Наступление ATI Technologies продолжается: RADEON X1900 XTX/XT (R580)
Часть 2: Особенности видеокарты, синтетические тесты
©х/ф «Иван Васильевич меняет профессию»

СОДЕРЖАНИЕ
- Часть 1 — Теория и архитектура
- Часть 2 — Практическое знакомство
- Особенности видеокарты
- Конфигурации стендов, список тестовых инструментов
- Результаты синтетических тестов
Наступление ATI Technologies продолжается: RADEON X1900 XTX/XT (R580): Часть 1: Теоретические сведения
Наступление ATI Technologies продолжается: RADEON X1900 XTX/XT (R580): Часть 2: Особенности видеокарты и синтетические тесты
Итак, мы продолжаем.
Все подробности об особенностях архитектуры R580 (RADEON X1900) уже освещены Александром Медведевым в первой части материала.
Итак, в планы ATI входит выпуск двух карт на этом GPU.
- ATI RADEON X1900 XTX 512MB GDDR3, 650/1550 MHz, 48 pixel/8 vertex pipes/16 TMUs/16 ROPs — $649;
- ATI RADEON X1900 XT 512MB GDDR3, 625/1450 MHz, 48 pixel/8 vertex pipes/16 TMUs/16 ROPs — $549;
Очевидно, что карты отличаются друг от друга минимально. И столь большая разница в цене обусловлена лишь маркетинговыми причинами, чтобы сбить спрос на 1900 XTX с самого начала завышенными ценами.
В нашей лаборатории побывал старший представитель линейки — 1900 XTX в виде reference card, а также X1900 XT в лице продукта от PowerColor, хотя это тоже reference :). О них и расскажем.
Учитывая то, что внешне обе карты ПОЛНОСТЬЮ ИДЕНТИЧНЫ (вплоть до мельчайших деталей!), то представлю лишь reference card.
Плата
| ATI RADEON X1900 XTX 512MB PCI-E | |
|---|---|
|
Интерфейс: PCI-Express x16
Частоты (чип/физическая по памяти (эффективная по памяти): 650/775 (1550) MHz (у 1900 XT — 625/725 (1450) МГц) Ширина шины обмена с памятью: 256bit Число вершинных конвейеров: 8 Число пиксельных конвейеров: 48 Число ROP: 16 Число TMU: 16 Размеры: 205x100x32mm (последняя величина — максимальная толщина видеокарты). Цвет текстолита: красный. Выходные гнезда: 2xDVI, S-Video. VIVO: есть (RAGE Theater) TV-out: интегрирован в GPU. |

|
| ATI RADEON X1900 XTX 512MB PCI-E | |
|---|---|
|
Карта имеет 512 МБ памяти GDDR3 SDRAM,
размещенной в 8-ми микросхемах на лицевой стороне PCB.
Микросхемы памяти Samsung (GDDR3). Время выборки у микросхем памяти 1,1ns, что соответствует частоте работы 900 (1800) МГц. |

|
| Сравнение с эталонным дизайном, вид спереди | |
|---|---|
| ATI RADEON X1900 XTX 512MB PCI-E | Reference card ATI RADEON X1800 XT 512MB PCI-E |

|

|

|
|
| Сравнение с эталонным дизайном, вид сзади | |
|---|---|
| ATI RADEON X1900 XTX 512MB PCI-E | Reference card ATI RADEON X1800 XT 512MB PCI-E |

|

|
Прекрасно видно, что дизайн в принципе не претерпел каких-либо изменений по сравнению с X1800 XT, только лишь чуть-чуть модернизировался блок питания (это логично, так как ядро новое, и микросхемы памяти уже другие, вольтажи иные). В остальном — полная копия, поэтому нет смысла особо заострять на этом внимание, тем более, что мы уже не один раз изучали X1800 XT.
Надо отметить то, что карта оснащена чрезмерно быстрой памятью 1,1 нс. При частоте в 1550 МГц достаточно и 1,26 нс, которая на Х1800 ХТ. Полагаю, что 1,1 нс будет стоять только на сэмплах, а на серийно выпускаемых картах — 1,26 нс. К тому же, вольтаж на памяти понижен относительно штатного для таких микросхем памяти, что, по сути, разгон сводит к нулю.
Стоит сказать, что карта снабжена парой гнезд DVI. Причем, Dual link DVI, что позволяет по цифровому каналу получать разрешения выше 1600х1200 (уже неоднократно возникали недовольства таким ограничением со стороны владельцев огромных цифровых мониторов).
Теперь рассмотрим систему охлаждения.




Да, перед нами все тот же кулер, как сказал мой коллега, «кулеры все больше и больше становятся похожими на холодильник».
