

ВведениеДанная статья основана на тестах, публикуемых компанией CD-Adapco Group, в которых автор статьи принимал непосредственное участие.
В статье проводится сравнительный анализ производительности современных 64- и 32-разрядных распределенных вычислительных систем, с числом процессоров до 126. Отражено сравнение систем, как в «однопроцессорном», так и в многопроцессорном вариантах. Для каждой системы проводится анализ масштабируемости (сокращение времени расчета тестовой задачи в зависимости от числа задействованных в нем процессоров). Представлены краткие описания тестируемых систем, включая описание архитектуры вычислительных узлов и обеспечивающих их соединение, коммутационных интерфейсов. Для справки, по каждой системе приведены данные стандартного теста SPEC CPU2000.
Компьютерные технологии глубоко проникли в сферу научных и инженерных расчетов. Мало того, можно вспомнить, что именно потребности в высокопроизводительных вычислительных системах со стороны высокотехнологичных отраслей промышленности заставили в свое время бурно развиваться компьютерную индустрию.
Сегодня при проектировании изделий, будь то в аэрокосмической, автомобильной, железнодорожной или другой области, широко применяются системы автоматизированного проектирования. До того, как приступить к постройке прототипа изделия «в металле», его полностью моделируют на компьютерах, в системах автоматизированного проектирования (САПР). Хотя сегодня практически во всех «тяжелых» системах, таких как Dassault System CATIA, EDS Unigraphics, PTC ProEngineer, присутствуют различные модули, позволяющие проводить прочностные, гидравлические, газодинамические и другие расчеты, как правило, их возможности ограничиваются только проверочным уровнем. Для проведения детальных исследований в вышеперечисленных областях существуют специализированные программные комплексы, получившие название CAE систем (computer-aided engineering). Расчеты, проводимые в данных системах, требуют больших вычислительных ресурсов. Время выполнения одного расчета может занимать очень много времени — порядка дня, неделя или даже более месяца. Для кардинального снижения времени решения задач, практически все CAE системы имеют возможность работать в многопроцессорном режиме. Одной из таких систем является программный комплекс STAR-CD.Программный комплекс STAR-CD
STAR-CD — многоцелевой CFD (Computational Fluid Dynamics) программный комплекс, предназначенный для проведения расчетов в области механики жидкости и газа. STAR-CD не является единственным расчетным пакетом, охватывающим данную область, аналогичными возможностями обладают программные пакеты ANSYS-CFX и FLUENT.
Аббревиатура «STAR» означает Simulation of Turbulent flows in Arbitrary Regions (Моделирование турбулентных потоков в произвольных геометрических областях).
STAR-CD позволяет решать задачи в следующих областях:
- Стационарные и нестационарные течения
- Ламинарные течения
- Турбулентные течения
- Сжимаемые и несжимаемые (включая около- и сверхзвуковые)
- Теплоперенос (конвективный, радиационный, теплопроводность с учетом твердых тел)
- Массоперенос
- Химические реакции
- Горение газообразного, жидкого и твердого топлива
- Распределенное сопротивление (например, в пористых средах, теплообменниках)
- Многокомпонентные течения
- Многофазные потоки — модель Лагранжа (дисперсные газ-тв.тело, газ-жидкость, жидкость-тв.тело, жидкость-жидкость)
- Многофазные потоки — модель Эйлера
- Свободные поверхности
Входящий в комплекс пакет STAR-HPC (High Performance Computing) предназначен для осуществления решения подготовленных в препроцессоре задач на многопроцессорных вычислительных системах. Распределение задачи по аппаратным ресурсам происходит следующим образом: расчетная геометрическая область (сетка) равномерно разбивается на количество частей, равное заказанному количеству процессоров. После этого, для каждой части генерируется исполняемый код, который выполняется соответствующими процессорами и узлами. В случае, когда расчетный узел представляет собой SMP систему, ему приходится одновременно выполнять столько процессов, сколько на нем было заказано процессоров для решения.
Описание тестовых задач
Теперь перейдем к тестовым задачам. Задачи имеют сильно отличающуюся размерность, — первая имеет небольшую размерность и служит, в основном, для сравнительного анализа производительности однопроцессорных конфигураций. Вторая — имеет значительно большую размерность и поможет оценить производительность систем с большим числом процессоров.
 | ENGINE COOLING IN AUTOMOBILE ENGINE BLOCK
|
Расчет течения охлаждающей жидкости в рубашке охлаждения блока цилиндров автомобильного двигателя (чистая гидродинамика без теплопереноса). Тест представляет собой задачу небольшой размерности, которая, при решении на однопроцессорной системе требует менее 1ГБ оперативной памяти, количество ячеек приблизительно 150.000.
 | TURBULENT FLOW AROUND A-CLASS CAR
|
Расчет внешнего обтекания легкового автомобиля. Задача большой размерности, требующая, при выполнении на однопроцессорном компьютере более 4 ГБ оперативной памяти, количество ячеек — около 6.000.000.
32-разрядные системы теоретически не могут адресовать более 4 ГБ оперативной памяти, но, при вычислении на кластерах, задача делится на несколько процессов, выполняющихся на разных компьютерах (узлах). После деления задачи ее части требуют локально меньшего пространства в оперативной памяти и с некоторого момента могут быть вписаны в рамки 4 ГБ.
Учитывая вышесказанное, во втором тесте приводятся результаты для 32-разрядных систем, начиная с 4 процессоров.
Тестирование проводится на версии пакета STAR-CD 3.15. В качестве программного интерфейса обмена данными между узлами используется свободная реализация MPI (Message Passing Interface) — MPICH.
Постоянно обновляемые результаты представленного в этой статье тестирования расположены по этой ссылкеОписание вычислительных систем и результатыт тестов
В тестировании принимают участие следующие системы:
64-разрядные системы:
HP
- HP-RX5670 Itanium 2, 1.5 GHz
- HP-RX2600 Cluster, Itanium 2, 1.0 GHz
- HP-RX2600 Cluster, Itanium 2, 1.5 GHz
- HP-SUPERDOME, PA-8700+, 875 MHz
- HP-J6700, PA-8700, 750 MHz
HP-Compaq
- HP-Alpha ES40, Alpha 21264 (EV68) 833 MHz
- HP-Alpha ES45, Alpha 21264C (EV68C) 1.0 GHz
- HP-Alpha GS1280, Alpha 21364 (EV7) 1.15 GHz
IBM
- IBM P655 Cluster, POWER4, 1.3 GHz
- IBM P655 Cluster, POWER4, 1.7 GHz
SGI
- SGI ALTIX, Itanium 2, 900 MHz
- SGI ALTIX, Itanium 2, 1.0 GHz
- SGI ALTIX, Itanium 2, 1.5 GHz
- SGI ORIGIN-300, R14000A, 600 MHz
- SGI ORIGIN-3000, R14000A, 600 MHz
Sun
- SUN Fire 15000, UltraSparcIII 900 MHz
- SUN Blade 2000, UltraSparcIII 1.050 GHz
32-разрядные системы:*
- CADFEM, Hydra-6G, Cluster, i850, Pentium 4 2.2 GHz
- FSC Hpcline, Cluster, i860, XEON 2.4 GHz
- FSC Hpcline, Cluster, E7501, XEON 2.8 GHz
- NEC, Cluster, AMD 8xxx, Opteron 2.0 GHz
- NEC, Cluster, i875P, Pentium 4, 2.6 GHz
- CRAY Hpc, Cluster, E7501, XEON 3.06 GHz
- IBM eServer325, Cluster, Opteron 2.0 GHz
*Процессоры Opteron были отнесены к 32-разрядным системам исключительно по причине отсутствия на текущий момент времени реализации программы STAR-CD для платформы AMD-64.
Сравнение систем при условии выполнения тестовых задач на одном процессоре
Для начала приведем результаты тестирования систем на одном процессоре, рис. 1, 2, основным условием при его выполнении является достаточный объем оперативной памяти для полного размещения в ней задачи. Для справок приведем результаты тестирования тех же систем в тесте SPEC CPU2000, рис. 3, 4. К сожалению, полных данных по, уже ставшим эталонными, тестам LINPACK найти не удалось, поэтому для интересующихся здесь приведена только ссылка на отчеты по результатам этого теста: performance.netlib.org

