-нибудь гиперпереходы. При перемещении новая сцена будет грузиться мгновенно.
Космические симуляторы любых видов — ещё одно поле приложения движка VirtualRay. Планетные системы, астероидные поля, космические аппараты — всё это прекрасно изображается при помощи сфер. Можно составить этакую "Звезду Смерти" и взорвать её при необходимости.
Игры аркадного толка также вполне могут базироваться на Сферическом движке.
Возможны приложения в играх экзотических жанров. Например, в играх, основанных на конструировании механизмов или создании живых существ.
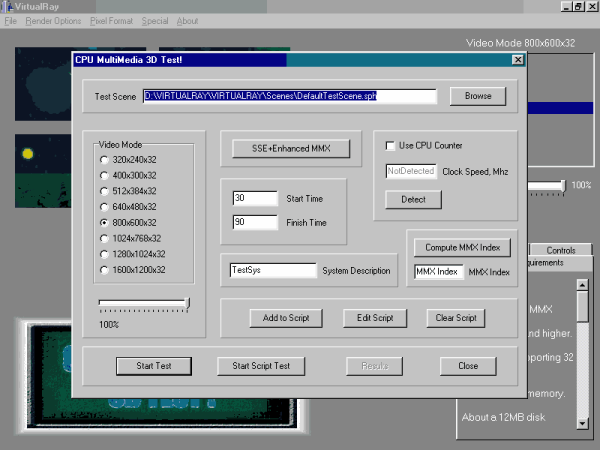
CPU MultiMedia 3D Test!
Есть ещё одно, самое очевидное, приложение Сферического движка. Производительность — это палка о двух концах: можно измерять скорость работы программы на данной системе, а можно — тестировать производительность системы при помощи измерения скорости работы данной программы. В демо-версию встроен CPUMultiMedia3DTest! — графический тест производительности подсистемы процессор + память. Сейчас я расскажу о специфике и преимуществах данного теста, и мы также коснёмся вопроса быстродействия программы на процессорах PentiumIII и AthlonMP. Читатели, не интересующиеся тестированием процессоров, могут пропустить этот раздел.
CPU MultiMedia 3D Test! — это тест процессора с точки зрения геометрических расчётов.
Графическое приложение, будь то студия трёхмерной графики или графический движок трёхмерного шутера, принципиально есть реализация на компьютере решения некоторой геометрической задачи. А решение любой геометрической задачи в конечном итоге разбивается на простые операции — в первую очередь, скалярное произведение векторов, вычисление нормы вектора, операции сложения-умножения векторов и матриц.
Ещё раз, эти операции постоянно повторяются в любом графическом приложении, более того, основная вычислительная нагрузка приходится именно на их выполнение.
Данный тест как раз и предназначен для определения производительности процессора в такого рода задачах.
Тест основан на измерении скорости отрисовки сцены графическим движком "VirtualRay". Как уже упоминалось, этот движок построен на методе обратной трассировки луча и не использует видеоускорители. В процессе его работы выполняется огромное количество сложных геометрических расчётов.
Полная "софтовость" движка позволяет практически полностью нивелировать влияние видеосистемы, скорости прокачки текстур через AGP и т.п. на результаты тестирования. Таким образом, получается чистая производительность системы процессор + память.
Особенности различных вариантов блока трассировки лучей (второй составляющей движка)
Как уже отмечалось выше, написанный на ассемблере цикл трассировки лучей имеет три варианта, отличающиеся набором используемых команд. SSE+EMMX вариант, FPU+EMMX вариант, FPU+MMX вариант.
Движок изначально проектировался с ориентацией на технологию SSE (Streaming SIMD Extension), так что SSE+MMX вариант полностью использует возможности SSE, там данные организованы специальным образом, мало переходов, используется инструкция предварительного кэширования данных, хранения часто используемых операндов в регистрах SSE. В этой части вообще нет команд FPU, поэтому использование MMX не вызывает обычных затруднений из-за несовместимости с FPU.
В FPU вариантах вместо SSE используется FPU, происходит постоянный swap регистров FPU в память, поскольку вместимость регистров FPU в четыре раза меньше, чем регистров SSE, и доступ к ним затруднён из-за стековой организации. Совершаются также лишние операции сохранения/восстановления регистров MMX и переключения из режима MMX в режим FPU и обратно.
