NVIDIA GeForce4 Ti 4400 и GeForce4 Ti 4600 (NV25)
или "Опять двадцать пять"
Результаты тестов
2D-графика
Традиционно начнем с 2D. С большим удовольствием отметим, что никаких замечаний к обеим картам в этом отношении нет. Качество изображения замечательное (разумеется, при наличии высококачественного монитора). Работать можно с прекрасным комфортом в разрешении 1600х1200 при 85Гц. Мне кажется, что качество Matrox G400/G450 в этом отношении достигнуто.
Подчеркну, что оценка 2D-качества есть вещь субъективная, не подвластная никаким измерительным инструментам, также она сильно зависит от конкретной карты и даже от связки карта-монитор. Поэтому никто и никогда не сможет дать подобную общую оценку для всей серии или марки видеокарт.
3D-графика, MS DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипов мы использовали модифицированные (для большего удобства и контроля) примеры из последней версии DirectX SDK (8.1, релиз). Без лишних преамбул перейдем к уже хорошо знакомым нашим постоянным читателям тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности ускорителя по
треугольникам. Для этого используется несколько одновременно выводимых в небольшом окне моделей,
каждая из которых состоит из 50 тысяч треугольников. Текстурирование отсутствует. Размеры моделей
минимальны — каждый треугольник не превышает одного пиксела. Хочется сразу отметить, что результат
этого теста, разумеется, останется недостижим для реальных приложений, где размеры треугольников
значительны, присутствуют текстуры и освещение. Приведем результаты этого теста для трех методов
отрисовки — оптимизированной для оптимальной скорости вывода (в том числе с учетом размера внутреннего
кеша вершин на чипе) модели — Optimized, неоптимизированной исходной модели — Unoptimized и той-же
неоптимизированной модели, выводимой в виде одного Triangle Strip — Strip:
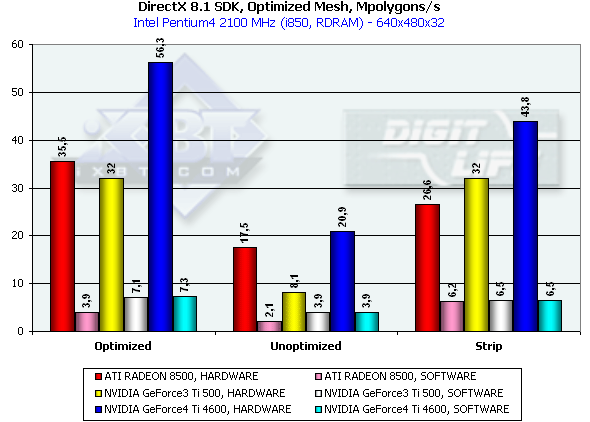
В случае полностью оптимизированной модели, когда влияние подсистемы памяти минимально, мы измеряем практически чистую производительность трансформации и установки треугольников. Налицо безоговорочное, лидерство Ti 4600 на базе NV25. 56 миллионов треугольников в секунду — цифра нешуточная, практически вдвое превосходит результаты RADEON 8500 и Ti 500. Что ж, именно так и должен был отразится на производительности второй блок T&L. В случае неоптимизированной модели, мы имеем дело скорее с эффективностью кеширования и пропускной полосой памяти. Но и здесь NV25 "на высоте", пропорциональной разнице частот между R 8500 и Ti 4600. Кроме того, очевидна существенная "работа над ошибками", проделанная по сравнению с более чем вдвое (!) менее эффективной в этом тесте NV20. В случае Strip-а из треугольников R200 чувствует себя хуже всего, а NV25, как и положено, заметно преумножает преимущество NV20, вновь на сравнимую с разницей частот величину. Итак, в этом тесте NV25 выступает безусловным лидером.
Кроме того, отметим существенное преимущество NV20 и NV25 в случае принудительной активации программного расчета геометрии. Причина этого явления кроется во взаимодействии процессора и ускорителя при передаче рассчитанных процессором данных — чипы NVIDIA получили значительное преимущество благодаря FastWrites механизму, позволяющему напрямую передавать геометрические данные из процессора в ускоритель, минуя системную память. В случае Strip модели это преимущество нивелируется из-за существенного (вдвое) снижения объема передаваемых данных.
