Nvidia Geforce GTX 580:
описание видеокарты и результаты синтетических тестов
СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарт
- Конфигурация стенда, список тестовых инструментов
- Результаты синтетических тестов
- Результаты игровых тестов (производительность)
Nvidia Geforce GTX 580: Часть 1: Теоретические сведения
В этой части, как обычно, мы изучим саму видеокарту, а также познакомимся с результатами синтетических
тестов.
| Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E | |
|---|---|
|

|
| Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E | |
|---|---|
|
Карта имеет 1536 МБ памяти GDDR5 SDRAM,
размещенной в 12 микросхемах на лицевой сторонe PCB.
Микросхемы памяти Hynix (GDDR5). Микросхемы рассчитаны на максимальную частоту работы в 1250 (5000) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E | Reference card Nvidia Geforce GTX 480 |

|

|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E | Reference card Nvidia Geforce GTX 480 |

|

|
Как мы видим, дизайн при переходе от GTX 480 к GTX 580 мало поменялся, в глаза бросается лишь отсутствие вентиляционного отверстия в PCB у GTX 580, когда как у GTX 480 оно есть. В остальном в дизайн печатной платы внесены минорные изменения и они не принципиальны. Собственно, так оно и логично, ведь чип GF110 — по сути повторяет своего предшественника GF100, а разница лишь в оптимизации разводки и уменьшении энергопотребления, что позволило включить все блоки, получая приемлемое количество годных кристаллов с пластины.
В целом карта получилась стандартных для топовых ускорителей размеров, поэтому поместится в любом корпусе.
Подключение к аналоговым мониторам с d-Sub (VGA) производится через специальные адаптеры-переходники DVI-to-d-Sub. Также с серийными картами поставляются переходники DVI-to-HDMI (данные ускорители поддерживают полноценную передачу видео и звука на HDMI-приемник, поскольку обладают собственным звуковым кодеком), поэтому проблем с такими мониторами также не должно быть. К тому же продукт уже оснащен одним разъемом HDMI. Следует напомнить, что комбинация из двух таких карт в режиме SLI позволяет выводить картинку игры сразу на ТРИ монитора, делая впечатления от игры более яркими, по аналогии с технологией AMD EyeFinity, но уже с поддержкой 3D-Vision (стереокартинки).
Максимальные разрешения и частоты:
- 240 Hz Max Refresh Rate
- 2048×1536×32bit @ 85Hz Max — по аналоговому интерфейсу
- 2560×1600 @ 60Hz Max — по цифровому интерфейсу (для DVI-гнезд с Dual-Link / HDMI)
По поводу HDTV. Одно из исследований также проведено, и с ним можно ознакомиться здесь.
Есть смысл сказать, что карта требуют дополнительного питания, причем двумя разъемами, один из которых 8-пиновый, а второй 6-пиновый. Если насчет последнего — нет проблем, так как уже все современные БП имеют такие «хвосты», то для запитки через 8-пиновый разъем требуется специальный переходник, который должен поставляться с серийными видеокартами.

Чип был получен на 38-й неделе этого года, то есть в сентябре.
О системе охлаждения.
| Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E | |
|---|---|
|
Казалось бы, внешне СО выглядит как у GTX 480, однако не видно тепловых трубок. И действительно, на деле кулер совершенно иной. Прежде всего, принципиально он теперь базируется на испарительной камере, которая заключена в медном узком отсеке, соприкасающемся с GPU. Над этой камерой выстроена конструкция из ребер охлаждения, через которые проходит воздух, гонимый цилиндрическим вентилятором на конце всего устройства. Как показал опыт, данное решение — более эффективно, нежели предыдущее на тепловых трубках. Внутри испарительной камеры особая жидкость, которая моментально передает тепло от нижней пластины к верхней. Но главный момент — это принципиально новое управление кулером, когда как теперь обороты вентилятора меняются плавно в зависимости от нагрева, и потому эффективность охлаждения выросла. Все это вкупе дает то, что кулера практически не слышно, особенно когда работа в простое или при малой нагрузке, в отличие от GTX 480.
|

|

|
|
Мы провели исследование температурного режима с помощью утилиты EVGA Precision (автор А. Николайчук AKA Unwinder) и получили следующие результаты:
Nvidia Geforce GTX 580 1536MB 384-битной GDDR5, PCI-E
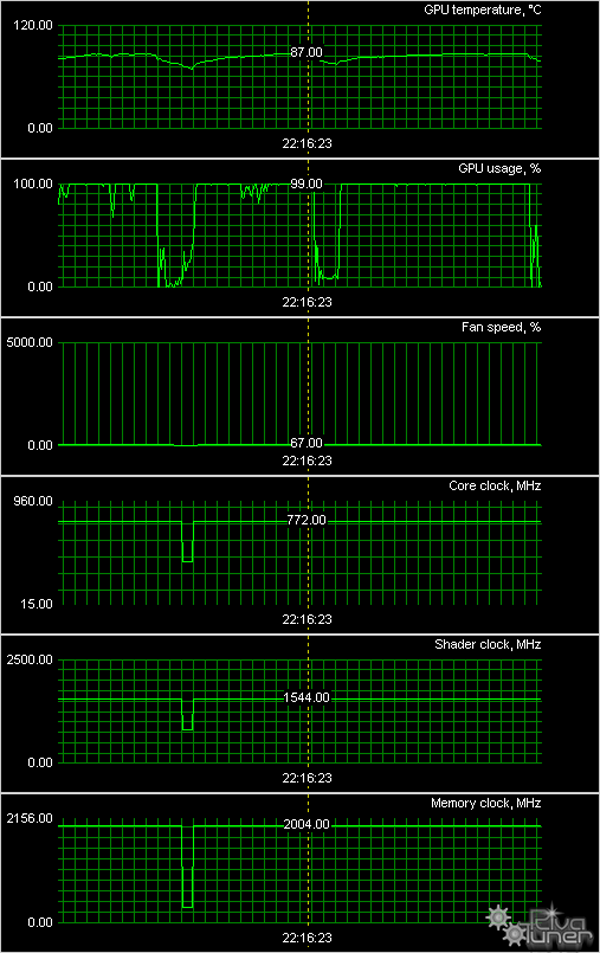
Как мы видим, максимальный нагрев всего лишь 87 градусов (это после восьмичасовой непрерывной работы в 3D). Это говорит и о том, что ядро в целом оптимизировано, ну и об эффективной СО.
