NVIDIA GeForce FX 5900 Ultra 256MB

СОДЕРЖАНИЕ
- Общие сведения
- Особенности видеокарты NVIDIA GeForce FX 5900 Ultra 256MB
- Конфигурации тестовых стендов и особенности настроек драйверов
- Результаты тестов: коротко о 2D
- Синтетические тесты RightMark3D: идеология и описание тестов
- Результаты тестов: RightMark3D: Pixel Filling
- Результаты тестов: RightMark3D: Geometry Processing Speed
- Результаты тестов: RightMark3D: Hidden Surface Removal
- Результаты тестов: RightMark3D: Pixel Shading
- Результаты тестов: RightMark3D: Point Sprites
- Результаты тестов: Синтетические тесты 3DMark2001 SE и 3DMark03
- Выводы из результатов синтетических тестов
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game1
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game2
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game3
- Результаты тестов: Игровые тесты 3DMark2001 SE: Game4
- Результаты тестов: Игровые тесты 3DMark03: Game1
- Результаты тестов: Игровые тесты 3DMark03: Game2
- Результаты тестов: Игровые тесты 3DMark03: Game3
- Результаты тестов: Игровые тесты 3DMark03: Game4
- Результаты тестов: Quake3 ARENA
- Результаты тестов: Serious Sam: The Second Encounter
- Результаты тестов: Return to Castle Wolfenstein
- Результаты тестов: Code Creatures DEMO
- Результаты тестов: Unreal Tournament 2003 DEMO
- Результаты тестов: AquaMark
- Результаты тестов: RightMark 3D
- Результаты тестов: DOOM III Alpha version
- Качество 3D
- Выводы
Результаты практического тестирования
Что же перейдем к самому интересному. Приведем и прокомментируем данные, полученные нами на ускорителях, нацеленных, как говорят сами производители, на энтузиастов: героя сегодняшнего материала — NVIDIA GeForce FX 5900 Ultra, а также NVIDIA GeForce FX 5800 Ultra и ATI RADEON 9800 PRO. В качестве опорной для анализа видеокарты в данном тестировании выступает NVIDIA GeForce FX 5800 Ultra, как наиболее близкая по архитектуре для GeForce FX 5900 Ultra. Результаты и их анализ для ATI RADEON 9800 PRO приводятся для выяснения, смогла ли NVIDIA превзойти по производительности флагман своего конкурента — ATI.
Pixel Filling
- Тест на скорость закраски буфера кадров (Pixel Fillrate). Закраска константным цветом — выборка
текстур не производится. Приведены результаты в миллионах пикселей в секунду для разных
разрешений, причем как в обычном режиме, так и для 4х MSAA:
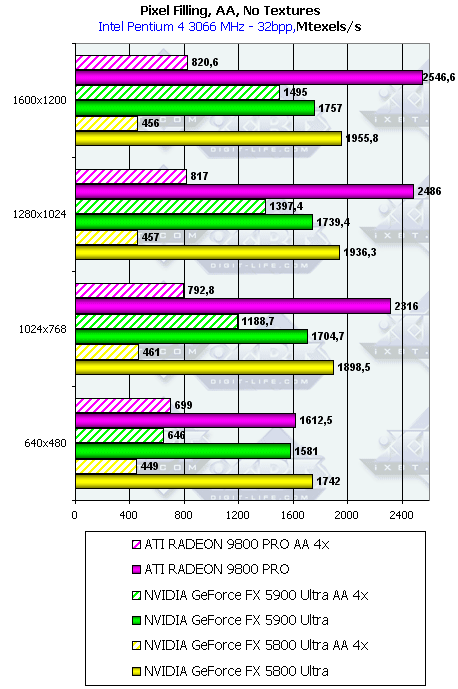
Скорость закраски в режиме без антиалиасинга в точности соответствует разнице частот между GeForce FX 5900 Ultra и NVIDIA GeForce FX 5800 Ultra (450 vs 500). Несмотря на более высокую тактовую частоту чипов GFFX — GeForce FX 5900 Ultra проигрывает конкуренту ATI во всех случаях. Из этого можно сделать вывод, что для чипов GFFX в случае простой закраски пропускная способность шины не является ограничивающим фактором. Radeon 9800 Pro берет лидерство в этом режиме за счет наличия 8 пиксельных конвейеров, способных записывать 8 значений цвета и глубины за такт и максимальные значения, показанные платой от ATI, ограничиваются именно пропускной способностью шины. FX может записать только 4 полных пикселя (цвет + глубина + когда надо буфер шаблонов aka Stencil). Однако 4 пиксельных процессора FX имеют одну интересную оптимизацию — если мы, в результате выполнения шейдера или просто закрашивая треугольник, не сохраняя значения цвета пикселя, а изменяем только значения глубины или буфера шаблонов, то каждый пиксельный процессор может за один такт выдать два результата. Таким образом, в сумме записав 8 значений глубины или буфера шаблонов за такт. Сейчас, при анонсе GeForce FX 5900 Ultra NVIDIA открыто сообщает об этой особенности GFFX, выставляя ее как преимущество и описав как часть технологии UltraShadow. Подобная оптимизация очень пригодится в играх с стенсильными тенями, подобных DOOM III, там она может ускорить прорисовку сцены почти в полтора раза. Однако в нашем тесте закрашиваются и значения цвета. Именно поэтому результат свидетельствует лишь о 4 пикселях, выводимых за такт.