Производительность блока вершинного шейдера
Этот тест позволяет определить предельную производительность блока вершинных шейдеров. Выполняется
достаточно сложный шейдер, вычисляющий как видовые преобразования, так и геометрические функции. Тест
проводится в минимальном разрешении, дабы минимизировать влияние закраски. Z-буфер отключен, так что HSR
также не может влиять на результаты:
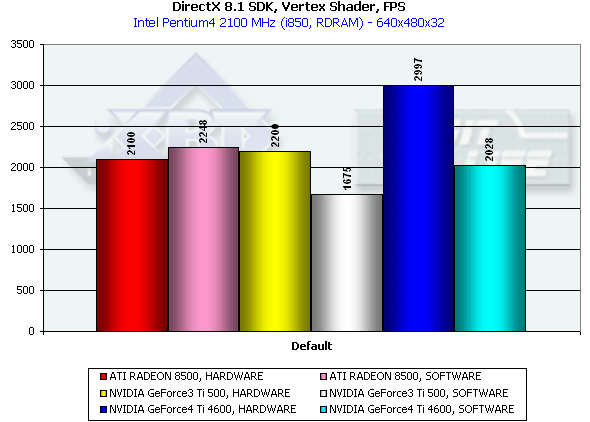
И вновь налицо существенное преимущество "двойного" T&L NV25. Более того, впервые мы наблюдаем картину, когда один из самых производительных (на момент анонса ускорителя) CPU заметно проигрывает по скорости обработки геометрических данных. Кроме того, мы можем сделать косвенный вывод о небольшом повышении у NV25 эффективности передачи рассчитанной программно геометрии (по сравнению с NV20) — благо драйверы для обоих чипов использовались совершенно одинаковые.
Интересно, что со времени прошлого большого обзора R200 скорость выполнения им вершинных шейдеров выросла более чем вдвое. При этом она подозрительно сравнялась со скоростью программной эмуляции, и в том обзоре мы уже наблюдали подобный скачок у NV20. На этот раз мы вновь решили проверить, не исполняются ли шейдеры R200 программно, и для этого понизили тактовую частоту процессора до 1 ГГц. Результаты (HARDWARE 1860, SOFTWARE 1470) свидетельствуют скорее в пользу истинно аппаратного исполнения. Что ж, ATI тоже не лыком шиты, и вполне успешно выжали из чипа новые соки за счет оптимизации драйверов (вероятно, в первую очередь компилятора шейдеров в микрокод).
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали
блендинг с использованием двух матриц как в жестком "аппаратном" варианте, так и с
использованием вершинного шейдера, выполняющего ту же функцию. Кроме того, мы, как обычно, "подстраховались"
результатами, полученными в режиме програмной эмуляции T&L:
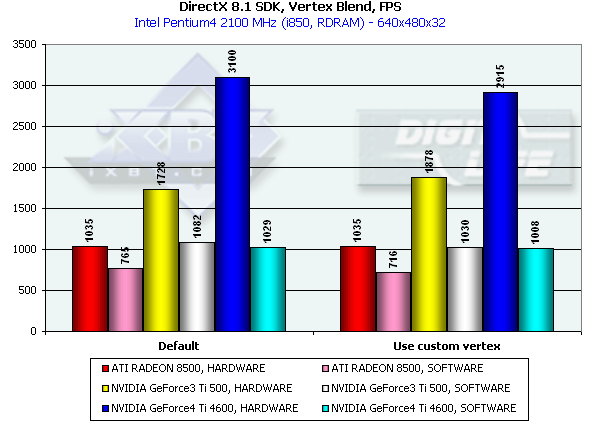
На сей раз, программная эмуляция везде проигрывает аппаратному исполнению, упираясь, судя по всему, (обратите внимание на похожести результатов с шейдером и без) в скорость передачи геометрии по AGP. Где, как уже было отмечено, продукты NVIDIA обладают некоторым преимуществом благодаря FastWrites. В случае аппаратного исполнения, на сей раз (по сравнению с прошлым большим тестом R200) шейдеры сравнялись с полностью аппаратным блендингом, который, таким образом, ввиду своей ограниченной гибкости, полностью потерял смысл на современных чипах. Интересно, что жесткий аппаратный блендинг на NV20 чуть медленнее, а на NV25 чуть быстрее шейдерного, но отличия крайне малы, что вполне естественно, учитывая отсутствие у NV20 и NV25 фиксированного T&L. Фактически, его роль играет специальный шейдерный микрокод, и равенство результатов предстает перед нами в новом свете — как признак того, что оптимизация компилируемых драйвером шейдеров близка к оптимуму.
