Технологии Sensaura
Компания Sensaura более 10 лет занимается созданием звуковых технологий. Все разработки Sensaura ориентированы на работу через стандартный интерфейс DirectSound3D и его расширения. Часть технологий Sensaura уже применяются на практике, другие разработки мы скоро увидим в действии. По сути, Sensaura предлагает использовать производителям звуковых чипов и карт специальные алгоритмы, которые в паре со стандартным API DS3D и расширениями для него, должны обеспечить моделирование и воспроизведение качественного 3D звука.
Попробуем кратко рассказать о том, что же предлагает Sensaura.
Digital Ear
Для корректного воспроизведения 3D звука через наушники или колонки необходимо использовать специальные алгоритмы, базирующиеся на использовании HRTF функций. Кроме того, при воспроизведении 3D звука через колонки необходимо использовать дополнительные алгоритмы Cross-talk Cancellation, вариант которых от Sensaura носит имя Transaural Cross-talk Cancellation (TCC). Подробно о том, что такое HRTF и TCC мы говорили в этом материале. В данной статье нас больше интересует, какие решения использует Sensaura.
Инженеры Sensaura пришли к выводу, что использование для формирования библиотек HRTF измерения, сделанные с помощью специального манекена или с приглашением реальных слушателей не могут обеспечить удовлетворить абсолютно всех слушателей. Дело в том, что какое бы большое число измерений не было сделано с использованием манекена, все полученные HRTF все равно будут усредненными. Все то же самое относится и к измерениям, сделанным с приглашением большого числа различных слушателей. Все равно есть небольшая часть людей, у которых совершенно отличные параметры слуха, а значит, при измерении у них получаются, совсем другие HRTF функции. В результате, какой бы большой и универсальной не была библиотека HRTF функций, часть людей не услышат ожидаемого 3D звука. Чтобы решить эту проблему, специалисты Sensaura разработали технологию Digital Ear (Цифровое ухо), ранее называвшуюся Virtual Ear. Суть идеи Digital Ear в том, что для измерения HRTF используется не просто манекен или приглашаются реальные слушатели, а используется чисто математический метод Ключевым элементом этого метода является математическая модель человеческого уха с изменяемыми параметрами. В основу математической модели положена концепция того, что сложные резонансные и дифракционные эффекты, являющиеся неотъемлемой частью любой HRTF функции могут независимо изменяться. В результате созданая дуплексная система, позволяющая изменять различные параметры в произвольном масштабе. Прежде чем была построена эта математическая модель было проведено масса исследований с целью точно смоделировать само ухо, точно определить, как оно реагирует на звуковые волны и как работает процесс человеческого слуха. Учитывались особенности восприятия мозгом различных звуков от источников, расположенных в разных точках пространства. Затем была создана модель уха из специального пластика, на нем были проведены измерения и отлажена математическая модель. Потом были получены базовые результаты измерения HRTF, на основе которых в дальнейшем с помощью специальных методов масштабирования стала формироваться библиотека HRTF. Использование математической модели гарантирует от наличия ошибок, которые возможны при физическом измерении HRTF с помощью манекена или реальных слушателей. Digital Ear можно настроить на огромное количество вариаций форм и размеров ушей реальных людей. В итоге получается обширная библиотека с возможностью очень гибко выбрать одну или несколько HRTF, которая наилучшим образом соответствует особенностям каждого конкретного слушателя. Кроме того, так как используется математическая модель, имеется возможность довольно простой модернизации алгоритмов и обновления библиотек HRTF без больших материальных затрат.
