Hierarchical Polygon Tiling with Coverage Masks
Уважаемый читатель! Для удобства изложения и восприятия, в исходный текст статьи добавлены материалы, которые помогут вам уяснить суть вопроса, или получить дополнительные знания по тематике упоминаемой в статье, но не раскрытой подробно. Такие материалы будут выделены курсивом и снабжены специальными значками:
|
О статье
В данной статье представлен алгоритм рендеризации изображения, основанный на разбиении участков изображения, содержащих проекции полигонов, на тайлы. В описываемом алгоритме глубина рекурсивного деления отображаемого пространства определяется охватывающими масками, которые классифицируют выпуклые полигоны в иерархии изображения как внутренние, внешние и пересекающие по отношению к конкретному тайлу (ячейке изображения). Такой подход позволяет реализовать деление по методу Варнока (Warnock), а само деление будет эффективно управляться операциями с битовыми масками.
Полученный таким образом алгоритм иерархического деления полигонов на тайлы (далее "Иерархический тайлинг") позволяет стремительно производить разбиение и просчет видимости отображаемого пространства, посещая при этом только те участки изображения, которые содержат видимые края поверхностей. Участки изображения, в которых видимость определена, больше не обрабатываются алгоритмом, и информация о них остается неизменной вплоть до окончательного формирования кадра. Тайлинг и формирование изображения с разрешением 512х512 требует столько же времени, как и традиционный метод сканирования (incremental scan conversion), но при большем разрешении (напр. 4096х4096) наш алгоритм оказывается на порядок быстрее, делая его удобным для решения таких задач, как сглаживание и линейная фильтрация. Для сложных сцен с большим количеством перекрывающихся полигонов мы комбинируем иерархический тайлинг с другими иерархическими алгоритмами определения видимости, производя отброс невидимой геометрии и в объектном пространстве. Тестируя такую комбинацию алгоритмов на изображении с сеткой в 4096х4096 пикселей, мы достигли производительности иерархического Z-буфера при просчете видимости на изображении размерностью 512х512 пикселей. При этом алгоритм эффективно сглаживал изображения, содержащие сотни тысяч полигонов.
| Описание иерархических алгоритмов определения видимости, и в частности, иерархического Z-буфера, можно прочитать здесь. |
Так как алгоритм требует строго придерживаться метода от ближнего к дальнему при подаче полигонов на обработку, то мы будем представлять исходную объектную сцену в виде древовидной структуры BSP (binary space partitioning tree). В тех случаях, когда поддержание строгого порядка сортировки по глубине не очень удобно, мы комбинируем иерархический тайлинг с иерархическим Z-буфером, переключаясь на Z-буфер в те моменты, когда поступивший на обработку объект в действительности не является ближайшим.
Введение
С момента изобретения растровой графики алгоритмам тайлинга уделялось пристальное внимание. Их задачей было максимальное эффективно определить, какому именно объекту в трехмерной сцене должен принадлежать конкретный пиксель из формируемого растрового изображения. В настоящее время программы, использующие тайлинг полигонов на недорогом компьютерном оборудовании, могут растеризовать простейшие трехмерные сцены на скоростях, соответствующих понятию интерактивной графики. Наиболее производительные алгоритмы тайлинга скрупулезно проработаны с целью максимальной утилизации когерентности в пространстве изображения, однако они редко используют возможность предварительного просчета видимости и тратят время на тайлинг невидимой геометрии. Поэтому встает вопрос о разработке нового алгоритма, позволяющего учесть когерентность изображения, предварительно просчитать и отбросить значительную часть невидимой геометрии и эффективно реализовать тайлинг видимой геометрии.
Наиболее простой и распространенный алгоритм тайлинга полигонов — это алгоритм преобразований по линии сканирования (incremental scanline conversion), далее-Инкрементальное сканирование.
| Понять принцип инкрементального сканирования можно из следующей статьи. На первый взгляд покажется, что инкрементальное сканирование с трудом попадает под определение тайлинга. Но, по сути, автор здесь абсолютно прав, т.к. пересекая полигон, линия сканирования сформирует прямоугольный тайл шириной в пиксель и длиной равной сечению полигона. |
На первой стадии алгоритма, линия сканирования, пересекая периметр полигона, определяет два крайних пикселя. Эти два пикселя обозначат прямоугольное пространство внутри полигона, которое далее будет просчитываться попиксельно, позволяя инкрементально обновлять оттенок (цвет) и значение глубины, в случае с Z-буфером. На второй стадии решаем извечную проблему 3D графики — проблему определения видимости. Видимость пикселей можно определить одним из следующих методов:
- используя Z-буфер, путем сравнения значений глубины;
- обрабатывая полигоны в порядке от дальнего к ближнему (алгоритм художника), каждый раз переписывая значения параметров пикселя.
- обрабатывая полигоны в порядке от ближнего к дальнему и обновляя только вакантные пиксели.
Преобразования по линии сканирования — инкрементальный алгоритм. Он очень эффективно использует когерентность изображения при нахождении краев полигонов и просчете параметров пикселей, поэтому прост в реализации и исполнении.
Однако первый и самый главный недостаток традиционного инкрементального сканирования состоит в том, что алгоритм вынужден сканировать каждый пиксель на каждом примитиве, затрачивая, таким образом, драгоценное время на обработку невидимой геометрии. Если сцена не слишком сложна, это не страшно, но если количество полигонов велико, указанный недостаток существенно понижает эффективность алгоритма. В идеале, время работы совершенного алгоритма должно быть прямо пропорционально сложности видимой геометрии сцены и не зависеть от общей сложности сцены и количества невидимых глазу полигонов.
Алгоритм рекурсивного деления пространства по Варноку [Warnock69] удовлетворяет поставленному условию в достаточной мере, осуществляя поиск видимых участков изображения путем рекурсивного, четырехкратного деления тайлов, содержащих полигоны. Если обработка примитивов осуществляется от ближнего к дальнему, то алгоритм будет исследовать только те тайлы, которые содержат видимые участки полигонов. Несмотря на то, что алгоритм Варнока в целом соответствует нашему желанию работать только с видимыми частями примитивов, традиционное деление осуществляется довольно медленно, и конечном итоге проигрывает по скорости инкрементальному сканированию, за исключением случаев с очень сложными сценами. Традиционный алгоритм Варнока, впрочем, как и инкрементальное сканирование, оказываются малопригодными для обработки сцен средней сложности.
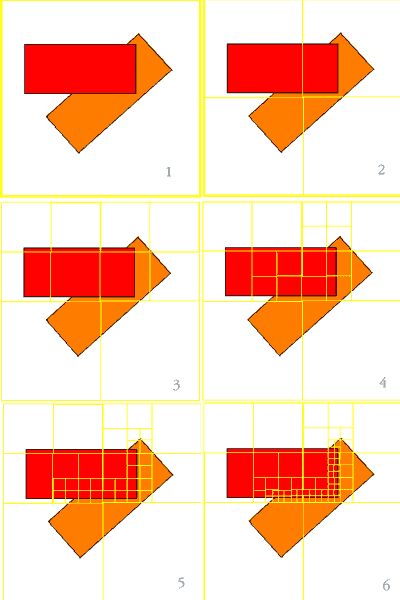
Второй недостаток, присущий инкрементальному сканированию, заключается в том, что оно затрачивает массу времени на определение краев полигона и просчет содержимого внутри примитива "пиксель за пикселем", тогда как все возможные комбинации пикселей, возникающие при пересечении краем полигона некоторого блока пикселей, могут быть просчитаны заранее и сохранены в виде битовых масок, называемых масками охвата. Путем композиционирования (здесь: совмещение на основе булевых операций) масок, соответствующих краю примитива, можно легко определить, какие именно пиксели будут принадлежать примитиву. Ранее подобная технология использовалась при реализации функций цифровой фильтрации изображения для вычисления площади охвата фрагментом полигона пространства внутри пикселя. [Carpenter84, Sabella-Wozny83, Fieume-et-al83, Fieume91].
