Intel Parallel Amplifier – профилировщик многопоточных приложений
Введение
Parallel Amplifier является четвертым инструментом, заключающим цикл разработки многопоточных приложений, который поддерживается Intel Parallel Studio, и служит для оптимизации производительности параллельных программ. Amplifier может быть установлен и проинтегрирован в Microsoft Visual Studio как часть набора, так и отдельно. Профилировщик производительности предназначен для того, чтобы выяснить, насколько эффективно используется мультиядерная платформа приложением, и где находятся те узкие места в программе, которые мешают ей масштабироваться, то есть ускорять время исполнения с ростом вычислительных ядер в системе. Сегодня, с выходом новых мультиядерных микропроцессоров, хорошая масштабируемость многопоточного приложения практически является достаточным условием автоматического роста его производительности (при прочих равных условиях). Поэтому Amplifier является необходимым инструментом для разработчика программного обеспечения, требовательного к производительности микропроцессора (решатели, фильтры, кодеки, рендеры, и т.д.).
В данной статье мы рассмотрим особенности использования Amplifier’а для оптимизации производительности параллельной программы на простом примере, а также увидим преимущества этого инструмента при работе с большими приложениями.
Методология оптимизации и пользовательский интерфейс
Методология оптимизации производительности приложения заключается в последовательном выполнении трех основных этапов, на которых происходит измерение характеристик производительности и параллельности приложения. Для более легкого интуитивного понимания этой последовательности пользователю предлагается выполнить три вида анализа, которые можно выбрать один за другим в инструментальной панели Amplifier’а.
- Hotspot-анализ. «На что моя программа тратит вычислительное время процессора?» Нам необходимо знать те места в программе, Hotspot-функции, где больше всего тратится вычислительных ресурсов при исполнении, а также тот путь, по которому мы в эти места попали, то есть стэк вызовов.
- Concurrency-анализ. «Почему моя программа плохо параллелится?» Часто бывает, что ожидаемый прирост производительности (например, при переходе от 4-ядерной системы к 8-ядерной) так и не достигается. Поэтому тут нужна оценка эффективности параллельного кода, которая дала бы представление о том, насколько полно используются ресурсы микропроцессора.
- Lock & Wait - анализ. «Где моя программа простаивает в ожидании синхронизации или операции ввода-вывода?» Поняв, что наша программа плохо масштабируется, мы хотим найти, где именно, и какие именно объекты синхронизации стали на пути к хорошей параллельности. Возможно, необходимо пересмотреть реализацию алгоритмов, а может, и всю параллельную инфраструктуру приложения.
Каждый из этих видов анализа запускается по отдельности и имеет собственное окно представления результатов. При этом встроенный Source View расширяет возможности обзора результатов относительно исходного кода программы, а Statistical Call Tree, или статистическое дерево вызовов, поможет получить «объемное» представление о путях вызовов Hotspot-функций. Результаты Concurrency-анализа позволят сделать вывод об общем уровне параллельности программы и конкретных проблемах благодаря группировке информации по функциям, модулям или потокам. А Lock&Wait-анализ позволит судить о причинах этих проблем. Наличие встроенного функционала сравнения результатов позволяет отслеживать влияние изменения кода программы на ее производительность.
Пройдя все эти этапы анализа, пользователь должен сформировать для себя определенное понимание поведения приложения в плане загрузки микропроцессора и эффективного использования его ресурсов. Исходя из этого понимания, можно будет делать выводы о дальнейших шагах по улучшению производительности программы. Возможно, это будет распараллеливание некоторой функции, которая выполняется слишком долго, и в однопоточном режиме занимает значительную часть времени исполнения программы. А возможно, параллельная программа, которая не прибавляет в производительности с увеличением количества потоков на многоядерной системе, потребует пересмотра схемы синхронизации или работы с общими разделяемыми данными. В любом случае, это процесс итеративный, и он потребует нескольких циклов анализа, сопровождаемых изменениями исходного кода и перекомпиляцией приложения.
Результаты каждого запуска профилировщика сохраняются в файловой системе в виде директории, шаблон имени которой может задавать сам пользователь. Место хранения директорий с результатами тоже может задаваться пользователем в окне опций Amplifier’а, которое может быть либо в директории хранения проекта Visual Studio, либо произвольным. По умолчанию, результаты так же отображаются в окне Visual Studio Soution Explorer, где ими можно управлять так же, как и другими файлами проекта Visual Studio.