Между некоторыми параметрами Digital Ear существует зависимость, не мешающая масштабированию каждого из параметров в отдельности. Это позволяет построить простой интерфейс пользователя, позволяющий путем определения и задания в качестве данных некоторых физических параметров, описывающих голову и уши слушателя выбрать именно те HRTF функции из библиотеки, которые наилучшим образом отвечают особенностям конкретного слушателя. Вот эти параметры:
- Размер головы (Head Size) — влияет на изменение величины ITD (Interaural time delay) задержки по времени при восприятии ушами слушателя звука от одного источника
- Размер уха (Ear Size) — влияет на протяженность звукового спектра
- Глубина ушной раковины (Concha Depth) — влияет на величину сдвига звукового спектра
- Тип ушной раковины (Concha Type) — влияет на величину амплитуды звукового сигнала
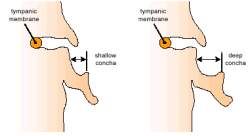
Слева неглубокая ушная раковина, справа — глубокая
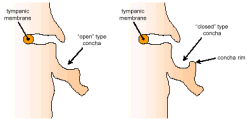
Слева ушная раковина открытого типа, справа — закрытого типа
В результате, каждый пользователь сможет настроить воспроизведения 3D звука с использованием технологии Digital Ear специально под себя. Пока технология Digital Ear не позволяет использовать гибкую настройку под конкретного слушателя и во всех дравейрах к звуковым картам, использующим технологии Sensaura задействуется универсальный набор HRTF функций, соответствующий среднему слушателю. Однако обещается, что уже в скором времени у пользователя появится возможность выбора HRTF под себя.
Смоделированный 3D звук мы можем слушать через наушники или через набор акустических колонок. При прослушивании через наушники используются только HRTF функции для воспроизведения эффектов 3D звука. Эта техника является традиционной и пока кардинально нового тут ничего не предвидится. За исключением шлифовки качества HRTF и предоставления пользователю возможности выбора HRTF конкретно под себя. При воспроизведении звука через две колонки также используется довольно традиционный метод комбинирования HRTF и алгоритмов cross-talk cancellation. Зато при вопсроизведении 3D звука через четыре и более колонок пока нет единого метода. Компания Sensaura разработала технологию MultiDrive, которая обеспечивает воспроизведение 3D звука с помощью более чем четырех колонок.
MultiDrive
Прежде всего начнем немного издалека. Зададимся вопросом, а зачем нам собственно слушать 3D звук через более чем одну пару колонок? Ну, в пользу мультиколоночных акустических систем можно сказать, что, во-первых у некоторых пользователей они уже есть, так почему бы их не использовать. Во-вторых, обычная ситема из двух колонок с использованием HRTF + CC имеет ряд ограничений при вопроизведении звуков от источников, расположенных в вертикальной плоскости и при движении источника звука по оси фронт/тыл. Итак, понятно, что, как минимум дополнительная пара колонок на тылах нам не повредит.
Есть и еще один момент. При использовании связки HRTF + CC могут возникнуть сложности корректного воспроизведения некоторых высокочастотных компонет звука выше величины в несколько kHz. Например, если на фоне звука взрывов нужно воспроизвести пение птахи. Причиной этого является невозможность реализовать идеально алгоритмы CC. Разные компании по разному борятся с этой проблемой, например, используются специальные фильтры высокой частоты, которые просто вырезают высокочастотные компоненты. В технологии MultiDrive применяются специальные фильтры, которые позволяют обеспечить воспроизведение звука, насыщенного высокочастотными компонентами.
Кроме того, для наилучшего восприятия звука слушатель должен находится в границах sweet spot, т.е. участка пространства, в котором звук воспринимается наилучшим образом. Понятно, что чем больше площадь sweet spot, тем большая свобода у слушателя. Мы ведь не манекены и не можем долгое время сидеть, не меняя положения головы относительно пола. В настоящее время наиболее распространена конфигурация из 4 колонок (не считая сабвуфера), поэтому в дальнейшем мы будем говорить именно о такой конфигурации акустики.
Технология MultiDrive позволяет воспроизводить 3D звук с использованием API DS3D. Суть этой технологии заключается в использовании HRTF функций на всех парах колонок с применением алгоритмов Transaural Cross-talk Cancellation (TCC). Отличие TCC от стандартных алгоритмов CC заключается в том, что они обеспечивают лучшие низкочастотные характеристики звука. Кроме того, предусмотрена возможность для пользователя управлять работой TCC, настраивая звучание под себя.
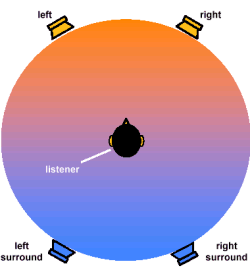
Каждая пара колонок создает фронтальную и тыловую полусферу соответственно. Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука и под управлением DS3D. В каждом звуковом поле применяются собственный алгоритм TCC. Исходя из этого, вокруг слушателя должно происходить плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, по сравнению, например, с двухколоночной конфигурацией.