Рис. 1. Тест «Engine», время выполнения тестовой задачи (Elapsed Time), для одного процессора.
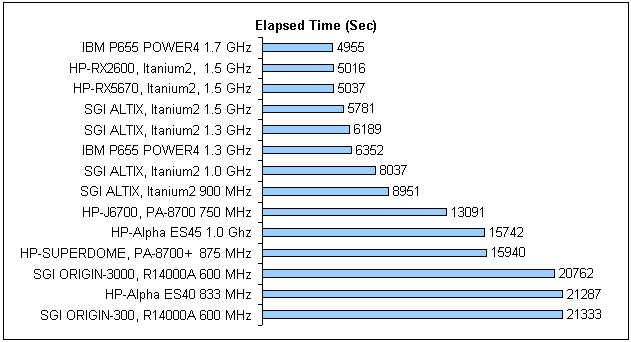
Рис. 2. Тест «A-Class», время выполнения тестовой задачи (Elapsed Time), для одного процессора.
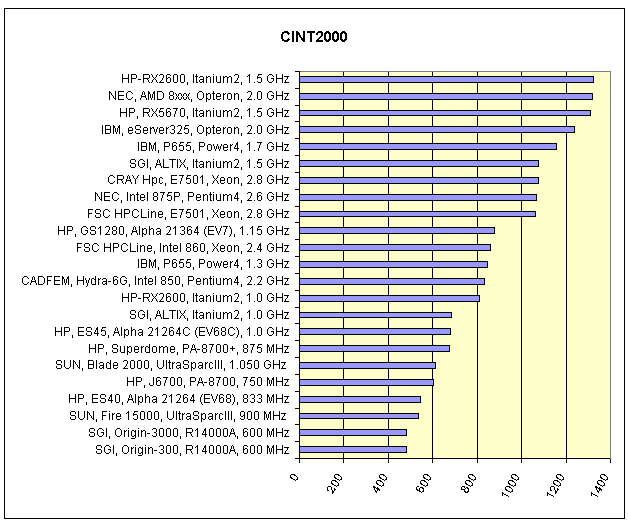
Рис. 3. Результаты SPEC-CINT2000, Result.
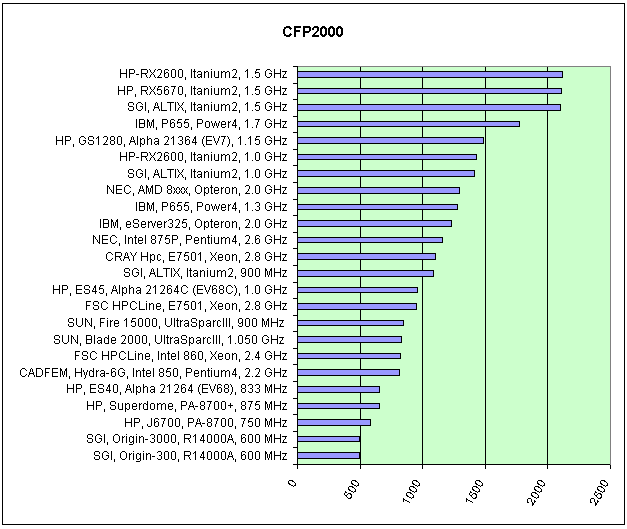
Рис. 4. Результаты SPEC-CFP2000, Result.
Теперь представим краткие описания систем и результаты, по их масштабируемости.64-разрядные системы
HP rx5670 server

Описание системы:
Сервер HP rx5670, построен на базе чипсета собственной разработки — zx1. В данном случае, чипсет представлен следующим набором логики: микросхема MIO (Memory and Input/Output Controller), включающая в себя контроллер процессорной шины, два контроллера памяти и контроллер ввода-вывода, две микросхемы — адаптеры расширения памяти SMA (Scalable Memory Adapter) и набор микросхем — адаптеров ввода-вывода. Блок-диаграмма чипсета zx1, в четырехпроцессорной конфигурации, представлена на рис. 5. Более подробную информацию о чипсете можно узнать по этой ссылке на сайте HP.

Рис. 5. 4-way hp zx1 chipset.
- Процессор: 4 процессора Intel Itanium 2 с частотой 1,5 GHz, кэш память: L3 — 6MB, L2 — 256 KB, L1 — 32KB (16KB — инструкции, 16KB — данные)
- Чипсет: HP zx1
- Память:
- Пропускная способность: 12.8 GB/s (2 канала х 4 порта)
- Тип: PC2100 ECC registered DDR266A SDRAM
- Максимальный объем: 96 GB
- Количество слотов: 48 DIMM на двух (по 24) платах расширения
- Шины: 3 x PCI-X 64/133, 6 x PCI-64/66, 1 x 6 x PCI-64/33
- Интерфейс жестких дисков: Ultra160 SCSI
- Операционная система: HP-UX 11i
Тест «Engine»
- Elapsed Time, 1CPU = 830.73
- Масштабируемость узла*:
- 2CPU = 2,02
- 4CPU = 4,60
Тест «A-Class»
- Elapsed Time, 1CPU = 5036.71
- Масштабируемость узла*:
- 2CPU = 1.57
- 4CPU = 1.94
Производительность системы по тестам SPEC (1CPU)**
- CINT2000: 1312
- CFP2000: 2108
* Здесь и далее, под масштабируемостью узла подразумевается отношение времени расчета задачи на одном процессоре к времени расчета на n процессорах.
** Подробное описание тестов на русском языке можно найти в статье «Тест SPEC CPU2000. Часть 1. Введение». Или на английском языке, на сайте организатора тестов www.spec.org
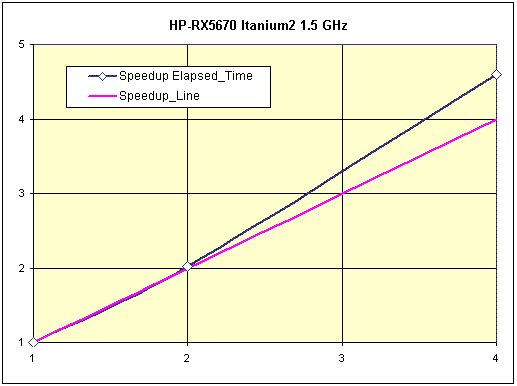
Рис. 6. Тест «Engine», масштабируемость системы.
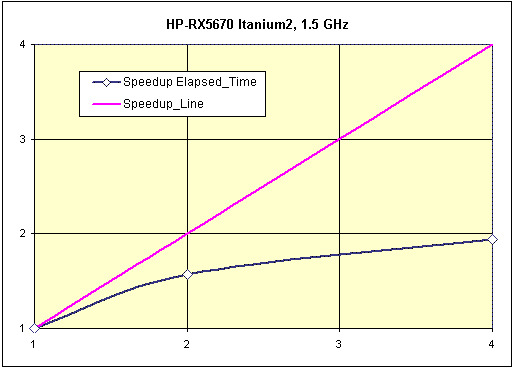
Рис. 7. Тест «A-Class», масштабируемость системы.
Комментарии:
Интересно сравнить данную систему с сервером rx2600 (см. ниже). Как в тесте «A-Class», так и в тестах SPEC rx2600 показывает несколько лучшие результаты, чем rx5670 (на одинаковых процессорах), несмотря на более высокую пропускную способность подсистемы памяти у rx5670. По всей видимости, здесь сказывается увеличение задержек при обращении к памяти за счет применения дополнительных контроллеров. Но масштабируемость заметно отличается в пользу rx5670. Здесь явно возрастает роль пропускной способности подсистемы памяти, несмотря на ее большую латентность. Тем не менее, связка из двух двухпроцессорных серверов rx2600 показывает лучшие результаты, чем один четырехпроцессорный сервер rx5670, как по масштабируемости, так и по времени выполнения теста.
HP rx2600 Cluster (Itanium 2, 1.0 GHz)

Описание системы:
Система состоит из 16 2-процессорных узлов, связанных между собою интерфейсом «Hyperfabric» (он же — Myrinet).
Межузловой интерфейс

- Пропускная способность между портами — 2,56 Gbit/s (full duplex) = 160 + 160 MB/s duplex
- Пропускная способность в приложениях MPI — 1.2 Gbit/s full duplex
- Латентность коммутатора — менее 500 ns
- Латентность протокола — менее 35 usec (MPI ping-pong test)
- Тип соединительных кабелей — «медь»
- Интерфейс адаптеров — PCI 64/66
- Поддерживаемые протоколы — TCP/IP, UDP, HP HMP (Hyper Messaging Protocol)
Коммутационное оборудование
- Hyperfabric A4891A 16-port copper switch
- HP A6092A PCI 64/66 HyperFabric Adapter
Расчетный узел:
Расчетный узел представляет собой двухпроцессорный сервер rx2600, построенный на чипсете zx1. Выше приводится описание четырехпроцессорной системы на основе этого чипсета. Двухпроцессорная конфигурация (рис. 8) отличается отсутствием адаптеров расширения памяти (SMA). В данном случае память подключается непосредственно к двум контроллерам, интегрированным в микросхему MIO (Memory and Input/Output Controller)
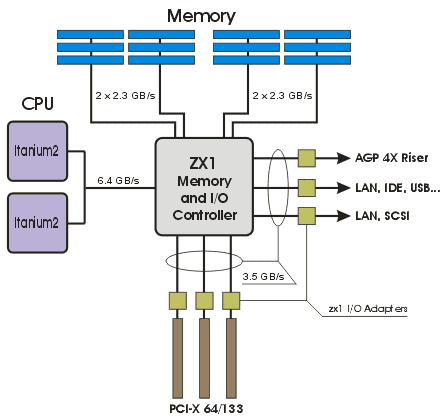
Рис. 8. 2-way hp zx1 chipset.
- Процессор: 2 процессора Intel® Itanium® 2 с частотой 1.0 GHz, кэш память: L3 — 3MB, L2 — 256 KB, L1 — 32KB (16KB — инструкции, 16KB — данные)
- Чипсет: HP zx1
- Память:
- Пропускная способность: 8.5 GB/s (2 канала х 2 порта)
- Тип: PC2100 ECC registered DDR266A SDRAM
- Максимальный объем: 24 GB
- Количество слотов: 12 DIMM
- Шины: — 4 x PCI-X 64/133
- Операционная система: HP-UX 11i
Тест «Engine»
- Elapsed Time, 1CPU = 1163.81
- Масштабируемость узла:
- 2CPU = 1,91
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 810
- CFP2000: 1427

