Семейства видеокарт AMD(ATI) RADEON
Справочная информация
Справочная информация о семействе видеокарт Radeon X
Справочная информация о семействе видеокарт Radeon X1000
Справочная информация о семействе видеокарт Radeon HD 2000
Справочная информация о семействе видеокарт Radeon HD 4000
Справочная информация о семействе видеокарт Radeon HD 5000
Справочная информация о семействе видеокарт Radeon HD 6000
Справочная информация о семействе видеокарт Radeon HD 7000
Справочная информация о семействе видеокарт Radeon 200
Справочная информация о семействе видеокарт Radeon 300
Справочная информация о семействе видеокарт Radeon 400
Справочная информация о семействе видеокарт Radeon 500 и Vega
Спецификации чипов семейства R[V]5XX
| кодовое имя | R580+ | R580 | R520 | RV570 | RV560 | RV530 | RV515 |
| базовая статья | здесь | здесь | здесь | здесь | здесь | здесь | |
| технология (нм) | 90 | 80 | 90 | ||||
| транзисторов (М) | 384 | 321 | 330 | 330 | 157 | 105 | |
| пиксельных процессоров | 48 | 16 | 36 | 24 | 12 | 4 | |
| текстурных блоков | 16 | 12 | 8 | 4 | |||
| блоков блендинга | 16 | 12 | 8 | 4 | |||
| вершинных процессоров | 8 | 5 | 2 | ||||
| шина памяти | 256 | 128 | |||||
| типы памяти | DDR, DDR2, GDDR3, GDDR4 |
DDR, DDR2, GDDR3 | |||||
| системная шина чипа | PCI-Express 16х | ||||||
| RAMDAC | 2 х 400МГц | ||||||
| интерфейсы | TV-Out TV-In (нужен чип захвата) 2 x DVI Dual Link |
||||||
| вершинные шейдеры | 3.0 | ||||||
| пиксельные шейдеры | 3.0 | ||||||
| точность пиксельных вычислений | FP32 | ||||||
| точность вершинных вычислений | FP32 | ||||||
| форматы компонент текстур | FP32, FP16 (без фильтрации) I8 DXTC*, S3TC 3Dc |
||||||
| форматы рендеринга |
FP32 и FP16 (последний - c блендингом и MSAA) I8 I10 (RGBA 10:10:10:2) |
||||||
| MRT | есть | ||||||
| Aнтиалиасинг | 2х, 4x и 6х MSAA псевдослучайное расположение отсчетов на решетке 12х12 |
||||||
| генерация Z | 1х в режиме без цвета, 2х в режиме MSAA | ||||||
| буфер шаблонов | двусторонний | ||||||
| технологии теней | специальные технологии отсутствуют | ||||||
Спецификации референсных карт на базе чипов семейств R[V]5XX
| карта | чип шина |
блоков PS/TMU/VS | частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) бит |
тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
| RADEON X1300 (HM) | RV515 PEG16х |
4/4/2 | 450 | 500(1000) | 32-128 GDDR3 | 4.0-16.0 (32/64/128) |
1800 | |
| RADEON X1300 | RV515 PEG16х/AGP |
4/4/2 | 450 | 250(500) | 128/256 DDR2 | 4.0-8.0 (64/128) |
1800 | |
| RADEON X1300 PRO | RV515 PEG16х/AGP |
4/4/2 | 600 | 400(800) | 256 DDR2 | 12.8 (128) |
2400 | |
| RADEON X1300 XT | RV530 PEG16х |
12/4/5 | 500 | 390(780) | 128/256 DDR2 | 12.5 (128) |
2000 | |
| RADEON X1600 PRO | RV530 PEG16х/AGP |
12/4/5 | 500 | 390(780) | 128/256 DDR2 | 12.5 (128) |
2000 | |
| RADEON X1600 XT | RV530 PEG16х/AGP |
12/4/5 | 590 | 690(1380) | 128/256 GDDR3 | 22.0 (128) |
2360 | |
| RADEON X1650 PRO | RV530 PEG16х |
12/4/5 | 590 | 690(1380) | 128/256 GDDR3 | 22.0 (128) |
2360 | |
| RADEON X1650 XT | RV560 PEG16х |
24/8/8 | 600 | 700(1400) | 256 GDDR3 | 22.4 (128) |
4800 | |
| RADEON X1800 XL | R520 PEG16х |
16/16/8 | 500 | 500(1000) | 256 GDDR3 | 32.0 (256) |
8000 | |
| RADEON X1800 XT | R520 PEG16х |
16/16/8 | 625 | 750(1500) | 256/512 GDDR3 | 48.0 (256) |
10000 | |
| RADEON X1800 XT CFE | R520 PEG16х |
16/16/8 | 625 | 720(1440) | 512 GDDR3 | 46.0 (256) |
10000 | |
| RADEON X1900 GT | R580 PEG16х |
36/12/8 | 575 | 600(1200) | 256 GDDR3 | 38.4 (256) |
6900 | |
| RADEON X1900 XT | R580 PEG16х |
48/16/8 | 625 | 725(1450) | 512 GDDR3 | 46.4 (256) |
10000 | |
| RADEON X1900 XTX | R580 PEG16х |
48/16/8 | 650 | 775(1550) | 512 GDDR3 | 49.6 (256) |
10400 | |
| RADEON X1900 CFE | R580 PEG16х |
48/16/8 | 625 | 725(1450) | 512 GDDR3 | 46.4 (256) |
10000 | |
| RADEON X1950 PRO | RV570 PEG16х |
36/12/8 | 580 | 700(1400) | 256 GDDR3 | 44.8 (256) |
6960 | |
| RADEON X1950 XTX | R580+ PEG16х |
48/16/8 | 650 | 1000(2000) | 512 GDDR4 | 64.0 (256) |
10400 | |
| RADEON X1950 CFE | R580+ PEG16х |
48/16/8 | 650 | 1000(2000) | 512 GDDR4 | 64.0 (256) |
10400 | |
карта |
чип шина |
блоков PS/TMU/VS |
частота ядра (МГц) | частота памяти (МГц) | объем памяти (Мбайт) | ПСП (Гбайт) бит |
тексель рэйт (Мтекс) | филл рэйт (Мпикс) |
Подробности: R520, серия RADEON X1800
Спецификации R520
- Кодовое имя чипа R520
- Технология 90 нм
- 321 миллион транзисторов
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта GDDR3 памяти
- PCI-Express x16 шинный интерфейс
- 16 пиксельных процессоров
- 16 текстурных блоков
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 8 вершинных процессоров
- Сквозная точность вычислений для вершин и пикселей — FP32
- Полная поддержка SM 3.0 (шейдерной модели версии 3.0), выборка значений текстур из вершинных процессоров не поддерживается!