Для облегчения процесса отслеживания изменений в производительности с изменением кода приложения предназначен функционал сравнения результатов анализа. Понятно, что простейшим способом сравнения был бы простой замер времени выполнения приложения до и после модификации. Однако в случае громоздких приложений этот метод может не сработать. Поэтому важно иметь возможность сравнения результатов с более высокой степенью гранулярности, например, на уровне функций. Хотя и в этом случае ничто не мешает замерить время выполнения функции с помощью встроенных вызовов измерения времени. Удобство встроенного функционала сравнения результатов заключается в его гибкости, так как он позволяет работать как на уровне процессов/потоков, так и на уровне функций и строк исходного кода. И при этом нет необходимости каждый раз писать дополнительный код для замера и отображения результатов измерений.
Раз мы упомянули громоздкие приложения, то необходимо отметить, что измерение производительности всего приложения часто не имеет смысла, так как часто эти приложения имеют некий графический интерфейс, требующий пользовательского ввода данных (например, открытия файлов проекта), выполняется некая фаза заполнения структур данных, открываются различные окна и панели, и так далее. Часто интерес представляет только определенная фаза выполнения приложения, которая начинается только после каких-либо действий с графическим интерфейсом пользователя, или по прошествии какого-либо периода времени. Чтобы сократить время анализа и размер данных трассировки, можно использовать режим запуска приложения с задержкой старта анализа. Для этого достаточно установить опцию "Start data collection paused" в свойствах проекта Parallel Amplifier (не путать со свойствами проекта Visual Studio) и нажать кнопку "Profile" тогда, когда это будет необходимо по логике работы приложения (Рис.1).
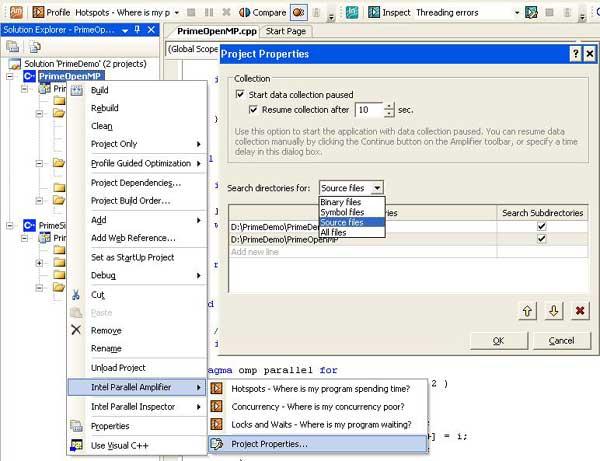
Кстати, кнопка "Profile" превращается в "Continue" после нажатия паузы или запуска в режиме "Start Paused". Так же можно установить временной интервал, когда Amplifier сам запустит коллекцию спустя определенное пользователем количество секунд после старта приложения.
Пока мы рассматриваем окно Project Properties, надо отметить, что в нем можно установить дополнительные пути к бинарным, исходным, или файлам с отладочной информацией, если они расположены не в местах по умолчанию. Тогда Amplifier включит эти пути в список поиска, и не будет запрашивать их каждый раз, когда потребуется открыть исходник, расположенный где-нибудь в другом месте файловой системы.
Итак, все предустановки сделаны, и можно начинать поэтапный анализ приложения.
Hotspot-анализ
Выбрав в панели инструментов "Hotspots" и нажав кнопку "Profile", мы запускаем Hotspot-анализ приложения, который предназначен для идентификации функций анализируемой программы, которые отнимают значительное время микропроцессора, и, скорее всего, влияют на общую производительность программы – Hotspot-функции.
Необходимо сказать, что поиск Hotspot-функций не несет в себе существенных накладных расходов. То есть анализ практически не влияет на время исполнения анализируемого приложения. Это достигается путем использования технологии временного сэмплирования стеков (Stack Sampling), в основе которой лежит прерывание работы приложения по таймеру с определенным (статистически обоснованным) интервалом, и фиксации адреса (IP) и контекста исполнения программы. При этом дополнительно происходит «раскручивание» стэка (stack unwinding) с целью определения пути вызова функции, в которой оказался каждый сэмпл. В результате, формируется трасса с данными, содержащими статистически значимые временные показатели функций, их стеки, а также контекст исполнения. По окончании выполнения программы или по прерыванию коллекции наступает фаза, называемая финализацией, в которой трасса раскрывается в имена функций, потоков, модулей и процессов, и выстраиваются список Hotspot-функций и статистическое дерево вызовов.