В FPU+MMX режиме дополнительно к режиму FPU+EMMX происходит эмуляция недостающих в MMX команд EMMX, что вызывает дополнительную нагрузку на блок MMX и дополнительный swap MMX регистров.
Ввиду специальной оптимизации под SSE и отсутствия команд FPU, первый вариант является хорошим тестом качества реализации SSE.
Использование MMX
С помощью MMX происходит работа с цветом, в первую очередь, текстурирование, билинейная фильтрация и т.п. В связи с этим, если сцену выводить без текстур, то влияние MMX части будет крайне незначительно на общую производительность. Будет также уменьшено влияние памяти, так как выборка элемента текстуры может приводить к задержкам.
Таким образом, можно получить индекс производительности MMX — выводить сцену одинаковой геометрии, текстурированной и без текстур, и сравнивать результаты. И это несмотря на слитность MMX кода и других частей программы.
Метод измерения
Для получения результатов измеряется среднее время работы различных блоков движка на некотором периоде времени при отрисовке динамической сцены. Движение сцены синхронизировано с течением реального времени и не зависит от fps. Таким образом, в разное время несколько изменяется характер вычислительной нагрузки.
Конечный индекс производительности есть обратная величина среднего времени работы соответствующего блока при отрисовке одного кадра.
- FPUС++ Index — первая часть движка, которая написана на C++
- SSE+EMMX Index — соответствующий вариант второй части движка.
- FPU+EMMX Index — соответствующий вариант второй части движка.
- FPU+MMX Index — соответствующий вариант второй части движка.
- Overall Index — совместное время работы двух блоков.
Этот результат можно интерпретировать как fps, который был бы, если бы работала только данная часть. Поскольку основная вычислительная нагрузка, как правило, приходится на цикл трассировки лучей (вторая составляющая), то её индекс близок к реальному fps. Однако, можно создать такую сцену, где бы большая часть нагрузки приходилась на первый блок анализа сцены.
Отметим, что реальный fps зависит от дополнительных факторов, как то синхронизация переключения страниц с частотой обновления монитора, времени работы процедуры изменения сцены и т.д.
Интерпретация
FPUС++ Index отражает производительность системы при выполнении сложных, вычислительно тяжёлых алгоритмов, насыщенных ветвлениями. Алгоритмов, написанных на языках высокого уровня без всякой SIMD оптимизации.
SSE+MMX Index отражает производительность SSE (+EMMX) в задачах 3D-графики на специально оптимизированном под SSE коде, с минимальным количеством переходов, при использовании оптимальной для SSE организации данных.
FPU+EMMX, FPU+MMX Index есть индекс производительности FPU (+MMX) в геометрических — графических приложениях, интенсивно работающих с векторами, матрицами и рисующих изображения.
Overall Index — комплексный показатель производительности системы.
Результаты тестов Pentium III, Athlon MP, Pentium 4, Athlon XP, etc
Мне пока не удалось провести обширного тестирования различных процессоров. Но это тестирование идет и во второй части этой статьи я представлю массу цифр и графиков, а также дам комментарии.
Замечание об акселераторах
Мне могут возразить и возразят, что нынешние самые современные видео-ускорители всё равно круче. Скоро, мол, цена на gf3 упадёт до 50$, никакой сферический движок не будет нужен. В ответ я хотел бы ответить следующее: с научно-исследовательской точки зрения некорректно сравнивать производительность программно реализованных алгоритмов, и ,так сказать, hardware accelerated алгоритмов. Может быть, если бы рейтрейсинг ускоряли с помощью железа, то такая производительность была бы — закачаешься.
Давайте сравнивать с программными движками, базирующимися на отрисовке треугольников при мощи z-буфера. C QuakeI и Unreal. Unreal, кстати, разрабатывался как софтовый движок, там, между прочим, применили продвинутый метод программного сглаживания текстур. В нём до сих пор остались следы этой первоначальной ориентации.