Рис. 9. Тест «Engine», масштабируемость системы.
Комментарии:
Масштабируемость системы на высоком уровне. К сожалению, на данной системе не выполнялись оба теста, поэтому сложно дать развернутую оценку.
HP rx2600 server (Itanium 2, 1.5 GHz)
Описание системы:
Система состоит из 16 2-процессорных узлов, связанных между собою интерфейсом «HyperFabric2» (он же Myrinet2000)
Межузловой интерфейс

- Пропускная способность между портами — 4.0 Gbit/s (full duplex) = 320 + 320 MB/s duplex
- Пропускная способность в приложениях MPI — 2.4 Gbit/s full duplex
- Латентность коммутатора — менее 500 ns
- Латентность протокола — менее 22 usec (MPI ping-pong test)
- Тип соединительных кабелей — «медь»
- Интерфейс адаптеров — PCI 64/133
Коммутационное оборудование
- Myrinet M3-E64 Switch Enclosure (Fiber)
- Myrinet M3-SW16-8F 8-Port Line Card (8)
- HP A6386 PCI HyperFabric2 Adapter
Расчетный узел:
Подробное описание расчетного узла, смотрите выше.
- Процессор: 2 процессора Intel Itanium 2 с частотой 1.5 GHz, кэш память: L3 — 6MB, L2 — 256 KB, L1 — 32KB (16KB — инструкции, 16KB — данные)
- Чипсет: HP zx1
- Память:
- Пропускная способность: 8.5 GB/s (2 канала х 2 порта)
- Тип: PC2100 ECC registered DDR266A SDRAM
- Максимальный объем: 24 GB
- Количество слотов: 12 DIMM
- Шины PCI-X: — 4 x PCI-X 64/133
- Встроенные устройства: DVD-ROM, 10/100/1000BT LAN, Ultra320 SCSI, 10/100BT management LAN 3 x RS-232 serial ports
- Жесткие диски: 3 hot-plug SCSI отсека.
- Операционная система: HP-UX 11i
Тест «A-Class»
- Elapsed Time, 1CPU = 5016.41
- Масштабируемость узла:
- 2CPU = 1.49
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1322
- CFP2000: 2119
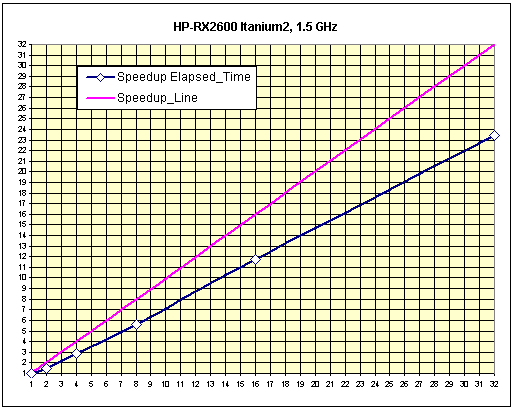
Рис. 10. Тест «A-Class», масштабируемость системы.
Комментарии:
См. комментарии к HP rx5670 и rx2600, выше.
HP 9000 Superdome 32-way

Описание системы:
HP Superdome — многопроцессорная система, построенная по ссNUMA технологии (cache-coherent, Non-Uniform Memory Access). В данной вычислительной системе реализована SMP (symmetric multi-processing) модель, позволяющая любому из процессоров использовать любую область памяти в системе.
HP Superdome 32-way состоит из 8 4-процессорных узлов, cвязанных между собой специализированной шиной, реализованной чипсетом HP Yosemite.
Чипсет HP Yosemite, имеет следующие интерфейсы: двухканальную шину памяти, четыре процессорные шины, одну коммутационную шину для связи с другими расчетными узлами и один порт ввода-вывода (рис. 11).
Коммутация между узлами реализована при помощи специализированной интегральной схемы «crossbar ASIC», работающей на частоте 500 MHz. Каждый чипсет связан с коммутатором «Crossbar Backplane» четырехканальной шиной с суммарной пропускной способностью 8 GB/s. Пропускная способность коммутатора 32 GB/s.
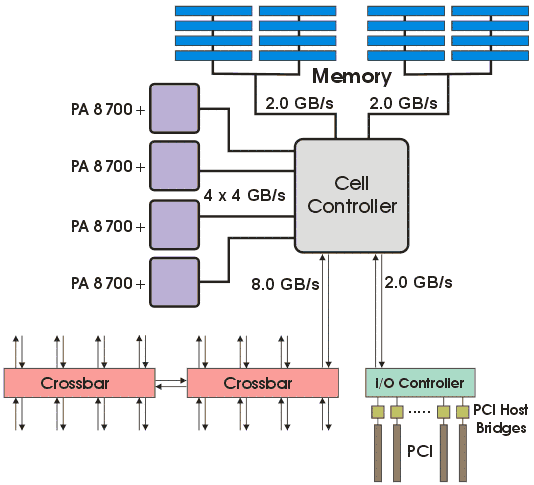
Рис. 11. Блок-диаграмма системы Superdome.
Расчетный узел:
- Процессор: 4 процессора PA-8700+ с частотой 875 MHz, кэш память: L1 2.25 MB (0.75 MB инструкции, 1.5 MB данные)
- Чипсет: HP Yosemite
- Память:
- Пропускная способность: 4 GB/s (2канала по 64 bit)
- Тип: ECC registered DDR 250 SDRAM
- Максимальный объем: 16 GB
- Количество слотов: 16 DIMM
- Дисковая подсистема: внешняя, через интерфейс Fiberchannel
- Операционная система: HP-UX 11i
Тест «Engine»
- Elapsed Time, 1CPU = 2251.32
Тест «A-Class»
- Elapsed Time, 1CPU = 15940.43
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 676
- CFP2000: 651

Рис. 12. Тест «Engine», масштабируемость системы.
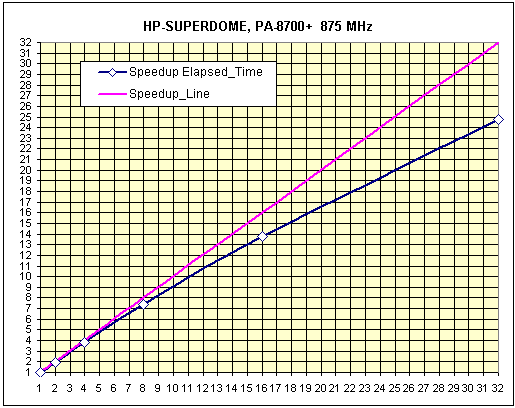
Рис. 13. Тест «A-Class», масштабируемость системы.
Комментарии:
Масштабируемость системы сильно зависит от пропускной способности и латентности шин, связывающих процессоры и узлы между собой. При прочих равных условиях, вычислительная способность процессора и узла также сильно влияет на масштабируемость, т.е. чем выше производительность процессора (узла), тем больше нагрузка на шины передачи данных и, как следствие, снижение показателя масштабируемости.
В данном случае производительность отдельного процессора относительно мала, что вкупе с высокоскоростной низколатентной шиной, позволяет достичь превосходных результатов системы в целом.
Так же, как и в предыдущих случаях, следует отметить падение масштабируемости с ростом размерности задачи.
Низкий результат для одного процессора, по сравнению с HP J6700 (см. ниже), возможно связан с особенностями архитектуры данной системы.
HP J6700 Cluster

Описание системы:
Система состоит из 8 2-процессорных узлов, связанных между собою интерфейсом Fast Ethernet, с пропускной способностью 100 Mbit/Sec.
Расчетный узел:
Расчетным узлом является рабочая станция HP J6700, ее блок-диаграмма представлена на рис. 14. Классическая SMP система, в которой «северный мост» обеспечивает взаимодействие двух процессоров с памятью и системой ввода-вывода.

Рис. 14. Блок-диаграмма HP J6700.
- Процессор: 2 процессора PA 8700 с частотой 750 MГц, кэш память: L1 2.25 MB (0.75 MB инструкции, 1.5 MB данные)
- Память:
- Пропускная способность: 1.6 GB/s (2 канала по 64bit)
- Тип: ECC SDRAM, 100MHz
- Максимальный объем: 16 GB
- Количество слотов: 16 DIMM
- Шины: 3x PCI 64/66
- Операционная система: HP-UX 11i
Тест «Engine»
- Elapsed Time, 1CPU = 1738.38
- Масштабируемость узла:
- 2CPU = 1.52
Тест «A-Class»
- Elapsed Time, 1CPU = 13091.44
- Масштабируемость узла:
- 2CPU = 1.32
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 603
- CFP2000: 581

