Intel Parallel Studio – инструмент для создания параллельных приложений
Введение
Компания Intel, являясь одним из лидеров в индустрии параллельных вычислений, расширяет свой многолетний опыт создания программных инструментов в сторону клиентских приложений для персональных компьютеров. Практика переноса или «конверсии» технологий из области научных исследований и высокопроизводительных вычислений в масс-маркет всегда приносила хорошие результаты. И сейчас наступает время, когда разработчикам клиентских Windows-приложений понадобятся мощные и удобные инструменты для адаптации существующих или написания новых приложений, максимально использующих производительность пользовательских систем на базе мультиядерных процессоров. Мы решили назвать эту эко-систему мэйнстримом (mainstream), в которой используются требовательные к производительности приложения для десктопов и мобильных систем, написанные под Windows на языке С или C++. Понятно, что часто графический интерфес приложений написан с использованием Java или .Net и managed-языков. Однако мы верим, что в большинстве случаев те части приложений, которые требовательны к производительности (решатели, фильтры, кодеки, и т.д.), реализованы именно на С/С++, и именно в них важно добиться задействования всех возможностей микропроцессора.
Очевидно, что фактическим стандартным набором разработчика мэйнстрим-приложений является Microsoft Visual Studio. Нисколько не умаляя качеств этого продукта, Intel предлагает расширить возможности Visual Studio для того, чтобы облегчить и оптимизировать цикл разработки масштабируемых параллельных программ для Windows. Сейчас уже нет сомнений, что дальнейшее увеличение производительности приложений будет достигаться за счет того, насколько хорошо эти приложения распараллелены и как хорошо они масштабируются с ростом процессоров в системе. Идеальная программа будет автоматически использовать всю мощь новых процессоров, выпускаемых в ближайшие годы, за счет вовлечения в работу большего количества ядер, число которых на кристалле постоянно растет с каждым поколением микроархитектуры чипов.
Intel Parallel Studio – это набор из нескольких инструментов, который является гармоничным продолжением или расширением Microsoft Visual Studio, и позволяющий за счет удобства использования, понятного интерфейса и оригинальных технологий добиваться хорошей эффективности параллельных програм на мультиядерных системах. Несмотря на то, что этот набор является plug-in’ом к Visual Studio, он полностью покрывает все этапы разработки приложения программистом, от создания скелета будущей параллельной программы до оптимизации релизной версии проекта. В состав этого набора входят четыре отдельных продукта, каждый их которых используется в своем сегменте цикла разработки, и каждый может быть проинсталлирован и интегрирован в Visual Studio как по-отдельности, так и всем пакетом сразу.
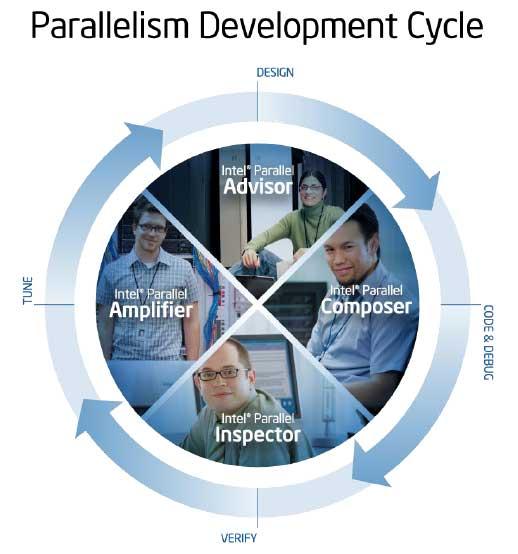
В состав пакета входят:
- Intel Parallel Advisor: поможет найти возможности распараллеливания кода с самого начала разработки приложения**
- Intel Parallel Composer: предназначен для генерирования параллельного кода, т.е. создания программ с помощью компилятора и широкого набора библиотек для многопоточных алгоритмов
- Intel Parallel Inspector: проверит ваше параллельное приложение на корректность и найдет ошибки работы с памятью
- Intel Parallel Amplifier: обнаружит «узкие места» в программе, которые мешают масштабируемости и увеличению производительности на мультиядерных платформах.
**В настоящее время Intel Parallel Advisor доступен только в виде альфа-версии на сайте исследовательских проектов*** и не входит в состав инсталляционного пакета.
Так как цикл разработки может быть непрерывен и повторяем в смысле возврата к коррекции дизайна после любого этапа, вплоть до оптимизации производительности, важно, чтобы все эти инструменты слаженно работали в одной среде и могли взаимодействовать друг с другом. Именно поэтому они глубоко интегрированы в среду Microsoft Visual Studio, и вам уже не придется запускать отдельные профилировщики и создавать отдельные эксперименты, когда нужно найти потоковые ошибки или оптимизировать программу. Весь функционал доступен в текущем проекте, из тулбаров или меню Visual Studio, а результаты анализа размещаются там же, где и файлы проекта. Хотя пользователь может и сам выбрать, где ему хранить файлы с результатами.
