Этой статьей мы начинаем небольшой цикл, посвященный различным реальным приложениям, которые могут использоваться для тестирования процессоров, компьютеров, ноутбуков и рабочих станций. В дальнейшем все рассматриваемые в данном цикле статей приложения будут положены в основу нового тестового пакета iXBT Application Benchmark 2017. Поскольку в новом тестовом пакете предполагается использование более 20 различных тестов, а сводить рассмотрение их всех в одну статью довольно сложно, мы решили сделать отдельный цикл статей. В рамках этого цикла будут рассматриваться только те приложения, которые не использовались нами ранее при тестировании процессоров и компьютеров.
Начнем мы с рассмотрения двух специализированных программных пакетов, которые применяются для решения задач молекулярной динамики: LAMMPS и NAMD. Отметим, что данные программные продукты входят в состав специализированного тестового пакета SPECwpc 2.0, который ориентирован на тестирование рабочих станций. Включение приложений LAMMPS и NAMD (и не только их) в тестовый пакет iXBT Application Benchmark 2017 позволит нам в дальнейшем отказаться от использования специализированных бенчмарков для рабочих станций.
Мы не ставим себе целью детальное изучение этих специализированных пакетов молекулярной динамики и создание расчетных задач с нуля, поскольку не являемся специалистами в данной области. Наш подход в данном случае следующий: расчетные задачи (workload) и команды запуска программ с соответствующими параметрами мы позаимствовали из пакета SPECwpc 2.0 (в который входят оба эти приложения, как уже было сказано выше). Более детально об этом будет рассказано далее.
LAMMPS
Одна из наиболее известных (в узких кругах) программ для классической молекулярной динамики — LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator). Данная программа является свободной (open source, GPL) и используется для расчетов взаимодействий до десятков миллионов атомов. Конечно же, программа очень непростая, ее освоение требует большого количества времени и специфических знаний в области молекулярной динамики. Есть и учебники, и даже курсы для освоения данной программы. Программа написана на языке C++ и не имеет графического интерфейса (только командный режим). Возможна компиляция исходных кодов под различные операционные системы (Linux, OS X, Windows). Кроме того, имеется большое количество различных опций компиляции, которые позволяют создавать исполняемый файл под конкретную архитектуру процессора и архитектуру графического процессора (Fermi, Kepler). Описание всех возможных опций данной программы выходит за рамки нашей статьи, но если кому-то интересно, учебник с описанием всех возможностей данного пакета есть на сайте разработчиков.
На сайте выкладываются заранее скомпилированные версии программы для различных операционных систем. Для тестирования мы воспользовались последней 64-битной Windows-версией LAMMPS 64-bit 20160516 (версия от 16.05.2016). Данная версия программы может запускаться как в однопоточном режиме, так и в многопоточном (в случае многоядерных процессоров и многопроцессорных систем), для этого служат разные команды. Конечно же, при тестировании процессоров мы использовали запуск в многопоточном режиме, но для этого необходимо дополнительно установить пакет MPI (Message Passing Interface), причем не любой (версия Microsoft не подойдет), а именно 64-битную версию MPICH2, созданную Argonne lab (mpich2-1.4.1p1-win-x86-64.msi).
После инсталляции пакета MPICH2 (по умолчанию он устанавливается в папку C:\Program Files\MPICH2) необходимо еще интегрировать его в систему. Для этого (обязательно в режиме администратора!) надо выполнить команду smpd.exe -install. Файл smpd.exe расположен в папке MPICH2\bin.
Более подробно с особенностями использования Windows-версии пакета LAMMPS можно ознакомиться здесь.
Далее инсталлируем пакет LAMMPS 64-bit 20160516 (в принципе, очередность установки этих двух пакетов не важна). По умолчанию он устанавливается в папку C:\Program Files, создавая там папку с именем LAMMPS 64-bit 20160516. Собственно, установки в смысле Windows не происходит, файлы пакета просто копируются в папку, которую в дальнейшем можно переименовать и переместить (например, сделать папку C:\LAMMPS).