Рис. 15. Тест «Engine», масштабируемость системы.
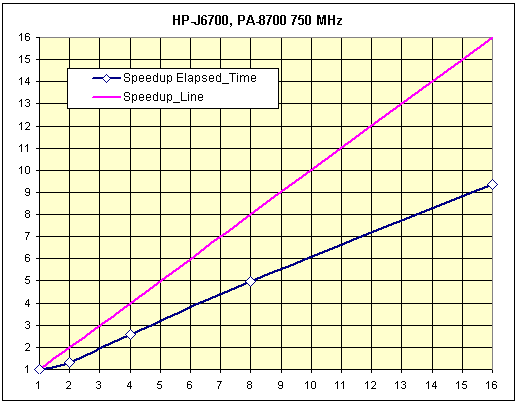
Рис. 16. Тест «A-Class», масштабируемость системы.
Комментарии:
См. комментарии к HP 9000 Superdome 32-way. В остальном, вполне прогнозируемый результат, без каких-либо неожиданностей — низкая пропускная способность и высокая латентность, присущая Fast Ethernet, дает низкие результаты масштабируемости системы. Тем не менее, тестирование этой системы показало, что программа STAR-CD нетребовательна к параметрам межузлового интерфейса, показывая хорошие результаты, даже на медлительном FastEthernet.
HP AlphaServer ES40 Cluster

Описание системы:
Система состоит из 8 4-процессорных узлов, связанных между собою интерфейсом «Quadrics».
Межузловой интерфейс

- Пропускная способность между портами — 6.4 Gbit/s (full duplex) = 400 + 400 MB/s duplex
- Пропускная способность в приложениях MPI — 2.6 Gbit/s full duplex
- Латентность коммутатора — 35-175 ns
- Латентность протокола — менее 4-5 usec (MPI ping-pong test)
- Тип соединительных кабелей — «медь»
- Интерфейс адаптеров — PCI-X 64/133
Расчетный узел:
Расчетный узел представляет собой сервер «Alphaserwer ES-40», Блок-диаграмма которого приведена на рис. 17. В сервере используется сложная система коммутации, организованная при помощи большого числа микросхем: «C» чип — обеспечивает интерфейс команд процессоров и памяти. «C» чип позволяет процессорам проводить транзакции одновременно. Восемь «D» чипов — обеспечивают интерфейс передачи данных для процессоров, памяти и системы ввода-вывода. Два P чипа — обеспечивают интерфейс четырех независимых шин PCI 64, или трех шин PCI 64 и одной AGP 4X.
Процессоры Alpha 21264 на плате расширения, вместе с кэш памятью второго уровня, монтируются в слоты на системной плате. Туда же, в специальные разъемы, монтируются платы с оперативной памятью.
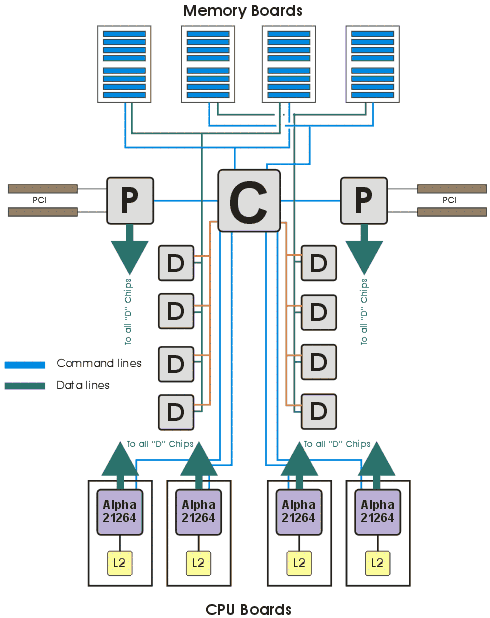
Рис. 17. Блок-диаграмма серверов ES 40/45.
- Процессор: 4 процессора Alpha 21264 (EV68) с частотой 833 MHz.
Кэш память: L2 8MB, L1 128KB (64 KB инструкции, 64 KB данные) - Память:
- Пропускная способность: 5.2 GB/s (2канала по 256 bit)
- Тип: ECC SDRAM 83 MHz
- Максимальный объем: 32 GB
- Количество слотов: 32 DIMM (по 8, на плату расширения)
- Шины: 6 x PCI 64/66, 4 x PCI 64/33. Опционально 1х AGP 4X
- Операционная система: Tru64 UNIX
Тест «Engine»
- Elapsed Time, 1CPU = 2232.23
- Масштабируемость узла:
- 4CPU = 5.58
Тест «A-Class»
- Elapsed Time, 1CPU = 21287.07
- Масштабируемость узла:
- 4CPU = 3.09
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 544
- CFP2000: 658

Рис. 18. Тест «Engine», масштабируемость системы.
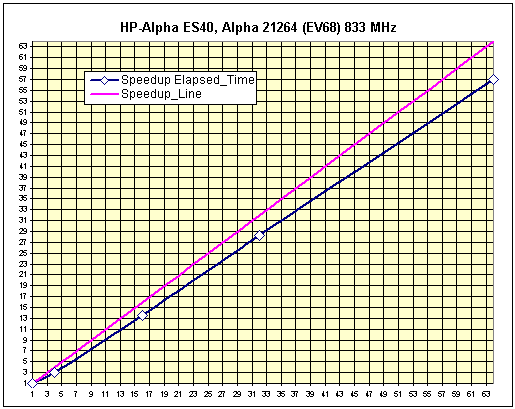
Рис. 19. Тест «A-Class», масштабируемость системы.
Комментарии:
Сочетание высокой пропускной способности и низкой латентности интерфейса «Quadrics» с относительно низкой производительностью узла дает максимальную отдачу системы в плане масштабируемости.
В пределах узла масштабируемость также на очень высоком уровне, что связано с оптимальной организацией взаимодействия компонентов в системе.
HP AlphaServer ES45 Cluster
Описание системы:
Система аналогична ES40, состоит из 8 4-процессорных узлов, связанных между собою интерфейсом «Quadrics» (см. выше).
Расчетный узел:
- Процессор: 4 процессора Alpha 21264C (EV68) с частотой 1000 MHz, кэш память: L2 8MB, L1 128KB (64 KB инструкции, 64 KB данные)
- Память:
- Пропускная способность: 8 GB/s (2 канала по 256 bit)
- Тип: ECC SDRAM 125 MHz
- Максимальный объем: 32 GB
- Количество слотов: 32 DIMM (по 8, на один процессор)
- Шины: 6 x PCI 64/66, 4 x PCI 64/33. Опционально 1x AGP 4X.
- Операционная система: Tru64 UNIX
Тест «Engine»
- Elapsed Time, 1CPU = 1598.37
- Масштабируемость узла:
- 4CPU = 4.92
Тест «A-Class»
- Elapsed Time, 1CPU = 15742.47
- Масштабируемость узла:
- 4CPU = 3.09
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 679
- CFP2000: 960

Рис. 20. Тест «Engine», масштабируемость системы.
Рис. 21. Тест «A-Class», масштабируемость системы.Комментарии:
Налицо падение масштабируемости, как для одного узла, так и для всей системы. Учитывая то, что архитектура системы идентична ES40, можно отметить, что повышение производительности одного процессора увеличило нагрузку на коммутационные шины, что сказалось на масштабируемости, хотя, в принципе, она осталась очень высокой.
HP AlphaServer GS1280

Описание системы:
Система состоит из восьми «процессорных» блоков, каждый из которых включает в себя четыре двухпроцессорных модуля, блок-схема такого модуля представлена на рис. 21.
Двухпроцессорные модули подключаются к специальной плате, которая реализует межпроцессорное взаимодействие. Между собой блоки соединяются специализированной шиной.
Взаимодействие между процессорами происходит по коммутационным каналам с пропускной способностью 6.2 GB/s. В каждом процессоре имеется четыре коммутационных порта (северный, южный, западный и восточный), через которые они осуществляют связь между собой. В конфигурациях серверов GS1280, имеющих до 32 процессоров, для связи процессоров задействуются только два порта — северный и южный. В данной, 64-процессорной конфигурации, задействованы все четыре порта.
Процессоры связаны между собой по схеме «двумерный тор», рис. 22. Подсистема ввода-вывода реализована в виде отдельного блока.
Связь между процессорными модулями и блоком ввода-вывода осуществляется за счет соединения I/O портов процессоров с портами соответствующего контроллера.
Блок ввода-вывода реализует интерфейсы PCI/PCI-X, AGP, Ultra3 SCSI и др.
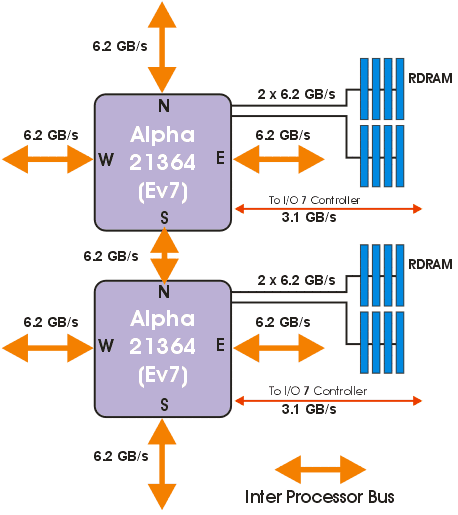
Рис. 21. Блок-диаграмма двухпроцессорного модуля сервера GS1280.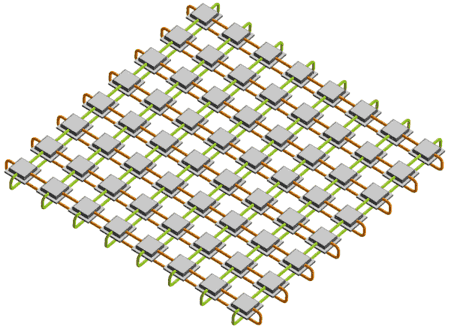
Рис. 22. Схема межпроцессорного соединения сервера GS1280.Расчетный узел:
- Процессор: 8 процессоров Alpha 21364 (EV7) с частотой 1150 MHz, кэш память: L2 1.75MB, L1 128KB (64 KB инструкции, 64 KB данные)
- Память:
- Пропускная способность: 12,3 GB/s (8 каналов по 16Bit)
- Тип: ECC RDRAM 800 MHz
- Максимальный объем: 32 GB (при установке RIMM модулей, емкостью 512MB)
- Количество слотов: 8 RIMM / процессор
- Дисковая система: внешняя
- Операционная система: Tru64 UNIX
Тест «Engine»
- Elapsed Time, 1CPU = 960.50
- Масштабируемость двухпроцессорного модуля:
- 2CPU = 2.04
- Масштабируемость в пределах процессорного блока:
- 4CPU = 4.18
- 8CPU = 8.47
Тест «A-Class»
- Elapsed Time, 1CPU = ?
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 877
- CFP2000: 1482