Quake неплохо работает, в отличии от Сферического движка, на старых компьютерах, и на новых PentiumIII показывает более высокий FPS. Но динамического освещения, теней, сглаженных текстур и true color там и близко нет. Как его возможности расширить до возможностей движка VirtualRay, совершенно не видно. Отмечу, что Сферический движок тоже не очень-то расширишь до QI. То есть, они не сравнимы.
Unreal, вроде бы, более развитый движок, чем QI, но скорость его работы гораздо ниже. В высоких разрешениях (640x480x16, 800x600x16) средний FPS около 20, минимальный вообще бывает около 15. Ничего принципиально нового там не появилось. И качество изображения всё равно оставляет желать лучшего.
Возможно, как раз тогда индустрия зашла в алгоритмический тупик, но появление видео-ускорителей разрешило экстенсивное развитие, развитие не в глубь, а вширь. В течение довольно долгого периода времени почти все усовершенствования сводились к увеличению числа полигонов в кадре. Ничего принципиального не добавлялось.
Гораздо интереснее рассмотреть аспекты совместной работы Сферического движка и 3D-акселераторов. Принципиально можно часть изображения и специальные эффекты нарисовать с помощью ускорителя и обогатить изображение. Конечно, частично теряется независимость движка, но, в некоторых случаях это, может быть оправдано. Однако, как всегда и бывает, искусственные препоны мешают делу. Отсутствие интерфейса чтения/записи в z-буфер ускорителя сильно затрудняет совмещение изображений. Объекты, нарисованные различными методами, не будут правильно заслонять друг друга. Тем не менее, готовится версия движка, умеющая рисовать при помощи акселератора разнообразные эффекты, сияния вокруг источников света, частицы и т.п.
Оптимизация под SSE
Достижение приемлемой производительности в высоких разрешениях стало возможно в первую очередь благодаря оптимизации под набор команд SSE. На процессорах без SSE программа выглядит бледно.
SSE — Streaming SIMD Extension. Потоковое SIMD расширение, если дословно переводить. SIMD — Single Instruction Multiple Data. Одна инструкция выполняет действия сразу с несколькими операндами.
Специфика движка состоит в том, что сотни тысяч раз выполняется процедура трассировки луча, и этот цикл занимает больше всего времени. Эту относительно небольшую процедуру и необходимо оптимизировать в первую очередь, поскольку самый небольшой выигрыш скорости умножается многократно.
В движке использовано два основных приёма оптимизации: специальная организация данных для SIMD технологии и хранение данных непосредственно в регистрах SSE.
Рассказ о SSE
Чтобы было более понятно, я приведу небольшой рассказ про SSE. Подробная спецификация команд SSE доступна на сайте корпорации Intel, в книжных магазинах уже давно появились книги, описывающие предмет. Я же расскажу в общем.
Итак, к стандартной архитектуре добавились 8 новых регистров. Это регистры прямого доступа, в отличие от регистров FPU, которые организованы в стек, что существенно усложняет программирование на ассемблере для FPU. В терминах языка C регистры имеют тип float[4] float=single — число одинарной точности, занимающее 4 байта. Таким образом, общий размер SSE регистров целых 128 байт, 32 числа с плавающей точкой, в 4 раза больше, чем FPU. FPU, правда, умеет работать с числами с повышенной точностью, но в движке они не используются.
С этими регистрами возможны следующие действия: загрузить/ выгрузить в память, перетасовать элементы одного или двух регистров. Например, первые два элемента одного регистра заменят последние два другого. Арифметические действия (сложение, вычитание, умножение, деление) с парой регистров как с векторами, то есть, операции производятся поэлементно. Извлечение квадратного корня из каждого элемента регистра и нахождение приближённого значения обратной величины и обратной к квадратному корню величины.
Покомпонентное сравнение двух регистров и покомпонентное нахождение максимума и минимума.
Конвертация в целое число, причём можно сразу записать значение в MMX регистр.
Побитовые логические операции с регистрами, как с последовательностью бит. Регистры как бы имеют тип bool[128].
Инструкции загрузки в кэш данных, которые будут востребованы позже. Эти инструкции призваны предотвращать простой процессора в ожидании данных из памяти.
