Секреты использования Intel Parallel Inspector для поиска ошибок многопоточности
Введение
Intel Parallel Inspector входит в состав набора Intel Parallel Studio. Inspector может быть установлен и проинтегрирован в Microsoft Visual Studio как часть набора, так и отдельно. Инструмент помогает разработчикам обнаружить ошибки в многопоточной программе на этапе ее написания и верификации, улучшая корректность и стабильность ее исполнения. Специфичный функционал инструмента и возможность его использоывния из командной строки подразумевают применение в процессе автоматизированного тестирования. Но, благодаря удобному графическому интерфейсу, Inspector используется разработчиками и в повседневной практике при проверке тех или инных участков проекта. Кроме того, анализ готовых проектов на наличие ошибок многопоточности часто «открывает глаза» на другие имеющиеся в коде проблемы, что заставляет задуматься о подходах к разработке многопоточных программ.
В данной статье мы рассмотрим особенности использования Inspector’а для поиска ошибок, специфичных для многопоточных программ. Инструмент также позволяет находить и ошибки доступа к памяти, но эта тема рассмотрена в отдельной статье.
Как обнаруживаются ошибки многопоточности
Как и другие инструменты, анализирующие корректность исполнения программы, Inspector не производит разбор и анализ синтаксиса исходного кода, а работает с объектами бинарного кода, исполняемыми в системе. Поэтому, для анализа исполняемого кода «на лету», Inspector использует специальные методы внедрения в процесс и перехвата вызовов системных и потоковых API. Данные собираются динамически, и анализируются только те участки кода, которые исполнялись при работе программы. Именно поэтому при тестировании рекомендуется запускать такие сценарии, которые бы охватывали тестируемый код как можно более полно (свойство полноты теста). Ввиду того, что инструмент не имеет априорной информации о количестве создаваемых потоков, их параметрах, времени жизни, разделяемых данных, методах работы с данными, функциях синхронизации и так далее, он выстраивает собственную динамическую модель исполнения приложения, основными элементами которой являются события, например, системные вызовы и доступ к разделяемым между потоками данным.
Для внедрения в процесс иследуемого приложения, перехвата системных вызовов и анализа всех инструкций чтения/записи памяти и их адресов на уровне бинарного кода в Inspector’е применяется модификация приложения с помощью динамической бинарной инструментации (рис.1). В основе инструментатора лежит утилита Pin - Dynamic Binary Instrumentation Tool (http://www.pintool.org), которая внедряется в анализируемый процесс непосредственно перед стартом, позволяя отслеживать выполнение практически любых инструкций и предоставляя API доступа к содержимому регистров, контексту выполнения программы, символьной и отладочной информации.
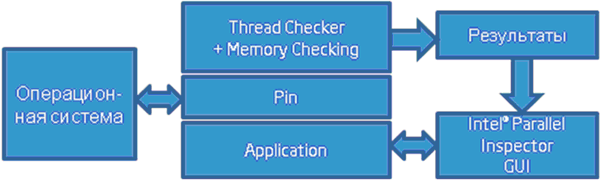
Для составления адекватной модели инструмент должен отслеживать все вызовы потоковых API и функции выделения/освобождения памяти динамически. В Windows таких API-функций более 170. Причем, возможно, не все функции поддерживаются инструментом, так как за основу взяты только те, которые опубликованы и описаны разаботчиком операционной системы. В связи с этим существует вероятность возникновения ошибок типа False Positive и False Negative, то есть ложное обнаружение ошибок, либо ошибочное необнаружение проблем. Иногда таких ошибок может быть достаточно много.