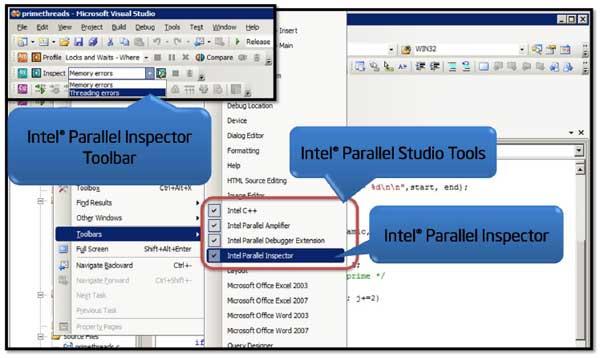
Несмотря на то, что для отображения разультатов анализа приложений используются собственные панели и окна, тесная интеграция с Visual Studio позволяет легко возвращаться в «родной» редактор кода прямо в ту функцию или на ту строку, которая анализируется в данный момент, чтобы продолжить редактирование программы.
Сложно описать, насколько интрументы «вросли» в среду Visual Studio, и как они взаимодействуют с ней. Проще попробовать своими руками «на ощупь» и почувствовать, что весь их функционал как бы является естественным продолжением Visual Studio и расширением ее возможностей, которых раньше недоставало для разработки хороших параллельных программ.
Intel Parallel Advisor
Существуют два похода к написанию параллельных програм. Первый - это распараллеливание, частичное или полностью, уже готовых последовательных приложений для ускорения работы некоторых достаточно изолированных участков, часто алгоритмов, которые не затрагивают всю архитектуру проекта. Здесь методологии как таковой не существует. Разработчик просто анализирует приложение и определяет участки программы, которые потребляют максимальное количество ресурсов микропроцессора. Затем анализируется структура проекта и принимается решение о модификации того или иного алгоритма. Второй подход предполагает изначальный дизайн с учетом требований параллельного выполнения нагрузки. И если концептуально проект можно разделить на участки, которые должны выполняться одновременно, то начать его реализацию в виде программы часто является сложной задачей для новичков. Особенно трудно написать проект так, чтобы потом не пришлось прибегать к первому подходу.
Здесь на помощь придет Parallel Advisor. Это совершенно новая категория или новый класс инструментов, который несет в себе некую методологию создания параллельных программ «с нуля» с использованием правильных подходов к их реализации, в том числе с использованием параллельных библиотек производительности. Понятно, что не каждая программа или алгоритм легко и просто параллелятся. Advisor найдет, из-за чего именно параллельная реализация может оказаться неэффективной, и попытается выдать нужные решения. Кроме того, все знания по применению параллельных библиотек будут собраны здесь в виде сэмплов и шаблонов, для того чтобы максимально облегчить начальный этап их использования. Однако и в случае с распараллеливанием готовой последовательной программы Advisor предоставит «путеводную нить», или workflow, по распараллеливанию, проверке корректности и оптимизации приложения, если разработчик пока еще не в силах «уложить» в голове эту методологию. Но через какое-то время работы с проектом надобность в Advisor’е отпадает, так как становятся понятными принципы разработки параллельной программы, а элементы методологии рассматриваются как дополнительный Help Page ресурс.
В текущем пакете Advisor не присутствует, зато его первая реализация в виде утилиты Intel Parallel Advisor Ligt доступна среди других исследовательских проектов на сайте Intel. Это сделано для того, чтобы сообщество разработчиков могло поделиться своими идеями относительно методологий распараллеливания, которые могут быть потом реализованы в будущем продукте. Такой же путь уже прошли хорошо известные теперь параллельная библиотека TBB и инструмент Performance Tuning Utility, которые стали частью Intel Parallel Studio, возвращая разработчикам их идеи в виде open source библиотеки для разработки на С++ и совершенно нового продукта для оптимизации производительности.
Intel Parallel Composer
Несмотря на некий маркетинговый акцент в названии продукта Composer – это не просто компилятор С++ от Intel. Он уже проинтегрирован в Visual Studio вместе с библиотекой производительности IPP и параллельной библиотекой TBB, что значительно облегчает процесс разработки параллельного кода для новичков, т.е. тех, кто еще не пользовался продуктами Intel, такими, например, как Compiler Pro, и только собирается попробовать улучшить производительность своих приложений с помощью технологий Intel.
Наличие сразу нескольких компонент в пакете позволит сразу же начать оптимизировать свою программу с использованием параллельных технологий, которые содержит Composer:
- Вычислительные примитивы, реализованные в виде функций в библиотеке IPP, гарантируют высокую производительность алгоритмов на платформах Intel;
- Поддержка новой версии стандарта OpenMP 3.0 позволит использовать multitasking, недоступный в предыдущих версиях, которые поддерживаются в том числе и компилятором Microsoft;
- Новый тип данных Valarray немного упростит код, реализующий векторные операции, а компилятор сгенерирует эффективный бинарный код, задействующий SIMD-инструкции для увеличения производительности;
- Поддержка компилятором элементов стандарта С++ 0х облегчит кодирование программистам.
