
Семейство чипов PowerVR Series 2
Торговая марка PowerVR известна нам довольно давно. Достаточно вспомнить 3D карту m3D от Matrox, которая аналогично картам на чипсетах Voodoo/Voodoo2 от 3dfx играли роль только трехмерного акселератора. Разработкой и производством чипов серии PowerVR совместно занимаются компании VideoLogic и NEC. Причем VideoLogic в основном занимается разработками, а NEC производством. Компания VideoLogic основана в 1990 году в Великобритании. В настоящее время в VideoLogic работают 130 сотрудников. К первому поколению PowerVR относятся чипы PCX1 и PCX2. Для своего времени первое поколение PowerVR было вполне прогрессивным и довольно успешным. Достаточно вспомнить такие аппаратные возможности первого поколения PowerVR, как воспроизведение объемных теней и освещения. Те, кто интересуются технологиями, вспомнят и то, что чипы PowerVR не использовали традиционные методы отображения. Однако, кроме очевидных достоинств, у первого поколения PowerVR было и масса недостатков, например, отсутствие поддержки режимов аппаратного смешивания цветов, плюс к этому конкуренты не стояли на месте, постоянно улучшая и расширяя возможности своих ускорителей. В результате, VideoLogic/NEC объявили о начале разработок нового поколения PowerVR (PowerVR Series 2 или PowerVRS2). На разработку ушло почти два года, и в ноябре 1998 года начались продажи игровых приставок Sega Dreamcast, использующих чип PowerVR 2DC. Позвольте, а причем здесь игровые приставки? 
Все просто. Дело в том, что компании NEC и VideoLogic уверены в том, что кросс-платформенная стратегия при создании графических акселераторов позволит снизить общие затраты на разработку и производство за счет больших объемов продаж. Более того, благодаря кросс-платформенности разработчики могут создавать приложения, которые могут применяться в трех различных секторах рынка.
В результате, семейство PowerVR включает в себя чипы, рассчитанные на разные сегменты игрового рынка. Это чип PowerVR 2DC для использования в игровых приставках Sega Dreamcast и игровых автоматах Naomi, графический акселератор R-Cade Vision 250 для игровых автоматов типа ArcadePC и чип PowerVR 250 для использования в 2D/3D акселераторах для PC, например Neon 250 от VideoLogic.
Более того, за первые четыре месяца продаж приставок Sega Dreamcast, их было продано в Японии более одного миллиона штук. Коммерческий успех налицо.
К слову, Naomi и Dreamcast почти одинаковы в том смысле, что оба продукта оснащены центральным RISC процессором Hitachi SH-4 200 MHz, одинаковым графическим процессором PowerVR 2DC 100 MHz и одинаковой 64 канальной звуковой системой, построенной на основе процессора ARM7 от Yamaha — AICA 45 MHz. Главное отличие состоит в объеме основной памяти, объеме графической памяти, объеме звуковой памяти и в оснащении накопителями данных. Naomi оснащена разъемами для ROM памяти с записанными играми, а Dreamcast оснащается устройством GD-ROM (1.2 Gb CD-ROM). 
Тема игровых приставок безусловна интересна, но нам гораздо интереснее ситуация с чипом PowerVR 250, который рассчитан на рынок графических ускорителей для PC. Пока известно только об одном акселераторе, использующем чип PowerVR 250, это ускоритель Neon 250 от VideoLogic. При этом массовые продажи Neon 250 пока не начались. Но к этому вопросу мы вернемся позднее.
Для начала посмотрим на характеристики нового ускорителя, большая часть которых относятся непосредственно к чипу PowerVR 250, входящего в семейство PowerVRS2.
Чип PowerVR 250

- 0,25 мкм технологический процесс
- По неподтвержденным данным, чип содержит около 10 млн. транзисторов
- 16 MB локальной видео памяти типа SDRAM (чип поддерживает до 32 Мб памяти типа SDRAM/SGRAM)
- 64-разрядный интерфейс шины памяти
- 250 MHz RAMDAC (предусмотрена возможность установки более быстрого RAMDAC)
- Максимальное разрешение 1920 x 1440 @ 65Hz
- Предпочтительное разрешение 1600x1200 @ 85 Hz (в этом разрешение будет обеспечиваться приемлемый уровень fps)
- Чип и память работают на частоте 125MHz
- Поддерживается интерфейс PCI и AGP mode x2 с SBA и DME
- Имеется возможность масштабирования за счет увеличение числа элементов обработки графики. Т.е. не нужно ставить второй чип, достаточно реализовать в виде отдельных чипов ключевые элементы tile-ускорителя и производительность увеличится.