В данной статье мы представим новый алгоритм, осуществляющий тайлинг полигонов, объединяющий в себе лучшие черты трех перечисленных выше традиционных алгоритмов. Ключевой особенностью нашей реализации, позволяющей собрать воедино три разных алгоритма, является обобществление охватывающих масок для всей иерархии изображения. Обобществленные маски будут называться тройственными охватывающими масками и обеспечат классификацию всех участков в структуре (иерархии) изображения как внутренних, внешних или пересекающих край примитива. Это позволит им непосредственно управлять делением отображаемого пространства на тайлы. В результате мы получим технологию иерархического тайлинга, эффективно определяющего видимость (по Варноку), использующего заранее просчитанные пиксельные комбинации (как при фильтрации с масками охвата) и успешно утилизирующего когерентность участков изображения (как и в случае с инкрементальным сканированием). Реализованный таким образом алгоритм очень эффективно производит тайлинг изображений с высоким разрешением (например, на сетке в 4096х4096 сэмплов) и таким образом, по своей сути, прекрасно подходит для сглаживания изображений методами на основе избыточности или для реализации функций фильтрации. Например, сглаживание на базе A-буфера с применением охватывающих масок [Carpenter84] нам представляется очень удобным вариантом.
| На iXBT уже представлен материал, посвященный акселератору, реализующему модифицированный А-буфер с охватывающими масками. |
Для сцен с большим количеством взаимно перекрывающихся полигонов мы комбинировали иерархический тайлинг с иерархическим алгоритмом определения видимости [Greene-Kass-Miller93, Greene-Kass94, Greene95], который позволяет отбросить невидимую геометрию непосредственно в объектном пространстве. Такая комбинация дает возможность рендеризовать сложнейшие сцены при малых временных затратах, обеспечивая при этом высокое качество сглаживания. Так, на тестовой сцене с 167 миллионами повторяющихся полигонов комбинированный метод определил видимость в изображении с сеткой 4096х4096 так же быстро, как метод иерархической Z-буферизации [Greene-Kass-Miller93] на изображении 512х512 пикселей.
Далее, во второй части, мы дадим обзор уже проведенных изысканий в области тайлинга полигонов. В третьей части рассмотрим тройственные охватывающие маски, в четвертой опишем алгоритм их применения. В пятой части обсудим варианты отсечения геометрии в объектном пространстве и их применение для сцен с высоким коэффициентом взаимного перекрытия примитивов. В шестой части будет представлен на обсуждение вопрос оптимизации рендеринга сложных, динамически меняющихся сцен. В седьмой части сравним между собой иерархический тайлинг и иерархический Z-буфер. В восьмой обсудим применение иерархического тайлинга для многогранников. Девятая часть будет посвящена конкретной реализации алгоритма и результатам его применения для простых и сложных сцен. И, наконец, в десятой части мы дадим наши заключения.
2. Предыдущие наработки
2.1 Алгоритм Варнока
Наш алгоритм основан на алгоритме рекурсивного деления пространства по Варноку [Warnock69], когда участки изображения (ячейки), в которых видимость не определена, делятся на четыре равных подпространства. В начальный момент все примитивы, составляющие сцену, назначаются базовой ячейке, называемой корневой ячейкой и равной размеру экрана. Далее корневая ячейка делится на четыре равные подпространства (субъячейки) меньшего размера. Теперь на каждой стадии деления (цикла рекурсии), наш алгоритм рассматривает субъячейки как находящиеся внутри полигона, содержащие полигон полностью или пересекающие обрабатываемый примитив. Будем называть эти ячейки как внутренние, внешние и пересекающие соответственно. Из всех трех типов ячеек только пересекающие ячейки будут подвергнуты дальнейшему делению. Ячейки, которые целиком находятся внутри одного или нескольких полигонов, считаются идентифицированными и дальнейшему делению не подлежат, так как все остальные полигоны, принадлежащие данной ячейке, будут невидимы и отброшены алгоритмом. Управление процессом деления ячеек на субъячейки и критерии, по которым делается вывод о необходимости дальнейшего деления, зависят от конкретного варианта реализации алгоритма Варнока и могут варьироваться [Roger85]. Типовая схема реализации обрабатывает полигоны без какой либо жесткой привязки к последовательности их подачи на обработку, поддерживает список потенциально видимых полигонов для каждой ячейки и затрачивает значительное время, сравнивая значения глубин с целью отсечения невидимых примитивов.
Когда обстоятельства позволяют удобно произвести обработку в порядке от ближнего к дальнему, как в случае с заранее отсортированной статической полигональной моделью или сценой, то применяется более эффективный и простой в реализации вариант алгоритма Варнока. В таком подходе полигоны обрабатываются алгоритмом строго по одному, от самого ближнего к самому дальнему. В процессе деления ячейки, полностью покрытые полигоном, отмечаются как закрытые, а закрытые ранее игнорируются, так как мы знаем, что вся остальная геометрия в данной ячейке будет скрытой (невидимой). Процесс деления и обработки полигона продолжается до тех пор, пока не достигнут минимально возможный размер ячейки или пока все ячейки не будут помечены как занятые. Такой вариант алгоритма Варнока исполняется заметно быстрее, т. к. нет необходимости поддерживать список примитивов и сравнивать глубины. Он более эффективен и потому, что в отличие от традиционного алгоритма, делению подвергаются ячейки, пересекающие только те примитивы, края которых будут видны на окончательном изображении. Наш алгоритм будет реализовывать именно такой вариант, который мы назовем алгоритмом Варнока с приоритетом глубины.
2.2 Охватывающие маски
В этой части мы обзорно рассмотрим способы применения охватывающих масок для реализации функций цифровой фильтрации изображения [Carpenter84, Sabela-Wozny83, Fiume-et-al83, Fiume91]. Суть здесь такова, что все возможные комбинации растровых сэмплов, возникающих при пересечении пикселя кромкой полигона, можно заранее просчитать, а затем применять, предварительно проиндексировав комбинации в соответствии с точками пересечения краев полигона и пикселя. Полученные таким образом комбинации сэмплов можно сохранить в виде битовой маски, а сэмплы, принадлежащие полигону, вдоль его краев определить при помощи логического умножения (операция "И") с маской. Использование операций с битовыми масками для определения видимости внутри пикселя даст результат независимо от способа подачи полигонов. Так, например, алгоритм с использованием А-буфера, впервые описанный Карпентером [Carpenter84], вычленяет из полигона краевые пиксельные фрагменты, сортирует их по глубине в порядке от ближнего к дальнему и путем композиционирования с битовыми масками находит сэмплы, определяющие видимость полигона внутри пикселя. Разработанный Карпентером алгоритм использует битовые маски и для ускорения фильтрации формируемого изображения. Так, основываясь на количестве бит в маске установленных в "1", определяется цветового смещения для видимого фрагмента (в указанном случае фрагмент равен пикселю) и комбинируется с текущим цветом пикселя. Такой подход к определению цвета пикселя, в сущности, выполняет сглаживание (antialiasing) изображения.
3. Тройственная маска
Для того, чтобы эффективно осуществлять тайлинг полигонов, наш иерархический алгоритм обобществляет битовые маски со всеми составляющими иерархии изображения. Такое решение позволит реализовать алгоритм Варнока, где процесс рекурсивного деления изображения будет управляться результатом битовых операций с масками. Обычная охватывающая маска классифицирует каждый растровый отсчет на краю полигона как наружный и внутренний по отношению к самому краю примитива (Рис 1а). По аналогии с алгоритмом Варнока, подобная операция классифицирует субъячейки как внешние, внутренние и пересекающие край, как показано на Рис. 1b, где край полигона проходит через сетку (4х4) субъячеек. Наша тройственная маска имеет именно такой вид, и ее тройственность заключается в тривиальном "Принять", "Отклонить" или "Работать дальше". Тройственная маска, разработанная нами, состоит из двух битовых масок: первая указывает на внутренние субъячейки, вторая на внешние (Рис1с и 1d). Будем обозначать первую маску буквой "С" (covered), а маску для внешних ячеек — буквой "V" (vacant). Оставшиеся субъячейки, пересекающиеся с краем полигона, назовем активной рабочей площадью маски, ввиду того, что принадлежащие ей ячейки требуют дальнейшей работы и позже будут снова поделены. Эта часть маски будет обозначена "А", показана на Рис. 1е и представляет собой А=~(С|V) — "ИЛИ-НЕ" в булевом выражении.
| В нашем случае битовые операции представлены в стандартной булевой нотации, когда & — означает "И", | — означает "ИЛИ", ~ — означает инверсию "НЕ" (комплемент) |
На практике алгоритм использует сетку размерностью 8х8, однако на рисунках в целях наглядности изображена сетка 4х4.