Рис. 23. Тест «Engine», масштабируемость системы.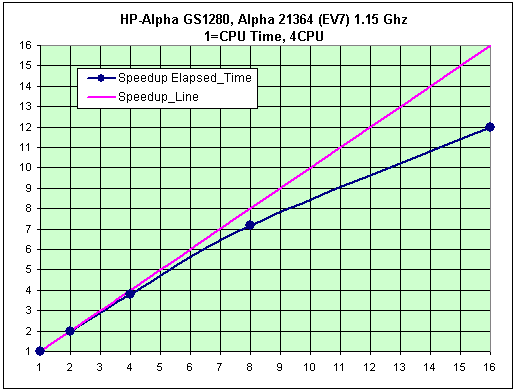
Рис. 24. Тест «A-Class», масштабируемость системы, за единицу принято время расчета тестовой задачи на 4-х процессорах.Комментарии:
Новая система, базирующаяся на архитектуре EV7, дает в данных тестах прирост производительности порядка 70% относительно систем на базе архитектуры EV6, при практически одинаковой частоте процессора. При этом масштабируемость системы держится на очень высоком уровне.
IBM eServer pSeries 655 Cluster

Описание системы:
Кластер, собран на основе серверов IBM pSeries 655, которые располагаются по два в одном корпусе. Связь между серверами осуществляется при помощи интерфейса SP Switch2, подробное описание которого можно найти по адресу: www-1.ibm.com.
Межузловой интерфейс:
SP Switch2 — высокоскоростной интерфейс передачи данных, типа «точка-точка».
- Пропускная способность между портами — 1000 MB/s (MPI Bi-directional)
- Латентность коммутатора — менее 1.5 usec
- Латентность — менее 18 usec (MPI)
- Тип соединительных кабелей — «медь»
- Интерфейс адаптеров — PCI-X
Расчетный узел:
IBM pSeries 655, представляет собой 4—8-процессорный SMP (symmetric multiprocessing) сервер. Сервер работает на одном процессоре Power4 или Power4+, MCM (multichip module), который объединяет четыре процессорных одноядерных или двуядерных чипа. Чипы имеют интегрированную кэш память второго уровня, также в них интегрированы контроллеры оперативной памяти и кэша третьего уровня. Кэш третьего уровня — внешний, располагается на системной плате в качестве отдельного модуля. Его объем равен 32 MB для каждого чипа. Оперативная память располагается на четырех картах расширения, включающих в себя по восемь несъемных модулей PDIMM. Процессоры, с частотой 1.3 и 1.7 GHz имеют одно ядро на чип, с частотой 1.0 и 1.5 GHz — два ядра. В тесте принимают участие системы на базе процессоров Power4 1.3 GHz и Power4+ 1.7 GHz. Блок-диаграмма процессорного блока представлена на рис. 25.
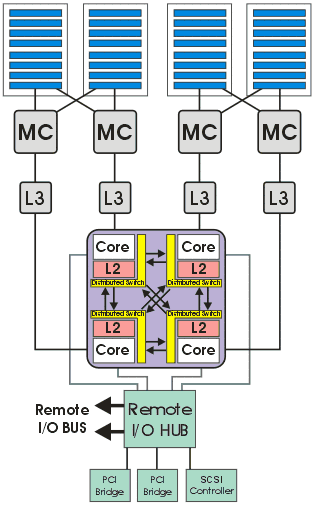
Рис. 25. Блок-диаграмма процессорного блока сервера IBM pSeries 655.- Процессор: Power4 1.3 GHz (4 ядра), Power4+ 1.7 GHz (4 ядра), кэш память: L3 32MB/ядро, L2 1.5MB/ядро, L1 96KB/ядро (32KB данные, 64 KB инструкции).
- Память:
- Максимальный объем: 64 GB
- Количество слотов: 4 специализированных карты памяти, имеющих до восьми несъемных модулей PDIMM.
- Операционная система: AIX5
Тест «Engine»
- Elapsed Time, 1CPU = 539.10
- Масштабируемость узла:
- 2CPU = 1.98
- 4CPU = 3.91
Тест «A-Class»
- Elapsed Time, 1CPU = 4955.17
- Масштабируемость узла:
- 2CPU = 1.57
- 4CPU = 3.48
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1158
- CFP2000: 1776
Power4 1.3 GHz
Тест «Engine»
- Elapsed Time, 1CPU = 705.36
- Масштабируемость узла:
- 2CPU = 1.94
- 4CPU = 3.73
Тест «A-Class»
- Elapsed Time, 1CPU = 6352.44
- Масштабируемость узла:
- 2CPU = 1.89
- 4CPU = 3.33
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 848
- CFP2000: 1281

Рис. 26. Тест «Engine», масштабируемость системы, 1 расчетный узел.
Рис. 27. Тест «A-Class», масштабируемость системы, 8 расчетных узлов.
Рис. 28. Тест «Engine», масштабируемость системы 4 расчетных узла.
Рис. 29. Тест «A-Class», масштабируемость системы, 8 расчетных узлов.Комментарии:
Несмотря на то, что по тестам SPEC процессоры Power4+, 1.7 GHz уступают Itanium2, 1.5 GHz, в данных тестах Power4+ показал лучшие результаты. Объяснением этому может служить наличие у процессоров Power4 большeго объема кэш памяти, которая, в данном случае, позволяет более эффективно использовать ресурсы процессора.
При увеличении размерности задачи масштабируемость узла падает незначительно, что подчеркивает высокую производительность межпроцессорной коммутации внутри MCM.
Стоит также отметить рост масштабируемости с увеличением частоты процессоров с 1.3 до 1.7 GHz, это связано с возросшей пропускной способностью межчиповых соединений.
SGI Altix 3000, Intel Itanium 2 900/1000/1500 MHz

Описание системы:
SGI Altix 3000 создан на базе архитектуры с распределенной совместно используемой памятью — «NUMAflex DSM» (distributed shared memory architecture) третьего поколения, сокращенно именуемой «NUMA3». Система использует глобальную адресацию памяти. Позволяет строить домены, расширяемые до 64 процессоров Itanium 2 с когерентной кэш памятью.
В NUMA3 архитектуре все процессоры и оперативная память связаны вместе в единую систему с помощью специальных коммутаторов «R-bricks», данная система коммутации называется «NUMAlink».
Основной «строительный блок» NUMAlink, «C-brick», содержит два процессорных модуля, каждый из которых включает чипсет «Super-Bedrock ASIC» и два процессора. Между собой чипсеты соединяются через один канал NUMAlink с пропускной способностью 6.4 ГБ/c. Коммутация блоков «C-brick» осуществляется через 8-портовый роутер «R-brick», позволяющий объединять до 4 блоков (16 процессоров). Для создания систем с большим количеством процессоров предусмотрена коммутация роутеров между собой. Блок-диаграммы расчетного узла «C-Brick» и всей системы приведены на рис. 30 и рис. 31, соответственно.
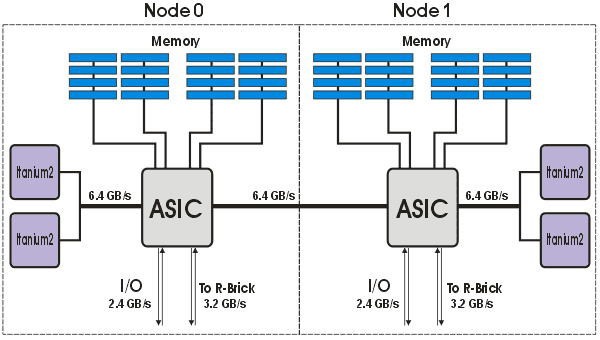
Рис. 30. Блок-диаграмма расчетного узла «C-Brick».
Рис. 31. Блок-диаграмма системы Altix.Межузловой интерфейс:
NUMAlink — высокоскоростной интерфейс передачи данных.
- Пропускная способность между внешними портами блоков — 2 х 1,6 GB/s
- Тип соединительных кабелей — «медь»
Расчетный узел:
- Процессор: 2 модуля, в одном корпусе, по 2 процессора Intel Itanium 2 с частотой 900/1000/1500 MHz, кэш память:L3 1.5 Mb/3 Mb/6 Mb (0.9/1.0/1.5 GHz), L2 — 256 KB, L1 — 32KB (16KB — инструкции, 16KB — данные)
- Чипсет: Super-Bedrock ASIC
- Память:
- Пропускная способность: 8.5 GB/s (4 канала)
- Тип: PC2100 ECC registered DDR266 SDRAM
- Максимальный объем: 64 GB
- Количество слотов: 32 DIMM (по 16 на два процессора)
- Шины: Устанавливаются отдельным узлом, соединенным через внешний интерфейс с расчетными узлами.
- Операционная система: Linux
Тест «Engine»
Itanium2 900 MHz
- Elapsed Time, 1CPU = 1144.00
- Масштабируемость узла:
- 2CPU = 1.90
- 4CPU = 3.97
Itanium2 1000 MHz
- Elapsed Time, 1CPU = 1046.00
- Масштабируемость узла:
- 2CPU = 2.06
- 4CPU = 4.30
Itanium2 1500 MHz
- Elapsed Time, 1CPU = 703.00
- Масштабируемость узла:
- 4CPU = 4.68
Тест «A-Class»
Itanium2 900 MHz
- Elapsed Time, 1CPU = 8951.00
- Масштабируемость узла:
- 4CPU = 3.66
Itanium2 1000 MHz
- Elapsed Time, 1CPU = 8037.00
- Масштабируемость узла:
- 4CPU = 3.60
Itanium2 1500 MHz
- Elapsed Time, 1CPU = 5781.00
- Масштабируемость узла:
- 4CPU = 3.47
Производительность системы по тестам SPEC (1CPU)
- Itanium2 1500 MHz
- CINT2000: 1077
- CFP2000: 2100
- Itanium2 1000 MHz
- CINT2000: 683
- CFP2000: 1410
- Itanium2 900 MHz
- CINT2000: ?
- CFP2000: 1090