// Пример функцию поэлементного сложения массивовFoo( float *a, float *b, float *c, int n ) { for( int i=0; i// Используйте Intel IPP напрямую// для математических и трансцендентных операций_ippsAdd_32f ( float *a, float *b, float *c, int n )// Новый Valarray подходит для множества// параллельных алгоритмовvalarray<float> Vb(b,n),Vc(c,n);valarray<float> Va = Vb + Vc
Применение Valarray и Intel Integrated Performance Primitives
На последнем пункте остановимся поподробнее. Наверняка уже многие посмотрели на документацию библиотеки TBB или даже успели ее попробовать использовать хотя бы в «Hello, World!» приложениях. Наверное, многие отметили некоторую громоздкость ее конструкций для реализации параллельных функций. Так вот, использовать параллельные алгоритмы TBB и шаблоны С++ стало проще, так как теперь компилятор поддерживает стандартные Lambda-функции, позволяющие реализовывать объект-функтор прямо в списке аргументов функции. В нижеследующем примере Lambda-функция позволяет избегать создания отдельного класса, реализующего параллельный регион, что особенно удобно, когда такая функция нужна только один раз в программе, и переиспользовать ее не нужно.
// Класс, параллельный регион, реализующий функцию// поэлементного сложения массивовclass ApplyABC {public: float *a; float *b; float *c; ApplyABC(float *a_,float *b_,float *c_):a(a_), b(b_), c(c_) {} void operator()(const blocked_range& r) const { for(size_t i=r.begin(); i!=r.end(); ++i) a[i] = b[i] + c[i]; }};// Функция, вызывающая алгоритм parallel_forvoid ParallelFoo( float *a, float *b, float *c, int n ) { parallel_for(blocked_range(0,n,10000),ApplyABC(a,b,c) );// Вызов алгоритма parallel_for уже содержит реализацию// поэлементного сложения массивов в списке аргументовvoid ParallelApplyFoo(size_t n, int x) { parallel_for( blocked_range(0,n,1000), [&]( const blocked_range& r ) -> void { for( size_t i=r.begin(); i!=r.end(); ++i ) a[i] = b[i] + c[i]; });}
Lambda-функции ( C++ 0X стандарт) упрощают программирование c шаблонами C++ и использование TBB
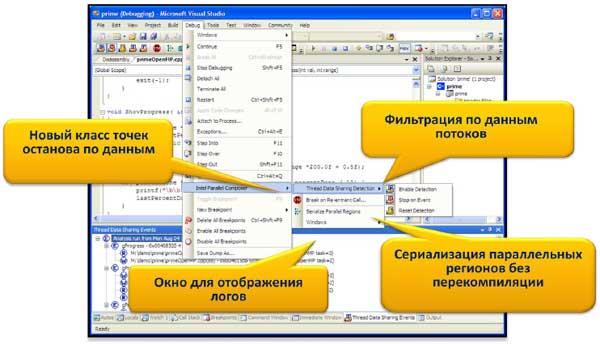
Ну и наконец, новая «фича», пока недоступная даже в Intel Compiler Pro – это встроенный параллельный отладчик PDE (Parallel Debugging Extention). Он является расширением к отладчику Microsoft и позволяет анализировать данные, разделяемые между потоками OpenMP, акцентируя внимание на конфликтах доступа и возможных проблемах с корректностью параллельных вычислений. PDE вводит новый тип точек останова по событиям, которыми, например, являются конкурентный доступ потоков к переменным или вход потоками в одну и ту же функцию. Подобной информации может быть собрано очень много, поэтому богатый набор фильтров позволяет отсеять неинтересующие нас события и сконцентрироваться на проблемных местах.
Для того, чтобы быстро определить насколько корректны результаты вычислений, выполняемых в параллельном регионе, мы можем в отладчике выполнить любой регион последовательно, и сравнить потом результаты. Причем перекомпилировать ни приложение, ни исследуемый модуль для этого не требуется.
Intel Parallel Inspector
Это, пожалуй, самый востребованный и ожидаемый инструмент на сегодняшний день, так как он помогает избавиться от ошибок в многопоточной программе на этапе верификации, повышая корректность и стабильность ее исполнения. Несмотря на свой характерный функционал Inspector применяется не только командами тестировщиков (QA team). Нормальная инженерная практика предполагает проверку программы на наличие ошибок и самим разработчиком, хотя бы на уровне юнит-тестов (unit tests).
