Тестирование современных многопроцессорных систем в среде LS-DYNA
Введение
В сети встречается много информации по тестированию всевозможных аппаратных платформ на различном программном обеспечении. К сожалению, не всегда можно сделать выводы по быстродействию для той или иной системы на основании результатов тестирования другой программы — не той, которую используешь. Особенно это касается многопроцессорных систем, которые могут вести себя совершенно непредсказуемо, не только в зависимости от программы, но и от задачи, решаемой в ней. Нередки случаи, когда двух и более процессорные системы выдают нулевой или даже отрицательный рост скорости вычислений.
Эта статья является результатом тестирования, которое проводилось с целью определения выигрыша в производительности двухпроцессорных систем для расчетов в программном комплексе LS-DYNA. Также одной из задач являлось сравнение двухпроцессорных систем с производительностью PC-кластеров с малым числом узлов, (тема вычислительных кластеров будет рассмотрена в следующей статье, здесь будет изложена только минимально необходимая информация).
Коротко о среде тестирования
LS-DYNA — многоцелевой конечно-элементный комплекс разработки Livermore Software Technology Corp. (LSTC) — предназначена для анализа высоконелинейных и быстротекущих процессов в задачах механики твердого и жидкого тела. Разработка данного программного продукта была начата в начале 70х годов. Первая коммерческая версия программы выпущена в 1976 г. Программа была первой в своей области и послужила основой для всех современных пакетов высоконелинейного анализа, оставаясь на лидирующих позициях до сегодняшнего дня. Предназначение LS-DYNA: нелинейная динамика, теплоперенос, теплообмен, термомеханика, разрушение и развитие трещин, контакт, квазистатика, Эйлерово и произвольное Лагранж-Эйлерово поведение (Arbitrary Lagrangian-Eulerian, ALE), акустика, многодисциплинарный связанный анализ (взаимодействие потоков жидкостей и газов с деформируемой конструкцией, например, колебания жидкости в баках, связанные термомеханические задачи и др.). LS-DYNA содержит более 130 уравнений состояния материалов и 25 контактных алгоритмов. Помимо основной явной центрально-разностной схемы в программу включены также неявные методы — разреженных матриц, предопределенных сопряженных градиентов, Ланцоша. Для тепловых задач допускается 4 схемы — явная Эйлера (прямой ход); Кренка-Николсона; Галеркина; чисто неявная схема (обратный ход). Более подробно, (на русском языке) о программе LS-DYNA вы можете узнать по этой ссылке.
В числе приложений: моделирование взрывов, краш-тестов, сейсмика, обработка металлов давлением и др. Исследование поведения материалов (прокат листовой и объемный, ковка, глубокая листовая штамповка-вытяжка, экструдирование, и пр.).
Программный код полностью распараллелен и векторизован (первые версии LS-DYNA работали на компьютерах CDC-7600 и CRAY-1). Поддерживается декомпозиция заданий на сетевых кластерах (в т.ч. из персональных компьютеров).
LS-DYNA существует для всех современных аппаратных платформ: IA-32, WindowsNT / Linux; IA-64 HPUX, Windows XP-64, Linux-64; HP-HPUX; SGI-IRIX; Sun-Solaris; IBM-AIX; и др. Версии для разных платформ выходят практически одновременно, что очень удобно для проведения сравнения всего спектра вычислительной техники, производимой сегодня в мире.
Описание тестовой задачи
В качестве теста использовалась одна из типовых «связанных» задач, в данном случае — взаимодействие структуры (снаряд, труба) и жидкости (грунт) : «воздействие взрыва на заглубленный объект» (рис. 1), подробное описание которой можно найти в интернете по адресу: underg_expl.zip, 1.06МБ. Выбор именно связанной задачи обоснован тем, что такие задачи наиболее сильно нагружают вычислительную систему.
По условию задачи заряд тротила массой 1000 кг с начальной скоростью 1000 м/с и углом падения a = 30° проникает в грунт над объектом, расположенном на глубине 8 м от поверхности. Объект представлял собой отрезок стальной трубы с закрытыми торцами длинной 10 м, диаметром 1 м и толщиной стенки 10 мм. На глубине 2 м происходил подрыв заряда.