В виду того, что ошибки многопоточности по существу – это неудачно расположенные во времени события, происходящие в одновременно работающих потоках, то строящаяся и анализирующаяся модель исполнения многопоточной программы тоже имеет протяженность «во времени». Однако отсчетами во временной шкале являются не секунды, а события, изменяющие состояние модели. Это позволяет обнаруживать не только ошибки, произошедшие во время тестирования, но и те, которые не произошли, но могли бы произойти при каких-либо других временных параметрах системы. Например, создание потока может быть первым отсчетом во «временной» шкале. Все вызовы функций синхронизации являются такими отсчетами, так же как и доступ к разделяемым переменным. А в промежутках между ними находятся участки (frames), в течение которых состояние считается неизменным, а доступ к данным - либо безопасным, либо нет, в зависимости от значения предыдущих отсчетов.
В качестве примера приведем ситуацию с доступом к глобальной переменной из двух потоков. На шкале уже есть отсчеты, соответствующие созданию обоих потоков, и один отсчет модификации переменной в потоке T1. Если в следующем «фрейме» зарегистрирован доступ к переменной из потока T2, то он будет признан опасным, и будет сформировано сообщение об ошибке. При этом совершенно не важно, насколько близко или далеко друг от друга в реальном времени эти события произошли. Если же доступ к переменной в потоках T1 и T2 разделяет отсчет определенного типа, например вызов функции синхронизации в T1 или функции уничтожения потока T1, то следующий фрейм будет признан для операции с переменной безопасным, как и остальные, до тех пор, пока не будут зарегистрированы события, способные повлиять на возможность ошибочной модификации глобальной переменной.
В течение исполнения приложения Inspector накапливает сообщения об ошибках и информацию о событиях, которые будут представлены пользователю. Некоторые из этих событий можно просмотреть в реальном времени еще до завершения работы программы.
В Intel® Parallel Inspector используется оригинальный подход к представлению структуры обнаруженных ошибок и анализируемых проблем в коде. Существуют три категории представления:
- Observation (замер или наблюдение). Некоторое изменение состояния, зафиксированное для определенного участка кода, например: создание объекта синхронизации, доступ к объекту в памяти, захват блокировки и т.д.
- Problem (проблема). Несколько логически объединенных наблюдений, которые обусловили проблему, например: чтение непроинициализированной памяти, внеочередной захват блокировки, незащищенный доступ к разделяемым данным.
- Problem Set (совокупность проблем). Набор проблем, в которых участвует одно или несколько общих наблюдений. Это может быть группа событий несинхронизированного чтения/записи незащищенных данных или потенциальная блокировка в цикле.
Взаимоотношение между этими категориями удобно рассматреть на примере графа (рис.2). Белые узлы графа представляют Проблемы. Они могут быть рассмотрены как уникальные случаи ошибок в программе. Красные узлы представляют Наблюдения. Каждая из Проблем связана с несколькими Наблюдениями локальной связью, отражаемой линией на графе. Иногда одно Наблюдение участвует в двух Проблемах. Например, если проблема «гонок» (data races) в параллельном коде возникла из за несихронизированного доступа по записи глобальной переменной, то наверняка существует еще несколько проблем, связанных с несинхронизированным доступом к этой переменной.
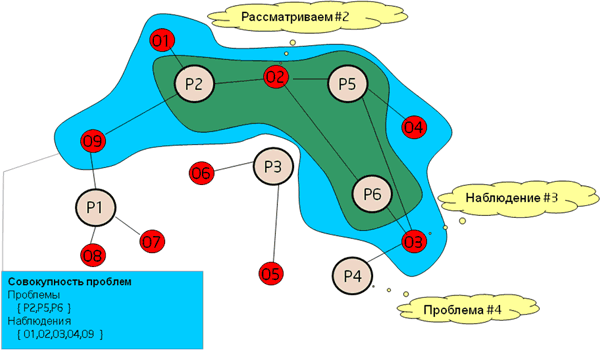
Глобальный граф взаимоотношений может быть рассмотрен в различных ракурсах. Давайте проанализируем Наблюдение O2. O2 участвует в трех различных Проблемах: P2 { O1,O2,O9}, P5{O2,O3,O4} и P6{O2,O3}. Мы экстраполируем взаимосвязь на все эти Наблюдения, потому что если все три проблемы решаются в случае изменения налюдения O2, то его модификация также окажет влияние на остальные Наблюдения.