Минусом использования HRTF + TCC на всех парах колонок является то, что для расчета TCC требуется масса вычислительных ресурсов и необходимость довольно точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF + TCC на четырех колонках не будет.
Стоит добавить, что MultiDrive рассчитана на совместное использование с алгоритмами MacroFX и ZoomFX от Sensaura.
MacroFX
Мы уже говорили выше, что с помощью HRTF и TCC можно воспроизвести качественный 3D звук. Но есть один нюанс. Обычно большинство измерений HRTF производятся в так называемом дальнем поле (far field, на дистации более 1 метра до источника звука), т.к. это существенно упрощает вычисления да и в большинстве игр воспроизводится звук от источников, находящихся на расстоянии от 1 метра и больше от слушателя. При этом, если источник звука находится на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда эффективность использования HRTF снижается. Дело в том, что для создания звучания от удаленного источника звука достаточно добавить к основному звуковому сигналу реверберацию. Иногда можно обойтись и без реверберации, сократив высокочастотные компоненты в основном звуковом сигнале. Если источник звука находится в ближнем поле, подобные решения не применимы. Но необходимость в воспроизведении звука от источников в ближнем боле нередки. Например, в игре типа RPG может возникнуть необходимость нашептать подсказку непосредственно в ухо игроку, а в FPS игре часто необходимо воспроизвести звук пролетающих рядом с головой игрока пуль. Все эти эффекты нельзя вопроизвести, если HRTF измерялись на дистанции от одного метра и более, т.е. в дальнем поле. Тем не менее, измерить HRTF для всей области ближнего поля очень сложно, а использование дискретных наборов HRTF, сделанных, например, для дистанций 1 м, 0,9 м, 0,8 м и т.д. не позволит сделать звук от движущегося объекта естественно плавным, он будет скачкообразным. Решением проблемы является использование единого набора универсальных HRTF для ближнего поля с использованием дополнительного алгоритма.
Этот алгоритм был создан Sensaura и получил имя MacroFX. В результате работы MacroFX можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя и вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя, преобразования этих данных в тесном взаимодействии с HRTF функциями. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. Все эти вычисления происходят до начала работы алгоритмов TCC, но сразу после расчета HRTF для всех источников звука.
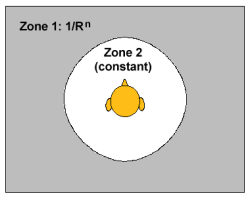
В DS3D предусмотрено три зоны (две из них показаны на рисунке слева). Зона 0 (ее нет на рисунке) в ней располагаются сильно удаленные источники звука, которые имеют постоянную интенсивность, не зависящую от расстояния. Источники в этой зоне могут не приниматься во внимание, т.е. слушатель их не слышит, либо они используются для формирования реверберации. Зона 1 это т.н. дальнее поле, в ней располагаются источники на расстоянии более 1 метра от слушателя и до определяемой разработчиком границы. В этой зоне интенсивность источников звука обратно пропорциональна расстоянию до слушателя. В зоне 2 (ближнее поле, расстояние до 1 м от слушателя) все источники звука имеют постоянную интенсивность. Это сделано для того, чтобы уровень громкости не превысил допустимого барьера и с целью ограничения нагрузки на шину данных.
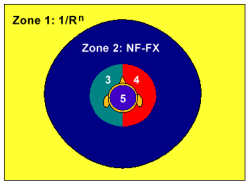
MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (дальнее поле) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле) в стиле MacroFX, покрывающие дистанцию рядом с головой слушателя, левое ухо, правое ухо и пространство внутри головы слушателя. При этом здесь также вводятся ограничение на дистанцию, чтобы сократить накладные расходы при вычислениях. Поэтому в зоне 2 используется стандартный алгоритм Near-Field FX, а в зонах 3, 4 и 5, которые начинают работать с расстояния в 20 см, используется как таковой алгоритм MacroFX. Эти три зоны рассчитаны на источники звука, расположенные очень близко к ушам пользователя (левому или правому). Если источник звука должен находится как бы в голове пользователя (например, переговоры авиадиспетчеров в авиасимуляторе), то для этого используется зона 5.
