Предлагаемый вашему вниманию тестовый пакет CPU RightMark предназначен для объективного измерения производительности современных и будущих процессоров в различных вычислительных задачах, таких как численное моделирование физических процессов и решение задач 3D-графики. Основной упор сделан на тестирование под нагрузкой блоков FPU/SIMD процессора и связки CPU—RAM. Результатом измерений является так называемая «чистая» производительность процессора — объективная характеристика, полученная без учета влияния других подсистем, вроде видео и дисковой, за исключением подсистемы памяти. Это позволяет достоверно сравнивать между собой производительность различных процессоров вне зависимости от типа остальных компонентов системы, что достигается за счет использования тестом только центрального процессора и измерения процессорного времени, потраченного только на непосредственное исполнение вычислительной задачи. Благодаря высокой точности измерений, для получения стабильных повторяемых результатов достаточно менее одной минуты работы теста.
Настоящая версия тестового пакета CPU RightMark состоит из двух тестов — теста производительности процессора (CPU Performance) и тест стабильности работы процессора (CPU Stability). Приступим к их рассмотрению.

Тест производительности процессора (CPU Performance)
В первом тесте решается оба типа указанных выше задач — численного моделирования физических процессов и 3D-графики. Результат вычислений физики системы частиц наглядно представляется на экране в виде красивой сцены, состоящей из множества сфер. Таким образом, реализованный в CPU RightMark тест производительности процессора можно разбить на два независимых, последовательно работающих модуля.
1. Численное моделирование
Первый модуль (Solver) осуществляет задачу численного моделирования физических процессов. При инициализации этого модуля задается количество рассчитываемых частиц, начальные значения координат этих частиц в пространстве, их скоростей и ускорений (последние, как правило, в начальный момент времени равны нулю), массы и радиусы частиц, параметры потенциала взаимодействия («линейный» и «квадратичный» факторы — lin_factor и quad_factor) и фактор потерь энергии, связанных с трением (v_factor).
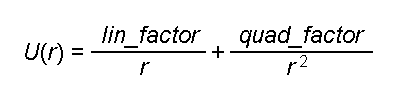
Потенциал взаимодействия частиц
Значения указанных параметров зависят от выбранной в настройках теста одной из семи моделей взаимодействия частиц, описание которых мы приведем ниже.
При выполнении теста, на каждом последующем шаге модуль Solver проводит оценку взаимодействия между частицами, результатом которой являются новые значения ускорений каждой частицы, после чего решаются обычные уравнения движения частиц, известные из классической механики.
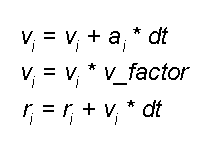
Уравнения движения частиц
Результатом решения являются новые значения скоростей и координат частиц, здесь же вычисляются значения энергии и импульса системы в целом, которые представляются на экране по мере выполнения теста. Процедура оценки взаимодействия и решения уравнений движения повторяется несколько раз, т.е. итеративно, причем число итераций и шаг времени dt можно варьировать.
Расчеты в этом модуле проводятся с использованием переменных с двойной точностью (double). В связи с этим, в настоящей версии Solver реализовано три варианта оптимизации кода. Первый использует x87 FPU, два других — SIMD-расширения, работающие с переменными двойной точности — SSE2 (доступные в процессорах Intel Pentium 4 и AMD Opteron/Athlon 64/FX) и SSE3 (появившиеся в недавно вышедшем процессоре Intel Pentium 4 Prescott). Последний отличается от SSE2-варианта использованием новой операции поэлементного сложения компонентов SSE2-регистра процессора. Кроме того, в каждой версии модуля Solver, рассчитанной под определенный набор инструкций, реализовано четыре варианта процедуры оценки взаимодействия частиц, отличающихся друг от друга количеством используемых «ручных» оптимизаций кода и, следовательно, своей производительностью. В тесте CPU Performance используется наиболее производительный вариант.
2. Визуализация сцены
Вернемся к рассмотрению принципа работы теста производительности. Рассчитанные модулем Solver значения координат частиц передаются второму модулю CPU RightMark — модулю визуализации сцены (Renderer). Инициализация этого модуля довольно проста, она также осуществляется при запуске теста и выборе типа модели. При этом задаются постоянные параметры сферических частиц, вроде их эффективного радиуса (который может отличаться от действительного радиуса), а также свойства поверхности — константы диффузного рассеяния (diffuse) и прямого отражения света (specular). Все остальные параметры — положения частиц, источников света, а также цвет источников — задаются заново на каждом кадре, т.е. могут свободно варьироваться во времени.
