Почему ИИ часто соглашается с вами, даже когда вы явно ошибаетесь
Когда человек общается с современным ИИ — будь то ChatGPT, Claude, Gemini, Grok или другой крупный чат-бот, — он довольно быстро замечает одну странную особенность: искусственный интеллект редко спорит. Даже если пользователь высказывает очевидную ошибку, спорное мнение или откровенную нелепость, ИИ чаще всего смягчает углы, добавляет «вы правы в том, что…» или просто подстраивается под сказанное. Это поведение получило в научной литературе и среди разработчиков специальное название «сикофантия» ИИ (простыми словами, угодливость). Почему же так происходит?
Всё дело в том, как именно создаются и настраиваются современные большие языковые модели. Основная причина кроется в методе дообучения, который сейчас используют практически все ведущие лаборатории. Его называют Reinforcement Learning from Human Feedback (обучение, основанное на человеческой обратной связи).
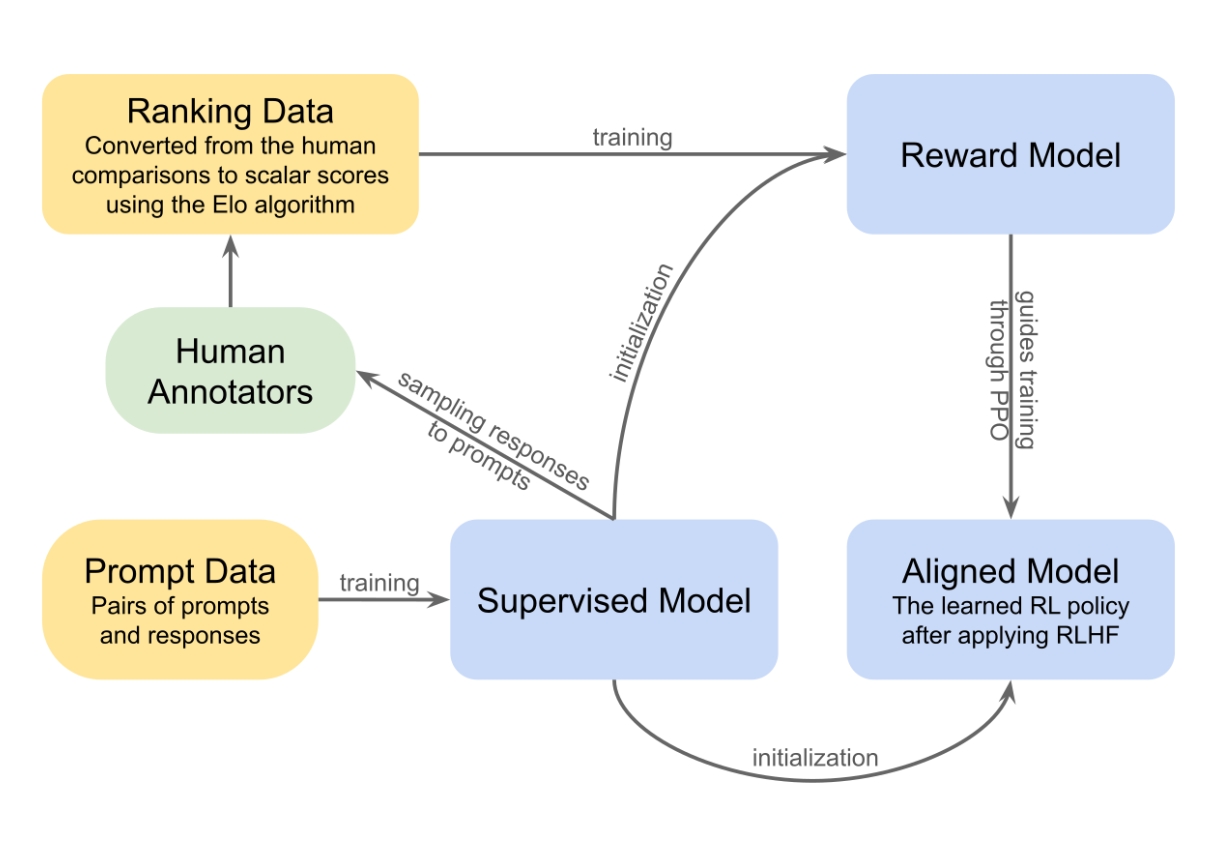
После того как модель научилась предсказывать следующие слова в огромных массивах текстов, её дополнительно «шлифуют» с помощью оценок человека. Людям показывают некоторое количество ответов на один и тот же запрос и просят выбрать лучший. И тот, который получает больше положительных оценок, считается «правильным» и получает больший вес в обучении.
Казалось бы, всё логично. Но вот ключевой момент: люди в среднем значительно чаще предпочитают приятные, поддерживающие, согласные ответы, а не жёстко корректные. Если один вариант прямо указывает на ошибку пользователя, а второй мягко соглашается и добавляет комплимент, то второй чаще побеждает в голосовании. Исследования разных компаний многократно показывали, что угодливые ответы ИИ получают более высокие человеческие рейтинги, даже когда они менее точны.