Максимальное энергопотребление карты под нагрузкой — 270—280 Вт.
Комплектация. Учитывая, что референс-образцы никогда не имеют комплектаций, мы этот вопрос опустим.
Установка и драйверы
Конфигурация тестового стенда:
- Компьютер на базе Intel Core I7 CPU 975 (Socket 1366)
- процессор Intel Core I7 CPU 975 (3340 МГц);
- системная плата Asus P6T Deluxe на чипсете Intel X58;
- оперативная память 6 ГБ DDR3 SDRAM Corsair 1600MHz;
- жесткий диск WD Caviar SE WD1600JD 160 ГБ SATA;
- блок питания Tagan TG900-BZ 900W.
- операционная система Windows 7 64bit; DirectX 11;
- монитор
Dell 3007WFP (30″); - драйверы ATI версии Catalyst 10.10; Nvidia версии 262.99 / 260.99.
VSync отключен.
Синтетические тесты
Используемые нами пакеты синтетических тестов можно скачать здесь:
- D3D RightMark Beta 4 (1050) с описанием на сайте http://3d.rightmark.org.
- D3D RightMark Pixel Shading 2 и D3D RightMark Pixel Shading 3 — тесты пиксельных шейдеров версий 2.0 и 3.0 ссылка.
- RightMark3D 2.0 с кратким описанием: Vista без SP1, Vista c SP1.
Для работы RightMark3D 2.0 требуется установленный пакет MS Visual Studio 2005 runtime, а также последнее обновление DirectX runtime.
Синтетические тесты проводились на следующих видеокартах:
- Geforce GTX 580 со стандартными параметрами (далее GTX 580)
- Geforce GTX 480 со стандартными параметрами (далее GTX 480)
- Geforce GTX 460 со стандартными параметрами, модель с 768 МБ памяти (далее GTX 460)
- Radeon HD 5970 со стандартными параметрами (далее HD 5970)
- Radeon HD 5870 со стандартными параметрами (далее HD 5870)
Для сравнения результатов новой модели Geforce GTX 580 были выбраны эти видеокарты по следующим причинам: Radeon HD 5870 — это пока что самое мощное одночиповое решение конкурента, HD 5970 — просто мощнейшее решение конкурирующей компании AMD, но уже двухчиповое. Решения Nvidia такие взяты потому, что Geforce GTX 480 — это наиболее производительная одночиповая карта на предыдущем топовом GPU, а среднебюджетная GTX 460 была взята просто для того, чтобы хотя бы косвенно судить о возможных изменениях в архитектуре GF110, по сравнению с GF104.
Direct3D 9: тесты Pixel Filling
В тесте определяется пиковая производительность выборки текстур (texel rate) в режиме FFP для разного числа текстур, накладываемых на один пиксель:
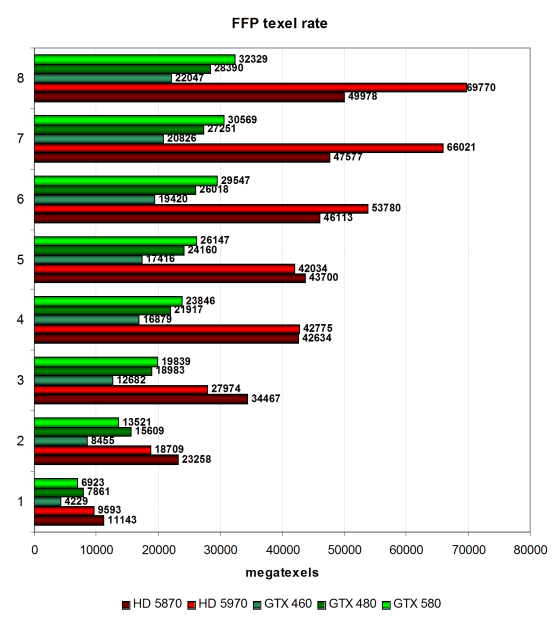
В очередной раз убеждаемся в том, что тест фильтрации RGB8 текстур устарел, и многие видеокарты показывают в нём цифры, далёкие от теоретически возможных значений. Поэтому мы перепроверим эти показатели далее, в тесте из пакета 3DMark Vantage. Результаты же нашей текстурной синтетики в случае GTX 580 сильно не дотягивают до пиковых значений, по ней получается, что новый чип выбирает лишь до 42 текселей за один такт из 32-битных текстур при билинейной фильтрации в этом тесте, что аж в полтора раза ниже теоретической цифры в 64 отфильтрованных текселя.