Целью расчета являлось моделирование процесса проникания снаряда, образования взрывной воронки, а также расчет кинематики и НДС (напряженно-деформированного состояния) объекта.
Построение расчетной области было проведено в препроцессоре ANSYS/LS-DYNA. Размерность модели составила около 280000 элементов.
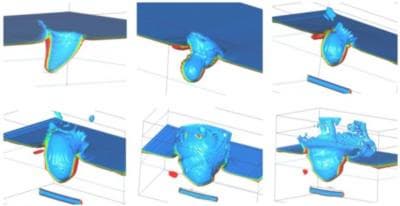
Рис. 1. Распределение плотности грунта в различные моменты времени после взрыва.
и видео ролик (139 КБ) для иллюстрации
Условия тестирования
Использовались версии программы: LS-DYNA 960SMP и LS-DYNA 960MPP (кластерная версия программы).
Тест для одно-двухпроцессорных машин проводился под операционной системой Windows 2000 Professional, для кластера — под Linux RedHat 7.3. Выбор операционных систем был продиктован традициями, сложившимися в расчетных отделах организаций (наших, отечественных) использующих данный программный продукт. Выбор конкретной версии Linux основывался на рекомендациях производителя программы.
Во всех тестах задача полностью помещалась в оперативной памяти компьютера, что практически устраняет влияние на время расчета операций с жестким диском (исключалась работа своп файла). Размер задачи в оперативной памяти для одно-двухпроцессорных конфигураций (LS-DYNA 960SMP) составил 329 МБ, для кластерной версии (LS-DYNA 960MPP) 693МБ (примерно по 100МБ/узел). Объем оперативной памяти на всех тестируемых конфигурациях — не менее 512MБ.
Аппаратные платформы
Тестирование проводилось на платформах, представленных в таблице 1.
Пояснения к таблице 1:
- n — номер позиции (таблица отсортирована по результатам — чем ниже строка, тем лучше).
- N, cpu — количество процессоров, занятых в тесте
- N, cpu, installed — количество процессоров, установленных на плату (наблюдается некоторое различие результатов при работе двухпроцессорных систем на одном процессоре, в случае, когда задача считается на одном процессоре, при установленных двух и в случае, когда физически установлен только один процессор.
- Freq/P-Rating — Частота, для процессоров Intel и P-рейтинг для процессоров AMD.
- FSB — Частота шины
- Mem type — тип оперативной памяти. В этой колонке, в тех пунктах, где рассматриваются системы с двухканальным контроллером памяти (NVIDIA nForce2 и Intel E7505), поставлены примечания: DCh — память работает в двухканальном режиме, SCh — память работает в одноканальном режиме.
- Mem freq — частота памяти
- Chipset — тип системной логики (чипсет)
- Mother Board — тип материнской платы
- OS — операционная система, W — MS Windows 2000Pro, SP1. L — Linux RedHat 7.3. Другие операционные системы в тесте не рассматривались. Linux RedHat 7.3 использовалась только на кластере, но по тесту, который был проведен на одном узле, можно судить о разнице в работе программы под разными О.С.
- Колонки CPU Time и Elapsed time — описаны подробно ниже, при рассмотрении гистограмм.
