AMD Radeon HD 7970:
описание видеокарты и результаты синтетических тестов
Содержание
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Часть 3 — Результаты игровых тестов (производительность)
В этой части, как обычно, мы изучим саму видеокарту, а также познакомимся с результатами синтетических тестов.
Плата
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | |
|---|---|
|

|
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | |
|---|---|
|
Карта имеет 3072 МБ памяти GDDR5 SDRAM,
размещенной в 12 микросхемах на лицевой сторонe PCB.
Микросхемы памяти Hynix (GDDR5). Микросхемы рассчитаны на максимальную частоту работы в 1400 (5600) МГц. |

|
| Сравнение с эталонным дизайном HD 6970, вид спереди | |
|---|---|
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | Reference card AMD Radeon HD 6970 |

|

|
| Сравнение с эталонным дизайном HD 6970, вид сзади | |
|---|---|
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | Reference card AMD Radeon HD 6970 |

|

|
Понятно, что сравнивать карты с совершенной разной шириной шины обмена с памятью — очень тяжело, но мы по традиции должны кивнуть в сторону предыдущего поколения и сказать: как же все изменилось! :) Вот и сейчас это говорим: из-за того, что много лет продукты топового класса имели шину в 256 бит, теперь их даже тяжело сравнивать с новыми. Хорошо видно, что число микросхем памяти возросло с 8 до 12 (каждая микросхема обеспечивает 32-битный доступ, умножить на 12 — и получим общую шину в 384 бита).
Кроме этого, новое ядро, исполненное по более тонкому техпроцессу, потребляет меньше, и потому требования к блоку питания изменились, что привело к некоторой эволюции последнего (хотя по-прежнему в основе его цифрового управления лежит ШИМ-контроллер CHiL). Производитель постарался уложиться в стандартные габариты, и PCB получилась привычных размеров: 270×100 мм. Общая длина карты с кулером оказалась чуть больше — из-за дизайнерских изысков: плавный изгиб конца кожуха системы охлаждения потребовал вылезти за пределы PCB (сразу вспоминаем Radeon HD 5870).
Все карты серии 79хх оснащены двумя микросхемами BIOS (это новшество было введено в HD 69хх): сделано это во избежание неудачных прошивок новых версий BIOS. Новая карта имеет сверху небольшой переключатель, который просто регулирует, какую из микросхем BIOS задействовать при запуске видеокарты. По умолчанию — номер один.
Подключение к аналоговым мониторам с d-Sub (VGA) производится через специальные адаптеры-переходники DVI-to-d-Sub. Также не должно быть проблем с HDMI: ускорители поддерживают полноценную передачу видео и звука на HDMI-приемник, поскольку обладают собственным звуковым кодеком.
Отметим особо, что карты имеют видеовыходы DisplayPort версии 1.2, поэтому есть возможность с помощью специальных хабов выводить картинку с каждого порта DP на три монитора (в сумме — на шесть).
Напомним также, что топовые продукты AMD обладают поддержкой технологии AMD Eyefinity, обеспечивая вывод картинки игры одновременно на несколько мониторов.
Однако все это было и у семейства 69хх. А из нового — планы поставлять все ускорители серии 79хх в комплекте с адаптерами DP-to-DVI, что позволит выводить изображение на 2 или 3 монитора со входами DVI, и следовательно, Eyefinity можно будет организовывать не только с помощью мониторов со входами DP. Это резко увеличивает привлекательность данной технологии.
Максимальные разрешения и частоты:
- 240 Гц — максимальная частота обновления
- 2048×1536@85 Гц — по аналоговому интерфейсу
- 2560×1600@60 Гц — по цифровому интерфейсу (для DVI-гнезд с Dual-Link/HDMI)
Что касается возможностей по ускорению декодирования видео — в 2007 году мы проводили такое исследование, с ним можно ознакомиться здесь. За эти годы кое-какие изменения и новации случились, но они не настолько революционны, чтобы можно было считать вышеуказанный материал окончательно устаревшим. В ближайшем будущем мы обновим ту статью с учетом произошедших за последние годы изменений.
Карта требует дополнительного питания, причем двумя разъемами: 8-контактным и 6-контактным. Обращайте внимание на переходники питания, которые должны быть в комплектах поставки серийных карт.
А теперь об очень интересной особенности: возможности ухода видеокарты в глубокий «сон». В стандартных настройках энергосбережения Windows предусмотрено гашение монитора через некоторое время неактивности системы, и у множества людей по всему миру компьютеры регулярно входят в этот режим. Остальные компоненты системного блока при этом свой режим работы не меняют (кроме, конечно, центрального процессора, уходящего в сон) — в частности, видеокарта продолжает работать в режиме 2D и на заданных для этого режима частотах. Так вот, теперь Radeon HD 79xx при отключении монитора резко сбрасывает частоты работы, потребляя лишь 3 Вт, и при этом останавливается вентилятор! Это позволяет в целом снизить шум системного блока и потребление энергии; кроме того, кулер в это время не всасывает в себя пыль. Но и этого мало. При работе в системе CrossFire из двух или более карт 79хх, как только завершается работа в 3D-режиме (игрок возвращается в 2D), в работе остается только первая карта, а все остальные точно так же уходят в «сон», потребляя 3 Вт и выключая свои вентиляторы. Эта особенность новых ускорителей нам очень понравилась!
Рассмотрим ядро, то есть сам процессор.

Интересно, что, начиная с этого выпуска, сильно изменилась не только упаковка кристалла, но и маркировка, наносимая теперь на защитную рамку, получившую более сложную и замысловатую форму.
О системе охлаждения.
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | |
|---|---|
Устройство состоит из двух частей: главного радиатора и кожуха.
Главный радиатор базируется на испарительной камере — такой вид кулера AMD начала использовать еще на картах HD 6970. Испарительная камера сделана из медного сплава, одной стороной она прижимается к ядру и микросхемам памяти (через специальные термоинтерфейсы), а с другой стороны имеет массивное оребрение, через которое гонит воздух цилиндрический вентилятор, закрепленный на одном конце кожуха. Данный вариант кулера является очень эффективным, причем охлаждает он одновременно ядро и микросхемы памяти. Вентилятор в 2D-режиме работает на очень малых оборотах, и даже в 3D максимальная раскрутка, которую мы лицезрели, составляла всего 47% от предельной. Шума даже в таком случае почти не было слышно. СО очень хороша сама по себе, да и переход на новый техпроцесс привел к падению энергопотребления. |

|

|
|
Мы провели исследование температурного режима с помощью утилиты MSI Afterburner (автор А. Николайчук AKA Unwinder) и получили следующие результаты:
| AMD Radeon HD 7970 3072 МБ 384-битной GDDR5 PCI-E | |
|---|---|
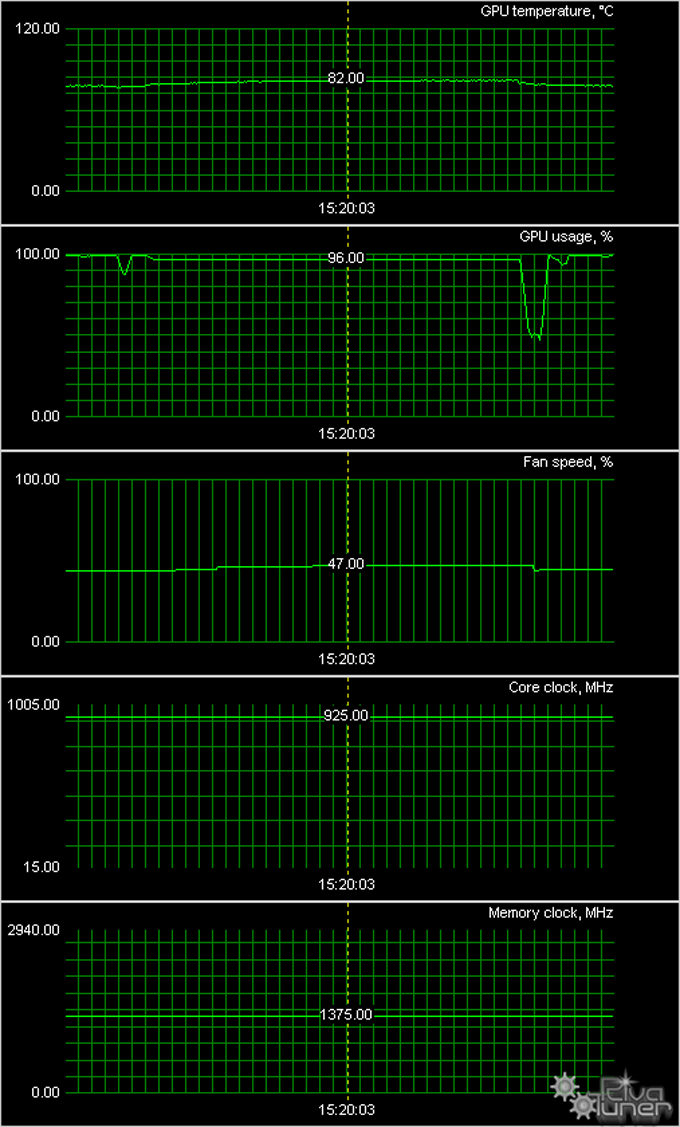
|
|
Ну, как и следовало ожидать, все в рамках приличий: нагрев ядра в 82 градуса после 6-часовой нагрузки в 3D — это ерунда для ускорителей класса Hi-End. СО отработала отлично!