2D часть
- Полная поддержка операций ROP, ускорение обработки текстовых и линейных примитивов
- Полная совместимость с VGA
- Преобразование цветовых пространств YUV в RGB
- Частичная поддержка на аппаратном уровне декодирования MPEG2 потоков (motion compensation, компенсация движения)
- Перекрытие цветов по ключам (Color key overlay)
- Поддержка одновременного отображения в нескольких окнах
3D часть
- В основе механизма рендеринга лежит tile архитектура, существенно снижающая требования к ширине полосы пропускания памяти
- Благодаря применению tile архитектуры, достигается сравнимая производительность с современными ускорителями, использующими классическую схему механизма рендеринга. Например, несмотря на использование 64-разрядной шины памяти и одного конвейера, производительность находится на уровне акселераторов с двумя конвейерами и 128-разрядным интерфейсом памяти.
- Все операции внутри конвейера рендеринга происходят с 32-битной точностью
- Воспроизведение при 24 битной глубине цвета плюс 8 бит для alpha канала, всего 32 бита
- Для повышения производительности, все операции внутри конвейера могут осуществляться с 24-битной точностью, а при воспроизведении на экране за счет растрирования будет использоваться 16-битная глубина цвета.
- При многопроходных операциях рендеринга, все вычисления происходят с 32-битной точностью. В случае необходимости растрирование до 16 битного цвета происходит после завершения рендеринга.
- Все операции, связанные с вычислением глубины сцены (в традиционных ускорителях это z-буферизация) выполняются с 32 битной вещественной точностью и без ущерба производительности.
- Удаление скрытых поверхность осуществляется на уровне пикселей
- Как такового Z-буфера нет, все операции происходят внутри чипа, соответственно необходимые объемы локальной памяти существенно ниже, чем в случае с традиционными акселераторами. Размер Z-буфера внутри чипа равен 512 Кб.
- Полноценный механизм расположения полигонов в пространстве (triangle setup engine) обрабатывает до 5 млн. видимых полигонов в секунду, с использованием вещественных чисел. В зависимости от мощности CPU это значение может меняться. Так, при PII333 обрабатывается около 1,2 млн. видимых полигонов, при PIII500, около 5 млн. видимых полигонов.
- Скорость заполнения полигонов (fillrate) равна 125 млн. пикселей в секунду, при этом эта величина является эффективным значением fillrate. Сравнимая величина fillrate соответствует значениям от 200 до 500 млн. пикселей в секунду в зависимости от сложности сцены
- Высокая эффективность при отображении сложных сцен
- Поддержка захвата управлением шины при загрузке данных из системной памяти
- Затенение Гуро (Gouraud shading) ARGB с коррекцией перспективы
- Полноценный механизм текстурирования (texture setup), т.е. всеми операциями над текстурами выполняются внутри чипа, тем самым, разгружая CPU
- Поддерживаются билинейная, трилинейная (за 2 прохода) и анизотропная (за 4 прохода) фильтрации с коррекцией перспективы
- Текстуры со скорректированной перспективой не искривляются, потому что PowerVR осуществляет разделение на уровне пикселей.
- Поддерживается dot product bump-mapping (скалярное рельефное текстурирование) в реальном времени
- Однопроходное мультитекстурирование за счет применение техники отсрочки текстурирования, т.е. текстурируются только видимые полигоны или пиксели
- Текстурирование с использованием карт окружающей среды (включая отражения)
- Поддерживается компрессия текстур VQ (vector quantization) со степенью сжатия до 10:1
- Возможно, будет реализована поддержка S3TC
- Поддерживаемые форматы текстур: с использованием палитры 8 бит на пиксель, 1555, 565, 4444, 8888, YUV 4:2:2
- Сглаживание всей сцены (full scene antialiasing) с использованием supersampling и без ущерба производительности, т.е. формируется изображение вдвое больше, чем требуется (или с произвольно выбранным коэффициентом масштабирования), а затем за счет уменьшения с масштабированием происходит вывод изображения на экран.
- Объемные эффекты: свет, тени, преломленный свет и т.д.
- Однородность затененных полигонов не изменяется при вращении
- Реальные тени могут отбрасываться любым объектом на любую поверхность и обновляться в каждом кадре
- Сортировка на основе данных о полупрозрачности (Translucency sorting)
- Эффект полупрозрачности и прозрачности может быть применен ко всему объекту, полигонам или для каждого пикселя в отдельности для получения таких эффектов, как грязное стекло, огонь, вода и даже для моделирования преломленного света и radiosity. Radiosity это графическая технология создания естественного освещения (включая непрямое освящение) на основе физической модели распространения света внутри сложной архитектурной среды. Эта техника позволяет точно вычислять пути распространения света и осуществлять полноцветную визуализацию сцены.