Теперь рассмотрим скорость закраски при использовании антиалиасинга. Картина кардинально меняется. По сравнению с GeForce FX 5800 Ultra карта серии 5900 резко вырывается вперед, причем конкурент от ATI может что-то противопоставить новому продукту NVIDIA только в низких разрешениях. При повышении разрешения GeForce FX 5900 Ultra является безусловным лидером, и это несмотря на вдвое меньшее количество пиксельных конвейеров (помним про 256-битную шину).
- Тест на скорость закраски буфера кадров с одновременным текстурированием.
Добавляется выборка одной простой билинейной текстуры — проверим, насколько
наличие конкурентного потока чтения из памяти понизит эффективность закраски.
Приведены результаты в миллионах пикселей в секунду, для разных разрешений,
причем как в обычном режиме, так и для 4х MSAA. Ввиду того, что все последние
драйвера ATI Catalyst (3.1 и выше) вкупе с нашим синтетическим тестом
выдают на некоторых продуктах ATI странные, очевидно заниженные результаты,
видимо, из за неудачной попытки оптимизировать работу этого теста на режимах
с выборкой значений текстур, мы не приводим результатов Pixel Filling с
текстурами для RADEON.
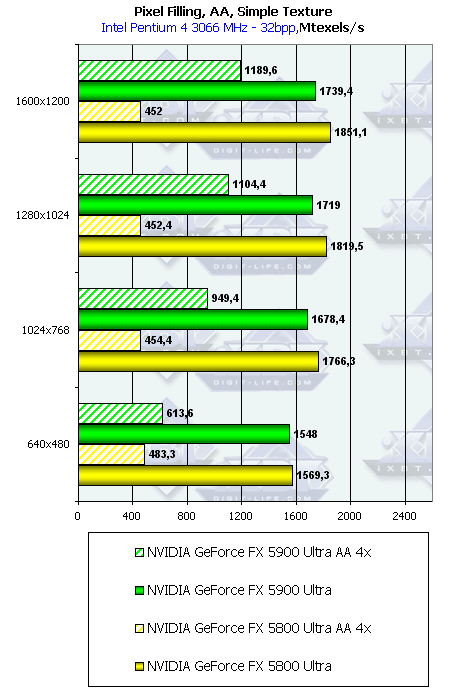
В общем и целом, картина практически та же, но пиковые значения упали. Давайте посмотрим, насколько хорошо измеренная действительность соотносится с теоретическими пределами, основанными на частоте ядра и числе конвейеров:
Продукт Теоретический максимум, млн.текселей в сек. Полученный максимум, млн.текселей в сек (без текстур). Полученный максимум, млн.текселей в сек (с одной текстурой). RADEON 9800 PRO 3000 2486 - GeForce FX 5900 Ultra 1800 1757 1739 GeForce FX 5800 Ultra 2000 1957 1848
Geometry Processing Speed
Займемся исследованием геометрической производительности ускорителей. Результаты в диаграммах сортированы по степени сложности используемой модели освещения. Самый нижняя группа — простейший вариант, соответствующий пиковой пропускной способности ускорителя по вершинам.