В папке пакета LAMMPS создается подпапка с названием Benchmarks. В этой папке содержатся файлы с задачами, которые можно использовать для тестирования. В этом еще одно преимущество данного пакета: не нужно самостоятельно создавать тестовые задачи. Имена файлов образованы по следующему правилу: исполняемый файл начинается с in, а после точки указывается название задачи — например, in.lj, in.rhodo или in.rhodo.scaled (в последнем примере rhodo.scaled — это название задачи). Кроме того, есть еще и файлы, имена которых начинаются с data, а после точки опять же указывается название задачи — например, data.chute. Это файлы с данными, которые используются в соответствующих задачах.
Всего в папке Benchmarks имеется пять различных задач, которые могут использоваться для тестирования. Использовать их все для наших целей избыточно, поэтому пока мы отобрали четыре задачи (Polymer chain melt benchmark (chain), Granular chute flow benchmark (chute), Rhodopsin protein benchmark (rhodo) и Lennard-Jones liquid benchmark (lj)), но возможно, в дальнейшем в пакете iXBT Application Benchmark 2017 будем использовать лишь два теста из четырех, дабы сократить время тестирования. Описание этих бенчмарков выходит за рамки данной статьи в силу их специфики, но те, кто знаком с темой, могут прочитать описание на английском языке.
Запуск программы LAMMPS производится через интерфейс MPI (команда mpiexec.exe), а для запуска LAMMPS в многопоточном режиме используется команда lmp_mpi.exe:
mpiexec.exe -wdir <рабочая_директория> -localonly %n% lmp_mpi.exe <команда_запуска>В данном случае параметр -wdir определяет рабочую директорию с исполняемым файлом и командой запуска программы LAMMPS (lmp_mpi.exe). Параметр -localonly задает количество одновременно выполняемых процессов, его значение должно соответствовать количеству логических (с учетом Hyper-Threading) ядер процессора.
Команда запуска исполняемого файла имеет следующую структуру:
-log <название_файла.out> <параметры> -in <путь_к_исполняемому_файлу>В данном случае параметр -log определяет файл с отчетом о выполнении задачи.
Параметры запуска исполняемого файла могут изменяться под каждую конкретную задачу, описание параметров приводится в файле readme.txt в папке Benchmarks. Например, если пакет LAMMPS находится в папке C:\LAMMPS, пакет MPICH2 установлен по умолчанию, а все файлы расчетных задач скопированы из папки C:\LAMMPS\Benchmarks в папку C:\LAMMPS\bin (это четыре исполняемых файла и три файла данных, поскольку задача lj не требует файла данных: in.chain.scaled, in.chute.scaled, in.rhodo.scaled, in.lj, data.chain, data.chute, data.rhodo), то для запуска теста используется следующая последовательность команд:
cd C:\Program Files\MPICH2\bin\ ;переходим в папку с исполняемым файлом mpiexec.exe
mpiexec.exe -wdir C:\LAMMPS\bin -localonly %n% lmp_mpi.exe <команда_запуска> В итоге в нашем случае четыре тестовые задачи запускаются следующими командами:
mpiexec.exe -wdir C:\LAMMPS\bin\ -localonly %n% lmp_mpi.exe -log test_lj.out -var x 8 -var y 8 -var z 8 -in in.lj
mpiexec.exe -wdir C:\LAMMPS\bin\ -localonly %n% lmp_mpi.exe -log test_rhodo.out -var x 4 -var y 3 -var z 3 -in in.rhodo.scaled
mpiexec.exe -wdir C:\LAMMPS\bin\ -localonly %n% lmp_mpi.exe -log test_chain.out -var x 8 -var y 8 -var z 12 -in in.chain.scaled
mpiexec.exe -wdir C:\LAMMPS\bin\ -localonly %n% lmp_mpi.exe -log test_chute.out -var x 16 -var y 16 -in in.chute.scaled Для запуска удобно использовать bat-файл, чтобы автоматически запускать все тестовые задачи по очереди. Запускать bat-файл нужно с правами администратора (Run As Administrator), в противном случае MPI-интерфейс работать не будет. В нашем случае bat-файл запускается с параметром, в качестве которого указывается количество ядер процессора, причем поскольку у нас полностью автоматизированный тест, количество ядер процессора тоже определяется автоматически.