- Эффективная реализация переходов и динамических ветвлений в пиксельных и вершинных процессорах
- Поддержка FP16 формата: полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и MSAA). Сжатие FP16 текстур, включая 3Dc
- Новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, для более качественного рендеринга без привлечения FP16
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной, два разнонаправленных кольца по 256 бит, (4 канала памяти, программируемый арбитраж)
- Эффективное кэширование и новая более эффективная реализация HyperZ
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса c поддержкой HDCP, а также HDMI через переходник
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.264, — новым алгоритмом компрессии видео, используемым в HD-DVD и Blu-Ray видеодисках
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
Подробности: RV530, серия RADEON X1600
Спецификации RV530
- Кодовое имя чипа RV530
- Технология 90 нм
- 157 миллионов транзисторов
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 128 бит интерфейс памяти (возможна 64 бит конфигурация)
- До 512 мегабайт DDR1/2 или GDDR3 памяти
- PCI-Express x16 шинный интерфейс
- 12 пиксельных процессоров
- 4 текстурных блока
- Вычисление, блендинг и запись до 4 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 5 вершинных процессоров
- Сквозная точность вычислений для вершин и пикселей — FP32
- Полная поддержка SM 3.0 (шейдерной модели версии 3.0), выборка значений текстур из вершинных процессоров не поддерживается!
- Эффективная реализация переходов и динамических ветвлений в пиксельных и вершинных процессорах
- Поддержка FP16 формата: полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур, включая 3Dc
- Новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, для более качественного рендеринга без привлечения FP16
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 256-битной(?) внутренней кольцевой шиной, два разнонаправленных кольца, (4 канала памяти, программируемый арбитраж)
- Эффективное кэширование и новая более эффективная реализация HyperZ
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса c поддержкой HDCP
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.264, — новым алгоритмом компрессии видео, используемым в HD-DVD и Blu-Ray видеодисках
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
Подробности: RV515, серия RADEON X1300
Спецификации RV515
- Кодовое имя чипа RV515
- Технология 90 нм
- 105 миллионов транзисторов
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 128 бит интерфейс памяти (возможны 64 и 32 бит конфигурации)
- До 256 мегабайт DDR1/2 или GDDR3 памяти
- Поддержка технологии HyperMemory
- PCI-Express x16 шинный интерфейс
- 4 пиксельных процессора
- 4 текстурных блока
- Вычисление, блендинг и запись до 4 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 2 вершинных процессора
- Сквозная точность вычислений для вершин и пикселей — FP32
- Полная поддержка SM 3.0 (шейдерной модели версии 3.0), выборка значений текстур из вершинных процессоров не поддерживается!
- Эффективная реализация переходов и динамических ветвлений в пиксельных и вершинных процессорах
- Поддержка FP16 формата: полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур, включая 3Dc
- Новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, для более качественного рендеринга без привлечения FP16
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT (Multiple Render Targets — рендеринг в несколько буферов)
- Контроллер памяти с 4-х канальным кроссбаром 4*32 бита (четыре канала памяти, программируемый арбитраж)
- Эффективное кэширование и новая более эффективная реализация HyperZ
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса c поддержкой HDCP
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.264, — новым алгоритмом компрессии видео, используемым в HD-DVD и Blu-Ray видеодисках
- 2D ускоритель с поддержкой всех функций GDI+
Архитектура R520/RV530/RV515
В этот раз мы не будем приводить собственную схему, а возьмем ее из материалов ATI — так как она в этот раз отличается похвальной детализацией и отображает все необходимые нам моменты.
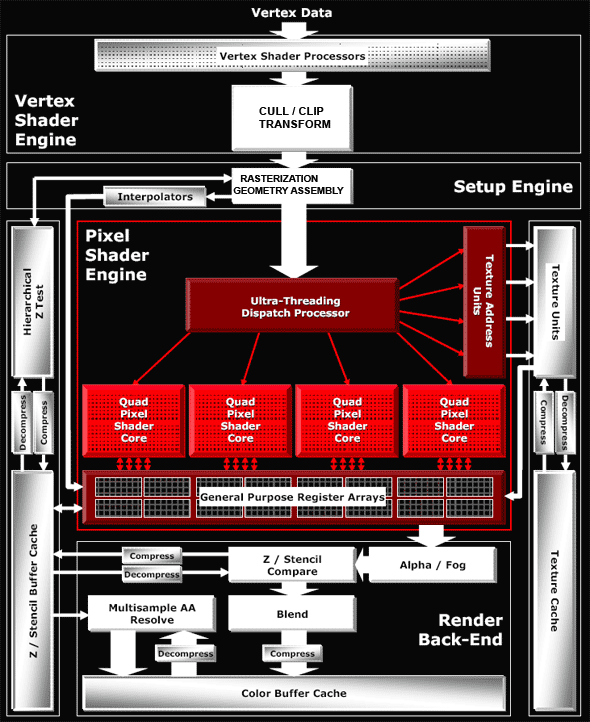
Архитектура вершинных процессоров
В наличии восемь одинаковых вершинных процессоров (на схеме они скрыты в блоке Vertex Shader Processors), соответствующих требованиям SM3 и построенных по стандартной для ATI схеме 3+1 (ALU каждого вершинного процессора может исполнять две разные операции одновременно, над тремя компонентами вектора и четвертой компонентой или скаляром). Фактически, вершинные процессоры стали очень похожими на то, что мы видели в NV4X и G7X, но без возможности выборки значений из текстур. Еще одно исключение — у NVIDIA схема 4+1 (за такт обрабатывается четырехкомпонентный вектор и скаляр), а тут 3+1. Потенциально схема G70 чуть более производительна, но реальная разница может быть практически незаметной, тем более сейчас, когда вершинные процессоры редко становятся узким местом во время рендеринга.