- Производительность фиксированного TCL (для NV3x и R3x0 — производительность эмулирующего его шейдера):
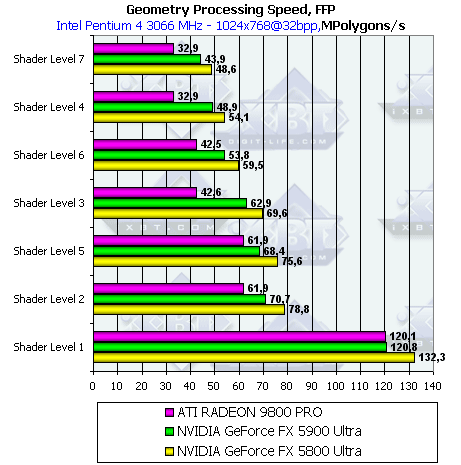
Результаты в точности соответствуют разнице частот — производительность GeForce FX 5900 Ultra ровно на 10% меньше GeForce FX 5800 Ultra (450 vs 500 Мгц)
- Теперь обратимся к вершинным шейдерам 1.1:
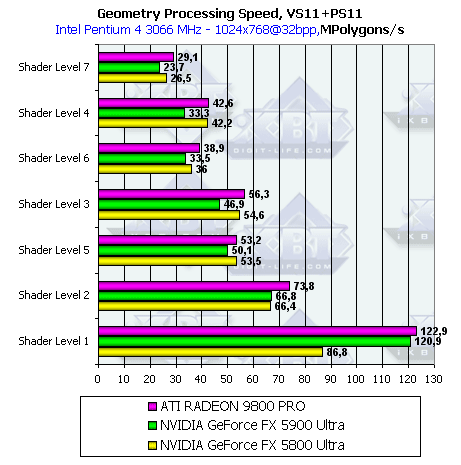
Здесь мы видим несколько странное поведение GeForce FX 5800 Ultra в сравнении с GeForce FX 5900 Ultra. В самом простом случае (Shader Level 1) карта показывает значительно меньшие результаты, чем при использовании функционально аналогичных настроек фиксированного TCL. А GeForce FX 5900 Ultra показывает сравнимые результаты между фиксированным TCL и вершинными шейдерами VS 1.1, причем это при использовании одинаковой версии драйверов, что исключает возможность оптимизации микрокода. При увеличении сложности шейдера мы опять видим ту же разницу в 10%.
- Еще один интересный тест — шейдеры 2.0 с циклами:
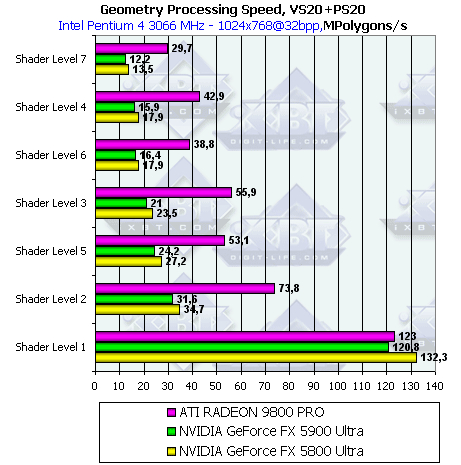
Как и на предыдущих тестах, мы видим, что разница между NV30 и NV35 в точности соответствует разнице частот. Заметим, что в случае компиляции самого простого шейдера (Shader Level 1) под вершинные шейдеры второй версии NV30 снова показывает "правильные", а не заниженные как в случае с вершинными шейдерами VS 1.1 результаты.
Очень интересный результат показывает ATI RADEON 9800 PRO: производительность исполнения вершинных шейдеров второй версии с циклами с точностью до погрешности эквивалентна производительности шейдеров первой версии, хотя ранее Radeon 9700 Pro показывал существенно меньшую производительность. Весьма велика вероятность того, что драйвер при компиляции шейдера в микрокод на новых драйверах "разворачивает" циклы в одну большую шейдерную программу.
Чипы серии NV3x видимо вынуждены эмулировать циклы со статическими переходами при помощи микрокода, рассчитанного на динамическое (зависимое от данных текущей вершины) исполнение. Поэтому в случае NV3x накладные расходы на циклы очень значительны! И это не удивительно, динамическое управление потоком команд может и должно вызывать большие задержки при выполнение циклов. Что мы здесь и наблюдаем -за гибкость приходится расплачиваться скоростью.
Но если наша догадка о "разворачивании" шейдеров в ATI RADEON 9800 PRO верна, то такая оптимизация может иметь и обратную сторону для ATI. Микрокод такого шейдера будет занимать значительно больше места по сравнению с версией с циклами — соответственно, драйвер сможет хранить меньшее количество шейдеров в кэше чипа, а время, потраченное на загрузку кода нового шейдера в чип, может свести на нет все оптимизации, полученные "разворачиванием" кода. При изменении константы задающей количество циклов драйвер также будет вынужден заново генерировать и загружать микрокод шейдера.