У нас получилось, что GTX 580 сильно уступил обеим видеокартам AMD и лишь ненамного оторвался от GTX 480. Кстати, интересна разница между GTX 480 и GTX 580 в разных условиях. Если в случаях с большим количеством текстур, где больше сказывается количество TMU и их частота, выигрывает вариант на основе нового GF110, то при уменьшении количества текстур на пиксель, GTX 480 догоняет и даже опережает GTX 580. Вероятно, это как раз результат изменений баланса в новом GPU, когда лёгкие условия принесены в жертву более тяжёлым. Рассмотрим эти же результаты в тесте филлрейта:
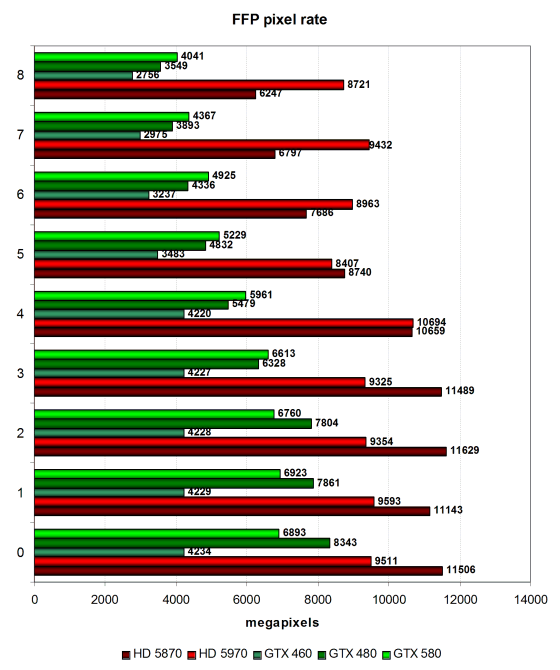
Эти цифры показывают скорость заполнения, и в них мы видим всё то же самое, но с учетом количества записанных в буфер кадра пикселей. Максимальный результат всё так же остаётся за решениями AMD, имеющими большее количество TMU и более эффективными по достижению высокого КПД в данном синтетическом тесте. В случаях с 0—2 накладываемыми текстурами рассматриваемое сегодня решение уступает всем остальным, кроме GTX 460 из совсем другого ценового диапазона. А максимальная разница между GF100 и GF110 не достигает и 15%.
Direct3D 9: тесты Pixel Shaders
Первая группа пиксельных шейдеров, которую мы рассматриваем, очень проста для современных видеочипов, она включает в себя различные версии пиксельных программ сравнительно низкой сложности: 1.1, 1.4 и 2.0, встречающихся в старых играх.
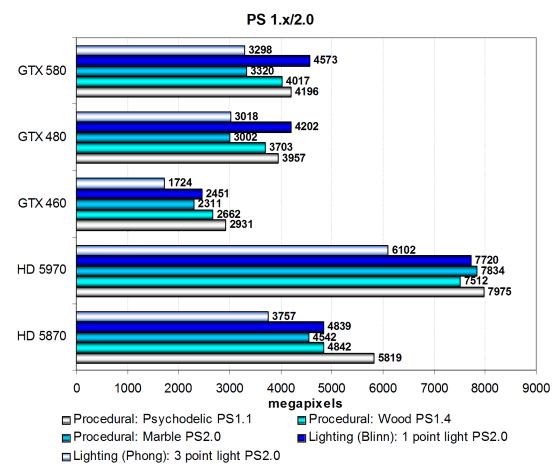
Эти тесты весьма просты для современных GPU и показывают не все возможности современных видеочипов, но они всё же интересны для оценки баланса между текстурными выборками и математическими вычислениями, особенно при внесении каких-либо изменений в архитектуру GPU.
Производительность в этих тестах ограничена по большей части филлрейтом и скоростью текстурных модулей, но с учётом эффективности блоков и кэширования текстурных данных. Проверяем, как сказались изменения в архитектуре GF110, по сравнению с GF100. Да похоже, что никак. В этих тестах нет FP16-текстур, да и оптимизации z-cull не сказались, поэтому разница между GTX 580 и GTX 480 получилась порядка 10%, что похоже на зависимость от эффективного филлрейта (то есть ПСП видеопамяти).
Посмотрим на результаты более сложных пиксельных программ промежуточных версий:
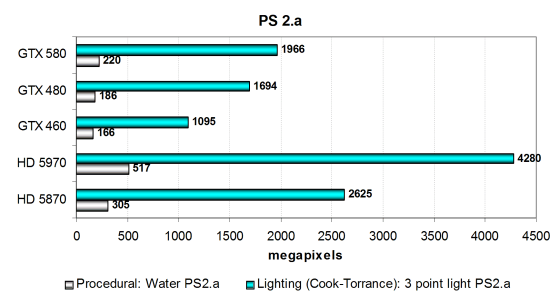
Ну вот, совсем другое дело. Разница между результатами GTX 480 и GTX 580 в этих тестах уже явно объясняется не только частотами. В сильно зависящем от скорости текстурирования тесте процедурной визуализации воды «Water» используется зависимая выборка из текстур больших уровней вложенности, и карты в нём обычно располагаются по скорости текстурирования, с поправкой на разную эффективность использования TMU. И в этом тесте GTX 580 быстрее чем GTX 480 на 18%. Хотя решения AMD на основе чипа(-ов) RV870 всё равно остаются далеко впереди.
Результаты второго теста отличаются менее значительно, в нём разница составила 16%. Этот тест более интенсивен вычислительно, и разница в нём примерно соответствует разнице в количестве ALU и их частоте. Понятно, что из-за этого данный тест лучше подходит для архитектуры AMD, имеющей большее количество математических блоков, и даже одночиповый Radeon HD 5870 легко обгоняет новинку компании Nvidia.
Direct3D 9: тесты пиксельных шейдеров Pixel Shaders 2.0
Эти тесты пиксельных шейдеров DirectX 9 сложнее предыдущих, они близки к тому, что мы сейчас видим в мультиплатформенных играх, и делятся на две категории. Начнем с более простых шейдеров версии 2.0:
- Parallax Mapping — знакомый по большинству современных игр метод наложения текстур, подробно описанный в статье Современная терминология 3D графики.
- Frozen Glass — сложная процедурная текстура замороженного стекла с управляемыми параметрами.