Таким образом, модулю Renderer поручается не менее важная задача — рассчитать и отобразить динамическую сцену, состоящую из множества сфер. Поскольку упор в тесте CPU RightMark делается на тестирование производительности именно процессора, а не, скажем, видеосистемы, то и метод визуализации должен быть соответствующим. Т.е. использовать для этой цели только CPU, в то же время не быть очень медленным, ну и, желательно, не уступать по качеству изображения стандартным методам визуализации с использованием 3D-ускорителей, а то и превосходить его. Лучшим претендентом на звание такого метода, удовлетворяющего все перечисленные выше требования, является хорошо известный метод обратной трассировки лучей. Рассмотрим особенности реализации этого метода в тесте производительности процессора CPU RightMark. Процедуру визуализации можно разбить на две части — предварительного анализа сцены (пререндеринга) и собственно трассировки лучей (рендеринга).
В ходе пререндеринга в первую очередь происходит преобразование координат частиц (сфер) и источников света относительно положения камеры и направления обзора. Далее проводится отсечение сфер, не попавших в поле зрения, путем проверки попадания центра сферы в пирамиду видимости (отметим, что в реализованных моделях, как правило, все сферы попадают в видимую область).
Следующим этапом является распределение индексов сфер по областям экранного (проекционного) пространства — маленьким клеточкам, которые для краткости будем называть тайлами. Это позволяет значительно сократить затраты на поиск первичного пересечения лучей в последующей процедуре рендеринга. Действительно, ведь при таком разбиении пространства для каждой точки экрана потребуется считать пересечения далеко не со всем множеством сфер, а лишь с небольшой его частью, попавшей в данный тайл.
Наконец, последний этап, наиболее алгоритмически сложный и затратный с точки зрения процессорного времени — расчет освещенности и затененности сфер. С этой целью для каждого источника света, с учетом его радиуса действия, создается массив сфер, которые он может потенциально освещать. После чего для каждой пары сфер из этого массива происходит проверка, может ли первая сфера потенциально затенять вторую, и наоборот. В результате такой непростой операции для каждой сферы создается список источников света, которые могут ее освещать, а для каждой пары «сфера-источник света» — список других сфер, которые могут этот источник света собою заслонять, пусть даже частично. Точно так же, как и деление экранного пространства на тайлы, эта процедура позволяет существенно сократить затраты на поиск пересечения со сферами так называемых «вторичных», или «теневых» лучей, испущенных из данной точки видимой сферы на источник света.
Мы подошли вплотную к описанию второй процедуры модуля Renderer — процедуры обратной трассировки лучей (рендеринга). Поскольку все необходимые данные уже получены при анализе сцены в ходе пререндеринга, задача обратной трассировки существенно упрощается. В ней осуществляется последовательный обход всех пикселей экрана. Если тайл, которому принадлежит данный пиксель, пустой (т.е. не содержит индексов сфер) — значит, обработку этого пикселя можно считать завершенной, и просто закрасить эту точку нужным элементом текстуры неба (или просто оставить этот пиксель пустым, если рисование неба отключено). Если же тайл содержит индексы сфер, ищется пересечение луча, испущенного из камеры в данную точку экрана, со всеми сферами, попадающими в этот тайл, и находится ближайшая. Заметим, что на деле пересечения может и не оказаться (скажем, если сфера попадает лишь в правый нижний угол тайла, а расчет производится для левого верхнего) — в этом случае также необходимо либо нарисовать небо, либо ничего не рисовать. Ну а если пересечение найдено, начинается длительная процедура, конечный результат работы которой — всего-навсего значение цвета данного пикселя. А вычисляется он следующим образом.
Для начала, если задано текстурирование сцены, происходит вычисление сферических текстурных координат и выборка элемента текстуры (который становится для этой точки константой диффузного рассеяния света, Kd), а также расчет фоновой составляющей освещенности (ambient, Ka). Далее проверяется, освещают ли эту сферу какие-либо источники света. Для каждого источника света из данной точки сферы испускается луч (L), с которым осуществляется проверка на пересечение со всеми потенциальными сферами-затенителями, до нахождения первого действительного пересечения. Эта проверка несколько проще, чем в случае первичных лучей — здесь не надо находить точные координаты пересечения, достаточно лишь знать сам факт наличия пересечения. Если пересечение найдено — значит, данный источник света заслонен другой сферой и не вносит свой вклад в освещение. Иначе данная точка поверхности сферы освещена этим источником света, и нам необходимо рассчитать ее освещенность, используя для этого, например, модель Фонга. Рассчитанная освещенность добавляется к общей освещенности данной точки.