Естественно, возникает вопрос: почему мы используем именно такие параметры для каждой тестовой задачи? Тут мы ничего не выдумывали, пакет LAMMPS (правда, более старой версии и иначе скомпилированный) входит в тестовый пакет SPECwpc 2.0, откуда мы и взяли параметры запуска тестовых задач.
NAMD 2.11
Пакет NAMD (NAnoscale Molecular Dynamics), как и LAMMPS, является бесплатной программой для выполнения расчетов молекулярной динамики. NAMD написан с использованием модели параллельного программирования Charm++ и используется для симуляции больших систем (миллионы атомов). Как гласит Википедия, программа была создана совместно Группой теоретической и вычислительной биофизики (TCB) и Лабораторией параллельного программирования (PPL) из Иллинойсского университета. Программа поддерживает мультипроцессорность, а также возможность использовать для расчетов графические процессоры (технология CUDA).
Обсуждение нюансов, когда имеет смысл использовать пакет LAMMPS, а когда — NAMD, выходит за рамки данной статьи в силу специфики этих приложений. Для тех, кто в теме, учебник с описанием возможностей пакета NAMD есть на сайте разработчика.
Как и в случае LAMMPS, программа NAMD не имеет графического интерфейса, для ее запуска используется командная строка, а для запуска в многопоточном режиме используется интерфейс MPI. Далее мы подробно опишем процесс инсталляции и запуска программы NAMD, чтобы каждый мог реализовать данный тест самостоятельно.
На сайте разработчика имеются заранее скомпилированные версии программы для различных операционных систем. Для тестирования мы использовали 64-битную Windows-версию NAMD 2.11 с поддержкой MPI (Win64 MPI). Скачанный zip-файл содержит папку NAMD_2.11_Win64-MPI, которую надо разархивировать.
Для запуска программы в многопоточном режиме необходимо дополнительно установить пакет MPI (Message Passing Interface), причем пакет MPICH2 (который мы использовали для LAMMPS) не подойдет. Мы установили версию MPI Microsoft (MS-MPI 7.1).
Сам пакет NAMD (как и LAMMPS) не инсталлируется. Просто создаем папку C:\NAMD, в ней подпапку namd (можно, конечно, и иначе, но тогда нужно будет учесть другие пути к папкам при написании команд), из разархивированной папки NAMD_2.11_Win64-MPI переносим все файлы в папку C:\NAMD\namd, а затем в папке namd создаем папку data, в которую нужно будет скопировать задачи для теста.
На сайте разработчика в разделе NAMD Performance есть один доступный для скачивания тест — ApoA1. Скачав и разархивировав данный тест, копируем папку apoa1 в папку data. Одного теста нам показалось недостаточно, поэтому мы добавили еще два, f1atpase и stmv, позаимствовав их из соответствующей директории бенчмарка SPECwpc 2.0 (кстати, там же есть и тест apoa1). Итак, в папку data копируются папки тестов apoa1, f1atpase и stmv.
Далее в папке C:\NAMD создается bat-файл для запуска тестовых задач (каждый отдельный тест можно запускать из командной строки). Запуск программы NAMD производится через интерфейс MPI (команда mpiexec.exe). Последовательность команд в командной строке следующая:
cd C:\Program Files\Microsoft MPI\Bin\ ;переходим в папку с исполняемым файлом mpiexec.exe
mpiexec.exe -wdir C:\NAMD\namd\namd2.exe <команда_запуска> В данном случае параметр -wdir определяет рабочую директорию с исполняемым файлом (с расширением .namd) и командой запуска программы NAMD.