Минусов два: размеры (из-за кулера карта вынуждена занимать два слота в системной плате) и стартовый шум. Плюс один, но большой: горячий воздух выносится за пределы системного блока, что очень важно при работе таких горячих элементов внутри него. А карта греется очень сильно!
Я еще раз отмечу, что шум, похожий на вой, только при старте системного блока. Затем обороты резко снижаются, и шума практически не слышно. Лишь при очень сильной нагрузке, когда температура поднимается выше 80 градусов, обороты немного повышаются, и можно слышать слабо-ощутимый шум.
Теперь посмотрим на сам процессор.
X1900 XTX — R580 изготовлен на 45-й неделе 2005 года, это где-то в ноябре, то есть, чипу нет и трех месяцев

Сравнение с X1800 XT

Как мы видим, размеры кристалла ощутимо выросли, чего и следовало ожидать, поскольку число пиксельных конвейеров увеличилось в 3 раза, поэтому количество ALU выросло также сильно, плюс увеличены снова кэши и т.д. Все же 400 млн. транзисторов, против 310.
Если учесть, что этот кристалл работает на частоте еще даже более высокой, чем у R520, то можно себе представить его энергопотребление! Я уже выше говорил, что карта очень и очень греется.
Продукт от PowerColor, в отличие от эталонной карты, поставляется в коробке, и имеет комплект поставки:


Повторю, что в остальном это просто копия рассмотренной ранее X1900 XTX.
Установка и драйверы
Конфигурации тестовых стендов:
- Компьютер на базе Athlon 64 (939Socket)
- процессор AMD Athlon 4000+ (2400MHz) (L2=1024K);
- системная плата ASUS A8N32 SLI Deluxe на чипсете NVIDIA nForce4 SLI X16;
- оперативная память 2 GB DDR SDRAM 400MHz (CAS (tCL)=2.5; RAS to CAS delay (tRCD)=3; Row Precharge (tRP)=3; tRAS=6);
- жесткий диск WD Caviar SE WD1600JD 160GB SATA.
- RADEON X1800 XT (HIS, PCI-E, 512MB GDDR3, 625/1500 MHz);
- GeForce 7800 GTX (ASUS EN7800GTX TOP, PCI-E, 256MB GDDR3, 486/1350 MHz);
- GeForce 7800 GTX (reference, PCI-E, 512MB GDDR3, 550/1700 MHz);
- операционная система Windows XP SP2; DirectX 9.0c;
- мониторы
ViewSonic P810 (21") иMitsubishi Diamond Pro 2070sb (21"). - драйверы ATI версии CATALYST 5.13beta; NVIDIA версии 81.98.
VSync отключен.
Для оценки эффективности нового ядра мы провели также тесты на X1900 XTX на пониженных до X1800 XT частотах 625/1500 МГц.
Теперь посмотрим на мониторинг (X1900 XTX):
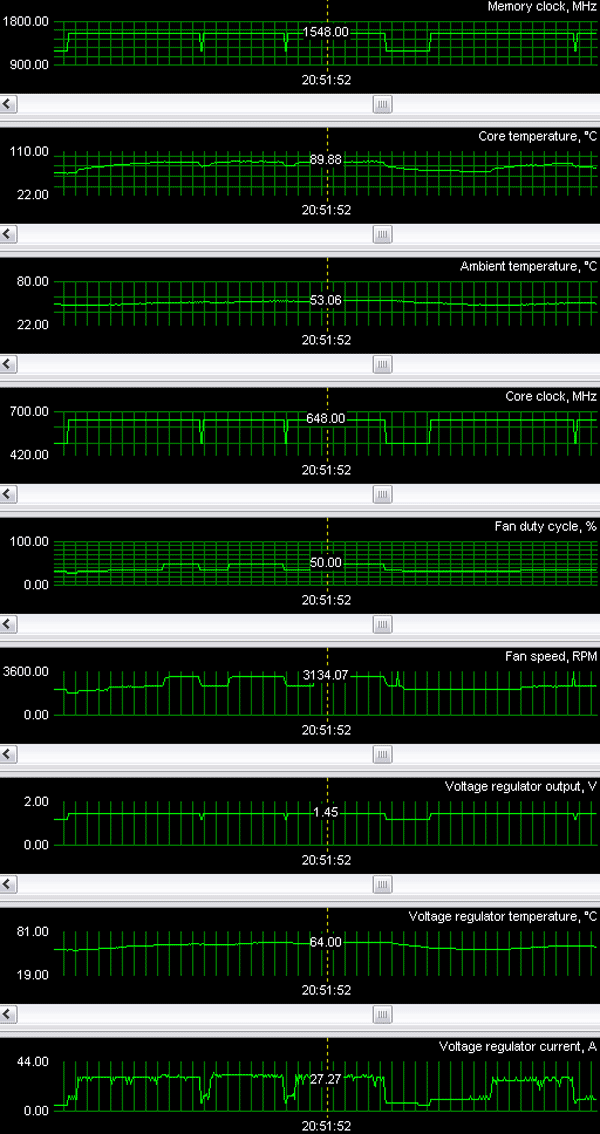
К нашей радости последняя версия RivaTuner после небольшой доработки автором Алексеем Николайчуком смогла корректно работать с новой картой и прекрасно осуществлять мониторинг. По нему видно, что максимальная температура ядра поднялась по сравнению с X1800 XT и составляет почти 90 градусов (по сравнению с 80 у X1800 XT). Максимальный ток нагрузки может достигать примерно 40 А, что в сочетании с напряжением в 1,45 В дает потребление ядра — 58 Вт (считаем 60 для ровного счета). Учитывая, что память работает на меньшем, чем положено для нее, напряжении, потребление там не столь велико (около 20-25 Вт), но все вместе с блоком питания и обслуживающей логикой — в пределах 50 Вт. Так что, новинка точно кушает выше 100Вт.