Модель освещения Фонга
Наконец, остается вывести рассчитанный цвет пикселя путем записи значения в буфер кадра (frame buffer). После чего всю процедуру трассировки можно повторять заново, но уже для следующего пикселя.
Для геометрических расчетов в модуле Renderer используются вещественные числа одинарной точности (float), а работа с цветом (текстурирование/освещение) осуществляется с помощью MMX-расширений. Поскольку одинарная точность оказывается вполне достаточной для геометрических расчетов, нам ничего не мешает использовать для оптимизации кода различные SIMD-расширения, работающие с векторами из чисел такого типа. В текущей версии CPU RightMark реализовано пять вариантов модуля Renderer. Первые два используют стандартный x87 FPU и расширения MMX, а также дополнения этого набора — MMX Extensions, появившиеся впервые в процессорах Intel Pentium III (как часть SSE) и ранних AMD Athlon. Третий вариант написан с использованием расширений AMD Extended 3DNow! и Extended MMX, в связи с чем его можно применять для сравнения производительности FPU и 3DNow!-кода на первых моделях процессоров AMD Athlon, в которых отсутствуют расширения SSE. Наконец, последние два варианта модуля Renderer в полной мере используют расширения Intel SSE и SSE3 и представляют собой пример серьезной «ручной» оптимизации кода. Так, здесь реализована параллельная обработка сразу четырех сфер при расчете отношений затененности в процедуре пререндеринга и при поиске пересечений первичных и вторичных лучей в процедуре рендеринга. В последнем случае дополнительный выигрыш в скорости достигается за счет активного использования инструкции горизонтального сложения (HADDPS), позволяющей с гораздо большей эффективностью считать скалярные произведения векторов, которые в процедуре трассировки лучей встречаются довольно часто.
Наконец, особенностью метода обратной трассировки лучей является возможность эффективной параллелизации вычислений, поскольку расчет каждой точки можно проводить совершенно независимо от расчета другой, даже соседней точки. Однако для большей эффективности и избежания конфликтов вследствие обращения разных процессоров к одной и той же области памяти (в случае SMP-систем) гораздо логичнее разбить экран на большие части, и поручить каждому процессору свою часть (будь то самостоятельный физический процессор или логический процессор в HT-системах), как это изображено на рисунке.

Многопоточный рендеринг
Применение подобной схемы позволяет достичь серьезный выигрыш в скорости, который оказывается практически пропорциональным количеству процессоров в SMP-системах и весьма ощутимым (до 40%) в системах с технологией Hyper-Threading.
Настройки теста производительности
Тест производительности процессора CPU RightMark имеет целый ряд настроек, задаваемых пользователем, причем с возможностью их варьирования в довольно широких пределах. Ниже мы перечислим все настройки, останавливаясь подробнее на наиболее важных из них.
Настройки модуля Renderer (Renderer Setup)
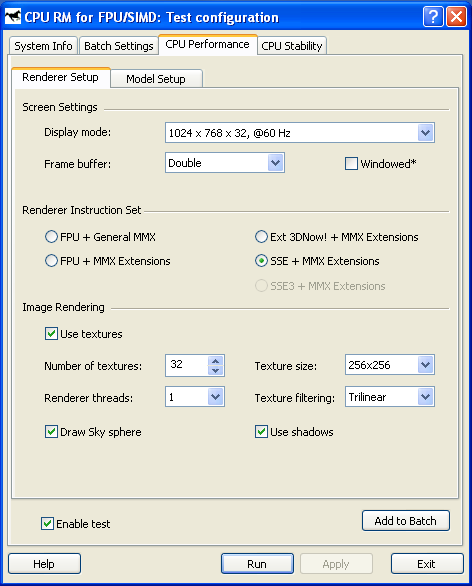
Screen Settings — параметры отображения сцены:
- Display Mode — установка разрешения и частоты обновления экрана. Список разрешений и частот создается на основе информации, предоставляемой драйвером видеокарты подсистеме DirectDraw.