Архитектура пиксельной части
Тут кроется все самое интересное. Посмотрите на схему - в отличие от NVIDIA, текстурные модули вынесены за общий конвейер, и архитектуру чипа можно назвать распределенной. Здесь нет общего длинного конвейера, по которому крутятся колесом квады, как в случае NVIDIA, совершенно отдельно существует текстурная часть — блоки генерации текстурных координат и доступа к текстурам и сами TMU, а отдельно — пиксельные процессоры, выполняющие арифметические и другие операции и наборы регистров с данными. Такая схема имеет свои плюсы и минусы. Основной минус — она хорошо подходит для механизма фаз, когда сначала идет интенсивная выборка текстур, а потом вычисления над ними (шейдеры версий 1.x и старые программы со стадиями), но чревата неоправданными задержками при зависимых выборках текстур, которые достаточно часто встречаются в современных шейдерах 2.x и 3.0. Представьте себе сами — одна команда доступа к текстуре реально вызывает длительную операцию, занимающую много тактов, и все это время вычислительный шейдерный процессор должен ждать? Не тут-то было — ATI достаточно элегантно решает этот вопрос! Причем решение универсально, оно не только эффективно исполняет зависимые выборки, но и повышает КПД работы пиксельной части на шейдерах с условиями и переходами, по сравнению с подходом NVIDIA. ATI называет эту технологию гипертредингом, давайте рассмотрим, как она работает...
Магический ящик под названием Ultra Threading Dispatch Processor дирижирует исполнением — одновременно в обработке находится 512 квадов, каждый из которых может быть на разных стадиях исполнения шейдера. Вместе с каждым квадом хранится его текущее состояние, текущая команда шейдера, значения ранее проверенных условий (информация о текущей ветке условного перехода). В чипах NVIDIA квады идут по кругу, один за другим, и максимум, что возможно — пропуск квадов, не подпадающих под текущую ветку условия. В R520 работа организована по иному — наш магический ящик постоянно проверяет наличие свободных ресурсов (будь то текстурные блоки или пиксельные) и направляет стоящие на очереди квады в освободившиеся устройства. Если квад не прошел проверку на условие и не должен обрабатываться той или иной частью шейдера, то он не будет болтаться по кругу, занимая место и время, вместе с другими квадами, которые нуждаются в обработке. Он просто пропустит те команды, которые ему не нужны и не будет занимать работой текстурный или пиксельный блок. Если квад ждет данных из текстурного блока — он пропустит вперед другие квады, которые загрузят пиксельные вычислительные блоки.
Таким подходом убивается сразу два зайца — скрывается латентность доступа к текстурам и эффективно используются вычислительные и текстурные ресурсы во время исполнения шейдеров с условиями и переходами. Эффективность обоих моментов напрямую зависит от числа квадов, которые может удержать в обработке наш магический ящик. И 512 выглядит вполне солидным набором, за такт мы можем получить текстуры для 4 квадов и обработать в пиксельных процессорах 4 квада, таким образом, до 8 квадов находятся в обработке каждый такт, а остальные ждут своей очереди или данных из текстурных блоков.
Несомненно, этот блок очень сложен и логика согласования и дирижирования набором квадов составляет значительную часть чипа, возможно, сравнимую с текстурными и пиксельными процессорами. Тем более, что наборы регистров с данными фактически относятся и к этому блоку — их должно быть очень много, чтобы эффективно хранить все промежуточные вычисления для 512 квадов, ожидающих своей очереди.
Теперь рассмотрим подробнее изменения в пиксельных процессорах и ALU. Как мы уже видели, пиксельные процессоры сгруппированы по 4 — то есть фактически мы имеем не 16 отдельных процессоров, а 4 процессора квадов, обрабатывающих за один такт 4 пикселя. Каждый такой процессор квадов состоит из следующего набора блоков:
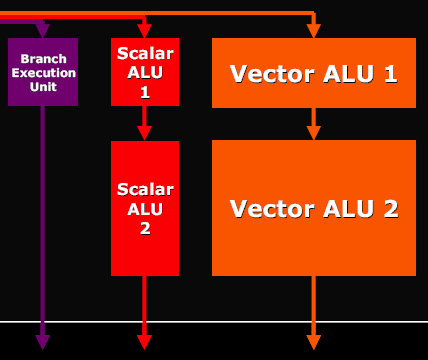
и может выполнить за такт над четырьмя пикселями следующий набор операций:
- VEC3 ADD + модификация и перестановка компонентов (Vector ALU 1)
- Scalar ADD + модификация компонентов (Scalar ALU 1)
- VEC3 ADD/MUL/MAD и другие операции (Vector ALU 2)
- Scalar ADD/MUL/MAD и другие операции (Scalar ALU 2)
- Операцию условного или безусловного перехода (Branch)
Кроме того, не забываем, что кроме этих пяти операций, параллельно может происходить операция адресации текстуры, то есть запроса данных из TMU. Таким образом, в случае оптимального кода шейдера мы получаем пиковую производительность в шесть операций за такт, что сравнимо с G70, если учесть разницу в архитектурных подходах к исполнению ветвлений. Но схема, примененная ATI, как мы уже отмечали, эффективнее справляется с переходами.
Интересно, что ATI верна своему подходу — 3+1 (могут быть исполнены две разные операции, одна над тремя компонентами вектора, вторая над скаляром, который является четвертой). В большинстве случаев подход NVIDIA (2+2 или 3+1 по выбору) можно считать более эффективным, однако на типичных графических задачах эта разница будет сказываться очень слабо.