- Проверим перекрестную зависимость от степени детализации геометрии и сложности шейдера:
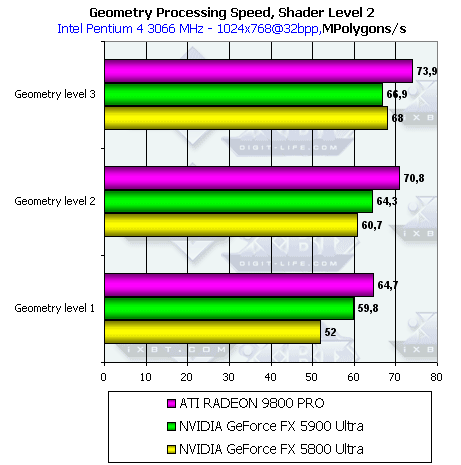
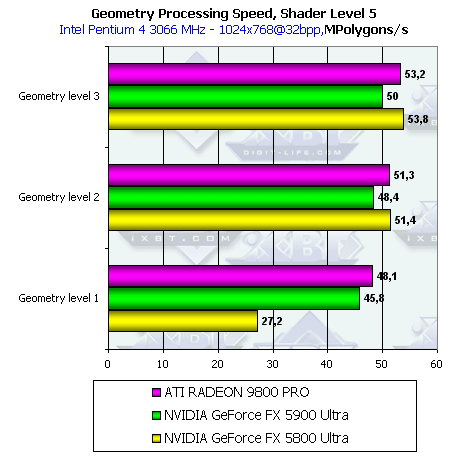
Здесь мы видим характерную картину: при малой детализации сцены (соответственно при малой загруженности геометрического блока чипа по сравнению с пиксельными конвейерами) GeForce FX 5900 Ultra выигрывает у 5800 Ultra возможно за счет намного большей пропускной способности шины и оптимизированного кэша кадрового буфера. А при увеличении нагрузки на геометрический блок вперед вырывается 5800 Ultra.
Hidden Surface Removal
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от
числа треугольников, на сцене без текстур (не учитывается ранняя проверка Z):
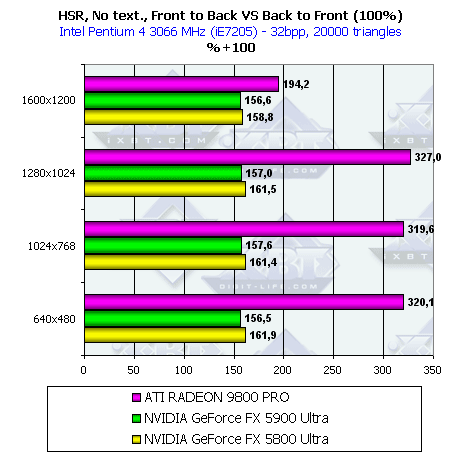
Как мы видим, из-за увеличившейся пропускной способности шины эффект от алгоритма HSR на NV35 даже несколько уменьшился по сравнению с NV30, т.к. даже в худшем случае (back to front sorting) шина памяти способна прокачать увеличившийся объем данных. Но эффективность HSR у обоих чипов все равно ниже, чем у R300 — дело в том, что R300 использует иерархическую структуру, и зачастую отсечение происходит на более высоком уровне, а следовательно, и более эффективно, в то время как у NV30 присутствует только один уровень принятия решения, совмещенный с тайлами, на основе которых сжимается информация о глубине. В максимальном разрешении 1600х1200 происходит резкое падение эффективности HSR на R300 — видимо, по каким-то причинам, например из-за ограниченности размера кэша, выделенного под иерархический буфер, он уже не используется, и решение об отсечении блоков принимается так же, как и в случае NV3x, только на самом нижнем базовом уровне, совмещенном с сжимаемыми блоками в буфере глубины.
Теперь давайте посмотрим на то, как эффективность HSR зависит от сложности сцены
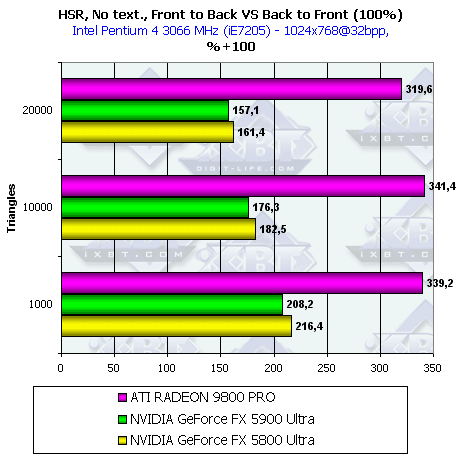
Как мы видим, для NV3x, обладающей только одним уровнем тайлов, эффективность работы HSR тем выше, чем меньше полигонов на сцене. R300 придерживается в этом вопросе золотой середины. Его HSR только расправляет крылья на сценах средней сложности.