Давайте разберем, какие же ошибки помогает обнаружить Parallel Inspector. Инструмент адресует два класса ошибок: ошибки многопоточности и ошибки работы с памятью, причем анализ для каждого класса запускается отдельно. Последний класс ошибок хорошо известен программистам, которые до последнего времени использовали различные инструменты, чтобы найти утечки памяти, нарушение целостности стека или доступ по несуществующим адресам. Второй класс ошибок связан с многопоточной природой програм. Они неизбежно возникают при разработке параллельных приложений, и их чрезвычайно сложно отловить, особенно если они проявляются нерегулярно и только при совпадении определенных условий.
Ошибки работы с памятью
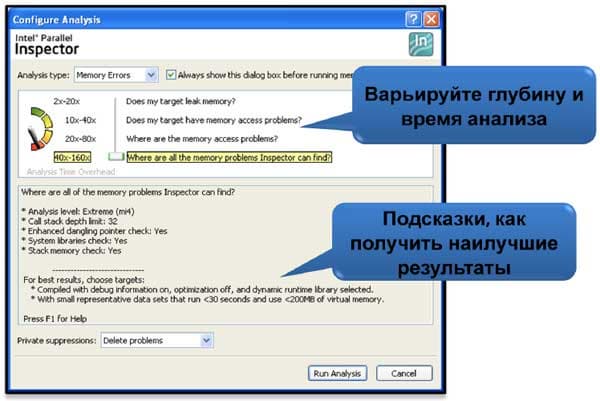
Механизм обнаружения ошибок памяти основан на анализе абсолютно всех инструкций чтения/записи и их адресов на уровне бинарного кода с помощью бинарной инструментации. В основе инструментации лежит утилита Pin - A Dynamic Binary Instrumentation Tool, которая внедряется в исследуемый процесс во время его запуска и позволяет отслеживать выполнение практически любых инструкций, предоставляет API доступа к содержимому регистров, контекста выполнения программы, символьной и отладочной информации. Понятно, что всесторонний анализ исполняемого кода не может быть проведен без существенных накладных расходов, поэтому он разделен на уровни, отражающие глубину и сложность анализа. Чемы выше уровень, тем больше потребуется времени для проверки приложения.
- Уровень mi1 – позволяет обнаруживать только утечки памяти, выделенной в куче (heap). Глубина стека функций равна 7, что даст достаточно информации для определения местонахождения ошибки и структуры вызовов функций, выделявших память.
- Уровень mi2 – позволяет обнаруживать все остальные ошибки работы с памятью в куче, которые мы рассмотрим ниже. Однако для снижения накладных расходов и ускорения анализа глубина стека выбрана равной единице. То есть на этом уровне мы сможем найти ответ на вопрос, есть ли в принципе ошибки в программе. А где эти ошибки, нам поможет определить следующий уровень.
- Уровень mi3 – отличается от предыдущего тем, что глубина стека увеличена до 12-ти. Плюс добавлен функционал поиска утерянных указателей. На этом уровне мы получаем наиболее полный анализ корректности работы с памятью в куче, но заплатим за это накладными расходами, которые увеличат время выполнения программы от 20 до 80 раз по сравнению с оригиналом.
- Уровень mi4 – высший уровень, дополнен анализом ошибок доступа к памяти, выделенной на стеке, которые не обнаружены на стадии компиляции или с помощью run-time check опций компилятора. Уровень вложенности функций – 32. Как и все остальные уровни, 4-й является инклюзивным, то есть включающим в себя все виды анализа на предыдущих уровнях. Соответственно, накладные расходы будут максимальными.
Глубина стека на каждом уровне выбрана эмпирически и является компромиссом между полнотой предоставляемой информации и величиной накладных расходов на анализ приложения. В данной версии продукта пользователь не может менять глубину стека.
В зависимости от выбранного уровня анализа, Parallel Inspector способен обнаруживать следующие виды ошибок работы с памятью:
- Memory Leak – возникают при выделении программой памяти в куче и неосвобождении ее по окончании программы;
- Invalid Memory Access – возникают при чтении/записи по недействительным адресам памяти, в куче или в стеке;
- Invalid Partial Memory Access - возникают при чтении/записи по частично недействительным адресам памяти;
- Missing Allocation – возникают при попытке освободить память по несуществующему адресу;
- Mismatched Allocation/Deallocation – возникают при попытке освободить память с помошью функций, не соответствующих функции выделения памяти;
- Uninitialized Memory Access – возникают при попытке чтения неинициализированной памяти, в куче или в стеке;
- Uninitialized Partial Memory Access – в возникают при попытке чтения частично неинициализированной памяти.
Приведем лишь несколько простых примеров, для иллюстрации ошибок памяти.