Пониженный вольтаж на памяти не дает никакой возможности разгона карты по памяти, а ведь очень жаль! Такая быстрая память, и не используется на всю катушку! Кстати, ядро само также плохо разгоняется, от силы на 685 МГц заработало: видимо, уже из 0.09мкм техпроцесса на сегодня выжали все, что можно. Правда, еще остается вероятность подъема напряжения на ядре, что мы уже видели ранее на примере X1800 XT PE, что выпустила компания Sapphire (мы изучали недавно такую карту).
Напомню, что для совместной работы X1xxx-карт с TV и монитором последний надо подключать к нижнему гнезду на видеокарте.
Синтетические тесты
Использованная нами версия пакета синтетических тестов D3D RightMark Beta 4 (1050) и ее описание доступна на
сайте 3d.rightmark.org.
Также мы использовали новые, усложненные и перекликающиеся с адекватными сейчас задачами тесты пиксельных шейдеров
версии 2.0 — D3D RightMark Pixel Shading 2 и нацеленные на будущее тесты D3D RightMark Pixel Shading 3. Сейчас эти тесты
находятся в стадии бета-тестирования и уже доступны для скачивания здесь:
Тесты проводились:
- На GeForce 7800 GTX 512MB со стандартными параметрами (далее G70);
- На оригинальном RADEON X1800 XT (далее R520);
- На новой карте RADEON X1900 XTX (далее R580);
- На новой карте RADEON X1900 XTX на частоте X1800 XT (далее R580-520).
Тест Pixel Filling
Пиковая производительность выборки текстур (texelrate), режим FFP, для разного числа текстур, накладываемых на один пиксель:
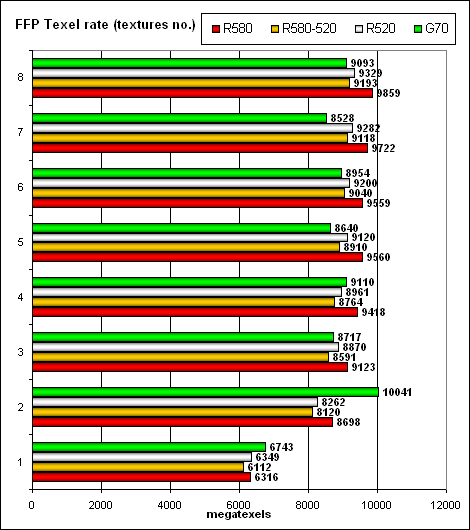
Итак, повышенная частота ядра новой карты на базе G70 позволяет нам говорить о паритете. Единственное исключение — оптимизированный случай двух текстур на пиксель, в котором NVIDIA вырывается вперед. В остальных ситуациях, карты идут нос к носу, согласно тактовым частотам и числу текстурных модулей. Более высокая тактовая частота ядра дает R580 небольшое монотонное преимущество на большом числе текстур. Зато G70 чуть быстрее на одной текстуре — то есть чуть-чуть эффективнее работает с буфером кадра. Интересно, что на равной частоте R520 выбирает текстуры чуть быстрее R580 — видимо, у последнего есть некие накладные расходы, связанные с увеличенным числом пиксельных процессоров, которые, по сути, в этом тесте бесполезны, но которыми надо дирижировать. Расходы эти заметны, постоянны, но столь малы, что не стоят нашего беспокойства — то есть архитектура хорошо масштабируется, и эта возможность была заложена в нее изначально. Впрочем, еще в Xenos (чипе из xbox 360) ATI имели дело с таким соотношением пиксельных процессоров и текстурных модулей (48:16) и наверняка хорошо отладили механизм их взаимодействия.