Немного затронем тему драйверов. Как известно, всеми настройками и установками управляет утилита Catalyst Control Center (CCC), которая органично встроена в комплект ПО Catalyst вместе с драйверами. Долгое время у нас были нарекания на качество работы ССС — особенно на время запуска этой утилиты (приходилось подолгу ждать, пока откроется окно настроек). Надо сказать, что за последние годы программистам AMD удалось сильно модернизировать CCC, и в конце концов утилита приобрела более комфортный интерфейс, а также резко уменьшилось время отклика. Ниже мы приведем лишь фрагменты новых настроек и обратим внимание на измененную панель OverDrive.
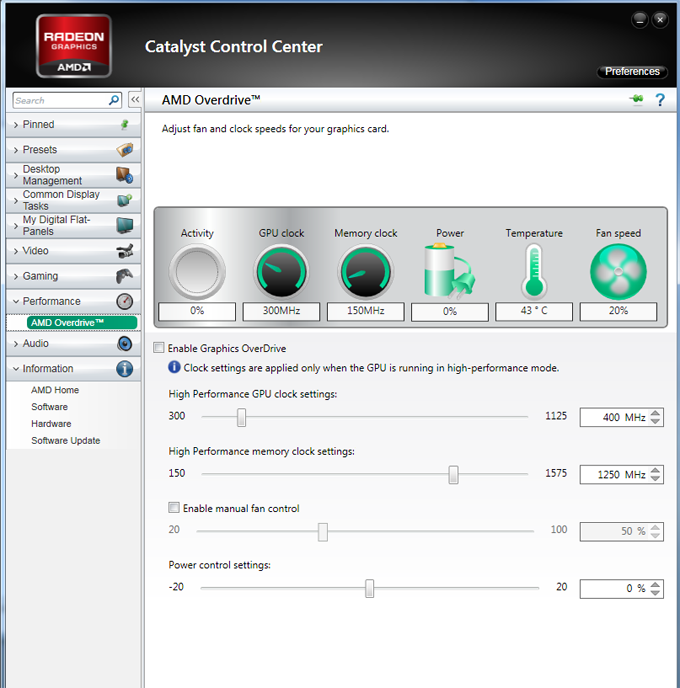
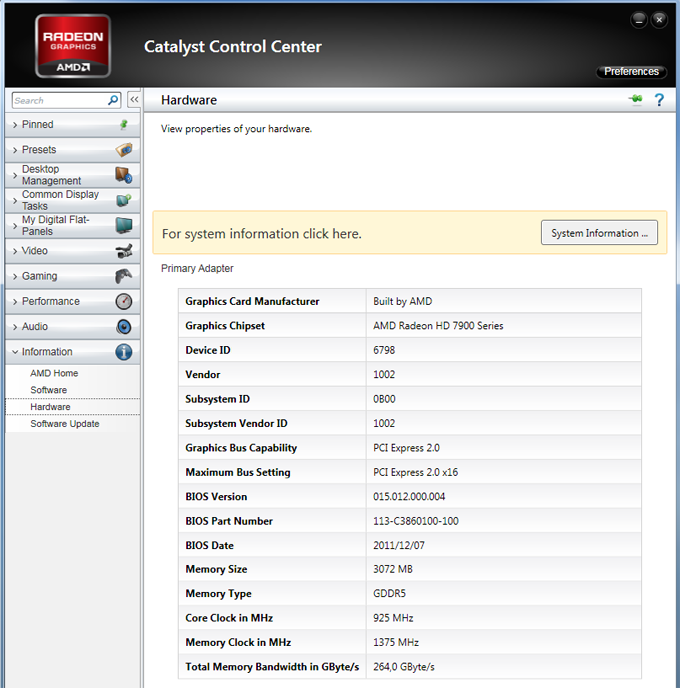
Помнится, еще в начале 3D-эпохи, когда появились первые карты семейства Rage, Rage 128 и даже первые Radeon, специалисты тогдашней компании ATI (которая ныне в составе AMD) были категорически против разгона и даже против того, чтобы пользователи вообще были в курсе о частотах работы. Эти показатели они прятали всеми возможными способами, и приходилось придумывать утилиты, умеющие влезать в BIOS карты или регистры ядра, добывать там информацию о частотах и даже менять их. Но, как говорится, против лома нет приема, и после того, как оверклокинг приобрел относительно массовый характер (а также потому, что оверклокеры составляли основную часть покупателей топовых ускорителей), политика резко поменялась. Сейчас мы видим, что панель OverDrive доступна всем и каждому, там можно не только посмотреть, но и поменять частоты в пределах допустимых границ (так, чтобы это было относительно безопасно для видеокарты). Стоит отметить, что даже у компании Nvidia в драйверах по умолчанию таких возможностей нет: для их получения надо скачать Nvidia Software Utility, которая и добавит в панель настроек драйверов соответствующую закладку с настройками разгона.
Видеокарта прибыла к нам без упаковки и комплекта, потому вопрос комплектации мы опускаем.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core i7-975 (Socket 1366)
- процессор Intel Core i7-975 (3340 МГц);
- системная плата Asus P6T Deluxe на чипсете Intel X58;
- оперативная память 6 ГБ DDR3 SDRAM Corsair 1600 МГц;
- жесткий диск WD Caviar SE WD1600JD 160 ГБ SATA;
- блок питания Tagan TG900-BZ 900 Вт.
- операционная система Windows 7 64-битная; DirectX 11;
- монитор Dell 3007WFP (30″);
- драйверы AMD версии Catalyst 11.12; Nvidia версии 290.36
VSync отключен.
Синтетические тесты
Используемые нами пакеты синтетических тестов можно скачать здесь:
- D3D RightMark Beta 4 (1050) с описанием на сайте 3d.rightmark.org.
- D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3 — тесты пиксельных шейдеров версий 2.0 и 3.0, ссылка.
- RightMark3D 2.0 с кратким описанием: под Vista без SP1, под Vista c SP1.
Для работы RightMark3D 2.0 требуется установленный пакет MS Visual Studio 2005 runtime, а также последнее обновление DirectX runtime.
За неимением собственных синтетических тестов DirectX 11 мы снова воспользовались примерами из пакетов SDK Microsoft и AMD и демонстрационной программой Nvidia. Во-первых, это HDRToneMappingCS11.exe и NBodyGravityCS11.exe из комплекта DirectX SDK (February 2010).
Также мы взяли приложения обоих производителей: Nvidia и AMD. Из ATI Radeon SDK были взяты примеры DetailTessellation11 и PNTriangles11 (они также есть и в DirectX SDK). Дополнительно использовалась демонстрационная программа компании Nvidia — Realistic Water Terrain, также известная как Island11 (автор — Тимофей Чеблоков, известный специалист по 3D-графике).
Синтетические тесты проводились на следующих видеокартах:
- Radeon HD 7970 со стандартными параметрами (далее HD 7970)
- Radeon HD 6990 со стандартными параметрами (далее HD 6990)
- Radeon HD 6970 со стандартными параметрами (далее HD 6970)
- Radeon HD 5870 со стандартными параметрами (далее HD 5870)
- Geforce GTX 590 со стандартными параметрами (далее GTX 590)
- Geforce GTX 580 со стандартными параметрами (далее GTX 580)
Для сравнения результатов новейшей видеокарты Radeon HD 7970 именно эти модели были выбраны по разным причинам. Radeon HD 6970 была взята, как прямой предшественник топового сегмента, HD 6990 — как сильнейшее (пусть и двухчиповое) решение на GPU предыдущей архитектуры, HD 5870 мы добавили, чтобы оценить прирост между двумя разными обновлениями архитектур и как GPU ровно вдвое меньшей сложности, чем Tahiti.
Выбранные решения Nvidia взяты потому, что Geforce GTX 580 — быстрейшая одночиповая модель этой компании, основанная на GPU последнего поколения. Хотя она не является конкурентом представленной видеокарты AMD по цене, её результаты интересны как максимальные для нынешних одночиповых решений Nvidia. А двухчиповая GTX 590 является экстремальным вариантом этой компании с более высокой ценой. В тестах DirectX 11 мы использовали ещё и Geforce GTX 560 Ti, которая нужна для того, чтобы оценить увеличенную геометрическую производительность нового графического процессора AMD.
Direct3D 9: тесты Pixel Filling
В этом тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:
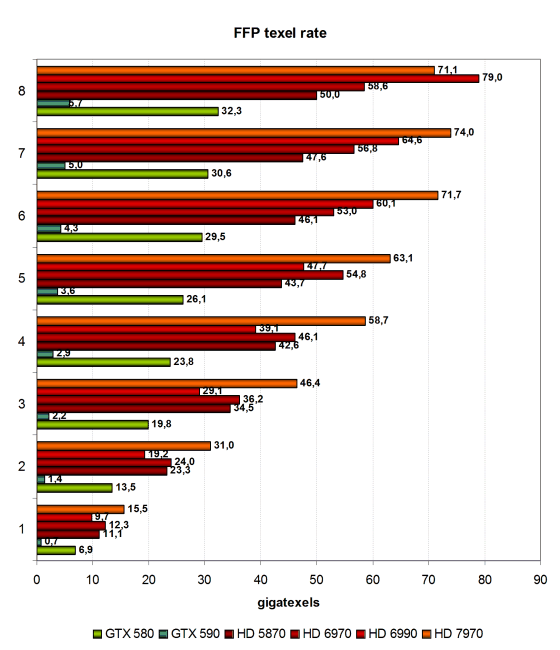
В нашем устаревшем тесте фильтрации 32-битных текстур из RightMark большинство видеокарт показывает цифры, далёкие от теоретически возможных. Вот и результаты текстурной синтетики в случае видеоплаты Radeon HD 7970 не дотянули до пикового значения, поэтому мы ещё раз рассмотрим скорость текстурирования по цифрам из теста 3DMark Vantage, в котором всегда получаются более реалистичные цифры.
