Введение
Parallel Inspector является одним из четырех инструментов, входящих в состав набора Intel Parallel Studio. Inspector может быть установлен и проинтегрирован в Microsoft Visual Studio как часть набора, так и отдельно. На сегодняшний день — это самый интересный и ожидаемый инструмент в составе пакета, так как он помогает обнаружить ошибки в многопоточной программе, на этапе верификации, повышая корректность и стабильность ее исполнения. Специфичный функционал Inspector’а подразумевает его применение командами тестировщиков (QA team). Однако и сами разработчики включают проверку программы на наличие ошибок, хотя бы на уровне юнит-тестов (unit tests), в свою инженерную практику.
В данной статье мы рассмотрим особенности использования Inspector’а для поиска ошибок доступа к памяти. Инструмент также позволяет находить и ошибки, характерные исключительно для многопоточных программ (dead locks, data races), но эта тема заслуживает отдельной статьи, и мы ее обсудим позже.
Механизмы поиска ошибок
В общем случае механизм обнаружения ошибок памяти основан на структурном анализе всей совокупности актов чтения и записи в память процесса в течение исполнения программы. Такой подход не нов и используется различными «мемори-чекерами», которые применяют так называемую статическую инструментацию для отслеживания инструкций чтения/записи и вызовов функций API работы с памятью. Для этого «измерительный инструмент» (instrumentation engine) модифицирует бинарный код еще до запуска его на исполнение (static binary instrumentation), вставляя определенные инструкции до и сразу после нужной инструкции или функции. Далее, инструментированная программа запускается на исполнение, а при достижении вставок кода сохраняются параметры программы, такие как временная отметка, текущий стек и контекст исполнения. Затем, вся эта масса информации обрабатывается с целью поиска нарушений доступа, некорректного использования, и других ошибок работы с памятью.
В Inspector’е применяется несколько другой подход анализа всех инструкций чтения/записи памяти и их адресов на уровне бинарного кода с помощью динамической бинарной инструментации. В основе инструментатора лежит утилита Pin — Dynamic Binary Instrumentation Tool, которая внедряется в анализируемый процесс непосредственно перед стартом и позволяет отслеживать выполнение практически любых инструкций, предоставляет API доступа к содержимому регистров, контексту выполнения программы, символьной и отладочной информации.
Можно провести некоторую аналогию между Pin и JIT (just-in-time) компилятором. Только на вход «Pin-компилятора» подается не байт-код, а исполняемый бинарный код. Pin перехватывает самую первую инструкцию программы и генерирует свою последовательность инструкций (трассу), совпадающую с первыми оригинальными инструкциями вплоть до первого ветвления программы (или до значения лимита инструкций в трассе), а затем, передает управление этой последовательности. Управление возвращается к Pin при наступлении ветвления, он генерирует новую последовательность инструкций, соответствующую ветке, и снова передает управление. Pin держит весь сгенерированный код в памяти, поэтому и исполнение и ветвление довольно эффективны. Оригинальный код не исполняется, а исполняются только сгенерированные последовательности. При этом пользователю утилиты дается возможность внедрять свой (анализирующий) код куда угодно (инструментация), за исключением разве что модулей ядра операционной системы.
Обе составляющие результирующего кода (инструментированный и анализирующий) «живут» в одном адресном пространстве модуля Pintool, который можно рассматривать как plug-in, позволяющий модифицировать процесс генерирования кода внутри утилиты Pin. Pintool регистрирует функции обратного вызова (callback), которые вызываются Pin каждый раз, когда в профилируемом приложении выполняется определенное условие (выполняется инструкция, вызывается функция, и т.д.). Эти функции ответственны за состав сгенерированной последовательности инструкций, они инспектируют код программы и определяют, есть ли необходимость, и где именно нужно вставить вызовы анализирующего кода в эту последовательность. Этими вызовами можно «накрыть» практически любые функции, исполняемые в приложении. А Pin позаботится о том, чтобы контексты вызовов были сохранены и восстановлены без изменений, чтобы функциям передавались правильные аргументы.