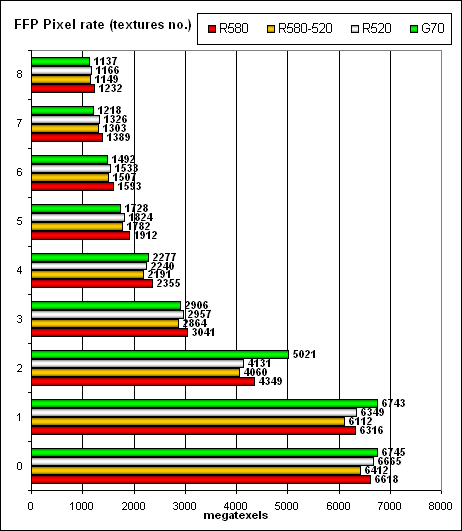
Та же самая картина, но уже в координатах количества записанных в буфер кадра пикселей. В пиковых случаях — 0, 1 и 2 текстуры NVIDIA чуть впереди, в остальных чуть позади.
Проверим ту же задачу, но в исполнении PS 2.0 шейдера:
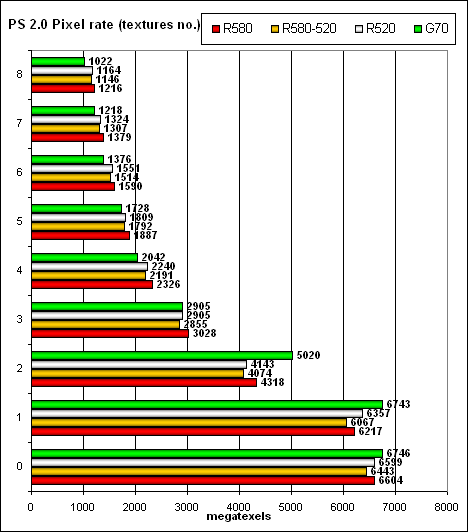
Итак, можно констатировать, что ничего не изменилось — как FFP, так и шейдеры работают совершенно одинаково (с точки зрения железа FFP эмулируется шейдером) и показывают одинаковые результаты. Доминирования не наблюдается, карты идут нос к носу.
Тест Geometry Processing Speed
Самый простой шейдер — предельная пропускная способность по треугольникам:
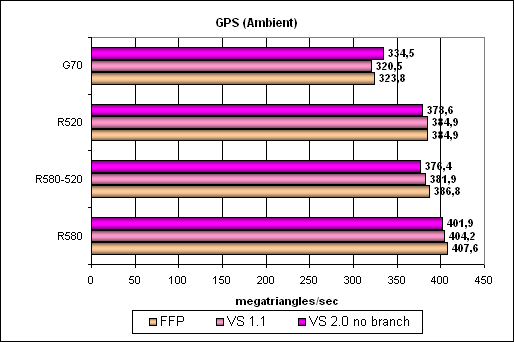
Все согласно тактовым частотам и числу вершинных блоков. Цифры потрясают — 400 миллионов треугольников в секунду — это с запасом. Интересно, что G70 выполняет эту задачу в режиме VS 2 более эффективно, чем в VS 1.1, а R580 и R520 наоборот. Разница не велика, но, посмотрим, во что она выльется в более сложных тестах.
Более сложный шейдер — один смешанный источник света:
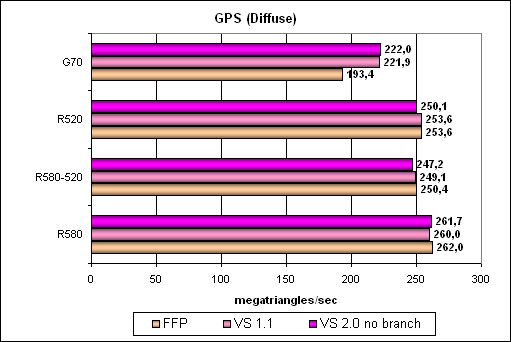
Картина прежняя, отставание NVIDIA в режиме эмуляции FFP несколько усилилось, но по-прежнему не существенно, учитывая большой запас скорости по треугольникам. Усложняем задачу далее:
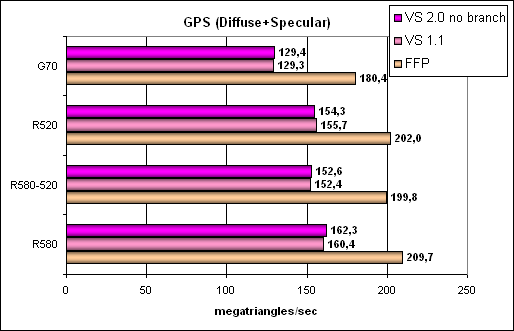
Ага, вот тут на смешанном источнике света проявляется наличие аппаратной оптимизации эмуляции FFP — в этом поколении она есть как у NVIDIA, так и у ATI. Между собой карты вновь распределились сугубо по частотам. Видно, что по сравнению с R520, вершинная архитектура R580 не претерпела никаких заметных изменений (см. R580-520 и R520).