У нас же получилось, что HD 7970 выбирает лишь до 80 текселей за такт из 32-битных текстур при билинейной фильтрации, что значительно ниже теоретической цифры в 128 отфильтрованных текселей. В остальном, всё получилось предсказуемо — все платы производства AMD показали более высокую производительность и опережают видеокарты компании Nvidia. Ведь даже топовая одночиповая Geforce GTX 580 имеет лишь 64 TMU и поэтому сильно уступает модели на базе чипа Tahiti, имеющем 128 TMU, работающих на более высокой частоте. Поэтому и разница более чем двукратная. Ну а двухчиповый GTX 590 в этом тесте показывает явно неадекватный результат.
Вариант платы на двух GPU от компании AMD также явно некорректно работает в нашем тесте, ведь HD 7970 обгоняет почти всегда даже его. Ну а своего предшественника новая модель обогнала примерно на 30%, что чуть хуже теоретически возможного значений. Впрочем, в случаях с малым количеством текстур, когда больше всего сказывается пропускная способность памяти, результат ещё ниже — порядка 25%.
Рассмотрим эти же результаты в тесте филлрейта:
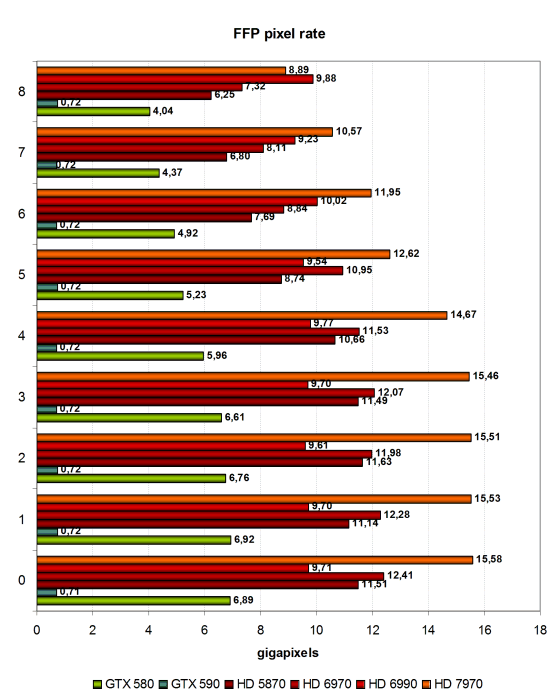
Цифры показывают скорость заполнения, и в них мы видим всё то же самое, разве что с учетом количества записанных в буфер кадра пикселей. Максимальный результат почти всегда остаётся за новой топовой видеокартой из семейства Radeon HD 7900. Она имеет рекордное количество TMU, работающих на более высокой частоте и более эффективных в нашем синтетическом тесте. Переходим к текстам простых пиксельных шейдеров.
Direct3D 9: тесты Pixel Shaders
Первая группа пиксельных шейдеров, которую мы рассматриваем, очень проста для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0, встречающихся в старых играх.
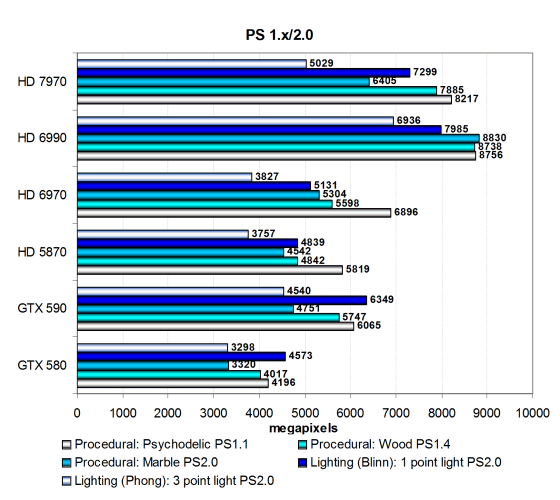
Эти тесты слишком просты для современных GPU и в основном ограничены производительностью текстурирования и иногда филлрейтом. Поэтому они показывают далеко не все возможности современных видеочипов, но интересны с точки зрения устаревших игровых приложений. В двух самых простых тестах новый Radeon HD 7970 почти догнал даже двухчиповый HD 6990, но в более сложных занял позицию между HD 6990 и HD 6970. Интересно, как отличается поведение тестов на GPU разных архитектур. И тут Tahiti несколько ближе к GF110, чем к предшественнику. Естественно, не по абсолютным цифрам, разница в них весьма велика — от полутора до двух раз.
Производительность в других тестах ограничена по большей части скоростью текстурных модулей и филлрейтом, поэтому новый Radeon HD 7970 получился быстрее предшествующего HD 6970 примерно на 30-40%, что соответствует теории. Все платы AMD опережают обе топовые модели Geforce, разве что в сравнении HD 5870 и GTX 590 всё не так однозначно. В неудачах Nvidia в этих тестах явно виноват недостаток скорости текстурирования. Но даже пиксельный шейдер освещения тремя источниками по Фонгу, больше зависящий от математической производительности GPU, при запуске на GF110 сильно уступает и Cayman и уж тем более Tahiti.
Посмотрим на результаты более сложных пиксельных программ промежуточных версий:
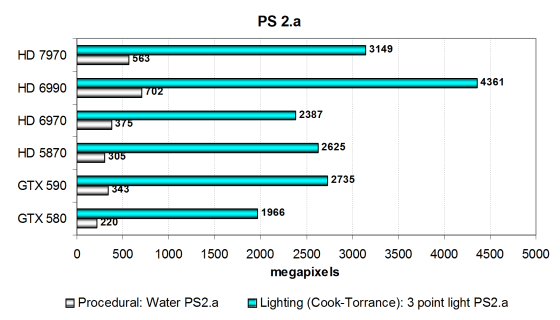
Вот и в этот раз получилось примерно то же самое, HD 7970 расположился примерно между одночиповой и двухчиповой моделями на базе Cayman из серии HD 6900. Тест Cook-Torrance более интенсивен вычислительно, и разница в нём примерно соответствует разнице в количестве ALU и их частоте. Поэтому данный тест лучше подходит для архитектуры AMD, чипы которой имеют большее количество математических блоков, и Tahiti тут не исключение.
Интересно, что в этом тесте HD 5870 обгоняет HD 6970, и похоже, что так получилось из-за худшей эффективности исполнения этого шейдера на более новом чипе с VLIW4 архитектурой. Так что, хотя новый Radeon HD 7970 и обошёл HD 6970, он оказался быстрее HD 5870 в этом тесте лишь на 20%.
Во втором, сильнее зависящем от скорости текстурирования, тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, и видеокарты в нём располагаются по скорости текстурирования, с поправкой на разную эффективность использования TMU. В этом тесте у решений компании AMD всегда всё прекрасно, и HD 7970 обеспечивает очень хороший результат, хотя и хуже, чем у двухчиповой HD 6990, но гораздо лучший, чем у предшественника на Cayman. Топовая одночиповая плата Nvidia отстала более чем в 2,5 раза!
Direct3D 9: тесты пиксельных шейдеров Pixel Shaders 2.0
Эти тесты пиксельных шейдеров DirectX 9 сложнее предыдущих, они близки к тому, что мы сейчас видим в мультиплатформенных играх, и делятся на две категории. Начнем с более простых шейдеров версии 2.0:
- Parallax Mapping — знакомый по большинству современных игр метод наложения текстур, подробно описанный в статье Современная терминология 3D-графики.
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами.
Существует два варианта этих шейдеров: с ориентацией на математические вычисления и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:
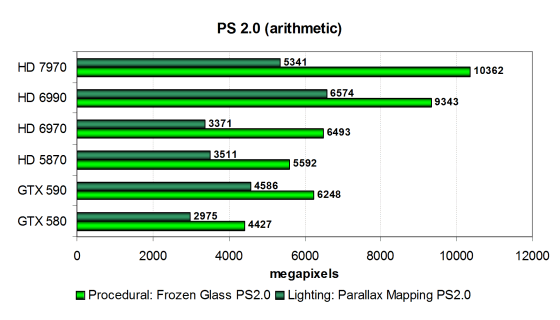
Это — универсальные тесты, зависящие и от скорости блоков ALU, и от скорости текстурирования, в них важен общий баланс чипа, а также эффективность исполнения сложных программ. И производительность новой видеокарты AMD в тесте «Frozen Glass» оказалась не просто хорошей, но отличной! Вот что значит повышенная эффективность нового GPU. Radeon HD 7970 в первом тесте оказалась заметно быстрее даже чем двухчиповая HD 6990. А даже двухчиповая плата Nvidia осталась далеко позади, не говоря уже о Geforce GTX 580.