Pintool может иметь еще более низкую гранулярность и инструментировать каждую инструкцию приложения. Для этого Pin предоставляет специальный API, позволяющий селективно инструментировать инструкции определенного типа, например, доступа к памяти или ветвления. Инструкции, специфичные для определенных микроархитектур, тоже могут быть проинструментированы с помощью специального API.
Так как Pintool является плагином, то он исполняется в том же процессе, что Pin и анализируемое приложение. Поэтому ему доступны все данные исполняемого модуля, включая файлы и дескрипторы. Если исполняемый модуль слинкован во время компиляции с динамическими библиотеками, то Pintool имеет доступ и к ним тоже, так как он контролирует выполнение загрузчика библиотек.
Интерфейс
Таким образом, в зависимости от целей и задач анализа, можно сформировать несколько типов Pintool-инструментов, которые бы имели свой уровень гранулярности инструментации и были бы «нацелены» на сбор определенного типа данных в исполняемой программе. Понятно, что всесторонний анализ исполняемого кода не может быть проведен без существенных накладных расходов. Поэтому он разделен на уровни, использующие разные Pintool-инструменты, имеющие разные возможности обнаружения ошибок и отражающие глубину и сложность анализа. Чем выше уровень, тем, как правило, больше потребуется времени для проверки приложения.
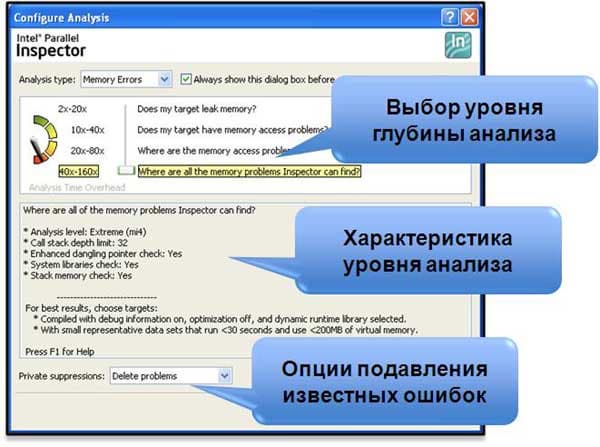
- Уровень mi1 – позволяет обнаруживать только утечки памяти, выделенной в куче (heap). Глубина стека функций равна 7. Это даст достаточно информации для определения местонахождения ошибки и структуры вызовов функций, выделявших память.
- Уровень mi2 – позволяет обнаруживать все остальные ошибки работы с памятью в куче, которые мы рассмотрим ниже. Однако для снижения накладных расходов и ускорения анализа, глубина стека выбрана равной единице. То есть, на этом уровне мы сможем найти ответ на вопрос, есть ли в принципе ошибки в программе. А где эти ошибки, нам поможет определить следующий уровень.
- Уровень mi3 – отличается от предыдущего тем, что глубина стека увеличена до 12-ти. Плюс добавлен функционал поиска утерянных указателей. На этом уровне мы получаем наиболее полный анализ корректности работы с памятью в куче, но заплатим за это накладными расходами, которые увеличат время выполнения программы от 20 до 80 раз по сравнению с оригиналом.
- Уровень mi4 – высший уровень, дополнен анализом ошибок доступа к памяти, выделенной на стеке, которые не обнаружены на стадии компиляции или с помощью run-time check опций компилятора. Уровень вложенности функций – 32. Как и все остальные уровни, 4-й является инклюзивным, то есть включающим в себя все виды анализа на предыдущих уровнях. Соответственно, накладные расходы будут максимальными.
Глубина стека на каждом уровне выбрана эмпирически и является компромиссом между полнотой предоставляемой информации и величиной накладных расходов на анализ приложения. В данной версии продукта пользователь не может менять глубину стека.
Чтобы начать анализ приложения, необходимо просто выбрать соответствующий тип анализа в инструментальной панели Parallel Inspector, нажать кнопку "Inspect" и выбрать уровень анализа.
Прежде чем приложение будет запущено, соответствующий Pintool внедрится в его процесс и, заменив оригинальный код, запустится в новом процессе, инициализируя запуск кода приложения. Вместе с загрузкой дополнительных библиотек это занимает какое-то время, поэтому пользователь заметит задержку старта приложения. Чем больше динамических библиотек в программе, тем больше эта задержка. Далее, приложение исполняется как обычно, только медленнее — в зависимости от глубины анализа, и, конечно, от относительного количества специфичных вызовов функций Memory API во время исполнения.