// Запись по недействительному адресу// освобожденной памятиchar *pStr = (char*) malloc(20);free(pStr);strcpy(pStr, "my string"); // Ошибка!// Попытка чтения неинициализированной памятиchar* pStr = (char*) malloc(20);char c = pStr[0]; // Ошибка!// Функция освобождения памяти// не соответствует функции выделенияchar *s = (char*)malloc(5);delete s; // Ошибка!// Выход за пределы стекаvoid stackUnderrun(){char array[10];strcpy(array, "my string");int len = strlen(array);while (array[len] != `Z`) // Ошибка! len--;}
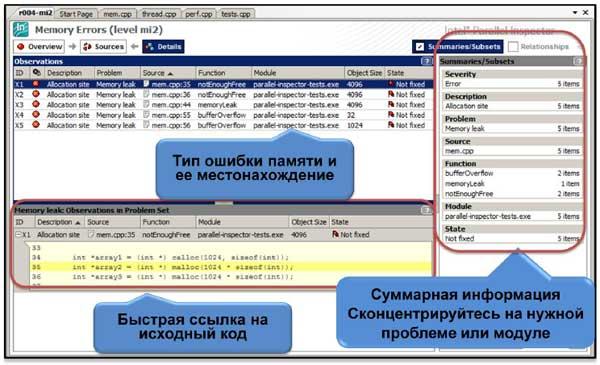
По окончании анализа приложения нам предоставляется лог событий или ошибок, которые были выявлены. Причем на всех уровнях, кроме mi1, мы можен начать анализировать логи еще до окончания анализа, так как результаты уже будут доступны.
Результаты структурированы таким образом, чтобы вначале у нас был обзор списка проблем, от которых потом можно перейти к деталям или в окно анализа исходного кода. В списке с найденными ошибками нам доступна вся информация относительно процесса, модуля и функции, в которой эта ошибка произошла. При значительном списке ошибок в случае достаточно большого проекта, удобно воспользоваться функционалом фильтрации по типу ошибки, по имени исходника, по имени функции или модуля. Исходный код сопровождается стеком вызовов функций. Для редактирования программы достаточно двойного щелчка мышки на строке кода, и мы попадаем в редактор Visual Studio.
Ошибки многопоточности
Наиболее распространенные ошибки многопоточности - это «гонки» (Data Races), или конкурирующий доступ потоков к разделяемым данным, и взаимоблокировки (Deadlocks), когда, захватив неправильно расставленные объекты синхронизации, потоки самозаблокировались и не могут продолжить свое выполнение. Простейший пример ошибки, которая рано или поздно приведет к «зависанию» программы, представлена в примере ниже.
// Поток A захватывает критическую секцию L1,// затем ожидает критическую секцию L2DWORD WINAPI threadA(LPVOID arg){ EnterCriticalSection(&L1); EnterCriticalSection(&L2); processA(data1, data2); LeaveCriticalSection(&L2); LeaveCriticalSection(&L1); return(0);}// Поток В захватывает критическую секцию L2,// затем ожидает секцию L1DWORD WINAPI threadB(LPVOID arg){ EnterCriticalSection(&L2); EnterCriticalSection(&L1); processB(data2, data1); LeaveCriticalSection(&L1); LeaveCriticalSection(&L2); return(0);}
Пример блокирующей иерархии объектов синхронизации
Коварство ошибок многопоточности заключается в том, что при отладке или тестировании приложения они могут и не проявляться. Но стоит измениться некоторым временным параметрам, например, запустить приложение на системе с другой тактовой частотой процессора, то они тут же себя обнаруживают. Особенно болезненной для производителя софта является ситуация, когда оттестированное вдоль и поперек в своей лаборатории приложение, иногда «падает» на системе заказчика, и отладиться удаленно нет никакой возможности.
Для Inspecrtor’а не имеет никакого значения, произошла ошибка во время исполнения анализируемого приложения или нет. Он инструментирует все инструкции потоковых API, вызовов функций синхронизации и обращения к разделяемым между потоками объектам, на уровне бинарного кода. Затем производятся анализ исполняемого пути приложения и выявление даже гипотетической возможности одновременного доступа потоками к незащищенным данным. Вот почему важно чтобы были пройдены все критические пути исполнения кода приложения, то есть тест должен обладать свойством полноты.
Те, кто уже знаком с инструментами многопоточного анализа Intel, наверняка обнаружат сходство с Thread Cheker. Действительно, в чем-то интерфейс был позаимствован оттуда, однако он значительно расширен, а механизм обнаружения ошибок и инструментирования, который лежит в основе Inspector’а, уже совершенно другой. Тем не менее, технология бинарного инструментирования несет с собой значительные накладные расходы на выполнение приложения. Поэтому оно будет исполняться дольше, чем его оригинал. Это неизбежная реальность. В связи с этим пользователю предоставлена возможность управления интрузивностью анализа. Для этого перед началом анализа он выбирает один из четырех уровней анализа, в зависимости от его глубины.