Рис. 32. Тест «Engine», масштабируемость системы.
Рис. 33. Тест «A-Class», масштабируемость системы.
Рис. 34. Тест «Engine», масштабируемость системы.
Рис. 35. Тест «A-Class», масштабируемость системы.
Рис. 36. Тест «Engine», масштабируемость системы.
Рис. 37. Тест «A-Class», масштабируемость системы.Комментарии:
На рост производительности одного процессора влияет, как рост частоты, так и рост объема кэша.
При росте производительности одного процессора, общая производительность не падает, а наоборот, растет. Это говорит о том, что система NUMAlink обладает достаточным запасом пропускной способности, а повышение масштабируемости связано с увеличением объема кэша процессоров.
SGI Origin 300

Описание системы:
SGI Origin 300 представляет собой DSM (distributed shared memory) систему. Состоит из четырех четырехпроцессорных узлов, объединенных в единую вычислительную систему при помощи коммутатора NUMAlink 3. Блок-диаграмма системы представлена на рис. 38.
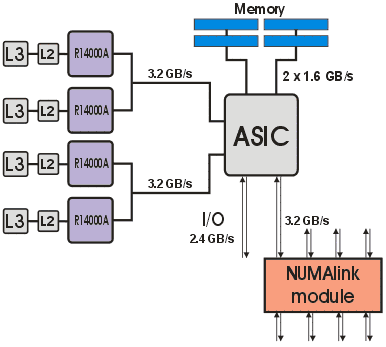
Рис. 38. Блок-диаграмма расчетного узла.Межузловой интерфейс:
NUMAlink — высокоскоростной интерфейс передачи данных.
- Пропускная способность между внешними портами блоков — 2 х 1,6 GB/s
- Тип соединительных кабелей — «медь»
Расчетный узел:
- Процессор: 4 процессора MIPS R14000A с частотой 600 MHz, кэш память: L3 кэш 8 MB, L2 4 MB, L1 64KB (32KB данные, 32 KB инструкции).
- Память:
- Пропускная способность: 3.2 GB/s (2 канала)
- Тип: ECC registered DDR 200 SDRAM PC1600
- Максимальный объем: 4 GB
- Количество слотов: 4 DIMM
- Операционная система: Irix
Тест «Engine»
- Elapsed Time, 1CPU = 2298.00
- Масштабируемость узла:
- 2CPU = 2.00
- 4CPU = 4.12
Тест «A-Class»
- Elapsed Time, 1CPU = 21333.00
- Масштабируемость узла:
- 4CPU = 2.98
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 483
- CFP2000: 495

Рис. 39. Тест «Engine», масштабируемость системы.
Рис. 40. Тест «A-Class», масштабируемость системы.Комментарии:
См. комментарии к SGI Origin 3000.
SGI Origin 3000

Описание системы:
SGI Origin 3000 представляет собой DSM (distributed shared memory) систему. Состоит из 32 четырехпроцессорных узлов, объединенных в единую вычислительную систему при помощи системы коммутации NUMAlink 3. Блок-диаграмма расчетного узла «C-Brick» приведена на рис. 41. Блок-диаграмма коммутации 128-процессорной системы представлена на рис. 42.
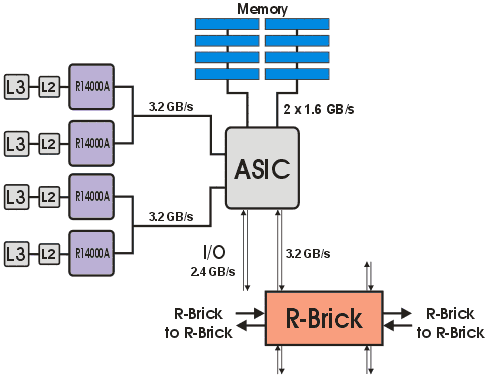
Рис. 41. Блок-диаграмма расчетного узла «C-Brick».
Рис. 42. Блок-диаграмма коммутации системы Origin 3000.Межузловой интерфейс:
NUMAlink — высокоскоростной интерфейс передачи данных.
- Пропускная способность между внешними портами блоков — 2х 1,6 GB/s
- Тип соединительных кабелей — «медь»
Расчетный узел:
- Процессор: 4 процессора MIPS R14000A с частотой 600 MHz, кэш память: L3 кэш 8 MB, L2 4 MB, L1 64KB (32KB данные, 32 KB инструкции).
- Память:
- Пропускная способность: 3.2 GB/s (2 канала)
- Тип: ECC registered DDR 200 SDRAM PC1600
- Максимальный объем: 8 GB
- Количество слотов: 8 DIMM
- Операционная система: Irix
Тест «A-Class»
- Elapsed Time, 1CPU = 20762.00
- Масштабируемость узла:
- 4CPU = 2.95
Производительность системы по тестам SPEC (1CPU)
- Аналогично Origin 300

Рис. 43. Тест «A-Class», масштабируемость системы.Комментарии:
Процессоры MIPS R1xxxx, к сожалению, обладают низкой производительностью, по сравнению со своими конкурентами. Более новые процессоры R16000, с частотой 700 MHz, работают несколько быстрее (см. сводную диаграмму на рис. 55), но общей картины не меняют. Для укрепления на рынке высокопроизводительных систем, компания SGI обратилась к технологиям Intel и стала производить системы собственной разработки на базе процессоров Itanium2.
По поводу масштабируемости: как и для систем Altix, в Origin применяется технология NUMALink для межпроцессорных связей, которая обладает большим запасом пропускной способности, что подтверждает сверхлинейный прирост производительности на задаче «A-Class», рис.43.
Sun Fire 15000

Описание системы:
Sun Fire 15000 представляет собой DSM (distributed shared memory) систему. Состоит из восемнадцати четырехпроцессорных узлов, объединенных в единую вычислительную систему, при помощи коммутатора Fireplane, обладающей пропускной способностью 9.6 Gb. Блок-диаграмма Sun Fire 15000 представлена на рис. 44.

Рис. 44. Блок-диаграмма системы Sun Fire 15000.Расчетный узел:
«Процессорный» блок включает в себя четыре процессора и оперативную память. Система ввода-вывода подключается в виде отдельных модулей.
- Процессор: 4 процессора UltraSPARC III с частотой 900 MHz, кэш память: L2 — 8 MB, L1 — 96KB (32KB — инструкции, 64KB — данные)
- Память:
- Пропускная способность: 2.4 Gb/s (4 канала)
- Тип: ECC registered SDRAM, 150 MHz
- Максимальный объем: 32 GB
- Количество слотов: 32 DIMM
- Операционная система: Solaris
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 535
- CFP2000: 844
Комментарии:
См. ниже, комментарии к Sun Blade 2000.
Sun Blade 2000

Описание системы:
Sun Blade 2000 — двухпроцессорная рабочая станция, построенная на процессорах UltraSPARCIII. Процессоры имеют встроенные контроллеры оперативной памяти, общаются между собой по шине FirePlane с пропускной способностью 4.8 GB/s. Блок-диаграмма рабочей станции представлена на рис. 45.