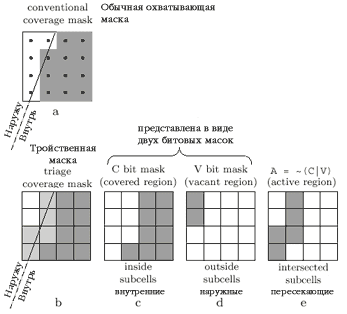 | Рисунок 1. Обычная охватывающая маска определяет единичные отсчеты сетки как наружные и внутренние (фрагмент а). Тройственная охватывающая маска определяет субъячейки как внешние, внутренние и пересекающие край полигона (фрагмент b). Будем называть их как закрытые (covered), вакантные (vacant) и активные (active). Сама тройственная маска состоит из двух битовых масок (C, V), определяющих закрытые и вакантные участки. На практике, наш алгоритм использует маски размерностью 8х8, а не 4х4, как изображено на рисунке. |
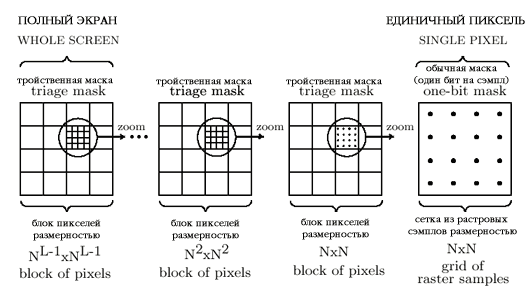
Обычные охватывающие маски реализуют две базовые функции тайлинга и определения видимости: (1) поиск маски, соответствующей обрабатываемому полигону из таблицы масок, описывающих края полигона; (2) поиск видимых сэмплов полигона внутри пикселя путем совмещения маски текущего полигона с маской пикселя, полученной при обработке предыдущего полигона (см. далее описание алгоритма). С точки зрения иерархического тайлинга, тройственные маски осуществляют те же самые операции. Разница состоит в том, что тройственные маски применяются на всех элементах иерархии изображения, а применение обычных масок ограничивается конкретным прямоугольным участком изображения, в нашем случае — пикселем. Иерархию изображения составляют уровни так называемой "пирамиды охвата", которая схематично воспроизведена на Рис. 2. (Если представить данный рисунок в трехмерной проекции, с соблюдением масштаба размеров уровней, изображение будет иметь вид пирамиды).
Рис. 2Схематическая диаграмма пирамиды масок размерностью NxN и количеством уровней L для изображения с дополнительной дискретизацией каждого пикселя сеткой размером NxN. Показанная "пирамида охвата" полностью состоит из тройственных масок, за исключением самого точного, верхнего уровня, где с пикселем ассоциируется обычная маска (один бит на отсчет). В приведенном примере иерархической дискретизации всего экрана, биты C и V тройственной маски будут указывать, какие именно квадратные участки экрана (тайлы) будут считаться закрытыми, вакантными или активными. На самом нижнем, грубом (по точности) уровне, тройственная маска соответствует экрану, на самом верхнем, точном пиксель дискретизируется растровыми сэмплами, которые представляют собой обычную маску. Четырех уровневая пирамида с масками 8х8 соответствует изображению в 512х512 пикселей с дополнительной (8х8) дискретизацией на каждый пиксель.
Операции (1) и (2), приведенные для тройственных масок, аналогичны обычным маскам и легко понятны. В работе [Greene95] можно дополнительно посмотреть примеры, иллюстрирующие совмещение тройственных масок и варианты формул для различных операций с масками.
Алгоритм работы различных масок
//Тайлинг полигона при помощи охватывающих масок.
Существующая охватывающая маска C для конкретной ячейки экрана представляет собой маску полигона, обработанного циклом ранее, и который находится ближе, чем обрабатываемый (текущий) полигон. Полигоны поступают на обработку строго по одному, от ближнего к дальнему.
Обычные охватывающие маски
Существующая маска пикселя: С
(1) В соответствии с точками пересечения краев полигона и границ пикселя выбираем из таблицы, соответствующие таким краям маски (назовем их E1, E2,...En).
Путем совмещения краевых масок определим маску полигона P :
P = E1 & E2 &...& En;
(2) Определим маску W соответствующую видимым сэмплам полигона P внутри С :
W = P & ~C;Обновляем содержимое пиксельной маски C :
C' = C | P;Тройственные охватывающие маски
Существующая тройственная маска для ячейки из "пирамиды охвата":
(Cc, Cv) — закрытые и вакантные составляющие маски.(1) Находим точки пересечения краев полигона с границей ячейки и находим соответствующие этим краям маски из таблицы ((E1c, E1v),... (Enc, Env)).Находим маску P(Pc, Pv) полигона :
Pc = E1c & E2c & ... & Enc;
Pv = E1v | E2v | ... | Env;
(2) Находим маску W полностью видимых ячеек, принадлежащих полигону внутри (Cc, Cv) :
W = Cv & Pc;Находим маску А активных ячеек на полигоне внутри (Сс, Сv):
А = ~(W | Pv | Cc);Обновляем (Cc, Cv):
Cc' = Cc | W;
Cv' = Cv & ~W;(Необходимо отметить, что обновление (Сс, Cv) может осуществляться и вызовами с других уровней пирамиды)
3.1 Тайлинг путем рекурсивного деления
Теперь, когда мы описали базовые операции тайлинга и определения видимых участков, можно перейти к рассмотрению процедуры тайлинга выпуклого полигона на основе рекурсивной процедуры. В начальный момент маски составляющие "пирамиду охвата" содержат информацию о тех участках растра, которые заняты ранее обработанными полигонами. Чтобы наше дальнейшее обсуждение приобрело более конкретный вид, договоримся, что мы будем использовать дополнительную 8х8 дискретизацию на каждый пиксель с целью осуществления функций фильтрации.
Для того, что бы осуществить деление полигона Р на маски, по точкам пересечения краев полигона с границей ячейки мы определяем соответствующие тройственные маски (просчитанные заранее и хранящиеся в виде таблицы). Найденные таким образом маски краев совмещаются (см. пометку (1) в описании алгоритма приведенного выше) для получения маски, соответствующей полигону Р в данной ячейке. Далее, начиная с корневой ячейки пирамиды, мы совмещаем маску полигона с маской соответствующей данной ячейке по предыдущим циклам. В результате мы определим три типа субъячеек:
- субъячейки, в которых полигон Р полностью невидим;
- в которых Р видим полностью (маска W);
- субъячейки, в которых видимость не определена, т.е. активные субъячейки (см. пометку 2).
Мы игнорируем ячейки, где Р невидим, отобразим или пометим ячейки, в которых видимость Р однозначно определена, а активные ячейки (маска А) дополнительно поделим (т.е. выполним рекурсию деления). Для каждой поделенной ячейки весь цикл выработки и обработки маски будет повторен, в результате мы перейдем на следующий уровень пирамиды, и определим новые активные ячейки, более точно соответствующие краю полигона. И так до самого точного уровня пирамиды, где ячейка будет равна пикселю на краю полигона, и с целью дальнейшей фильтрации мы задействуем самый верхний уровень пирамиды, делящий пиксель на сетку из растровых сэмплов. В этом случае мы сможем переключиться на работу с традиционным А-буфером: находим видимые сэмплы, принадлежащие Р; определяем их влияние на конечный цвет пикселя и полученное значение заносим в накопитель; после этого обновляем охватывающую маску для пикселя.
