На сегодняшний день, двухъядерные процессоры, пожалуй, представляют большую половину продукции, выпускаемой двумя ведущими производителями процессоров. С точки зрения подсистемы памяти, отличаются эти процессоры как внутренней ее организацией (в частности, способом организации L2-кэша — раздельного для каждого из ядер или общего для обоих ядер), так и организацией ее внешнего интерфейса (наличием либо отсутствием интегрированного контроллера памяти и типом памяти, который поддерживает данный контроллер). Совершенно понятно, что для наиболее полного изучения этой подсистемы необходимо использование для доступа в кэш/память не только одного, но и обоих ядер процессора. В таком режиме можно обнаружить определенные аспекты функционирования подсистемы памяти, принципиально скрытые от наблюдения при традиционном «одноядерном» подходе. Кроме того, одновременное обращение двух ядер к оперативной памяти может способствовать достижению большей величины реальной пропускной способности памяти, т.е. в большей степени отражать характеристики самой оперативной памяти (т.к. «узким местом» может являться скорость обмена данными внутри самого процессора).
Учитывая важность указанных выше обстоятельств, мы включили в состав новой версии тестового пакета RightMark Memory Analyzer (RMMA) 3.7 небольшое (его размер — всего 48 КБ) вспомогательное тестовое приложение, получившее название «RightMark Multi-Threaded Memory Test» (сокращенно — RMMT). Решение сделать это приложение отдельным было принято в связи с изначальной «низкоуровневой» направленностью основного тестового приложения RMMA, рассчитанного в первую очередь на изучение микроархитектурных деталей ядра процессора, нежели аспектов «многоядерного» взаимодействия при доступе в кэш процессора или оперативную память. В то же время, идеология вспомогательного приложения RMMT в существенной степени отличается от идеологии самого RMMA.
Рассмотрим внешний вид RightMark Multi-Threaded Memory Test.
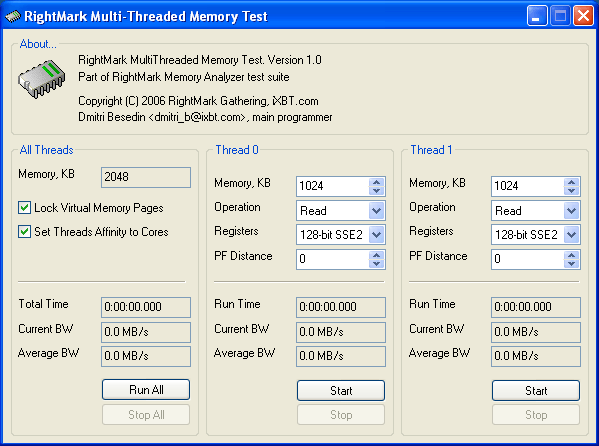
Легко видеть, что в этом приложении принципиально отсутствует какая-либо информация о самом процессоре и платформе — все это предоставляется основным приложением RMMA. Для теста RMMT важно лишь количество присутствующих в системе «системных процессоров» — не важно каких, физических или виртуальных. С помощью RMMT можно изучать поведение подсистемы памяти при отдельном, либо совместном обращении к памяти как на традиционных SMP-системах (2 и более физических процессоров), так и на платформах класса Pentium 4 с технологией Hyper-Threading (2 логических процессора) и, конечно, же, современных двухъядерных процессорах (2 физических ядра, каждое из которых может содержать в себе 1 или 2 логических процессора). Не исключена поддержка и комбинированных решений — например, SMP-систем на базе двухъядерных процессоров. В соответствии с количеством «системных процессоров» приложением выбирается количество потоков, используемых для обращения к памяти, однако в текущей версии программы это количество не может превышать 8 потоков.
Общая (по отношению ко всем потокам) информация отображается в разделе «All Threads». Здесь отображается общий объем оперативной памяти, используемой всеми потоками (Memory, KB), а ниже доступны следующие опции:
Lock Virtual Memory Pages — «удерживает» выделенные каждым потоком страницы памяти в оперативной памяти, т.е. препятствует их вытеснению в page-файл операционной системой.