Почти все вышеупомянутые операции можно так же проводить с одними (одним) первыми элементами регистров. Это сделано, в первую очередь, для удобства.
Обобщая, можно сказать, что добавлены команды для выполнения арифметических операций с четырёхмерными векторами и вспомогательные инструкции.
Основа оптимизации программы под SSE — такая организация кода, чтобы было естественно выполнение одной арифметической операции над четырьмя независимыми парами операндов.
Какие к этому могут быть препятствия? Вообще-то, далеко не всегда подряд выполняются четыре однотипные операции, четыре сложения или четыре умножения. Но это ещё полбеды, операции можно переставить. Очень часто проведение последующей операции зависит от результата предыдущих. Например, между двумя сложениями стоит сравнение и ветвление.
Наиболее естественная область приложения SSE — оптимизация как раз линейной алгебры. Умножение-сложение матриц от 4x1 до 4x4 — "любимые" операции SSE. Там нет ветвлений и действия однотипны.
Для поддержки разработчиков Intel выпустил специальную библиотеку — Small Matrix Library. В ней реализованы класс матрица, класс вектор. Операторы, отвечающие арифметическим действиям, реализованы как inline функции, написанные в кодах SSE. Есть и FPU вариант, и при компиляции можно указывать целевую платформу. Очень удобно, можно сразу получить два варианта: для процессоров с SSE и без. И при разработке вообще не думать ни о каком SSE, просто использовать классы, отвечающие матрицам и векторам. Благо, IntelC++Compiler для всех операторов искусно вставит SSE-оптимизированный код.
В дистрибутив Small Matrix Library (SML) входит интересная программа, демонстрирующая преимущества SML. Она считает время выполнения операции при оптимизации под SSE и FPU.
Ниже я привожу её лог.
| Операция | SSE/FPU | Время выполнения* |
|---|---|---|
| 3x3 * 3x1 | FPU | 31 |
| 3x3 * 3x1 | SSE | 29 |
| Transpose(3x3) * 3x1 | SSE | 23 |
| 4x4 * 4x1 | FPU | 53 |
| 4x4 * 4x1 | SSE | 31 |
| Transpose(4x4) * 4x1 | SSE | 27 |
| 3x3 * 3x3 | FPU | 79 |
| 3x3 * 3x3 | SSE | 59 |
| 4x4 * 4x4 | FPU | 172 |
| 4x4 * 4x4 | SSE | 90 |
| 6x6 * 6x1 | FPU | 113 |
| 6x6 * 6x1 | SSE | 60 |
| 6x6 * 6x6 | FPU | 652 |
| 6x6 * 6x6 | SSE | 307 |
| 4x4 * 4x4 (general case) | SSE | 529 |
| Inverse 4x4 | FPU | 392 |
| Inverse 4x4 | SSE | 209 |
| Inverse 6x6 | FPU | 1118 |
| Inverse 6x6 | SSE | 600 |
*Время выполнения указано в тактах процессора. Замеры производились на PIII 800EB.
Отмечу, что при замерах все данные находились в кэше.
Необходимые пояснения. 4x4 * 4x4 (general case) — 4x4 матрицы перемножаются как mxn матрицы, с использованием циклов. В остальных случаях размер матриц известен заранее, что позволяет избавиться от циклов и добиться таким образом серьёзной оптимизации.
Проанализируем результаты. Первое, что бросается в глаза, это маленькое различие в скорости между SSE и FPU вариантами 3x3 * 3x1 и неожиданная прибавка производительности в случае транспонирования матрицы. Это объясняется необходимостью в одном из вариантов дополнительно тасовать содержимое регистров, что бы строки матрицы правильно "легли" для умножения на вектор.
Естественен разрыв относительного выигрыша в производительности между умножениями трёхмерных и чётырёхмерных матриц. Напомню, что регистры SSE четырёх элементные.
Тем не менее, в части движка, написанной на C++, SML почти не используется. Дело в том, что в блоке предварительного анализа сцены мало умножений и обращений матриц и много ветвлений. В основном, только умножение трёхмерной матрицы на вектор. И вектора, в основном, трёхмерные. Ввиду этого, я решил сконцентрироваться на оптимизации под SSE процедуры трассировки луча.