Еще до окончания анализа приложения нам предоставляется лог событий или ошибок, которые были выявлены в процессе выполнения. Причем на всех уровнях, кроме mi1, мы можем начать анализировать логи, и исходный код еще до окончания анализа, так как результаты уже будут доступны.
Результаты анализа структурированы таким образом, чтобы вначале у нас был обзор списка проблем (Problem Sets), представляющих собой конечный результат действия нескольких событий, приведших к проблеме. Например, доступ к недействительной памяти является следствием выделения самой памяти, преждевременного ее освобождения и собственно попытки доступа. Такие детали в виде зарегистрированных событий (Observations) можно посмотреть в окне, нажав кнопку "Details" в главном окне. Там же можно быстро взглянуть на код, в котором это событие произошло (Рис.3).
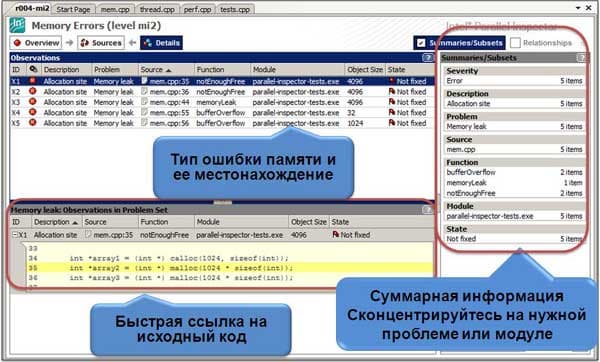
Это удобно, когда нет необходимости переключаться в редактор исходного кода, а нужно просто пройтись по ошибкам в списке и просмотреть, на какие строки кода ссылается диагностика.
В списке с найденными ошибками нам доступна вся информация относительно процесса, модуля, функции, и номера строки кода, в которой эта ошибка произошла. В реальных проектах список ошибок бывает значительный. В этом случае удобно воспользоваться фильтром по типу ошибки, ее описанию, по имени исходника, по имени функции или модуля. В процессе исправления ошибок можно помечать их как исправленные, или отфильтровывать, чтобы они не загромождали список.
Из списка проблем или детального списка можно перейти в режим Sources (Рис.4).
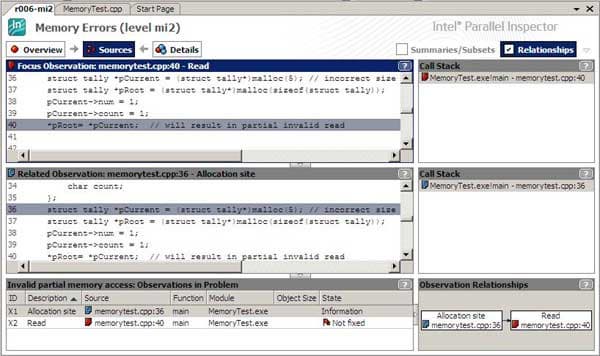
Инструмент предоставит два окна с исходным кодом, в которых будет отображена взаимосвязь между начальным действием, как правило, выделением или инициализацией памяти, и конечным действием, которое привело к ошибке, например попытка чтения или записи. Какое именно их этих действий является ошибочным, инструмент знать не может, так как они определяются логикой приложения. Но нарушение корректности реализации логики будет продемонстрировано, как с помощью исходного кода, так и в окне Observations Relationships, где графически выстраивается связь между исходным и конечным событиями. При этом события помечаются различными цветами, чтобы легко было определить соответствующие окна исходного кода, описания событий и стеки вызовов функций. Стеки вызовов нужны для того, чтобы было легче ориентироваться, каким образом мы попали в ту или иную функцию, так как событие, приведшее к ошибке, далеко не всегда может оказаться в самом исследуемом приложении, а, например, в сторонней библиотеке. Найдя ошибку, совсем не обязательно переключаться Alt-Tab’ом в окно редактора Visual Studio и искать нужные файл исходника и строку. Достаточно двойного щелчка мышки на строке кода в окне Sources, и мы попадаем в редактор Visual Studio в нужное нам место.