- Уровень ti1 – позволяет обнаруживать взаимные блокировки потоков. Глубина стека функций равна единице;
- Уровень ti2 – дополнительно позволяет обнаруживать конкуренцию доступа к незащищенным данным, «гонки»;
- Уровень ti3 – отличается от предыдущего тем, что глубина стека увеличена до 12-ти;
- Уровень ti4 – высший уровень, позволяющий определять все типы ошибок многопоточности. Уровень вложенности функций – 32. Как и все остальные уровни, 4-й является инклюзивным, то есть включающим в себя все виды анализа на предыдущих уровнях. Соответственно, накладные расходы будут максимальными.
В дополнение к ошибкам взаимной блокировки Inspector способен обнаруживать следующие ошибки многопоточности:
- Lock Hierarchy Violation – возникает при захвате нескольких объектов синхронизации, состоящих в иерархии или уже захваченных данным потоком. Являются подмножеством ошибки взаимной блокировки, Deadlock;
- Potential Privacy Infringement – возникает при попытке доступа к стековой памяти другого потока.
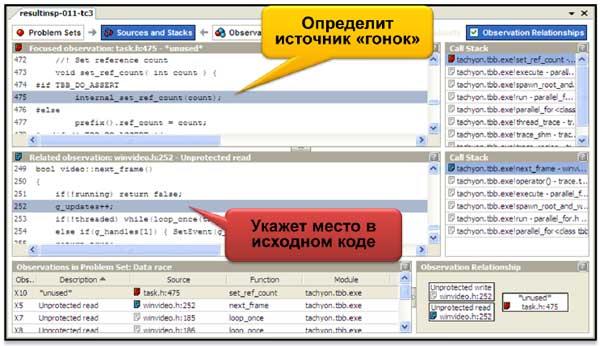
После окончания исполнения приложения Inspector выведет список ошибок и диагностических сообщений о событиях, связанных с существованием потоков в процессе выполнения. Каждому сообщению Inspector сопоставит строку исходного кода, в которой найдена причина того или иного события или ошибки, а также стек вызовов функций и адрес памяти. Так как потоковые ошибки сопряжены с выполнением программы несколькими потоками одновременно, а иногда доступ к незащищенным данным может происходить из разных функций, то для удобства представления и обнаружения причин ошибки Inspector отображает сразу два окна исходного кода с функциями, выполнявшимися разными потоками. Из любого окна очень легко перейти в редактор Visual Studio, для редактирования программы. Для того, чтобы проанализировать приложение, не требуется никаких специальных ключей компиляции. Достаточно просто в режиме Debug запустить инструмент на исполнение.
Intel Parallel Amplifier
Профилировщик производительности предназначен для того, чтобы выяснить, насколько эффективно используется мультипроцессорная платформа приложением, и где находятся те узкие места в программе, которые мешают ей масштабироваться и увеличивать производительность с ростом вычислительных ядер в системе. Методология профилировки приложения предельна проста: необходимо ответить себе на три основных вопроса, каждый из которых соответствует своему типу анализа и отражает суть, место и причины проблем с производительностью.
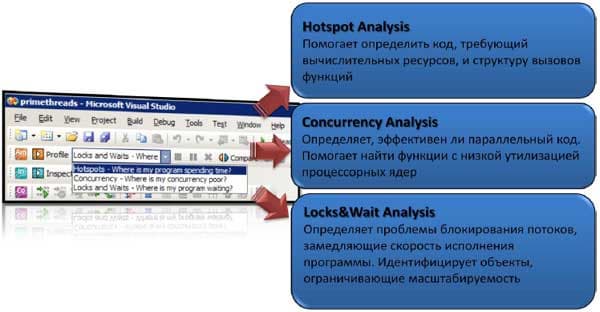
- Hotspot-анализ. «На что моя программа тратит вычислительное время процессора?» Нам необходимо знать те места в программе, Hotspot-функции, где больше всего тратится вычислительных ресурсов при исполнении, а также тот путь, по которому мы в эти места попали, т.е. стэк вызовов.
- Concurrency-анализ. «Почему моя программа плохо параллелится?» Бывает, что независимо от того, насколько продвинута параллельная инфраструктура приложения, ожидаемый прирост производительности при переходе например от 4-ядерной системе к 8-ядерной так и не достигается. Поэтому тут нужна оценка эффективности параллельного кода, которая дала бы представление о том, на сколько полно используются ресурсы микропроцессора.
- Lock & Wait - анализ. «Где моя программа простаивает в ожидании синхронизации или операции ввода-вывода?» Поняв, что наша программа плохо масштабируется, мы хотим найти, где именно и какие именно объекты синхронизации стали на пути к хорошей параллельности. Возможно необходимо пересмотреть реализацию алгоритмов, а может, и все параллельную инфраструктуру приложения.
Каждый из этих видов анализа запускается по отдельности и имеет собственное окно представления результатов. При этом встроенный Source View расширяет возможности обзора результатов относительно исходного кода программы, а Statistical Call Tree, или статистическое дерево вызовов, поможет получить «объемное» представление о путях вызовов Hotspot-функций. Наличие встроенного функционала сравнения результатов позволяет отслеживать влияние изменения кода программы на ее производительность.