| n | CPU Type | n, cpu | n, cpu, installed | Freq / P-rating | FSB | Mem type | Mem freq | Chipset | Mother Board | os | CPU_Time, sec | Elapsed_Time, sec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Pentium III | 1 | 2 | 450 | 100 | SDR | 100 | intel 440BX | ASUS, P2B-D | W | 17416 | 17421 |
| 2 | Pentium III | 1 | 1 | 700 | 100 | SDR | 100 | intel 440BX | Gigabyte BX2000+ | W | 12624 | 12636 |
| 3 | Pentium III | 1 | 1 | 700 | 100 | SDR | 100 | intel 440BX | Gigabyte BX2000+ | W | 12524 | 12540 |
| 4 | Pentium III | 2 | 2 | 450 | 100 | SDR | 100 | intel 440BX | ASUS, P2B-D | W | 11287 | 11292 |
| 5 | Pentium III | 1 | 1 | 800 | 100 | SDR | 100 | intel 440BX | ASUS, P3B-F | W | 10855 | 10889 |
| 6 | Pentium III | 1 | 1 | 1000 | 133 | SDR | 133 | VIA 694X | ASUS, CUV4X-E | W | 10546 | 10560 |
| 7 | Pentium III | 1 | 1 | 933 | 133 | SDR | 133 | intel 440BX | ASUS, P3B-F | W | 9127 | 9134 |
| 8 | Athlon XP | 1 | 1 | 1800+ | 266 | SDR | 133 | VIA KT133A | Soltek, SL-75KAV | W | 5573 | 5580 |
| 9 | Pentium 4 | 1 | 1 | 2000 | 400 | DDR | 266 | intel 845PE | ASUS, P4PE | W | 5080 | 5125 |
| 10 | Athlon XP | 1 | 1 | 2200+ | 266 | SDR | 133 | VIA KT133A | Soltek, SL-75KAV | W | 4941 | 4972 |
| 11 | Xeon (P4) | 1 | 1 | 2000 | 400 | DDR, DCh | 200 | Intel E7505 | Intel, SE7505VB2 | W | 4912 | 4924 |
| 12 | Xeon (P4) | 1 | 2 | 2000 | 400 | DDR, DCh | 200 | Intel E7505 | Intel, SE7505VB2 | W | 4810 | 4859 |
| 13 | Pentium 4 | 1 | 1 | 2000 | 400 | RDR | 400 | Intel 850 | ASUS, P4T-E | W | 4785 | 4814 |
| 14 | Xeon4 | 1 | 1 | 2000 | 400 | RDR | 400 | Intel 860 | Iwill, DP-400 | W | 4748 | 4787 |
| 15 | Xeon (P4, wHT) | 1 | 1 | 2000 | 400 | DDR, DCh | 200 | Intel E7505 | Intel, SE7505VB2 | W | 4578 | 4589 |
| 16 | Pentium 4 | 1 | 1 | 2200 | 420 | RDR | 420 | Intel 850 | ASUS, P4T-E | W | 4371 | 4406 |
| 17 | Athlon MP | 1 | 2 | 2200+ | 266 | DDR | 266 | AMD 760MPX | ASUS, A7M266-D | W | 4329 | 4353 |
| 18 | Pentium 4 | 1 | 1 | 2666 | 533 | DDR | 266 | intel 845PE | P4PE, i845PE | W | 4173 | 4208 |
| 19 | Pentium 4 | 1 | 1 | 2400 | 480 | RDR | 480 | Intel 850 | ASUS, P4T-E | W | 4136 | 4158 |
| 20 | Athlon XP | 1 | 1 | 1800+ | 266 | DDR, DCh | 266 | NVIDIA nForce2 | ASUS, A7N8X | W | 4117 | 4164 |
| 21 | Athlon XP | 1 | 1 | 2200+ | 266 | DDR, SCh | 266 | NVIDIA nForce2 | ASUS, A7N8X | W | 3942 | 3989 |
| 22 | Pentium 4 | 1 | 1 | 2666 | 533 | DDR | 333 | intel 845PE | ASUS, P4PE | W | 3895 | 3942 |
| 23 | Xeon (P4) | 1 | 1 | 2666 | 533 | DDR, DCh | 266 | Intel E7505 | Intel, SE7505VB2 | W | 3755 | 3775 |
| 24 | Xeon (P4) | 1 | 2 | 2666 | 533 | DDR, DCh | 266 | Intel E7505 | Intel, SE7505VB2 | W | 3682 | 3704 |