Процесс финализации разделен с фазой коллекции сэмплов с тем, чтобы добиться гибкости обработки собранных данных и уменьшить влияние процесса сбора данных на саму программу. Представьте такой сценарий: необходимо собрать коллекцию данных, на машине заказчика, с целью определения проблем профиля производительности поставляемого приложения на его платформе. Обычно продуктовые версии программ не содержат файлов с отладочной информацией, а это значит, что собранная трасса хотя и будет финализирована, в ней не окажется имен Hotspot-функций, а только адреса вызовов. Эти результаты профилировки можно перенести на машину с отладочной версией приложения и ре-финализировать коллекцию, выбрав в контекстном меню результата "Re-finalize". Собранным адресам вызовов сопоставятся символы из .pdb-файлов, и в списке можно будет увидеть имена функций. Есть и более «прозаическое» применение этому функционалу – запуская профилировку на своей рабочей машине, пользователь может просто забыть скопировать .pdb-файлы для анализа или указать путь к ним. И если коллекция занимает достаточно длительное время, проще ее ре-финализировать, нежели собирать данные снова.
Итак, результатом запуска приложения на Hotspot-анализ будет интегрированное в главное окно Visual Studio окно "Hotspots" со списком «горячих» функций, напротив каждой из которых отображена ее временная характеристика, как в числовом, так и в графическом представлении. По умолчанию, результаты отсортированы так, что самая «горячая» функция оказалась в списке первой (самое большое значение CPU Self-Time). Если функций слишком много, то на помощь придут фильтры, позволяющие отфильтровать список по имени модуля, потока и процесса. Кроме того, функции представлены в режиме Bottom-Up, то есть имя может быть «раскрыто» для представления стека вызова этой функции вниз по стэку (Рис.2).
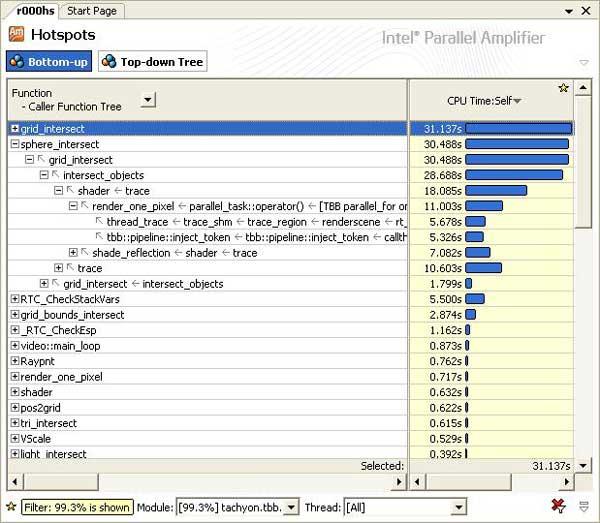
Как альтернативу, в режиме "Top-Down Tree" (статистического дерева вызовов) мы можем получить представление данной функции от самого верхнего вызова вниз, которое помогает определить все пути ее вызовов и критический путь. Важными временными характеристиками функций здесь являются Self-Time (то есть время, затраченное на выполнение самой функцией) и Total-Time - время, затраченное самой функцией и всеми функциями, вызванными из нее (Child Functions). Без такого представления, например, очень трудно определить, каким образом очень часто исполняемые функции (типа memcpy) влияют на производительность, если они попали в список самых «горячих» в Hotspot-листе.
Дополнительном источником данных по стэкам является окно Stack View, в котором с помощью полосового индикатора можно определить, какой именно путь внес наибольший вклад (в смысле влияния на производительность).
Сам факт определения имени «горячей» функции может нам ничего и не говорить. Поэтому полезно посмотреть, какой именно код в этой функции внес наибольший вклад в потребление процессорного времени. Функции бывают довольно громоздкими, содержащими достаточно большое количество строк кода, много циклов и ветвлений. Понятно, что основные «потребители» процессорного времени – это циклы, но какой из них, и какие именно инструкции внутри цикла нагружают CPU? С этим нам поможет разобраться режим Sources, то есть отображение исходного кода программы. Для этого достаточно двойного клика мышкой на имени функции, чтобы открылось окно исходного кода, в котором строкам программы сопоставлены временные характеристики его исполнения (Рис.3).