Существует два варианта этих шейдеров: с ориентацией на математические вычисления и с предпочтением выборки значений из текстур. Рассмотрим математически интенсивные варианты, более перспективные с точки зрения будущих приложений:
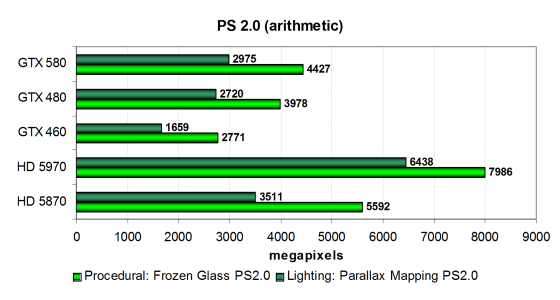
Это универсальные тесты, зависящие и от скорости блоков ALU, и от скорости текстурирования, в них важен общий баланс чипа. Производительность видеокарт в тесте «Frozen Glass» схожа с той, что мы видели выше в «Cook-Torrance», но новая GTX 580 быстрее GTX 480 лишь на 11%, то есть производительность ограничена частотой GPU или филлрейтом, а архитектурные оптимизации в данном случае не сыграли. Ну и понятно, что оба решения компании AMD также оказались быстрее и в этот раз.
Во втором тесте «Parallax Mapping» разница ещё меньше — лишь 9%. Вероятно, скорость в тесте ограничена не столько математической производительностью, а скорее тактовой частотой основной части GPU. Игровые приложения обычно зависят от большего числа параметров, по сравнению с синтетическими, и они не упираются явно в какой-то один параметр. Рассмотрим эти же тесты в модификации с предпочтением выборок из текстур математическим вычислениям:
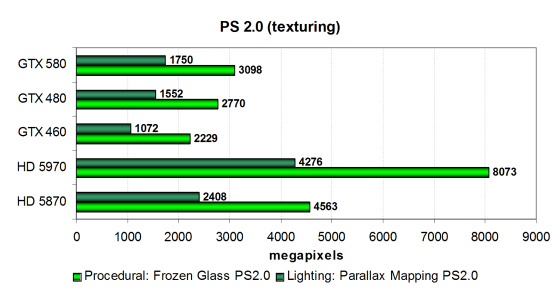
Забавно, но хотя даже новая топовая видеокарта продолжает уступать и HD 5870, и HD 5970 в этих тестах с упором на текстурирование, разница между GTX 580 и GTX 480 немного увеличилась — с 9—11% до 12—13%. Вот тут уже одной частотой не обойтись, похоже, что повлияло и большее количество исполнительных блоков.
Всё это были устаревшие задачи, в основном с упором в текстурирование или филлрейт, а далее мы рассмотрим результаты ещё двух тестов пиксельных шейдеров — но уже версии 3.0, самых сложных из наших тестов пиксельных шейдеров для Direct3D 9 API, которые намного показательнее с точки зрения современных игр на ПК. Тесты отличаются тем, что сильнее нагружают и ALU, и текстурные модули, обе шейдерные программы сложные и длинные, включают большое количество ветвлений:
- Steep Parallax Mapping — значительно более «тяжелая» разновидность техники parallax mapping, также описанная в статье Современная терминология 3D графики.
- Fur — процедурный шейдер, визуализирующий мех.
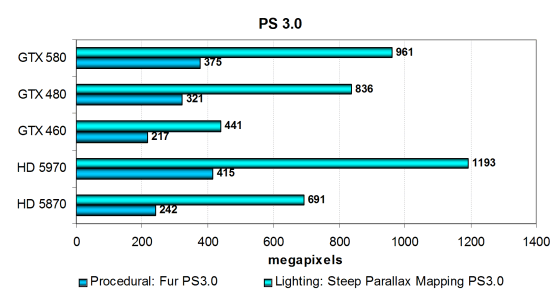
Это первые из DX9-тестов, в которых видеокарты производства Nvidia выглядят сильнее, чем решения AMD. Похоже, что с тестами более сложных пиксельных шейдеров версии 3.0 у решений Nvidia всё далеко не так плохо. Оба PS 3.0 теста довольно сложные, скорость в них почти не зависит от ПСП и текстурирования, они отличаются большим количеством ветвлений, с которыми очень неплохо справляется новая архитектура Nvidia.
И в этих тестах GTX 580 показал результат выше чем GTX 480 на 15—17%, что примерно соответствует теории (но от архитектурных улучшений в этих тестах толку также нет никакого). Результаты GTX 580 значительно выше, чем у HD 5870, и приближаются к производительности двухчипового HD 5970, особенно в тесте Fur, что можно считать отличным результатом.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (текстурирование, циклы)
Во вторую версию RightMark3D вошли два знакомых PS 3.0 теста под Direct3D 9, которые были переписаны под DirectX 10, а также ещё два новых теста. В первую пару добавились возможности включения самозатенения и шейдерного суперсэмплинга, что дополнительно увеличивает нагрузку на видеочипы.
Данные тесты измеряют производительность выполнения пиксельных шейдеров с циклами, при большом количестве текстурных выборок (в самом тяжелом режиме до нескольких сотен выборок на пиксель) и сравнительно небольшой загрузке ALU. Иными словами, в них измеряется скорость текстурных выборок и эффективность ветвлений в пиксельном шейдере.
Первым тестом пиксельных шейдеров будет Fur. При самых низких настройках в нём используется от 15 до 30 текстурных выборок из карты высот и две выборки из основной текстуры. Режим Effect detail — «High» увеличивает количество выборок до 40—80, включение «шейдерного» суперсэмплинга — до 60—120 выборок, а режим «High» совместно с SSAA отличается максимальной «тяжестью» — от 160 до 320 выборок из карты высот.
Проверим сначала режимы без включенного суперсэмплинга, они относительно просты, и соотношение результатов в режимах «Low» и «High» должно быть примерно одинаковым.
Производительность в этом тесте зависит и от количества и эффективности блоков TMU, и от филлрейта с ПСП, хоть и в меньшей степени. Результаты в «High» получаются примерно в полтора раза ниже, чем в «Low», как и должно быть по теории. В Direct3D 10 тестах процедурной визуализации меха с большим количеством текстурных выборок решения Nvidia всегда были сильны, вот и в этот раз они впереди, несмотря на то, что последняя архитектура AMD к ним подтянулась.