Еще более сложная задача, включая переходы:

Вот здесь мы видим, что переходы — слабое место вершинного блока ATI — если во всех остальных тестах ATI выигрывает у NVIDIA, то в случае динамических переходов производительность заметно падает. В то время как для G70 эти переходы предпочтительнее статических. Сказывается разная организация вершинных блоков — ATI ведет родословную еще от R420 и даже ранее, его вершинные блоки не поддерживают выбор из текстур (тонкий момент, по сути, ставящий под сомнение полноту поддержки SM3 — мы обсуждали этот вопрос дважды, в интервью с ATI и NVIDIA) и менее продвинуты архитектурно в плане работы с переходами. Однако это не сказывается особенно на реальных приложениях, так как большинство из них использует вершинные шейдеры 2.0 без динамических переходов, а производительность блоков у обоих конкурентов, как мы видим, огромна. Ситуация изменится позже с выходом WGF 2 карт, вершинные блоки которых должны будут эффективно справляться с ветвлениями и доступом к текстурам.
Выводы по геометрическим тестам: картина не сильно изменилась, разница между R580 и R520 обусловлена только тактовой частотой ядра. Никаких архитектурных новшеств не наблюдается. Налицо паритет или небольшое лидерство ATI в зависимости от задачи. Если не считать отсутствие доступа к текстурам и странности с компиляцией и исполнением шейдеров 3.0, вершинные блоки продуктов ATI заслуживают похвалу — всё на уровне!
Тест Pixel Shaders
Первая группа шейдеров — достаточно простых для исполнения в реальном времени, 1.1, 1.4 и 2.0:
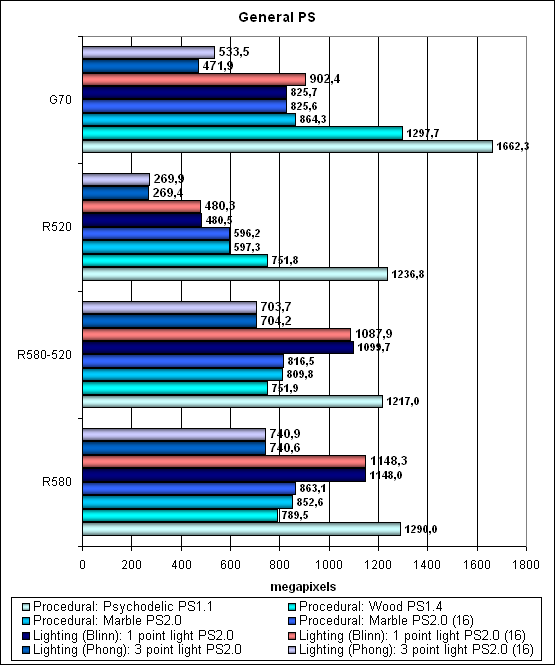
На самых простых PS1.X шейдерах впереди NVIDIA, как и ранее. На более сложных шейдерах 2.0 впереди R580, его преимущество очевидно, хотя и не двукратно. Затем идет R580 на частоте R520 и G70. На последнем месте заметно отстающий R520. Итак, налицо похвальное исправление ситуации с R520 — теперь NVIDIA проигрывает на шейдерах 2.0. По сравнению с R520 новый чип увеличил производительность некоторых шейдеров вдвое, некоторых в полтора раза — что вполне оправдано, учитывая то, сколько транзисторов стоили дополнительные 32 пиксельных процессора. Причем, это без увеличения числа текстурных блоков, только за счет вычислений. Шейдеры с пониженной точностью вычислений — FP16 выполняются быстрее на G70 и не несут никакой выгоды R580 — все верно, различная организация архитектур дает себя знать. Если G70 получает преимущество при снижении числа временных регистров или их точности, то у R5XX их просто «достаточно» и этот чип не относится к объему временных данных так болезненно. А значит, потенциально, его архитектура лучше масштабируется и лучше приспособлена для будущих вычислений, сложных шейдеров и таких дальних перспектив как произвольный доступ к памяти из шейдеров. Остается только похвалить ATI — залог на будущее хорош и очевиден.