| 25 | Athlon XP | 1 | 1 | 2200+ | 266 | DDR, DCh | 266 | NVIDIA nForce2 | ASUS, A7N8X | W | 3681 | 3726 |
| 26 | Xeon (P4, wHT) | 2 | 2 | 2000 | 400 | DDR, DCh | 200 | Intel E7505 | Intel, SE7505VB2 | W | 3453 | 3471 |
| 27 | Pentium 4 Cluster* | 1 | 1 | 2200 | 400 | RDR | 400 | Intel 850 | ASUS, P4T-E | L | 3427 | 3451 |
| 28 | Xeon (P4) | 2 | 2 | 2000 | 400 | DDR, DCh | 200 | Intel E7505 | Intel, SE7505VB2 | W | 3378 | 3390 |
| 29 | Xeon (P4) | 2 | 2 | 2000 | 400 | RDR | 400 | Intel 860 | Iwill, DP-400 | W | 3074 | 3124 |
| 30 | Athlon MP | 2 | 2 | 2200+ | 266 | DDR | 266 | AMD 760MPX | ASUS, A7M266-D | W | 3055 | 3084 |
| 31 | Xeon (P4) | 2 | 2 | 2666 | 533 | DDR, SCh | 266 | Intel E7505 | Intel, SE7505VB2 | W | 2922 | 2934 |
| 32 | Xeon (P4, wHT) | 2 | 2 | 2666 | 533 | DDR, DCh | 266 | Intel E7505 | Intel, SE7505VB2 | W | 2757 | 2810 |
| 33 | Xeon (P4) | 2 | 2 | 2666 | 533 | DDR, DCh | 266 | Intel E7505 | Intel, SE7505VB2 | W | 2491 | 2531 |
| 34 | Pentium 4 Cluster* | 2 | 2 | 2200 | 400 | RDR | 400 | Intel 850 | ASUS, P4T-E | L | 1764 | 1856 |
| 35 | Pentium 4 Cluster* | 4 | 4 | 2200 | 400 | RDR | 400 | Intel 850 | ASUS, P4T-E | L | 897 | 1092 |
| 36 | Pentium 4 Cluster* | 6 | 6 | 2200 | 400 | RDR | 400 | Intel 850 | ASUS, P4T-E | L | 620 | 844 |
* Характеристики кластера: 2-6 узлов (P4-2200MHz, i850, 1Gb RDRAM PC800/узел) межузловое соединение — Gigabit Ethernet, межузловое взаимодействие основано на LAM (Local Area Multicomputer) — реализации MPI(message passing interface).
Таблица 1. Оборудование, используемое при тестировании.
Результаты тестирования
Результаты тестирования приведены для двух характеристик — «CPU Time» и «Elapsed Time». Как правило, эти показатели применяются для оценки машинного времени практически во всех расчетных программах. «CPU Time» отражает процессорное время, потраченное на выполнение только процесса решения (рис. 2). Данная характеристика отражает потенциальные возможности вычислительных систем, здесь не учитывается время, которое система тратит на работу с видеосистемой, жесткими дисками, драйверами устройств, сетевым обменом (в случае кластера) и т.п. «Elapsed Time» (рис. 3) показывает полное время решения задачи — с момента нажатия «Enter» до вывода результата.
Хотя для всех систем, кроме кластерной, эти показатели схожи, в пределах 1-2% (для кластера разница существенно больше, в основном из-за наличия интенсивного сетевого обмена между узлами), считаю уместным привести оба показателя.
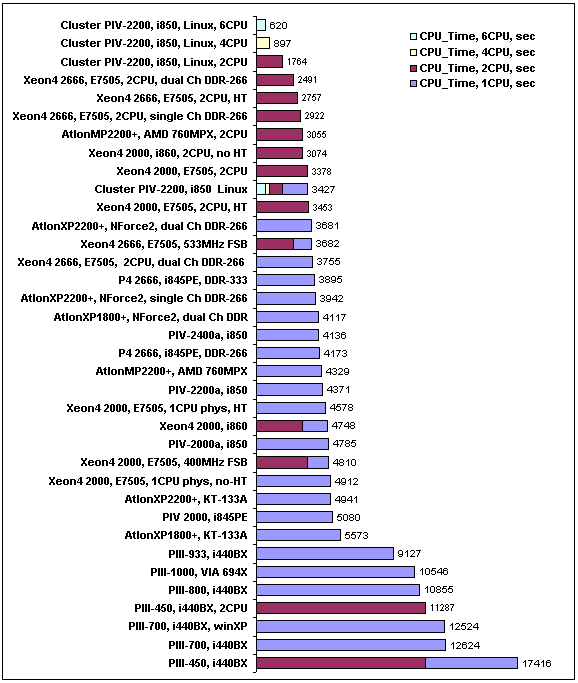
Рис. 2. Время выполнения процесса (CPU_Time), сек.