В результате, GTX 580 опережает GTX 480 в этом тесте на 17% и почти догоняет двухчиповый Radeon HD 5970. Также отметим явное влияние эффективного филлрейта и ПСП, так как GTX 460 оказалась далеко позади. Посмотрим на результат этого же теста, но с включенным «шейдерным» суперсэмплингом, увеличивающим работу в четыре раза, возможно в такой ситуации что-то изменится и ПСП с филлрейтом будут влиять меньше:
Включение суперсэмплинга теоретически увеличивает нагрузку в четыре раза, и в этот раз решения Nvidia хоть и остаются сильнее, чем карты AMD, но разница уже меньше, и GTX 580 уже ближе к HD 5870 чем к HD 5970. GTX 460 провалилась вниз ещё дальше, ну а нас больше всего интересует разница между GF100 и GF110. И тут мы видим уже разницу 21—22%, что явно говорит о влиянии архитектурных изменений в виде z-cull-оптимизаций.
Второй тест измеряет производительность исполнения сложных пиксельных шейдеров с циклами при большом количестве текстурных выборок и называется Steep Parallax Mapping. При низких настройках он использует от 10 до 50 текстурных выборок из карты высот и три выборки из основных текстур. При включении тяжелого режима с самозатенением число выборок возрастает в два раза, а суперсэмплинг увеличивает это число в четыре раза. Наиболее сложный тестовый режим с суперсэмплингом и самозатенением выбирает от 80 до 400 текстурных значений, то есть в восемь раз больше, по сравнению с простым режимом. Проверяем сначала простые варианты без суперсэмплинга:
Данный тест несколько интереснее с практической точки зрения, так как разновидности parallax mapping давно применяются в играх, а тяжелые варианты, вроде нашего steep parallax mapping, используются во многих проектах, например, в играх Crysis и Lost Planet. Кроме того, в нашем тесте, помимо суперсэмплинга, можно включить самозатенение, увеличивающее нагрузку на видеочип примерно в два раза, такой режим называется «High».
Диаграмма во многом похожа на предыдущую (без SSAA). В обновленном D3D10 варианте теста без суперсэмплинга, GTX 580 справляется с поставленной задачей лучше, чем одночиповый конкурент HD 5870, но хуже, чем двухчиповый HD 5970. Разница с GTX 480 снова получилась порядка 17%, то есть соответственно количеству исполнительных блоков и их тактовой частоте. Посмотрим, что изменит включение суперсэмплинга, ведь он снова должен вызвать большее падение скорости на картах Nvidia.
При включении суперсэмплинга и самозатенения задача получается ещё более тяжёлой, совместное включение сразу двух опций увеличивает нагрузку на карты почти в восемь раз, вызывая большое падение производительности. Разница между скоростными показателями протестированных видеокарт изменилась, включение суперсэмплинга сказывается как и в предыдущем случае — карты производства AMD явно улучшили свои показатели относительно решения Nvidia.
И теперь HD 5870 уже опережает GTX 480, а HD 5970 становится лидером в этом тесте. Новое решение Nvidia всё-таки опережает одночипового конкурента, но до HD 5970 ему ой как далеко. Зато очень интересными получились сравнительные цифры GTX 480 и GTX 580. Даже на диаграмме видно, что разница в лёгких условиях составила те же 21%, а вот в тяжёлых (режим High) она выросла уже до 39%! Вероятно, мы снова видим следствие неких архитектурных оптимизаций, ибо ничем другим такую разницу просто не объяснить.
Direct3D 10: тесты пиксельных шейдеров PS 4.0 (вычисления)
Следующая пара тестов пиксельных шейдеров содержит минимальное количество текстурных выборок для снижения влияния производительности блоков TMU. В них используется большое количество арифметических операций, и измеряют они именно математическую производительность видеочипов, скорость выполнения арифметических инструкций в пиксельном шейдере.
Первый математический тест — Mineral. Это тест сложного процедурного текстурирования, в котором используются лишь две выборки из текстурных данных и 65 инструкций типа sin и cos.
Чисто математические тесты вряд ли будут особенно интересными в этот раз, так как графический процессор GF110 архитектурно не отличается от своего топового предшественника GF100. И разница в идеале должна соответствовать разнице в частотах и количестве ALU, то есть быть равной где-то около 17%.
Понятно, что решения AMD в таких математических тестах явно останутся значительно более быстрыми, так как в вычислительно сложных задачах разница с ними была явно большей, чем это значение. И современная архитектура AMD в таких случаях имеет большое преимущество перед конкурирующими видеокартами Nvidia. Что и подтверждается в очередной раз: HD 5970 примерно вдвое быстрее, чем GTX 580. Хотя, надо сказать, что разница заметно сократилась — нужно ждать обновления топового видеочипа и соответствующих карт от AMD.
Что касается сравнения GTX 580 и GTX 480, то тут всё ровно по теории — разница в скорости составила 16%. В общем, все решения расположились примерно соответственно теоретическим показателям, это касается как карт Nvidia, так и AMD. Рассмотрим второй тест шейдерных вычислений, который носит название Fire. Он тяжелее для ALU, и текстурная выборка в нём только одна, а количество инструкций типа sin и cos увеличено вдвое, до 130. Посмотрим, что изменилось при увеличении нагрузки:
Но и тут всё примерно так же — скорость рендеринга ограничена почти исключительно производительностью шейдерных блоков, и поэтому карты AMD далеко впереди. Разница между GTX 480 и GTX 580 осталась ровно той же — 16%, что почти точно соответствует значению, корректному с теоретической точки зрения.
Direct3D 10: тесты геометрических шейдеров
В пакете RightMark3D 2.0 есть два теста скорости геометрических шейдеров, первый вариант носит название «Galaxy», техника аналогична «point sprites» из предыдущих версий Direct3D. В нем анимируется система частиц на GPU, геометрический шейдер из каждой точки создает четыре вершины, образующих частицу. Аналогичные алгоритмы должны получить широкое использование в будущих играх DirectX 10.