- Загружаемый табличный цветной туман для каждого пикселя и для вершин полигонов
- Отраженный свет со смещением цветов
- Поддерживается многопроходное смешивание с использованием Alpha канала и по цветовым ключам
- Поддерживаются режимы смешивания D3D и OpenGL
Поддерживаемые ОС и API:
- Соответствует спецификациям архитектуры Talisman
- Windows 95, Windows 98, Windows NT 4.0 и Windows 2000
- Microsoft DirectX 6.х
- OpenGL (ICD)
- PowerSGL Direct
- В драйверах обещана реализация поддержки инструкций 3DNow! и SSE.
Соответствие требованиям PC 99
- PCI Power Management
- VMI
- DDC2B
- VBE 3.0 BIOS
Теперь поговорим подробнее об особенностях архитектуры PowerVR 250.
Ограничения при создании реалистичного изображения

Некоторые мощные и важные специальные эффекты требуют использования совершенно других методов при построении изображения, нежели традиционная архитектура 3D графики, с тем, чтобы затраты системных ресурсов были минимальны, а общая стоимость решения была приемлемой. Примером подобных возможностей может служить способность динамически изменять отображаемый на экране объект в зависимости от его взаимодействия с другими объектами сцены, например, машина при движении попадает в тень от дерева. Подобные возможности не могут быть эффективно реализованы при использовании традиционных методов, базирующихся на полигонной технологии. Для решения подобных задач необходимы механизмы, которые могут правильно и эффективно моделировать реальный мир.
Традиционные методы отображения 3D графики не могут обеспечить одновременно высокую производительность при низкой стоимости реализации. Технология PowerVR минимизирует требования к объему локальной видеопамяти и к ширине полосы пропускания внутренней шины данных. В случае с традиционной архитектурой, необходимо наличие текстурной памяти и кадрового буфера, хранящие данные реального изображения и z-буфер, хранящий информацию о глубине сцены для каждого кадра.
Для снижения необходимых объемов локальной памяти в технологии PowerVR отсутствует потребность в Z-буфере как таковом. Для обеспечения максимальной производительности, процесс удаления скрытых поверхностей реализован на аппаратном уровне. В результате существенно снижаются необходимые объемы локальной памяти, и снимается проблема с пропускной способностью и скоростью доступа к локальной памяти. Более того, так как процесс удаления скрытых поверхностей полностью реализован внутри чипа, все вычисления производятся на тактовой частоте устройства, а значит с ростом тактовой частоты чипа, производительность будет также возрастать. Эта архитектура впервые была реализована еще в первом поколении PowerVR чипов (PCX1 и PCX2). В архитектуру чипов второго поколения PowerVR были внесены существенные улучшения.
PowerVR также в значительной степени снижает требования к ширине полосы пропускания памяти, используемой для хранения текстур и в качестве кадрового буфера. Пропускная способность текстурной памяти минимизируется благодаря использованию метода отсроченного текстурирования (deferred texturing). В отличие от традиционных систем рендеринга, где текстурируется каждый полигон и потенциально любой полигон может вновь перезаписываться, в архитектуре PowerVR происходит наложение текстуры только на те пиксели (полигоны или часть полигонов), которые будут действительно видимыми на экране.
Эта отсрочка возможна благодаря применению специальной техники удаления скрытых поверхностей (hidden surface removal, HSR), в результате применения которой на выходе получаются группы пикселей (tiles) с полностью определенными параметрами глубины и это только те пиксели, которые будут видны на экране. Во время рендеринга каждого кадра, каждый пиксель на экране текстурируется только один раз и каждый пиксель, предназначенный для вывода на экран, записывается в кадровый буфер только один раз. В итоге, только видимые полигоны текстурируются и фильтруются. Напротив, в традиционных системах рендеринга, каждый пиксель из каждого отображаемого полигона потенциально должен быть записан в кадровый буфер. В этом заключается главная разница между графическими процессорами PowerVR и традиционными полигонными. Чипы второго поколения PowerVR обрабатывают матрицы 32х16 пикселей (или tile) за один такт.
Ключевыми компонентами графических ускорителей второго поколения PowerVR являются: "Tile accelerator" (тайл акселератор), "Image Synthesis Processor" (ISP, процессор синтезирующий изображение) и "Texturing and Shading Processor" (TSP, процессор текстурирования и затенения). Рассмотрим каждый из этих компонентов в отдельности.
Tile accelerator
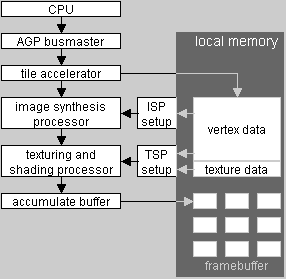
Центральный процессор системы (CPU) передает данные о вершинах полигонов в буфер сцены (scene buffer), располагаемые в системной памяти.