В итоге в нашем случае три тестовые задачи запускаются следующими командами:
mpiexec.exe -wdir C:\NAMD\namd\namd2.exe data\apoa1\apoa1.namd
mpiexec.exe -wdir C:\NAMD\namd\namd2.exe data\f1atpase\f1atpase.namd
mpiexec.exe -wdir C:\NAMD\namd\namd2.exe data\stmv\stmv.namd Как мы уже отмечали, для автоматического запуска всех тестовых задач по очереди удобно использовать bat-файл. Запускать bat-файл следует с правами администратора (Run As Administrator), в противном случае MPI-интерфейс работать не будет. В случае пакета NAMD (при использовании MS-MPI 7.1) можно не указывать в параметрах количество ядер процессора, вычисления и так будут распараллеливаться на все имеющиеся ядра.
Отметим, что пакеты LAMMPS и NAMD загружают все ядра процессора на 100%.
Тестовый стенд и методика тестирования
Для тестирования с использованием приложений LAMMPS и NAMD мы использовали стенд следующей конфигурации:
- Процессор: Intel Core i7-6950X (Broadwell-E)
- Системная плата: Asus Rampage V Edition 10 (Intel X99)
- Память: 4×4 ГБ DDR4-2400 (Kingston HyperX Predator HX424C12PBK4/16)
- Видеокарта: Nvidia Quadro 600;
- Накопитель: SSD Seagate ST480FN0021 (480 ГБ)
В ходе тестирования замерялось время выполнения тестовых задач в пакетах LAMMPS и NAMD. Рассматривалась зависимость результатов тестирования от количества используемых ядер процессора, от частоты ядер процессора и от частоты памяти.
Зависимость результатов от количества ядер процессора
Количество используемых в ходе тестирования ядер процессора Intel Core i7-6950X регулировалось через настройки UEFI BIOS платы Asus Rampage V Edition 10. Напомним, что процессор Intel Core i7-6950X является 10-ядерным, но поддерживает технологию Hyper-Threading, поэтому операционной системой и приложениями он видится как 20-ядерный (у него 20 логических ядер). Мы не отключали технологию Hyper-Threading и меняли лишь количество физических ядер процессора от 1 до 10. В дальнейшем мы будем говорить о логических ядрах процессора, количество которых менялось от 2 до 20 с шагом 2. Частота работы всех ядер фиксировалась и составляла 4,0 ГГц.
Результаты тестирования следующие:
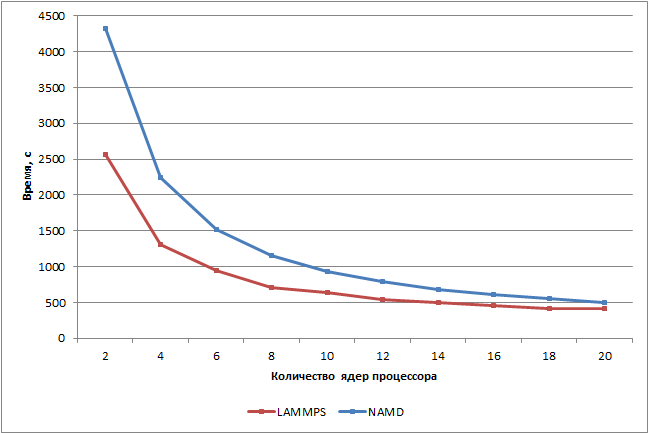
Как видим, зависимость результатов (скорости выполнения тестовых задач) от количества ядер процессора не является линейной. При переходе от двух к четырем ядрам время выполнения теста уменьшается примерно в 1,9 раза и в пакете LAMMPS, и в пакете NAMD. А вот при переходе от 18 к 20 ядрам время выполнения тестовых задач в пакетах LAMMPS и NAMD меняется уже не так значительно (уменьшается на 2,8% в пакете LAMMPS и на 9,8% в пакете NAMD). Тем не менее, сама скорость выполнения тестовых заданий зависит от числа ядер процессора почти линейно. Более наглядно это можно продемонстрировать на графике зависимости нормированной скорости выполнения тестовых задач от числа ядер процессора (нормируется относительно времени выполнения задач на двух логических ядрах процессора).