Если при этом статус пикселя сменился с вакантного или активного на активный или занятый, то статус маски в предыдущем, более грубом, уровне тоже должен смениться. Поэтому, используя простые операции с битами, мы меняем статус соответствующей маски из другого уровня пирамиды. Когда рекурсивный процесс заканчивается, мы можем сказать, что все видимые участки полигона были обработаны делением, а пирамида полностью обновлена. Описанная выше процедура приведена в листинге № 1 псевдокода.
LISTING 1 (pseudocode)
/*
Recursive subdivision procedure for tiling a convex
polygon P.
After clipping P to the near clipping plane in object
space, if necessary, and projecting P's vertices into
the image plane, we call tile_poly with the root mask of
the mask pyramid, P's edge list, and "level" set to 1.
arguments:
(Cc,Cv): pyramid mask (input and output)
edge_list: P's edges that intersect pyramid mask
level: pyramid level: 1 is root, 2 is next coarsest, etc.
*/
tile_poly((Cc,Cv), edge_list, level)
{
set active_edge_list to nil /* build P's mask (Pc,Pv) */
Pc = all_ones
Pv = all_zeros
for each edge on edge_list {
find intercepts on square perimeter of mask
if square is outside edge
then return /* polygon doesn't intersect mask */
if edge intersects square, then {
append edge to active_edge_list
/* Note: at the pixel level, Ec is a conventional
coverage mask and Ev = ~Ec */
look up edge mask (Ec,Ev)
Pc = Pc & Ec
Pv = Pv | Ev
}
}
/* make "write" bit mask and update pyramid mask */
W = Cv&Pc
Cc = Cc | W
Cv = Cv & ~W if level is the pixel level, then {
/* filter pixel using coverage mask W */
/* to perform A-buffer box filtering:
add bitcount*color to accumulation buffer */
evaluate shading and update accumulation buffer
return
}
for each TRUE bit in W {
for each pixel in this square region of screen {
/* to perform A-buffer box filtering:
add 64*(polygon color) to accumulation buffer */
evaluate shading and update accumulation buffer
}
}
/* Recursive Subdivision */
/* make "active" bit mask */
A = ~(W | Pv | Cc)
/* subdivide active subcells */
for each TRUE bit in A {
/* call corresponding subcell S
call its pyramid mask (Sc,Sv) */
copy all edges on active_edge_list that intersect
S to S_edge_list
tile_poly((Sc,Sv), S_edge_list, level+1)
/* propagate coverage status to coarser levels of
mask pyramid */
if Sc is all_ones
then Cc = Cc | active_bit /* set covered status */
if Sv is not all_ones
then Cv = Cv & ~active_bit /* clear vacant status */
}
}
4 Рендеринг сцены
Теперь, когда сама процедура тайлинга полигона была рассмотрена, мы готовы применить ее к рендеризации кадра. Но для начала уясним суть применяемых структур данных: структуры пирамиды, массива изображения, структуры используемой трехмерной модели.
4.1 Структуры данных
Для того, что бы деление Варнока могло управляться операциями с битовыми масками, мы храним информацию о видимости ранее обработанных полигонов в пирамиде, состоящей из охватывающих масок. Как мы видим из схемы на Рис. 2, в начальный момент единственная тройственная охватывающая маска представляет собой целый экран, тройственные маски следующего уровня соответствуют субъячейкам корневой маски и т.д. Таким образом, "пирамиду охвата" можно назвать иерархическим представлением изображения (отображаемого пространства), где С и V биты маски классифицируют ячейки изображения как занятые, вакантные или активные. Внутри занятых ячеек, вся геометрия, лежащая глубже, полностью скрыта и является невидимой. Внутри вакантных ячеек все растровые сэмплы считаются незанятыми в текущий момент и могут сменить свой статус при обработке других полигонов. Внутри активных ячеек, по крайней мере, один растровый сэмпл (но не все сразу) будет однозначно занят. На самом верхнем уровне пирамиды мы используем традиционные маски, где один бит описывает статус единичного отсчета растра (растрового сэмпла): т.е. — занят сэмпл или нет, а именно лежит внутри полигона или снаружи. Верхний, пиксельный, уровень пирамиды используется при избыточной дискретизации и реализации фильтрации. В этом случае каждая маска соответствует сетке 8х8 растровых сэмплов внутри одного пикселя. Так, соответствующая такому описанию пирамида изображения 512х512 pix с избыточной дискретизацией 8х8 на каждый пиксель будет содержать четыре уровня — тройственные маски будут храниться в трех массивах размерностью 1х1, 8х8 и 64х64; а четвертый уровень будет представлять массив 512х512 обычных масок.
Однако если нам не нужна избыточная дискретизация, и фильтрация изображения производиться не будет, то обычная маска будет соответствовать 8х8 блоку пикселей. В этом случае пирамида изображения 512х512 pix будет построена из двух массивов (1х1, 8х8) тройственных масок и одного массива (64х64) обычных масок, где один бит будет соответствовать целому пикселю.
Требования к количеству памяти, необходимой для хранения пирамиды, очень невелики. Ввиду того, что самый точный уровень использует всего один пиксель на растровый сэмпл, и наибольшее количество ячеек пирамиды будет находиться именно на этом уровне, то результирующие требования к памяти будут чуть выше, чем один бит на сэмпл. На практике, для хранения N-уровневой пирамиды потребуется, в среднем, от 1 целой и 1/32 до 1 целой и 1/63 бит на сэмпл, при N>1. Для сравнения заметим, что поддержка Z-буфера требует несопоставимо большего количества памяти, т.к. буфер хранит значение глубины для каждого сэмпла изображения.
Следующей структурой данных, используемой в нашем алгоритме, будет массив изображения, хранящий значения цветности на каждый пиксель. Если мы будем реализовывать фильтрацию изображения на основе А-буфера [Carpenter84], значения оттенка, получаемые на основе анализа 64 субпиксельных сэмплов, накапливаются в каждом элементе массива. Таким образом, аккумулятор (накопительный буфер) будет достаточно объемным. Каждый цветовой канал кодируется 16 битами на пиксель. Если не применять фильтрацию, то параметры пикселей не требуют накопления в буфере и для работы будет применен обычный массив цветности изображения.
Теперь несколько слов о представлении трехмерной модели. Наш алгоритм требует жесткого порядка обработки полигонов от ближнего к дальнему, поэтому представить трехмерную сцену в виде дерева двоичного деления пространства, или по другому, дерева BSP (binary space partitioning tree) будет наиболее оптимальным решением. Заранее просчитанная BSP сцена обеспечит нам требуемый порядок подачи полигонов на обработку. Далее, в части 6, мы обсудим аспекты использования BSP при формировании динамических сцен.
4.2 Стадия предварительных вычислений
На этапе предварительных вычислений мы формируем дерево BSP для нашей сцены. Далее, создаем таблицы краев для обычных и тройственных масок. Для этого мы делим периметр квадрата, соответствующего ячейке, на равные отрезки (например, на 64 равных отрезка). Каждой паре отрезков, не принадлежащих одной и той же стороне квадрата, будет соответствовать запись в таблице, представляющей собой двумерный массив. Запись представляет собой маску, соответствующую расположению сэмплов в сетке при определенном пересечении краем полигона сторон квадрата. После формирования таблицы мы узнаём, какие именно отрезки периметра пересечены и находим соответствующую запись. С целью экономии, для краев с противоположными направлениями мы применяем одну и ту же запись, так как логическое "отрицание" операции (C | V) для битовых масок, по сути, соответствует обратному краю. Однако иерархический тайлинг подразумевает однозначное трактование занятых и вакантных участков в тройственной маске, поэтому для исключения неоднозначности мы применяем следующую процедуру. Концы отрезков, применяемых для деления квадрата, всегда сформируют некий четырехугольник. Отсюда, любая субъячейка, пересекаемая этим четырехугольником, будет считаться активной, гарантируя действительную вакантность для вакантных ячеек, и занятость для занятых.