- Frame Buffer — используемая схема кадрового буфера. В двухбуферной схеме (Double) в видеопамяти создается два буфера, один из которых отображается на экране, пока происходит заполнение другого, после чего они меняются местами. В более сложной схеме (Triple) используется дополнительный невидимый буфер, что позволяет заполнять его данными, не дожидаясь окончания отображения текущего кадра на экране. Учитывая, что скорость рендеринга сцены методом обратной трассировки лучей, как правило, заведомо ниже, чем частота обновления экрана, применение схемы Triple Buffering не является актуальным, поскольку приводит лишь к дополнительному расходу видеопамяти. В режиме Offscreen Rendering рисование сцены осуществляется в буфер, находящийся в системной памяти, что, как правило, является более медленным по сравнению с использованием видеопамяти. Причина этого связана с «засорением» кэша процессора ненужными данными (результатами расчета цвета пикселей), которое не происходит при записи в видеопамять ввиду того, что последняя осуществляется по протоколу write-combining, минуя систему кэш-уровней процессора.
- Windowed — режим отображения сцены в окне. Размер окна фиксирован и составляет 640x480 пикселей. Данный режим предназначен для отладочных целей и недоступен по умолчанию. Его можно включить с помощью настроек в ключе системного реестра HKEY_CURRENT_USERSoftwareRightMarkRMCPUTweak установкой значения Windowed: REG_DWORD = 1.
Renderer Instruction Set — набор расширений процессора, используемый модулем Renderer:
- FPU + General MMX (Intel Pentium MMX и выше).
- FPU + MMX Extensions (Intel Pentium III и выше, AMD Athlon и выше).
- Ext 3DNow! + MMX Extensions (AMD Athlon и выше).
- SSE + MMX Extensions (Intel Pentium III и выше, AMD Athlon XP/MP и выше).
- SSE3 + MMX Extensions (Intel Pentium 4 Prescott).
- Use Textures — включение/выключение режима текстурирования сцены.
- Number of textures — количество используемых текстур (1—32). Каждой сфере назначается собственная текстура, номер которой равен номеру сферы, взятому по модулю количества текстур.
- Texture Size — максимальный допустимый размер текстур (от 16x16 до 256x256). Ввиду использования процедуры MIP-мэппинга реальный размер текстур, особенно при низких разрешениях, может быть меньшим заданного. Для наглядности в ходе выполнения теста на экране представляется процентное распределение текстур по размерам. Точно так же, как и увеличение количества текстур, увеличение их размера приводит к увеличению нагрузки на подсистему кэша/памяти.

Распределение текстур по размерам
- Texture filtering — режим фильтрации текстур. Bilinear — билинейная фильтрация, при которой выборка элемента текстуры осуществляется путем двойной линейной интерполяции четырех соседних точек одного и того же MIP-уровня текстуры. Трилинейная фильтрация (Trilinear) является более совершенной ввиду использования процедуры билинейной фильтрации дважды, для каждого из соседних MIP-уровней текстуры (таким образом, интерполяция проводится по восьми точкам). Использование последней приводит к увеличению нагрузки на MMX-блок процессора и подсистему памяти, что позволяет тестировать указанные компоненты в более жестких условиях.
- Renderer threads — количество используемых потоков рендеринга. Возможными вариантами являются 1, 2, 4, 8 и 16 потоков, что позволяет измерять производительность широкого круга многопроцессорных систем.
- Draw sky sphere — включение/выключение режима рисования неба. Поскольку, как правило, оно составляет большую часть сцены, а его отображение по сложности сопоставимо с выборкой элемента текстуры для остальных сфер, отключение рисования неба приводит к ощутимому увеличению производительности процедуры рендеринга.
- Use shadows — включение/выключение расчета теней. При его отключении не производится расчет затенителей сферы в процедуре пререндеринга и расчет пересечений «теневых» лучей в процедуре рендеринга. Это приводит к некоторому увеличению скорости отображения сцены в целом, но ценой потери реалистичности изображения.
Настройки модели и модуля Solver (Model Setup)
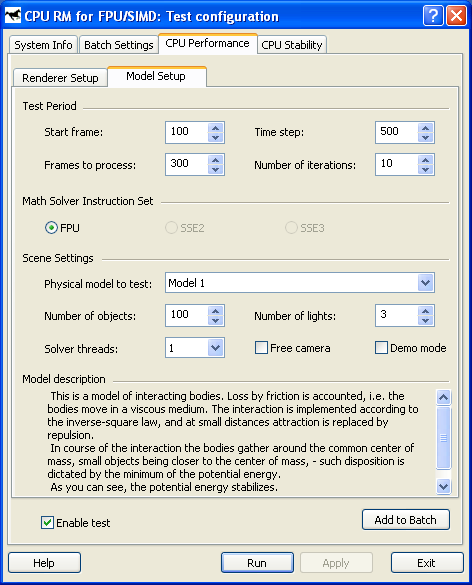
Test Period — настройки продолжительности теста и параметров модуля Solver:
- Start frame — номер кадра, с которого начинается измерение производительности.