В графе могут быть Проблемы, которые стоят особняком (P3) и никак не связаны с общими для других Проблем Наблюждениями.
Еще один тип взаимоотношений представляют опосредованные отношения между P1 и P4, которые, возможно, имеют различные пути их решения. Хотя, если представить себе, что O3 и O9 – это аллокация объектов, добавление необходимых элементов сихронизации для этих объектов могло бы разорвать эту сложную связь.
В любом случае пользователю не нужно анализировать глобальный граф взаимоотношений, так как результаты представлены пользовательским интерфейсом в более удобной для восприятия табличной форме. Хотя, если проанализировать любую из найденных проблем в списке, мы всегда сможем восстановить такой граф.
Интерфейс
Еще до запуска приложения пользователь должен выбрать уровень анализа, который определяет детализацию получаемой информации и накладные расходы на исследование. Последние обусловлены использованием технологии динамического бинарного инструментирования. Приложение будет исполняться дольше, чем если бы оно было запущено вне анализа. В обычной практике для пользователей время анализа не является критичным, так как он проводится один раз в текущей сборке проекта. Тем более, что если тестирование автоматизированное, то длительный тест можно оставить на ночной период. Однако возможность управления глубиной анализа тоже необходима, и пользователю предоставляется четыре уровня анализа, в зависимости от его глубины:
- Уровень ti1 – позволяет обнаруживать взаимные блокировки потоков. Глубина стека функций равна единице. Это самый «легкий» тип анализа, который позволяет быстро проверить программу, которая почему-то иногда «виснет»; чтобы понять, являются ли ошибки многопоточности причиной проблем.
- Уровень ti2 – дополнительно к первому уровню позволяет обнаруживать конкуренцию доступа к незащищенным данным, «гонки». Это основной уровень, на котором относительно быстро обнаруживаются большинство ошибок многопоточности. Глубина стэка выбрана минимальной, так как на этом уровне мы обнаруживаем, что ошибки есть, не вникая особенно, где они располагаются. При этом накладные расходы относительно невысокие. Уровень является оптимальным для быстрого автоматизированного тестирования.
- Уровень ti3 – отличается от предыдущего тем, что глубина стека увеличена до 12-ти. Уровень используется для исследования конкретных проблем многопоточности, включая анализ потока исполнения программы, приведшего к ошибке.
- Уровень ti4 – высший уровень, позволяющий определять все типы ошибок многопоточности, которые способен обнаруживать инструмент. Главная отличительная особенность – анализирует многопоточный доступ к стековой памяти. Уровень вложенности функций – 32. Как и все остальные уровни, 4-й является инклюзивным, то есть включающим в себя все виды анализа на предыдущих уровнях. Соответственно, накладные расходы будут максимальными. Анализ реального большого приложения может занять значительное время, поэтому рекомендуется проводить его либо в автоматизированном режиме на тестовых системах, либо оставлять работающий с приложением инструмент на выходные в конце недели.
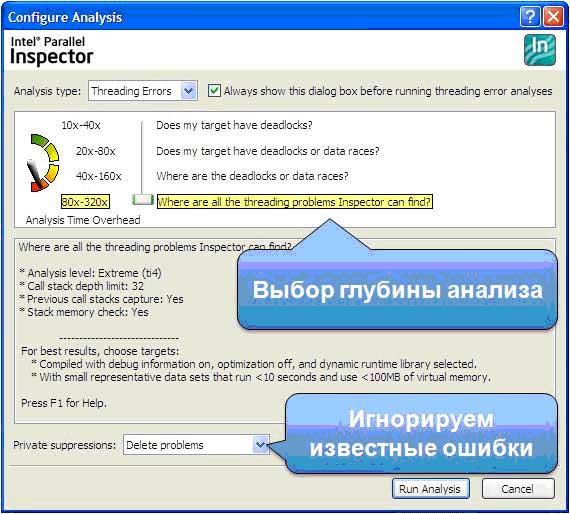
Глубина стека на каждом уровне выбрана эмпирически и является компромиссом между полнотой предоставляемой информации и величиной накладных расходов на анализ приложения. В данной версии продукта пользователь не может менять глубину стека.