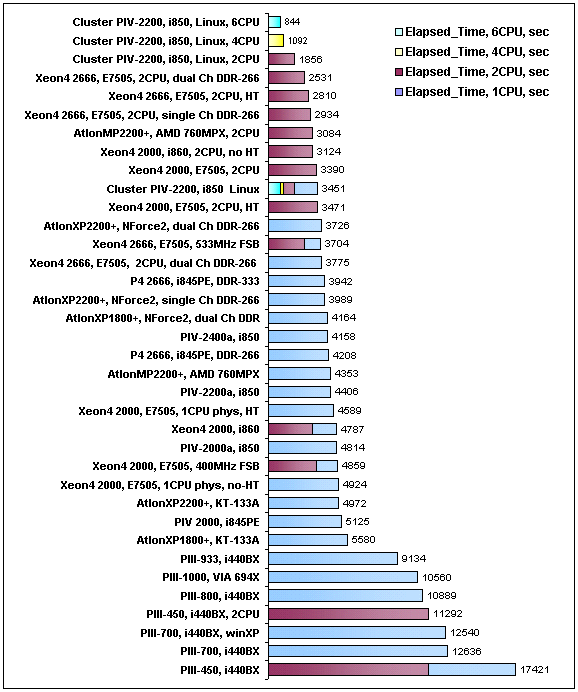
Рис. 3. Полное время выполнения задачи (Elapsed Time), сек.
Детали
Перейдем теперь к рассмотрению частных случаев.Рассмотрим подробно, какой прирост скорости счета дает установка второго процессора на плату в SMP системах.
На рис. 4, 5 показан прирост скорости для многопроцессорных компьютеров по CPU Time и Elapsed Time соответственно. Анализируя данные видно, что наибольший прирост скорости для SMP систем показывают компьютеры на основе синхронных чипсетов: Intel 440BX и Intel 860. Наиболее вероятной причиной этого являются минимальные затраты времени, выраженные в тактах шины, затраченные на передачу сообщений между частями кода, обрабатываемого разными процессорами.
Еще следует отметить возрастание прироста скорости счета при увеличении частоты системной шины с 400 до 533 МГц на системе с чипсетом E7505. Этому способствует возросшая пропускная способность процессорной шины.
Тот факт, что кластерные системы (даже два узла, соединенных кросс-овер кабелем) намного превзошли в данном тесте SMP системы объясняется хорошей параллелизацией кода программы. MPP версия LS-DYNA автоматически разделяет расчетную область на количество блоков, равное количеству узлов в кластере. Далее каждый узел производит расчет своей части, при этом интенсивно обмениваясь данными с соседними узлами. Результаты расчета собираются на головной машине. В свою очередь, при использовании многопроцессорной SMP системы такого «разделения труда» не происходит — всем процессорам приходится обрабатывать единый массив данных и при этом использовать общую шину памяти.
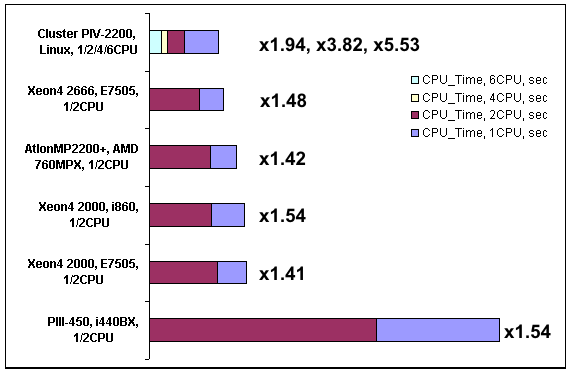
Рис. 4. Прирост скорости для многопроцессорных систем (CPU Time)
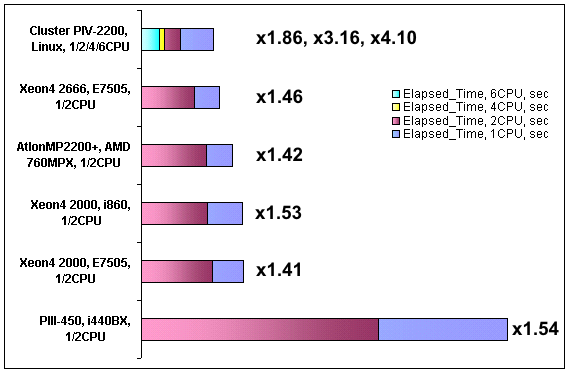
Рис. 5. Прирост скорости для многопроцессорных систем (Elapsed Time)
Теперь посмотрим на различие в результатах, полученных под различными операционными системами. Тесты, проводимые под Windows 2000 Professional, Windows 2000 Server и Windows XP, показали идентичные результаты. Версия программы, скомпилированная для Linux, дает ощутимый прирост (28%), одинаковый для CPU и Elapsed Time (см. рис. 6). Здесь сказывается лучшая оптимизация кода программы под Linux.