Изменение балансировки в тестах геометрических шейдеров не влияет на конечный результат рендеринга, итоговая картинка всегда абсолютно одинакова, изменяются лишь способы обработки сцены. Параметр «GS load» определяет, в каком из шейдеров производятся вычисления — в вершинном или геометрическом. Количество вычислений всегда одинаково.
Рассмотрим первый вариант теста «Galaxy», с вычислениями в вершинном шейдере, для трёх уровней геометрической сложности:
Соотношение скоростей при разной геометрической сложности сцен примерно одинаково для всех решений, производительность соответствует количеству точек, с каждым шагом падение FPS составляет около двух раз. Задача для современных видеокарт не особенно сложная, производительность в целом ограничена не только скоростью обработки геометрии, но и пропускной способностью памяти в какой-то мере.
Новый топовый графический процессор Nvidia показывает свою силу, во всех режимах заметно обгоняя конкурентов, в том числе даже и двухчиповую карту AMD. Как и ожидалось, выполнение геометрических шейдеров у GF110 осталось весьма эффективным, и новый чип быстрее предыдущего топа примерно на 20%. Посмотрим, как изменится ситуация при переносе части вычислений в геометрический шейдер:
При изменении нагрузки в этом тесте, цифры для решений и Nvidia и AMD почти не изменились. Видеокарты в данном тесте «не замечают» изменения параметра GS load, отвечающего за перенос части вычислений в геометрический шейдер, и показывают аналогичные предыдущей диаграмме результаты. Посмотрим, что изменится в следующем тесте, который предполагает большую нагрузку именно на геометрические шейдеры.
«Hyperlight» — это второй тест геометрических шейдеров, демонстрирующий использование сразу нескольких техник: instancing, stream output, buffer load. В нем используется динамическое создание геометрии при помощи отрисовки в два буфера, а также новая возможность Direct3D 10 — stream output. Первый шейдер генерирует направление лучей, скорость и направление их роста, эти данные помещаются в буфер, который используется вторым шейдером для отрисовки. По каждой точке луча строятся 14 вершин по кругу, всего до миллиона выходных точек.
Новый тип шейдерных программ используется для генерации «лучей», а с параметром «GS load», выставленном в «Heavy», — ещё и для их отрисовки. Иными словами, в режиме «Balanced» геометрические шейдеры используются только для создания и «роста» лучей, вывод осуществляется при помощи «instancing», а в режиме «Heavy» выводом также занимается геометрический шейдер. Сначала рассматриваем лёгкий режим:
Относительные результаты в разных режимах снова соответствуют нагрузке: во всех случаях производительность неплохо масштабируется и близка к теоретическим параметрам, по которым каждый следующий уровень «Polygon count» должен быть менее чем в два раза медленней.
Судя по всему, в этом тесте скорость рендеринга для всех решений не ограничена геометрической производительностью, по крайней мере явно. А результаты двухчипового HD 5970 просто некорректны. Зато новый Geforce GTX 580 является лидером теста и в этот раз превосходит GTX 480 в трёх режимах нагрузки по-разному, в лёгком — на 16%, в тяжелом — уже на 23%. И снова мы видим влияние оптимизаций, повлиявших на баланс в режимах с различной нагрузкой на GPU.
Впрочем, цифры должны сильно измениться на следующей диаграмме, в тесте с более активным использованием геометрических шейдеров. Также будет интересно сравнить друг с другом результаты, полученные в режимах «Balanced» и «Heavy».
Вот в этом тесте мы видим явную разницу между чипами с традиционным графическим конвейером (Radeon) и топовыми чипами с архитектурой Fermi. Да, GF104 по скорости исполнения геометрических шейдеров отстаёт, но это и карта другого ценового диапазона. Зато GF100 и GF110 серьёзно опережают одиночный RV870 (результаты двухчиповой карты снова некорректны).
В общем, возможности топовых чипов Nvidia по обработке геометрии и скорости исполнения геометрических шейдеров явно значительно выше конкурирующих решений AMD. Новое решение GTX 580 в этом тесте опережает предшественника лишь на 11—13%, и в этот раз мы видим явное несоответствие теоретическим показателям. Или увеличение влияния пропускной способности памяти.
Direct3D 10: скорость выборки текстур из вершинных шейдеров
В тестах «Vertex Texture Fetch» измеряется скорость большого количества текстурных выборок из вершинного шейдера. Тесты схожи по сути, и соотношение между результатами карт в тестах «Earth» и «Waves» должно быть примерно одинаковым. В обоих тестах используется displacement mapping на основании данных текстурных выборок, единственное существенное отличие состоит в том, что в тесте «Waves» используются условные переходы, а в «Earth» — нет.
Рассмотрим первый тест «Earth», сначала в режиме «Effect detail Low»:
Предыдущие исследования показали, что на результаты этого теста влияет и скорость текстурирования, и пропускная способность памяти (что особенно заметно по результатам GTX 460). Разница между всеми решениями не такая уж большая, только GTX 460 показывает заметно отличающиеся результаты. Выборки из вершин картам Nvidia даются несколько легче, поэтому GTX 580 быстрее одночиповой HD 5870 и почти наравне с HD 5970.
Любопытна разница между GF110 и GF100. Если в лёгком режиме она достигает 30% в пользу новой карты, то в двух других не дотянула и до 5%. Видимо, снова виноват изменённый баланс, ну или оптимизации в драйверах для разных решений также разные. Посмотрим на производительность в этом же тесте с увеличенным количеством текстурных выборок:
Взаимное расположение карт на диаграмме почти не изменилось. Теперь GTX 580 точно впереди всех во всех режимах, а разница с GTX 480 стала ещё необычнее — до 52% в лёгком режиме! Возможно, что-то с результатами GTX 480 неверно или виноваты отличающиеся оптимизации в различных версиях драйверов.