Выше было написано, что в SSE есть, теперь надо сказать, чего в SSE нет. Там нет простой реализации главной для локальной геометрии пространства, в котором мы живём, операции — скалярного произведения трёхмерных векторов.
Чтобы эффективно выполнять эту операцию при помощи SSE, надо восемь векторов поставить на попа и загнать в таком виде в регистры SSE. Тогда можно тремя умножениями и двумя сложениями получить значения четырёх скалярных произведений.
| 4 элемент | 3 элемент | 2 элемент | 1 элемент | Регистр SSE |
|---|---|---|---|---|
| XMM7 | ||||
| XMM6 | ||||
| VectorB4.x | VectorB3.x | VectorB2.x | VectorB1.x | XMM5 |
| VectorB4.y | VectorB3.y | VectorB2.y | VectorB1.y | XMM4 |
| VectorB4.z | VectorB3.z | VectorB2.z | VectorB1.z | XMM3 |
| VectorA4.x | VectorA3.x | VectorA2.x | VectorA1.x | XMM2 |
| VectorA4.y | VectorA3.y | VectorA2.y | VectorA1.y | XMM1 |
| VectorA4.z | VectorA3.z | VectorA2.z | VectorA1.z | XMM0 |
Ввиду этого, при помощи SSE оптимизирована только процедура обработки луча, зато она целиком написана на ассемблере, вообще без применения FPU, и скалярные произведения вычисляются оптимальным образом. Соответственно, данные, например, информация о затенителях сфер, записаны в оптимальном для загрузки в SSE-регистры виде, что обеспечивает наилучшую производительность.
Сравнение SSE, SSE2, 3DNow!, 3DNow!Pro
Проведём теперь сравнительный анализ различных SIMD-расширений процессорных команд. 3DNow! — SIMD-расширение от AMD, впервые появившееся в процессорах k6-2. С появлением новых процессоров AMD 3DNow! пополнялось новыми командами, но принципиальных изменений не происходило. Главных отличий от SSE два: регистры 3DNow! двухэлементные, а не четырёхэлементные, как регистры SSE. Можно сказать, имеют тип float[2]. И набор команд аналогичен SSE, только они работают с двумя парами операндов. И второе отличие: 3DNow! и FPU не могут работать параллельно, приходится вызывать специальную довольно медленную команду переключения в режим FPU с потерей всего содержимого регистров 3DNow!, так как они физически совпадают с регистрами FPU. И MMX тоже особенно не попользуешься, поскольку MMX приходится делить с 3DNow! все те же 8 регистров.
Сразу отмечу, размер регистров — 2 у 3DNow! и 4 у SSE — довольно косвенно связан с быстродействием. Он, скорее, влияет на программирование под эти расширения. Рассмотрим это влияние. Двухэлементные регистры легче полностью использовать, чем четырёхэлементные. Нужно тратить меньше усилий на организацию данных. В 3DNow! есть полезная возможность складывать между собой два элемента одного регистра, чего нет в SSE. Видимо, это следствие меньшего размера регистров. В SSE нельзя легко сложить между собой все четыре элемента, что очень сильно затрудняет программирование. Зато если уж организовали данные нужным образом, то больший объём регистров SSE позволяет обойтись меньшим числом команд. Далее, больший объём позволяет хранить часто используемые операнды в регистрах SSE, что затруднительно при использовании 3DNow!
AMD выпустила специальную библиотеку для работы с векторами, в которой векторные и матричные операции реализованы inline функциями, написанными на 3DNow! Выше было рассказано об аналогичной библиотеке SML от Intel. Так вот, библиотека AMD гораздо лучше оптимизирована для работы с трёхмерными векторами и матрицами, и скалярное произведение векторов тоже существенно лучше реализовано. В библиотеке SML, по всей видимости, скалярное произведение векторов вообще реализовано с помощью FPU.
SSE2-развитие SSE в процессорах Pentium4. SSE2 использует те же регистры, что и SSE, но теперь они имеют тип double[2]. Набор команд, соответственно, аналогичен SSE. В SSE2 появились также команды для работы с целыми числами, регистры интерпретируются как имеющие тип int с различной разрядностью. Этакий Double MMX (регистры SSE2 имеют размер 128 бит, в два раза больше, чем 64 — размер регистров MMX).