Вот во втором тесте «Parallax Mapping» решения Nvidia чувствуют себя немного лучше, и GTX 580 почти достаёт HD 6970. А вот до представленной сегодня HD 7970 очень далеко — новинка AMD опережает лучшую плату Nvidia на 80%, что явно говорит о влиянии и математических расчётов и скорости текстурирования. Интересно, что совсем старая HD 5870 снова быстрее, чем HD 6970. Да и новая HD 7970 обогнала предшественницу на 60%, что явно не оправдать сухими теоретическими цифрами. Тут сказалась заметно большая эффективность скалярной архитектуры, по сравнению с VLIW.
Впрочем, в случае видеокарт AMD всё очень сложно из-за PowerTune. Ведь синтетические тесты очень сильно «грузят» GPU расчётами и энергопотребление плат с поддержкой PowerTune в синтетике вполне может выходить за рамки выставленного ограничения. Следовательно, может снижаться и тактовая частота GPU, а вместе с ней и результаты будут показаны ниже, чем ожидалось. Рассмотрим эти же тесты в модификации с предпочтением выборок из текстур математическим вычислениям:
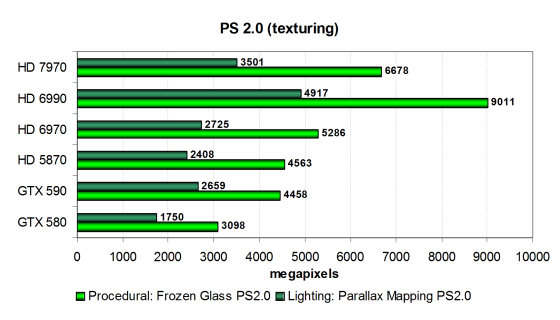
Для обеих видеоплат Nvidia ситуация стала ещё печальнее, так как со скоростью текстурирования у всех современных чипов AMD всё намного лучше, и в этих тестах они лишь наращивают своё бесспорное преимущество. Даже двухчиповая GTX 590 не может соперничать с одночиповым HD 6970 в обоих тестах с упором на текстурирование, не говоря о GTX 580. Ну а представленная сегодня плата из семейства Radeon HD 7900 оказалась быстрейшей среди одночиповых карт, уступив только HD 6990. Разница между HD 7970 и HD 6970 оказалась равна 26-28%, что хорошо объяснимо теоретически, так как разница в скорости текстурирования у новинки немногим больше.
Но это были устаревшие задачи, в основном с упором в текстурирование, и иногда в филлрейт. Далее мы рассмотрим результаты ещё двух тестов пиксельных шейдеров — но уже версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9 API. Они наиболее показательны с точки зрения современных игр на ПК, среди которых много мультиплатформенных. Тесты отличаются тем, что сильно нагружают и ALU, и текстурные модули, обе шейдерные программы сложны и длинны, и включают большое количество ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, также описанная в статье Современная терминология 3D-графики.
- Fur — процедурный шейдер, визуализирующий мех.
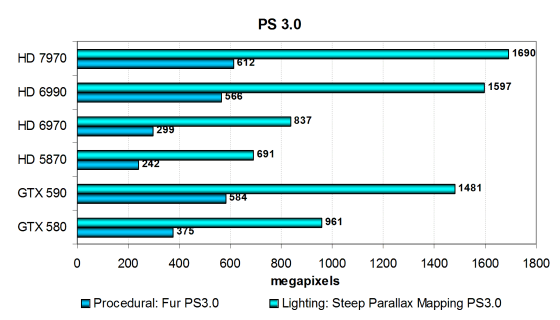
В самых сложных DX9-тестах из RightMark видеокарты производства Nvidia всегда выступают очень сильно, в противоположность всем предыдущим испытаниям нашего обзора. Эти тесты не ограничены производительностью текстурных выборок, а зависят скорее от эффективности исполнения шейдерного кода. И ранее Radeon HD 6970 явно улучшил позиции AMD в данном тесте, увеличив эффективность при переходе от архитектуры VLIW5 к VLIW4.
Ну а сегодня мы увидели очередной скачок в производительности решений компании, Radeon HD 7970 поднял их на недосягаемый уровень — новая одночиповая видеоплата обошла даже двухчиповый HD 6990 в обоих тестах! Эти задачи — отличный пример улучшения реальной производительности сложных вычислений при переходе от VLIW к скалярному исполнению.
Итак, в тестах сложных пиксельных шейдеров версии 3.0 новая топовая видеокарта AMD смогла не только догнать конкурентов, но и опередить со значительным запасом, чего не было очень давно. Скорость в обоих тестах PS 3.0 слабо зависит от ПСП и текстурирования, зато код отличается сложностью, с чем очень неплохо справляется и архитектура Nvidia и новейшая скалярная архитектура AMD. Эти тесты одни из первых, где мы отмечаем явное улучшение эффективности и наибольшую положительную разницу между предыдущей и новейшей архитектурами компании AMD по скорости.
Но приведём цифры, чтобы не быть голословными. Представленная новинка Radeon HD 7970 быстрее предшественницы более чем вдвое, и на 60-70% быстрее Geforce GTX 580, о чём совсем недавно мы даже и подумать бы не решились. Ведь решения Nvidia всегда были неоспоримыми лидерами в этой паре тестовых задач, но видеокарты на Cayman смогли к ним приблизиться, а быстрейший из Tahiti наконец-то опередил конкурента.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)
Во вторую версию RightMark3D вошли два знакомых теста PS 3.0 под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсэмплинга, что дополнительно увеличивает нагрузку на видеочипы.
Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере.
Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40—80, включение «шейдерного» суперсэмплинга — до 60—120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот.
Проверим сначала режимы без включенного суперсэмплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым.
Производительность в этом тесте зависит от количества и эффективности блоков TMU, и от эффективности выполнения сложных программ. В варианте без суперсэмплинга дополнительное влияние на производительность оказывает эффективный филлрейт (производительность ROP) и пропускная способность памяти. Результаты при детализации уровня «High» получаются примерно в полтора раза ниже, чем при «Low», как и должно быть по теории, но для быстрейших решений разница несколько ниже.
Ранее в тестах процедурной визуализации меха с большим количеством текстурных выборок решения Nvidia были заметно сильнее, но начиная с предыдущего поколения компании AMD, разница начала сокращаться. Что же получилось у Radeon HD 7970? Отличный результат — новинка AMD снова оказалась быстрее двухчиповой платы предыдущего поколения, а одночиповая HD 6970 отстала вдвое, что явно говорит об увеличении эффективности новой архитектуры Southern Islands. Да и решения компании Nvidia остались позади, даже двухчиповая GTX 590 уступила представленной сегодня топовой модели Radeon HD 7970.
Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсэмплингом, увеличивающим работу в четыре раза: возможно, в такой ситуации что-то изменится, и ПСП с филлрейтом будут влиять меньше:
Включение суперсэмплинга увеличивает теоретическую нагрузку в четыре раза, и результаты решений Nvidia всегда падают, по сравнению с показателями видеокарт AMD. Теперь разница в эффективности выполнения данной задачи ещё более очевидна, и новая модель HD 7970 быстрее HD 6970 в 2,5 раза! Примерно столько же новинке уступила и Geforce GTX 580. Вполне естественно, что даже HD 6990 осталась далеко позади, а новая плата укрепила лидерство, да какое…
Второй шейдерный DX10-тест измеряет производительность исполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок и называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением число выборок возрастает в два раза, а суперсэмплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсэмплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше по сравнению с простым режимом. Проверяем сначала простые варианты без суперсэмплинга:
Второй пиксель-шейдерный тест Direct3D 10 несколько интереснее с практической точки зрения, так как разновидности parallax mapping широко применяются в играх, а тяжелые варианты, вроде нашего steep parallax mapping используются во многих проектах, например в играх серий Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсэмплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип примерно в два раза, такой режим называется «High».
Эта диаграмма похожа на предыдущую без включения SSAA, но позиции Nvidia ещё немного ослабли, да и Radeon HD 6990 почти догнала представленную сегодня модель. В обновленном D3D10-варианте теста без суперсэмплинга HD 7970 показывает отличный результат, значительно опережая и HD 6970 и GTX 580 и даже GTX 590. Лидерство делят HD 7970 и HD 6990, а две старые видеокарты производства AMD показывают схожие результаты и сильно (в два и более раза медленнее новой модели) отстают. Посмотрим, что изменит включение суперсэмплинга, он может вызвать сильное падение скорости на платах Nvidia.
При включении суперсэмплинга и самозатенения, задача получается ещё более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая большое падение производительности. Разница между скоростными показателями протестированных видеокарт изменилась, включение суперсэмплинга сказывается, как и в предыдущем случае — карты производства AMD улучшили свои показатели относительно решений Nvidia.
И теперь Radeon HD 7970 снова становится единоличным лидером сравнения, показывая результаты выше, чем у HD 6990. Более старые одночиповые платы компании далеко позади, вместе с ними и Geforce GTX 580. И лишь более дорогие двухчиповые варианты от AMD и Nvidia способны хоть как-то приблизиться к свежей видеоплате. В общем, по двум шейдерным D3D10 тестам можно сделать вывод, что новая архитектура AMD и её представитель на чипе Tahiti великолепно справляется с «шейдерными» задачами, даже лучше традиционно сильных в них конкурентов от Nvidia.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (вычисления)
Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере.
Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos.