4.3 Формирование кадра
Создание кадра изображения начинается с чистки содержимого накопительного буфера и пирамиды. Обработка полигонов производится начиная с самого ближнего, в порядке, обеспечиваемом BSP структурой сцены. Каждый полигон подрезается по размерам выбранного квадранта в объектном пространстве, если необходимо, и проецируется на двумерное отображаемое пространство. При этом на не нужно хранить информацию о глубине. Перед тем, как приступить к тайлингу полигона, мы определяем, является ли видимым прямоугольник, содержащий в себе полигон (polygon bounding box). Если эта процедура не позволяет определить, что прямоугольник спрятан, то мы помещаем его в наименьшую из возможных ячеек нашей пирамиды и работаем с ним в соответствии с процедурой, описанной в Листинге 1. В тех участках экрана, где фрагменты полигона видимы, мы обновляем содержимое буфера изображения и статус пирамиды. Как только все полигоны обработаны, сцена считается обработанной и содержимое буфера изображения выводится на экран.
4.4 Способы фильтрации совместимые с нашим алгоритмом
Мы уже обсудили применение фильтрации на базе А-буфера, который, в свою очередь, к алгоритмам area sampling (дискретизация участков изображения). Abram, Westover и Whitted применили охватывающе маски к методам jitter (разброс сэмплов по стохастическому закону) и конволюции c произвольным ядром, а так же для выполнения операций затенения полигонов на базе таблиц [Abram-et-al85]. Все эти методы совместимы с иерархическим тайлингом. Для реализации табличной конволюции (table driven convolution) влияние каждого субпиксельного сэмпла на соседние пиксели вычисляется заранее и хранится в виде таблицы коэффициентов. Для простейших реализаций затенения полигонов влияние произвольного набора сэмплов может быть сохранено в виде коэффициентов, которые позволят, например, эффективно, байт за байтом, работать с охватывающими масками. Мы использовали этот метод для фильтрации 3х3 сетки из соседствующих пикселей.
4.5 Обычная дискретизация (Point sampling)
Для исключения функций фильтрации изображения и осуществления обычной дискретизации нам достаточно упростить наш алгоритм. В этом случае маска, соответствующая самому точному уровню пирамиды, будет определять не сетку субпиксельных сэмплов, а пиксельный блок 8х8. Таким образом, для каждой субъячейки, имеющей значение "TRUE" (см. псевдокод), мы определяем оттенок пикселя и пишем результат непосредственно в буфер изображения. Ввиду того, что теперь единичный сэмпл соответствует пикселю, нам нет необходимости использовать аккумулирующий (накопительный) буфер.
5. Иерархическое отсечение полигонов в объектном пространстве
Благодаря своей способности отсекать невидимую геометрию во всех элементах, составляющих иерархию изображения, иерархический тайлинг обрабатывает плотно перекрытые сцены значительно эффективнее типовых тайловых алгоритмов, которые вынуждены тратить время на попиксельную обработку невидимой геометрии. Тем не менее, наш алгоритм "пропустит через себя" все полигоны сцены, хотя многие из них вскоре определятся как полностью невидимые. Что бы исправить положение, мы скомбинируем наш алгоритм с иерархическим методом определения видимости [Greene-Kass-Miller93, Greene-Kass94, Greene95], что позволит иерархически отбросить невидимую геометрию непосредственно в объектом пространстве сцены. В нашем случае мы применим алгоритм иерархического Z-буфера [Greene-Kass-Miller93], хотя это и потребует внесения некоторых изменений в структуру объектного и отображаемого пространств. Так, в отображаемом пространстве вместо использования Z-пирамиды будет применена наша "пирамида охвата". В объектном пространстве мы изменим дерево разбиений пространства (octree) таким образом, чтобы обеспечить строгий порядок полигонов от ближнего к дальнему. Заметьте, что наш Z-буфер обрабатывал подпространства в порядке от ближнего к дальнему, но полигоны, находящиеся в этих подпространствах, могли обрабатываться в любом порядке, а так как сами кубические подпространства (квадранты) иерархически входили друг в друга, т.е. были дочерними и сами могли иметь дочерние квадранты, то будет недостаточным, просто построить структуру BSP внутри каждого квадранта. Что бы обеспечить строгий порядок обработки от ближнего к дальнему, мы должны видоизменить алгоритм построения древовидной структуры BSP.
В дальнейшем, для краткости, заглавная буква И с точкой (И.) будет означать понятие иерархический. Так, например, И.Z-буфер — будет означать Иерархический Z-буфер.
5.1 Building an Octree of BSP trees (построение октаструктуры из структур BSP)
| Если попытаться на русском языке объяснить значение термина Octree, то это будет означать "дерево, получающееся в результате рекурсивного деления объемного пространства на восемь кубических субпространств". Громоздко и неудобно употреблять такое описание постоянно, поэтому в рамках данной статьи это дерево будем называть Октаструктурой (от лат. Окта — восемь). Также необходимо уяснить, что аналогия с деревом основана на схематическом изображении данного процесса. Если воспроизвести процесс в виде рисунка, то получится некое подобие дерева, где каждая ветвь будет давать восемь новых ветвей. Как и каждое дерево, октаструктура имеет корень, ветви и листву. Причем каждая ветвь имеет узел(node) — точку роста, из которой и растут дальнейшие ветви. Листву формируют конечные, верхушечные узлы на самых последних ветвях дерева, т.е. те узлы, которые не дают новых ветвей, а являются листьями дерева. Такие листовые узлы (leaf nodes) в октаструктуре означают наиболее малые и последние субпространства, которые больше не подвергаются делению. Корнем в октаструктуре является базовый куб, охватывающий всю сцену целиком. Почитайте статью об иерархическом Z-буфере, если приведенное пояснение вам показалось недостаточным. Структура BSP (Binary Space Partitioning tree) также представляет собой дерево делений пространства, но только каждый раз на два. В наиболее распространенном варианте BSP разделителем каждый раз является плоскость полигона, которая делит пространство на два субпространства. Деление продолжается до тех пор, пока все полигоны не будут принадлежать своим собственным ветвям BSP дерева. Характерной особенностью структуры BSP является то, что она позволяет извлекать полигоны из структуры в соответствии с глубиной их залегания, как в порядке от ближнего к дальнему, так и наоборот. И последнее: в контексте рекурсивных делений пространств понятие "узел" и "ветвь" дерева будут идентичны и взаимозаменяемы. |
Начиная с корневого куба, соответствующего всему объектному пространству сцены, по очереди помещаем в него полигоны. Когда количество полигонов в кубе достигнет порогового значения (например, 30) мы делим куб на восемь меньших, дочерних кубов (подпространств). Размещаем полигоны в дочерних кубах, подрезая их под границы дочерних кубов, если необходимо. Подгружаем полигоны из списка содержащихся в сцене. Дочерние кубы, в которых количество примитивов достигнет порога, поделим его еще на восемь подпространств и т.д. После того как все полигоны сцены были размещены в своих собственных подпространствах, в соответствии с древовидной структурой рекурсии, то мы получим полностью сформированное дерево восьмикратных делений объектного пространства (октаструктуру), где все полигоны принадлежат конечным (листовым) ветвям дерева. Нам осталось только построить структуру BSP из полигонов, находящихся в листовых ветвях октаструктуры [Foley-et-al90]. Т.е. структуры BSP будут находиться только на конечных ветвях octree. Вот теперь, когда кубические подпространства сцены обрабатываются в порядке от ближнего к дальнему, а расположение полигонов в конечных ветвях определяется деревом BSP, мы можем с уверенностью сказать, что полигоны будут поступать на обработку начиная с самого ближнего и заканчивая самым дальним, и у нас не будет необходимости проверять их глубину.