SSE2 получился аналогичен 3DNow! только работает не с float, а с double.
Рассмотрим, наконец, 3DNowProfessional — продолжение 3DNow! в самых последних процессорах AMD — AthlonXP, AthlonMP. Самое важное, что в 3DNowPro включили SSE, так что теперь SSE поддерживают новейшие процессоры всех основных производителей. Вместе с введением поддержки SSE, AMD в который раз расширило 3DNow!, добавив туда команды, облегчающие работу с регистрами 3DNow! в случае их интерпретации как комплексных чисел. Действительно, двухэлементный регистр 3DNow!, естественно, представлять содержащим действительную и мнимую части комплексного числа. Комплексные числа используются в преобразованиях Фурье, а преобразования Фурье — в кодировании звука и изображения.
Теперь можно провести анализ ситуации с различными расширениями. Перефразируя известную фразу, скажу: "Если появляются SIMD-расширения, значит это зачем-то кому-то нужно".
3DNow! — само название говорит об одной из целей производителя: привлечь, строго говоря, обмануть, покупателя. Выигрыш от использования 3DNow! не больше полутора, максимум, SQRT(3) разов, что никак не тянет на "3DNow!". Это, кстати, почти всегда завышенная оценка. В реальности относительная выгода не так велика (на Athlon'ах с хорошим сопроцессором). К тому же, даже 3D программа далеко не вся может быть оптимизирована под 3DNow!, так что общая добавка производительности ещё меньше.
Хочется сделать ещё одно замечание: многие программы, показывающие фантастический прирост производительности при оптимизации под SIMD — это касается и 3DNow! и SSE — просто не были до этого хорошо оптимизированы. Их взялись оптимизировать и сразу под SIMD. Поделюсь своим личным опытом в этой области. Я решил переписать на ассемблер относительно небольшую часто вызываемую функцию. Мой ассемблерный код имел в полтора раза меньший размер, по сравнению со сгенерированным IntelC++Compiler4.5, но работал практически также. Переписал с использованием SSE. Правда, задействовались только первые два элемента регистров SSE, поскольку нужно было вычислять скалярные произведения двух, а не четырёх пар векторов. И этот вариант работал с прежней скоростью. Дело в том, что изначально код на C++ был хорошо написан, и компилятор его не испортил при компиляции.
Вспомним, что в те времена, когда появилась 3DNow!, процессоры AMD были хуже Intel'овских в операциях с плавающей точкой из-за плохого конвейера для сопроцессора, а скорость SIMD меньше зависит от качества реализации конвейера, так что 3DNow! была призвана исправить ситуацию в вычислениях с вещественными числами.
Рассмотрим SSE. С ним ситуация, как ни странно, вполне аналогична. Как известно, SSE имеет титул: The Internet Streaming SIMD Extension. В определённые дни на компьютерные рынки приходят маркетологи корпорации Intel и демонстрируют покупателям, как SSE помогает при работе с Internet.
Известно, что, в угоду возможности наращивания частоты, конвейер процессора Pentium4 сделан не оптимальным образом. И опять SIMD-расширение призвано выправить положение. Без использования SIMD, Pentium4 значительно проигрывает в некоторых тестах многим процессорам меньшей частоты, иногда даже PentiumIII. Есть все основания предполагать, что с увеличением частоты процессора Pentium4 разрыв между производительностью SIMD и неSIMD кода будет только увеличиваться.
Выводы
На основании проведённого анализа можно сделать более-менее достоверные выводы о перспективах использования SIMD. Так как SSE поддерживают и последние процессоры AMD, с оптимизацией под 3DNow! почти никто больше возиться не будет. Зачем это надо, если SSE есть и у PentiumIII и у CeleronII, не говоря уже про Pentium4. А 3DNow! актуально только для старых Athlon, которые скоро заменят новые AthlonXР. Зато оптимизация под SSE станет обязательной, поскольку иначе на Pentium 4 будет плохо работать. Какой-нибудь Pentium 4 3GHz будет работать, как PentiumIII 1.5GHz.