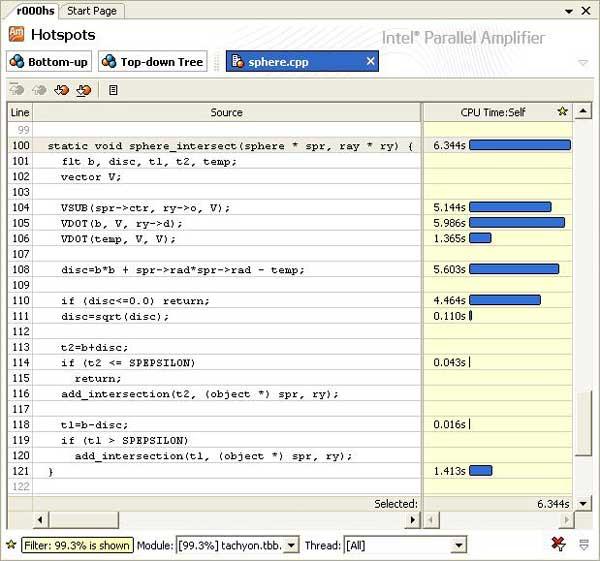
В колонке "CPU Time" – значение времени исполнения инструкций, составляющих данную строку, представленное в числовом и графическом виде. Кстати, для удобства это значение можно выводить и в процентах от общего времени анализируемого объекта.
Тут важно понимать, что эти временные значения не являются точными измерениями исполнения строк кода, а только их статистическими оценками, хотя и достаточно адекватными. Поэтому напротив некоторых строк не будет никаких значений. Это не значит, что они исполнялись 0 секунд, просто в процессе сэмплирования на эти инструкции не пришлось ни одного сэмпла. А раз так, то время их исполнения не является сколько-нибудь статистически значимым, и выводить значения не имеет смысла. И наоборот, те строки, инструкции которых выполнялись достаточно большое количество раз, чтобы набрать весомую статистику, будут иметь более точное значение оценок времени исполнения. И чем больше это время по сравнению с другими участками кода, тем сильнее будет выделена строка полосовым индикатором. А при открытии окна Sources в центр экрана будет помещена строка, занявшая самую большую часть времени исполнения всей функции.
Дальше, собрав информацию по «горячим» функциям и участкам кода, программист сам принимает решение, каковы его последующие шаги: либо оптимизация алгоритма, реализуемого в функции, с целью сокращения времени ее выполнения, либо анализ структуры данных с целью распараллеливания функции и распределения вычислительной нагрузки между ядрами микропроцессора.
Concurrency-анализ
Допустим, вы определили наиболее требовательные к производительности функции и распараллелили их исполнение. Однако при запуске приложения вы не видите существенного прироста производительности, или прирост не соответствует вашим ожиданиям. Значит, необходимо определить, насколько эффективен параллельный код в данном приложении. Запускаем Concurrency-анализ и ожидаем результатов.
Скорее всего, вы заметите, что приложение в режиме Concurrency работает уже медленнее, то есть существуют определенные накладные расходы на исполнение в данном режиме. Это связано с тем, что Amplifier производит инструментирование всех вызовов потоковых API и примитивов синхронизации приложения, очевидно, для отслеживания поведения потоков в системе при выполнении пользовательской программы. На сегодняшний момент Amplifier поддерживает Windows API создания и управления потоками и синхронизации, а также потоковую модель OpenMP, поддерживаемую как компилятором Intel, так и Microsoft.
По окончании анализа будет выведено окно с результатами «Concurrency», а также, пожалуй, главная метрика в результатах Concurrency-анализа – уровень утилизации – интегральная характеристика параллельности всего приложения, представленная в окне Summary (Рис.4).
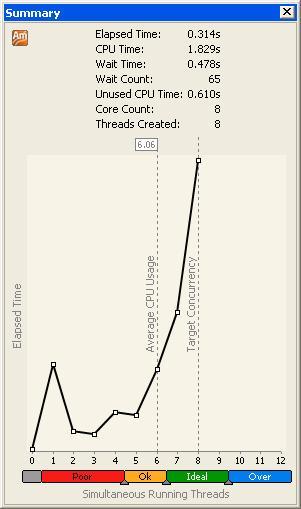
Эта характеристика дает нам представление о том, насколько хорошо распараллелено наше приложение в целом. Она представлена гистограммой распределения времени исполнения приложения по уровням параллельности (Concurrency Level). Уровень параллельности – это количество потоков, находящихся в прогрессе исполнения (runnable threads), а под уровнем утилизации понимают долю времени, в течение которого программа выполнялась одновременно в N ядрах процессора. Уровень N=1 означает, что программа выполнялась последовательно, N=2 – в двух потоках, и так далее. В идеальном случае график должен иметь пик на уровне N, равному числу вычислительных ядер в системе, и незначительные показатели на всех остальных уровнях. Кстати, цветом и квалификаторами (Poor, Ok, Ideal, Over) график индицирует, насколько близка к идеальной утилизация процессора. Другим важным свойством такого представления является то, что по графику можно оценить потенциал роста производительности программы (целью является достижение Target Concurrency), в случае разрешения проблем с масштабируемостью.