5.2 Комбинирование иерархических алгоритмов тайлинга и видимости
Теперь, когда мы решили, каким именно образом будем обеспечивать обработку полигонов от ближнего к дальнему, перейдем к рассмотрению способа одновременного использования иерархических алгоритмов тайлинга и видимости. Как и в случае с иерархическим Z-буфером, мы будем работать с кубическими подпространствами от ближнего к дальнему, проверяя их на видимость и отбрасывая невидимые кубы. Видимость куба проверим путем тайлинга, и как только найдем видимый фрагмент, тайлинг данного куба прекращаем. Заметьте, что в отличие от иерархического Z-буфера, нам будет достаточно произвести тайлинг силуэта куба (если, конечно, куб не пересекает плоскость экрана). Для Z-буфера обработка силуэта была недостаточной, необходимо было проверить три наружных стороны (поверхности) куба. Мы несколько модифицируем процедуру в Листинге 1 так, что бы она возвращала TRUE в тот момент, когда маска полигона будет покрывать вакантную субъячейку или вакантный сэмпл (в случае пиксельной сетки). Такая модификация позволит использовать типовую процедуру для тестирования силуэта куба на видимость. Как только мы определили, что куб является видимым, мы обрабатываем принадлежащую ему структуру BSP методом от ближнего к дальнему, получая соответствующую пирамиду охвата. Закончив со всеми кубами сцены, мы сможем констатировать факт, что все видимые полигоны обработаны алгоритмом тайлинга и двумерное изображение сцены сформировано.
Такая комбинация алгоритмов эффективно работает как с объектным, так и с отображаемым пространством. Также как и иерархический Z-буфер в объектном пространстве, мы посещаем только видимые ветви дерева. В отображаемом пространстве иерархический тайлинг посещает только те ячейки, которые пересекаются видимыми в окончательном изображении поверхностями. Видимые сэмплы изображения повторно не переписываются.
При использовании графического акселератора, осуществляющего операции шейдинга, например текстурирование, мы сможем осуществлять проверку видимости центральным процессором, а шейдинг переложить на акселератор. В этом случае иерархический тайлинг будет формировать пирамиду охвата и отсекать геометрию в объектном пространстве, а акселератор сможет выполнить рендеринг видимых полигонов со сглаживанием на основе Аккумулирующего буфера, если таковой поддерживается [Haeberli-Akeley90]. Это будет очень производительным способом получить изображение сцен высокой плотности с наложением текстур.
6 Работа с динамическими моделями (сценами)
Однако иерархический тайлинг имеет и свои недостатки. Так, одним из них является необходимость жестко придерживаться метода от ближнего к дальнему. Это не проблема, если сцена статична, так как ее легко представить в виде BSP. Незначительное количество перемещающихся объектов также не вызовет заметных замедлений в работе алгоритма. Но в случае, когда сцена содержит множество перемещающихся полигонов, поддержка режима от ближнего к дальнему вызовет гигантский взрыв в количестве необходимых вычислений. Ниже будут рассмотрены два варианта, позволяющих обойти эту проблему.
6.1 Ленивая Z-буферизация (Lazy Z-buffering)
Описываемый ниже так называемый "ленивый Z-буфер" является хорошей альтернативой в случаях, когда, по крайней мере, часть сцены может быть удобно просчитана от ближнего к дальнему. Для удобства дальнейшего изложения определимся, что мы будем использовать избыточную дискретизацию и фильтрацию изображения. Для реализации указанного варианта тайлинга несколько подкорректируем наш алгоритм. Для каждой ячейки в пирамиде мы будем поддерживать минимальное и максимальное значение Z, исходя из глубины залегания уже просчитанных полигонов пересекающих ячейку. Будем называть эти значения как znear и zfar -соответственно. Далее, вместо того, что бы позволить алгоритму автоматически отсечь часть полигона, которая пересекает занятые ячейки, условимся, что отсечем ее только тогда, когда сам полигон будет лежать глубже значения zfar для ячейки. Условимся, что на пиксельном уровне фрагменты полигона поступают в таком порядке, какой позволит нам использовать охватывающую маску пикселя, т.е., например, один или несколько не перекрывающихся между собой фрагментов покрывают все субпиксельные сэмплы перед поступлением остальных фрагментов. Соблюдение этих условий легко контролировать с помощью пиксельной маски и значений znear/zfar. До тех пор, пока на обработку не поступил фрагмент, нарушающий эти условия — мы осуществляем фильтрацию изображения обычным образом, аккумулируя значения пиксельных коэффициентов затенения и обновляя маску пикселя. Одновременно кэшируем текущую информацию о фрагменте. Как только поступил фрагмент, нарушающий условия — мы очищаем аккумулятор со значениями оттенков пикселей и переходим к работе с обычным (традиционным) z-буфером. Для этого выделяем место в памяти для хранения цветности и глубины для каждого субпиксельного сэмпла, извлекаем из кэш хранимый там фрагмент и обрабатываем его. В результате мы получим точно такое же значение сэмпла изображения, которое мы получили бы при использовании избыточного z-буфера с самого начала. После того, как все полигоны в сцене были подвергнуты тайлингу, нам останется только осуществить фильтрацию значений пикселей из z-буфера. В конечном итоге, мы получим изображение, аналогичное тому, которое получилось бы при использовании базового иерархического тайлинга со строго упорядоченной обработкой по глубине.
В случае, когда большая часть сцены обрабатывается строго от ближнего к дальнему, то вышеизложенный вариант "ленивого z-буфера" будет лишь немногим медленнее базового иерархического тайлинга. Описанная ситуация возникнет тогда, когда некоторое небольшое количество движущихся полигонов будет размещено перед статическим (неизменяемым) набором примитивов, просчитанных от ближнего к дальнему. При самых тяжелых условиях, когда расположенные впереди движущиеся объекты не были обработаны первыми, ленивый z-буфер окажется чуть медленнее иерархического z-буфера.
6.2 Слияние древовидных структур
Для полигональных сцен, состоящих их независимо передвигающихся твердых объектов, можно применить другой способ просчета изображения, дающий возможность обработать полигоны строго от ближнего к дальнему, а значит использовать стандартный иерархический тайлинг полигонов. Для этого каждое твердое тело сцены мы представим в виде отдельной октаструктуры из структур BSP (аналогично тому, что описывалось в параграфе 5.1). Для формирования кадра изображения мы обрабатываем все октаструктуры одновременно, в порядке от ближнего к дальнему, отбрасывая те ветви октаструктуры, кубические пространства которых полностью перекрыты пирамидой охвата. Синхронность обработки октаструктур обеспечиваем следующим образом — для каждой октаструктуры выбираем самый ближний куб из листовых ветвей в качестве текущего и проверяем его на пересечение с ближайшими кубами листовых ветвей остальных октаструктур. Если одиночный куб не пересекает других кубов, то мы смело рендеризуем всю его BSP структуру. Если пересекает, то подрезаем полигоны пересеченных кубов под границы текущего куба, полученные фрагменты внедряем в структуру BSP текущего куба и уже затем рендеризуем полученное BSP дерево. Таким образом, мы последовательно отбросим или отрендеризуем все ветви октаструктур, тем самым закончив обработку сцены. Описанный подход к визуализации динамических сцен близок по затратам времени к стандартному иерархическому тайлингу, за исключением разницы во времени, необходимом на реорганизацию и слияние древовидных структур объектов. Слияние структур может потребовать значительных вычислений и времени, но в большинстве сцен такое объединение будет не частым явлением, поэтому допустимо считать, что применение описанного метода будет оправданным.