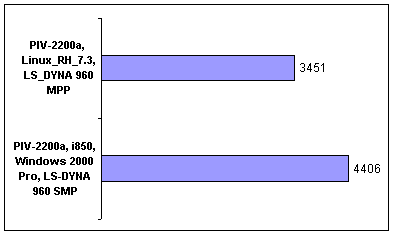
Рис. 6. Elapsed Time для OS Windows 2000 Pro и Linux RedHat 7.3
Очень сильно сказывается на производительности систем пропускная способность памяти. Например, замена в системе с чипсетом Intel 845PE памяти c DDR-266 на DDR-333 увеличивает производительность системы на 8%, а применение двухканального чипсета E7505 c памятью DDR-266 дает прирост уже в 11.5% (рис.8). Если сравнивать производительность систем на базе процессора Athlon XP, самый медленный вариант с памятью SDRAM, самый быстрый (в данном тесте) — с двухканальной DDR266, то прирост составит 34% (рис.7). Так что стоит задуматься, имеет ли смысл делать «плавный» апгрейд, чтобы сохранить великие запасы SDR, оставшиеся со времен легендарного 440BX.

Рис. 7. Elapsed Time для разных типов памяти и системной логики, AMD.

Рис. 8. Elapsed Time для разных типов памяти и системной логики, Intel.
Влияние технологии Hyper Treading было проверено в двух вариантах на чипсете Intel E7505 (рис.9). В случае с установленным на плату одним процессором (в системе, виртуально, работали два), прирост от использования данной технологии составил порядка 7%. При установленных двух процессорах (в системе, виртуально, работали четыре) наблюдалось, наоборот, падение производительности на 11%. Прирост производительности в первом случае можно объяснить более рациональным использованием конвейера процессора. Во втором случае падение производительности, по-видимому, происходит из-за возрастающей нагрузки на процессорную шину и шину памяти, а как отмечалось выше, приложение весьма критично к этим параметрам.
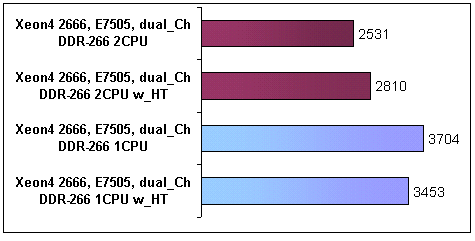
Рис. 9. Влияние технологии Hyper-Threading на производительность системы (Elapsed_Time)
Напоследок приведу две гистограммы, на которых сгруппированы результаты теста близких по частоте (P-rating, в случае процессоров Athlon) процессоров от Intel и AMD. На рис.10 представлены системы с одним процессором, на рис.11 — с двумя. Среди систем с одним процессором неоспоримым преимуществом обладают процессоры от AMD. Возможные причины: большая длинна конвейера Pentium-4 и недостаточная оптимизация программного кода данной версии LS-DYNA под его архитектурные особенности (правда, не думаю, чтобы код специально оптимизировали под процессоры Athlon). Также может сказываться разница в объемах и реализации кэша первого уровня. Еще одной причиной (если не главной) может служить нехватка пропускной способности процессорной шины и шины памяти у систем с процессорами Pentium-4.
При сравнении двухпроцессорных конфигураций наблюдается относительный паритет. Здесь двум процессорам Athlon MP явно недостаточно пропускной способности процессорной шины и шины памяти в 2.1 ГБ/С.