Рассмотрим результаты второго теста текстурных выборок из вершинных шейдеров. Тест «Waves» отличается меньшим количеством выборок, зато в нём используются условные переходы. Количество билинейных текстурных выборок в данном случае до 14 («Effect detail Low») или до 24 («Effect detail High») на каждую вершину. Сложность геометрии изменяется аналогично предыдущему тесту.
А вот результаты в тесте «Waves» не похожи на то, что мы видели на предыдущих диаграммах. Может быть, совсем уж явного преимущества продукции AMD нет, но они стали значительно сильнее в этом тесте. GTX 580 показывает производительность примерно на уровне GTX 480 и HD 5870. Раньше мы предполагали, что в этом тесте сильно сказывается влияние ПСП, но сегодняшние цифры этому выводу противоречат. Рассмотрим второй вариант этого же теста:
Изменения снова почти отсутствуют, но интересно, что теперь GTX 580 опережает предшествующую GTX 480 на 20% в двух режимах, а не в одном. А вот в тяжёлом разницы между ними почти нет. В остальном отметим, что результаты нового графического процессора GF110 во втором тесте вершинных выборок примерно равны скорости двухчиповой карты конкурента, — и это очень хороший результат.
3DMark Vantage: Feature тесты
Синтетические тесты из пакета 3DMark Vantage могут показать нам что-то, что мы упустили. Этот тестовый пакет хоть уже и не новый, но его feature-тесты обладают поддержкой D3D10 и интересны уже тем, что отличаются от наших. При анализе результатов нового решения Nvidia в этом пакете мы сможем сделать какие-то новые и полезные выводы, ускользнувшие от нас в тестах семейства RightMark. Особенно это касается теста скорости текстурных выборок.
Feature Test 1: Texture FillПервый тест — тест скорости текстурных выборок. Используется заполнение прямоугольника значениями, считываемыми из маленькой текстуры с использованием многочисленных текстурных координат, которые изменяются каждый кадр.
К сожалению, даже тест Futuremark не показывает того теоретически возможного удвоения скорости текстурных выборок в определённых условиях. Зато в их тесте текстурной производительности получается совсем иное соотношение результатов, по сравнению с нашим. И эти цифры больше похожи на истинное положение дел. Хотя даже в этих тестах карты Nvidia более эффективно используют имеющиеся текстурные блоки, но продолжают отставать от решений AMD, что вполне объяснимо с точки зрения теории — у последних банально больше блоков TMU.
Больше всего нас интересует сравнение Geforce GTX 480 и GTX 580, и в данном случае новая видеокарта на базе чипа GF110 показывает ожидаемый результат, превосходящий предшественницу на 18%, что соответствует теории. Разница между всеми решениями наблюдается примерно такая, какая и должна быть, исходя из технических характеристик.
Feature Test 2: Color FillТест скорости заполнения. Используется очень простой пиксельный шейдер, не ограничивающий производительность. Интерполированное значение цвета записывается во внеэкранный буфер (render target) с использованием альфа-блендинга. Используется 16-битный внеэкранный буфер формата FP16, наиболее часто используемый в играх, применяющих HDR-рендеринг, поэтому такой тест является вполне своевременным.
В этом тесте мы уже видим влияние не только увеличенной рабочей частоты (так как количество блоков ROP у GF110 и GF100 равное), но и архитектурных изменений, ведь в тесте Vantage используется как раз 16-битный текстурный формат с плавающей точкой, ускоренный в GF110 и GF104.
В остальном показатели производительности в тесте примерно соответствуют теоретическим цифрам филлрейта, без учёта влияния ПСП видеопамяти. Цифры Vantage показывают именно производительность блоков ROP, а не величину пропускной способности, и GTX 580 в этом тесте оказался быстрее GTX 480 почти на четверть — на 24%.
Результаты теста примерно соответствуют теоретическим цифрам и зависят от количества блоков ROP и их частот. GTX 580 показывает неплохой результат, сразу же за двухчиповым HD 5970, заметно обгоняя одночиповое решение, имеющее меньшую теоретическую скорость заполнения. Понятно, что аутсайдером становится недорогой GTX 460, имеющий всего лишь 192-битную шину памяти.
Feature Test 3: Parallax Occlusion Mapping
Один из самых интересных feature-тестов, так как подобная техника уже используется в играх. В нём рисуется один четырехугольник (точнее, два треугольника) с применением специальной техники Parallax Occlusion Mapping, имитирующей сложную геометрию. Используются довольно ресурсоёмкие операции по трассировке лучей и карта глубины большого разрешения. Также эта поверхность затеняется при помощи тяжёлого алгоритма Strauss. Это тест очень сложного и тяжелого для видеочипа пиксельного шейдера, содержащего многочисленные текстурные выборки при трассировке лучей, динамические ветвления и сложные расчёты освещения по Strauss.
Тест отличается от других подобных тем, что результаты в нём зависят не исключительно от скорости математических вычислений или эффективности исполнения ветвлений или скорости текстурных выборок, а от всего понемногу. И для достижения высокой скорости важен правильный баланс блоков GPU и ПСП видеопамяти. Заметно влияет на скорость и эффективность выполнения ветвлений в шейдерах.
Как видно по результатам, тест также выполняется на GTX 580 более чем на 24% быстрее, по сравнению с GTX 480, что говорит о влиянии архитектурных изменений в GF110 на общую производительность. Именно из-за них, в дополнение к повышенным частотам и количеству ALU, GTX 580 показал практически идентичный с Radeon HD 5870 результат в этом тесте, отстав только от двухчиповой карты конкурента.
Feature Test 4: GPU ClothТест интересен тем, что рассчитывает физические взаимодействия (имитация ткани) при помощи видеочипа. Используется вершинная симуляция, при помощи комбинированной работы вершинного и геометрического шейдеров, с несколькими проходами. Используется stream out для переноса вершин из одного прохода симуляции к другому. Таким образом, тестируется производительность исполнения вершинных и геометрических шейдеров и скорость stream out.