7. Сравнение возможностей иерархического тайлинга с иерархическим Z-буфером
Следующая таблица производит сравнение двух иерархических алгоритмов по некоторым ключевым параметрам.
| Сравниваемые параметры | Иерархический тайлинг | Иерархический Z-буфер |
| Иерархия в объектном пространстве | стр-ра BSP октаструктура стр-р BSP | октаструктура (octree) |
| Иерархия в отображаемом простр-ве | пирамида из охватывающих масок | Z-пирамида |
| Необходимость обработки строго от ближнего к дальнему | да | нет |
| Количество бит на сэмпл для хранения инфор-ии о цветности | 0 (не нужно) | RGB. Обычно 24-36 бит на сэмпл |
| Среднее количество бит на сэмпл для храниния информ-ии о видимости | менее 1 целой и 2/63 бит на сэмпл | Z. Обычно 24-32 бита на сэмпл |
| Буфер изображения | аккумулятор | стандартный кадровый |
| Необходимость хранения таблиц для охватывающих масок | да | нет |
| Неоднократная перезапись пикселя | отсутствует | присутствует |
| Встроенная поддержка функций фильтрации изображения | да | нет |
| Поддержка статуса "занято" для ячеек пирамиды изображения | да | нет |
Как видно, И.тайлинг использует жесткую (от ближнего к дальнему) последовательность при обработке полигонов, что усложняет иерархию объектного пространства, которая может состоять из сложной октаструктуры структур BSP. Следующее преимущество иерархического Z-буфера — он не нуждается в хранении и использовании заранее сформированых таблиц (массивов) для масок охвата. Это две единственные позиции, по которым иерархический тайлинг проигрывает, в остальных — он бесспорный лидер. Там, где И.Z-буфер требует хранить информацию о цветности и глубине единичного сэмпла изображения, И.тайлинг (в среднем) обеспечивает кодирование на уровне 1 бита на сэмпл. В результате, требования к количеству оперативной памяти почти на два порядка ниже. Так, например, для растеризации изображения размером 512х512 пикселей с дискретизацией 8х8 на каждый пиксель, И.тайлинг потребовал только 3.7% памяти от объема, необходимого z-буферу. К другим преимуществам И.тайлинга относятся такие особенности, как отсутствие необходимости повторно переписывать содержимое одного и того же пикселя. И.тайлинг по своей природе очень близок к методам, используемым функциями фильтрации изображения, и эффективно утилизирует когерентность в отображаемом пространстве путем идентификации участков в пирамиде, которые полностью закрыты самостоятельными примитивами.
8. Тайлинг многогранников
Алгоритм иерархического деления с использованием охватывающих масок можно эффективно применить для деления выпуклого трехмерного многогранника на воксельную сетку. При этом деление будет основано на методе Варнока. В этом случае 64 битная тройственная маска будет описывать каждую из 4х4х4 ячеек куба как внутреннюю, внешнюю или пересекающую плоскости многогранника. Тройственная маска для выпуклой многогранной фигуры внутри куба может быть получена путем совмещения масок для лицевых сторон куба. Рекурсивная процедура деления многогранника будет аналогична тайлингу полигона и обеспечит посещение только тех ячеек в трехмерной охватывающей пирамиде, которые пересекаются лицевыми поверхностями многогранника. Скорость и новизна, обеспечиваемая описываемым алгоритмом объемного тайлинга, делает его очень привлекательной альтернативой традиционным алгоритмам [Kaufman86].
9. Реализация на практике и результаты
Иерархический тайлинг полигонов был реализован на Си и производил растеризацию сцен, состоящих из выпуклых полигонов с равномерным цветовым затенением. Программа производила рендеринг как в режиме обычной дискретизации (point sampling), так и с использованием функций фильтрации изображения. Фильтрация могла осуществляться как на основе традиционного А-буфера так и на основе более сложного и редкого алгоритма, применяющего максимумы косинуса в пределах окружности радиусом в один пиксель. (Для простоты, далее будем называть этот алгоритм косинусоидальной фильтрацией). Цветовые компоненты в накопителе А-буфера представлялись целым 16 битным числом, и 32 битным числом с плавающей точкой в случае использования косинусоидальной фильтрации. Таблицы (массивы) для масок охвата создавались из расчета разбиения периметра квадрата на 64 отрезка. Битовые маски для пиксельного уровня пирамиды генерировались по стохастическому закону с использованием случайного расположения сэмплов внутри соответствующей квадратной области внутри пикселя [Dippe-Wold85, Cook86]. Все описываемые ниже тесты производились на компьютере SGI Indigo2 с 75 Мгц процессором R-8000, который без труда осуществлял 64 битовые операции с масками.
Для того, чтобы оценить производительность И.тайлинга по сравнению с традиционным инкрементальным сканированием, мы задействовали простейшую модель, состоящую из 64 кубов, обеспечивающих 192 лицевые поверхности (См. Рис.5). Рендеризация проводилась как с использованием И.тайлинга, так и с применением традиционного "алгоритма художника" т.е. методом от дальнего к ближнему, в результате чего метод инкрементального сканирования многократно переписывал каждый пиксель на своем пути. В результате И.тайлинг обеспечил рендеризацию изображения в 512х512 пикселей с фильтрацией на сетке в 4096х4096 растровых сэмплов за 0.357 секунды. Алгоритм художника за такое же время обеспечил рендеризацию сетки в 910х910 сэмплов, а протестировать его на сетке 4096х4096 мы просто не смогли ввиду тривиальной нехватки количества оперативной памяти на компьютере для формирования полноцветного RGB изображения таким способом. Проведенный пример показывает, что даже на простейших моделях для осуществления сглаживания и фильтрации И.тайлинг более привлекателен традиционного сканирования.
Для тестирования возможностей И.тайлинга при рендеризации сложных, плотно перекрытых сцен мы комбинировали иерархический тайлинг с иерархическим алгоритмом определения видимости (как описано в параграфе 5). В качестве тестовой модели мы применили ту же самую модель модульного здания, использованную при тестировании иерархического Z-буфера в работе [Greene-Kaas-Miller93]. В соответствии с параграфом 5.1, мы построили октаструктуру на основе структур BSP для дублирующихся модулей офисного здания. Каждая из структур BSP содержала приблизительно 16000 прямоугольников. Размножив структуры по размерам границ здания, мы получили 408 этажную модель, напоминающую Empire State Building в Нью-Йорке, состоящую из 167 миллионов прямоугольников. Рисунки 4, 6, 7 показывают получившееся здание с различных ракурсов.
Что бы сравнить производительность И.тайлинга и И.Z-буфера мы рендеризовали анимацию, представляющую собой виртуальную прогулку по зданию. И.тайлинг производил визуализацию изображения на сетке в 4096х4096 растровых сэмплов, получив в итоге финальные кадры с разрешением 512х512 пикселей и наложенной фильтрацией. И.Z-буфер непосредственно осуществлял рендеринг 512х512 pix изображения с обычной дискретизацией. В итоге И.тайлинг показал практически одинаковую производительность с И.Z-буфером, но с той разницей, что в первом случае мы наблюдали сглаженный А-буфером приятный на вид кадр, а во втором, как и ожидалось, изображение имело отчетливо заметную "ступенчатость".