EMBM рельеф
В этом тесте мы измеряем производительность, а точнее ее падение, возникающее при использовании наложения
карт отражения (Environment) и рельефа на основе карт отражения (EMBM — Environment Bump). Для
тестирования использовалось разрешение 1280*1024 — т.к. именно в нем различия между картами и разными
режимами текстурирования выражено наиболее резко:
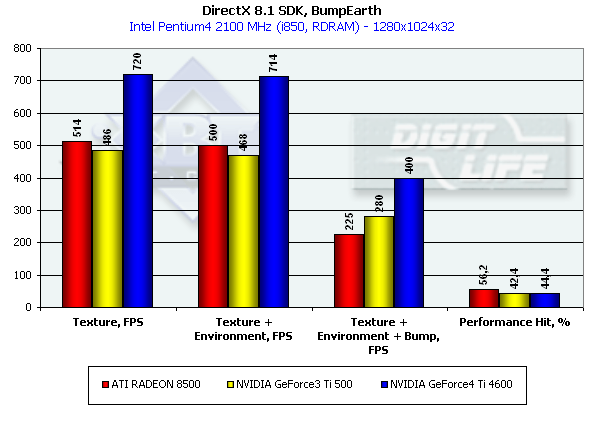
Ti 4600 вновь занимает четкую лидирующую позицию, заметно опережая остальные карты по эффективной скорости закраски во всех трех режимах. Сильнее всего EMBM бьет по R200, однако, сама по себе разница в падении не столь существенна, сколь низка эффективность любой (даже без EMBM) закраски на R200. Чипы NVIDIA красят гораздо эффективнее, особенно при пересчете на единицу тактовой частоты — 240 МГц NV20 практически сравнялась с 275 МГц R200.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив
производительность карт в высоком разрешении при выполнении 5 различных
по сложности шейдеров, для билинейно фильтрованных текстур:
Ti 4600 на коне, и характер зависимости от сложности шейдера и числа текстур полностью повторяет предыдущий чип (NV20). А вот R200 демонстрирует печальную слабость, существенно сдавая на сложных заданиях. Повторное использование текстурных блоков стоит ему гораздо дороже, нежели творениям NVIDIA.
Итак, подведем первый промежуточный итог. По сумме тестов DX 8.1 SDK карта NVIDIA GeForce4 Ti 4600 выходит очевидным, четким победителем. Что, впрочем, от нее и ожидалось — удивительно, если бы разница в полгода не сказалась именно таким образом. Однако не будем забывать, что только результаты реальных приложений позволят нам судить об общей сбалансированности этого чипа. Оставайтесь с нами.
3D-графика, VillageMark (Тестирование эффективности HSR)
Для того, чтобы оценить эффективность реализации HSR, мы использовали тест с большим уровнем
OverDraw — VillageMark v.1.17. Приводим результаты обеих карт со включенным и
отключенным HSR:
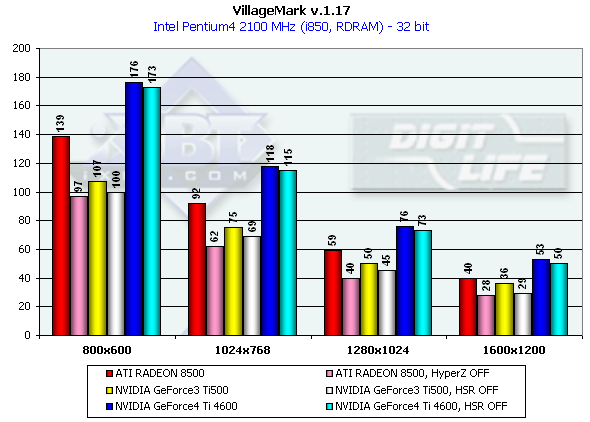
Кроме очевидного преимущества NV25, особенно ярко выраженного в разрешении 1280х1024, в глаза бросается интересный факт — падение производительности при отключенном HSR для NV25 и NV20 очень мало. Особенно по сравнению с R200. Говорит ли это о более низкой эффективности HSR? Нет, и вот почему. Если в случае R200 мы отключаем весь HyperZ, т.е. целый комплекс оптимизаций на основе иерархического представления Z буфера (в том числе, HSR, сжатие Z, быстрая очистка Z), то в случае NVIDIA, как выяснилось при более детальном анализе, нам удалось выключить только сжатие Z, а сам HSR (Z-Cull) в драйверах 27.ХХ на данный момент включен по умолчанию и активируется вне зависимости от состояния ключей в реестре. Как бы там ни было — общая эффективность NV25 в сценах с высоким overdraw налицо.