Одной из полезных особенностей интерфейса Inspector’а является подавление диагностики уже известных ошибок. По каким-либо причинам, у нас может не быть необходимости исправлять ошибки определенного типа, или ошибки в определенных модулях, или в исходных файлах. Например, существует проблема так называемых false positives, то есть ложных диагностик, когда обнаруживается якобы ошибка работы с памятью, которая, на самом деле, таковой не является. Такие случаи возможны при использовании некоторых сторонних библиотек, или при реализации собственных пользовательских аллокаторов в программе. В таком случае можно, используя фильтры, добавить ошибку в список Private Suppressions, и при старте анализа использовать одну из опций: "Mark problems" или "Delete Problems". При этом ошибки будут либо помечены в списке, либо вообще не отображены. Для отмены подавления достаточно выбрать опцию "Do not use suppressions".
В заключение описания интерфейса полезно упомянуть о возможности использования инструмента в режиме command line. Основное его предназначение – автоматизация процесса тестирования, например, для регрессионных тестов в QA. Диагностики в этом случае формируются в текстовом режиме и легко могут быть обработаны с помощью скриптов. Встроенная система помощи содержит всю информацию относительно формата командной строки.
Типы обнаруживаемых ошибок
Memory Leaks. На первом уровне mi1 инструмент обнаруживает только «утечки памяти». Они возникают при выделении памяти в куче и неосвобождении ее по окончании программы. В списке Problems мы увидим ошибки Memory Leak, для которых, помимо обычной информации будет указан размер утечки. Если выделение потерянной памяти происходит несколько раз в одной и той же строке, например, в цикле, то диагностика выдаст суммарный результат. Если к этой строке осуществлялся доступ разными путями, то есть будут разные стеки, то диагностики будут отдельными.
Необходимо отметить, что анализ на уровне mi1 происходит гораздо быстрее, чем на других уровнях. Это связано с тем, что, несмотря на инструментацию, утилита Pin используется в режиме Probe mode. Probe mode – это метод, в котором используется внедрение «датчиков», jump-инструкций, только в начале определенных функций перед загрузкой образа исполняемого модуля. Перед внедрением кода «датчика», Pin замещает несколько первых инструкций кода функции на свои, и перенаправляет управление в обработчик. Длинна внедренного кода «датчика» на архитектуре IA-32 составляет 5 байт, на архитектуре Intel 64 – 7 байт. Поскольку и приложение, и обработчик выполняются практически без изменений (нет замещения кода всех инструкций), то производительность оказывается намного выше, чем в обычном режиме.
Pintool (mi1) дополняет функции выделения и освобождения памяти собственными, анализирующими функциями, с помощью Pin API. Отследив все вызовы выделения и освобождения памяти в куче, можно, сопоставив их, сделать вывод, какие из выделенных объектов памяти не были освобождены до завершения программы. Стоит только отметить, что если ссылка на выделенную в куче память будет сохранена в глобальном указателе, то ошибка «утечка памяти» сигнализирована не будет. Это отчасти является ограничением технологии, и на сегодняшний день анализ глобальных указателей не поддерживается. С помощью Windows API dbghelp.dll будут определены модули, имена функций, в которых память была выделена, и номера соответствующих строк кода.
Нахождение символов и строк кода, как и получение корректного стека, требует наличия отладочной информации для исполняемого кода. Поэтому крайне желательно включить ее генерирование во время компиляции и линковки с помощью ключей /Zi и /DEBUG. Оптимизирующий компилятор создаст дополнительные трудности на пути определения принадлежности собранных данных функциям и строкам, поэтому оптимизацию кода лучше отключить, используя ключ /Od. Если анализ приложения происходит в Debug-режиме, то эти опции включены в проекте Visual Studio по умолчанию. Какой именно С++ компилятор используется в Visual Studio, — Intel или Microsoft, особого значения не имеет.