Выбрав соответствующий тип анализа в инструментальной панели Parallel Inspector, пользователь нажимает кнопку “Inspect” и выбирает уровень анализа. Инструментатор внедрится в процесс анализируемого приложения, заменив оригинальный код, и инициализирует запуск кода программы. Как и в случае с Memory Checker'ом, вместе с загрузкой дополнительных библиотек процесс старта приложения занимает определенное время, поэтому пользователь заметит задержку. Чем больше динамических библиотек в программе, тем больше эта задержка. Далее, приложение исполняется как обычно, только медленнее - в зависимости от глубины анализа, ну и, конечно, от относительного количества специфичных вызовов функций Memory и Threading API во время исполнения.
После окончания исполнения приложения Inspector выведет список ошибок и диагностических сообщений о событиях, связанных с существованием потоков в процессе выполнения. Каждому сообщению Inspector сопоставит строку исходного кода, в которой найдена причина того или иного события или ошибки, а также стек вызовов функций и адрес памяти.
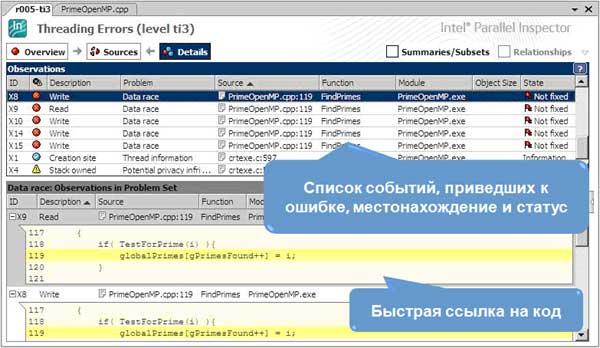
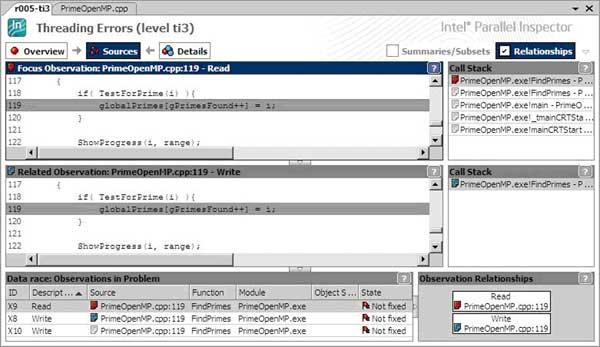
В соответствии с упомянутым выше графом, результаты анализа структурированы таким образом, чтобы вначале у нас был обзор списка проблем (Problem Sets), представляющих собой конечный результат действия нескольких событий, приведших к проблеме (Observations). Например, «гонки» или data race проблема является следствием доступа из двух потоков к общим данным по «чтению и записи», или по «записи и записи». Такие детали в виде зарегистрированных событий можно посмотреть в окне, нажав кнопку “Details” в главном окне. Там же можно взглянуть на код, в котором это событие произошло (Рис.4). Это удобно, когда нет необходимости переключаться в редактор исходного кода, а нужно просто пройтись по ошибкам в списке и просмотреть, на какие строки кода ссылается диагностика.
В списке с найденными ошибками нам доступна вся информация относительно процесса, модуля, функции и номера строки кода, в которой эта ошибка произошла. В реальных проектах список ошибок бывает значительным. В этом случае удобно воспользоваться фильтром по типу ошибки, ее описанию, имени исходника, имени функции или модуля. В процессе исправления ошибок можно помечать их как исправленные, или отфильтровывать, чтобы они не загромождали список.