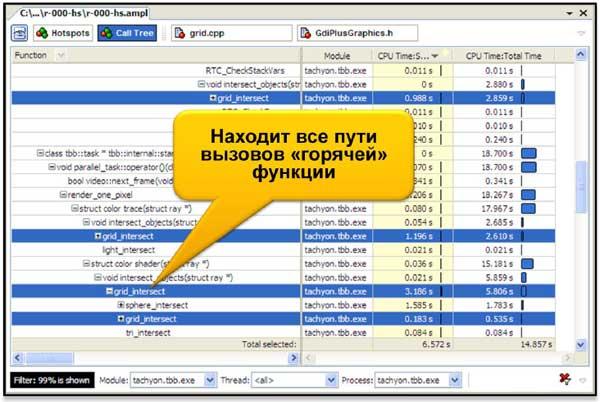
Итак, результатом запуска приложения на Hotspot-анализ будет интегрированное в главное окно Visual Studio окно со списком «горячих» функций, напротив каждой из которых представлена ее временная характеристика как в числовом, так и в графическом представлении. По умолчанию результаты отсортированы так, что самая «горячая» функция оказалась в списке первой. Кроме того имя каждой функции может быть «раскрыто» для представления всех стеков вызовов этой функции. А в окне Stack View можно определить, какой именно путь внес наибольший вклад (в смысле влияния на производительность).
Необходимо отметить, что поиск Hotspot-функций не несет в себе существенных накладных расходов. То есть анализ не влияет на время исполнения анализируемого приложения. Это достигается путем использования технологии временного сэмплирования стеков (Stack Sampling), благодаря которой мы получаем трассу с данными, содержащими статистически значимые временные показатели функций, их стеки, а также контекст исполнения. В постпроцессинге трасса раскрывается в имя функции, потока, модуля и процесса, и выстраиваются список Hotspot-функций и статистическое дерево вызовов.
Естественно, что определив имя интересующей нас Hotspot-функции, мы бы хотели проанализировать ее исходный код, поняв какие конструкции чрезмерно потребляют время процессора. Двойной клик мышкой на имени функции открывает нам Source View закладку, где затраченное функцией время на исполнение распределено по строкам исходного кода, а самое «горячее» место перемещено в центр окна – это очень удобно, особенно когда листинг функции занимает несколько экранов.
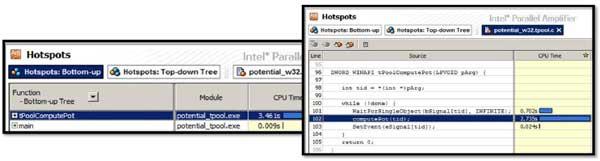
Если мы переключимся на закладку статистического дерева вызовов, то получим Top-Down представление для данной функции, которое помогает определить все пути ее вызовов и критический путь. Важными временными характеристиками функций здесь являются Self-Time, то есть время, затраченное на выполнение самой функцией, и Total-Time, время, затраченное самой функцией и всеми функциями, вызванными из нее (Children Functions). Без такого представления, например, очень трудно определить, каким образом очень часто исполняемые функции (типа memcpy) влияют на производительность, если они попали в список самых «горячих» в Hotspot-листе.
Пожалуй, главной метрикой в результатах Concurrency-анализа является интегральная характеристика параллельности всего приложения, представленная в окне Summary и которая дает нам представление о том, насколько хорошо распараллелено наше приложение в целом. Эта характеристика представлена гистограммой распределения времени исполнения приложения по уровням параллельности (Concurrency Level). Под уровнем параллельности понимают долю времени, в течение которого программа выполнялась в N ядрах процессора. Уровень N=1 означает, что программа выполнялась последовательно, N=2 – в двух потоках, и так далее. В идеальном случае график должен иметь пик на уровне N, равному числу вычислительных ядер в системе, и незначительные показатели на всех остальных уровнях. Другим важным свойством такого предсталения является то, что по графику можно оценить потенциал роста производительности программы, в случае разрешения проблем с масштабируемостью.
В главном окне мы получим список функций, при выполнении которых программа недоиспользовала возможности микропроцессора, и уровень параллельности был низкий. Чем больше времени выполнялась функция в неэффективном с точки зрения производительности режиме, тем выше она в списке. То есть это не список Hotspot-функций, хотя он и может с ним пересекаться. Здесь напротив каждой функции представлена графическая характеристика параллельности программы в виде «градусника», где зеленый цвет обозначает порцию времени исполнения в идеальном для данной системы режиме, а красным – время, в течение которого ресурсы системы недоиспользовались. Если функция вызывалась из нескольких мест, то каждому ее стеку будет аттрибутирована эта характеристика. Есть еще синий цвет, который обозначает время исполнения программы в потоках, количество которых превышает число ядер процессора – переиспользование ресурсов. При незначительном превышении числа потоков идеального количества ничего страшного с производительностью обычно не происходит, так как влияние избыточного количества потоков в очереди системы начинает быть заметным со значительным ростом этого количества.