Алгоритм MacroFX полностью прозрачен для интерфейсов и игр. Это означает, что если у вас установлена звуковая карта, в драйвер которой встроена поддержка MacroFX, то вы услышите работу этой технологии во всех играх, где источники звука попадают в ближнее поле. Разумеется, в зависимости от конкретной игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX можно добиться очень впечатляющих эффектов, например, писк комара прямо в ухе, свист ветра в ушах при езде на велосипеде и т.д.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, являющихся точечными. В реальной жизни звук зачастую исходит от больших по размеру источников звука или от композитных источников, объединяющих собой сразу несколько источников звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. В реальной жизни, когда поезд проезжает рядом с нами, мы слышим стук колес, скрип рессор, звук от буферов и т.д. Тем не менее, при моделировании источника звука типа поезд с использованием интерфейса DS3D поезд представляется, как точечный источник звука. В результате звук получается ненатуральным, т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом. Технология ZoomFX решает эту проблему, за счет введения такого параметра источника звука, как размер и сложность. Если вспомнить про наш поезд, то он будет представлен в виде собрания нескольких источников звука, типа шума колес, шума двигателя, шума сцепок вагонов и т.д. Для представления большого по размеру объекта используется набор из нескольких точечных источников звука. Для того чтобы мы слышали отдельные составляющие композитного источника звука используется метод динамической декорреляции (Dynamic Decorrelation), позволяющий выделить отдельные источники, составляющие композитный источник звука.

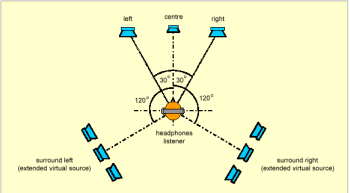
На рисунке слева показано, как источник звука типа вертолет представляется в виде нескольких точеных источников. Когда вертолет далеко от нас, все четыре точечных источника формируют единый звуковой сигнал в виде гула. Этот основной звук можно снабдить дополнительными звуковыми сигналами в виде реверберации, чтобы пользователю было проще определить источник звука. Например, что вертолет летит на расстоянии 50 метров на фоне высотного здания из стеклобетона. Как только вертолет приблизится на достаточное расстояние к нам, так, что мы сможем легко его рассмотреть вполне логично ожидать, что мы сможем выделить звук от лопастей (как они рассекают воздух), звук от турбины и звук от хвостового винта. Именно для таких целей и предназначен ZoomFX. На практике все работает следующим образом. В качестве носителя звука вертолета может выступать обычный монофонический wav файл. Затем, когда возникает необходимость выделить составляющие источники звука, начинает работать динамический декоррелятор, который выделяет несколько вторичных звуков, которые затем подвергаются обработке HRTF фильтрами, затем происходит сложение соответствующих каналов (правые с правыми, левы с левыми и т.д.), затем сигнал обрабатывается алгоритмами TCC и воспроизводится через акустическую систему. К слову, возможность создания нескольких виртуальных источников звука с помощью ZoomFX может быть использована, например, для воспроизведения в наушниках многоканального звука типа Dolby Digital.
Технология ZoomFX в отличие от MacroFX не является прозрачной для интерфейсов и игр. Для ее поддержки будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
EnvironmentFX
Технология EnvironmentFX создана для моделирования звука окружающей среды и рассчитана на использование со стандартными интерфейсам типа EAX и I3DL2. По сути, технология EnvironmentFX позволяет воспроизводить эффект реверберации, описывая то, как звуки достигают ушей слушателя в зависимости от параметров помещения. Помещением может быть и открытое пространство и маленькая келья монаха. Когда слушатель находится в помещении с истоником звука он сначала слышит звук, достигший его ушей по прямому пути, затем, чуть поздее, он сылшит ранние отражения (звуки несколько раз отразившиееся от стен или объектов) и в самый последний момент он слышит реверберацию, т.е. поле остаточных отраженных звуков, затухающее со временем.
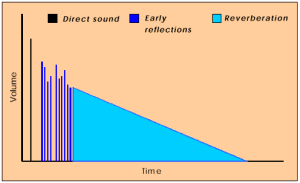
На иллюстрации слева показано распределение звуковых сигналов в зависимоти от уровня громкости и продолжительности во времени.