Из списка проблем или детального списка можно перейти в режим Sources (рис.5). Так как потоковые ошибки сопряжены с выполнением программы несколькими потоками одновременно (а иногда доступ к незащищенным данным может происходить из разных функций), то для удобства представления и обнаружения причин ошибки Inspector отображает сразу два окна исходного кода с функциями, выполнявшимися разными потоками. В них будет отображена взаимосвязь между событиями, например такими, как доступ по чтению и записи к данным, которые привели к «гонкам». Нарушение корректности реализации многопоточной логики будет продемонстрировано как с помощью исходного кода, так и в окне Observations Relationships, где графически выстраивается связь между событиями, в данном случае равноправными. При этом события помечаются различными цветами, чтобы легко было определить соответствующие окна исходного кода, описания событий и стеки вызовов функций. Стеки вызовов нужны для того, чтобы было легче ориентироваться, каким образом мы попали в ту или иную функцию; так как событие, приведшее к ошибке, далеко не всегда может произойти в самом исследуемом приложении, а, например, может быть вызвано в сторонней библиотеке. Найдя ошибку, совсем не обязательно переключаться Alt-Tab’ом в окно редактора Visual Studio и искать нужные файл исходника и строку. Достаточно двойного щелчка мышки на строке кода в окне Sources - и мы попадаем в редактор Visual Studio в нужное нам место.
При активном использовании в приложении сторонних многопоточных библиотек возникает риск ложных диагностик, которые выдает Inspector из-за нехватки отладочной информации в модулях или нестандартных способах синхронизации потоков. Довольно показательным примером может служить так называемая User Level Synchronization, когда вместо использования потокового API, предоставляемого операционной системой, применяются методы легковесных пользовательских примитивов для улучшения производительности. В данном случае Inspector не подозревает, что разработчик позаботился о целостности данных, и будет регистрировать ошибки data race. Для того чтобы подобные диагностики не замусоривали отчет о проблемах, полезно применять механизм подавления диагностики уже известных ошибок, Suppressions. Пользователь может создавать собственные фильтры, добалять ошибку в список Private Suppressions, специфицируя критерий ее фильтрации, например, по модулю, имени функции, файлу исходного кода и даже строке (рис.6.).
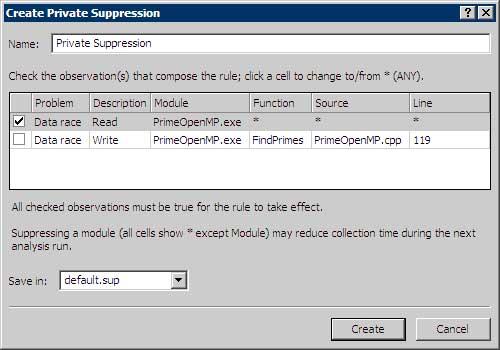
При следующем старте анализа необходимо использовать одну из опций: "Mark problems" или "Delete Problems". При этом ошибки будут либо помечены в списке, либо вообще не отображены. Для отмены подавления достаточно выбрать опцию "Do not use suppressions". При необходимости файл с созданными фильтрами можно использовать и для других проектов. Для этого достаточно его сохранить в каком либо доступном месте и добавить путь к нему в настройках Public Suppressions: Menu > Tools > Options > Intel Parallel Inspector > General > Suppressions > Public Suppressions.
Типы обнаруживаемых ошибок многопоточности и некоторые хитрости
Основными ошибками многопоточности являются «гонки» (data races), или конкурирующий доступ потоков к разделяемым данным, и взаимоблокировки (deadlocks), когда, захватив неправильно расставленные объекты синхронизации, потоки самозаблокировались и не могут продолжить свое выполнение. Примеры кода, приводящего к такого рода ошибкам, рассматривать не будем; они достаточно просты и обсуждались множество раз. Необходимо только упомянуть, что Inspector выдает еще два типа ошибок: Lock Hierarchy Violation и Potential Privacy Infringement.