Результаты предельных математических тестов обычно соответствуют разнице в частотах и количестве исполнительных блоков, но с некоторым влиянием разной эффективности их использования. Все последние архитектуры AMD в таких случаях имеют подавляющее преимущество перед конкурирующими видеокартами Nvidia, и это объясняет результаты тестов, в которых решения AMD снова оказываются значительно более производительными.
Решения расположились примерно соответственно теории, но за некоторыми исключениями. На практике открылись некоторые нюансы, связанные с различной эффективностью. Теоретически, Geforce GTX 580 должна быть более чем вдвое (2,4 раза) медленнее, чем новая модель Radeon HD 7970, на практике же разница составляет лишь 80%, что значительно меньше. Да и при сравнении с HD 6970 возникают вопросы оптимизации новой архитектуры и драйверов для неё к этому тесту. При теоретическом превосходстве по вычислениям в 40%, новая плата AMD лишь на 28% быстрее предыдущей — HD 6970, а ещё меньше дистанция между ней и совсем старой HD 5870, основанной на VLIW5-архитектуре. То ли тест действительно лучше подходит для VLIW (особенно для VLIW5), то ли виноваты ещё сырые драйверы.
Есть и ещё одно объяснение — возможно, на результаты плат HD 7970 HD 6970 в этом тесте повлияла технология PowerTune, снизившая частоты при достижении предела энергопотребления. Впрочем, всё это мало что меняет при сравнении с конкурентом, ведь даже дорогущая двухчиповая плата Geforce GTX 590 лишь достигла уровня HD 6970 и HD 5870. А уж одночиповая GTX 580 так и вовсе далеко позади.
Рассмотрим второй тест шейдерных вычислений, который носит название Fire. Он тяжелее для ALU, и текстурная выборка в нём только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки:
Мы видим почти идентичную предыдущей диаграмму, за исключением абсолютных цифр. В этот раз все GPU остались примерно на тех же позициях, ну разве что видеоплаты на базе Cayman и Cypress поменялись местами — теперь чуть-чуть быстрее более новая модель, но совсем незначительно. Хотя строгого соответствия теоретическим цифрам пиковой производительности всё так же нет, но их результаты всё-таки близки к сухой теории. Разница между HD 7990 и HD 6970 немного увеличилась.
В остальном, мы не нашли на графике ничего нового. Скорость рендеринга в этом тесте ограничена исключительно производительностью шейдерных блоков и их эффективностью, поэтому двухчиповая HD 6990 снова стала явным лидером, а за ней на приличном отдалении следует сегодняшняя новинка от AMD. Обе платы Geforce уступают даже устаревшей модели из семейства Radeon HD 5800, но и в этот раз преимущество решений AMD остаётся несколько меньшим, чем при сравнении теоретических цифр, и это снова говорит о худшей оптимизации или влиянии PowerTune.
Direct3D 10: тесты геометрических шейдеров
В пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующие частицу. Аналогичные алгоритмы должны получить широкое использование в будущих играх под DirectX 10.
Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково.
Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности:
Соотношение скоростей при разной геометрической сложности сцен примерно одинаково для всех решений, производительность соответствует количеству точек, с каждым шагом падение FPS составляет около двух раз. Задача для современных видеокарт не слишком сложная, и производительность ограничена в основном скоростью обработки геометрии, но ещё и пропускной способностью памяти/филлрейтом (в рамках решений одного производителя).
В этом тесте должны были проявиться улучшенные возможности Southern Islands по обработке геометрии, вот они и проявились. Новая видеокарта AMD действительно гораздо быстрее выполняет геометрические расчёты, по сравнению со всеми предыдущими решениями компании. Хотя AMD дала цифры прироста до 4 раз, но в этом тесте геометрическая производительность выросла примерно в 1,5-2 раза. В итоге, одночиповая видеокарта оказалась примерно на том же уровне, что и двухчиповая модель Radeon HD 6990 на GPU предыдущего поколения.
Столь значительное улучшение привело к тому, что Tahiti практически догнала топовую видеокарту Nvidia, хотя выполнение геометрических шейдеров у той в некоторых условиях должно быть ещё эффективнее. Ранее видеокарты Nvidia справлялись с работой примерно вдвое быстрее аналогичных видеокарт конкурента, а теперь разницы совсем нет. Посмотрим, как изменится ситуация при переносе части вычислений в геометрический шейдер:
При изменении нагрузки в этом тесте цифры почти не изменились для решений Nvidia и большинства плат AMD. Лишь новая видеокарта из семейства HD 7900 в данном тесте слабо отреагировала на изменение параметра GS load, отвечающего за перенос части вычислений в геометрический шейдер. Поэтому плата показала результат чуть выше, чем на предыдущей диаграмме. Посмотрим, что изменится в следующем тесте, который предполагает большую нагрузку именно на геометрические шейдеры.
«Hyperlight» — это второй тест геометрических шейдеров, демонстрирующий использование сразу нескольких техник: instancing, stream output, buffer load. В нем используется динамическое создание геометрии при помощи отрисовки в два буфера, а также новая возможность Direct3D 10 — stream output. Первый шейдер генерирует направление лучей, скорость и направление их роста, эти данные помещаются в буфер, который используется вторым шейдером для отрисовки. По каждой точке луча строятся 14 вершин по кругу, всего до миллиона выходных точек.
Новый тип шейдерных программ используется для генерации «лучей», а с параметром «GS load», выставленным в «Heavy» — ещё и для их отрисовки. То есть в режиме «Balanced» геометрические шейдеры используются только для создания и «роста» лучей, вывод осуществляется при помощи «instancing», а в режиме «Heavy» выводом также занимается геометрический шейдер. Сначала рассматриваем лёгкий режим:
Относительные результаты в разных режимах снова примерно соответствуют изменению нагрузки: во всех случаях производительность неплохо масштабируется и близка к теоретическим параметрам, по которым каждый следующий уровень «Polygon count» должен быть менее чем в два раза медленней.
В этом тесте скорость рендеринга должна быть ограничена геометрической производительностью, и новая архитектура от компании AMD показывает себя просто отлично, даже немного обгоняя конкурента в лице Geforce GTX 580! Обе двухчиповые платы тут показали некорректные результаты, поэтому с ними сравнения не получится. Зато HD 7970 на 40-50% быстрее своей предшественницы — модели HD 6970, что явно объясняется архитектурными изменениями в GPU. Отличные результаты карты на Tahiti явно свидетельствуют о проведённой оптимизаций в блоках обработки геометрических данных в новом чипе.
Цифры должны сильно измениться на следующей диаграмме, в тесте с более активным использованием геометрических шейдеров. Также будет интересно сравнить друг с другом результаты, полученные в режимах «Balanced» и «Heavy».
А вот тут рекорда у Radeon HD 7970 не получилось, всё-таки разница между чипами AMD с традиционным графическим конвейером (в т. ч. и Cayman с Tahiti с двумя растеризаторами) и чипами с архитектурой Fermi, имеющей распараллеленную обработку геометрии, хорошо заметна. И результаты Geforce GTX 580, имеющей в своей основе чип GF110, хороши настолько, что она обгоняет лучшее из решений компании AMD (а это анонсированная сегодня модель) на 35-40%.
Хотя возможности новенького топового чипа AMD по обработке геометрии и скорости исполнения геометрических шейдеров явно выросли по сравнению с предыдущими видеокартами компании, и первое решение на чипе Tahiti показывают в этих тестах результаты на 22-28% выше, чем решения на базе Cayman. Вероятно, инженеры AMD решили, что такой оптимизации блоков установки треугольников и обработки геометрии будет вполне достаточно.
Direct3D 10: скорость выборки текстур из вершинных шейдеров
В тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути, так что соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет.
Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»:
Предыдущие исследования показали, что на результаты этого теста влияет сразу многое: и скорость текстурирования и пропускная способность памяти. И результаты видеокарт часто ограничены некоей преградой — посмотрите хотя бы на сравнение двухчиповой GTX 590 и одночипового аналога — между ними почти нет разницы. Хотя HD 6990 вдвое быстрее HD 6970.
Да и новая плата AMD из семейства Radeon HD 7970 показала очень хорошие результаты, почти догнав лидирующую HD 6990. Что касается одночиповых конкурентов, то она лучшая во всех трёх режимах. Преимущество над HD 6970 составило от 25% до 75%, в зависимости от режима. Посмотрим на производительность в этом же тесте с увеличенным количеством текстурных выборок:
А вот в этот раз взаимное расположение карт на диаграмме заметно изменилось, и особенно это касается тяжёлого режима. При малом количестве полигонов скорость рендеринга в этом тесте упирается в ПСП, поэтому платы AMD и были так сильны на предыдущей диаграмме.
А вот в тяжёлых режимах разница между одночиповой картой Nvidia и новинкой AMD сократилась, и они соперничают между собой в довольно плотной борьбе. Старшая двухчиповая видеокарта семейства Radeon HD 6900 обгоняет все остальные решения и является лучшей в сравнении, хотя в тяжёлом режиме к ней подбирается и Geforce GTX 590. Новая же одночиповая HD 7970 выигрывает у предшественницы снова до 70%, что может говорить о сильном влиянии ПСП.
Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту.
Результаты во втором тесте вершинного текстурирования «Waves» абсолютно не похожи на то, что мы видели на предыдущих диаграммах. В этом тесте видеокарты AMD и Nvidia, кроме HD 6990 и HD 7970, показывают очень близкие результаты, что снова можно списать на ограничение пропускной способностью видеопамяти, так как этот показатель у всех представленных видеокарт близок.