"Tile accelerator" переносит данные о вершинах полигонов (vertex data) в локальную видеопамять через 64 разрядную шину памяти. Передаются данные о вершинах полигонов, покрывающих один tile, что эквивалентно области экрана размером 32х16 пикселей (всего 512 пикселей). Вычисление границ этого прямоугольника осуществляются во время получения данных. В результате создается лист отображения (display list), который содержит адрес каждого полигона в локальной памяти. При тактовой частоте в 125 МГц "Tile accelerator" может обрабатывать 20.9 миллионов треугольников в секунду, с ростом тактовой частоты, пиковая производительность будет увеличиваться.
Image Synthesis Processor
Используя лист или список отображения, "Image Synthesis Processor" (или просто ISP) считывает полигоны для каждого tile. Он идентифицирует самый верхний полигон для каждого пикселя и отбрасывает за ненадобностью полигоны, которые скрыты от зрителя (т.е. происходит удаление скрытых поверхностей, HSR). Имея 32 элемента обработки (processing elements или PE) и реализованный в чипе Z-буфер ISP способен обрабатывать одновременно 32 пикселя с использованием алгоритма Z-буферизации с 32-разрядной точностью. При тактовой частоте 125 МГц ISP может обрабатывать 8.4 млн. треугольников в секунду. Если имеются полупрозрачные полигоны, процесс удаления скрытых поверхностей (HSR) происходит за два прохода: сначала обрабатываются полупрозрачные полигоны, затем непрозрачные полигоны. Полупрозрачные полигоны должны быть отсортированы в зависимости от параметра глубины до начала процесса HSR. Приложение может осуществлять предварительную сортировку полупрозрачных уровней или в самом чипе может быть реализована сортировка по полупрозрачности на уровне пикселей. Сортировка на уровне пикселей используется, если невозможна сортировка на уровне полигонов, например, в случае пересекающихся полигонов. В результате своей работы ISP передает на выходе в "Texturing and Shading Processor" (процессор текстурирования и затенения, TSP) только видимые, непересекающиеся полигоны покрывающие tile (тайл).
Texturing and Shading Processor
Процессор текстурирования и затенения или просто TSP, как следует из названия, осуществляет операции стандартного текстурирования и затенения используя в качестве данных координаты текстур и итераторы RGB видимых полигонов. Так как обрабатываются только видимые полигоны, величина используемой полосы пропускания для текстурирования соответствует лишь части ширины полосы пропускания необходимой в случае применения традиционных полигонных графических процессоров, если коэффициент сложности глубины сцены больше чем единица. По тем же причинам, число полигонов, которые должны быть отображены в каждой сцене, соответствует лишь части того количества полигонов, которые должны быть отображены традиционными акселераторами. Следствием всего этого является то, что значение fillrate чипа PowerVR 250, которое необходимо для достижения эквивалентных величин скорости смены кадров в одно-текстурных играх с коэффициентом сложности глубины сцены большем, чем единица соответствует лишь части от величины fillrate традиционных графических ускорителей. В виду того, что текущая реализация TSP имеет только один конвейер текстурирования/рендеринга, при мультитекстурировании используется один такт для каждого текстурного слоя. Для трилинейной фильтрации требуется два такта. По сравнению с трилинейной фильтрацией, анизотропная фильтрация обеспечивает большую гибкость при выборе эталонных текселей, всего 16 штук. Т.е., в то время как конкуренты используют 8 эталонных текселей для анизотропной фильтрации, в PowerVR 250 задействуются 16 текселей. Но анизотропная фильтрация обходится дороже — для ее реализации необходимо четыре такта. Первичный и вторичный 32 разрядные буферы накопления (accumulation buffers) обеспечивают реализацию на аппаратном уровне смешивания нескольких текстур и скалярное рельефное текстурирование. После того, как все тайлы (tiles) для всей сцены отображены и собраны вместе, весь кадр выводится на экран.

Чип PowerVR 250 имеет многофункциональную, основанную на тайловой архитектуре систему кэширования, которая позволяет использовать встроенную в чип память для различных задач: хранения различных параметров, значений глубины сцены, пикселей, текстур, результатов вычислений и т.д. Производительность традиционных полигонных систем сильно зависит от размера текстурного кэша и ширины полосы пропускания локальной памяти. В случае с PowerVR 250 это не так. Благодаря такой системе кэширования, PowerVR 250 имеет эффективную поддержку мультитекстурирования. При этом все операции над различными слоями текстур при их наложении на полигоны происходят внутри чипа и до того, как конечный результат будет записан в кадровый буфер.
Стоит отметить и возможность смешивания различных техник фильтрации, например, билинейной и анизотропной, для обеспечения высокого качества изображения при высокой скорости воспроизведения.
К слову, чип PowerVR 250 не имеет архитектурных ограничений для поддержки затенения Фонга (Phong shading). Сегодня этот тип затенения не поддерживается из-за высокой стоимости реализации и больших вычислительных затрат, однако в будущем такая поддержка может быть реализована, особенно, если будет использоваться геометрический сопроцессор.