Еще один важный момент новой архитектуры — кэширование сжатых данных — как данные глубины и буфера кадра, так и текстурные данные хранятся в кэшах чипа в сжатом виде и распаковываются и запаковываются на лету, по мере доступа к ним из соответствующих блоков. Таким образом, эффективность кэширования возрастает, можно считать, что объем кэшей виртуально увеличился в несколько раз.
Логично предположить, что такая архитектура с разделенными текстурными и пиксельными блоками может очень хорошо масштабироваться:
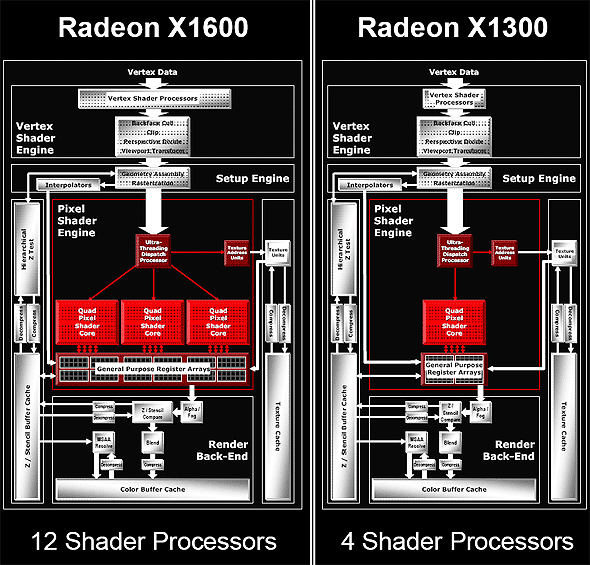
Как мы видим, RV530 и RV515 построены по той же самой схеме. В RV515 остался только один квад — это упрощает многие аспекты, в том числе и для магического ящика дирижера. В RV530 ситуация сложнее — там три пиксельных процессора квада, но только один текстурный блок. То есть, мы имеем 12 пиксельных процессоров и 4 TMU, пусть и используемых оптимальным путем, практически без простоев. Разумеется, в случае простых шейдеров без сложных вычислений, пиксельные процессоры будут простаивать, ожидая текстурные данные, но современные шейдеры, на которые и нацелен этот чип, зачастую производят заметный объем вычислений (5-8 команд) на один доступ к текстуре, в таких случаях схема будет вполне оправдана. Судя по всему, число транзисторов, потраченное на текстурную часть чипа, больше, чем в случае пиксельных ALU, и потому такой дисбаланс оказался оправданным с точки зрения разработчиков из ATI.
Фактически, отказ от 6-8 текстурных блоков и позволил сделать 12 (а не 8 или 4) пиксельных процессора при сохранении той же сложности чипа. Насколько это оправдано на практике — зависит от эффективности текстурных блоков ATI, от эффективности работы диспетчера-дирижера и от соотношения различных команд в исполняемых шейдерах.
Об интерфейсах вывода
Все новые ускорители поддерживают HDCP формат на оба DVI интерфейса, а старшие модели на базе R520 способны выводить на DVI разъемы и HDMI (High Definition Media Interface, интерфейс для вывода изображения и звука на цифровые кинотеатры и другие аудио-видео воспроизводящие устройства нового поколения, подробнее о распространенных интерфейсах можно прочитать в нашем предварительном материале о R520).
Выводы по архитектуре R520/RV530/RV515
- Интересная новая архитектура, с большими возможностями масштабирования и высокой эффективностью использования пиксельных и текстурных ресурсов чипа
- Наконец-то есть поддержка шейдеров 3.0, и более того, полноценная работа с FP16 буфером кадра в любых режимах включая MSAA и сжатие текстур
- Реализация переходов и исполнение сложных шейдеров 3.0 происходит эффективнее, чем в последних чипах NVIDIA. А на обычных шейдерах 2.0 и ранее, производительность как минимум сравнимая, с перевесом в сторону ATI в расчете на один конвейер
- К сожалению, выход линейки был несколько задержан, что сказалось на конкуренции и популярности карт R[V]5XX. Выход некоторых карт после анонса задержался дополнительно на пару месяцев
- Решение сделать 4 текстурных блока у 12 конвейерного RV530 весьма спорно, практические тесты показывают, что такая конфигурация не была оправдана на момент выхода карт на рынок
- К сожалению, отсутствует выборка текстур из вершинных процессоров (такая возможность есть у NV4X и G70), а также не поддерживается фильтрация для FP16 текстур
Подробности: R580, серия RADEON X1900
Спецификации R580
- Кодовое имя чипа R580
- Технология 90 нм
- 384 миллиона транзисторов
- FС корпус (flip-chip, перевернутый чип без металлической крышки)
- 256 бит интерфейс памяти
- До 1 гигабайта GDDR3 памяти
- PCI-Express x16 шинный интерфейс
- 48 пиксельных процессоров
- 16 текстурных блоков
- Технология выборки четырех соседних значений из текстуры вместо одного за такт, в случае отсутствия фильтрации (ускоряет фильтрацию, запрограммированную в шейдере, например, для FP16)
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- 8 вершинных процессоров
- Сквозная точность вычислений для вершин и пикселей — FP32
- Поддержка SM 3.0 (шейдерной модели версии 3.0), включая динамические ветвления в пиксельных и вершинных процессорах. Все так же отсутствует выборка текстур из вершинных процессоров.
- Эффективная реализация переходов и динамических ветвлений в пиксельных и вершинных процессорах
- Поддержка FP16 формата: полностью поддерживается вывод в буфер кадра в плавающем формате FP16 (включая любые операции блендинга и даже MSAA). Сжатие FP16 текстур, включая 3Dc+. Аппаратная фильтрация при выборке FP16 текстур не поддерживается!
- Новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, для более качественного рендеринга без привлечения FP16
- Новый качественный алгоритм анизотропной фильтрации (пользователю доступен выбор между более быстрой и более качественной реализацией анизотропии), улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT (Multiple Render Targets - рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной, два разнонаправленных кольца по 256 бит, (4 канала памяти, программируемый арбитраж)
- Эффективное кэширование и новая более эффективная реализация HyperZ (по заявлениям ATI - были вдвое увеличены внутричиповые буфера HyperZ по сравнению с R520)
- 2 x RAMDAC 400 МГц
- 2 x DVI интерфейса c поддержкой HDCP, а также HDMI через переходник
- TV-Out и TV-In интерфейс, HDTV-Out
- Аппаратный видеопроцессор (для задач компрессии, декомпрессии и постобработки видео), новое поколение, способное ускорять работу с H.264 - новым алгоритмом компрессии видео, используемым в HD-DVD и Blu-Ray видеодисках
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
R580 является как бы работой над ошибками по отношению к R520. Это более производительная версия чипа с увеличенным числом пиксельных процессоров (число текстурных осталось прежним). Очевидно, что основным и единственным существенным отличием от предыдущего флагмана ATI является втрое увеличенное число пиксельных процессоров. Причем, без увеличения числа текстурных блоков - то есть ситуация очень напоминает RV530, в котором соотношение 3:1 уже было сделано, пусть и с меньшим числом конвейеров. В нашей обзорной статье рассмотрено, насколько успешно такое архитектурное решение показывает себя по сравнению с конкурентом, там также проведены исследования производительности, вызванные этими 32 дополнительными пиксельными процессорами в R580. Весьма рекомендуется прочитать выше про архитектуру R520, так как она схожа с R580 и рассмотрена там подробнее.
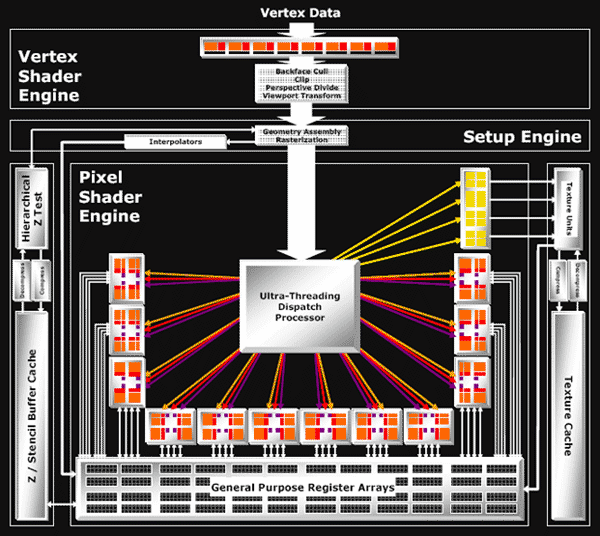
На диаграмме видно, что прибавилось большое число пиксельных вычислительных процессоров, но число текстурных процессоров (блоков) осталось прежним - 4 квада (то есть 16 текстур, выбираемых за такт). Налицо дисбаланс, который рассматривался в практических частях статей на примере RV530. Специалисты ATI считают, что это разумный компромисс, в современных играх соотношение вычислительных и текстурных операций уже может достигать более чем 7 к 1. Насколько такая архитектура оправдана - вопрос непростой, и он проверяется в наших материалах тестами, как синтетическими, так и игровыми. Там проведено уникальное сравнение R520 и R580 на равной частоте - отличие которых, фактически, только в числе пиксельных процессоров. Это сравнение показывает, где дополнительная вычислительная мощь дает преимущество, а где расходуется впустую. Разумеется, только программисты будущих приложений решат, сделать им крен в сторону вычислений или нет, но очевидно, что рано или поздно это произойдет.
Подробности: R580+, серия RADEON X1950
Спецификации R580+
- Кодовое имя чипа R580+
- Технологический процесс 90 нм
- 384 миллиона транзисторов
- Корпус flip-chip (перевернутый чип без металлической крышки)
- 256-битный интерфейс памяти
- Поддержка до 1 гигабайта DDR2, GDDR3 или GDDR4 памяти
- Шинный интерфейс PCI-Express x16
- 48 пиксельных процессоров
- 16 текстурных блоков
- 8 вершинных процессоров
- Вычисление, блендинг и запись до 16 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Точность вычислений для вершин и пикселей — FP32
- Поддержка SM 3.0 (шейдерной модели версии 3.0), включая динамические ветвления в пиксельных и вершинных процессорах. Единственное ограничение - отсутствие выборки текстур из вершинных процессоров
- Эффективная реализация переходов и динамических ветвлений в пиксельных процессорах
- Поддерживается рендеринг в буфер кадра формата FP16, включая операции блендинга и мультисэмплинг, а также введен новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, пригодный для более качественного рендеринга без использования FP16
- Поддержка текстур в формате FP16, в том числе текстурного сжатия для FP16 текстур, включая технологию 3Dc+. Аппаратная фильтрация при выборке FP16 текстур не поддерживается
- Технология выборки четырех соседних значений из текстуры вместо одного за такт, в случае отсутствия фильтрации (ускоряет фильтрацию, запрограммированную в пиксельном шейдере, например, для формата FP16)
- Качественный алгоритм анизотропной фильтрации, пользователю доступен выбор между более быстрой и более качественной реализацией, улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT рендеринг (Multiple Render Targets - рендеринг в несколько буферов)
- Контроллер памяти с 512-битной внутренней кольцевой шиной, два разнонаправленных кольца по 256 бит, 4 канала памяти, программируемый арбитраж
- Эффективное кэширование и более эффективная реализация HyperZ (по заявлению ATI, в очередной раз были увеличены внутричиповые буферы HyperZ, по сравнению с R580)
- Два RAMDAC 400 МГц
- Два DVI Dual Link интерфейса с поддержкой HDCP и HDMI
- TV-Out и TV-In интерфейс, HDTV-Out
- Последнее поколение аппаратного видеопроцессора, выполняющего задачи компрессии, декомпрессии и постобработки видеоданных, с поддержкой аппаратного ускорения декодирования H.264 - наиболее прогрессивного видеоформата
- 2D ускоритель с поддержкой всех функций GDI+