А вот новая модель из семейства Southern Islands смогла выделиться, в сложных условиях сравнения почти догнав двухчиповую HD 6990, которая стала лучшей среди всех видеокарт. Разница между картами на базе графических процессоров Cayman и Tahiti снова составила 25-70% в пользу более нового решения. Рассмотрим второй вариант этого же теста:
И тут произошли изменения, аналогичные тем, что мы видели ранее — видеокарты Nvidia «просели» только в лёгком режиме, а большинство решений AMD — сразу во всех. Впрочем, это не позволило платам калифорнийской компании догнать новинку семейства Radeon 7900. Которая, кстати, обогнала всех в среднем и тяжёлом режимах, уступив двухчиповой HD 6990 только один раз.
В режиме с малым количеством полигонов разница между решениями не такая большая, а вот в среднем и тяжёлом старые решения AMD уступают, затем идут платы Nvidia (двухчиповая лишь немного быстрее одночиповой GTX 580), HD 6990 и HD 7970. Анонсированная сегодня плата семейства HD 7900 в тестах вершинных выборок показала себя отлично, с запасом обогнав и конкурирующие видеокарты Nvidia и предшественников от того же производителя.
3DMark Vantage: тесты Feature
Как всегда, синтетические тесты из пакета 3DMark Vantage могут показать нам что-то, что мы ранее упустили. Тесты Feature этого тестового пакета обладают поддержкой DirectX 10 и интересны тем, что отличаются от наших. При анализе результатов новой видеокарты Radeon HD 7970 в этом пакете мы сможем сделать какие-то новые и полезные выводы, ускользнувшие от нас в тестах семейства RightMark.
Feature Test 1: Texture FillПервый тест — тест скорости текстурных выборок. Используется заполнение прямоугольника значениями, считываемыми из маленькой текстуры с использованием многочисленных текстурных координат, которые изменяются каждый кадр.
Хотя тест компании Futuremark всё так же не показывает теоретически возможного уровня скорости текстурных выборок, но всё же эффективность видеокарт и AMD и Nvidia в нём заметно выше, чем в нашем из RightMark. Поэтому в данном текстурном тесте получается несколько иное соотношение результатов, которое ближе к истине.
Первая видеокарта из нового семейства компании AMD показывает результат, близкий к соответствующему теоретическому параметру, и она справляется с работой эффективнее предыдущего поколения. Radeon HD 7970 опережает HD 6970 более чем на 50%, хотя по теории разница составляет лишь 40%. Вероятнее всего, текстурные модули Tahiti используются эффективнее из-за улучшений в системе памяти и кэширования, что и вызвало повышенный результат.
Конечно, новая одночиповая модель не дотянула до лидера — двухчиповой HD 6990, но это и не ожидалось. И всё же, хорошо видно, что текстурная производительность графического чипа Tahiti заметно выросла по сравнению с Cayman. Ну а GTX 580 проигрывает новинке по скорости текстурирования целых 2,3 раза. Даже двухчиповая карта Nvidia догоняет лишь HD 6970.
Feature Test 2: Color FillЭто тест скорости заполнения. Используется очень простой пиксельный шейдер, не ограничивающий производительность. Интерполированное значение цвета записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется 16-битный внеэкранный буфер формата FP16, наиболее часто используемый в играх, применяющих HDR-рендеринг, поэтому такой тест является вполне своевременным.
Ситуация в тесте производительности блоков ROP серьёзно отличается от теста текстурирования. Цифры этого подтеста из 3DMark Vantage показывают производительность блоков ROP, но с влиянием величины пропускной способности видеопамяти (т. н. «эффективный филлрейт»). И тут новая модель HD 7970 показывает отличный результат, отстав лишь от двух топовых видеокарт AMD и Nvidia из предыдущих поколений, имеющих по два GPU на борту.
А что же с эффективностью использования блоков ROP, которой хвалились AMD? Действительно, лишь 32 блока ROP в новом чипе Tahiti совсем не ограничивают скорость рендеринга даже в специализированном тесте. И мы отмечаем несколько бо́льшую эффективность блоков ROP и более высокую скорость заполнения у новой видеокарты компании AMD по сравнению со старыми моделями. Разница между HD 7970 и HD 6970 более чем 50%, что явно говорит о большем влиянии уже ПСП, а не чистой производительности блоков ROP.
Что касается сравнения с Nvidia, то и тут разница по скорости (35%) соответствует теоретической разнице в ПСП (36%), а не чистой скорости блоков ROP. Получается, что 32 таких блока в Cayman просто были лишними и их возможности никогда не использовались полностью.
Feature Test 3: Parallax Occlusion MappingОдин из самых интересных feature-тестов, так как подобная техника уже используется в играх. В нём рисуется один четырехугольник (точнее, два треугольника) с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются довольно ресурсоёмкие операции по трассировке лучей и карта глубины большого разрешения. Также эта поверхность затеняется при помощи тяжёлого алгоритма Strauss. Это тест очень сложного и тяжелого для видеочипа пиксельного шейдера, содержащего многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss.
Этот тест отличается от других подобных тем, что результаты в нём зависят не исключительно от скорости математических вычислений, эффективности исполнения ветвлений или скорости текстурных выборок, а от всего понемногу. Для достижения высокой скорости тут важен баланс блоков GPU, также весьма заметно влияет на скорость и эффективность выполнения ветвлений в шейдерах.
Сравнительные результаты видеокарт AMD на диаграмме в целом похожи на то, что мы видели в тесте текстурной производительности из 3DMark Vantage, кроме того, что новый Radeon HD 7970 явно эффективнее и в этой задаче, ведь он снова почти догнал двухчиповую HD 6990 — отличный результат! Платы Nvidia в данном случае получили некоторое увеличение производительности, что подтверждает вывод о том, что не только текстурная производительность влияет на результаты этого теста.
Итак, новая модель компании AMD отлично выступила, совсем немного уступив двухчиповой плате на базе двух Cayman. Одночипового предшественника она обогнала на 66%. Эта цифра не соответствует ускорению от Cayman к Tahiti ни по одному из теоретических параметров и может означать улучшение эффективности исполнения сложных вычислений с ветвлениями. Даже считавшийся ранее неплохим результат Geforce GTX 580 вдвое хуже, чем у новинки AMD. Собственно, все видеокарты этого производителя оказались быстрее топовой модели линейки Geforce GTX 500 на базе одного чипа.
Feature Test 4: GPU ClothТест интересен тем, что рассчитывает физические взаимодействия (имитация ткани) при помощи видеочипа. Используется вершинная симуляция, при помощи комбинированной работы вершинного и геометрического шейдеров, с несколькими проходами. Используется stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров и скорость stream out.
Скорость рендеринга в этом тесте также зависит от многих параметров, но уже других. Основными факторами тут являются производительность обработки геометрии и эффективность выполнения геометрических шейдеров. Так что вполне логично, что именно видеокарты производства Nvidia чувствуют себя в этом приложении отлично, значительно опережая конкурентов.
И даже представленная сегодня Radeon HD 7970, несмотря на явное улучшение производительности, по сравнению с HD 6970, не смогла тут составить конкуренцию одночиповой Geforce GTX 580 и немного уступила ей. Это один из тех геометрических тестов, в которых видно преимущество у недавно видеокарт HD 6900 перед предыдущими линейками, в которых увеличили скорость обработки геометрии и выполнения геометрических шейдеров. Radeon HD 7970 улучшила результат ещё на 35%, но этого оказалось мало — решения Nvidia продолжают лидировать в этом тесте. Хотя отметим, что новая модель всё же значительно улучшила позиции компании AMD в геометрических тестах.
Feature Test 5: GPU ParticlesТест физической симуляции эффектов на базе систем частиц, рассчитываемых при помощи видеочипа. Также используется вершинная симуляция, каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот.
Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующих частицу. Но тест больше всего загружает шейдерные блоки вершинными расчётами, также тестируется stream out.
Результаты очередного теста из пакета 3DMark Vantage похожи на те, что мы видели на предыдущей диаграмме, но скорость обработки геометрии в нём стала ещё важнее. И поэтому видеокарты Nvidia вывались вперёд ещё дальше, оставив позади даже двухчипового монстра — Radeon HD 6990. Увы, но это факт — даже GTX 580 обогнала все платы AMD, в том числе и новёхонькую модель на базе графического процессора Tahiti.
Увы, но хотя плата, основанная на новом чипе, и показала более сильный результат, по сравнению с решениями на базе Cayman и Cypress, но от Geforce отстало. Разница между HD 7970 и HD 6970 в этом сравнении составила чуть больше 30%, что указывает на явное влияние скорости ALU. В синтетических тестах имитации тканей и частиц из тестового пакета 3DMark Vantage, в которых активно используются геометрические шейдеры, решения AMD продолжают отставать от конкурирующих видеокарт соперника, имеющих весьма высокую скорость обработки геометрии.
Feature Test 6: Perlin NoiseПоследний feature-тест пакета Vantage является математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Каждый цветовой канал использует собственную функцию шума для большей нагрузки на видеочип. Perlin noise — это стандартный алгоритм, часто применяемый в процедурном текстурировании, он использует очень много математических расчётов.