Set Threads Affinity to Cores — задает строгое соответствие между номером потока и номером исполняющего его физического/логического процессора, иными словами, осуществляет строгую «привязку» потоков к соответствующим процессорам.
Обе опции включены по умолчанию. Ниже расположены информационные поля:
Total Time — отображает общее время работы теста. Каждый новый запуск отдельного потока прибавляет к этому времени время исполнения данного потока. Легко убедиться, что при одновременном запуске двух потоков показание общего времени теста будет увеличиваться в удвоенном темпе. Ничего странного в этом нет — то же самое происходит при подсчете общего процессорного времени операционной системой на многопроцессорных платформах.
Current BW — показывает общую текущую пропускную способность, являющуюся суммой показаний текущей пропускной способности по всем потокам. Под «текущей» пропускной способностью имеется в виду ее «мгновенное» значение, полученное по секундному интервалу обновления информации, принятого в этом тесте по умолчанию.
Average BW — показывает общую усредненную пропускную способность. Аналогично показанию «Current BW», эта величина является суммой усредненной пропускной способности по всем потокам. Под «усредненной» пропускной способностью подразумевается величина пропускной способности, оцененная по всему времени работы теста (т.е. общее количество байт, поделенных на общее время теста).
Элементы управления тестом представлены кнопками «Run All» и «Stop All», назначение которых достаточно очевидно — они осуществляют одновременный запуск (с точностью до времени создания и инициализации каждого из потоков) и одновременную остановку (с точностью до завершения работы и уничтожения каждого из потоков) всех тестовых потоков.
Операции с каждым из потоков осуществляются в разделах «Thread 0», «Thread 1» и т.д. — как мы уже говорили выше, их количество равно количеству присутствующих в системе процессоров, но не может превышать 8.
Параметры теста для каждого из потоков задаются следующими опциями:
Memory, KB — объем используемого блока памяти (от 1 КБ до 1 ГБ). При запуске теста, каждый из потоков выделяет и работает с собственной областью памяти. Более того, при задании опции «Set Threads Affinity to Cores» память размещается в «своем» пространстве, что может быть полезно, например, при изучении многопроцессорных платформ с архитектурой NUMA.
Operation — вид операции обращения к памяти. Возможные варианты:
- «Read» — обычное линейное чтение данных. Полезно при доступе в L2-кэш процессора и для оценки «средней» реальной пропускной способности памяти;
- «Read w/PF» — чтение с программной предвыборкой. Полезно для достижения максимальной реальной пропускной способности памяти;
- «Write» — обычная линейная запись данных. По аналогии с «Read», данный режим теста позволяет оценить пропускную способность L2-кэша на запись и «среднюю» реальную пропускную способность памяти;
- «Write NT» — запись данных методом прямого сохранения (Non-Temporal store), минуя иерархию кэшей процессора. Позволяет оценить максимальную реальную пропускную способность памяти на запись.
Registers — тип регистров процессора, используемых для чтения/записи данных. Варианты — «64-bit MMX» (обращения с помощью MOVQ reg, [mem]; MOVQ [mem], reg и MOVNTQ [mem], reg) и «128-bit SSE2» (MOVDQA reg, [mem]; MOVDQA [mem], reg и MOVNTDQ [mem], reg).
PF Distance — величина дистанции программной предвыборки, в байтах. Возможные значения — от 0 до 4096 байт с шагом 64 байта (с таким же шагом, равным длине строки L2-кэша современных процессоров, проведена расстановка самих инструкций предвыборки в тесте чтения с программной предвыборкой). Данная настройка актуальна только для режима «Read w/PF».
Размещенные в нижней половине показатели «Run Time», «Current BW» и «Average BW» существенно аналогичны рассмотренным выше общих показателей для всех потоков, поэтому опустим их рассмотрение. Очевидно также, что кнопки «Start» и «Stop», относящиеся к каждому из потоков, позволяют запускать и останавливать данный поток в любой момент времени. Таким образом, тест RMMT позволяет изучать как однопоточное обращение к кэшу процессора или оперативной памяти (со стороны любого ядра), так и одновременное обращение к кэшу/памяти произвольной комбинацией присутствующих процессорных ядер, физических или логических процессоров.