Итак, если смотреть в будущее, забыть о шейдерах 1.X — решение ATI не выглядит неоправданным, а наоборот, дает чипу ощутимое лидерство над G70. Впрочем, мы еще не знаем, как поведет себя G71, да и не забываем, что по числу транзисторов сам G70 менее сложен. В любом случае, здесь, в отличие от RV530, концепция 3:1 развернулась в полную силу и продемонстрировала ее уместность в плане пиксельных шейдеров.
Посмотрим далее, более длинные шейдеры:
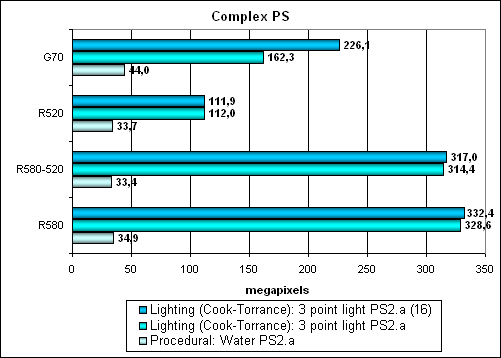
Здесь вновь NVIDIA получает преимущество от 16 битной точности представления (не забываем, что интенсивные промежуточные вычисления в такой точности могут привести к заметному ухудшению качества рендеринга, и сейчас стандартом де-факто и требованиями всех будущих API являются внутренние вычисления в формате FP32). На сложной модели вычислений R580 почти втрое превосходит R520 и заметно обыгрывает NVIDIA, особенно если не учитывать FP16 вариант. Это похвально. Интересно, что небольшая разница между FP16 есть и тут — видимо, сказывается слишком большое число промежуточных вычислений. Но эта разница еле заметна и не критична. В свою очередь шейдер с процедурной водой очень интенсивно использует доступ к текстурам, причем зависимый больших уровней вложенности, и поэтому выполняется быстрее на NVIDIA, где текстурных модулей больше. На лицо дилемма, о которой мы говорили ранее — разные алгоритмы могут быть реализованы разными путями, и на одном чипе получит преимущество реализация с приоритетом вычислений, а на другом — с приоритетом доступа к текстурам. Ведь что-то можно посчитать, а можно просто выбрать из заранее подготовленной таблицы. К сожалению, в данный момент архитектуры не сходятся, и для каждой из них будет оптимален свой шейдер, что привнесет новые сложности программистам, особенно тем, которые старательно оптимизируют свои шейдеры с точки зрения производительности.
В любом случае, на лицо существенное улучшение в области пиксельных шейдеров у R580 по сравнению с R520. Новый чип действительно может считаться королем шейдерной мощи и заметно превосходит G70 на любых не упирающихся в выборку текстур вычислениях.
А теперь:
Наши новые шейдерные тесты
Новые тесты, на которые мы будем постепенно переходить в будущих обзорах, доступны для скачивания (см. выше) в составе архива бета-версии D3D RightMark. В будущем мы откажемся от синтетических тестов с более ранними версиями и полностью сосредоточимся на HLSL шейдерах для SM 2.0 и 3.0. Более ранние шейдеры можно будет проверить на примере существующих приложений, а синтетические тесты, нацеленные на текущий момент и даже далее, в будущее, требуют корректировки в соответствии с веяниями времени, что и было проделано.
Начнем с более простых шейдеров PS 2.0. Доступны два новых теста, реализующих актуальные для современных приложений эффекты:
- Parallax Mapping;
- Сложную процедурную текстуру замороженного стекла Frozen Glass с управляемыми извне параметрами.
Оба шейдера мы тестируем в двух исполнениях: максимально ориентированном на вычисления и на выборку текстур. Кроме того, мы проверяем результаты для FP16 и для FP32 точности вычислений.