- Поддержка технологии ATI CrossFire
Спецификации референсной карты RADEON X1950 XTX
- Частота ядра 650 МГц
- Эффективная частота памяти 2.0 ГГц (2*1000 МГц)
- Тип памяти GDDR4, 0.91 нс (штатная частота до 2*1100 МГц)
- Объем памяти 512 мегабайт
- Пропускная способность памяти 64.0 гигабайта в секунду
- Теоретическая скорость закраски 10.4 гигапикселя в секунду
- Теоретическая скорость выборки текстур 10.4 гигатекселя в секунду
- Два DVI-I разъема (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
- Потребляет более 100 Вт энергии, примерно столько же, что и RADEON X1900 XTX
Спецификации референсной карты RADEON X1950 CrossFire Edition
- Частота ядра 650 МГц
- Эффективная частота памяти 2.0 ГГц (2*1000 МГц)
- Тип памяти GDDR4, 0.91 нс (штатная частота до 2*1100 МГц)
- Объем памяти 512 мегабайт
- Пропускная способность памяти 64.0 гигабайта в секунду
- Теоретическая скорость закраски 10.4 гигапикселя в секунду
- Теоретическая скорость выборки текстур 10.4 гигатекселя в секунду
- Один DVI-I разъем (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- Шина PCI-Express 16х
- Разъем CrossFire
- Потребляет более 100 Вт энергии, примерно столько же, что и RADEON X1900 XTX
Перед нами небольшая модификация чипа R580, в этот раз изменений в чипе очень мало, существенных нововведений нет вообще. Основное и единственное значительное отличие состоит в модификации контроллера памяти, исправлении неких ошибок по работе с новым типом памяти GDDR4. Теперь, обновленный контроллер памяти в R580+ поддерживает сразу три типа памяти: DDR2, GDDR3 и GDDR4. Также, по словам ATI, в R580+ были сделаны и другие мелкие изменения: увеличен размер некоторых кэшей, HyperZ теперь работает в разрешениях вплоть до 2560х1600. Все остальное осталось прежним: количество транзисторов, число пиксельных, текстурных и вершинных процессоров, используемый техпроцесс. Некоторое время назад многими источниками предполагалось, что в производстве R580+ будет использоваться 80 нм техпроцесс, что позволит снизить себестоимость чипа, уменьшить его энергопотребление и, возможно, увеличить частоту чипа в новых продуктах. Но ожиданиям не суждено было сбыться, вероятно, на техпроцесс 80 нм перейдут уже чипы нового поколения (R600) и чипы из других ценовых секторов, выходящих между R580+ и следующим поколением.
Так как R580+ является почти полной копией чипа R580, который, в свою очередь, был модифицированным R520, мы настоятельно рекомендуем прочитать соответствующие обзоры: RADEON X1800 (R520) и RADEON X1900 (R580). Отличий у CrossFire версии платы по сравнению с обычной в этот раз больше, теперь частота чипа и памяти у этих версий равная, а единственное отличие заключается в том, что вместо двух DVI разъемов и TV-out на ней установлен один DVI и специальный CrossFire разъем. Интересно и то, что рекомендуемые цены на эти две модели также не отличаются, обе предполагается продавать за $449.
Как мы видим, спецификации R580+ и RADEON X1950 XTX почти полностью повторяют данные R580 и RADEON X1900 XTX, соответственно. Единственным отличием от предыдущей топовой модели ATI является использование GDDR4 памяти. Тактовая частота чипа осталась прежней, для RADEON X1950 XTX сохранили частоту RADEON X1900 XTX - 650 МГц, а вот частота локальной видеопамяти изменилась, теперь она равна 1000(2000) МГц, что еще недавно казалось недостижимым значением. Понятно, что столь высокая рабочая частота стала возможной именно благодаря применению нового типа памяти. Референсная видеокарта RADEON X1950 XTX использует микросхемы памяти GDDR4 со временем доступа 0.9 нс, что соответствует частоте работы 1100(2200) МГц, это даже чуть выше рабочей частоты в рассматриваемой модели.
GDDR4 (Graphics Double Data Rate, версия 4) - это новое поколение «графической» памяти, специально разработанной для применения в 3D видеокартах, работающее почти в два раза быстрее, чем GDDR3. Основными отличиями GDDR4 от GDDR3, существенными для пользователей, являются повышенные рабочие частоты (а значит, и пропускная способность) и сниженное энергопотребление. Технически, память GDDR4 не сильно отличается от GDDR3, это ее дальнейшее развитие, что значительно упрощает адаптацию существующих чипов и разработку будущих продуктов с поддержкой нового типа памяти. Первыми видеокартами с чипами GDDR4 на борту стали RADEON X1950 XTX, а у компании NVIDIA продукты на базе этого типа памяти планируются несколько позднее. Скорее всего, это будут видеокарты уже на базе NVIDIA G80.
Новый тип памяти разрабатывался компаниями Samsung и Hynix в сотрудничестве с ATI, которая руководила разработкой в рамках JEDEC. Сегодня чипы GDDR4 уже выпускаются указанными двумя компаниями, но только Samsung начала ее промышленное производство. Память не так давно стала поставляться в больших объемах производителям видеокарт, в массовое производство с июня этого года запущены модули со скоростями до 1.2(2.4) ГГц, также компания заявляла об успешной разработке чипов с рабочими частотами вплоть до (1.6)3.2 ГГц, что в два раза больше, чем у самых скоростных чипов GDDR3. В данный момент, компания Samsung выпускает три типа чипов памяти GDDR4: со временем доступа 0.71, 0.83 и 0.91 нс, с рабочими частотами от 1100(2200) до 1400(2800) МГц. Остается надеяться, что имеющие место проблемы с доступностью новой памяти GDDR4, которая выпускается пока в ограниченных объемах, со временем исчезнут.