EnvironmentFX позволяет моделировать различные типы акустики за счет использования специальных алгоритмов, рассчитывающих ранние отражения и реверберацию. При этом истоник каждого из ранних отраженных звуков может позиционироваться индивидуально в 3D пространстве. Для того, чтобы переходы между различными помещениями (читай разными аустическими средами) были плавными и естественными предусмотрены специальные фильтры, причем алгоритм EnvironmentFX динамически переконфигурируется переключаясь на нужный. Имеется возможность динамического регулирования уровня интенсивности реверберации для каждого источника звука индивидуально. EnvironmentFX специально ориентирована на воспроизведение через мультиколоночную конфигурацию акустики с использованием технологии MultiDrive, но при этом допускается воспроизведение звука и через две колонки или наушники. Для моделирования различных акустических сред EnvironmentFX использует параметры самого источника звука (интенсивность, расположение в пространстве) и параметры окружающей среды. Для воспроизведения звука вокруг пользователя EnvironmentFX использует следующие характеристики:
- Direct-to-reverberant sound ratio — соотношение уровней громкости основных звуков и реверберации. Уровень громкости основного звука становится интенсивнее при достижении ушей слушателя и становится тише, когда уходит на задний план. В тоже время уровень громкости реверберации приблизительно неизменен вне зависимости от расстояния между слушателем и источником звука. Сооношение уровней громкости основного звука и реверберации дает слушателю важную информацию для оценки расстояния до источника звука.
- Room size — размеры помещения. В маленьком помещении, например холле, расстояние между отраженными звуковыми волнами мало, т.е. отраженные звуки близки друг к другу и довольно быстро формируют остаточную реверберацию. В большом помещении, например ангаре для самолетов, наоборот, отраженные волны преодолевают большие расстояния и для формирования реверберации требуется больше времени.
- High-frequency cut-off — отбрасывание высокочастотных компонент звука. Когда материал стен или объектов отражает звук, не все частотные компоненты отражаются с одинаковой степенью. Большинство материалов поглощают частоты определенного значения, т.е отбрасывается часть высокочастотных компонент. Например в ванной комнате отражаются звуки с частотой вплоть до 14000 Гц, а в гостинной комнате с коврами на стенах отбрасываются все компоненты с частотой более 2000 Гц.
- Early reflection level — уровень интенсивности ранних отражений. Ранние отражения дают возможность пользователю определить наличие близких объектов и стен. Чем больше предметов и стен находится близко к пользователю тем большим будет процент ранних отражений в общей звуковой картине. Например, близкорасположенные стены из кирпича в коридоре формируют большое количество ранних отражений, а открытое трявяное поле не формирует ни одного раннего отраженного звука.
- Reverberation level — уровень интенсивности реверберации. Уровень громкости реверберации может варьироваться при смене одного помещения на другое.
- Reverberation decay time — время затухания реверберации. Это время, необходимое для того, чтобы реверберация была полностью поглощена воздухом и стенами в помещении. Например, в большом ангаре со звукоотражающими стенами время реверберации порядка 10 секунд, в палате со стенами из войлока очень хорошо поглощающих звук, время затухания реверберации около 0.2 секунды.
- High Frequency decay time — время затухания высокочастотных компонент звука. Время затухания высокочастотных компонент напрямую завист от свойств окружающих объектов и стен. Например мрамор хорошо отражает высокочастотные звуки, а под водой высокочастотные компоненты очень быстро затухают.
- Density — плотность. Плотность отраженных звуков зависит от числа объектов, от которых отражается звук. Чем выше плотность, тем быстрее отраженные звуки переходят в реверберацию. Закрытая комната со звукоотражающими стенами имеет очень высокую плотность отражений, по сравнению с открытым полем.
- Diffusion — рассеивание. Величина, показывающая с какой степенью звуковые волны совмещаются или разделяются при соприкосновении с поверхностями в помещении. Комната с разнообразными по форме объектами созадает высокую степень диффузии звука, чем простот пустая комната с голыми стенами. Многие концертные залы имеют такую форму, что возникает диффузная реверберация.
- Detuning — расстройка. Расстройка может использоваться для симуляции изменения тональности звука, которая возникает при отражении звука от движущихся поверхностей. Может изменяться как величина, так и глубина расстройки. Применяется, например, для симуляции плеска волн на ветру.
Нетрудно заметить, что хотя мы рассмотрели технологию EnvironmentFX самой последней в статье, она, несомненно самая важная из применяемых на практике разработок Sensaura.
| 14 февраля 2000 г. |

|
| Дополнительно |
|