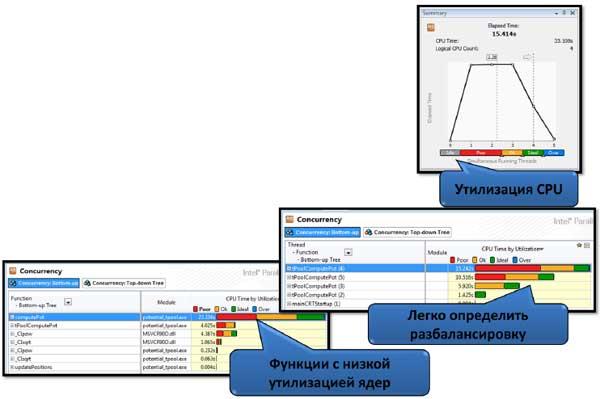
Таким образом, в параллельной программе важно найти не только Hotspot-функции, но и понять, насколько хорошо они распараллелены и нужно ли над ними работать в плане более эффективной балансировки нагрузки или оптимизации объектов синхронизации. Если же Hotspot-функции распараллелены хорошо, то они не окажутся в списке с красной зоной «градусника», и тогда работа по увеличению производительности разделяется на две задачи: оптимизация Hotspot-функций на микроархитектурном уровне и улучшение параллельности тех функций, которые в списке есть и недоиспользуют ресурсы микропроцессора.
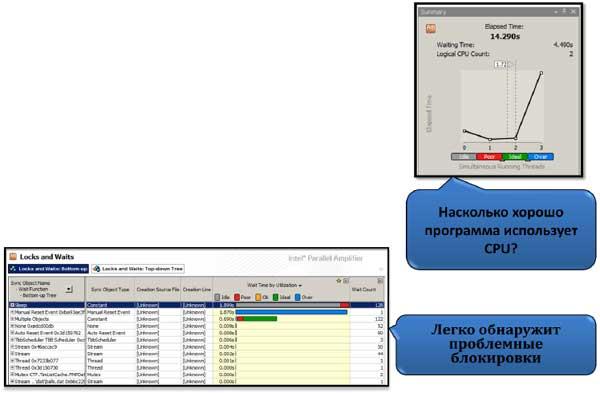
Профилировка приложения с помощью Locks & Waits-анализа поможет нам найти причину, почему не масштабируется приложение, что мешает ему выполняться с большим количеством потоков. В суммарной характеристике появляется метрика заблокированных потоков, то есть порция времени, когда потоки находились в заблокированном состоянии и не нагружали микропроцессор. Главное же окно отображает список функций, исполнение которых было заблокировано в ожидании каких-либо объектов синхронизации. При этом чем больше влияние такой функции на время исполнения программы, тем выше она в списке. Изменяя группировку объектов отображения в списке, мы получим список тех самых объектов синхроницации, которые и являются причиной блокировок. Будь то критическая секция, «накрывающая» большой и часто исполняемый в потоках участок кода, или Wait-функция, ожидающая события достаточно большое количество времени, с этим надо будет что-то делать уже самому программисту. Получив список «виновников» плохой масштабируемости, разработчик уже сам принимает решение, каким образом он изменит реализацию данного алгоритма или всю потоковую инфраструктуру в целом. Важно, что он имеет объективную картину состояния с блокировками в программе и может оценить, сколько необходимо затратить усилий для переписывания софта, и что это в результате даст.
Заключение
Предлагая комплексное решение в виде нового набора инструментов для разработки параллельных програм, Intel ставит своей задачей облегчить старт новичкам и сделать работу более продуктивной для опытных разработчиков на С/С++ под Windows, использующих Microsoft Visual Studio. Разрабатывая эффективные и масштабируемые программы, мы сохраняем инвестиции в будущем за счет автоматического увеличения производительности приложений на будущих многоядерных платформах.
Выпуская Parallel Studio, Intel провела обширную бета-программу, в течение которой значительное количество разработчиков пользовались продуктом и присылали свои отзывы и рекомендации по каналам обратной связи. Все они были учтены и рассмотрены архитекторами проекта, а также был сделан вывод о чрезвычайной важности участия комьюнити в исследовательских проектах, разрабатываемых в Intel. Собственно поэтому важные исследовательские проекты размещены на сайте whatif***. Кроме того, все замечания и пожелания по улучшению продукта можно разместить на ISN форумах, как англоязычном, так и русскоязычном***. Тем более, что для данного продукта это будет основная модель поддержки клиентов.
***
Англоязычный форум http://software.intel.com/en-us/forums/intel-parallel-studio
Русскоязычный форум http://software.intel.com/ru-ru/forums/intel-parallel-studio
Сайт исследовательских проектов Intel http://whatif.intel.com
Комментарии