Fillrate
Формально, значение fillrate чипа PowerVR 250 соответствует величине 125 млн. пикселей в секунду. Так как обрабатываются только видимые полигоны, число полигонов, которые должны быть отображены для каждой сцены, соответствует лишь части того количества полигонов, которые должны быть воспроизведены традиционными акселераторами. Благодаря реализованному внутри чипа процессу удаления скрытых поверхностей (HSR) коэффициент сложности глубины сцены для PowerVR 250 всегда соответствует единице, независимо от числа объектов в сцене. В результате значение fillrate чипа PowerVR 250, которое необходимо для достижения эквивалентных показателей скорости смены кадров в одно-текстурных играх с коэффициентом сложности глубины сцены большем, чем единица соответствует лишь части от величины fillrate традиционных графических ускорителей. В двух-текстурных играх с коэффициентом сложности глубины сцены равным двойке, величина fillrate, необходимая для достижения такой же скорости смены кадров, точно такая же, как при использовании традиционных чипов, накладывающих за один проход две текстуры на один пиксель, при эквивалентных тактовых частотах.

Тут стоит отметить одну важную деталь. Обычно, под величиной fillrate подразумевается скорость текстурирования и наложения освещения вообще всех полигонов, даже тех, которых мы не видим на экране. Поэтому, в случае с PowerVR 250 речь идет об эффективной величине fillrate, т.к. воспроизводятся только видимые полигоны. В результате достигается и более высокая сравнительная производительность. Именно поэтому в спецификации указаны и цифры сравнительной величины fillrate. Благодаря тому, что PowerVR 250 откладывает процесс текстурирования до того момента, пока не будут удалены все скрытые поверхности, коэффициент сложности глубины сцены не оказывает влияния на величину fillrate. В результате, в более сложных сценах у традиционных акселераторов величина fillrate снижается, а у PowerVR 250 нет.
Величина fillrate вычисляется по формуле: "разрешение x коэффициент сложности глубины сцены x частоту смены кадров". Например, если сложность глубины сцены равна 3, и мы воспроизводим сцену с частотой смены кадров 60 fps, то получим следующие величины fillrate для разных разрешений:
| Разрешение | PowerVR 250 | Другие ускорители |
|---|---|---|
| 640x480 | 18.4 | 55.3 |
| 800x600 | 28.8 | 86.4 |
| 1024x768 | 47.2 | 141.6 |
| 1280x1024 | 78.6 | 235.9 |
Из этой таблицы наглядно видно, что подразумевается под эффективным значением fillrate. Однако в нашем примере мы не учитывали другие факторы, которые могут влиять на величину fillrate, это мультитекстурирование и прозрачность. Реализация прозрачности не является серьезным препятствием, т.к. в чипе PowerVR 250 есть аппаратная поддержка сортировки по параметру полупрозрачности. Кроме этого, традиционные графические акселераторы используют дополнительные такты для очистки Z-буфера и кадрового буфера. А в чипе PowerVR 250 происходит глобальный сброс состояния Z-буфера и буферов накопления. В результате, когда конвейер традиционного полигонного акселератора останавливается, чтобы произошла очистка Z-буфера, конвейер PowerVR 250 продолжает работать, работать и работать (как батарейка Energizer :-)) и за каждый такт воспроизводит новый пиксель. Поэтому в реальных приложениях величина эффективного fillrate чипа PowerVR 250 будет близка к значению, заявленному в спецификации.
Dot product bump mapping
Скалярное рельефное текстурирование (dot product bump mapping или еще называемое perturbed normal bump mapping) реализовано на аппаратном уровне и требует двух тактов на выполнение: один такт на получение базовой текстуры, а второй для текстуры карты рельефа (или карты высот). Чип PowerVR 250 вычисляет скаляр на основе световых данных (цвете, направленности и интенсивности). Значение скаляра используются для затенения рельефной текстуры. Во время второго прохода затененная базовая текстура модулируется с рельефной картой. Этот метод хорошо применим в случае динамических источников света; все, что требуется, это новое направление света и цвет. За счет реализации такого метода рельефного текстурирования на аппаратном уровне не происходит дополнительной загрузки CPU, а значение fillrate практически не снижается.
В случае нескольких независимых источников света, все они комбинируются в виде одного входного параметра или для каждого источника света определяется отдельный уровень рельефной карты. Последний вариант может быть чрезвычайно дорогим при реализации, а значение fillrate может существенно снизиться.
Пропускная способность памяти и организация потоков данных
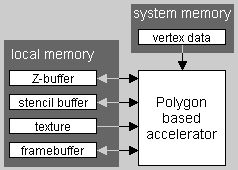
На иллюстрации справа, можно увидеть какие потоки данных, в каком количестве и в каких направлениях организованы между чипом полигонного (традиционного) акселератора и локальной видеопамятью. Доступ к Z-буферу является двунаправленным, т.к. Z-буфер должен обновляться и проверяться. Поток текстурных данных обычно однонаправленный, т.к. текстуры только выбираются из памяти. Доступ к кадровому буферу двунаправленный, т.к. в случае реализации полупрозрачности происходит обращение к кадровому буферу для восстановления исходного пикселя.