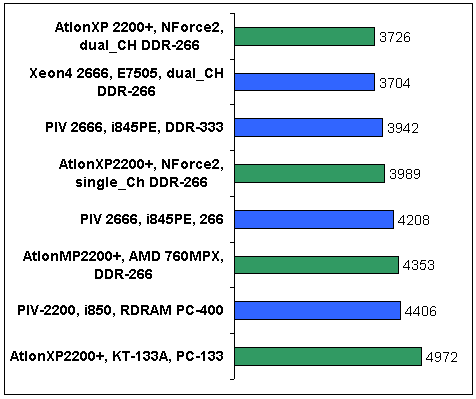
Рис. 10. Сравнение производительности систем на базе процессоров AMD и Intel (Elapsed_Time) однопроцессорные системы
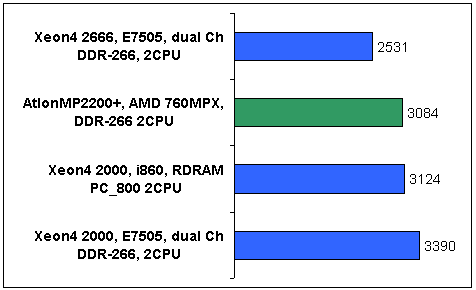
Рис. 11. Сравнение производительности систем на базе процессоров AMD и Intel (Elapsed_Time) двухпроцессорные системы
Выводы
К сожалению, не весь спектр современных x-86 вычислительных систем удалось охватить в данном обзоре. Особенно не хватает информации по платформам SerwerWorks. Надеюсь, что смогу добавить в эту статью новые данные по мере их поступления. Но, даже те данные, которые удалось получить, дают возможность сделать некоторые выводы:
Программа LS-DYNA дает значительный прирост производительности при использовании ее на многопроцессорных системах, как с общей памятью (SMP), так и с распределенной памятью (MPP). Наиболее выгодным является использование кластерных систем с распределенной памятью (MPP). Хотя напрямую сравнивать MPP и SMP системы несколько некорректно. Двухпроцессорные SMP системы — это, как правило, рабочие станции с операционной системой Windows (для сегмента пользователей данной программы), которые выполняют, помимо непосредственно расчетов, самые разнообразные функции. Linux кластеры, в свою очередь, применяются в качестве «числодробильных аппаратов» с жесткими правилами администрирования и вряд ли подойдут для многоцелевого применения (хотя, известны различные варианты). Еще, немаловажным фактором, является разница в стоимости SMP и MPP версий программы, но это предмет отдельного разговора.
Производительность программы напрямую зависит от пропускной способности оперативной памяти. Современные двухканальные чипсеты для памяти DDR дают наибольший выигрыш (к сожалению, не было возможности испытать системы на чипсете Intel 850E с памятью RDRAM PC-1066).
Значительный прирост скорости вычислений дает использование LS-DYNA 960 под ОС Linux ввиду лучшей оптимизации кода под эту операционную систему.
Применение технологии Hyper-Threading в процессорах Intel ускоряет счет в случае одного процессора и замедляет его при использовании двух процессоров.
Хорошо зарекомендовали себя процессоры AMD Athlon XP, среди однопроцессорных систем их выигрыш на лицо. В двухпроцессорном исполнении наблюдается паритет с процессорами Intel.
Выражаю свою искреннюю благодарность за помощь, оказанную при проведении тестирования:
- Андрею Богачу, представительство CAD-FEM в странах СНГ, за подготовленную задачу в программе LS-DYNA, ставшую основой для тестирования.
- Михаилу Стародубцеву, представительство CAD-FEM в странах СНГ, за предоставленный вычислительный кластер.
- Алексею Устинову, представительство Intel в странах СНГ и Балтии, за предоставленные процессоры Xeon и материнскую плату Intel SE7505VB2 вместе с шасси.
- Лидии Филипповой, компания Пирит, за предоставленные системные платы: ASUS, A7N8X, P4PE, Iwill, DP-400, процессоры Intel Pentium4 и AMD AthlonXP.
- Москалеву Александру, ОЦРК, за предоставленную двухпроцессорную систему на базе AMD AthlonMP.
- Константину Соловову, компания NIAGARA, за оказанную поддержку.
Комментарии