Дополнительными данными, содержащимися в окне Summary, являются, собственно, количество логических ядер процессора в данной системе (Core Count) и число потоков, запускавшихся приложением (Threads Created). Время исполнения приложения (Elapsed Time) указывает время на «настенных часах», затраченное на исполнение программы, а процессорное время (CPU Time) отражает суммарное время, потраченное ядрами процессора на активное исполнение программы. То есть если двухпоточная программа выполнялась одним потоком 5 секунд, а другим – 10, то CPU Time = 15 секунд. В идеале, CPU Time = Elapsed time число логических ядер. Кроме того, в Summary будет указано время ожидания процессора (Wait Time), когда потоки ждут событий синхронизации или заблокированы на вводе-выводе, и время неиспользованное процессором для вычислений (Unused CPU Time) – общее время, потерянное процессором на блокировках или неисполнении потоками программы.
В главном окне Concurrency-анализа инструмент предоставляет список функций, при выполнении которых программа недоиспользовала возможности микропроцессора, и уровень параллельности был низкий. Чем больше времени выполнялась функция в неэффективном с точки зрения «параллельной производительности» режиме, тем выше она в списке. В отличие от списка Hotspot-функций, здесь представлены «узкие места» в смысле параллельного выполнения работы, хотя эти списки могут и пересекаться. Здесь, напротив каждой функции представлена графическая характеристика параллельности программы в виде «градусника», где зеленый цвет обозначает порцию времени исполнения в идеальном для данной системы режиме, а красным – время, в течение которого ресурсы системы недоиспользовались. Если функция вызывалась из нескольких мест, то каждому ее стеку будет аттрибутирована эта характеристика. Есть еще синий цвет, который обозначает время исполнения программы в потоках, количество которых превышает число ядер процессора – переиспользование ресурсов. При незначительном превышении числа потоков идеального количества, обычно ничего страшного с производительностью не происходит, так как влияние избыточного количества потоков в очереди системы начинает быть заметным со значительным ростом этого количества.
Еще одним полезным свойством инструмента является возможность группировать результаты по потокам (Thread – Function – Caller Function Tree), что позволяет оценить балансировку потоков при исполнении приложения (Рис.5) и определить, какие функции внесли вклад в ту или иную долю времени исполнения в зеленой или красной зоне (нужно раскрыть ветку потока, и ниже будет представлен список функций и соответствующий им «градусник»).
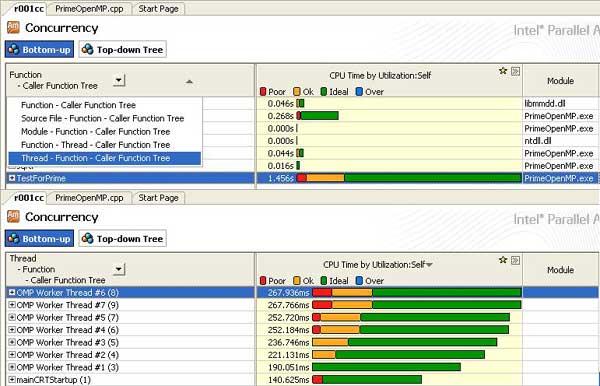
Понятно, что правильной оценка балансировки при группировке по потокам будет только тогда, когда параллельный регион в программе только один. Если их несколько, то целесообразнее группировать по регионам (OpenMP Region – Wait Function – Wait Function Tree).
Таким образом, в параллельной программе важно найти не только Hotspot-функции, но и понять, насколько хорошо они распараллелены, и нужно ли над ними работать в плане более эффективной балансировки нагрузки или оптимизации объектов синхронизации. Если Hotspot-функции распараллелены хорошо, то они не окажутся в списке с красной зоной «градусника», и тогда работа по увеличению производительности разделяется на две задачи: оптимизация Hotspot-функций на микроархитектурном уровне и улучшение параллельности тех функций, которые есть в списке и которые недоиспользуют ресурсы микропроцессора.