Преимущества новых модулей памяти перед GDDR3 не только в скорости - энергопотребление модулей, по разным оценкам, примерно на 30-40% ниже, чем у GDDR3. Более низкое энергопотребление GDDR4 позволяет снизить требования к питанию и охлаждению или увеличить энергопотребление видеочипа, оставив неизменным потребление видеокарты в целом. Снижение потребления может быть достигнуто за счет более низкого номинального напряжения VDD для GDDR4 - 1.5 В, что позволяет говорить об экономии энергии по сравнению с GDDR3. Однако в ранних чипах, устанавливаемых на карты RADEON X1950, используется напряжение 1.8 В, то есть то же самое, что и для GDDR3. А для самых мощных решений может использоваться напряжение 1.9 В. Именно из-за этого X1950 XTX сейчас потребляет не меньше, чем X1900 XTX, несмотря на то, что потенциально GDDR4 менее требовательна к питанию, чем предыдущая версия «графической» памяти.
Повышение рабочей частоты памяти выразилось в улучшении показателя ее пропускной способности, для RADEON X1950 XTX ПСП равна 64 Гб/с, что больше, чем у любой другой одночиповой видеокарты, вышедшей ранее. Для сравнения, у NVIDIA GeForce 7800 GTX значение ПСП равно 51.2 Гб/с, у GeForce 7800 GTX 512Mb - 54.4 Гб/с, причем, на последней устанавливалась самая быстрая GDDR3 память. GDDR4 память, установленная на видеокарте RADEON X1950 XTX, имеет почти 30% преимущество по пропускной способности перед прошлым топом компании ATI, это позволяет новому решению иметь до 15% преимущества перед X1900 XTX в условиях большой нагрузки на видеопамять, таких, как высокие разрешения с включенным антиалиасингом.
Подробности: RV570, RADEON X1950 PRO
Спецификации RV570
- Кодовое имя чипа RV570
- Технологический процесс 80 нм
- 330 миллионов транзисторов
- 256-битный интерфейс памяти
- Поддержка DDR, DDR2 или GDDR3 памяти
- Шинный интерфейс PCI-Express x16
- 36 пиксельных процессоров
- 12 текстурных блоков
- 8 вершинных процессоров
- Вычисление, блендинг и запись до 12 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Точность вычислений для вершин и пикселей — FP32
- Поддержка SM 3.0 (шейдерной модели версии 3.0), включая динамические ветвления в пиксельных и вершинных процессорах. Единственное ограничение - отсутствие выборки текстур из вершинных процессоров
- Эффективная реализация переходов и динамических ветвлений в пиксельных процессорах
- Поддерживается рендеринг в буфер кадра формата FP16, включая операции блендинга и мультисэмплинг, а также введен новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, пригодный для более качественного рендеринга без использования FP16
- Поддержка текстур в формате FP16, в том числе текстурного сжатия для FP16 текстур, включая технологию 3Dc+. Аппаратная фильтрация при выборке FP16 текстур не поддерживается
- Технология выборки четырех соседних значений из текстуры вместо одного за такт, в случае отсутствия фильтрации (ускоряет фильтрацию, запрограммированную в пиксельном шейдере, например, для формата FP16)
- Качественный алгоритм анизотропной фильтрации, пользователю доступен выбор между более быстрой и более качественной реализацией, улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT рендеринг (Multiple Render Targets - рендеринг в несколько буферов)
- Эффективное кэширование и более эффективная реализация HyperZ
- Два RAMDAC 400 МГц
- Два DVI Dual Link интерфейса с поддержкой HDCP и HDMI
- TV-Out и TV-In интерфейс, HDTV-Out
- Последнее поколение аппаратного видеопроцессора, выполняющего задачи компрессии, декомпрессии и постобработки видеоданных, с поддержкой аппаратного ускорения декодирования H.264 - наиболее прогрессивного видеоформата
- 2D ускоритель с поддержкой всех функций GDI+
- Интегрированная поддержка технологии ATI CrossFire
Спецификации референсной карты RADEON X1950 PRO
- Частота ядра 580 МГц
- Эффективная частота памяти 1.4 ГГц (2*700 МГц)
- Тип памяти GDDR3, 1.4 нс (штатная частота 2*700 МГц)
- Объем памяти 256 мегабайт
- Пропускная способность памяти 44.8 гигабайт в секунду
- Теоретическая скорость закраски 7.0 гигапикселя в секунду
- Теоретическая скорость выборки текстур 7.0 гигатекселя в секунду
- Два DVI-I разъема (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
Подробности: RV560, RADEON X1650 XT
- Кодовое имя чипа RV560
- Технологический процесс 80 нм
- 330 миллионов транзисторов
- 128-битный интерфейс памяти
- Поддержка DDR, DDR2 или GDDR3 памяти
- Шинный интерфейс PCI-Express x16
- 24 пиксельных процессоров
- 8 текстурных блоков
- 8 вершинных процессоров
- Вычисление, блендинг и запись до 8 полных (цвет, глубина, буфер шаблонов) пикселей за такт
- Точность вычислений для вершин и пикселей — FP32
- Поддержка SM 3.0 (шейдерной модели версии 3.0), включая динамические ветвления в пиксельных и вершинных процессорах. Единственное ограничение - отсутствие выборки текстур из вершинных процессоров
- Эффективная реализация переходов и динамических ветвлений в пиксельных процессорах
- Поддерживается рендеринг в буфер кадра формата FP16, включая операции блендинга и мультисэмплинг, а также введен новый целочисленный тип данных RGBA (10:10:10:2) для буфера кадра, пригодный для более качественного рендеринга без использования FP16
- Поддержка текстур в формате FP16, в том числе текстурного сжатия для FP16 текстур, включая технологию 3Dc+. Аппаратная фильтрация при выборке FP16 текстур не поддерживается
- Технология выборки четырех соседних значений из текстуры вместо одного за такт, в случае отсутствия фильтрации (ускоряет фильтрацию, запрограммированную в пиксельном шейдере, например, для формата FP16)