Итак, сперва вычислительно интенсивные варианты решения задачи:
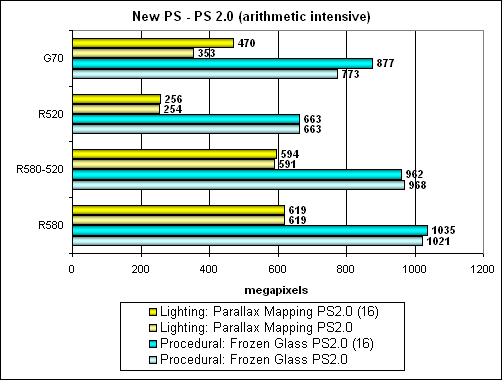
Как мы видим, на первом месте стабильно идет R580 (особенно ему удается параллакс-маппинг), затем G70 и на последнем R520. Опять таки, производительность G70 заметно зависит от точности. Теперь те же самые тесты в варианте с предпочтением выборки текстур:
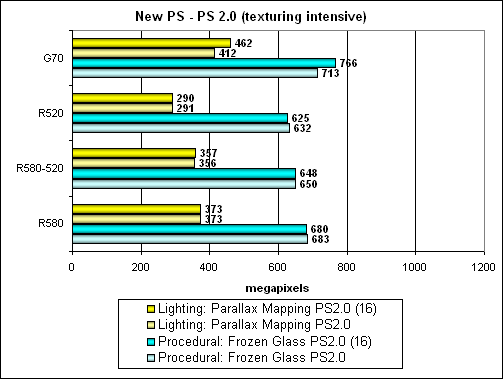
Здесь, как мы видим, преимущество R580 над R520 практически не сказывается, так как все упирается в текстурные блоки, которых и там и там 16. В таком случае NVIDIA выглядит победителем, формально. Однако так как она все равно чуть быстрее работает в первом сценарии с вычислениями (на процедурном тесте) и чуть, но не сильно, медленнее во втором (на тесте параллакс-мапинга) программисты, скорее всего, предпочтут остановиться на первых вариантах шейдеров и не делать два разных шейдера для разных карт. В этой ситуации выиграет ATI, конечно, если программисты не решат, почему-либо (интересно почему?) сделать шейдер именно с упором на текстуры, для того чтобы сравнять шансы G70 и R580. Тогда выйдет что все 32 новых пиксельных процессора ATI сделаны почем зря. Интересная ситуация — слишком много зависит от контекста и предпочтения программистов, посмотрим, какие пути они выберут в своих приложениях. Однако не забываем, что может быть ситуация, когда выбор уже сделан — скажем, игра уже вышла, и тогда все может сложиться не в пользу R580. Просто потому, что программисты еще не знали о его особенностях и столь высокой производительности именно на вычислениях, а не на выборке текстур.
Теперь еще один новый тест — пиксельные шейдеры 3.0:
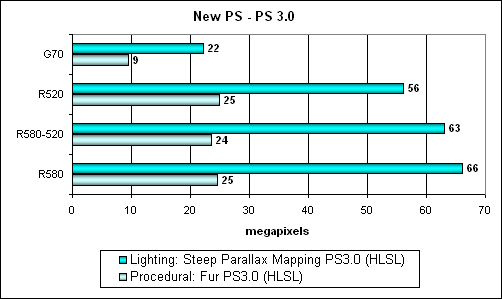
Два шейдера, больших, сложных, с интенсивными ветвлениями:
- Steep Parallax Mapping;
- Процедурный шейдер Fur (мех).
Эти шейдеры без компромиссов — только посмотрите на скорость их исполнения даже на таких производительных картах. Ни о каких 16 битах вычислений речи не идет, все по полной программе. Очевидна и расстановка сил — эффективное исполнение SM 3 шейдеров новой архитектурой ATI налицо. Преимущество более чем двукратное. Браво! Задел на будущее есть, осталось только реализовать его в рамках WGF 2 платформы. И тогда, шейдерам будет действительно недалеко до своих собратьев из кино и высокопроизводительного оффлайнового рендеринга.
Выводы: увеличенное число пиксельных процессоров R580 дает себя знать с лучшей стороны во всех шейдерных тестах, начиная с PS 2.0. Налицо существенный задел на будущее — для сложных кинематографических шейдеров и прекрасная фора для передовых игр настоящего. Но будет ли она раскрыта? Ведь число текстурных блоков по-прежнему 16. Далее, в игровых тестах мы увидим, как современные приложения соотносятся с соотношением 3:1, выбранным ATI. Наши непростые синтетические тесты показали, что при правильном подходе к написанию эффектов преимущество R580 неоспоримо, но, надо знать о нем, чтобы выбрать этот подход. Будет ли это сделано, и было ли это сделано в уже существующих играх? Посмотрим.
Тест HSR
Пиковая эффективность (без текстур и с текстурами) в зависимости от сложности геометрии:
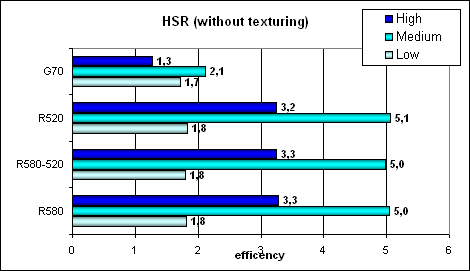
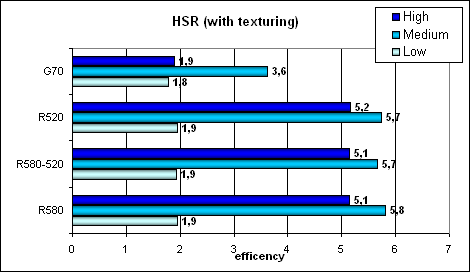
Как мы видим, никаких изменений в практических тестах по отношению к R520 не наблюдается. Возможно, начиповый буфер и правда был увеличен, но его скомпенсировала повышенная частота ядра. В любом случае иерархический HSR в исполнении ATI выглядит более успешным, чем одноуровневый в случае NVIDIA, особенно на сложных и средних сценах.