- Наличие и максимальная эффективность HSR в процентах в зависимости от разрешения и от
числа треугольников, на сцене с текстурами (с учетом ранней проверки Z):
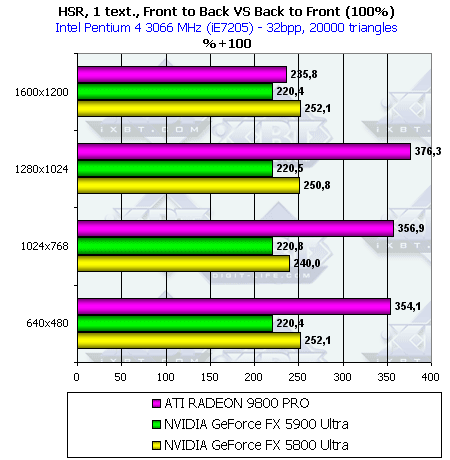
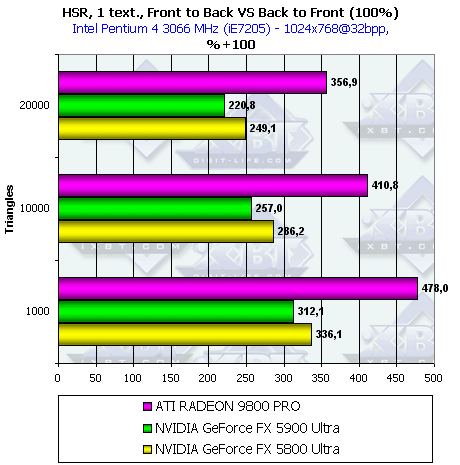
Итак, здесь все чипы демонстрирую рост эффективности от ранней проверки Z. С учетом наличия текстуры, все чипы начинают предпочитать сцены с низким числом полигонов. В остальном поведение аналогично предыдущему тесту.
- Посмотрим, как изменится эффективность в случае сравнения хаотической и сортированной сцены, как
с текстурой, так и без:
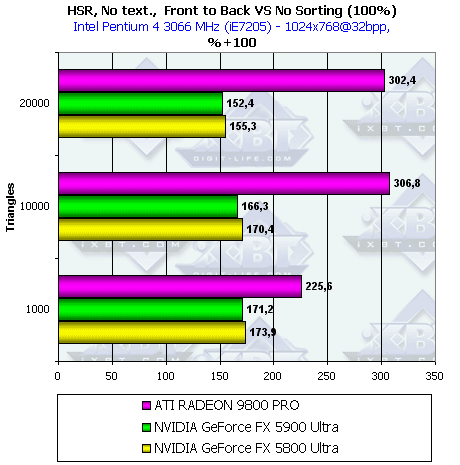
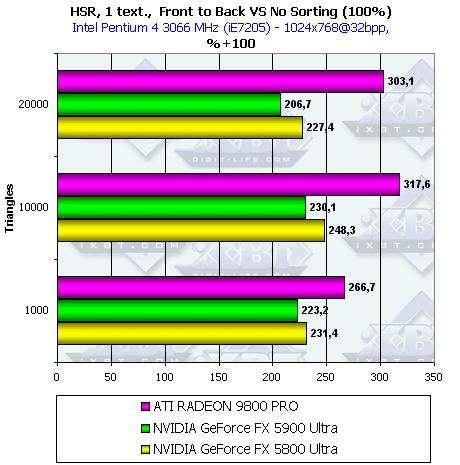
Принципиально ничего нового, соотношение эффективности HSR у разных чипов осталось прежним, прирост от техник HSR уменьшился. Но все равно при использовании текстур все чипы продемонстрировали прирост более чем в 2 раза.
Итак, даже в случае исходно хаотической сцены прирост велик. Вывод — если хотите воспользоваться
благами HSR — сортируйте сцену перед выводом. Тогда и только тогда вы получите значительное, в
несколько раз, преимущество!
[ Предыдущая часть (2) ]
[ Следующая часть (4) ]
| 13 мая 2003 г. |
|
|