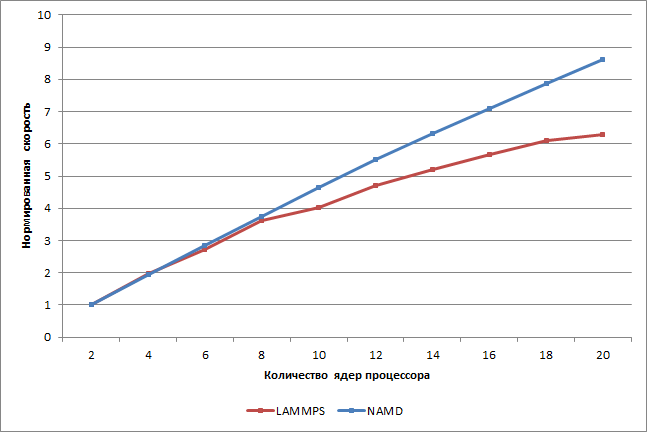
Скорость выполнения тестовых задач в пакете NAMD меняется почти линейно в зависимости от числа ядер процессора. Скорость выполнения тестовых задач в пакете LAMMPS меняется линейно вплоть до 8 логических ядер процессора, а при дальнейшем увеличении ядер процессора (вплоть до 20) начинает наблюдаться тенденция к постепенному насыщению результатов.
В целом, увеличение числа ядер процессора в десять раз (от 2 до 20) приводит к уменьшению времени выполнения теста в 6,3 раза (уменьшение на 84,1%) в пакете LAMMPS и в 8,6 раза (уменьшение на 88,4%) в пакете NAMD.
Зависимость результатов от частоты процессора
Частота ядер процессора Intel Core i7-6950X менялась в настройках UEFI BIOS платы Asus Rampage V Edition 10 путем изменения коэффициента умножения. Частота менялась от 3,0 ГГц до 4,2 ГГц с шагом 200 МГц. Динамическое повышение частоты (режим Turbo Boost) отключалось. Использовались все ядра процессора (10 физических/20 логических ядер).
Результаты тестирования следующие:
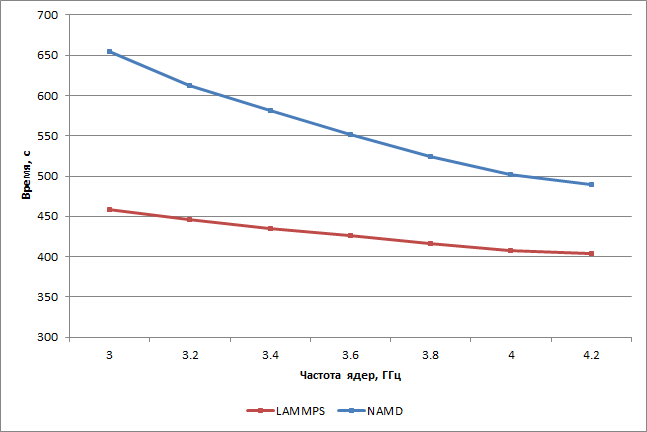
Как видно по результатам, в пакете LAMMPS время выполнения тестовых задач слабо зависит от частоты процессора. При увеличении частоты процессора от 3 до 4,2 ГГц (увеличение на 40%) время выполнения тестовых задач уменьшается всего на 12%. Пакет NAMD более чувствителен к тактовой частоте процессора: так, увеличение тактовой частоты на 40% (с 3 до 4,2 ГГц) приводит к уменьшению времени выполнения теста на 25%.
Сравнивая полученные результаты тестирования с результатами зависимости времени выполнения тестов от числа ядер процессора, можно сделать следующий важный вывод: время выполнения тестовых задач в пакете LAMMPS хуже масштабируется по частоте и количеству ядер процессора в сравнении с тестовыми задачами в пакете NAMD. Теме не менее, и в пакете LAMMPS, и в пакете NAMD тестовые задачи отлично распараллеливаются на все доступные ядра процессора и загружают каждое ядро на 100%.