Из-за большого количества пересекающихся потоков данных и их нерегулярной сущности могут возникать конфликты. 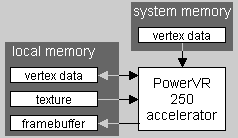
Теперь рассмотрим структуру организации потоков данных в случае с чипом PowerVR 250. В то время как чипу PowerVR 250 не нужен внешний поток данных для связи с Z-буфером, дополнительно (по сравнению с традиционными чипами) необходимо использовать двунаправленный поток данных для доступа к информации о вершинах полигонов (vertex data).
На иллюстрации не изображен буфер шаблонов (stencil buffer, стенсель буфер), так как он не упоминается среди набора возможностей PowerVR 250, но он может быть реализован на аппаратном уровне внутри чипа. Доступ к кадровому буферу является однонаправленным и с фиксированной шириной полосы пропускания. При реализации полупрозрачности используются накопительные буферы внутри чипа для применения соответствующих эффектов.
Так как доступ к локальной памяти является предсказуемым и регулярным, конфликты потоков данных возникают существенно реже, а процессы кэширования выполняются более эффективно. Несмотря на присутствие дополнительного потока для передачи данных о вершинах полигонов, общая ширина полосы пропускания памяти меньше, чем в случае с традиционными чипами даже при нулевом значении ширины полосы пропускания Z-буфера. При этом значение ширины полосы пропускания, используемой для передачи текстурных данных и записи в кадровый буфер, составляет лишь часть от ширины полосы пропускания, используемой для тех же целей в традиционных графических чипах. Исходя из всего выше сказанного, можно сделать вывод о том, что использование 64-разрядного интерфейса памяти, вместо являющегося сегодня стандартным 128-битного интерфейса памяти в традиционных графических чипах, не является слабым местом чипа PowerVR 250.
Full scene antialiasing
Использование сглаживания всей сцены (Full scene antialiasing, FSAA) это шаг вперед по сравнению с обычным краевым сглаживанием (edge antialiasing). Краевое сглаживание размазывает лестничный эффект на краях полигонов, однако не может избавить от муара изображения. FSAA обеспечивает высокое качество изображения за счет устранения лестничного эффекта и муара. Такой результат достигается за счет рендеринга изображения с высоким разрешением, а затем масштабное уменьшение разрешения изображения до более низких значений (supersampling или суперсемплинг) с применением фильтров сглаживания. Суперсемплинг изображения осуществляется за счет суперсемплинга всей сцены внутри чипа, масштабного уменьшения разрешения (downsampling), фильтрации, а уже затем записи результата в кадровый буфер. Суперсемплинг используется приложениями напрямую через DirectX, а также через PowerSGL Direct. В драйверы для карт на PowerVR 250 будет встроен апплет, который позволит включать и выключать поддержку суперсемплинга для любого приложения. Коэффициент суперсемплинга может выбираться гибко, исходя из потребностей разработчика приложения. Дело в том, что использование суперсемплинга, например, x2 может сказаться на общей производительности чипа. В этом случае для воспроизведения изображения в разрешении 800х600 и при использовании суперсемплинга x2, внутри чипа формируется изображение с разрешением 1600х1200. Хотя на величину fillrate суперсемплинг x2 не оказывает влияния, но внутри чипа обрабатывается в 4 раза больше пикселей, поэтому общая производительность снижается, т.е. показатель fps будет ниже. При этом для FSAA не требуется дополнительных вычислительных затрат CPU, в отличие от краевого сглаживания. Тем не менее, для суперсемплинга могут использоваться любые значения, выбираемые по осям x и y. В итоге, если разработчик считает, что суперсемплинг х2 для данной сцены это слишком медленно, он может выбрать, например параметр 1.8х1.2.

FSAA является естественным расширением тайловой архитектуры Ширина полосы пропускания, необходимая для передачи данных о вершинах полигонов и текстур эквивалентна сцене с высоким разрешением. Ширина полосы пропускания необходимая для записи данных в кадровый буфер эквивалентна сцене с масштабно уменьшенным разрешением. При отображении в разрешении 800х600 и суперсемплинге х2, внутреннее разрешение будет 1600х1200, и величина fillrate будет соответствовать этому разрешению. Сцена с высоким разрешением хранится в tile-буфере внутри чипа размером 512 Кб. Сцена с уменьшенным разрешением передается в кадровый буфер, т.е. объемы памяти и ширина полосу пропускания для кадрового буфера точно такие же, как если бы происходит рендеринг сразу сцены с низким разрешением. Другими словами никаких дополнительных накладных расходов не требуется. Напротив, в традиционных акселераторах для реализации подобной операции потребуются большие объемы быстрой локальной памяти для кадрового буфера и для Z-буфера. Не смотря на то, что полигонные акселераторы имеют в списке поддерживаемых функций FSAA, на самом деле эта возможность не всегда может использоваться на практике из-за того, что значения необходимой ширины полосы пропускания и fillrate невероятно возрастают, т.е. традиционному акселератору может просто не хватить ресурсов и мощности.