Следующий уровень анализа mi2 способен обнаружить почти все оставшиеся типы ошибок доступа к памяти, выделенной в куче. Однако для ускорения анализа глубина стека выбрана равной единице. То есть на этом уровне мы сможем найти ответ на вопрос, есть ли в принципе ошибки в программе. А где эти ошибки, как мы попали в функции с ошибками, нам поможет определить следующий уровень mi3. Он отличается от предыдущего тем, что глубина стека функций увеличена до 12. Плюс добавлена возможность поиска утерянных указателей, которую мы рассмотрим позже.
Missing Allocation. Ошибки возникают при попытке освободить память по несуществующему адресу. Проще говоря, если будет случайно продублирован вызов функций free/delete или их аргумент указывает на несуществующую память, будет диагностирована ошибка. И если в Debug-режиме компилятор с включенной опцией run-time check найдет эту оплошность еще в процессе компиляции, в Release-режиме сообщение об ошибке выдано не будет.
Mismatched Allocation/Deallocation. Такие ошибки возникают при попытке освободить память с помощью функций, не соответствующих функции выделения памяти. Например, где-то «глубоко в недрах программы» выделяется какой-нибудь объект, допустим, буфер обмена или дескриптор, и конечный пользователь должен его освободить. При этом сам объект может быть выделен с помощью run-time функции malloc, но пользователь использует в своем C++ модуле функцию delete (Листинг 1).
char *pStr = (char*) malloc(16);...delete pStr;//Err:Mismatched Allocation/Deallocationfree(pStr);free(pStr);// Err:Missing Allocation
В окне Details Inspector выдаст две цитаты кода с выделенными строками: в качестве Allocation Site — строку когда, где память была выделена в malloc, и Mismatched Allocation/Deallocation диагностику в месте, где вызвана delete-функция. Этим особенно хорошо иллюстрируется разница между событиями и проблемой. Несколько вполне корректных сами по себе событий, таких как аллокация и деаллокация памяти, составляют одну проблему из списка, который и представлен в окне Overview. А окно Observations Relationships указывает временную причинно-следственную связь между событиями. То есть в данном случае первична аллокация памяти, за которой последовала ее некорректная деаллокация.
Invalid Memory Access и Invalid Partial Memory Access. Ошибки возникают при чтении/записи по недействительным адресам памяти в куче или в стеке и по частично недействительным адресам памяти. В программах довольно часто встречается такая небезопасная функция копирования строк, как strcpy. В Листинге 2 представлен пример, где сделана попытка скопировать строку "my string" по уже несуществующему адресу.
char *pStr = (char*) malloc(16);free(pStr);strcpy(pStr, "my string");//Err:Invalid Memory Accesschar *pStr = (char*) malloc(16);free(pStr);char *pStr1 = (char*) malloc(16);strcpy(pStr, "my string");//Err:Invalid Memory Access
В результате работы Inspector’а мы можем получить несколько одинаковых ошибок Invalid Memory Access, ссылающихся на одну и ту же строчку кода. Возможно, это смутит пользователя, однако нужно понимать, что Inspector анализирует не исходный код, а исполняемый. И в данном случае, возможно, компилятор оптимизировал копирование строки, выполнив его несколькими инструкциями. Естественно, что все эти инструкции принадлежат одной и той же строке исходного кода. Это, кстати, одна из причин, почему лучше использовать Debug-режим для анализа приложения Inspector’ом.
Если в прошлом примере мы копировали строку в память, которая была недействительна, то сейчас мы рассмотрим более сложный случай – одна из самых коварных ошибок при работе с указателями и памятью (Листинг 2). Сначала мы выделяем буфер памяти с помощью malloc и сохраняем его адрес в указателе pStr. Затем сразу освобождаем ее и выделяем буфер такого же размера, но по указателю pStr1. Далее, копируем строку по старому указателю. В некоторых случаях, когда между выделениями памяти нет других операций с кучей, и при этом, когда программа выполняется в незагруженных другими приложениями системах, велика вероятность, что значения адреса в обоих указателях pStr и pStr1 совпадут, и ничего страшного в этот раз не произойдет. Но тем и коварна данная ошибка, что при переносе программы на реальную систему, например, у заказчика, приложение начнет падать, что совершенно недопустимо. Осталось отметить, что такой тип ошибки обнаруживается Inspector’ом только на уровне mi3 и выше, где включен дополнительный механизм поиска «утерянных» указателей. Естественно, расплатой за это станут дополнительные накладные расходы во время анализа.