Зависимость результатов от частоты памяти
Теперь рассмотрим зависимость скорости выполнения тестовых задач от частоты работы памяти DDR4. Память работала в четырехканальном режиме (по одному модулю на канал), а ее частота менялась в настройках UEFI BIOS в диапазоне от 1600 до 2800 МГц c шагом в 200 МГц. Тайминги памяти фиксировались и не менялись при изменении частоты. Все ядра процессора работали на частоте 4,0 ГГц.
Результаты тестирования следующие:
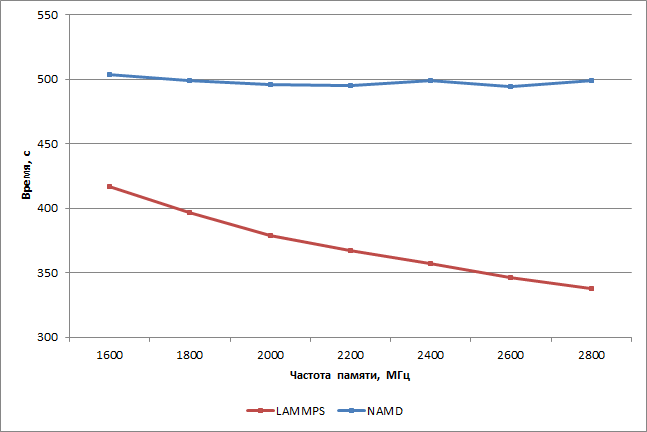
Как видим, скорость выполнения тестовых задач в пакете NAMD практически не зависит от частоты работы памяти. Точнее, в четырехканальном режиме работы памяти пропускной способности DDR4 вполне достаточно даже на частоте 1600 МГц, и дальнейшее увеличение частоты памяти не позволяет ускорить выполнение тестовых задач.
А вот для тестовых задач в пакете LAMMPS ситуация несколько иная. Здесь наблюдается почти линейная зависимость времени выполнения тестовых задач от частоты памяти, и в диапазоне от 1600 до 2800 МГц (при четырехканальном режиме работы) увеличение частоты памяти на 200 МГц позволяет сократить время выполнения тестовых задач примерно на 3-5%. Результат, конечно, довольно скромный, но, тем не менее, зависимость от частоты памяти есть. Увеличение частоты памяти с 1600 до 2800 МГц (на 75%) приводит к суммарному сокращению времени выполнения тестовых задач на 19%.
Заключение
Итак, в первой статье нашего нового цикла мы рассмотрели два теста на основе специализированных приложений молекулярной динамики LAMMPS и NAMD. На примере 10-ядерного процессора Intel Core i7-6950X было показано, что тестовые задачи в этих пакетах хорошо распараллеливаются на все ядра процессора и загружают их на 100%. Именно это обстоятельство позволяет рассматривать данные приложения как отличный вариант для тестирования многоядерных процессоров. Зависимость скорости выполнения тестовых задач от числа ядер процессора является почти линейной для пакета NAMD (в диапазоне от 2 до 20 логических ядер). В приложении LAMMPS зависимость скорости выполнения тестовых задач от числа ядер процессора является почти линейной вплоть до 8 логических ядер, но при большем числе ядер скорость выполнения тестовых задач постепенно насыщается.
Также было показано, что время выполнения тестовых задач в приложении LAMMPS в меньшей степени зависит от частоты ядер процессора, чем в приложении NAMD.
Наконец, было показано, что время выполнения тестовых задач в приложении LAMMPS линейным образом зависит от частоты памяти DDR4 (в четырехканальном режиме и диапазоне от 1600 до 2400 МГц). А вот в приложении NAMD время выполнения тестовых задач вообще никак не зависит от скорости памяти (в тех же оговоренных режимах работы памяти).
В следующей статье данного цикла мы рассмотрим два математических пакета, которые можно использовать для тестирования процессоров и компьютеров: пакет FFTW для реализации быстрого преобразования Фурье и пакет GNU Octave.