- Качественный алгоритм анизотропной фильтрации, пользователю доступен выбор между более быстрой и более качественной реализацией, улучшенная трилинейная фильтрация
- Поддержка «двустороннего» буфера шаблонов
- MRT рендеринг (Multiple Render Targets - рендеринг в несколько буферов)
- Эффективное кэширование и более эффективная реализация HyperZ
- Два RAMDAC 400 МГц
- Два DVI Dual Link интерфейса с поддержкой HDCP и HDMI
- TV-Out и TV-In интерфейс, HDTV-Out
- Последнее поколение аппаратного видеопроцессора, выполняющего задачи компрессии, декомпрессии и постобработки видеоданных, с поддержкой аппаратного ускорения декодирования H.264 - наиболее прогрессивного видеоформата
- 2D ускоритель с поддержкой всех функций GDI+
- Интегрированная поддержка технологии ATI CrossFire
Спецификации референсной карты RADEON X1650 XT
- Частота ядра 600 МГц
- Эффективная частота памяти 1.4 ГГц (2*700 МГц)
- Тип памяти GDDR3, 1.4 нс (штатная частота 2*700 МГц)
- Объем памяти 256 мегабайт
- Пропускная способность памяти 22.4 гигабайт в секунду
- Теоретическая скорость закраски 4.8 гигапикселя в секунду
- Теоретическая скорость выборки текстур 4.8 гигатекселя в секунду
- Два DVI-I разъема (Dual Link, поддерживается вывод в разрешениях до 2560х1600)
- Шина PCI-Express 16х
- TV-Out, HDTV-Out, поддержка HDCP
Оба видеочипа - графические процессоры нового поколения, произведенные по нормам 0.08 мкм техпроцесса. Ядро совершенно одинаковое и по размеру и по количеству транзисторов, физически RV560 и RV570 - это один и тот же чип, но в разных упаковках. Для RV560 применена 128-битный корпус для установки на PCB дизайна X1600 (также для этих чипов урезаются возможности - треть пиксельных и текстурных блоков), а для RV570 - большая упаковка под 256-бит с защитной рамкой, для установки на упрощенную PCB серии X1900.
Выход новых чипов среднего уровня у ATI откладывался не один раз. Вероятно, это было связано с применением нового техпроцесса, ведь в остальном в них ничего нового нет, RV570 почти равен по характеристикам уже имеющемуся RADEON X1900 GT, который основан на урезанном R580. Но теперь на его место пришел RV570 с теми же 36 пиксельными блоками и 12 текстурными, то есть тем же привычным для последних решений ATI соотношением блоков пиксельных шейдеров и текстурных. Но чип стал намного меньше по размеру и его производство обходится дешевле. Частоту чипа оставили той же, а частота памяти выросла с 1200 до 1400 МГц. Дизайн PCB у X1950 PRO схож с тем, что применен в дорогих и сложных картах семейства X1900, но PCB значительно упростили, микросхемы памяти повернули на 90 градусов, заодно сильно упростив и сам блок питания, уменьшилось количество аналоговых элементов в нем. Так как новые чипы обходятся дешевле, а дизайн плат упрощен, в итоге получилось неплохое решение с рекомендуемой ценой $199.
RADEON X1650 XT занял место над бывшим X1600 XT, недавно переименованным в X1650 PRO. То есть, получилось так, что X1650 PRO и X1650 XT основаны не на одном чипе, работающем на разных частотах, как мы привыкли, а это два совершенно разных чипа. X1650 PRO базируется на RV530 с 12 пиксельными, 5 вершинными и 4 текстурными блоками, а новая карта основана на RV560 с 24 пиксельными, 8 вершинными и 8 текстурными блоками. Получилось, что некоторые характеристики выросли почти в два раза, но частоты работы и ширина шины памяти не изменились. Соответственно, вычислительная мощь возросла сильно, а вот пропускная способность памяти может серьезно сдерживать производительность. Хотя для рекомендованной цены в $149 решение получилось очень интересным в любом случае. PCB X1650 XT отличается от привычной нам по картам X1600 и X1650 только разводкой разъемов CrossFire, так как RV560 поддерживает этот режим без необходимости установки мастер-карты, остальное в дизайне платы, кроме ряда тонкостей и нюансов по цепям питания, оставлено без изменений.
Нужно отметить отдельно, что в дизайн обеих плат, и для RV560 и для RV570, были добавлены разъемы для соединения специальными шлейфами в режим CrossFire. Причем, поддержка CrossFire без специальных карт и чипов была интегрирована в сами GPU. Наконец-то у ATI появилась возможность связки двух обычных плат в режиме CrossFire, как было изначально у NVIDIA с их SLI. Дизайны карт предусматривают подключение двух переходников или одного, но очень широкого. Дело в том, что в последнем случае сигнал одновременно может передаваться только в одну сторону, когда как у нового CrossFire появилась возможность передачи одновременно двух сигналов в обе стороны. Кроме того, соединительные переходники будут иметь вид гибких шлейфов, и потому расстояние между видеокартами не имеет значения, когда как для SLI обычно используются жесткие и имеющие определенную длину переходники.
Справочная информация о семействе видеокарт Radeon X
Справочная информация о семействе видеокарт Radeon X1000
Справочная информация о семействе видеокарт Radeon HD 2000
Справочная информация о семействе видеокарт Radeon HD 4000
Справочная информация о семействе видеокарт Radeon HD 5000
Справочная информация о семействе видеокарт Radeon HD 6000
Справочная информация о семействе видеокарт Radeon HD 7000
Справочная информация о семействе видеокарт Radeon 200
Справочная информация о семействе видеокарт Radeon 300
Справочная информация о семействе видеокарт Radeon 400
Справочная информация о семействе видеокарт Radeon 500 и Vega
| 23 ноября 2007 |
|
|