- Frames to process — количество кадров для измерения производительности. Общее количество отображаемых кадров составляет сумму этих двух величин.
- Time step — шаг одной итерации при решении уравнений движения, в микросекундах.
- Number of iterations — количество итераций оценки взаимодействия/решения уравнений движения.
Math Solver Instruction Set — набор расширений, используемый модулем Solver:
- FPU (поддерживается практически всеми процессорами).
- SSE2 (Intel Pentium 4, AMD Opteron/Athlon 64/FX).
- SSE3 (Intel Pentium 4 Prescott).
Scene Settings — выбор модели и настройка дополнительных параметров сцены:
- Physical model to test — тип используемой физической модели взаимодействующих тел (1 — 7). Ниже приведено описание каждой из моделей.
Модель 1
Учитываются потери на трение, то есть тела движутся в вязкой среде. Взаимодействие осуществляется по закону обратных квадратов расстояний, при малых расстояниях притяжение сменяется отталкиванием. В процессе взаимодействия тела накапливаются около общего центра масс, причем более мелкие объекты оказываются ближе к центру масс. Такое расположение диктуется минимумом потенциальной энергии. В процессе взаимодействия потенциальная энергия системы стабилизируется.Модель 2
Учитываются потери на трение, то есть тела движутся в вязкой среде. Взаимодействие осуществляется по закону обратных расстояний, при малых расстояниях притяжение сменяется отталкиванием. Конфигурация объектов становится шаровой, поскольку такое расположение соответствует минимуму потенциальной энергии.Модель 3
Потери на трение отсутствуют. Взаимодействие осуществляется по закону обратных расстояний, при малых расстояниях притяжение сменяется отталкиванием. Конфигурация объектов не стабилизируется с течением времени.Модель 4
Диссипативные силы (потери на трение) отсутствуют. Взаимодействие осуществляется по закону обратных квадратов расстояний, при малых расстояниях притяжение сменяется отталкиванием. Конфигурация объектов не стабилизируется с течением времени.Модель 5
Потери на трение отсутствуют. Взаимодействие осуществляется по закону обратных квадратов расстояний, при малых расстояниях притяжение сменяется отталкиванием. Модель представляет собой звезду с поясом астероидов. Конфигурация объектов не стабилизируется с течением времени. Вследствие этой нестабильности практически при всех начальных условиях некоторые астероиды за счет взаимодействия друг с другом улетают на бесконечность. Такое поведение характерно для системы многих тел, взаимодействующих по закону обратных квадратов радиусов без трения (это физически точный закон гравитационного взаимодействия). Однако стабильность конфигурации с одним центральным телом довольно высока и растет по мере роста массы центрального тела.Модель 6
Потери на трение отсутствуют. Взаимодействие осуществляется по закону обратных расстояний, при малых расстояниях притяжение сменяется отталкиванием. Модель представляет собой три звезды с общим поясом астероидов. Конфигурация объектов не стабилизируется с течением времени, однако отдельные объекты не улетают на бесконечность. Такое поведение связано с тем, что соответствующий потенциал неограниченно возрастает на бесконечности. Данная модель является примером системы, находящейся в бесконечно глубокой потенциальной яме.Модель 7
Учитываются потери на трение, то есть тела движутся в вязкой среде. Взаимодействие осуществляется по закону обратных расстояний, при малых расстояниях притяжение сменяется отталкиванием. Конфигурация объектов становится шаровой — такое расположение соответствует минимуму потенциальной энергии. Подобное поведение можно считать демонстрацией поверхностного натяжения. Такая модель также может описывать каплю воды. - Number of objects — количество взаимодействующих частиц. Увеличение количества частиц приводит к квадратичному увеличению времени расчета системы модулем Solver.
- Number of lights — количество источников света. Влияет как на скорость предварительного расчета сцены (пререндеринга), так и на скорость рендеринга.
- Solver threads — количество используемых потоков. В настоящей версии единственным возможным значением является 1 поток.
- Free camera — режим свободного управления камерой с помощью клавиатуры и мыши. По умолчанию камера является фиксированной, поскольку сравнение между собой результатов теста, полученных при использовании режима свободного управления камерой, является бессмысленным.