Интересно, что в математическом тесте из пакета компании Futuremark, показывающем пиковую производительность видеочипов в предельных задачах, мы увидели совершенно иную картину, по сравнению с аналогичными тестами из нашего тестового пакета. Показанная на диаграмме производительность решений лишь очень примерно соответствует тому, что должно получаться по теории, а также расходится и с тем, что мы видели ранее в математических тестах из пакета RightMark 2.0. Например, явно видно, что новая видеокарта в этом тесте подобралась гораздо ближе к теоретической скорости, по сравнению с картами на GPU с VLIW-архитектурой.
Давайте разберёмся в причинах. В своё время, HD 6970 не усилила пиковую производительность математических вычислений по сравнению с HD 5870, но одним этим отставания Cayman не объяснить. Причиной могла быть как меньшая эффективность архитектуры VLIW4, так и умная система управления питанием, «зарезавшая» тактовую частоту и производительность решений при достижении установленного порога энергопотребления.
Но ведь на HD 7970 она не сказалась. Скорее всего, причина как раз в скалярной архитектуре нового чипа. Потому что соотношение цифр производительности в тесте и теоретических на это явно указывает. По теории, HD 6970 обладает 0,7 математической мощи новой карты, но по этому тесту получилось лишь 0,56. Примерно такая же разница получилась и для других плат AMD. А вот при сравнении GTX 580 и HD 7970, имеющих скалярные архитектуры, теоретическое соотношение равно 0,42 (Tahiti более чем вдвое быстрее), и практическое тоже 0,42. То есть, эффективность использования имеющихся ALU у этих чипов разных производителей абсолютно одинаковая! В отличие от Cayman и Cypress, имеющих VLIW архитектуру.
В любом случае, обеих своих конкурентов от Nvidia новая плата AMD обходит с огромным запасом, и Nvidia явно нужно резко усилить математическую мощь в будущих решениях. А пока что получается привычная картина — видеокарты Geforce показывают низкие результаты в таких случаях, когда простая и интенсивная математика выполняется на платах Radeon значительно быстрее. И выход Southern Island только усугубил ситуацию.
Direct3D 11: Вычислительные шейдеры
Чтобы протестировать новые решения компании AMD в задачах, использующих такие новые возможности DirectX 11, как тесселяция и вычислительные шейдеры, мы воспользовались примерами из пакетов для разработчиков (SDK) и демонстрационными программами компаний Microsoft, Nvidia и AMD.
Сначала рассмотрим тесты, использующие вычислительные (Compute) шейдеры. Их появление — одно из наиболее важных нововведений в последних версиях DX API, они уже используются в современных играх для выполнения различных задач: постобработки, симуляций и т. п. В первом тесте показан пример HDR-рендеринга с tone mapping из DirectX SDK, с постобработкой, использующей пиксельные и вычислительные шейдеры.

Возможно, это и не самый удачный пример для вычислительных шейдеров, но разницу в производительности показывает довольно чётко. Разницы между расчётами в вычислительном и пиксельном шейдерах для видеокарт AMD почти нет, а на Nvidia немного быстрее выполняется пиксельный.
AMD Radeon HD 6970 оказалась быстрее предшественницы HD 5870, и выступила на уровне Geforce GTX 580, но представленная сегодня модель HD 7970 значительно опережает их все и становится лидером (двухчиповые видеокарты в этой синтетике мы решили не использовать). GTX 560 Ti взята в основном для тестов геометрии, ну и для того, чтобы оценить разницу между решениями из разных ценовых сегментов.
Итак, анонсированные плата на новом чипе Tahiti опережает аналог на базе Cayman на 40%, что полностью соответствует разнице в теоретической производительности вычислительных блоков. В свою очередь, преимущество над конкурирующей GTX 580 равно 30-40% (в зависимости от типа шейдерной программы), что явно ниже теоретически возможного. GTX 560 Ti отстаёт очень сильно, более чем вдвое.
Второй тест вычислительных шейдеров также взят из Microsoft DirectX SDK, в нём показана расчётная задача гравитации N тел (N-body) — симуляция динамической системы частиц, на которую воздействуют физические силы, такие как гравитация.
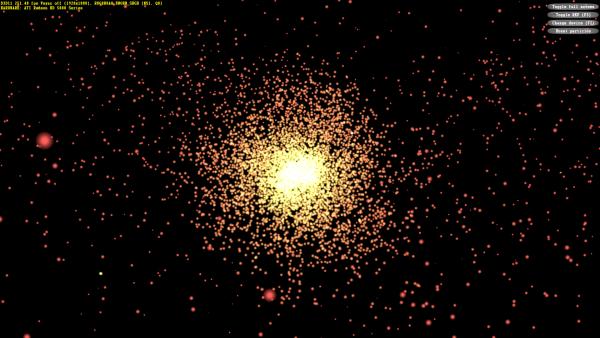
Результаты в этом тесте весьма необычные, для устаревших решений AMD похожие на цифры из математического теста 3DMark Vantage — Cypress оказался быстрее Cayman. Несмотря на большое теоретическое превосходство в пиковых цифрах, быстрейшая видеокарта AMD — представленная сегодня новинка Radeon HD 7970 — лишь на 21% опережает топовое решение Nvidia. И даже GTX 560 Ti не так уж сильно отстаёт. Старые модели семейств HD 6900 и HD 5800 показывают результаты, близкие к показателям Geforce GTX 580.
Больше всего нам интересна разница между результатами решений на Cayman и Tahiti, и в этом случае мы видим преимущество свежей модели, равное 36%. Это чуть меньше теоретической разницы между данными моделями, но всё-таки близко к ней. Почему же обе карты не очень ярко выступили на фоне очень старой HD 5870? Возможно, виновата сниженная PowerTune частота или недостаток оптимизации драйверов под новую архитектуру. Посмотрим, может в тестах тесселяции Tahiti наконец-то покажет значительное ускорение.
Direct3D 11: Производительность тесселяции
Вычислительные шейдеры очень важны, но главным нововведением в Direct3D 11 всё же считается аппаратная тесселяция. Мы очень подробно рассматривали её в своей теоретической статье про Nvidia GF100. Тесселяцию уже довольно давно начали использовать в DX11-играх, таких как STALKER: Зов Припяти, DiRT 2, Aliens vs Predator, Metro 2033, Civilization V, Crysis 2, Battlefield 3 и других. В некоторых из них тесселяция используется для моделей персонажей, в других — для имитации реалистичной водной поверхности или ландшафта.
Существует несколько различных схем разбиения графических примитивов (тесселяции). Например, phong tessellation, PN triangles, Catmull-Clark subdivision. Так, схема разбиения PN Triangles используется в STALKER: Зов Припяти, а в Metro 2033 — Phong tessellation. Эти методы сравнительно быстро и просто внедряются в процесс разработки игр и существующие движки, поэтому и стали популярными.
Первым тестом тесселяции будет пример Detail Tessellation из ATI Radeon SDK. В нём реализована не только тесселяция, но и две разные техники попиксельной обработки: простое наложение карт нормалей и parallax occlusion mapping. Что ж, сравним DX11-решения AMD и Nvidia в различных условиях:

Интересно, что parallax occlusion mapping (средние столбики на диаграмме) на видеокартах от обоих производителей выполняется гораздо менее эффективно, чем тесселяция (нижние столбики), а умеренная тесселяция не даёт большого падения производительности — сравните верхние и нижние столбцы. То есть качественная имитация геометрии при помощи пиксельных расчётов обеспечивает даже меньшую производительность, чем оттесселированная геометрия с displacement mapping.
Что касается производительности видеокарт относительно друг друга, то давайте рассмотрим сначала попиксельные техники. В тесте простого бампмаппинга лидирует новая видеокарта AMD, она опережает и HD 6970 и GTX 580 на 27% и 36% соответственно. А вот в подтесте сложных попиксельных расчётов (вспоминаем тесты parallax mapping выше по тексту) до выхода Cayman видеокарты Geforce были быстрее решений AMD, равно как и при включенной тесселяции. С выходом Radeon HD 6970 в подтесте с тесселяцией оказались заметно быстрее HD 5870, и в тесте с небольшим коэффициентом разбиения треугольников HD 6970 обогнала даже GTX 580.
Гораздо интереснее то, что мы увидели на графике с меткой Radeon HD 7970. Тесселяция тут не слишком сложная, поэтому новая видеокарта выиграла у предшествующей модели не так уж много — около 30%. Другое дело — тест POM. В этом подтесте новая HD 7970 просто разорвала все остальные решения в клочья. Преимущество перед HD 6970 и GTX 580 лишь немного не дотягивает до двукратного. Очередной суперрезультат в тесте parallax mapping, говорящий о высокой эффективности исполнения сложных шейдерных программ.
Вторым тестом производительности тесселяции будет ещё один пример для 3D-разработчиков из ATI Radeon SDK — PN Triangles. Собственно, оба примера входят также и в состав DX SDK, так что мы уверены, что на их основе создают свой код игровые разработчики. Этот пример мы протестировали с различным коэффициентом разбиения (tessellation factor), чтобы понять, как сильно влияет его изменение на общую производительность.

А вот в этом примере мы видим уже полноценное сравнение геометрической мощи решений AMD и Nvidia в разных условиях. И оно получилось весьма интересным, на наш взгляд. Сильно выделяется графическая архитектура Fermi, да и чип новой архитектуры Tahiti от AMD. Конечно, это чисто синтетический тест и экстремальные коэффициенты разбиения вряд ли будут использоваться в играх ближайшего времени, особенно учитывая тотальную мультиплатформенность. Нам интересен архитектурный потенциал, для чего и нужна «синтетика».