Ошибка Invalid Partial Memory Access возникает, когда происходит доступ к составному объекту памяти, например, структуре, часть которого недействительна. В Листинге 3 представлен пример такого кода.
struct tally { int num; char count;};struct tally *pCurrent = (struct tally*)malloc(5); //incorrect size!struct tally *pRoot = (struct tally*)malloc(sizeof(struct tally));pCurrent->num = 1;pCurrent->count = 1;*pRoot= *pCurrent;//Err:Invalid Partial Memory Accesschar array[10];strcpy(array, "my string");int len = strlen(array);while (array[len] != 'Z')//Will read from below the stack pointer len--;
Здесь используется функция выделения памяти под структуру tally с явным указанием размера и с помощью sizeof, что более правильно. Далее, мы инициализируем поля одной из структур по указателю pCurrent единицами и копируем ее в структуру по указателю pRoot. Inspector диагностирует ошибку Invalid Partial Memory Access в строке копирования, при этом в диагностике ошибочной (Partial Invalid Read) будет названа структура по указателю pCurrent.
Давайте разберемся, в чем состоит ошибка. К сожалению, Inspector пока еще не может подсказать нам, что по умолчанию включена опция компилятора /Zp4, которая заставляет его выравнивать размеры структур до величины 4 байт. А значит, sizeof нашей структуры из переменных типа int и char составляет не 5, а 8 байт. То есть при копировании мы попытались прочитать 8 байт структуры по указателю pCurrent, в которой инициализированы, а значит, действительны, только первые 5 байт памяти.
В том же Листинге 3 представлен пример ошибки, которая может быть обнаружена только на уровне mi4. Этот уровень позволяет находить ошибки доступа к памяти, выделенной на стеке, которые, по какой-то причине, не обнаруживаются еще на стадии компиляции с помощью run-time chek опций компилятора. Для данного примера копирования символов строки "my string" в цикле Inspector выдаст диагностику чтения недействительной памяти в теле массива. Действительно, так как в данной строке нет символа ‘Z’, то на одиннадцатой итерации произойдет попытка чтения символа за границей выделенного в стеке участка памяти.
Uninitialized Memory Access и Uninitialized Partial Memory Access. Ошибки возникают при попытке чтения выделенной, то есть действительной, но неинициализированной памяти, в куче или в стеке. Простейший пример такой ошибки представлен в Листинге 4.
char *pStr = (char*) malloc(16);char c = pStr[0]//Uninitialized Memory Accessstruct person { unsigned char age; char firstInitial; char middleInitial; char lastInitial;};struct person *p1, *p2;p1 = (struct person*) malloc(sizeof(struct person));p2 = (struct person*) malloc(sizeof(struct person));p1->firstInitial = 'c';p1->lastInitial = 'o';*p2 = *p1;//Uninitialized Partial Memory Read
Мы сделали попытку чтения первого символа из неинициализированной строки в переменную с. Как и в случае доступа к частично недействительной памяти, может быть ошибка доступа к частично неинициализированной памяти. Пример тоже со структурой. Если попытаться только скопировать частично проинициализированную структуру person, расположенную по указателю p1, в новую структуру по указателю p2, Inspector выдаст ошибку Uninitialized Partial Memory Read для строки копирования, при этом в качестве Allocation Site будет определена строка выделения памяти для структуры по указателю p1.
Заключение
Наверное, не имеет особого смысла объяснять последствия ошибок, вызванных некорректным использованием памяти, разработчикам программного обеспечения. Необходимость использования инструмента, подобного Inspector, в процессе разработки не вызывает сомнений. Вопрос в том, насколько этот инструмент удобен для использования, и насколько полно он покрывает возможные проблемы корректности исполнения программ. Разработчики Intel Parallel Inspector будут рады услышать мнения пользователей о продукте и обсудить те недостатки, которые еще есть в нем, на ISN форумах, как англоязычном, так и русскоязычном.