Поговорим о поддерживаемых интерфейсах
PowerVR 250 позиционируется в качестве нейтрального чипа, по отношению к интерфейсам (API). Т.е. собственный специализированный интерфейс PowerVR SGL Direct поддерживается исключительно для удобства разработчиков, обеспечивая поддержку всех возможностей чипов серии PowerVRS2, ориентированных, прежде всего на рынок игровых приставок и автоматов. В результате, PowerVR 250 полностью поддерживает интерфейсы Direct3D и OpenGL, т.е. отвечает всем современным требованиям.
Стоит отметить, что чипы серии PowerVRS2 ориентированы именно на игровое применение, т.е., например, для систем CAD чип не рассчитан.
Поговорим о самой карте
В марте на CeBIT была продемонстрирована карта VideoLogic Neon 250 построенная на чипе PowerVR 250. Карта была снабжена бета драйверами, но, несмотря на это, продемонстрировала высокое качество изображения и производительность на уровне конкурентов.

Карта была установлена в компьютер следующей конфигурации: Pentium III 500 MHz, 128 MB PC100 SDRAM и были зафиксированы следующие результаты:
Синтетический тест:
| 3D Mark99 (800х600@16) — 4202 |
В реальном приложении были получены следующие цифры:
| Quake II Timedemo 1 | |
|---|---|
| 1024x768x16: | 61.8 fps |
| 800x600x16: | 95.5 fps |
| Quake II Crusher | |
| 1024x768x16: | 49.7 fps |
| 800x600x16: | 55.0 fps |
Напомним, что использовались бета драйверы. Можно констатировать, что показатели получились вполне конкурентоспособные.
Сейчас практически стандартной является опция TV-Out, более того пользователи хотят иметь возможность использовать свой телевизор вместо монитора. В чипе PowerVR 250 предусмотрена поддержка такой возможности. Пока для карты Neon 250 это не реализовано, но если спрос будет достаточным, эта опция будет предложена всем желающим.
VideoLogic больше не планирует совмещать на одной карте графику, видео и звук, на подобие 5DSonic, так что гибридов мы таких больше не увидим. Кстати, в качестве аргумента, почему VideoLogic больше не хочет делать такие карты, было заявлено, что пользователи хотят иметь возможность для гибкой модернизации.
Представители VideoLogic заявили, что при воспроизведении изображения с 32-битной глубиной представления цвета разница в скорости по сравнению с 16-битным воспроизведением будет минимальна. Однако никаких цифр пока не приводится. Остается ждать реальных плат, если они вообще когда-нибудь появятся.
Самое интересное, что есть неподтвержденная информация о том, что PowerVR 250 будет поддерживать технологию сжатия текстур S3TC, которая встроена в DX6. По крайней мере, это выглядит логично. Зачем продвигать собственную технологию сжатия VQ, когда есть хорошо продвигаемый стандарт S3TC, поддерживаемый Microsoft, S3 и Matrox?
Что касается стоимости карт на PowerVR 250, то называются цифры в районе $100 за карту Neon 250 c 16 Мб локальной памяти. По словам представителей VideoLogic чипы PowerVR 250 будут обходится менее чем в $30 при партии в 10000 штук. Можно только констатировать, что цена вполне конкурентоспособная.
Подведем итоги
В чипе PowerVR 250 реализован рендеринг на основе списков отображения, т.н. tile архитектура, которая обеспечивает удаление скрытых поверхностей внутри чипа. Благодаря такой организации отсутствует необходимость во внешнем Z-буфере. В результате реализуется обработка текстур с отсрочкой, вследствие чего текстурируются и фильтруются только видимые полигоны. Это главные отличия от традиционных, т.н. полигонных, графических архитектур.
Кроме того, все операции внутри конвейера чипа чип PowerVR 250 происходят с 32-битной точностью, включая вычисления параметров Z-буфера, и на аппаратном уровне поддерживаются такие функции, как скалярное рельефное текстурирование (dot product bump mapping), анизотропная фильтрация, объемные эффекты, суперсемплинг всей сцены и т.д.

Все эти параметры отвечают требованиям, предъявляемым к современным 3D графическим акселераторам.
Несмотря на один конвейер, производительность PowerVR 250 вполне конкурирует с двухконвейерными акселераторами, особенна в играх с коэффициентом сложности глубины сцены равным или большим двойке. Из-за того, что для очистки Z-буфера используется меньше тактов, достигается большая эффективность fillrate.