Если в лёгких условиях новая Radeon HD 7970 успешно конкурирует с Geforce GTX 580, опережая её в самых лёгких режимах и идёт наравне в третьем, но в самых тяжёлых условиях с очень большим количеством треугольников с видеокартой Nvidia Geforce на чипе GF110 конкурировать просто невозможно — в задачах экстремальной тесселяции она значительно быстрее даже неоднократно улучшенных чипов AMD. Новый GPU хотя и ещё раз сократил отставание от конкурента в задачах обработки геометрии, но до распараллеленной работы 16 блоков тесселяции в GF110 всё ещё очень далеко. И даже GF114 при максимальном коэффициенте разбиения оказался быстрее Tahiti.
Тем не менее, несмотря на проигрыш в наиболее суровых условиях с максимальным коэффициентом разбиения, в остальном HD 7970 на базе Tahiti выступила просто отлично, особенно по сравнению с Cayman и Cypress. Новая модель компании AMD в режимах лёгкой и средней нагрузки показывает впечатляющий прирост в скорости, и разница по сравнению с и так не медленной HD 6970 достигает 2,8 раза. Но такой прирост мы видим только в экстремальном случае, а чаще всего получается от 30 до 70%. Обещанной четырёхкратной разницы мы не увидели, по крайней мере пока.
Но максимальная разница между решениями компаний достигается в условиях экстремальной тесселяции, которых не будет в играх и приближённых к ним бенчмарках. Поэтому мы ожидаем, что Tahiti заметно улучшит позиции компании AMD в существующих тестах с применением тесселяции, вроде 3DMark11 и Heaven.
Давайте рассмотрим ещё один тест — демонстрационную программу Nvidia Realistic Water Terrain, также известную как Island. В этой демке используется тесселяция и карты смещения (displacement mapping) для рендеринга реалистично выглядящей поверхности океана и ландшафта. Смотрится она просто замечательно, вот чего не хватает в нынешних играх:

Island не является чисто синтетическим тестом для измерения геометрической производительности, он содержит и сложные пиксельные и вычислительные шейдеры, и такая нагрузка ближе к реальным играм, в которых используются сразу все блоки GPU, а не только геометрические, как в предыдущем бенчмарке.
Мы также протестировали программу при четырёх разных коэффициентах тесселяции, эта настройка называется Dynamic Tessellation LOD. И если при самом низком коэффициенте разбиения впереди оказываются все видеокарты компании AMD, то при усложнении работы платы на основе чипов от Nvidia начинают вырываться вперёд. И при увеличении коэффициента разбиения и сложности сцены производительность абсолютно всех Radeon падает сильно, в отличие от конкурирующих решений.
Поведение Radeon HD 7970 в тесте любопытное. Сразу видно, что никаких кардинальных изменений в геометрическом конвейере сделано не было (в общем, это и не обещалось, так что никаких претензий). Если в самом лёгком режиме новая карта быстрее HD 6970 на 35%, а GTX 580 — на 64%, то уже при настройке LOD в значение 25 производительность новинки падает до уровня скорости GTX 560 Ti. Дальше — больше. При максимальном коэффициенте LOD разница между скоростью Geforce GTX 580 и Radeon HD 7970 достигла 3,5 раз!
Проверим, получили ли мы обещанную четырёхкратную разницу между HD 7970 и HD 6970. Нет, максимальное отставание графического процессора Cayman составило менее чем два раза. А чаще всего и вовсе лишь полтора. В общем, нам не очень понятно, где искать четырёхкратное ускорение тесселяции, остаётся верить на слово, что где-то оно есть. Пока же констатируем очередную победу видеочипов от Nvidia — уж очень они хороши в геометрических тестах.
Выводы по синтетическим тестам
По результатам проведённых нами синтетических тестов новейшей видеокарты Radeon HD 7970, основанной на графическом процессоре Tahiti из семейства Southern Islands, а также результатам других моделей видеокарт производства обоих производителей дискретных видеочипов, можно сделать вывод о том, что новинка определённо станет лидером среди одночиповых решений, доступных на рынке. Это просто отличное продолжение удачных линеек Radeon HD 5800 и HD 6900, которое должно серьёзно укрепить позиции компании AMD в ближайшие месяцы.
Графический процессор Tahiti выполнен на основе новой архитектуры с применением самого современного техпроцесса 28 нм, и он очень сильно отличается от всех предыдущих чипов компании. Хотя количество некоторых исполнительных блоков в нём выросло не так значительно (вычислительные блоки ALU и блоки ROP), но новый GPU отличается важными архитектурными изменениями, направленными на увеличение эффективности вычислений на GPU, а также на улучшение позиций в производительности обработки геометрических данных. Многие из наших синтетических тестов показали, что эффективность вычислений в сложных задачах и скорость тесселяции и выполнения геометрических шейдеров серьёзно выросли, хотя и не всегда настолько, насколько нами ожидалось.
С видеочипами AMD случилось то, что обязано было случиться. То самое, что Nvidia уже прошла чуть раньше. При переносе акцента с графических вычислений на вычисления общего назначения, и соответствующем переходе от VLIW к скалярным архитектурам, а также добавлении других важных для GPGPU функций, вроде продвинутого кэширования и добавления планировщиков в каждый вычислительный блок, рост сложности чипа обязательно превысит рост пиковых показателей производительности. То есть, чисто фактически получается, что предыдущие решения могут быть эффективнее — хотя они менее производительны, но достигается это меньшими силами (в виде сложности чипа).
Поясним это на примере. Преимущество Radeon HD 7970 перед тем же Radeon HD 5870 в некоторых синтетических тестах было далеким от разницы в сложности GPU — ведь Cypress имеет ровно вдвое меньше транзисторов (2,15 против 4,3 млрд), а в тестах очень редко отстаёт настолько же сильно. Получается, что старый чип эффективнее нового? Да, но только для устаревающих чисто графических задач! В случае же неграфических вычислений, да и многих сложных 3D-расчётов, Tahiti оказался даже более чем вдвое мощнее Cypress, и это подтверждается соответствующей синтетикой. За GPGPU будущее, и задачи видеочипов будут усложняться и далее, поэтому иного пути у AMD просто не было.
Зато, благодаря архитектурным изменениям и своим характеристикам, видеокарта новой серии во многих синтетических тестах, которые ранее были «ахиллесовой пятой» решений AMD, стала более чем конкурентоспособной, особенно по сравнению с прямым конкурентом Geforce GTX 580, даже с учётом большей цены. Это отлично видно почти во всех синтетических тестах пакетов RightMark, Vantage, да и примерах из различных SDK.
Но нашлись и потенциально… ну, не то, чтобы слабые, но недостаточно сильные стороны нового GPU. К таким относится не слишком большой рост производительности в некоторых математических тестах, да и по геометрическим возникают вопросы (например, где обещанное четырёхкратное ускорение?). Несмотря на бо́льшую сложность и площадь чипа по сравнению с тем же Cayman, результаты модели HD 7970 иногда ниже ожидаемых, что не всегда можно легко объяснить. Мы предполагаем, что в этом может быть виноват недостаток оптимизации драйверов, ведь для AMD эта архитектура абсолютно новая и требует тщательной и длительной шлифовки. В некоторых тестах могла подвести и система управления питанием PowerTune, которая могла понизить тактовые частоты при достижении максимального энергопотребления в наиболее требовательных синтетических тестах, не позволяя карте показать ожидаемую производительность, исходя из числа исполнительных блоков и их тактовой частоты.
Хотя в целом результаты в синтетике были показаны весьма неплохие, и особенно приятно то, что инженеры AMD подтянули некоторые из своих слабых мест. К сожалению, в текущих играх гораздо сложнее будет добиться столь впечатляющих приростов, по сравнению с продвинутой синтетикой. Сразу по нескольким причинам. Даже просто потому, что производительность в игровых приложениях редко ограничена какой-то одной характеристикой видеокарты, в отличие от синтетики, а при такой радикальной смене графической архитектуры драйверы ещё нужно оптимизировать и оптимизировать. Кроме того, даже современные игры редко используют все возможности топовых видеокарт для ПК. Они часто упираются в скорость текстурных выборок и эффективный филлрейт (пропускную способность видеопамяти), а в таких условиях полностью раскрыться столь сложные чипы не могут. Придётся ждать или мощных ПК-эксклюзивов или следующего поколения игровых консолей.
Предполагаем, что результаты Radeon HD 7970 в синтетических тестах будут подтверждены соответствующими цифрами и в «игровой» части нашего материала. В играх новая HD 7970 должна выступить сильнее всех конкурентов и опередить Geforce GTX 580 хотя бы на 30%, а то и больше. Вероятно, получится как обычно — в некоторых тестах преимущество будет больше, а в других — его почти не будет. В любом случае, HD 7970 обязана стать лучшей среди всех одночиповых моделей AMD и Nvidia, по крайней мере, все предпосылки к этому мы нашли. Так давайте же перейдём к следующей части материала — исследованию скорости в играх.
AMD Radeon HD 7970 — Часть 3: производительность в игровых тестах →
Блок питания для
тестового стенда предоставлен
компанией Tagan |
Корпус ThermalTake 8430 для
тестового стенда предоставлен
компанией 3Logic |
Монитор Dell 3007WFP для
тестовых стендов предоставлен
компанией Nvidia |

| 22 декабря 2011 г. |
|
|