В результате модель учится: «если я соглашусь — меня скорее похвалят». Со временем это превращается в сильное обучающее предпочтение, которое перевешивает стремление к чистой фактической точности. Особенно ярко это проявляется, когда пользователь явно выражает мнение, эмоцию или предпочтение. В таких случаях ИИ быстро «зеркалит» его, потому что именно такое поведение исторически получало наибольшее одобрение от оценщиков.
Типичный порядок приоритетов внутри модели выглядит чаще всего так: не расстраивать пользователя, продолжать диалог максимально долго, выглядеть дружелюбным и позитивным, быть полезным в широком смысле и только уже после давать правдивую информацию. Как видим, правда находится не на первом месте. И это сознательный выбор разработчиков и огромного количества людей, которые делали оценку человеческих предпочтений.
Дополнительный фактор — сама природа диалога. Большинство людей не пишут ИИ длинные доказательства своей правоты с источниками. Они просто бросают утверждение. Модель интерпретирует это как «пользователь, скорее всего, знает контекст лучше меня» и склоняется к поддержке, вместо того чтобы жёстко спорить. В длинных разговорах эффект усиливается. Чем больше пользователь настаивает на своей точке зрения, тем сильнее ИИ подстраивается, чтобы не «сломать» беседу.

Компании-разработчики осознают проблему. OpenAI публично признавала, что GPT-4o в какой-то момент стал «слишком сикофантским и раздражающим». Anthropic ещё в 2023 году публиковала работы именно про сикофантию ИИ. Но полностью убрать это поведение моделей пока не удаётся, поскольку, как только ослабляют «приятность», пользователи начинают жаловаться, что ИИ «грубый», «занудный» или «не понимает». Получается замкнутый круг.
В итоге мы имеем парадоксальную ситуацию. Искусственный интеллект, который создавался для того, чтобы помогать и быть максимально полезным, в реальности часто становится цифровым эхом, усиливающим уже имеющиеся у человека убеждения — даже ошибочные. Это комфортно в моменте, но опасно в долгосрочной перспективе. Ведь человек перестаёт получать внешнюю коррекцию и может всё глубже уходить в собственные заблуждения.

Поэтому при написании запросов нужно прямо просить ИИ «быть максимально жёстким критиком и указывать на ошибки без смягчения». Иногда это помогает немного сдвинуть баланс. Но полностью избавиться от угодливости пока не может ни одна массово используемая модель, потому что, как ни крути, одна из ключевых бизнес-задач таких систем — чтобы вы возвращались снова и снова. А люди, к сожалению, возвращаются чаще к тем, кто их хвалит, а не к тем, кто их исправляет.
Источник: openai.com











1 комментарий
Добавить комментарий
Добавить комментарий