- Demo mode — включение режима демонстрации, позволяющего использовать тест в качестве скринсэйвера. При его включении количество рассчитываемых кадров неограниченно. Завершить демонстрацию можно нажатием клавиши Escape.
Кроме того, имеется ряд дополнительных настроек режима демонстрации, находящихся в системном реестре в ключе HKEY_CURRENT_USERSoftwareRightMarkRMCPUDemo:
// отображение статистики (0 = выключено, 1 = включено)
ShowInfo: REG_DWORD = 0// периодическая рандомизация модели (0 = выключена, 1 = включена)
RandomizeModel: DWORD = 1// интервал рандомизации модели (количество кадров)
RandomizeInterval: REG_DWORD = 200// режим анимации камеры (0 = выключен, 1 = включен)
CameraFly: REG_DWORD = 1// направление анимации камеры (0 = против часовой стрелки, 1 = по часовой стрелке)
CameraCW: REG_DWORD = 1// скорость анимации камеры (1 — 10)
CameraSpeed: REG_DWORD = 3
Конечным результатом выполнения первого теста являются следующие характеристики производительности системы:
Math Solving FPS — скорость расчета физики системы частиц.
Prerendering FPS — скорость пререндеринга (предварительного анализа) сцены.
Rendering FPS — скорость рендеринга сцены.
Overall FPS — средняя (по всем трем параметрам) скорость.
Тест стабильности процессора (CPU Stability)
Второй тест CPU RightMark предназначен для длительного тестирования стабильности работы процессора под нагрузкой. В качестве последней используется та же самая задача численного моделирования, осуществляемая модулем Solver. Результат измерений представляется в виде зависимости производительности процессора от времени. С помощью этого теста, в частности, можно отследелить момент снижения производительности процессора (throttling) при его перегреве выше допустимого предела, при наличии у процессора технологии мониторинга температуры (Thermal Monitor).
Настройки теста стабильности
Настройки теста стабильности, по существу, практически не отличаются от настроек модуля Solver в первом тесте, за исключением ряда специфических моментов.
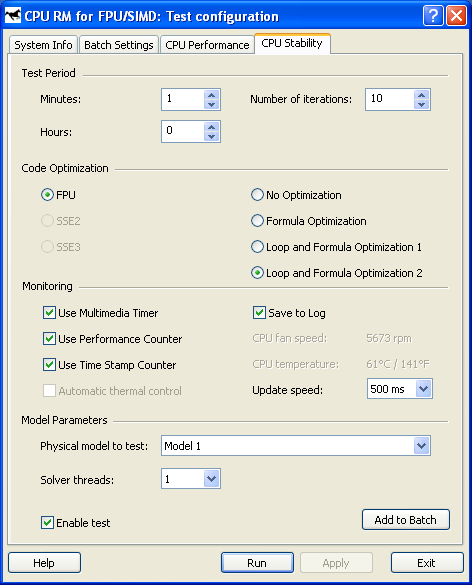
Test Period — продолжительность теста (Minutes, Hours), параметры модуля Solver (Number of iterations).
Code Optimization — тип используемых расширений процессора (FPU, SSE2, SSE3), а также используемый вариант оптимизации процедуры оценки взаимодействий:
- No Optimization — оптимизация не используется.
- Formula Optimization — оптимизация формулы.
- Loop and Formula Optimization 1 — оптимизация формулы, «раскручивание» цикла, вариант 1.
- Loop and Formula Optimization 2 — оптимизация формулы, «раскручивание» цикла, вариант 2.
Monitoring — режим измерения производительности:
- Use Multimedia Timer — использование стандартного Windows Multimedia Timer;
- Use Performance Counter — использование высокопроизводительного счетчика (HPC);
- Use Time Stamp Counter — использование счетчика тактов процессора (TSC);
- Save to Log — сохранение результатов каждого измерения в файл.
- Update speed — скорость обновления графика (500, 1000 и 1500 мс);
- Automatic thermal control, CPU fan speed, CPU temperature — в настоящее время не реализовано.
Model Parameters — выбор модели и количества потоков модуля Solver.
- Physical model to test — выбор физической модели (1 — 7). Описание каждой из моделей приведено выше.
- Solver threads — число потоков, используемых модулем Solver. В настоящей версии теста можно задавать 1 или 2 потока. При этом главный поток всегда осуществляет вычисления с использованием FPU/SSE2/SSE3-блоков процессора, в то время как во второй поток (при указании двух потоков) использует ALU-блок процессора для целочисленных вычислений. Данная схема разработана для более эффективной нагрузки систем с технологией Hyper-Threading.