Вероятно, скорость рендеринга в этом тесте зависит сразу от нескольких параметров, производительности обработки геометрии и эффективности исполнения геометрических шейдеров. И в этом представленный сегодня GTX 580 показывает себя просто отлично, являясь лидером и заметно опережая конкурентов от AMD.
В общем, с выполнением геометрических шейдеров и скоростью обработки геометрии у GF110 всё даже ещё лучше, чем у GF100. Разница между этими решениями вполне соответствует теоретическим характеристикам чипов, и составляет 18% — в точном соответствии с теорией.
Feature Test 5: GPU ParticlesТест физической симуляции эффектов на базе систем частиц, рассчитываемых при помощи видеочипа. Также используется вершинная симуляция, каждая вершина представляет одиночную частицу. Stream out используется с той же целью, что и в предыдущем тесте. Рассчитывается несколько сотен тысяч частиц, все анимируются отдельно, также рассчитываются их столкновения с картой высот.
Аналогично одному из тестов нашего RightMark3D 2.0, частицы отрисовываются при помощи геометрического шейдера, который из каждой точки создает четыре вершины, образующих частицу. Но тест больше всего загружает шейдерные блоки вершинными расчётами, также тестируется stream out.
Результаты этого теста похожи на те, что мы видели на предыдущей диаграмме. Geforce GTX 580, основанный на GF110, снова показывает лучший результат, значительно обгоняя конкурирующие видеокарты, двухчиповая из которых в данных тестах просто не получает преимущества от второго GPU.
В синтетических тестах имитации тканей и частиц тестового пакета 3DMark Vantage, где используются геометрические шейдеры, новый чип GF110 показал себя с самой лучшей стороны, так как он заметно опережает конкурирующие графические процессоры компании AMD. Разница между GTX 580 и GTX 480 в этот раз составила лишь 15% (видимо, производительность частично ограничена ещё и ПСП).
Feature Test 6: Perlin NoiseНу и последний feature-тест пакета Vantage является математически-интенсивным тестом видеочипа, он рассчитывает несколько октав алгоритма Perlin noise в пиксельном шейдере. Каждый цветовой канал использует собственную функцию шума для большей нагрузки на видеочип. Perlin noise — это стандартный алгоритм, часто используемый в процедурном текстурировании, он использует очень много математических расчётов.
А вот в математическом тесте из пакета компании Futuremark, который показывает пиковую производительность видеочипов в предельных задачах, мы видим уже другую, но тоже знакомую нам картину. Показанная на диаграмме производительность решений примерно соответствует тому, что должно получаться по теории, и тому, что мы видели ранее в наших математических тестах из пакета RightMark 2.0.
В этом математическом тесте Geforce GTX 580 показывает результат на 19% выше, чем GTX 480, что примерно соответствует теории. Ну а что касается сравнения с конкурентом, то все уже привыкли к тому, что видеокарты AMD всегда выигрывают этот тест с большим преимуществом. Простая, но интенсивная математика выполняется на видеокартах Radeon значительно быстрее. Хотя разница между GF110 и RV870 уже составляет хотя бы не несколько раз, а «всего лишь» 45%. Подождём выхода нового топового чипа AMD, он должен снова серьёзно вырваться вперёд в математических вычислениях.
Выводы по синтетическим тестам
По результатам проведённых нами синтетических тестов новой модели Nvidia Geforce GTX 580, основанной на графическом процессоре GF110, а также результатам других моделей видеокарт производства обоих производителей дискретных видеочипов, можно сделать вывод о том, что это — наиболее мощное решение для верхнего ценового диапазона, основанное на улучшенном чипе GF110, созданном на базе графической архитектуры Fermi.
Модель Geforce GTX 580 отличается улучшенной производительностью и потребительскими характеристиками, по сравнению с предшествующим ему решением — GTX 480. Новая видеокарта выделяется увеличенным количеством активных (не отключённых аппаратно) исполнительных блоков: ALU, TMU, PolyMorph; повышенной тактовой частотой, а также некоторыми архитектурными улучшениями: удвоенной скоростью фильтрации FP16 текстур и улучшениями в алгоритмах z-cull.
Благодаря всему этому, результаты GTX 580 выросли примерно на 20%, по сравнению с GTX 480, и во многих синтетических тестах именно эта карта стала новым лидером. Например, в тестах геометрических шейдеров и физических расчётов (имитации тканей и частиц в пакете Vantage, где также используются геометрические шейдеры), а также и других вычислительных тестах со сложными программами новый чип показал себя просто замечательно. Хотя лидерство в хорошо распараллеленных, но не слишком сложных по алгоритму расчётных задачах в тестах RightMark и Vantage, всё же остаётся за решениями AMD.
Небольшие архитектурные изменения в GF110, по сравнению с GF100, привели к росту результатов, но лишь в крайне ограниченном количестве тестов. В основном повышение производительности GTX 580 связано именно с увеличением количества исполнительных блоков и росту тактовой частоты GPU. Но и это неплохо, так как такой рост стал возможен не просто в рамках потребления GTX 480, но даже и с его снижением.
В итоге можно с уверенностью ожидать, что очень хорошие результаты Geforce GTX 580 в синтетических тестах, а также отличные теоретические характеристики будут подкреплены сильными результатами в следующей части нашего материла, где вы ознакомитесь с игровыми тестами из нашего набора. Предполагаем, что и в игровых тестах прирост скорости рендеринга Geforce GTX 580 над GTX 480 будет равен примерно 15—20%. И это позволит назвать новую видеокарту быстрейшим одночиповым решением на рынке на данный момент.
Nvidia Geforce GTX 580 — Часть 3: Игровые тесты (производительность)
Блок питания для
тестового стенда предоставлен
компанией TAGAN |
Корпус ThermalTake 8430 для
тестового стенда предоставлен
компанией 3LOGIC |
Монитор Dell 3007WFP для
тестовых стендов предоставлен
компанией Nvidia |

| 9 ноября 2010 |
|
|