С целью оценки способности алгоритма осуществлять фильтрацию изображения чрезвычайно сложных сцен мы произвели рендеринг анимации, в которой камера совершала облет здания Empire State Building и затем проходила сквозь него. На рисунках 6 и 7 показаны кадры из той анимации — они представляют собой изображения размерностью 512х512 пикселей, которые были получены путем тайлинга на 4096х4096 сетке растровых сэмплов со стохастическим распределением. Изображение подвергалось косинусоидальной фильтрации. Изображение модели здания под углом зрения соответствующем Рис.6 содержит приблизительно 750000 видимых полигонов, а некоторые пиксели заключают в себе десятки примитивов и, тем не менее, мы наблюдали высококачественное сглаживание кадров по всей длине анимации. Стохастическое распределение субпиксельных сэмплов превратило искажения, вызванные дискретностью изображения (aliasing) в "шум", который замечался только на кадрах, содержащих сотни тысяч видимых примитивов. Иногда на полученной нами анимации мы могли наблюдать паразитный муар — его происхождение объяснялось применением одинаковых стохастических комбинаций для всех пикселей. Эта проблема решалась путем использования нескольких вариантов комбинаций сэмплов.![]()
На реальных тестах с применением косинусной фильтрации и в режиме поддержки множественных стохастических комбинаций сэмплов алгоритм показал время в 5.15 минуты для Рис. 6 и 34 секунды для Рис. 7, содержащего приблизительно 83300 видимых полигонов. Использование однотипных комбинаций сэмплов уменьшило время рендеризации изображения Рис. 6 до 4.48 секунды. Приведенные выше результаты тестирования позволяют сказать, что рассмотренный нами иерархический алгоритм тайлинга полигонов с использованием охватывающих масок очень эффективно обрабатывает сцены сверхсложной геометрии и сферой его применения является генерация изображений трехмерных моделей высокой и сверхвысокой сложности.
10. Заключение
Элегантный алгоритм деления пространства, изобретенный Варноком, является одним из самых известных в компьютерной графике. Однако, несмотря на то, что этот алгоритм очень хорошо изучен, на практике его применяют достаточно редко, ввиду недостаточной производительности оригинальной процедуры деления. В нашей работе мы показали, насколько эффективным может быть деление по Варноку управляемое тройственными охватывающими масками. Получившийся в результате алгоритм иерархического тайлинга полигонов показывает прекрасные результаты, обрабатывая только ячейки с видимыми фрагментами полигонов и никогда не переписывая однажды сформированный пиксель. Конек алгоритма — изображения с высоким разрешением, поэтому это очень удобный инструмент для осуществления функций сглаживания и фильтрации. Алгоритм компактен, не вызовет сложностей при реализации и требует минимальных размеров памяти.
11. Особые благодарности
Автор благодарит Гавина Миллера за предложенный вариант совмещения аппаратного и программного тайлинга, описанного в п. 5.2. Гавин также оказал содействие в проектировании тестовой модели офисного блока Рис. 4. Общение и дискуссии с Piter van Zee зародили идеи совмещения древовидных структур, описанного в п. 6.2. И, наконец, автор выражает признательность рецензенту #4 SIGGRAPH за очень внимательное изучение статьи и конструктивную критику.

Внутренний вид модели Empire State Building. Иерархический тайлинг просчитал это изображение за 3.32 секунды на сетке в 4096х4096 сэмплов. Результирующее изображение составило 512х512 пикселей. (75 Mhz processor)

Алгоритм осуществил тайлинг этой сцены с фильтрацией на базе А-буфера за 360 миллисекунд. Изображение размером 512х512 пикселей на сетке 4096х4096 сэмплов.

Кадр из анимации "Naked Empire". Модель этого 408 этажного здания состоит из 167 миллионов прямоугольников, 750000 из которых видимы в данном ракурсе. Это изображение размером 512х512 пикселей было просчитано алгоритмом иерархического тайлинга с включенной функцией фильтрации на базе стохастической сетки 4096х4096 сэмплов. Стохастический (по случайной выборке) подход к формированию субпиксельных комбинаций сэмплов сформировал "зашумление" на участках изображения с наиболее плотной геометрией. Рендеризация этого кадра потребовала 5.15 минут на 75 Мгц процессоре.

Еще один кадр из Naked Empire. Заметьте, что модель здания не имеет внешних стен, что дало возможность заглянуть глубоко во внутрь модели небоскреба. Рендеризация данного кадра потребовала 34 секунды на процессоре в 75 Мгц.
Ссылки и литература
- [Abram-et-al85]
- G. Abram, L. Westover, and T. Whitted, "E_cientAlias-Free Rendering using Bit-Masks and Look-Up Tables" Proceedings of SIGGRAPH '85, July 1985, 53-59.
- [Carpenter84]
- L. Carpenter, "The A-buffer, an Antialiased HiddenSurface Method" Proceedings of SIGGRAPH '84 , July 1984.
- [Catmull74]
- E. Catmull, "A Subdivision Algorithm for ComputerDisplay of Curved Surfaces" PhD Thesis, Report UTEC-CSc-74-133, Computer Science Dept., University of Utah, Salt LakeCity, Utah, Dec. 1974.
- [Catmull78]
- E. Catmull, "A Hidden-Surface Algorithm with Anti-Aliasing" Proceedings of SIGGRAPH '78 , Aug. 1978, 6-11.
- [Cook86]
- R. Cook, "Stochastic Sampling in Computer Graphics" ACM Transactions on Graphics, Jan. 1986, 51-72.
- [Dipp_e-Wold85]
- M. A. Z. Dipp_e and E. H. Wold, "Antialiasingthrough Stochastic Sampling" Proceedings of SIGGRAPH' 85, July 1985, 69-78.
- [Fiume-et-al83]
- E. Fiume, A. Fournier, and L. Rudolph, "A ParallelScan Conversion Algorithm with Anti-Aliasing for a General-Purpose Ultracomputer" Proceedings of SIGGRAPH '83 , July1983, 141-150.
- [Fiume91]
- E. Fiume, "Coverage Masks and Convolution Tables forFast Area Sampling" Graphical Models and Image Processing, 53(1), Jan. 1991, 25-30.
- [Foley-et-al90]
- J. Foley, A. van Dam, S. Feiner, and J. Hughes, Computer Graphics, Principles and Practice, 2nd edition, Addison-Wesley, Reading, MA, 1990.
- [Fuchs-Kedem-Naylor80]
- H. Fuchs, J. Kedem, and B. Naylor, "OnVisible Surface Generation by a Priori Tree Structures", June 1980, 124-133.
- [Greene-Kass-Miller93]
- N. Greene, M. Kass, and G. Miller, "Hier-archical Z-Buffer Visibility" July 1993, 231-238.
- [Greene-Kass94]
- N. Greene and M. Kass, "Error-Bounded An-tialiased Rendering of Complex Environments", July 1994, 59-66.
- [Greene95]
- N. Greene, "Hierarchical Rendering of Complex Environments" PhD Thesis, Univ. of California at Santa Cruz, ReportNo. UCSC-CRL-95-27, June 1995.
- [Greene96]
- N. Greene, "Naked Empire" ACM Siggraph Video Re-view Issue 115: The Siggraph `96 Electronic Theater, August 1996.
- [Haeberli-Akeley90]
- P. Haeberli and K. Akeley, "The AccumulationBuffer: Hardware Support for High-Quality Rendering", Aug. 1990, 309-318.
- [Kaufman86]
- A. Kaufman, "3D Scan Conversion Algorithms forVoxel-Based Graphics", Oct. 1986, 45-75.
- [Meagher82]
- D. Meagher, "The Octree Encoding Method for Efficient Solid Modeling" PhD Thesis, Electrical Engineering Dept., Rensselaer Polytechnic Institute, Troy, New York, Aug. 1982.
- [Naylor92a]
- B. Naylor, "Interactive Solid Geometry Via PartitioningTrees", May 1992, 11-18.
- [Naylor92b]
- B. Naylor, "Partitioning Tree Image Representation andGeneration from 3D Geometric Models", May 1992, 201-212.
- [Rogers85]
- D. Rogers, Procedural Elements for Computer Graphics, McGraw-Hill, New York, 1985.
- [Sabella-Wozny83]
- P. Sabella and M. Wozny, "Toward Fast Color-Shaded Images of CAD/CAM Geometry", 3(8), Nov. 1983, 60-71.
- [Teller92]
- S. Teller, "Visibility Computations in Densely OccludedPolyhedral Environments" PhD Thesis, Univ. of California atBerkeley, Report No. UCB/CSD 92/708, Oct. 1992.
- [Warnock69]
- J. Warnock, "A Hidden Surface Algorithm for Com-puter Generated Halftone Pictures" PhD Thesis, ComputerScience Dept., University of Utah, TR 4-15, June 1969.


