


В официальном блоге компании Nvidia появилась интересная запись, в которой рассказывается об особенностях первого поколения Maxwell. Первые продукты на архитектуре Maxwell, такие, как GeForce GTX 750 Ti, основаны на чипе GM107 и предназначены для использования в малопотребляющих устройствах – ноутбуках, компактных компьютерах и не только. Ключевым моментом Maxwell для разработчиков HPC и других GPU-приложений является большой скачок в энергоэффективности: почте вдвое по сравнению с архитектурой Kepler, что делает Maxwell отличной базой для будущих продуктов в линейке Nvidia Tesla.
В этом посте рассказывается о пяти главных вещах про Maxwell, которые следует знать разработчику GPU-приложений. Среди них - преимущества архитектуры, специфика нового потокового процессора Maxwell, руководства по настройке и ссылки на дополнительные ресурсы.
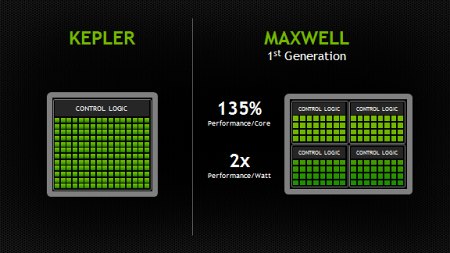
Сердце Maxwell: более эффективные мультипроцессоры
Потоковый процессор (SM) в Maxwell - его называют SMM - создан с нуля и обладает значительно большей энергоэффективностью по сравнению с предшественниками. Стоит отметить, что Kepler SMX был достаточно эффективен для своего поколения. В результате его создания инженеры Nvidia увидели новые возможности в повышении эффективности архитектуры GPU, которые и были реализованы в SM Maxwell. Улучшения коснулись механизмов распределения управляющей логики и нагрузки, гранулярности алгоритмов энергосбережения, планирования инструкций и количества исполняемых инструкций за такт, а также многих других аспектов, позволивших SM Maxwell намного опередить Kepler SMX по эффективности. Новая архитектура SM Maxwell позволила увеличить количество SM до пяти в GM107, в отличие от двух в GK107, при увеличении площади матрицы всего на 25%.
- Улучшенное планирование инструкций
Количество ядер CUDA в одном SM сократилось, однако с учетом возросшей эффективности исполнения в Maxwell (прирост производительность в расчете на SM составляет в пределах 10% от производительности Kepler) и более эффективных размеров SM, общее число ядер CUDA на GPU будет намного выше, чем у Fermi и Kepler. В Maxwell SM осталось то же самое количество планировщиков инструкций и уменьшены задержки на арифметических операциях по сравнению с Kepler.
Как и в SMX, в каждом SMM есть четыре warp-планировщика, но в отличие от SMX, все ключевые функциональные блоки SMM привязаны к определенному планировщику, а не делятся между ними. Количество ядер на один раздел теперь равно степени двойки, что упрощает планирование – каждый планировщик использует свой собственный набор ядер количеством равным размеру warp`а. Warp-планировщик может по-прежнему за один такт выполнять две инструкции (например, выполняя математическую операцию на CUDA-ядрах одновременно с выполнением операции обращения к памяти в блоке load/store), однако теперь можно полностью загрузить CUDA-ядра даже если планировщик отправляет на выполнение по одной инструкции.
- Увеличенная загрузка потоковых процессоров
SMM по многим аспектам похож на SMX архитектуры Kepler, при этом ключевые изменения нового типа процессоров направлены на повышение эффективности без необходимости значительного увеличения параллелизма в расчете на SM в приложении. Размер регистрового файла (64K 32-битных регистров), максимально количество warp`ов на SM (64 warp`а) и максимальное количество регистров (255 регистров) остались прежними. Максимальное количество блоков на потоковый мультипроцессор SMM удвоилось до 32, что должно привести к автоматическому увеличению загрузки для ядер, которые использую малый размер блока – 64 или меньше – в предположении, что регистры и разделяемая память не ограничивают загрузку мультипроцессора.
- Уменьшены задержки при выполнении арифметических инструкций
Еще одним значительным преимуществом SMM является уменьшение задержек выполнения арифметических инструкций. Так как загрузка мультипроцессора (которая преобразуется в параллелизм на уровне warp`ов) у SMM такая же или лучше, чем у SMX, сокращенные задержки улучшают использование CUDA-ядер и повышают скорость работы ядра.
Увеличенная выделенная общая память
В архитектуре Maxwell предусмотрено 64 кбайт разделяемой памяти, в то время как в Fermi или Kepler эта память делится между L1-кэшом и разделяемой памятью. В Maxwell один блок по-прежнему может использовать до 48 кбайт разделяемой памяти, причем увеличение общего объема разделяемой памяти может привести к увеличению загрузки мультипроцессора. Это стало возможным благодаря объединению функциональности L1-кэша и текстурного-кэша в отдельном блоке.
Быстрые атомарные операции в разделяемой памяти
В архитектуре Maxwell появились встроенные атомарные операции над 32-битными целыми числами в разделяемой памяти, а также CAS-операции над 32-битными и 64-битными значениями в разделяемой памяти – с помощью них можно реализовать другие атомарные функции. В случае Kepler и Fermi приходилось использовать сложный принцип "Lock/Update/Unlock", что приводило к дополнительным издержкам.
Динамический параллелизм
Динамический параллелизм, появившийся в Kepler GK110, позволяет GPU самому создавать задачи для себя. Поддержка этой функции была впервые добавлена в CUDA 5.0, позволяя нитям на GK110 запускать дополнительные ядра на том же GPU.
Теперь динамический параллелизм поддерживается во всей продуктовой линейке, включая даже такие экономичные чипы, как GM107. Разработчикам это на руку, так как теперь для приложений не требуется создавать специальные алгоритмы для high-end GPU, отличающиеся от тех, которые используются на графических процессорах более низкого уровня.
Подробнее о программировании Maxwell
Подробнее об архитектуре и оптимизации кода под Maxwell смотрите в Руководстве по настройке Maxwell и Руководстве по совместимости Maxwell, которые уже доступны для зарегистрированных разработчиков CUDA. Авторизуйтесь или бесплатно вступайте в сообщество уже сегодня.