Locks & Waits-анализ
Определив с помощью Concurrency-анализа функции, которые неэффективно выполняют параллельную работу, нам необходимо понять, что явилось тому причиной. Мы знаем, что потоки блокируются при попытке захвата уже занятых (другими потоками) элементов синхронизации или при вызове функций ввода-вывода. Наша цель – найти эти места в функциях и понять, насколько сильно они влияют на производительность параллельного приложения.
Например, захват потоком критической секции для выполнения короткой операции в теле функции, такой как обновление глобального флага или увеличение общего счетчика, не влечет к существенным проблемам блокирования потоков в обычном приложении. Однако если вы попробуете создать искусственный тест, где в единственном в программе цикле будет только короткая операция, «обернутая» критической секцией, то все потоки «столпятся» вокруг этой секции и большую часть своего времени будут проводить в ожидании ее освобождения. Чем больше будет потоков, тем существеннее будет проблема. Такой код часто называют highly contended. Мы должны обнаружить такие конструкции, если они есть в реальном приложении, и исключить интенсивное соперничество потоков за ресурс.
Другим примером может быть помещение в критическую секцию кода, выполняющего слишком большую работу (проблема гранулярности), когда свободные потоки ожидают освобождения ресурса слишком долго, простаивая и не выполняя полезной работы.
Использование функций ввода-вывода, таких как работа с объектами сериализации (вывод на экран, запись/чтение файла), блокирует работу потоков, так как такие системные функции могут выполняться только последовательно. Поэтому необходимо исключить использование таких объектов в вычислительно-нагруженной части приложения, работающей параллельно.
Профилировка приложения с помощью Locks & Waits-анализа поможет нам найти причину, почему не масштабируется приложение, какие функции ввода-вывода или объекты синхронизации мешают ему выполняться тем быстрее с увеличением количества потоков. Обратите внимание, что в суммарной характеристике (окно Summary) есть метрика, которая предоставляет оценку количества вызовов, приведших к блокировке потоков (Wait Count).
Главное окно Lock & Waits-анализа отображает список функций, исполнение которых было заблокировано в ожидании каких-либо объектов синхронизации. При этом, чем больше влияние такой функции на время исполнения программы, тем выше она в списке. По умолчанию, установлена группировка по объектам синхронизации, функциям ожидания и дереву их вызовов (Sync Object Name – Wait Function – Wait Function Tree). В данном случае функцией ожидания является та функция приложения, в которой потоки были заблокированы при попытке захвата данного объекта синхронизации. Раскрыв древовидный список объекта синхронизации, мы увидим, в какой функции потоки были заблокированы, и каким образом мы туда попали, то есть стэк вызовов.
Изменяя группировку объектов отображения в списке, мы можем получить распределение влияния объекта синхронизации по потокам, работавшим в приложении. Это может дать пользователю дополнительную информацию о занятости потоков в выполнении того или иного проблемного параллельного региона.
Что бы ни являлось причиной блокировки, будь то критическая секция, «накрывающая» большой и часто исполняемый в потоках участок кода, или WaitFor-функция, ожидающая события достаточно большое количество времени, с этим надо будет что-то делать уже самому разработчику приложения. Получив список «виновников» недостаточной масштабируемости программы, разработчик уже сам принимает решение, каким образом он изменит либо реализацию данного алгоритма, либо всю потоковую инфраструктуру в целом. Важно то, что он имеет объективную картину состояния с блокировками в программе и может оценить, сколько необходимо затратить усилий для переписывания софта, и какой в результате будет эффект.
Заключение
Intel Parallel Amplifier являет собой некое интегральное решение, объединяющее методологию профилировки параллельного приложения и являющееся «наследником» профилировщиков VTune Performance Analizer и Intel Thread Profiler. Пожалуй, главное отличие от предыдущих инструментов в том, что методология значительно упрощена и стала более понятной простым разработчикам, а не только опытным специалистам по оптимизации. Однако поскольку Intel Parallel Amplifier построен на базе новых технологий сбора данных, имеющих низкие накладные расходы, возможно, какой-то функциональности от VTune и Thread Profiler пользователям будет недоставать. Все замечания и пожелания по поводу функционала продукта можно разместить на ISN форумах, как англоязычном, так и русскоязычном. Тем более что для Intel Parallel Studio это будет основная модель поддержки клиентов.
Англоязычный форум http://software.intel.com/en-us/forums/intel-parallel-studio
Русскоязычный форум http://software.intel.com/ru-ru/forums/intel-parallel-studio
Сайт исследовательских проектов Intel http://whatif.intel.com
Комментарии