Конечно, этот прогноз верен в том случае, если Intel останется лидером продаж. Если же рынок неожиданно заполонят непонятно от куда взявшиеся какие-нибудь AthlonXP3000+, которые отлично работают безо всякого SSE, то лень разработчиков помешает выпуску оптимизированных под SSE программ, что окончательно погубит этот самый Pentium4. Однако, якобы AthlonXP3000+ неоткуда взяться, поскольку оптимальный конвейер не совместим с высокой частотой.
Введение поддержки SSE в последние процессоры AMD может говорить о том, что AMD тоже собирается пойти по стопам Intel в деле повышения частоты, и будущие процессоры AMD тоже будут плохо работать на программах без SIMD оптимизации.
Печалит, однако, тенденция перекладывания производителями процессоров своих проблем на разработчиков. Необходимость оптимизировать программу под процессор не есть хорошо. К тому же, компиляторы, которые бы эту проблему решали автоматически, без участия программиста, очень тяжело сделать. Главные достижения в этой области — автоматическая подставка SSE-оптимизированной процедуры умножения четырёх мерных матриц и векторная библиотека от AMD.
Нет бы сделать что-то действительно хорошее, ту же геометрию оптимизировать по-человечески. Например, увеличили бы стек сопроцессора, чтобы в него помещалось несколько матриц, и добавили бы несколько настоящих 3D команд, вроде таких:
- fLoadVector mem
- fLoadMatrix mem
- fStoreVector mem
- fStoreMatrix mem
- fMulVectorScalar r1,r2
- fMulVectorVector r1,r2
- fMulVectorMatrix r1,r2
- fMulMatrixScalar r1,r2
- fMulMatrixMatrix r1,r2
- fAddVectorVector r1,r2
- fAddMatrixMatrix r1,r2
- fDotProduct r1,r2
- fNormalizeVector r1,r2
- fInverseMatrix r1,r2
Тогда было бы не стыдно назвать расширение Super Enhanced 3D Extension.
Правда, объективно установить баланс между оптимизацией железа под софт и софта под железа невозможно.
Оптимизация трассировки лучей под SSE
Рассмотрим идеи оптимизации трассировки лучей под SIMD-расширения процессорных команд. Как правило, перед запуском цикла трассировки в ходе предварительной обработки сцены для каждого луча находится множество объектов, с которыми он может пересечься. Делается это путём, например, группировки лучей, отвечающих некоторым областям экрана, и нахождения всех объектов, которые могут пересекаться с каким-нибудь лучом группы. После этого связанную с лучом информацию можно скомпоновать, что бы её можно было легко загружать в регистры SSE и проверять пересечение параллельно с четырьмя объектами. Это хорошо получается, когда объекты однотипны: например, поверхности первого порядка, поверхности второго порядка. Тут есть элемент спекулятивного выполнения: вдруг не все четыре пересечения нужно будет считать, например, из-за того, что уже первое пересечение дало положительный результат. Однако, когда объектов много, это вполне оправдывается.
Аналогичная идея может применяться для оптимизации трассировки отражённого луча или лучей, направленных на источники света. Для каждого объекта формируется массив объектов, с которыми может пересечься отражённый луч. И, с помощью SSE, считается пересечение сразу с четырьмя объектами.
Интересно, что в случае увеличения размера SIMD-регистров до 8, 16, 32, 64, 128 и т.д. эта идея также проходит.
В состав SSE входят команды быстрого приближённого вычисления обратной величины и обратного квадратного корня. Для выполнения геометрических расчётов их использование проблематично из-за больших погрешностей. Их лучше использовать для вычисления таких величин, как освещённость, цвет, которые всё равно будут отображаться с округлением до 1/256.
Заключение
Пути развития неисповедимы. Трудно заранее определённо сказать о перспективах той или иной технологии. Несомненна некоторая научная ценность движка VirtualRay. Однако, найдётся ли ему практическое применение в какой-либо области, покажет время. Быть может, некоторые идеи, заложенные в движок, продолжат своё развитие и найдут своё воплощение в совершенно иной форме.