Рис. 45. Блок-диаграмма системы Sun Blade 2000.Расчетный узел:
- Процессор: 4 процессора UltraSPARC III с частотой 1050 MHz, кэш память: L2 — 8 MB, L1 — 96KB (32KB — инструкции, 64KB — данные)
- Память:
- Пропускная способность: 6.4 Gb/s (4 канала x 128 bit)
- Тип: ECC registered SDRAM, 100 MHz
- Максимальный объем: 8 GB
- Количество слотов: 8 DIMM
- Операционная система: Solaris
Тест «Engine»
- Elapsed Time, 1CPU = 1833.15
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 610
- CFP2000: 827
Комментарии:
Обе системы от Sun показали низкие результаты производительности (См. рис. 1, 55, 56), остается надеяться на развитие технологии SPARC в будущем.32-разрядные системы
Учитывая то, что информация по 32-разрядным платформам легкодоступна, мы не будем заострять внимание на их архитектуре. Укажем лишь наименование наборов микросхем, используемых в системах.
CAD-FEM, Hydra-6G

Описание системы:
Система состоит из 6 однопроцессорных узлов, связанных между собою интерфейсом Gigabit Ethernet
Расчетный узел:
- Процессор: 1 процессор Intel Pentium 4 с частотой 2,2 GHz, FSB 400MHz
- Чипсет: Intel 850
- Память:
- Пропускная способность: 3.2 GB/s
- Тип: RDRAM PC800
- Максимальный объем: 2 GB
- Количество слотов: 4 RIMM
- Шины: PCI — 6 x PCI 32/33
- Жесткие диски: 1 x UDMA-100
- Операционная система: RedHat Linux 7.3
Тест «Engine»
- Elapsed Time, 1CPU = 1454.11
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 833
- CFP2000: 818

Рис. 46. Масштабируемость системы.Комментарии:
Кластер, конфигурация которого выбиралась из расчета максимальной эффективности по критерию цена/производительность.
Fujitsu Siemens Computers, Hpcline, FastEthernet

Описание системы:
Система состоит из 8 двухпроцессорных узлов, связанных между собой интерфейсом Fast Ethernet.
Расчетный узел:
- Процессор: 2 процессора Intel Xeon с частотой 2,4 GHz, FSB 400MHz
- Чипсет: Intel 860
- Память:
- Пропускная способность: 3.2 GB/s
- Тип: RDRAM PC800 ECC
- Максимальный объем: 2 GB
- Количество слотов: 4 RIMM
- Шины: PCI — 2 x PCI 64/66 4 x PCI 32/33
- Операционная система: Linux
Тест «Engine»
- Elapsed Time, 1CPU = 1149.52
- Масштабируемость узла:
- 2CPU = 1.59
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 859
- CFP2000: 825

Рис. 47. Тест «Engine», масштабируемость системы.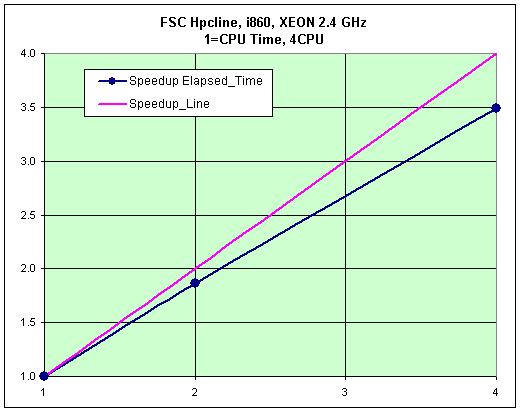
Рис. 48. Тест «A-Class», масштабируемость системы, за единицу принято время расчета тестовой задачи на 4 процессорах (2 узла).Комментарии:
Низкая масштабируемость обусловлена характеристиками интерфейса FastEthernet.
Заметно сильное снижение производительности при использовании двухпроцессорных узлов, по отношению к однопроцессорным, что связано как с относительно низкой масштабируемостью внутри узла (1.59 — 1 узел/2 процессора против 1.96 — 2 узла/2 процессора), так и с возрастающей вычислительной мощностью узла — растет нагрузка на сеть.
Fujitsu Siemens Computers, Hpcline, Myrinet-2000
Описание системы:
Система состоит из 32 двухпроцессорных узлов, связанных между собой интерфейсом Myrinet 2000, характеристики которого приведены выше.
Расчетный узел:
- Процессор: 2 процессора Intel Xeon с частотой 2.8 GHz, FSB 533MHz
- Чипсет: Intel E7501
- Память:
- Пропускная способность: 4.3 GB/s (2 канала по 64 bit)
- Тип: Registred ECC DDR 266
- Максимальный объем: 12 GB
- Количество слотов: 6 DIMM
- Операционная система: Linux
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1061
- CFP2000: 947
Комментарии:
Данная система представлена только в тесте «A-Class», ее результаты можно увидеть на сводной диаграмме (рис. 55).
NEC Opteron Cluster

Описание системы:
Система состоит из 16 двухпроцессорных узлов, связанных между собой интерфейсом Gigabit Ethernet.
Расчетный узел:
- Процессор: 2 процессора AMD Opteron 246 с частотой 2.0 GHz
- Чипсет: AMD 8xxx
- Память:
- Пропускная способность: 5.33 GB/s (2 канала)
- Тип: Registred ECC DDR 333
- Максимальный объем: 8 GB
- Количество слотов: 8 DIMM
- Операционная система: Linux
Процессоры Opteron в данных тестах работали в 32-разрядном режиме.
Тест «Engine»
- Elapsed Time, 1CPU = 716.61
- Масштабируемость узла:
- 2CPU = 1.90
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1239
- CFP2000: 1231

Рис. 49. Тест «Engine», масштабируемость системы.
Рис. 50. Тест «A-Class», масштабируемость системы, за единицу принято время расчета тестовой задачи на 4-х процессорах (2 узла).Комментарии:
Процессоры Opteron246 показали высокую производительность. Mасштабируемость, в пределах узла, является практически линейной. Это сказывается на повышенной загрузке межузлового интерфейса, что приводит к относительно низкой масштабируемости кластера.
NEC Pentium-4 Cluster, GigabitEthernet
Описание системы:
Система состоит из 32 однопроцессорных узлов, связанных между собой интерфейсом Gigabit Ethernet.
Расчетный узел:
- Процессор: 1 процессор, Pentium 4, с частотой 2.6 GHz
- Чипсет: Intel 875P
- Память:
- Пропускная способность: 6.4 GB/s (2 канала)
- Тип: ECC DDR 400
- Максимальный объем: 2 GB
- Количество слотов: 4 DIMM
- Операционная система: Linux
Тест «Engine»
- Elapsed Time, 1CPU = 756.00
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1067
- CFP2000: 1160

Рис. 51. Тест «Engine», масштабируемость системы.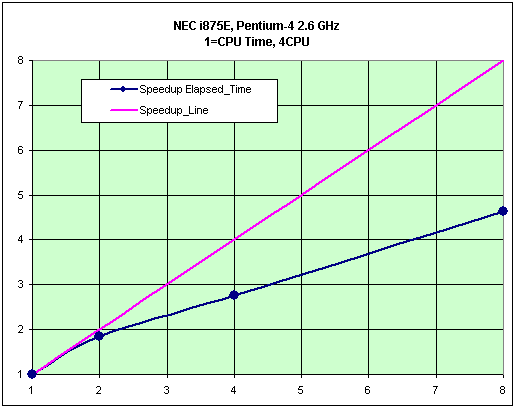
Рис. 52. Тест «A-Class», масштабируемость системы, за единицу принято время расчета тестовой задачи на 4-х процессорах (4 узла).Комментарии:
Сравнивая производительность систем на базе процессоров Intel Xeon, 3.06 GHz, и Intel Pentium 4, 2.6 GHz, можно отметить, что программа STAR-CD критична к пропускной способности процессорной шины и памяти, т.к. система на процессоре с частотой 2.6 GHz дает лучшие результаты.
Использование большого количества мощных однопроцессорных узлов сильно загружает GigabitEthernet. Учитывая примерно равную производительность процессоров Pentium 4 2.6 GHz и Opteron246 в тесте «Engine», можно отметить, что в данном случае для построения многопроцессорных кластеров на GigabitEthernet выгоднее использовать меньшее число более мощных узлов.
CRAY HPC Cluster, GigabitEthernet
Описание системы:
Расчет проводился на пяти узлах, связанных между собой интерфейсом Gigabit Ethernet.
Расчетный узел:
- Процессор: 2 процессора Intel Xeon с частотой 3.06 GHz
- Чипсет: Intel E7501
- Память:
- Пропускная способность: 4.3 GB/s
- Тип: Registred ECC DDR 266 (2 канала)
- Максимальный объем: 6 GB
- Количество слотов: 6 DIMM
- Операционная система: Linux
Тест «Engine»
- Elapsed Time, 1CPU = 997.05
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1074
- CFP2000: 1103

Рис. 53. Тест «Engine», масштабируемость системы.Комментарии:
К сожалению, весьма мало данных было снято с этой системы, но, тем не менее, отметим, что масштабируемость узла значительно ниже, чем у систем на базе процессоров Opteron. В данном случае, с точки зрения производительности системы, выгоднее использовать однопроцессорные узлы. Сравнивая результаты с системой на базе Xeon, 2.8 GHz, и Myrinet2000 (рис. 55), очевидно преимущество интерфейса Myrinet2000.
IBM eServer325 Cluster