Lock Hierarchy Violation. Эта ошибка прояляется, когда порядок захвата нескольких объектов синхронизации (мьютекс, критическая секция, и т.д.) в одном потоке отличается от порядка их захвата в другом. Либо в случае, когда объекты захватываются одним потоком, а освобождаются другим. Ситуация Deadlock является следствием ошибки Lock Hierarchy Violation. Но если Inspector обнаружил ошибку Deadlock, то только она и будет диагностироваться.
Potential Privacy Infringement. Интересная ситуация, связанная с тем, что один поток пытается доступиться к объектам стековой памяти в другом потоке. Простой пример, демонстрирующий такую ситуацию:
int *p;//глобальный указатель//функция потока Т1{int q[10]; //локальный массив переменныхp = q; //публикация локальных данныхq[0] = 1;}//функция потока Т2{*p = 2; //доступ к стеку Т1}
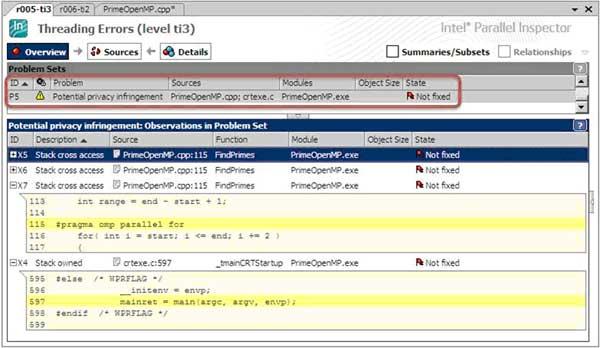
Inspector выдаст предупреждение Potential Privacy Infringement, указывая на события Stack Across Access в функции, исполняемой потоком T2, и Stack Owned в функции, исполняемой потоком T1. На самом деле обычно так не поступают, публикуя локальные данные потока с возможностью доступа к ним из других потоков. Но такую диагностику все-таки можно встретить в реальных приложениях, например, базирующихся на OpenMP. При этом Stack Across Access будет диагностирован в точке создания дополнительных потоков, например в строке с прагмой omp parallel (рис.7). Это происходит потому, что поток-потомок имеет доступ к разделяемым стековым переменным; в данном примере это start и end.
Рассмотрим еще один интересный случай. В процессе анализа приложения одного из наших пользователей было обнаружено, что Inspector диагностирует data race там, где, по идее, его быть не должно. Ниже представлен урезанный пример, который сам по себе не вызовет такую ошибку, но показателен по сути.
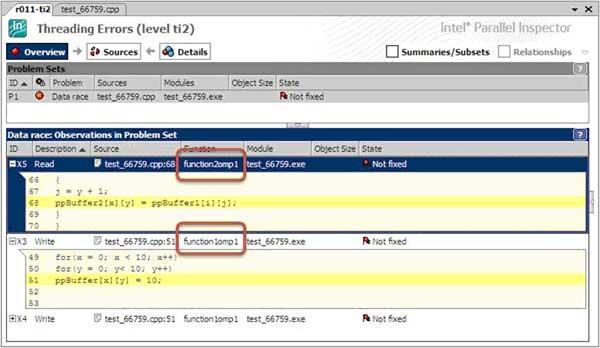
void function1(int **ppBuffer){ #pragma omp parallel for for(int x = 0; x < 10; x++) for(int y = 0; y < 10; y++) ppBuffer[x][y] = 10; return;}void function2(int **ppBuffer1, int **ppBuffer2){ #pragma omp parallel for for(int x = 0; x < 10; x++){ for(int y = 0; y < 10; y++) { j = y + 1; ppBuffer2[x][y] = ppBuffer1[i][j]; }} return;}int main(void){ ...//some code here including allocation ppBuffer1,2 function1(ppBuffer1); function2(ppBuffer1, ppBuffer2); return 0;}
Инспектор выдал ошибку Data Race, указывая в качестве событий чтение буфера памяти в функции function2 и запись буфера памяти в функции function1. Результаты диагностики представлены теперь для реального примера (рис.8).