Благодаря низким требованиям к ширине полосы пропускания шины памяти, чип PowerVR 250 оснащен 64 разрядной шиной памяти, в то время как в традиционных акселераторах приходится использовать 128 разрядную шину памяти. Однако, в планах NEC/VideoLogic предусмотрены улучшения в интерфейсе и типе используемой локальной памяти. Скорее всего, следует ожидать перехода на использование памяти типа Rambus DRAM или Virtual Channel Memory DRAM. Эти типы памяти позволят существенно снизить общие временные задержки при работе с памятью и увеличить ее пропускную способность, при этом нет никакой необходимости увеличивать разрядность шины памяти. Напомним, что NEC является ведущим разработчиком памяти типа VC DRAM.
Теперь добавим ложку дегтя.
Главная проблема — это производство самих чипов PowerVR 250, с которым NEC не справляется. VideoLogic свою часть работы выполнила: дизайн чипа полностью завершен, драйвера есть, заготовки для карт есть, нет только самих чипов. Причем, проблемы с производством у NEC начались еще год назад, в последний раз срок начала массового производства было назначен на май 1999, и нам обещали, что уже в июне мы увидим первые карты Neon 250 на чипе PowerVR 250.
Но, 21 апреля NEC заявила, что проблемы не решены и начало массового производства перенесено на сентябрь 1999. Да, эти парни сами хоронят свой продукт. Правда, уже на следующий день представители NEC заявили, что их неправильно поняли, и что на самом деле все идет по плану, и в июне все желающие смогут купить карты Neon 250. Кредит доверия к NEC в смысле производства чипов PowerVR 250 давно исчерпан, поэтому единственным доказательством могут служить реальные продажи карт, а не очередные пресс-релизы.
Если бы карты на чипе PowerVR 250 появились в прошлом году, как это и обещалось изначально, расстановка сил на рынке 3D графики могла бы быть сегодня несколько иной. Если бы карты на PowerVR 250 появились на рынке до этого лета, то шансы на успех все равно были бы высоки. Дело в том, что в марте на CeBIT была продемонстрирована работоспособность карты Neon 250 в современных играх. На практике было продемонстрировано великолепное качество изображения и высокая производительность. Однако перенос массового производства и продаж на осень это почти смертельный удар. Хотя, если карты начнут продаваться летом, то свой кусок рынка они получат. Другой вопрос, какой размер будет у этого куска. Даже, несмотря на всю свою уникальность, чип PowerVR 250 может просто устареть. Для плат Neon 250 может просто не остаться места на рынке, их некому будет покупать.
Самое обидное, что в данном случае проблема именно в производстве, а не в дизайне чипа. Например, в случае с Pwermedia3 от 3Dlabs наблюдается обратная ситуация.
В свое время, в 1995 году, VideoLogic отказалась от сотрудничества с ST Microelectronics (тогда SGS Thomson) в пользу партнерства с NEC. Недавно, VideoLogic подписала с ST Microelectronics новое соглашение, по которому, впрочем, ST Microelectronics будет партнером VideoLogic в производстве чипов третьего поколения PowerVR Series 3. К слову, официальный анонс PowerVR Series 3 намечен на вторую половину 1999 года.
В этой связи можно предположить следующий сценарий развития событий. К осени, если у NEC не произойдет внезапных улучшений с производством (чему есть примеры в истории, например у Intel), VideoLogic откажется от производства карт на PowerVR 250, а сразу начнет продажи карт на чипе третьего поколения. Причем создать новый чип довольно просто, учитывая масштабируемость архитектуры PowerVR и особенности дизайна. Достаточно увеличить тактовую частоту ядра, например до 150 MHz, увеличить объем локальной видео памяти до 32 Мб, с возможностью расширения до 64 Мб, добавить поддержку AGP x4 и буфера шаблонов. Увеличить число процессорных элементов (что позволит обрабатывать одновременно большее количество пикселей) или просто поставить два чипа PowerVR 250 и производительность возрастет линейно. При этом нет необходимости менять интерфейс памяти, да и саму память. В результате получится современный графический акселератор с великолепным качеством изображения и высочайшей производительностью.
Более того, инженеры VideoLogic давно ведут разработки геометрического сопроцессора, чтобы переложить все вычисления координат вершин полигонов, освещенности и трансформаций с CPU на геометрический сопроцессор. Если эти работы удастся завершить к осени, то новый чип PowerVR может опередить появление NV10 от nVidia и обеспечить тандему ST Microelectronics/VideoLogic лидерство на рынке. Но это всего лишь наши предположения, пока что нам остается лишь надеяться, что полоса неудач для уникальной технологии PowerVR закончится и мы сможем попробовать платы на чипе PowerVR 250 в деле…