Описание системы:
Система состоит из 32 двухпроцессорных узлов, в качестве межузлового интерфейса используется Myrinet 2000.
Расчетный узел:
- Процессор: 2 процессора Opteron 246 с частотой 2.0 GHz
- Чипсет: AMD 8xxx
- Память:
- Пропускная способность: 5.33 GB/s
- Тип: Registred ECC DDR 333 (2 канала)
- Максимальный объем: 6 GB
- Количество слотов: 6 DIMM
- Дисковая подсистема: Ultra320 SCSI
- Операционная система: SuSE Linux 8
Процессоры Opteron в данных тестах работали в 32-разрядном режиме.
Тест «Engine»
- Elapsed Time, 1CPU = 941.74
- Масштабируемость узла:
- 2CPU = 2.04
Производительность системы по тестам SPEC (1CPU)
- CINT2000: 1239
- CFP2000: 1231

Рис. 54. Тест «Engine», масштабируемость системы.Комментарии:
Очевиден прирост производительности по сравнению с аналогичной системой NEC Opteron Cluster, основанной на GigabitEthernet (рис.55).Выводы
Один процессор
Для многопроцессорных систем, приведенных в тестировании, данные по решению задач на одном процессоре имеют некоторую погрешность, по той причине, что физически в расчетном узле установлено несколько процессоров, и некоторые отклонения, по сравнению с системой с честно установленным одним процессором, в любом случае, будут. Особенно это касается больших SMP систем, типа Superdom. Как правило, эти отличия составляют порядка 2—5%. Связаны они, в первую очередь, с обслуживанием подсистемы ввода-вывода. Но так как во время выполнения задачи обращение к дисковой подсистеме минимизировано, вполне можно ориентироваться на эти данные.
Тестирование систем, в однопроцессорной конфигурации, подтвердило лидерство «топовых» 64-разрядных решений от IBM и Intel, на процессорах Power4+ и Itanium2. Хотя Itanium2 лидирует в тестах SPEC, при решении задач в рассматриваемом программном пакете, наблюдается его отставание от Power4+, здесь сказывается огромный размер кэш памяти у процессоров от IBM. Возможно, с появлением процессоров Itanium2 c увеличенным размером кэш памяти третьего уровня до девяти мегабайт ситуация изменится в его пользу. Хорошие результаты показал процессор Alpha 21364. К сожалению, после слияния HP и Compaq ожидать бурного развития линейки этих процессоров не приходится. 64-разрядные процессоры других производителей сильно отстают от лидеров. Как известно, HP и SGI давно смотрят в сторону IA64 и, похоже, решили оставить собственные разработки. Компания Sun, похоже, решила обратить свои взгляды на процессоры Opteron от AMD.
Современные 32-разрядные процессоры практически не уступают своим 64-разрядным собратьям в производительности, за тем лишь исключением, что не могут адресовать больше 4 ГБ памяти и тем самым решать большие задачи. Но при работе в кластере объем требуемой адресуемой памяти для одного процессора при увеличении количества узлов сокращается. Таким образом, становится возможным решение задач большой размерности, используя недорогие 32-разрядные решения. Правда, в этом случае остро встает вопрос по постановке больших задач и обработке их результатов, для чего также требуется большое количество памяти. Выходом из этой ситуации может послужить использование отдельной 64-разрядной рабочей станции, которую при желании можно использовать в качестве внешнего терминала и управляющего узла.
Один узел
Масштабируемость в рамках одного узла сильно зависит от размерности задачи. Она падает, когда размерность задачи увеличивается.
Системы, базирующиеся на архитектуре неоднородного доступа к памяти (NUMA), имеют преимущества в масштабируемости перед классическими симметрично-многопроцессорными (SMP) решениями. Например, в тесте «A-Class», HP rx5670 server показывает на четырех процессорах коэффициент масштабируемости 1.94, а расчетный узел SGI Altix, на тех же четырех процессорах Itanium2 1.5 GHz, показывает результат 3,47. Для теста «Engine» — 4.60 и 4.68, соответственно. Та же картина наблюдается, если сравнивать 32-разрядные системы. Система на синхронном чипсете Intel 860, на двух процессорах Intel Xeon, показывает коэффициент масштабируемости 1.59, в то время как системы на базе процессоров Opteron, в тесте «Engine», показывают результаты 1.9 и 2.04.
Система в целом
Весомым элементом, наряду с производительностью процессора и расчетного узла, определяющим производительность многопроцессорной системы, является интерфейс межузловой коммутации. От межузлового интерфейса зависит, в какой степени будут реализованы возможности процессоров. Чем ниже пропускная способность интерфейса и выше его латентность, тем больше задержки при передаче данных между процессорами и, соответственно, ниже суммарная вычислительная мощность системы.
Для наглядности приведем сводную диаграмму, отображающую время выполнения «большой» задачи (A-Class), всеми системами. Задача «Engine» имеет меньшую значимость по причине слишком малого расчетного времени, требуемого на ее выполнение.
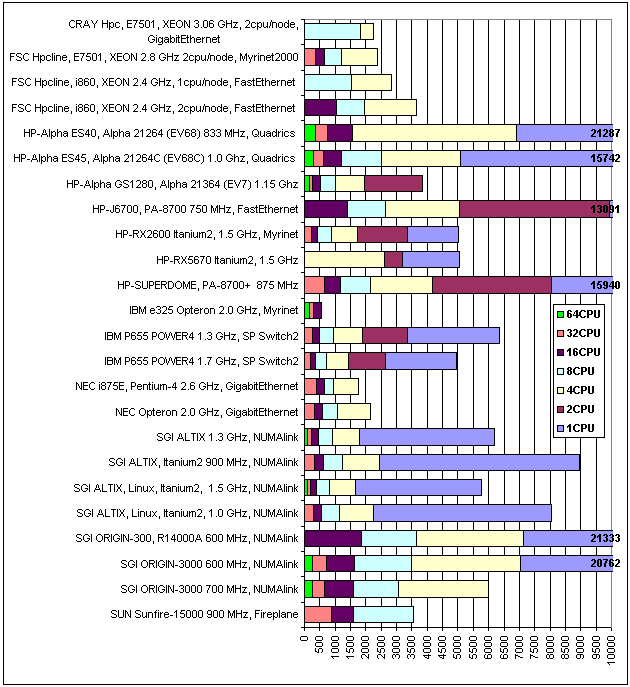
Рис.55. Время выполнения тестовой задачи «A-Class», в секундах.
Рис.56. В другом масштабе, для наглядности.На рис. 56 системы отсортированы по времени выполнения задачи для 16 процессоров. Вышеприведенное утверждение насчет влияния межузлового интерфейса на производительность систем, может проиллюстрировать перераспределение «призовых мест», с увеличением задействованных в решении процессоров.
В ряде случаев наблюдается получение сверхлинейного прироста производительности. Данному явлению можно дать следующее объяснение: одному процессору при выполнении задачи приходится работать с большим массивом данных, располагающимся в оперативной памяти. При разбиении расчетной области на части, массив данных равномерно разбивается на количество частей, равное количеству процессоров. Массив данных, обрабатываемый одним процессором, уменьшается, и вместе с тем увеличивается относительный объем данных, который может содержаться в кэш памяти. Таким образом, повышается как эффективность работы одного процессора, так и всей системы.
Обобщая данные по масштабируемости систем, можно выделить основные, влияющие на нее, факторы:
- Производительность процессора
- Масштабируемость в пределах узла
- Производительность межузлового интерфейса
В общем случае зависимость масштабируемости от числа процессоров выглядит, как показано на рис. 57.
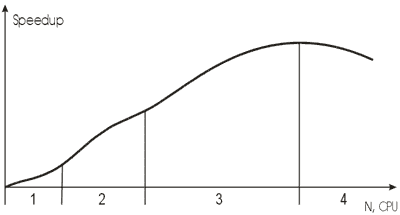
Рис.57. Общая картина масштабируемости систем.Зона 1 — это прирост скорости вычислений, в рамках одного расчетного узла.
Зона 2 — плавный рост масштабируемости. Размер части задачи, отданной на выполнение одному узлу, достаточно велик, значительного изменения в масштабируемости внутри узла не происходит.
Зона 3 — в начале — интенсивное увеличение масштабируемости. Размерность задачи уменьшается до оптимальных пределов, возрастает эффективность кэш памяти процессоров, повышается масштабируемость в пределах узла. Далее следует уменьшение интенсивности и выход графика «в горизонт» из-за нарастающих задержек, связанных с межузловым интерфейсом.
Зона 4 — падение масштабируемости. Трафик межузлового обмена данными возрастает настолько, что характеристик интерфейса становится недостаточно для своевременной передачи данных между узлами.Заключение
Программа STAR-CD (STAR-HPC) очень хорошо адаптирована для работы на многопроцессорных системах. При решении задач в многопроцессорном режиме, между расчетными узлами устанавливается обмен данными с относительно низким объемом трафика, который умеренно растет с увеличением числа и вычислительной мощности узлов. Это в первую очередь подтверждают достойные результаты, полученные в системах даже с очень медленным интерфейсом FastEthernet. Интерфейс GigabitEthernet показал хорошие результаты масштабируемости. Учитывая относительно низкую стоимость оборудования, системы, построенные на GigabitEthernet, бесспорно обладают наилучшим соотношением цена/производительность для систем с количеством узлов примерно до 16—20. Использование высокопроизводительных межузловых интерфейсов, типа Myrinet, становится оправданным в случае, когда количество процессоров становится больше 16.
Благодарности:
Выражаю свою искреннюю благодарность представительству CAD-FEM в странах СНГ (www.cadfem.ru) и лично Михаилу Стародубцеву за помощь, оказанную при написании статьи.