На самом деле, тем, кто знаком с fork/join моделью OpenMP, такая ошибка кажется невероятной, даже с учетом того, что выделение памяти для буфера организовано так, что она берется из одного массива, выделенного из кучи одним оператором Дело в том, что функции function1 и function2, хотя и выполняются в параллельном режиме, вызываются одна за другой в main, и точка возврата из function1 практически являеся join-точкой для потоков, созданных внутри нее. А значит, даже если функции оперируют одним и тем же, разделяемым буфером памяти, они не могут создать такую ситуацию Race Condition по определению модели OpenMP.
Пользователь, внимательно следящий за сообщениями во время анализа Inspecrot'а, может увидеть, как инструмент предупреждает о том, что обнаружены проблемы с OpenMP run-time. Такое поведение инструмента обусловлено тем, что программа была слинкована с Microsoft OpenMP run-time библиотекой (vcomp.dll), а Inspector не поддерживает каких либо других OpenMP библиотек времени исполнения кроме Intel. Сделано это не специально, а в силу сложившихся обстоятельств, одним из которых является то, что Intel поддерживает более новую версию стандарта OpenMP.
Значит ли это, что Inspector непригоден для анализа OpenMP-приложений, скомпилированных в MSVS? Нет. Это ограничение легко обойти. Для этого достаточно слинковаться с Intel OpenMP run-time библиотекой, явно передав линкеру ее имя.
Для Microsoft Visual Studio IDE необходимо изменить следующие настройки проекта:
Project Properties -> Linker -> Input -> Ignore Specific Library -> указать vcomp.dll или vcompd.dll
Project Properties -> Linker -> Input -> Additional Dependencies -> вписать libiomp5md.lib
Для тех, кто использует компиляцию из командной строки, нужно модифицировать команду следующим образом:
icl /MD /openmp hello.cpp /link /NODEFAULTLIB:"vcomp.dll" libiomp5md.lib
Более подробную информацию о совместимости OpenMP библиотек можно почерпнуть здесь: Using the OpenMP Compatibility Libraries
Рассмотрим пример прямо противоположный предыдущему.
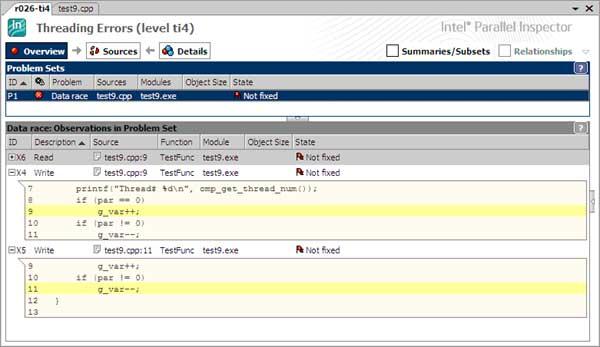
В некоторых случаях Inspector может не обнаруживать ошибку Data Race, несмотря на то, что она явно заложена в коде (рис. 9). Правда, для этого пришлось придумать синтетический пример, который вряд ли встречается в реальной практике.
int g_var;void TestFunc(int par){ printf("Thread# %d", omp_get_thread_num()); if (par == 0) g_var++; if (par != 0) g_var--;}int _tmain(int argc, _TCHAR* argv[]){omp_set_num_threads(2);#pragma omp parallel for for (int i=0; i<2; i++) TestFunc(i);printf("%d ", g_var);return 0;}
В данном примере функция TestFunc() вызывается в двух различных потоках с входными параметрами 0 и 1. То, что это именно так, можно проверить с помощью вывода на печать исполнения функции omp_get_thread_num(). При этом глобальная переменная модифицируется в обоих потоках, что, по идее, несомненно должно детектироваться как ошибка Data Race.