Следует отметить, что сцена в этом тесте выводится не в порядке глубины, а просто "как есть", и поэтому HSR нетайловых чипов, наиболее эффективно справляющийся с выводимыми по мере удаления сценами, не получает на этом тесте эффекта, сравнимого с полностью тайловыми архитектурами, которые аппаратно сортируют сцену по мере ее вывода. Но, т.к. большинство реальных приложений изначально выводит сцены не сортируя полигоны, мы считаем этот тест вполне правомерным.
3D-графика, предварительный тест на основе iXBT/Digit-Life RightMark Video Analyser
В данный момент мы разрабатываем тестовый пакет, исходные тексты которого будут доступны всем желающим (OpenSource). Мы создали небольшой предварительный тест на основе одной сцены и движка, который ляжет в основу этого пакета. Отличительными особенностями этого теста является большая сложность геометрии (более 150000 полигонов в кадре) и широкое использование возможностей DirectX 8.1. Все освещение базируется на вершинных шейдерах, закраска — на пиксельных, практически повсеместно используются карты среды и рельефа, т.е. накладывается до 4 текстур на точку. Кроме того, в этом примере рассчитывались в реальном времени тени от предметов с использованием Shadow Buffer технологии. Положительной особенностью теста является низкая зависимость от процессора — большинство процессорного времени он проводит в Direct3D и драйверах, в ожидании ускорителя.
Приведем несколько скриншотов:



И результаты теста:
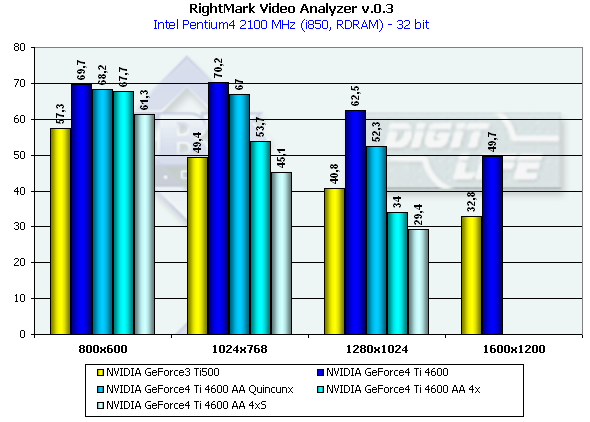
Как мы видим, тест не сильно зависит от разрешения, ввиду очень высокой сложности сцен и большой
нагрузки на геометрическую часть ускорителя. Впрочем, при включении AA, очень благодатно влияющего
на визуальное качество сцен с большим количеством мелких полигонов, мы, наконец, начинаем чувствовать
влияние разрешений. Более того, мы думаем, что в скором будущем акценты всех приложений сместятся
в сторону геометрической сложности сцен, и разрешение уже не будет играть такой роли — мощность
ускорителя будет достаточна для закраски любых разрешений, а рост будет направлен в основном в
область реализма (гибкости) и все более возрастающей сложности геометрии. Интересно, что вновь именно
в разрешении 1280*1024 отрыв NV25 от NV20 наиболее существенен — карта словно проектировалась в
расчете на это разрешение. И возросшая пропускная способность памяти, и ее удвоенный объем сильнее
всего сыграли на руку NV25 в этом режиме. Учитывая все большее распространение 17 и 18 дюймовых ЖК,
для которых этот режим является родным, мы можем только приветствовать этот факт.
| 6 февраля 2002 г. |

|
| Дополнительно |
|