С текстурированием NVIDIA чуть реабилитирует себя — сказывается более эффективная (для простой закраски) интеграция текстурных модулей в пиксельный конвейер.
Абсолютные значения для сравнения:
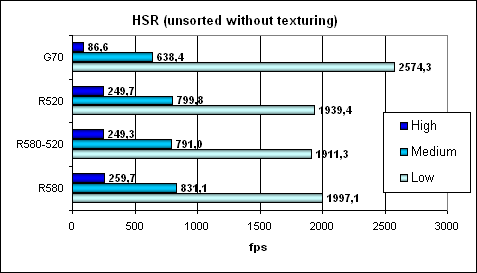
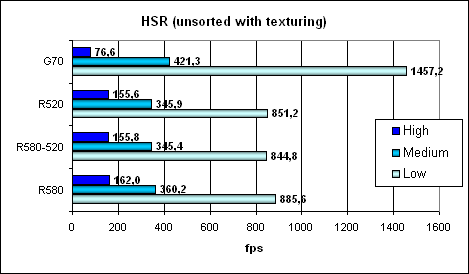
Тут мы видим, что, несмотря на более низкую эффективность, 24 текстурные модуля G70 могут показать зубы. Впрочем, как только дело дойдет до вычислений и шейдеров, а не только простой закраски хаотичной сцены, преимущество быстро сойдет на нет. Сама же эффективность работы блока HSR, как мы уже отметили ранее, у G70 ниже.
Тест Point Sprites
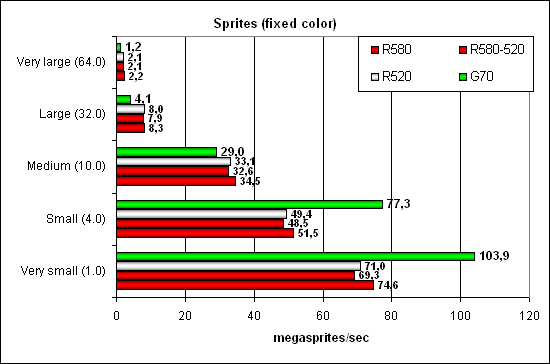
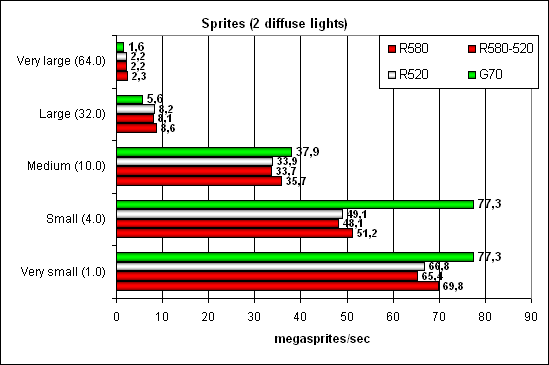
Все как обычно — NVIDIA впереди на небольших спрайтах благодаря более эффективной работе с буфером кадра. По мере роста их размера и сложности освещения она проигрывает, впрочем, не фатально.
Выводы по синтетическим тестам
- Увеличение числа пиксельных процессоров реально демонстрирует мощь и масштабируемость новой архитектуры ATI. Пенальти на согласование большего числа блоков не велико, а преимущество в пиксельных шейдерах очень заметно и стремительно растет по мере роста их сложности;
- Самая досадная проблема — по-прежнему 16 текстурных блоков R580. В тех случаях, которые можно назвать неудобными, именно они не дают R580 показать себя лучше или не хуже G70. Не надо быть провидцем, чтобы предсказать, что она напомнит о себе и в реальных игровых тестах. Если бы их было 24 или 32 — 7800 GTX заметно проиграл бы R580 во всех тестах. А так — посмотрим, скорее всего, будет иметь место паритетная или около того ситуация, за исключением преимущества G70 в DOOM 3 и движках на его основе;
- Вершинная производительность ATI на высоте (хотя и есть небольшие выше упомянутые «но»).
Впереди будет самая главная часть по тестам в играх. Оставайтесь с нами!
Наступление ATI Technologies продолжается: RADEON X1900 XTX/XT (R580) — Часть 3: Игровые тесты (производительность)

| 24 января 2006 г. |
|
|