Что бы еще более точно убедиться в корректности начальныз условий, можно проверить код дизассемблера на предмет оптимизации функции TestFunc(), из которого видно, что операции инрементации и декрементации присутствуют.
| 1. | # if (par == 0) | ||
| 2. | 0040105A | mov | eax,dword ptr [par] |
| 3. | 0040105D | test | eax,eax |
| 4. | 0040105F | jne | TestFunc+4Bh (401067h) |
| 5. | g_var++; | ||
| 6. | 00401061 | inc | dword ptr [g_var (4072A4h)] |
| 7. | if (par != 0) | ||
| 8. | 00401067 | mov | eax,dword ptr [par] |
| 9. | 0040106A | test | eax,eax |
| 10. | 0040106C | je | TestFunc+58h (401074h) |
| 11. | g_var--; | ||
| 12. | 0040106E | dec | dword ptr [g_var (4072A4h)] |
Не раскрывая особых секретов внутренней имплементации Inspector’а, можно сказать, что инструмент отслеживает доступ к памяти потоками, выделяя подобные участки в «теневой» памяти и сохраняя историю доступа потоков к ним и вызовов функций синхронизации. Однако копировать все данные в «теневую» память было бы чрезвычайно накладно, поэтому инструмент поступает следующим образом. Если поток Т1 один раз обращается к памяти 0хNNNN, то ничего не происходит (за исключением сохранения «истории» факта этого доступа). Далее, если поток T2 обратился к той же памяти, то это уже сигнал к тому, чтобы сохранить объект в «теневой» области и начать отслеживать дальнейшие обращения к нему. Однако, если эта память больше не читается/пишется, то никаких дальнейших действий в отношении анализа доступа не производится.
Так, собственно, и происходило в нашем примере. Одна и та же переменная g_var была «тронута» каждым из двух потоков, при этом не происходило пересечения обращения к переменной и наступления событий синхронизации или активности другого потока, что вызвало создание «теневой» ячейки под g_var, и не более того. Вот если бы мы установили три и более исполняемых потока, или произвели еще какую-либо операцию над g_var, то тогда бы «гонка» была диагностирована.
Сделано это исключительно для того, чтобы резко снизить накладные расходы на анализ любого обращения к памяти, которое так и останется единичным обращением. В результате мы можем получить такие вот вырожденные случаи, когда на уровнях ti2-ti3 очевидные «гонки» не обнаруживаются, хотя по заявленным описаниям должны бы. Но на то они и вырожденные случаи, чтобы встречаться в практике в реальных программах крайне редко. Разработчики считают, что данный компромисс никак не отразится на качестве обнаружения потоковых проблем в реальных приложениях. Более того, если запустить пример на анализ на уровне ti4, то ошибка будет успешно диагностирована (рис. 10), так как здесь уже не требуется достижения компромисса между скоростью и тщательностью поиска ошибок.
Заключение
Использование инструмента, проверяющего корректность исполнения программ, является обязательным условием при разработке моногопоточных приложений. Все потоковые «чекеры» используют те или иные подходы для увеличения производительности анализа, и не существует ни одного инструмента общего назначения, который бы гарантировал 100-процентную вероятность обнаружения всех потоковых ошибок и исключал бы ложные диагностики, – это ниша специализированных анализаторов, привязанных к определенным параллельным языкам и run-time библиотекам. Поэтому при анализе необходимо тщательно проверять полученные диагностики, и удостоверяться, что код программы мог ее вызвать. В сложных случаях разработчики Intel Parallel Inspector будут рады вам помочь, а также услышать мнения пользователей о продукте и обсудить те недостатки, которые еще есть в нем, на ISN форумах, как англоязычном, так и русскоязычном.
Комментарии